MySQL 索引实现
数据结构
Mysql 使用 B+树
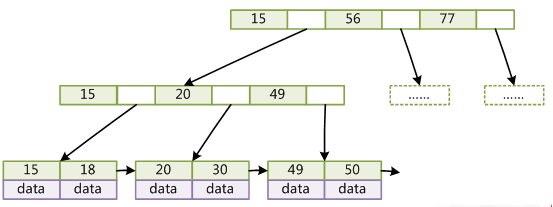
为什么选择 B+ 树,而非二叉树,红黑树,B- 树呢?
- 二叉树:对于表提供自增整形字段作为建立索引的列,那子元素总是添加去了右侧,导致左子树一直为空,那么查找时就完全退化成了没加索引那样了。
- 红黑树:红黑树解决了二叉树不平衡的问题。然为什么要费力保持树的平衡性?是因为树的查找性能取决于树的高度,让树尽可能平衡,就能降低树高。但因为其父节点只能存在两个子节点,那在数据量大的时候,深度也很大。
- B树:BTree 的结构可以弥补红黑树树深的缺点,B 树是一种多路的搜索树,它的每一个节点都可以拥有多于两个孩子节点。当一棵树无法加载进内存时,B 树多路的威力得以展现,内存可以每次加载 B 树的一个节点然后一步步向下找。但若范围查询,BTree结构还是要从根节点开始往下查询一遍,效率不够高。
- B+:B+ 在 B 树上改进,它的数据都在叶子节点,同时叶子节点之间还加了指针形成链表。范围选择只需要找到首尾,通过链表就能把所有数据取出来了。
见 B+ Tree
InnoDB 索引实现
InnoDB 也使用 B+Tree 作为索引结构,但具体实现方式却与 MyISAM 截然不同。
第一个重大区别是 InnoDB 的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
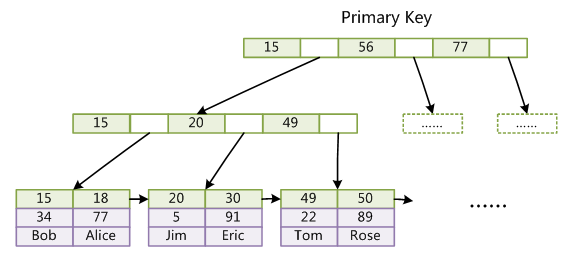
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
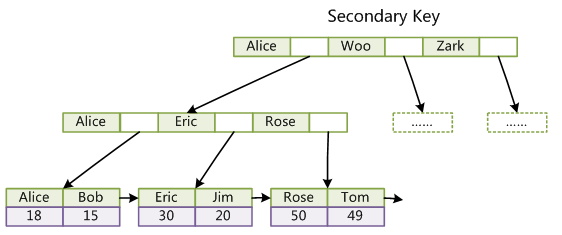
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
联合索引
和单列的索引的差别在于联合索引是每个树节点中包含多个索引值,在通过索引查找记录时,会先将联合索引中第一个索引列与节点中第一个索引值进行匹配,匹配成功接着匹配第二个索引列和索引值,直到联合索引的所有索引列都匹配完;如果过程中出现某一个索引列与节点相应位置的索引值不匹配的情况,则无需再匹配节点中剩余索引列,前往下一个节点。
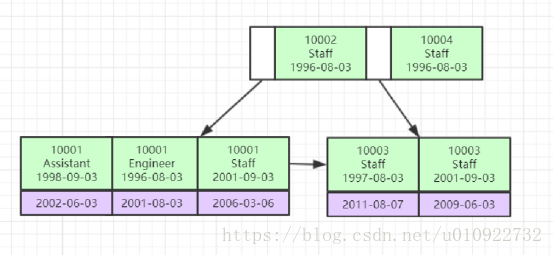
什么时候使用联合索引?
咨询 dba,根据经验,才发现联合索引的建立要求的条件挺苛刻。一般程序开发中很难确定最左前缀的选择,因为这个查询条件可能并不一定包含那个最左前缀。dba如是说
对于查询列来说。一般基值比较(基值大是指这个列在全表数据中,重复项很少)大的,单列加索引。基值比较少,但是经常查询的,可以加联合索引。排序的可以考虑加联合索引,查询列在前,排序列在后。其他的不推荐联合索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号