BUAA_OO_第一单元总结
1. 作业简介
OO第一次作业的主要内容是展开一个含有括号、三角函数、求和函数、自定义函数的表达式,使其不含有多余的括号、求和函数、自定义函数等。在完成化简的基础上,可以对表达式进行同类项合并、三角函数合并等操作,使其长度最小,这样可以获得较高的性能分。
表达式格式的构造采用了形式化的描述,这是一种很新奇而有效的结构。意味着我们可以轻松地用递归调用生成符合条件的表达式,也可以只针对给定的表达式结构对应地解析,不必自行构造样例情况。
第一次作业的形式化表述如下:
- 表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
- 项 → [加减 空白项] 因子 | 项 空白项 * 空白项 因子
- 因子 → 变量因子 | 常数因子 | 表达式因子
- 变量因子 → 幂函数
- 常数因子 → 带符号的整数
- 表达式因子 → '(' 表达式 ')' [空白项 指数]
- 幂函数 → 'x' [空白项 指数]
- 指数 → '**' 空白项 带符号的整数
- 带符号的整数 → [加减] 允许前导零的整数
- 允许前导零的整数 → (0|1|2|…|9)
- 空白项 →
- 空白字符 → (空格) | \t
- 加减 → '+' | '-'
2. 架构分析
2.1 表达式结构类图

Factor接口 是所有表达式组成部分的顶层接口,其中定义了一个方法:getCalculator,其作用为返回一个Calculator型的对象,作为所有表达式组分的统一化表示。Calculator内部实现了相互之间的加减乘除、乘方、toString方法,其原理是在内部定义一个私有的hashMap,用hashMap来定义表达式中的项,依赖此实现简洁的化简操作。项中只包含化简结果所允许的基本因子,包括x, cos(), sin()。
Expr类 是表达式类,也是整个表达式体系的最上层结构。按照形式化定义,其中内置了一个数组用来盛放项Term。
Term类 是项类,表示一个表达式中连续相乘的部分,其中内置一个数组用于盛放因子Factor。由于Term类中可盛放的因子也包含表达式因子,因此Expr完全可以作为Factor盛放在Term类中。因表达式形式化的限制,容器中一般不含有Term。
Number类,Variable类,Power类 分别表示纯数字、变量x、幂次,是项中最基本的因子。
Function接口 是用于管理所有函数的接口,其可被视为项中的因子。
Sine, Cosine类 是三角函数类。
Sum类 是求和函数类,定义了求和的开始、结束、因子,并通过字符串替换来实现代入。
CustomFunc类 是自定义函数类,其内部定义了一个substitute函数,能通过字符串替换完成代入。
2.2 表达式的计算
以下是两个重要的表达式计算类:Calculator类和BasicItem类。
(由于StarUML不支持变量类型中带有",", 因此HashMap中的","用下划线代替了)

思路:我们可以把所有表达式的化简结果归结为 系数 * 最简项 + 系数 * 最简项 + 系数 * 最简项 + ... 的形式
在第一次作业中,由于最后的表达式里面只会出现x,形如 $a_n * x^n + a_{n-1} * x^{n-1} + ... + a_1 * x + a_0 $, 所以我们可以用hashMap简单地记录表达式中x的次数与系数的对应关系。
在第二、三次作业中,每个项中不一定只含有x一个因子,可能是含有多个基本因子的形式,如\(x^3*sin(x)^2*cos(x**5)*sin((x+9))\),此时我们就得记录连乘因子与系数的对应关系。关键是连乘因子用什么来表示。首先,直观上可以用String来表示,但是这样就很难合并同类项了,因为同样的式子,交换项中因子的顺序,字符串就不会相同。我采用的是构建一个对象BasicItem, 在其中定义HashMap映射式子中基本因子与次数的关系。再把BasicItem作为key存放到Calculator的HashMap中,映射其与系数的关系。
用自定义的对象作为HashMap的key,需要定义equals和hashCode方法,用来定义两个项是否相等,以及求哈希值。hashMap的相等当且仅当两个hashMap所含的项相同(不论顺序),这样,相同的项可以轻松地合并。
一般情况下,我们只需要用Idea自动帮我们生成equals和hashCode就可以了。
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
BasicItem basicItem = (BasicItem) o;
return Objects.equals(hashMap, basicItem.hashMap);
}
@Override
public int hashCode() {
return Objects.hash(hashMap);
}
此外,相比于直接在Calculator中创建一个全局HashMap(HashMap<HashMap<String, Integer>, Integer>), 我更倾向于将前一个HashMap放到一个类里单独操作。原因是全局的hashMap逻辑相对复杂,代码写起来容易出错。若把部分功能下放到BasicItem中,逻辑关系会比较简单,而且只要设计好了BasicItem内部的方法,就可以在上层直接使用,不需要顾及底层的细节,这样不容易出错。
3. 度量分析
3.1 圈复杂度
3.1.1、什么是圈复杂度
圈复杂度(Cyclomatic complexity,CC)也称为条件复杂度,是一种衡量代码复杂度的标准,其符号为V(G)。
直观来说,圈复杂度衡量的是代码中条件判断、循环等语句的数量。一般条件判断、循环越多,圈复杂度越高,表示要走遍所有判断分支所需的次数越多。
圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1。
对应的计算公式为:V (G) = P + 1
其中P为判定节点数,常见的判定节点有:
- if 语句,包括else if,else
- while 语句
- for 语句
- case 语句,switch中的所有case语句都应被计算
- catch 语句
- and 和 or 布尔操作 (对应条件判断中的|| 和 &&)
- ? : 三元运算符
3.1.2、计算圈复杂度示例
以我在Parser类里写的解析表达式函数parseExpr为例:
public Expr parseExpr() {
Expr expr = new Expr();
boolean isNeg = false;
if (lexer.peek().equals("+") || lexer.peek().equals("-")) {
if (lexer.peek().equals("-")) {
isNeg = true;
}
lexer.next();
}
Term term = parseTerm();
if (isNeg) {
term.neg();
}
expr.addTerm(term);
while (lexer.peek().equals("+") || lexer.peek().equals("-")) {
String peek = lexer.peek();
lexer.next();
// 根据前面的符号来取反
Term term1 = parseTerm();
if (peek.equals("-")) {
term1.neg();
}
expr.addTerm(term1);
}
return expr;
}
首先,我们数分支语句if, while的数量:
共有4(if) + 1(while) = 5
然后,我们数逻辑运算&& 和 ||的数量:
共有2(||)=2
根据上面的公式,相加可得 V(G) = P + 1 = 5+2+1 = 8
与MetricsReload中计算的值相等。
3.1.3、圈复杂度与测试
测试驱动的开发 与 较低圈复杂度值 之间存在着紧密联系。
因为在编写测试用例时,开发人员会首先考虑代码的可测试性,从而倾向编写简单的代码(因为复杂的代码难以测试)。
一个好的测试用例设计经验是:创建数量与被测代码圈复杂度值相等的测试用例,以此提升测试用例对代码的分支覆盖率。
这意味着,在之后的OO测试中,为了覆盖所有的情况,至少需要造V(G)个样例,每个样例需要走不同的“圈路径”,这可以用我们之前学的JUnit很容易实现。同时也给我们单元测试提供了一种很好的思路。
3.2、本次代码的度量分析
- 方法度量分析
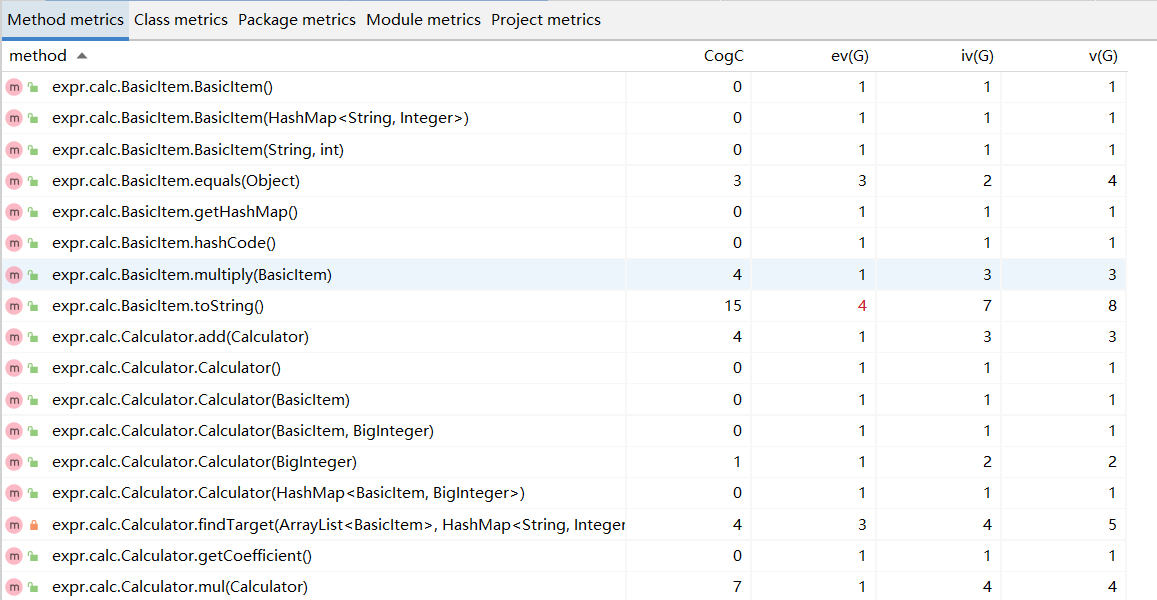
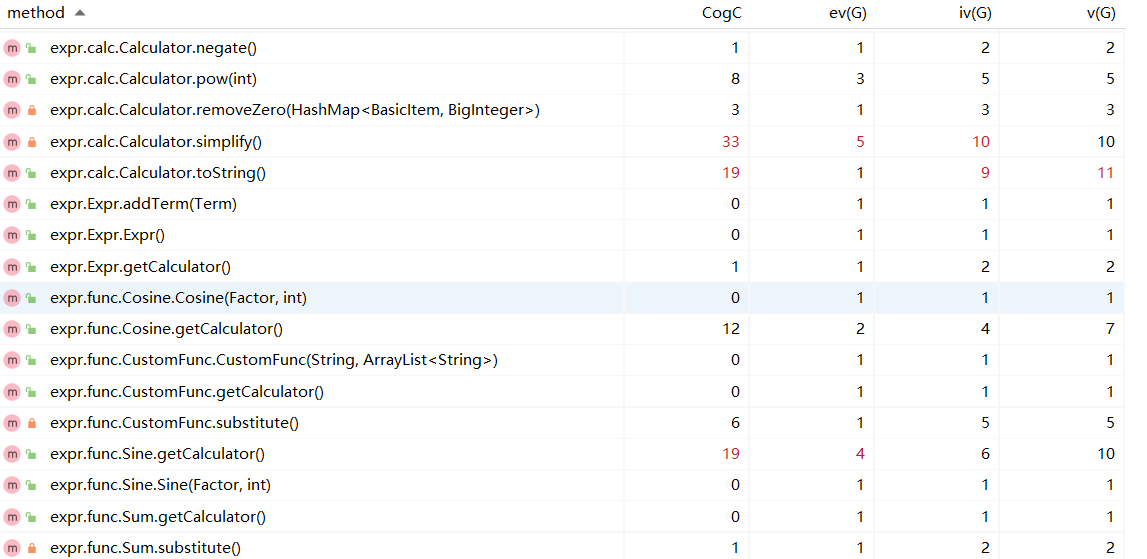
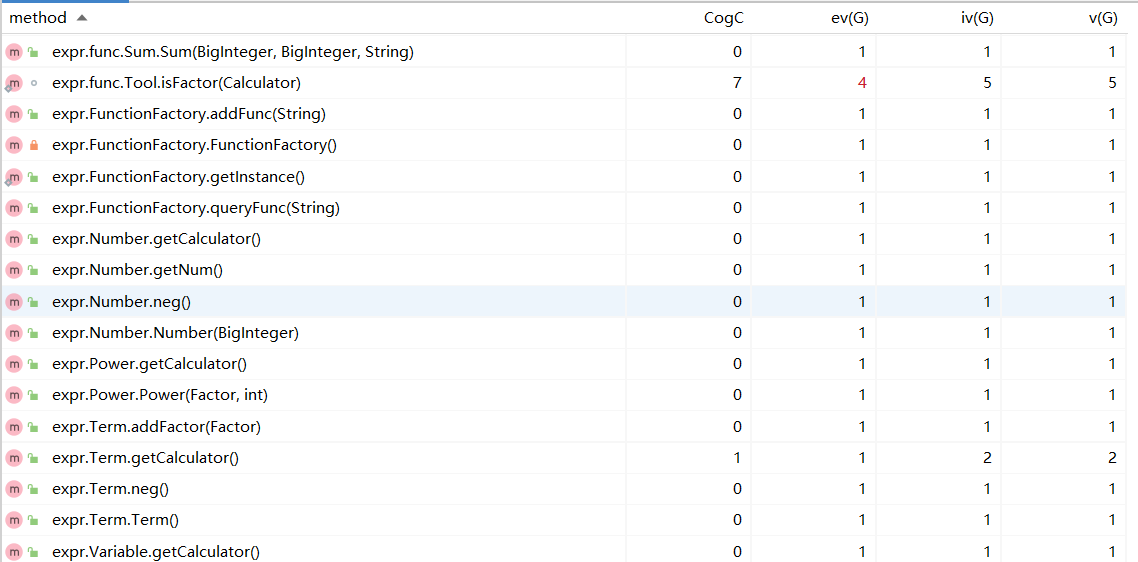
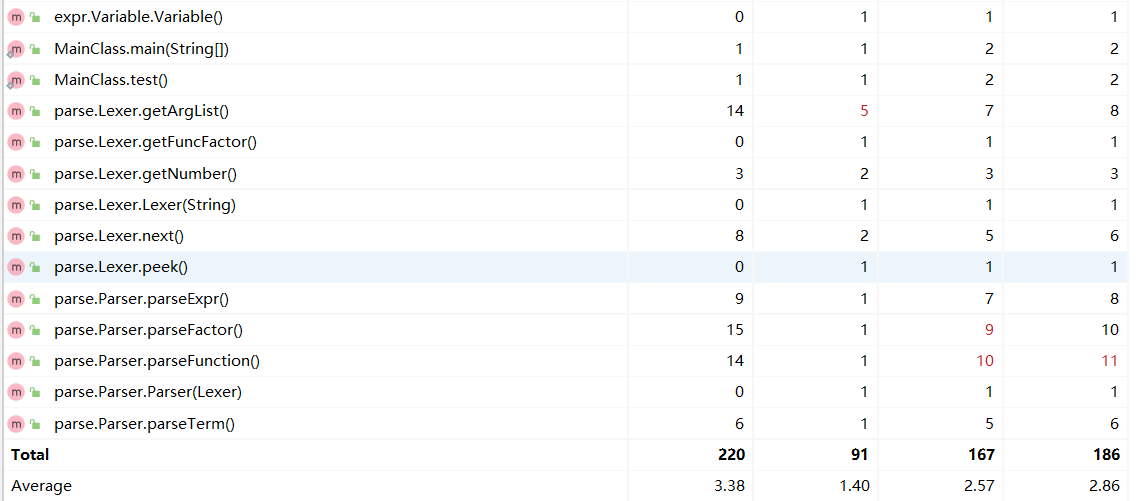
- 类度量分析

4. bug分析
4.1 Hack思路 & 评测机设计
第一单元我主要在第一次作业Hack到他人的代码,主要是通过生成样例数据跑大规模评测来完成的。
测试数据我采用Python生成,按照递归的方式逐次调用,依次生成形式化表述中各表达式部件。在递归过程中,需要控制括号的深度,以防因随机选择表格式组分时选择了表达式因子偏多而造成无限循环。(我并不理解其中的原理,可能与概率论有关系?)在递归时设一个深度因子depth, 每次生成括号,向下传递深度depth-1,如果depth为0,就不再继续生成括号。这样能够有效防止无限递归,又很好地控制了表达式的复杂度。
# 生成数字
def getNum():
length = randint(1, numlen)
result = ""
for i in range(length):
num = str(randint(0, 9))
result = result + num
return result
def coinChoice():
return randint(1,2) == 1
def getAddSub():
return "+" if coinChoice() else "-"
def getSignedNum():
num = getNum()
return (getAddSub() + num) if coinChoice() else num
def getExponent():
return "**" + ("+" if coinChoice() else "") + str(randint(0,expmax))
def getPower():
return "x" + getExponent()
def getTerm(depth):
str = (getAddSub() if coinChoice() else "") + getFactor(depth)
for i in range(randint(1, level)):
str = str + "*" + getFactor(depth)
return str
def getTriangleFunc():
funcName = "cos" if coinChoice() else "sin"
factor = getSignedNum() if coinChoice() else getPower()
return f"{funcName}({factor})"
def getFactor(depth):
choice = randint(1,4) if depth != 0 else randint(1,3)
if choice == 1:
return getPower()
elif choice == 2:
return getSignedNum()
elif choice == 3:
return getTriangleFunc()
else:
return f"({getExpr(depth-1)})" + (getExponent() if coinChoice() else "")
def getExpr(depth):
str = (getAddSub() if coinChoice() else "") + getTerm(depth)
for i in range(randint(1, level)): # 有限的表达式项
str = str + getAddSub() + getTerm(depth)
return str
评测结果时使用了Python的Sympy库,将化简后的表达式与原表达式进行比较,判断是否相等。(Sympy太强大了,z做数分求导、极限yyds!)
之后的作业,我没有对自定义函数、sum进行生成和评测,因为sympy中没有这样的函数定义,需要自己实现替换。觉得太麻烦,相当于同样一份代码写两份。但是,听了研讨课上同学的分享,我发现其实求和可以直接转换为Sympy的类型,自定义函数也可以在内部就进行替换了,不用按照作业程序的方式:先生成数据,再解析化简,最后比较,而是可以在生成过程中直接把sum,自定义函数解析化简。后两次作业没有用评测,结果都出了bug,也算是吃了个教训吧。
4.2 典型bug分析
- sin cos 的0次幂不处理问题
例:
sin(2)**0 ===> sin(2)
原因:basicItem在toString的过程中没有考虑因子系数为0的情况,且sin()的getCalculator方法在指数为0时仍然返回一个hashMap,里面映射sin因子到0。这种情况,反映了参数接口两边规范不一的情况。为避免这种情况,需要在函数和类之间协作时规范传入传出数据的格式,调试时还可使用assert(断言某种情况发生),方便排错。
- \(sin^2(x) + cos^2(x)\)化为1,与常数项因子冲突
例:
sin(x)**2 + cos(x)**2 + 1 ==> 1
原因:sin^2 与 cos^2 加和后的因子直接放入HashMap中,没有判断hashMap中是否有相同的因子。
改进:先判断HashMap中是否有相同因子,若有,则需要更新;若没有,则直接put。
- sum 起点和终点使用大整数问题
原因:这种属于读指导书不细,导致吃亏。
5. 架构设计体验
第一次作业时,我就按照课程要求采用了表达式对象层层包含建树的架构。不得不说,这种架构真的是相当地稳,在第二、三次作业有新要求时,完全不需要有大变化,只需要加一些新的因子就行了。
但是,在解析表达式的时候,一开始仿照课上实验写的Lexer词法分析类与Parser表达式解析却出现了很大的冲突,导致我纠结于一些读字符串元素的操作到底是放在Lexer的next方法里,还是放在Parser的parseX里。最后,我平衡了两个类的功能,使得读小型表达式部分 (如"sin", "cos", "(", ",", "+"等等) 的操作,放在lexer里面,具体生成解析结构的操作,放在Parser里面。
- 优点:模块分离,易于测试和排错,可读性较强。
- 缺点:两个模块是强耦合的,添加新功能时需要同时操作两个类,就本次作业而言把所有解析功能都集成到Parser里更方便;Lexer和Parser在字符串处理上的职责不清,添加新功能时令人纠结,也不利于理清代码逻辑。
递归下降的方法适用性和解析能力很强,天然可以处理多层括号。因此,在第二次作业到第三次作业的转换过程中,递归下降法的解析过程几乎不需要改动。而写的一些用正则表达式解析的代码,在迭代的时候就遇到很大困难,因为要求变了,正则部分就需要全改。到最后的时候,我的代码里面几乎没有正则表达式了,这侧面也说明了递归下降方法的强大。
6. 心得体会
-
- 感受到了自动化测试的重要性,纯自己造数据很容易漏掉一些情况,之后很容易被hack,还是得写写数据生成器和评测机。
-
- 架构很重要,在写程序之前,先要有个完整、逻辑清晰的架构设计,再去写代码就不会糊里糊涂的了。
-
- 更了解java的自带数据结构了。在使用HashMap时,对其边遍历边修改&删除元素,导致出错。由此明白这种情况下需要用迭代器迭代处理。
-
- 理解了面向对象的理念。面向对象是一种思维方法,涉及三个基本问题:如何管理对象、如何建立对象之间的层次关系、如何管理和利用层次关系。初步理解了如何站在更高的层次上分析问题、解决问题。
-
- 学会用checkstyle之后,代码风格赏心悦目,浏览代码省时省力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号