The Scale step of Design a Distributed File System(DFS)
主要是两方面:读的scale和写的scale
总结一下这篇文章:

关于解决方法的一些细节:
首先 当文件越来越多的时候,server数量是否够?
即单master是不是足够?
答案是:够。工业界90%的系统都采用单master.
但是单master会造成单点失效,所以如何处理写入/读取错误,恢复文件等就非常重要。
所以,如何去判断某个chunk是否broken?答案:checksum
一般来说 一个chunk有一个checksum,其大小是4bytes, which is 32 bits. 所以1P的文件只有62.5MB的空间用于储存checksum.
那么什么时候写入checksum?
写chunk的时候顺便写了
那么什么时候检查checksum?
需要读出这一块数据的时候进行检查。我们要重新读入数据然后重新计算checksum,比较现在的checksum和之前的是不是一样
如何避免data loss when chunk server is down/fail?
server down是什么原因?质量不够好,或者数量太少每一台负载2过大。所以就多买几台呗。
或者买更多的 用来做备份。那么新的问题又来了:我们需要多少个备份?每个备份放在哪里?三个 两个放的物理位置近一些 一个放的物理位置远一些。
当一个chunk损坏了 如何恢复?
找master解决 这就是他的本职工作
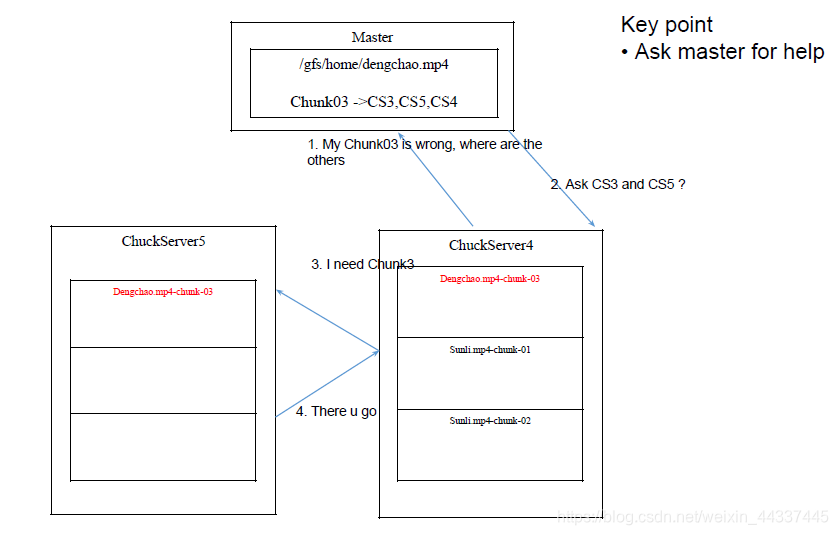
当一个chunkserver挂了怎么办?
采用heartbeat机制 即每个chunkserver隔固定的时间就向master报告。
当然 解决的方法是让master和chunkserver可以互相转换。
如何针对写进行scale?
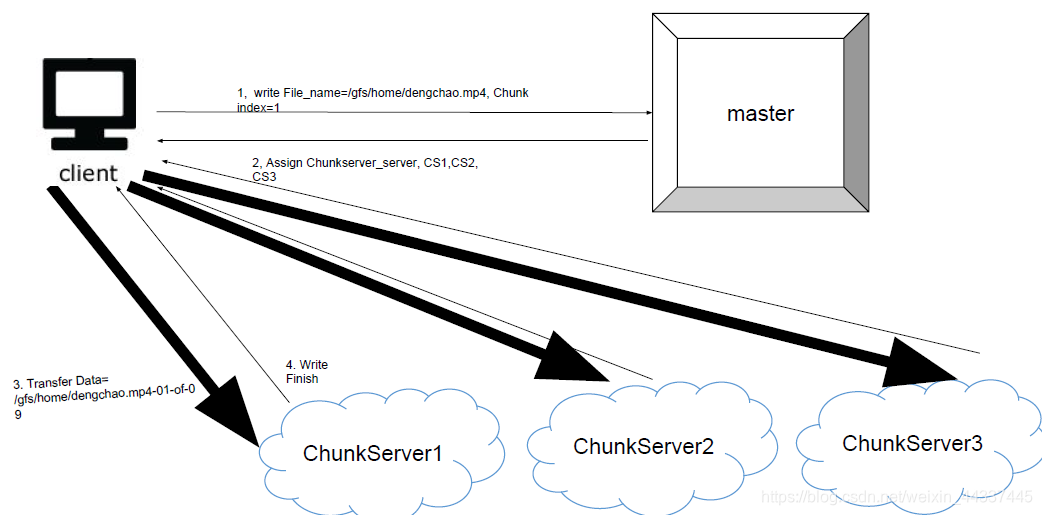
how to solve the client bottleneck?
在client里面选择一个队长。
那么怎么样选择队长呢?找物理距离最近的 找现在不干活的(所以队长始一直变化的)
how to solve chunkserver failure?
比如说下面这种情况:
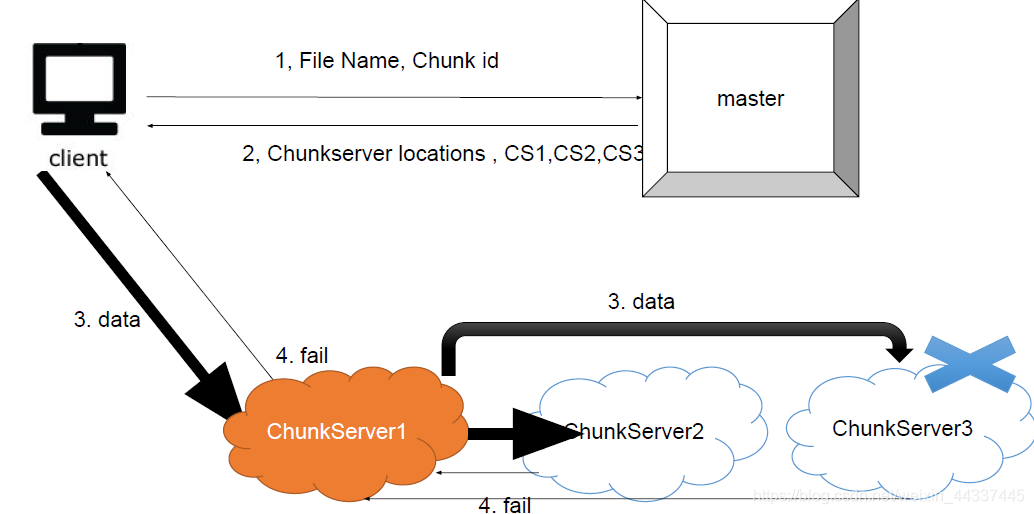
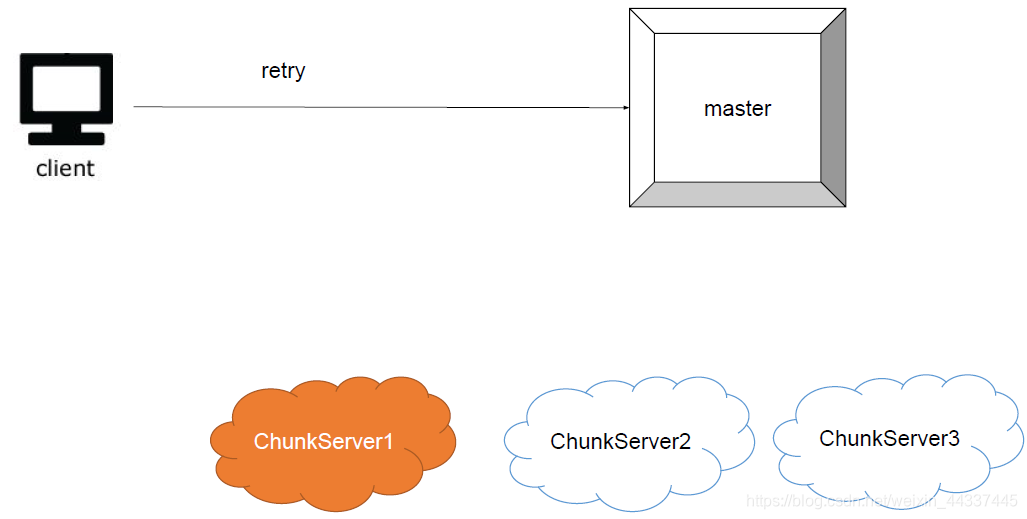
如果是这样的话 那就对master进行重试:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号