fastapi U1S02、小说章节读取——fastapi返回数据和网页 ,路径参数
为啥要返回不同的东西
上回咱们让fastapi的基本服务跑了起来,接下来我们开始处理请求。
大致来说,请求的目的有两种:
- 请求数据自己处理——APP,js脚本等
- 请求一个网页直接给用户展示
基本上所有的开发需求都是围绕着这两点展开的。
接下来的内容有点多,请大家耐心跟着尝试一遍,理解fastapi的基本用处。
定制请求数据
不同的请求路径
通过修改请求路径,我们可以实现在浏览器中调整一下请求,得到不同的数据。体现到网页上其实就是一个网站里的不同子页面
话不多说上代码
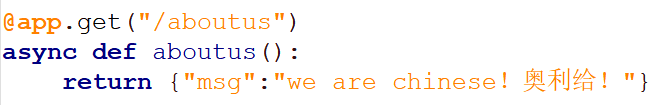
点击可以复制代码
from fastapi import FastAPI
app = FastAPI()#创建一个服务器的实例(对象)
@app.get("/")
async def index():
return {"msg":"诶,我修改了"}
@app.get("/aboutus")
async def aboutus():
return {"msg":"we are chinese!奥利给!"}
if __name__ =='__main__':#表示直接运行当前的程序
import uvicorn
uvicorn.run('main:app', host='localhost', port=8000, reload=True)
看一下效果:
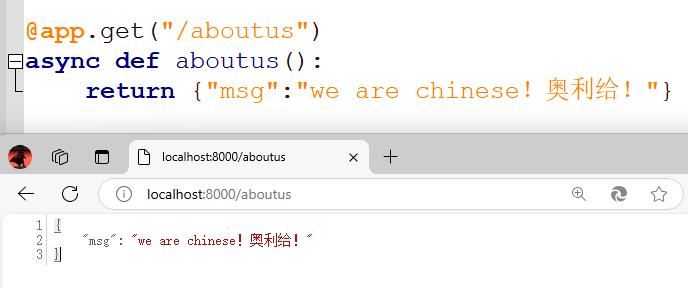
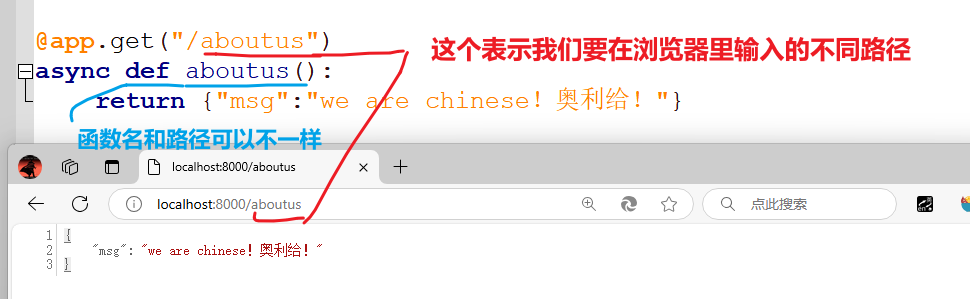
说明:
注意:接下来的代码就不给完整的了,请大家自己学会往代码里加
带参的请求
不需要参数的请求就直接获取数据,上一篇笔记已经写过了。这里咱们再添加一个带参数的请求。

点击查看代码:添加了带参数的请求
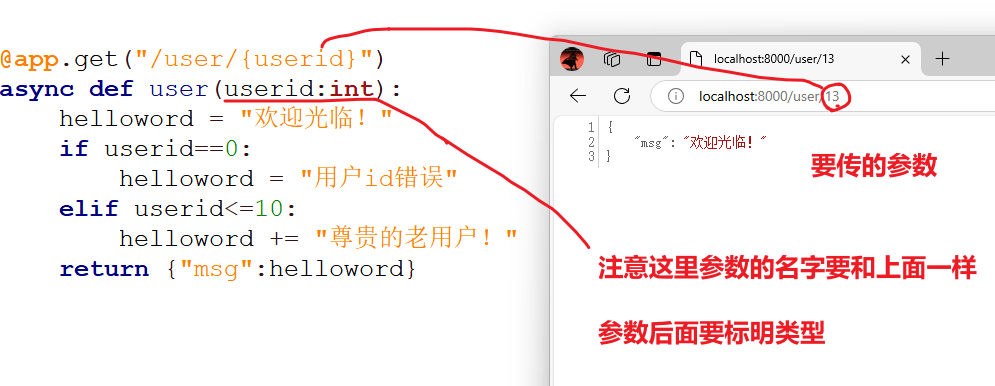
@app.get("/user/{userid}")
async def user(userid:int):
helloword = "欢迎光临!"
if userid==0:
helloword = "用户id错误"
elif userid<=10:
helloword += "尊贵的老用户!"
return {"msg":helloword}
程序运行的效果:user后面给不同的数字,这次就能得到不一样的结果,这是因为我们在代码里做了处理。
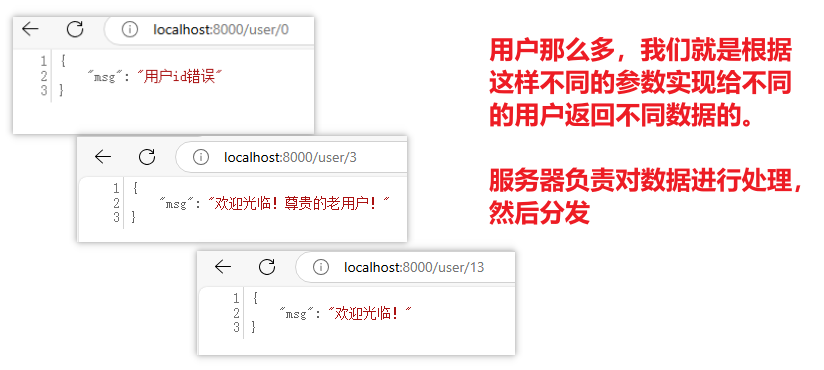
解析:
小试牛刀——小说章节请求
接下来我们通过带参的方式,请求一下本地小说的不同章节。
首先请把下面的附件下载下来,然后解压到电脑里。
https://gitee.com/cgyounger/python-tutorial/raw/master/fastapi/章节.rar
备注:
- 如果你懂得文件的路径怎么用,那么放哪里随意
- 如果你不懂路径怎么用,请把所有的文件都放到和代码一起的文件夹里。
最好是用一个文件夹把文件放进去,因为这样看起来很厉害。
注意:下面代码里的函数名还用了user,一方面想让大家体会一下函数名和路径名可以不一样这件事。另一方面是因为我忘了改。
代码:

点击查看代码
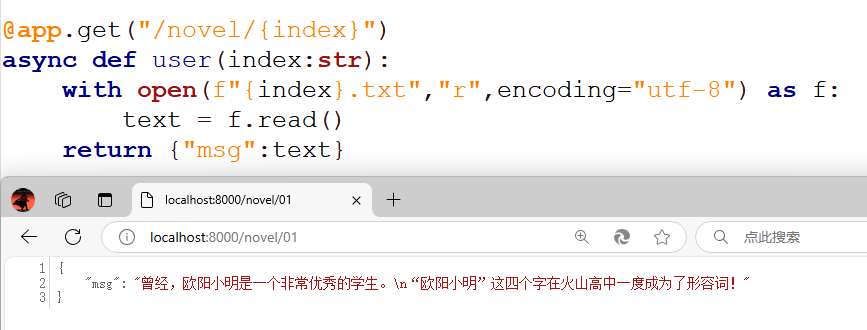
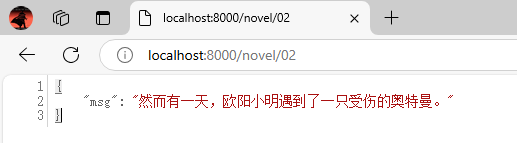
@app.get("/novel/{index}")
async def user(index:str):
with open(f"{index}.txt","r",encoding="utf-8") as f:
text = f.read()
return {"msg":text}
未完待续!
用网页来展示内容
基本做法
我们可以看到浏览器加载出来的太丑了,换行\n都给整出来了。
上面的处理方式是给打算自己处理数据的情况使用的。比如一个小说APP,但是网页的话就不能直接这么给
那接下来咱们了解一下怎么给用户返回一个现成的网页。
老规矩,先上代码。
注意要加一个import

接口代码:

点击查看代码
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
@app.get("/novelhtml/{index}",response_class=HTMLResponse)
async def user(index:str):
with open(f"{index}.txt","r",encoding="utf-8") as f:
text = f.read()
htmlstr = f'''<!DOCTYPE html>
<html lang="en">
<html>
<head>
<meta charset="utf-8">
<title>novel</title>
</head>
<body>
<p style="white-space:pre">{text}</p>
</body>
</html>
'''
return htmlstr
看看具体的效果:
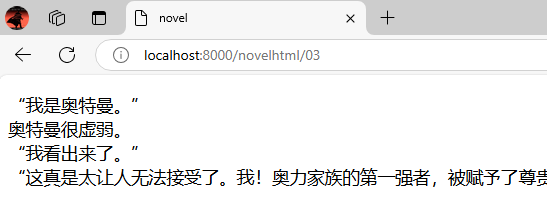
解析:
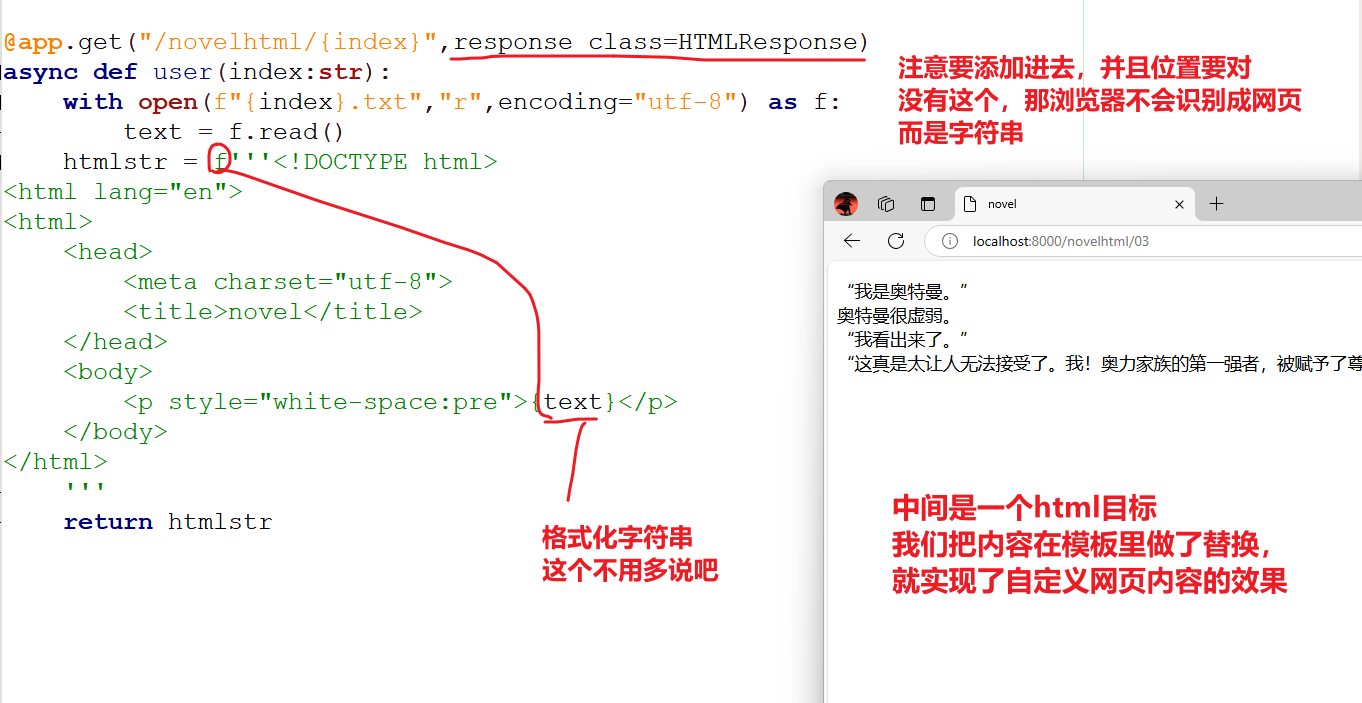
读取HTML模板
可以看到上面的代码,在函数里面写了一个html的字符串,会导致代码很长,很乱,很low。
并且还有个什么问题呢,如果要添加样式、脚本、等等的,相信我,你会原地爆炸!
所以我们再做个事儿:把HTML模板弄成文件,然后读取文件进行操作。
首先在代码的文件夹里,弄个html后缀的文件,内容就是刚才的一堆html字符串。
建议自己操作一遍文件的创建过程。偷懒的同学……
偷懒的同学对不住,下面的链接进去自动打开成网页了,不能下载
https://gitee.com/cgyounger/python-tutorial/blob/master/fastapi/noveltemplate.html
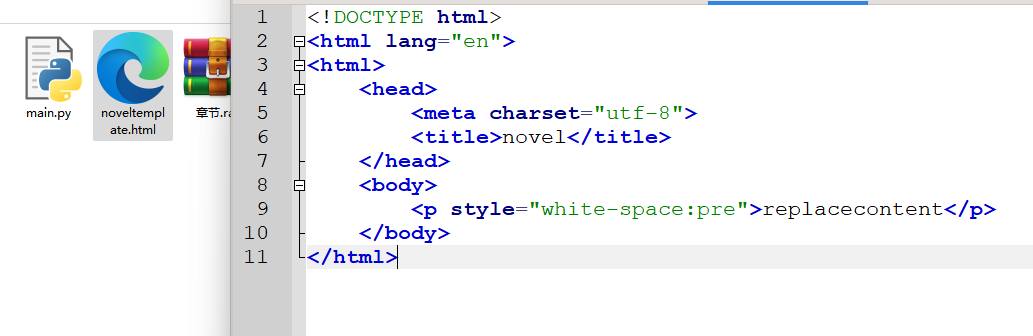
然后我们把代码做一下调整,html的内容从文件里读取

试试吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号