
一个开源的文档 MCP 工具
前言
大模型的知识库几乎总是过时的:在模型开始训练的时候就已经过时了。这可能导致模型的知识与最新的技术文档互相矛盾,从而使模型生成错误或无法工作的代码。一个典型的例子是,苹果公司在 2025 年对旗下各个操作系统的 UI 设计进行了一次重大修改(https://zh.wikipedia.org/wiki/Liquid_Glass ),导致现有几乎所有模型都无法生成最新的、符合设计规范的 UI 代码。根据我的使用经验,主流模型对技术文档的知识至少滞后 2-3 年,也就是说现在新出一个技术,可能要在 2-3 年后才能用上不借助任何工具就能使用这个技术的模型。
如何解决这个问题?目前主流的方案是设置一个 MCP 服务器,服务器爬取最新的文档,然后模型通过关键词查询,服务器通过 RAG 返回查询结果。目前已经有一些商业化的产品:
但是,商业产品要钱啊。于是我就找到了这个可以自建服务器的开源产品:https://github.com/arabold/docs-mcp-server
部署
项目基于 Node.js 开发,提供了打包好的 Docker 镜像。也可以用 npx 直接运行,但我用 pnpx 试了一下没跑起来,就用 Docker 了。这个项目比较倾向于让用户搭建一个独立的服务器来运行,而不是放在各大工具的 MCP 配置里,让工具拉起服务。
docker run --rm \
-v docs-mcp-data:/data \
-v docs-mcp-config:/config \
-p 6280:6280 \
ghcr.io/arabold/docs-mcp-server:latest \
--protocol http --host 0.0.0.0 --port 6280
这里用 -v 创建了两个 Docker volume:docs-mcp-data 和 docs-mcp-config,分别用来存储爬取到的文档数据和项目的配置。
如果希望能在后台运行,可以指定 -d 参数:
docker run -d --rm \
-v docs-mcp-data:/data \
-v docs-mcp-config:/config \
-p 6280:6280 \
ghcr.io/arabold/docs-mcp-server:latest \
--protocol http --host 0.0.0.0 --port 6280
还是比较消耗资源的。空闲状态就占了 500MB 内存。不过 Node.js 嘛,没办法。
通过 WebUI 添加文档库
容器跑起来之后,可以访问 http://127.0.0.1:6280 来查看项目的 WebUI。
我这里已经添加了一些文档了。
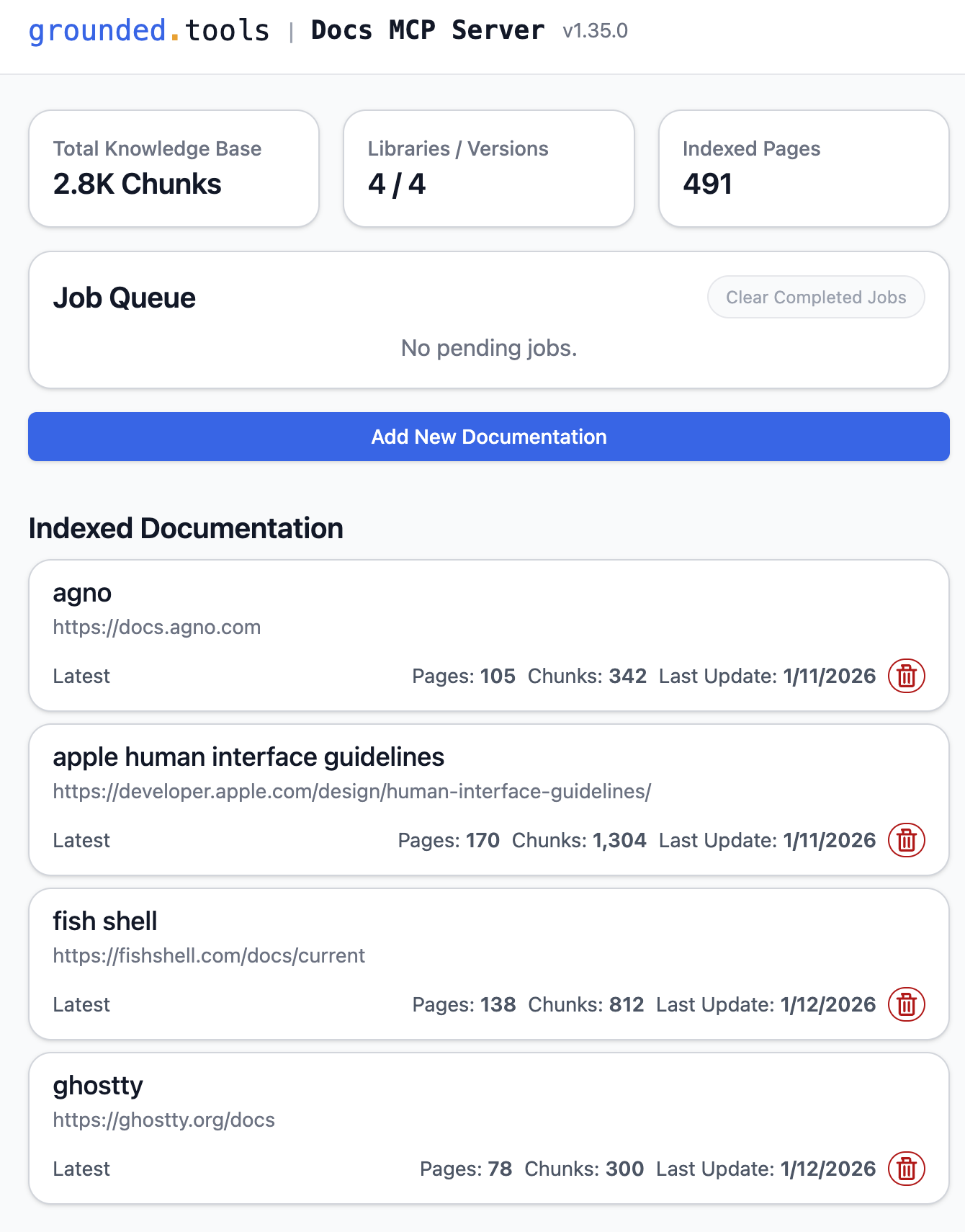
添加文档也比较简单,直接点击「Add New Documentation」按钮,然后粘贴文档的网址、取一个名字就可以了。确定 URL 的时候需要稍微注意一下,服务器默认爬取给定 URL 的子页面,因此我们最好在文档网站里多切换几个页面,找出那个公共的前缀。
其他的内容都可以保持默认或者不填。然后点击「Start Indexing」。
后文会介绍接入 Embedding 模型的方法。这个项目默认使用 OpenAI 的 Embedding 模型,需要在启动时提供一个有效的 OpenAI API Key,如果没有提供,就会回退到默认的文本搜索,精度可能稍低。如果希望接入自己的 Embedding 模型,可以先看完本文再添加文档。
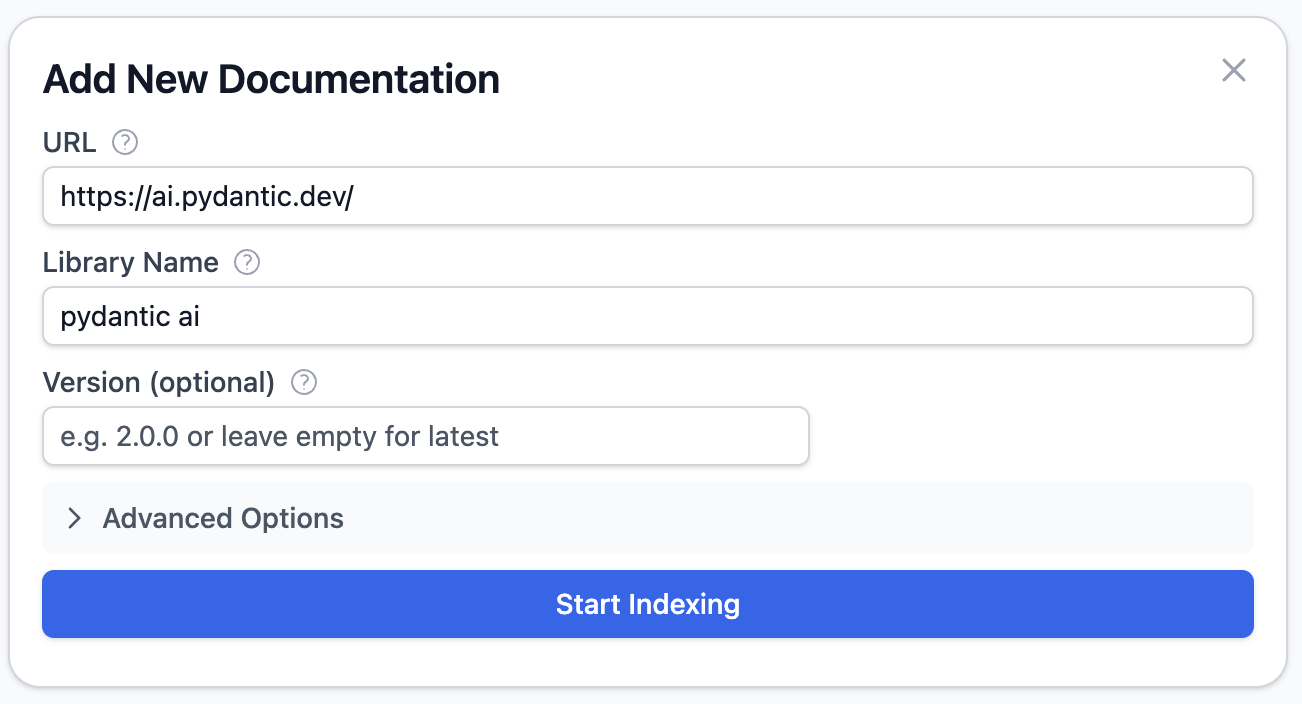
开始索引之后,服务器会一边探索页面一边爬取。
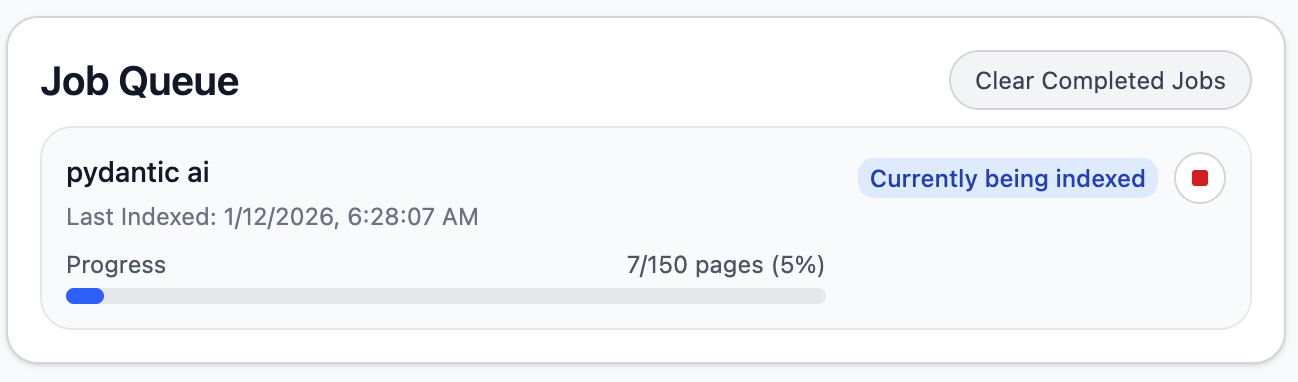
索引完成,显示为已完成:
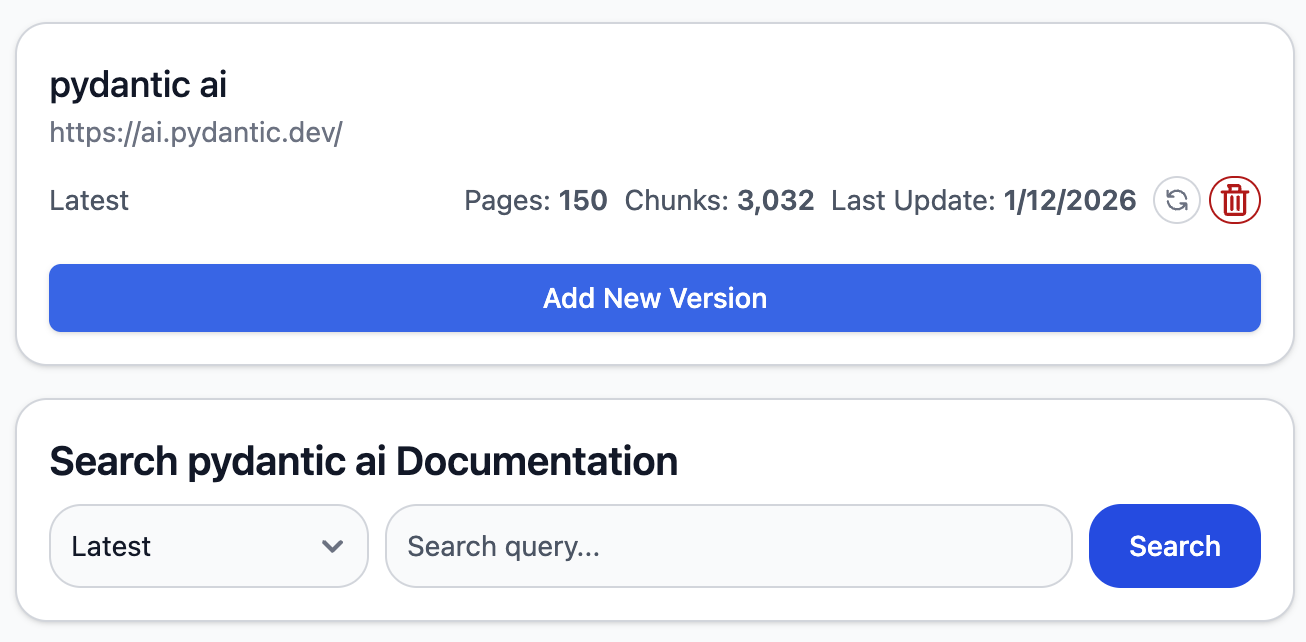
然后我们点击下面的文档卡片可以查看详情。

这里可以添加其他文档版本,点击右侧的刷新按钮可以抓取最新的文档。
接入 MCP
文档准备好后,就可以接入这个 MCP 了。
例如,在 Cherry Studio 中,点击快速创建 MCP,类型需要选择「可流式传输的 HTTP」,这也是目前接入远程 MCP 的首选方法。地址填写 http://127.0.0.1:6280/mcp ,如果是远程服务器需要对应更改 IP。
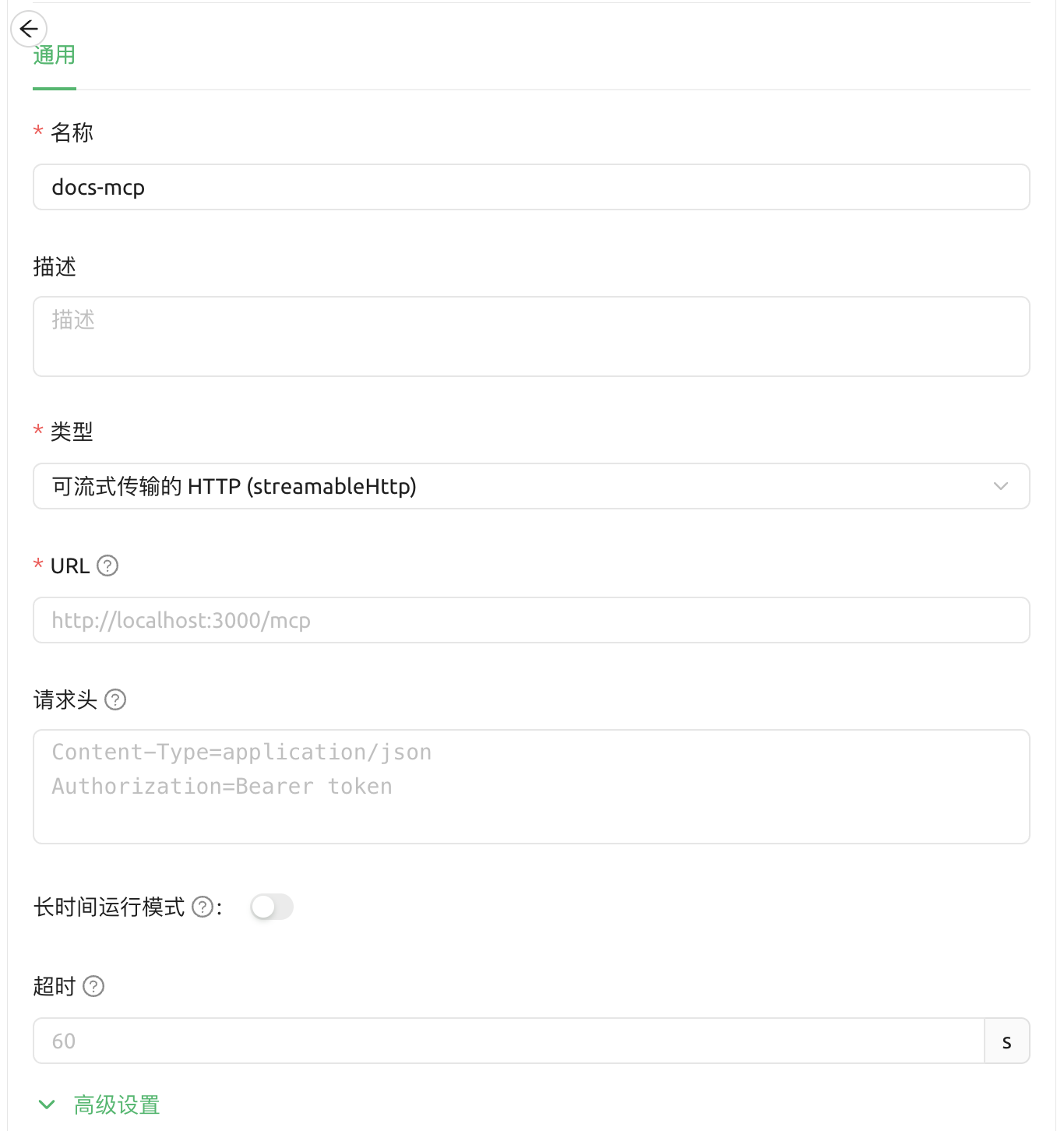
这个服务器也提供
/sse端点,用于兼容已经被弃用的 SSE 连接方法。
创建之后,就可以看到所有可用的工具。
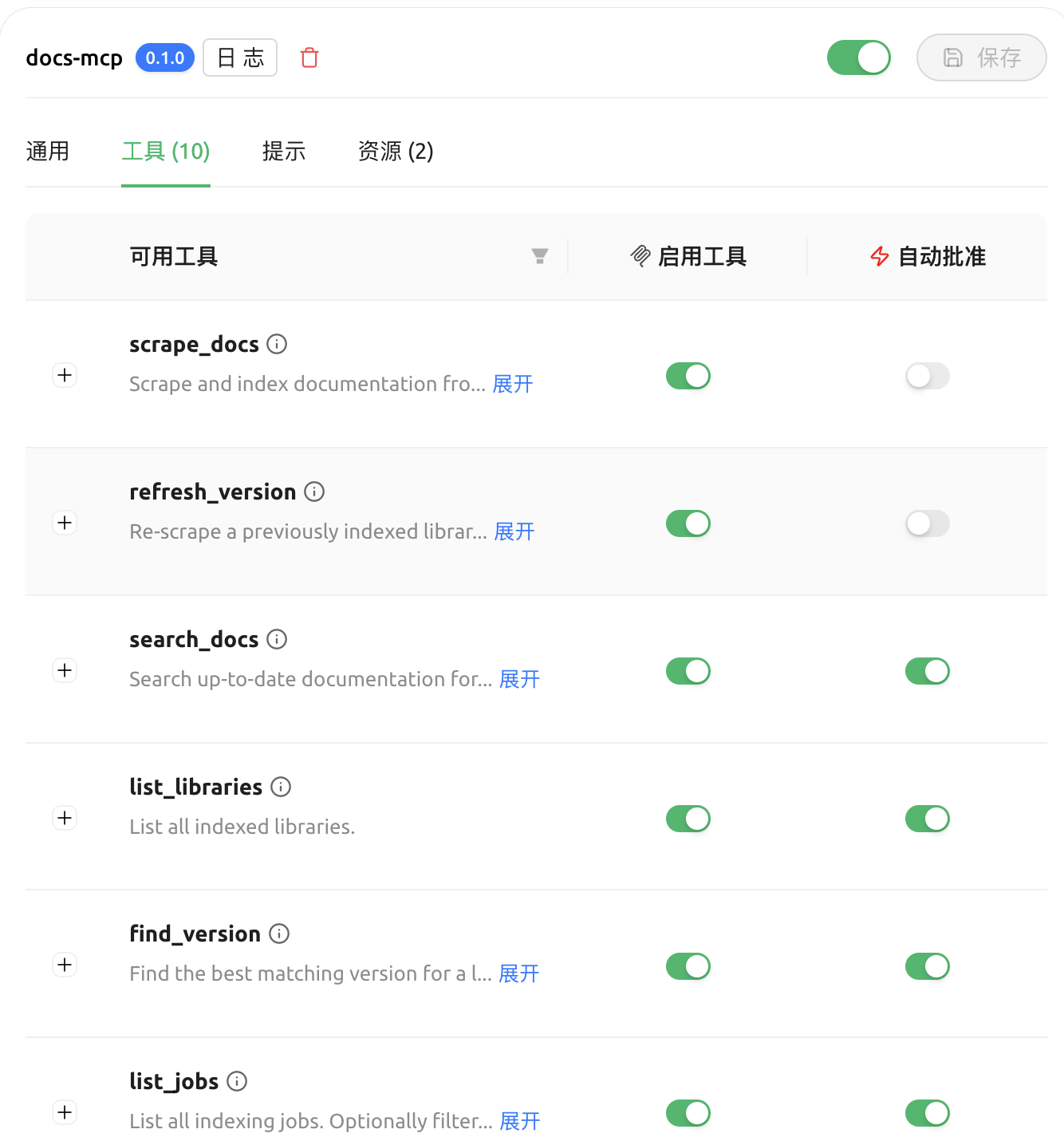
接下来,我们可以测试检索效果。需要选择一个带有工具调用功能的模型,并在对话框中启用这个 MCP 工具,然后要求它查询我们刚刚添加的文档。我这里用 DeepSeek-V3.2 来展示效果。

又例如,在 OpenCode 中,我们可以修改配置文件 ~/.config/opencode/config.json:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"docs-mcp-server": {
"type": "remote",
"url": "http://10.13.21.221:6280/mcp",
"enabled": true
}
}
}
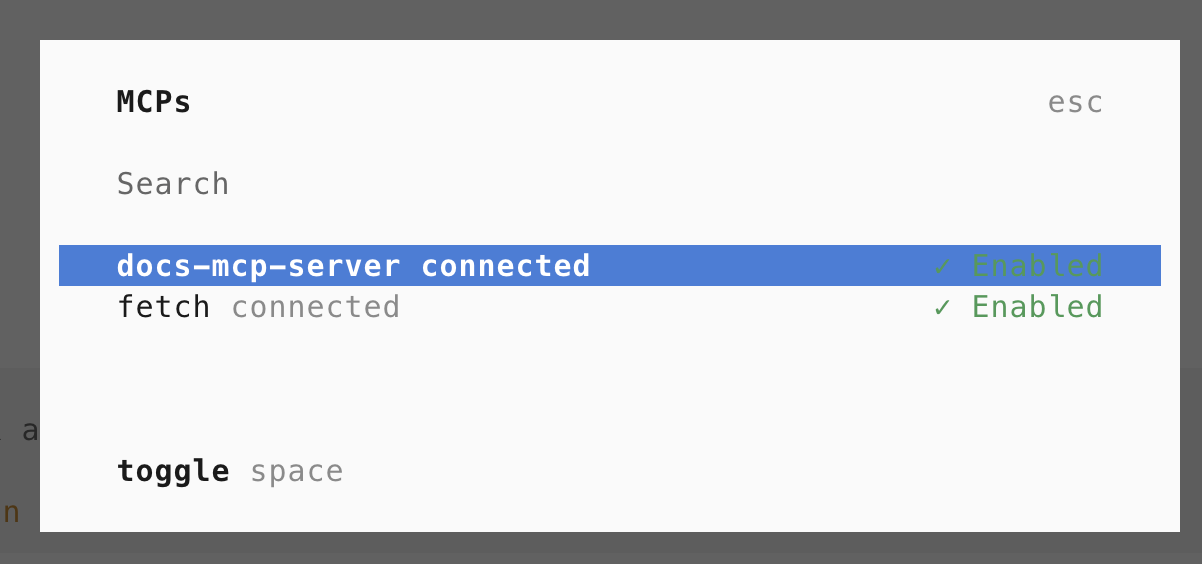
打开 OpenCode,输入 /mcp 命令,可以看到这个工具已经连上了。(fetch 是我自己添加的,与本文无关)
接下来就可以直接询问文档相关的问题。
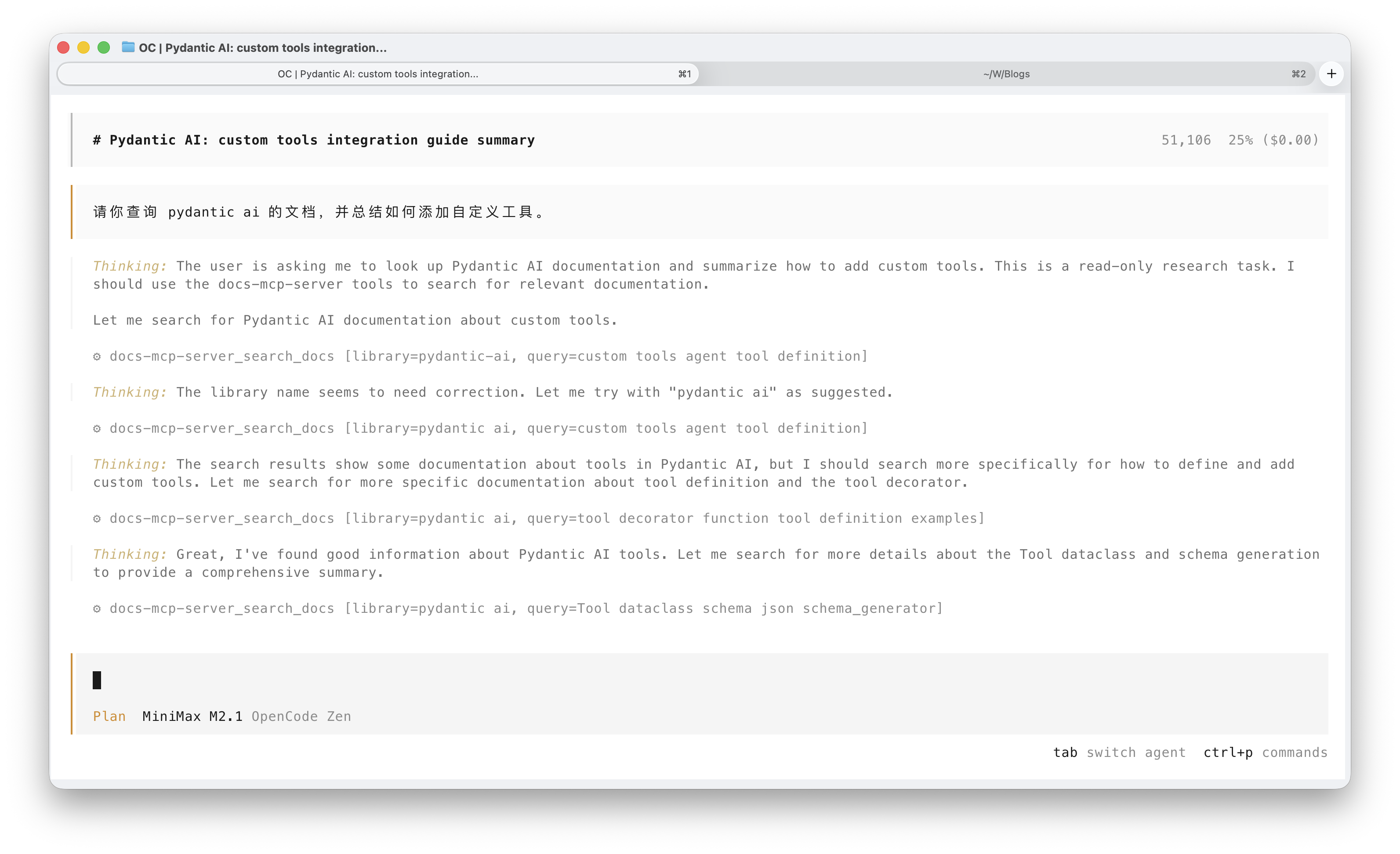
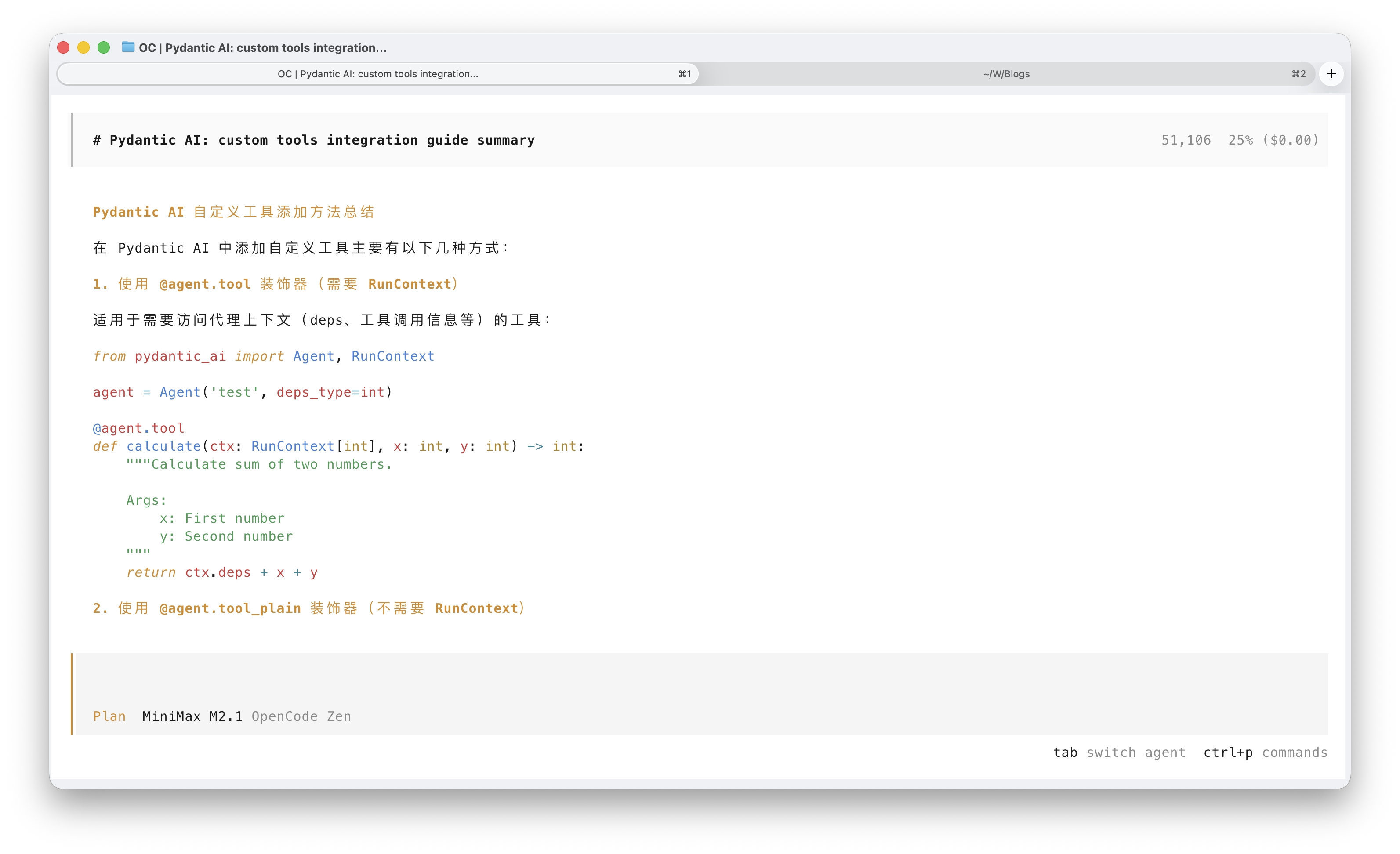
接入 Embedding 模型改善查询效果
前文已经提到,项目默认使用 OpenAI 提供的嵌入模型,如果没有 OpenAI API Key,我们也可以接入自定义的嵌入模型,例如本地跑一个,或者其他云供应商的。我这里采用了硅基流动提供的免费嵌入模型 BAAI/bge-m3,虽然已经有些旧了(2024 年 1 月发布),但仍然可用。创建一个 API Key 就可以接入,对于这个文档 MCP 来说,免费模型的 rate limit 足够单人使用了。
在启动服务器时可以通过环境变量指定自定义的 BASE_URL、API Key 和 Embedding 模型名称。
以下就是我个人的启动命令了:
docker run -d --name docs-mcp-server --rm \
-v docs-mcp-data:/data \
-v docs-mcp-config:/config \
-p 6280:6280 \
-e OPENAI_API_KEY=sk-xxxxxxxxx \
-e OPENAI_API_BASE=https://api.siliconflow.cn/v1 \
-e DOCS_MCP_EMBEDDING_MODEL=BAAI/bge-m3 \
-e DOCS_MCP_TELEMETRY=DOCS_MCP_TELEMETRY \
ghcr.io/arabold/docs-mcp-server:latest \
--protocol http --host 0.0.0.0 --port 6280

 浙公网安备 33010602011771号
浙公网安备 33010602011771号