System Design of Database System(4S)
4S:
scenario:
就是给定key 或者说是查询语句 返回值
storage:
数据库虽然表面上是以表的形式进行储存,但是底层并不是这样的
底层实际上还是以文件的形式储存,所以如果这样的话那么跟文件系统有什么区别呢?文件系统查一个文件里面的内容会很慢 但是数据库肯定不能这样啊。
Service:
CRUD
能不能搞个方法使得查询文件内容快一点呢?
答案是可以 只需要把文件读取到内存里面即可(大文件怎么办?)
就算是小文件 我们把他读到内存里面 然后呢怎么样快速查找我们需要的数据呢?
二分搜索文件。但是如果文件储存在硬盘里面 如何在硬盘里面进行二分呢?(我们采用外排序的方法 即拿出来一部分进行在硬盘中排序)
如果有一天数据被修改了怎么办呢?如果我们要怎么样保证数据的时效性?
首先 不能直接在文件里面修改,因为在某一行修改会直接导致后面的内容都要移动。
然后如果想要覆盖的话 这个比直接修改所花费的时间还多。
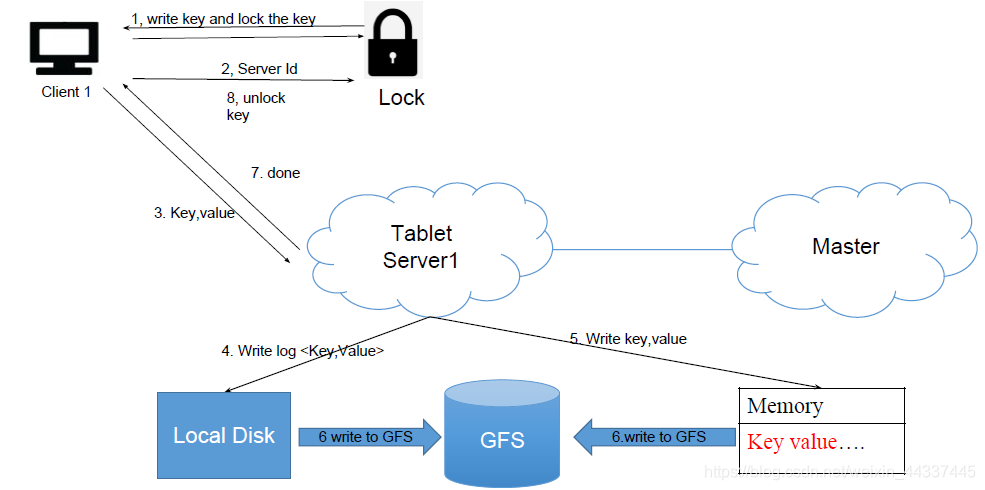
所以最优的方法是直接append在文件的最后面,好处是非常快
所以BigTable为了写入的优化 选择了直接append,但是独取得时候怎么办呢?
只能把所有相关的都读取出来。而且还有一个问题 如何解决文件没有顺序不能二分查询的问题?我们需要过一段时间把文件统一整理。
那么有没有一个方法 度的时候二分查询 写的时候最后append操作?我们需要分块有序,即每一块都是内部有序 写的时候只有最后一块是无序的。
但是块越写越多 会有很多重复 每次查询所有的块将会非常耗时间
解决方法 定期K路归并
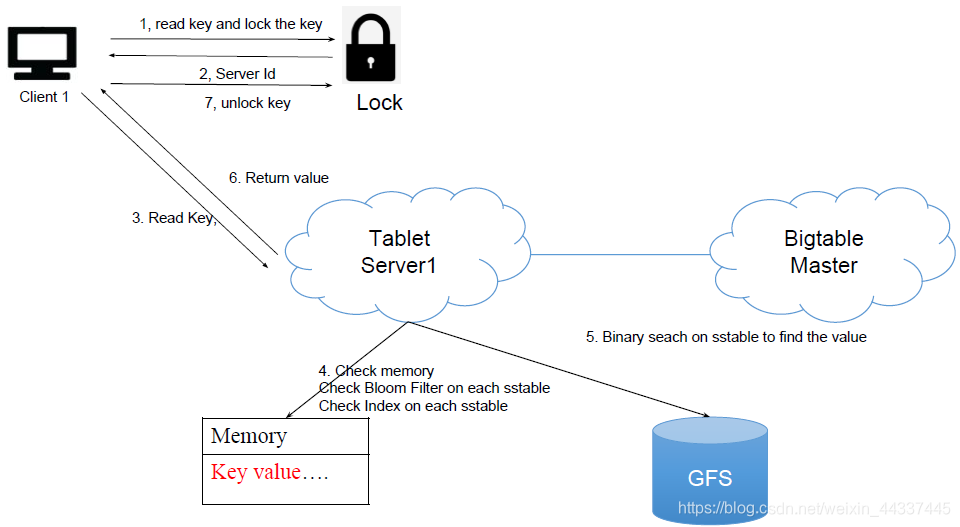
还有没有其他方法查询文件内容更快些呢?(除了之前的for 循环和硬盘二分法)
我们可以针对文件内容建立Index
但是如何检查一个key是不是在文件里面呢?
这时候就要用布隆过滤器。
Scale:
后续的问题 以及如何handle大量数据和请求,或者说如何handle怎么样可能出现的宕机。
详见单独的博文《Scale step of System Design of Database System》
总结Big table要点:

其实核心就是读和写:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号