
论文笔记:Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models
http://arxiv.org/abs/2203.11171
此文已被 ICLR 2023 接收。
太长不看
使用 CoT 提示方法,一次性采样多条路径然后选择出现次数最多的那个结果作为最终的结果。已经证明比纯粹的贪婪解码效果好得多,也能抵抗一些不良的提示条件。
摘要
本文直觉上的前提是:需要复杂推理的问题往往有多种解法,且有多种方法都可获得正确的答案。
引言
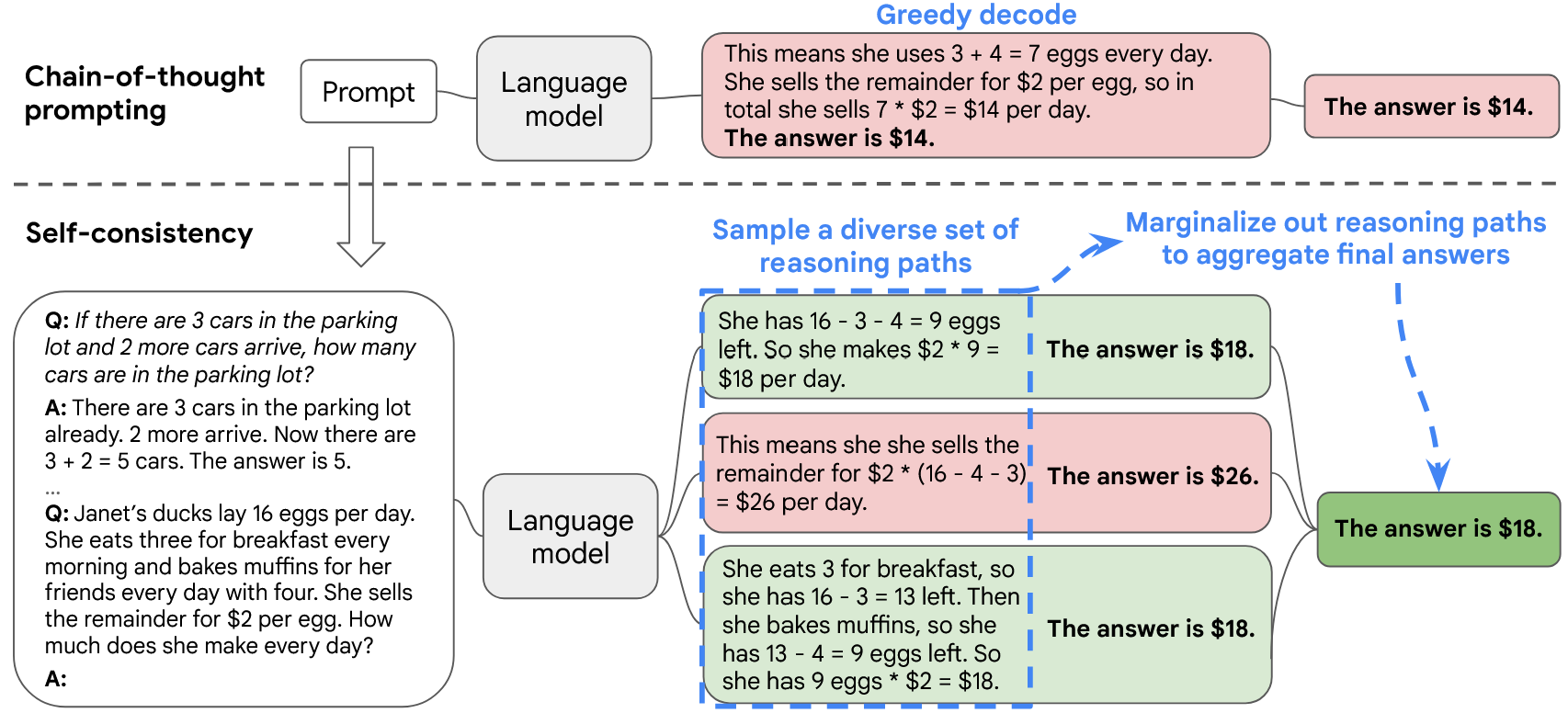
Self-Consistency 包含三个步骤:
- 使用思维链(CoT)提示法引导语言模型;
- 采样多条推理路径;
- 对推理路径进行边缘化处理,并通过在最终答案集中选择最一致的答案进行聚合。
方法
对一个问题的推理过程进行采样,可以得到若干条路径 \(\mathbf{r}_i\) 和与路径对应的结果 \(\mathbf{a}_i\)。那么给定一个 prompt 和一个问题,通过路径 \(\mathbf{r}_i\) 得到结果 \(\mathbf{a}_i\) 的概率可以表示为
理论上,上面这个概率值可以通过将路径上所有 token 生成时的概率相乘得到。实际上,为了保证数值的稳定,我们通常将这些概率取自然对数(即所谓 logprob)后相加。
我们可以直接将所有路径的这个概率值相加,但注意到序列越长,乘起来的概率值(总是小于 1)越多,从而导致最终的结果更小。也就是说联合概率会天然地惩罚更长的序列。为了避免这一问题,可以对概率进行归一化,即对 logprob 的和除以总 token 量 K。
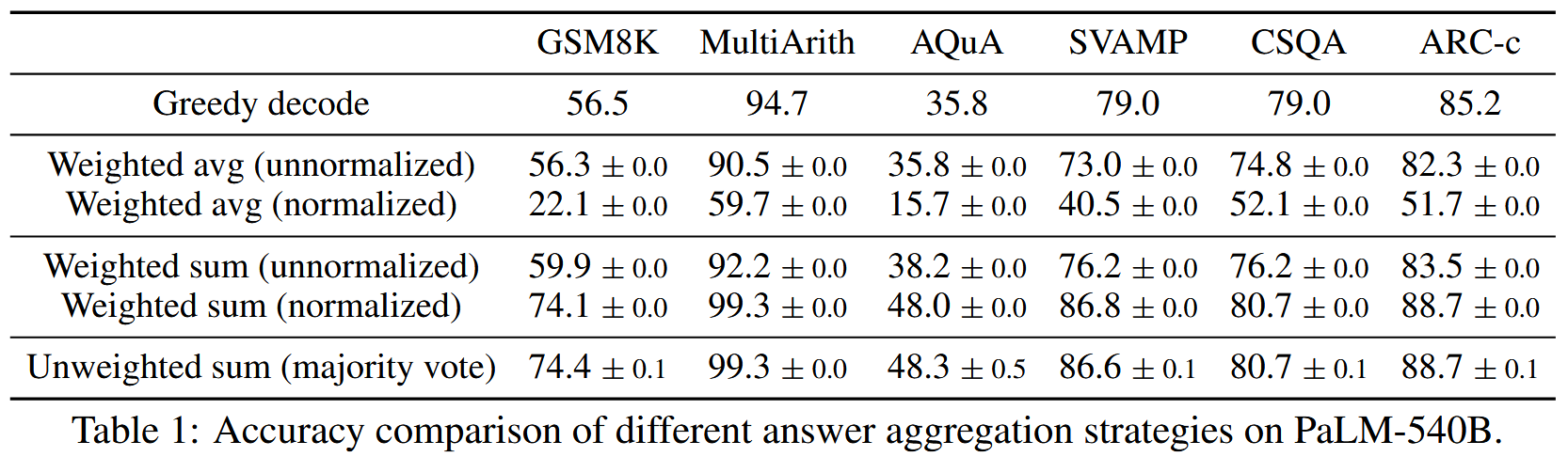
作者测试了几种处理方法:
- 贪婪解码:基线。
- Weighted avg (unnormalized) 不带归一化的加权平均,即对每个得出的答案,将得到该答案的所有路径的概率相加,然后除以对应的路径数量,选择平均最高的答案。此方案效果不佳,因为它削弱了高频正确答案的优势。即使有 10 条路径得出答案 A,但若其中几条概率很低,就会拉低 A 的平均得分。这违背了“多数一致”的直觉。
- Weighted avg (normalized) 带归一化的加权平均。完全继承了上述方法的劣势,且归一化进一步扭曲了概率分布,导致这个方法的效果最差。
- Weighted sum (unnormalized) 不带归一化的加权和,与 2 的区别是仅相加概率,不除以数量,其效果要好得多。
- Weighted sum (normalized) 带归一化的加权和。在 4 的基础上进行归一化,效果很好。
- 多数投票,完全忽略概率,只看答案出现的次数,效果与 5 差不多,也是本文最终采用的方案。
论文发现模型不善于区分正确路径和错误路径,这表现为它们归一化后的概率都差不多。因此进行简单的多数投票是可行的。
这背后也反映了当前 LLM 的一个问题:其生成概率的校准性(Calibration)较差,无法可靠地用于判断自身推理的质量。
作者指出,这种方法原则上只适用于答案确定的问题,如数学题。但如果能设计方法衡量两条路径之间的一致性(如,两条路径的结论相互佐证或相互矛盾),则此方法也能推广到开放的文本生成问题上。
实验
从几个维度进行了实验
任务和数据集
- 算术推理
- 常识推理
- 符号推理
模型
- UL2:20B 参数,编码器-解码器架构,性能接近 GPT-3
- GPT-3:175B 参数
- LaMDA-137B:密集仅解码器架构
- PaLM-540B:密集仅解码器架构
使用少样本提示,不对模型进行任何微调,使用与基线(CoT)相同的提示词。
采样方法
- 对于 UL2 和 LaMDA-137B,取温度 T=0.5,Top-K=40;
- 对于 PaLM-540B,取 T=0.7,Top-K=40;
- 对于 GPT-3,取 T=0.7 不进行 Top-K 截断。
结果
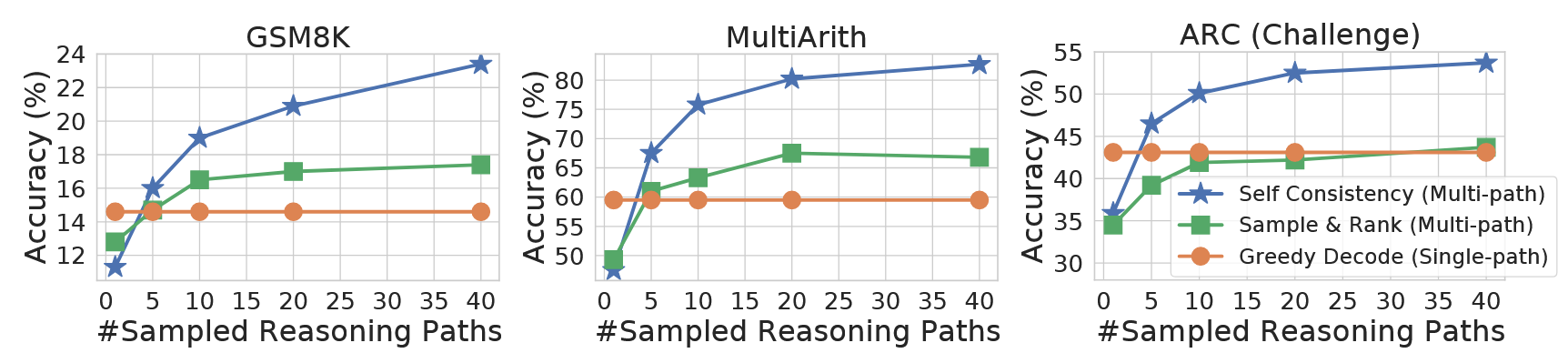
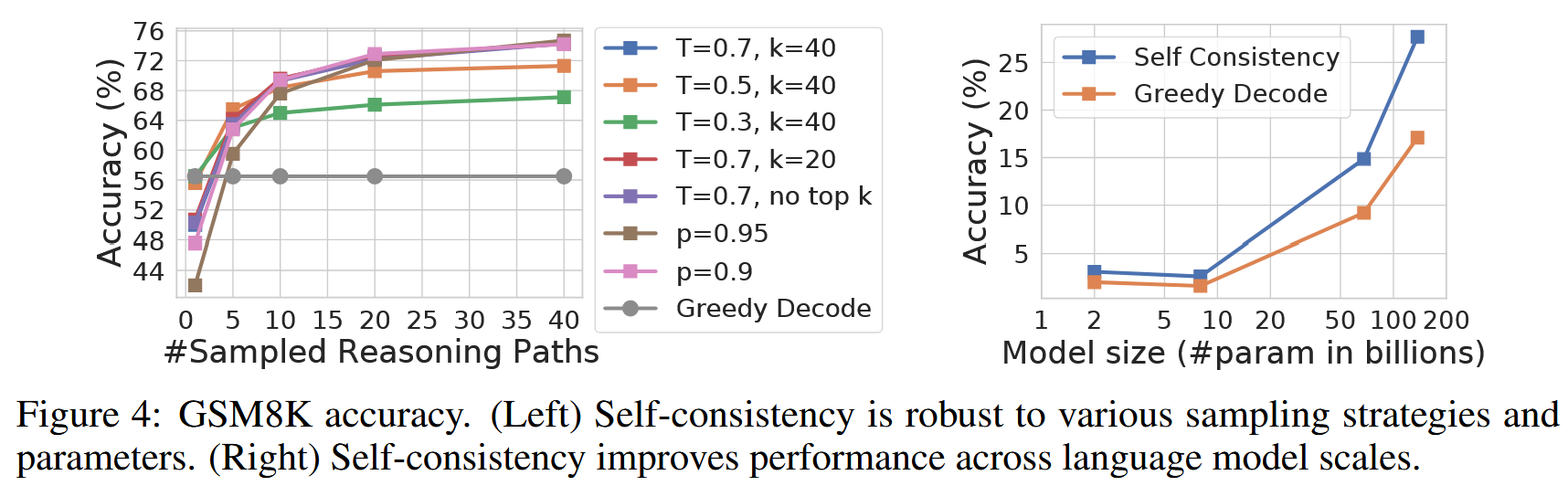
Self-Consistency 在所有 4 个模型上都显著提升了准确率,且随着模型规模的增大,这种提升变得更加显著。
另外,有文献表明,在少样本上下文学习中,有时 CoT 提示相比标准提示反而会降低性能。但本文的方法则不会导致性能下降。
本文方法优于 Sample & Rank 方法。后者同样采样出多条路径,但将这些路径按照对数概率进行排序然后直接选择概率最高的方法。
本文方法也可以与 Beam Search 联合使用,但联合使用对性能有害。这是因为 Beam Search 会降低答案的随机性:文献,而随机性显然对本文的方法至关重要。
本文方法也优于集成方法。后者是训练多个模型然后综合它们的结果,而本文更像是单个模型的“自集成”。
作者还测试了不同采样参数对效果的影响。更高的温度显然有利于性能。
作者还发现在少量提示词不完美的情况下,Self-Consistency 同样能够稳健地提升性能。
作者还发现,一致性与准确性高度相关。更高的一致性通常对应更高的准确性。这表明一致性可以作为模型的信心的指示。
本文的一些不足
- 显著更高的计算开销。进行采样多条解码路径会显著增加推理时的计算量,从而导致更长的解码时间,论文并未设计任何提前终止解码的方案,因此所有路径都将持续解码直至得出一个答案,这导致了解码时间的成倍增加。
- 本文也缺少对一些关键问题的讨论,如模型为什么在多条采样路径中倾向于收敛到正确答案,又如模型为什么不能通过单一采样路径进行自我校准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号