kubernetes 笔记-1
kubernetes 笔记1
网络
需要解决的问题
- 同一个 Pod 内的多个容器间通信:lo(最简单,使用本地回环通信)
- 各
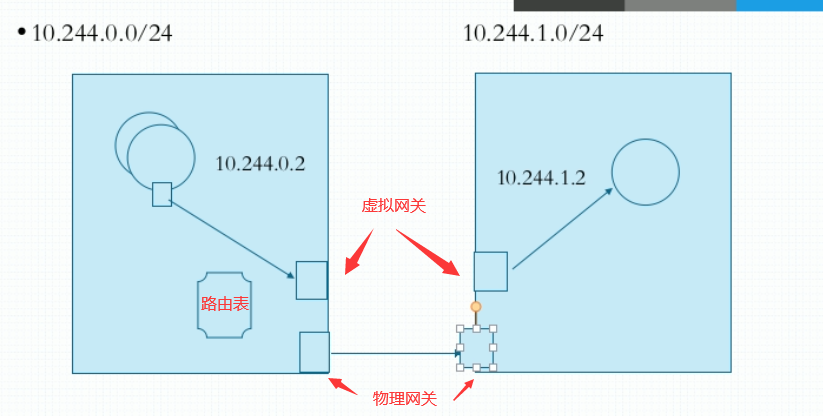
Pod之间的通信Overlay Network叠加网络:虽然跨节点,但是相当于工作在同一节点中,使用二层网络进行通信,就不用通过ARP广播进行通信。
Pod与Service之间通信Pod与Service是不在同一网段的- 通过本地的 iptables 规则可进行通信,
Service与 集群外部客户端的通信;
如何解决
k8s 本身不提供网络解决方案,但是支持 CNI 协议。
CNI 第三方网络插件:
- flannel
- calico
- canel
- kube-router
- ... ... ...
无论是哪个插件,实现的原理都是基于以下解决方案:
解决方案:
- 虚拟网桥:bridge,用纯软件的方式实现一个虚拟网卡,
- 多路复用:MacVLAN,
- 基于
mac的方式去创建VLAN,为每个虚拟接口配置一个独有的MAC地址,使一个物理网卡承载多个容器去使用,这就相当于直接使用物理网卡,基本物理网卡中的 macVlan 机制进行跨节点通信。
- 基于
- 硬件交换:SR-IOV(单根IO序列化)
- 现市面上的网卡均支持此功能,这是一种创建虚拟设备的高性能方式,使每个虚拟设备都表现为有一个单独的物理网卡。
性能:SR-IOV > MacVLAN > bridge
对于 k8s 来说,使用 CNI 插件。即 kubelet 在启动时,直接在 /etc/cni/net.d/ 下读取对应的配置文件 ,加载相应的 CNI 插件。
网络策略
CNI 插件除了:网络地址分配,网络地址管理之外,还需要确保网络插件能够实现辅助设置pod和pod之间是否能够互相访问的网络策略。
flannel 有一缺陷是暂时无法支持网络策略;calico 则可以。两者可以搭配起来用。
flannel
flannel:支持多种后端(承载报文的方式):
-
VxLAN(默认)
- Vxlan(扩展的虚拟局域网)
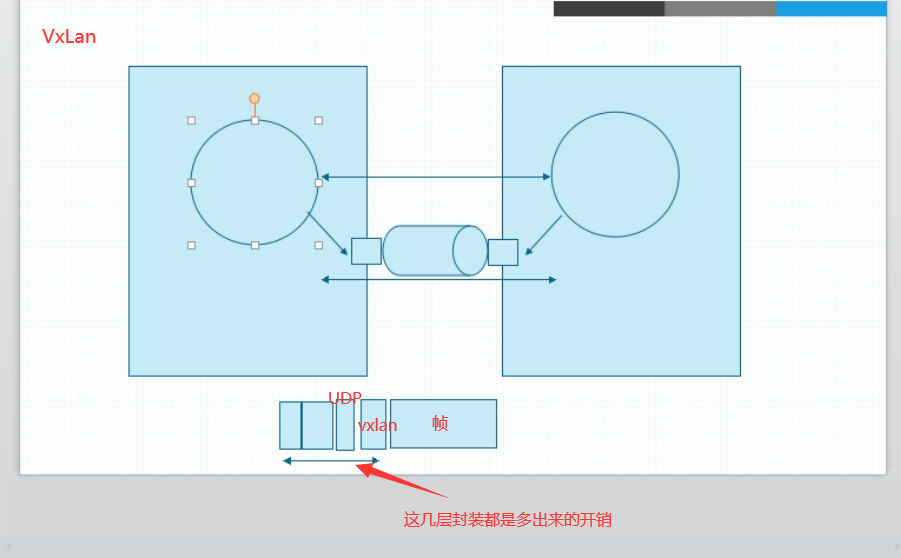
-
Directrouting (直接路由)
- 这是VxLan 有一种扩展功能,当源与目标节点在同一网段,则使用 host-GW 方式;如果不在同一网段,中间隔着路由,则降级为原生 VxLan 的叠加隧道方式
-
host-gw:Host Gateway(此种方式性能比 calico 都好)
- 要求各节点必须工作在同一个三层网络中
- UDP
- 使用纯粹的 UDP 报文进行方式,因为其使用的是普通的 UDP 报文方式,而不是 VxLan 专用的 UDP 报文,因此,性能比前两者低很多很多。
资源:对象
将资源实例化出来后,就称为:对象
kubernetes 有一个 RESTful 风格的 API,把一切操作对象都通过资源来管理,通过标准的 http 请求方法:GET,PUT,DELETE,POST ... ... 来完成操作。
-
名称空间级资源
- workload 工作负载性资源:
Pod,Deployment... ... - 服务发现及均衡资源:
Service,Ingress... ... - 配置与存储资源:
Volume,CSIConfigMap,SecretDownwardAPI
- 元数据型资源
HPA,PodTemplate,LimitRange
- workload 工作负载性资源:
-
集群级的资源
Namespace,Node,clusterRole,ClusterRoleBinding
metadata
annotations
资源注解:与 label 很相像,都是键值。
不同的地方在于:它不能用于挑选资源对象,仅用于为对象提供“元数据”,且不受长度限制。
这并非是可有可无的,此资源有些时候可能被某些程序用到,且非常重要,作为基本判断辨识条件
Pod
pod 的分类
- 自主式 Pod
- 控制器管理的 Pod
- ReplicationController
- k8s 早期的控制器,但是由于一开始设计时,将所有应用都包含在内,无法实现,已废弃
- ReplicaSet
- 无状态应用的
pod控制器,但是一般不单独使用。 - 一般由
ReplicaSet之上的一个资源Deployment来启动
- 无状态应用的
- Deployment
- 较之
ReplicaSet有更丰富的功能。 - HPA:
HorizontalPodAutoscale自动伸缩控制器。HAP也是属于Deployment下一级的资源
- 较之
- DeamonSet
- 用于确保集群的每个
node只运行一个特定的pod,通常用来实现系统集的后台任务。
- 用于确保集群的每个
- StatefulSet
- 用于有状态应用的部署
- Job
- 只执行一次任务就终止的
pod
- 只执行一次任务就终止的
- CronJob
- 周期性的一次性任务
pod
- 周期性的一次性任务
- ReplicationController
Deployment
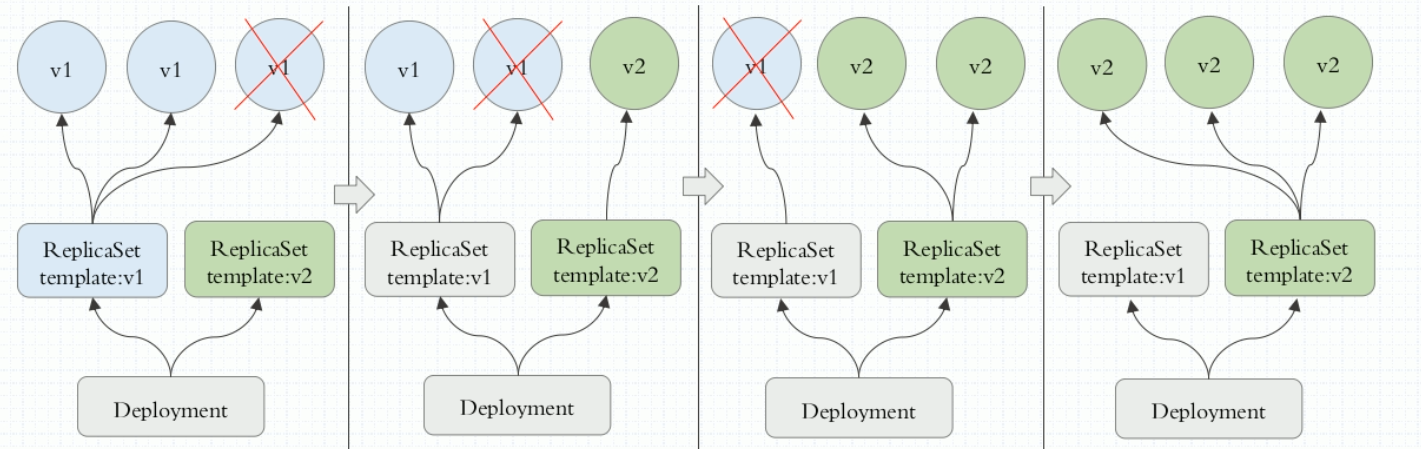
一个 Deployment 可以管理多个 ReplicaSet ,默认是10个,Deployment 支持滚动更新或 pod,可以用来进行设置蓝绿发布。
将滚动暂停,即:“灰度”变成“金丝雀”
deployment 在可以控制 pod 的更新粒度:(允许多几个,少几个的策略)
kind: Deployment
metadata:
spec:
paused: false | true # 是否暂停滚动更新
revisionHistoryLimit: 10 # 更新时保留多少个历史版本
strategy: # 更新策略
type: Recreate # 重建式更新:删一个,再建一个
type: RollingUpdate # 滚动式更新
maxSurge: 5 | 10% # 最多可多几个 | 多x%
maxUnavailable: 5 | 10% # 最多可少几个 | 少x%
kubectl rollout paused # 滚动更新暂停
kubectl rollout resume # 滚动更新继续
kubectl rollout undo # 回滚
statefulSet
必须有三个组件:
- headless service
- statefulSet
- volumeClaimTemplate
pod 名称是集群中的唯一标识符。所以需要 headless service 来为 pod 定义唯一的、有顺序的名称。
由于一般有状态服务的 pod 存储的数据都是不相同的,所以通过 pod 模板直接定义存储卷就不可取了。volumeClaimTemplate 存储卷申请模板,可以让每个 statefulSet 控制下的 pod 自动生成专用的 PVC 和 PV。
---
apiVesion: v1
kind: Service
metadata:
name: myapp-svc
labels:
app: myapp-svc
spec:
clusterIP: None
ports:
- name: web
port: 80
selector:
app: myapp-pod
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: myapp
spec:
serviceName: myapp-svc
replicas: 2
selector:
matchLabels:
app: myapp-pod
template:
metadata:
labels:
app: myapp-pod
spec:
containers:
- name: myapp
image: myapp:v5
ports:
- name: web
containerPort: 80
volumeMounts:
- name: myappdata
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: myappdata
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "gluster-dynamic"
resources:
requests:
storage: 2Gi
每一个 pod 的名称都可以被解析,完整名称为:
<pod_name>.<service_name>.<ns_name>.svc.cluster.local
---
apiVersion:
kind: StatefulSet
metadata:
name:
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: <integer>
当希望进行阶段更新、执行金丝雀或执行分阶段展开时,需要用到分区更新,因 pod 是默认从 0 开始进行有序号标识的。
分区更新:
所有序号大于等于该分区序号的 Pod 都会被更新。
---
apiVersion:
kind: StatefulSet
metadata:
name:
spec:
updateStrategy:
type: OnDelete
type 设置为 OnDelete 时,控制器将不会自动更新 StatefulSet 中的 Pod。用户必须手动删除 Pod 以便让控制器创建新的 Pod 。
Pod 的生命周期
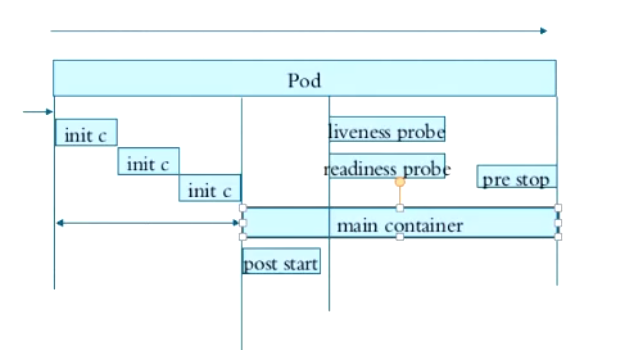
初始化
在主容器启动前,有一段时间是需要进行一些初始化操作的,一般会启动相应的初始化容器进行执行,初始化容器是短时间存在的。初始化容器,必须串行执行。
生命周期勾子
主容器刚刚启动的时刻,在结束前的时候,用户可以手动潜入做一些手动操作,一般是一条或一些命令,执行完就结束。无论是启动时,还是结束前,做的事通常是一些勾子,勾住一些命令执行一下,作为开场前的预设,结束前的清理。
-
启动时勾子
post start -
结束前勾子
pre stop
容器探测
在运行过程中,可以做容器探测
-
liveness probe:存活状态检测
- 主要用于探测主容器是否处于运行状态
-
readiness probe:就绪状态检测
- 用于探测容器中的主进程是否准备就绪并能对外提供服务
无论是哪种 probe 都支持3种探测行为:
ExecAction执行自定义命令TCPSocketAction向指定的TCP端口发请求HTTPGetAction向对指定的http服务发请求
探针类型有三种:
- ExecAction
- TCPSocketAction
- HTTPGetAction
一般只设置其中一种即可,根据不同的应用特性设置
探针的重要性
当一个服务以 pod 的形式向外提供服务时,一旦pod中的container启动,没有做存活性或就绪性检测,此时如果有请求被调度到此pod,则会出现无法提供服务的情况。
因为pod启动到应用就绪是有一个阶段的:初始化、启动容器、容器内主程序启动、主程序应用展开,主程序应用提供服务。
容器的重启策略
容器的重启策略restartPolicy
- Always
- OnFailure:只有状态为错误时才重启
- Never
pod 的终止前,先发送 terminal 信号,有一个宽限期,通常是30s,如果没有终止,最后再发送 kill 强行终止。
Containers
ports
在 pods.spec.containers.prots 中定义的 containerPort 只是用作说明性的内容,并不意味着容器内是一定暴露这个端口,端口是否暴露到可以让外部访问,一是看容器的的应用是否使用了此端口,二是定义 service 时是否定义 targetPort
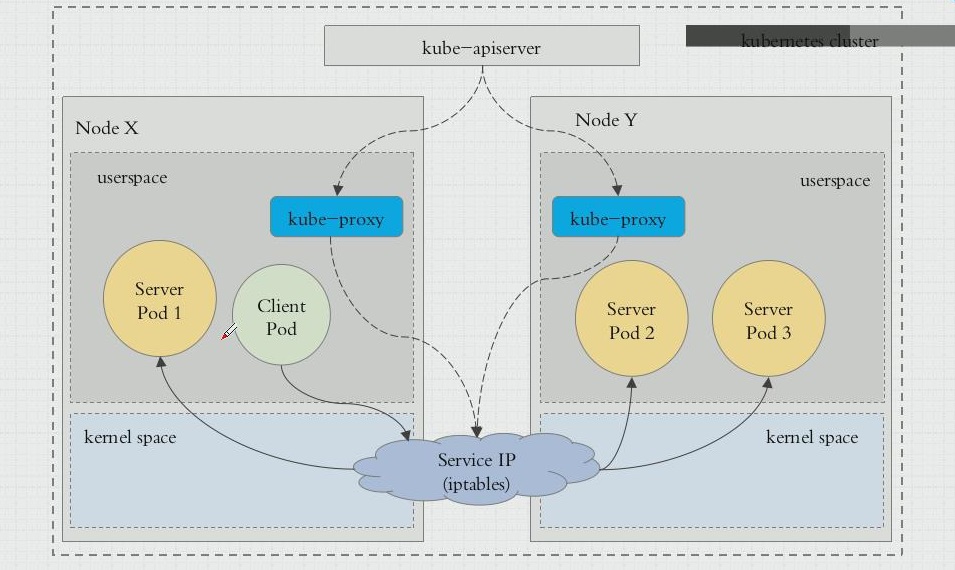
kube-proxy
kube-proxy是运行在各个node节点的守护进程kube-proxy与API-Server交互,动态将pod与service的改变写入到各个node中底层的iptables规则中去
Service
service的名称可以被croeDNS解析成对应的IP- 解析搜索域为:
.svc.cluster.local - 所以完整域名为:
<SERVICE_NAME>.<NAMESPACE>.svc.cluster.local - 当
service的IP有变动,coreDNS会动态修改对应的IP
- 解析搜索域为:
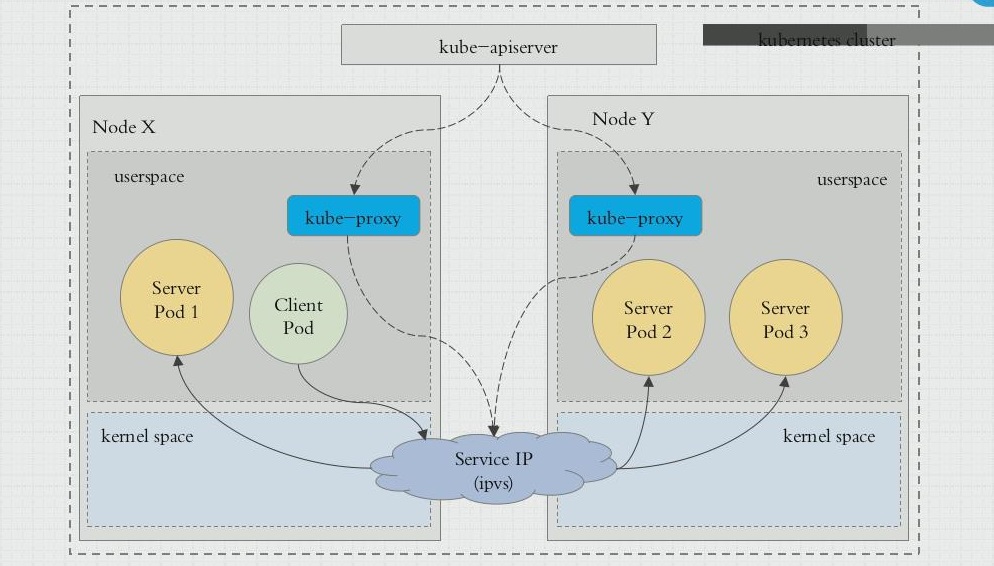
service的IP只是iptables规则中的地址,无法ping通,只进行转发service的管理是靠kube-proxy来实现的- ipvs 取代不了 iptables ,因为 ipvs 只能用于 负载均衡,无法进行 NAT 转换等功能。
三种工作模型
service 实际方式有三种工作模型
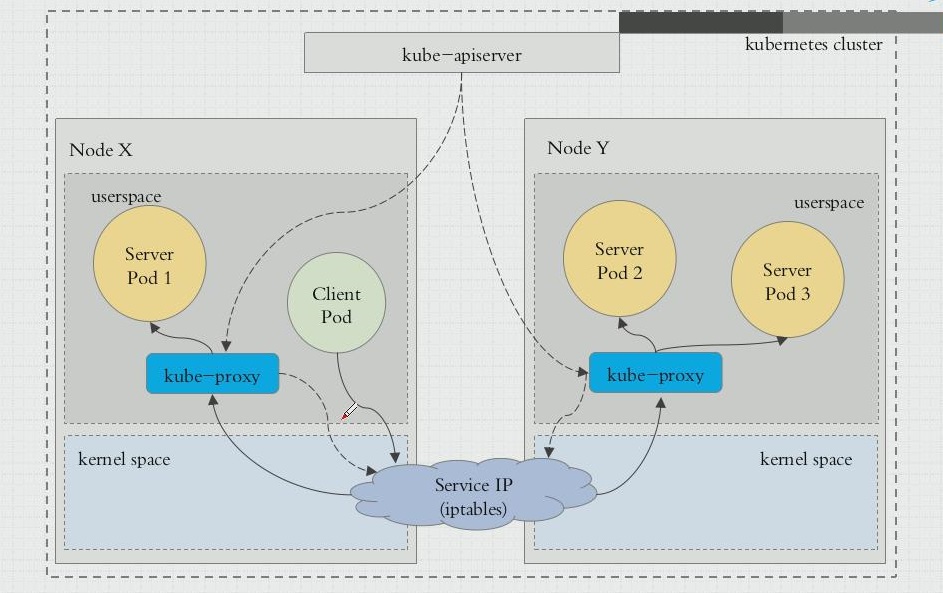
user space
- kube-proxy 是工作在
用户空间的一个进程:- 内部请求:client-pod 请求发送至 内核空间中的 service 规则(即iptables规则),service 将其提交给用户空间的 kube-proxy,kube-proxy 封装完代理后,再回到内核空间,由 iptables 规则进行分发到各节点的 kube-proxy,再由 kube-proxy 转发至请求的 server-pod。
iptables
ipvs
类型
clusterIP
- 默认类型。只支持集群内部进行访问
nodePort
- 默认范围(30000-32767)
修改K8S中NodePort方式暴露服务的端口的默认范围(30000-32767)的方法
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16 --service-node-port-range=8000-9000"
比如想把端口范围改成1-65535,则在apiserver的启动命令里面添加如下参数:
–service-node-port-range=1-65535
LoadBalancer
这是用于当 kubernetes 集群部署于工作在云环境中的虚拟机上,而云环境支持 LBAS 的负载均衡器的一键调用,则此类型可直接在云环境底层创建此 负载均衡器
ExternalName
集群外部的服务引用到集群内部,集群内部的服务可直接使用。
它应该是一个 hostname 或者是 FQDN
但是 FQDN 又应该是一个 CNAME,而 CNAME 应该指向真正的 FQDN。
- ExternelName
- FQDN
- CNAME --> FQDN
- FQDN
clusterIP 升级完善 ---> NodePort
NodePort 升级完善 ---> LoadBalancer
No ClusterIP ---> Headless
HeadlessService
正常情况下,service 是有:service_name:service_ip
可将 service_name 解析成对应的 service_ip,是 一 一 对应关系。
headlessService 即不指定 service_ip
将 service_name 直接解析成后端的多个 pod_ip
在 statefulSet 中是一项非常重要的定义
apiVersion: v1
kind: Service
metadata:
name: demo
spec:
selector:
app: demo
type: ClusterIP
clusterIP: None # 将其定为 None 即为 headless
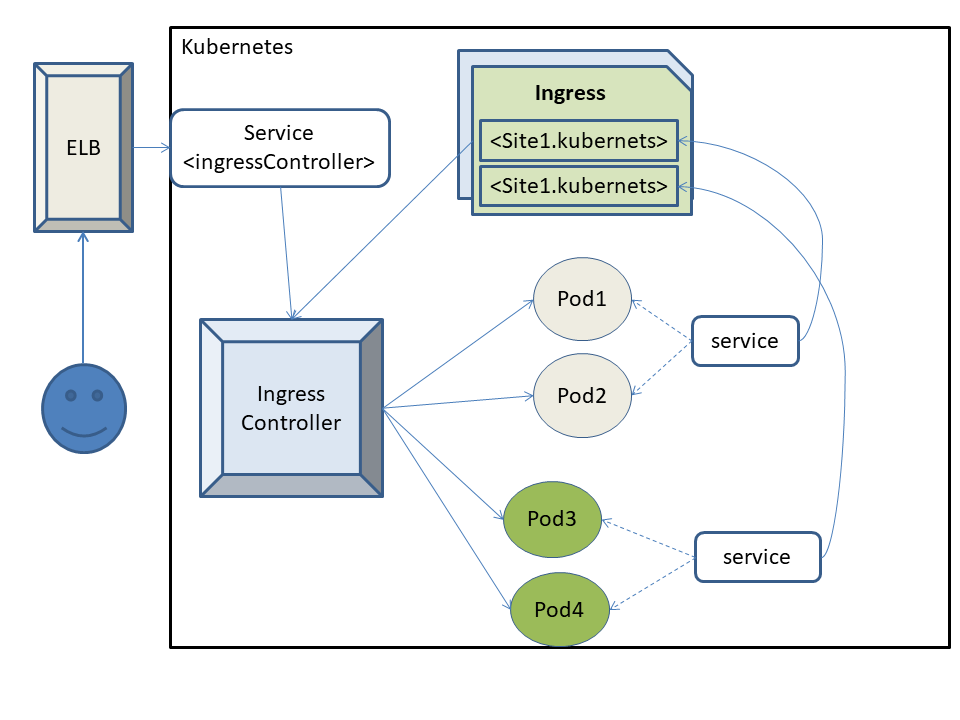
Ingress Controller
service 有个问题:当有外部访问时,要通过2级代理,严重影响效率,且是通过 iptables 规则转发,是4层调度,因此,如果我们要建立 https 服务时,就需要每一个后端服务 pod 都得配置为 https 的主机,因为4层调度自身是无法卸载 https 会话的。
kubernetes 还有一种引入集群外部流量的方式:Ingress,这是一种7层调度器,它利用一种7层 pod 来实现将外部流量引入到集群内部,但是它也需要 service 的工作。
Ingress 常用的工具有3种:Nginx,Envory,Thaefic
在 server mesh 微服务网格中,用的较多的是 envoy
工作原理
运行一个特殊的 Pod ,比如 Nginx,Envory,Thaefic。
此 pod 拥有7层调度代理功能,并且直接共享宿主机的网络名称空间(即相当于 node 上的一个应用程序),如此就可以直接引入外部流量,且可卸载 SSO 会话,实现7层调度。
由于其要共享宿主机的网络名称空间,所以调度同一后端服务的这个特殊 Pod 在每个节点只能有一个,这就需要通过 DaemonSet 这个控制器来实现。
但是,由于这个特殊的 Pod 主要的目的是用来做7层调度的,当 kubernetes 集群有非常多节点时,没有必要每个节点都运行此 pod ,使用 DaemonSet 控制器是为了高可用,一般能实现高可用即可。
所以,一般应该如此设置:比如,k8s集群中有3000个节点,我们可以拿出其中3个节点,然后将这3个节点打上“污点”,然后专门部署此类 pod ,其它常规 pod 无法调度到这3个节点。
如果不使用 DaemonSet 的方案,也可使用 Deployment ,不过就需要给 Deployment 创建一个 NodePort 的 Service 来引入集群外部流量,这样的方案会使得转发层级变多,效率变慢,但是部署较容易。
此类特殊的 pod 就叫:Ingress Controller。这不是一个控制器,可以理解为:调度器。
Pod 是有生命周期问题,Ingress Controller 代理后端 Pod 时,由于其本身没有动态记录 Pod 的功能,所以需要一个 service 进行辅助,但是该 service 不进行代理,只用于动态记录 Pod 的变动,并将此记录动态写入到 Ingress Controller 的配置文件中,这个配置文件是一种特殊的资源,就叫做:Ingress。
Ingress:一种特殊资源,用于定义 Ingress Controller 的前端代理模式的相关配置,与一个 service 交互,动态获取后端 Pod 的信息。
且作为一种k8s的资源,可以直接将相关配置注入到 Ingress Controller 中,并且还能触发主容器重载配置文件。
apiVersion:
kind: Ingress
metadata:
name:
spec:
backend: # 用于定义默认调度后端,能够处理与任何规则都不匹配的请求。一般用于定义404
serviceName: <string> -req
servicePort: <string> -req
rules:
- host: <string> # WEB 的虚拟主机名
http:
paths:
- path: <string> # 默认是"/"
backend:
serviceName: <string> -req
servicePort: <string> -req
tls:
- hosts:
- web1.com
- web2.com
secretName: <string>
Volume
PV 是集群中的资源。PVC 是对这些资源的请求,并且还充当对资源的声明检查。
PV 是集群级别的资源;PVC 是名称空间级别的资源。
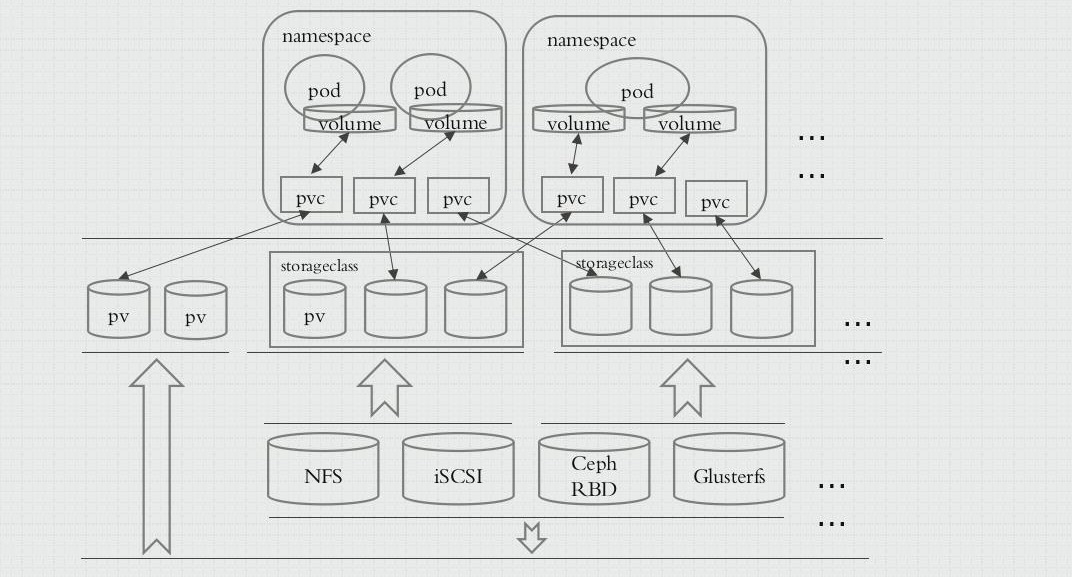
PersistentVolume
- RWO:ReadWriteOnce:单路读写
- ROX:ReadOnlyMany:多路只读
- RWX:ReadWriteMany:多路读写
当 PVC 要与 PV 绑定时,其中 PVC 的 accessModes 须是 PV 的子集才能绑定
PersistentVolumeClaim
持久性存储卷申请
configMap、secret
configMap、secret 是给客户可以从集群外部向内部 pod 注入配置信息的特殊存储卷,并不直接提供存储功能。
configMap 是明文存储的,一般用于配置信息,secret 是使用 base64 编码存储的,一般用于存储敏感信息如账号密码、证书私钥等。
configMap、secret 本质是一样的,都是以 key=value 的形式存储信息,可以有多个 key=value,其中 value 没有字符长度限制,所以一个 key 就可以包含整个配置文件。
configMap、secret 都是属于 名称空间 级别资源。
configMap 以 env 方式注入 pod:此种方式,当 configMap 有变动时,无法动态更新到 pod ,因 pod 只有在启动的时候才会进行一次 env 注入,后续除非 pod 重启,否则不会再注入 ENV。
apiVersion: v1
kind: Pod
metadata:
name:
spec:
containers:
- name:
image:
ports:
- name: http
containerPort: 80
env:
- name: NGINX_SERVE_PORT # 容器内的需要定义的环境变量
valueFrom:
configMapKeyRef:
name: nginx-config # 引用的 configMap
key: nginx_port # configMap 中的 key,这个 key 的 value 会传递给上面的容器中的 ENV。
configMap 以 volume 形式挂载至 pod,可实现动态更新。
apiVersion: v1
kind: Pod
metadata:
name:
spec:
containers:
- name:
image:
ports:
- name: http
containerPort: 80
volumeMounts:
- name: nginxconf
mountPath: /etc/nginx/conf.d/
volumes:
- name: nginxconf
configMap:
name: nginx-www
echo xxxxxxxxxx | base64 -d # base64 解码
RBAC
k8s集群有2类认证时的账号:一是 userAccount(用户账号,现实中人使用的账号),另一是 serviceAccount(服务账号,给 Pod 中应用的程序,当访问 API-server 时的认证信息使用的)
从外部向集群内部进行管理,一般需要经过三个阶段的安全检查:
认证 --> 授权 --> 准入控制
- 认证:相当于注册一个账号。
- 授权:给注册的账号进行相关授权。
- 准入控制:对授权的补充,当需要在集群内联动其它 Pod 时的控制机制。
k8s集群是高度模块化设计。
认证、授权、准入控制,都是通过插件实现的。
一个K8s集群内可能会有很多插件,支持不同的验证方式,但每阶段检查只需要通过一种认证方式即可,不需要重复认证。
授权插件:Node,ABAC,RBAC,Webhook 等等。
客户端(user、group、extra) ----> API-server
user:username,uid
extra:额外信息
user 对 API-server 发起操作请求,API-server 需要识别此 user 是否拥有访问权限。
k8s 中的 API资源 是分组管理的,且有不同的版本,而 user 发起的请求一定是某个特定的 API 资源,那么具体是指向哪个 API 资源,在请求时是需要带上相关标识的,API 又是属于 restful 风格的接口,那么这个标识是通过 URL 的 Request path 来进行的。
例:
- 对一个名为 myapp-deploy 的 deployment 发起请求,则实际请求的路径为:
http://192.168.1.10:6443/apis/apps/v1/namespaces/default/deployments/myaa-deploy/
HTTP requests verb:
- get,post,put,delett
API requests verb:
- get,list,create,update,patch,watch,proxy,delete,redirect,deletecollection
请求的 API 中包含的元素:
- API group,Namespace,Resource,Subresource
每个 ns 下的 pod 都需要跟 API-server 交互,每个 ns 下面都有一个在集群安装时提前配置好的 secret,名为:``default-token-xxxxx,当有pod创建时,会自动以volume的方式挂载至pod,以使 pod有权限跟API-server` 交互。
serviceAccount :一个标准的 k8s 资源。
它本身不具有授权功能。通过授权机制可以给其授权,而后 pod 将其指定使用,则获得 serviceAccount 的权限。
kubectl create serviceaccount admin # 创建一个 sa
kubectl get sa
NAME SECRETS AGE
admin 1 5s
default 1 46d
kubectl describe sa admin # 可以看到这个创建的 SA 会自动拥有一个 Token
Name: admin
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: admin-token-6rlhs
Tokens: admin-token-6rlhs
Events: <none>
kubectl get secret
NAME TYPE DATA AGE
admin-token-6rlhs kubernetes.io/service-account-token 3 47s
default-token-s2njn kubernetes.io/service-account-token 3 46d
'此时,就可用这个 token 用来认证登录这个 k8s 集群,但是由于没有配置权限,所以可以登录,但无法进行任何操作。'
'认证不代表权限,针对 k8s 的所有操作都需要有授权。'
k8s 集群中其它组件都需要跟 API-server 连接,都是 API-server 的客户端,kubectl 也是。
kubectl config view # 查看API-server的客户端 kubectl 的配置
apiVersion: v1
kind: Config
preferences: {}
clusters: # 集群列表
- name: kubernetes
cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.255.21:6443
contexts: # 上下文列表
- context:
cluster: kubernetes
user: kubernetes-admin
current-context: kubernetes-admin@kubernetes # 当前上下文
users: # 用户列表
- name: kubernetes-admin
user:
client-certificate-data: REDACTED
client-key-data: REDACTED
- 'context 用于指定哪个用户访问哪个集群。'
证书中的证书持有者的名称必须跟 user_name 一致。因为证书持有者就是 user。
ls /etc/kubernetes/pki/ # 此处即为k8s集群的相关证书私钥
apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt ca.crt etcd front-proxy-ca.key front-proxy-client.key sa.pub
apiserver-etcd-client.crt apiserver.key apiserver-kubelet-client.key ca.key front-proxy-ca.crt front-proxy-client.crt sa.key
------------------------------------------------------------------------------
可根据上面的:ca.crt、ca.key 进行给自己创建的用户自签证书
(umask 077; openssl genrsa -out test.key 2048) # 创建一个私钥
openssl req -new -key test.key -out test.csr -subj "/CN=test" # 根据私钥生成一个证书签署请求
openssl x509 -req -in test.csr -CA ca.csr -CAkey ca.key -CAcreateserial -out test.crt -days 365 # 生成自签证书
openssl x509 -in test.crt -text -noout # 查看证书
RBAC:角色授权访问控制。(此插件中,默认所有权限都是拒绝的,所以授权的权限都是“允许”权限,没有“拒绝”权限)
user account | service account --> 角色 role --> 权限 permissions( operations 允许的操作 --> objects 被操作的对象 )
role/rolebinding 是名称空间级别的资源;``clusterRole/clusterRoleBinding` 是集群级别的资源。
用户、角色、许可:user、role、permission
让一个 user 扮演一个 role,而 role 拥有 permission ,所以这个 user 就拥有了这个 role 的 permission。
所以,授权,不是给 user 授权 ,而是给 role 授权。
能够去扮演 role 的 user 有两种,即:
- Human UserAccount
- Pod ServiceAccount
Object URL:
- /apis/
/ /namespaces/<NS_NAME>/ [/object_id]
role:
- operations
- get、list、watch、patch、delete、proxy、update、... ...
- objects
- resource group
- resource
- non-resource
rolebinding
- user account、group、service account
- role
dashboard
自身不进行认证,只提供一个认证代理,所有登录 dashboard 的认证必须是 k8s 的内部认证账号。
因如果直接将认证跟 dashboard 绑定,那么将导致任何进入 dashboard 的人都拥有一样的权限

 浙公网安备 33010602011771号
浙公网安备 33010602011771号