
论文笔记:DeepPrune: Parallel Scaling without Inter-trace Redundancy
DeepPrune: Parallel Scaling without Inter-trace Redundancy
http://arxiv.org/abs/2510.08483
TL;DR
LLM 进行并行思考时会产生很多导向相同结果的冗余路径。本文使用一个微调的 LLM 来在推理早期判断两条路径是否可能导向同一结果,然后使用一种动态剪枝算法来提前终止冗余的路径,最终实现精度不明显下跌的同时大幅减少 token 消耗。
Introduction
LLM 的推理时扩展(inference-time scaling)有两种主要路线:
- 线性扩展,即单条思考轨迹中扩展长度,输出长度能够扩展到 128K 左右;
- 并行扩展,即并行地生成多条思考轨迹,输出总长度可达到 100M 甚至更多。
目前的一些高效思考优化方案大多集中于线性扩展路线,针对并行扩展路线的优化工作较少,目前主要是基于模型内部置信度的方案。但这种方案有两个问题:
- 无法降低不同思考路径之间的冗余
- 有在早期终止正确思考路径的风险
本文在早期实验中观察到,大约 80% 的并行思考轨迹会得出相同的最终答案,而仅有 20% 会产生不同的解决方案。这一现象揭示了当前并行思考范式中存在显著的冗余性。
作者尝试研究通过早期的思维轨迹(如前 500 个词)的分析来确定最终答案的等价性,发现现有模型(SentenceBERT 和 Qwen3-4B-Instruct)的分类效果很差。最终作者通过训练一个基于 LLM 的分类器来实现更高精度的分类,并将冗余的路线提前终止。
本文的主要贡献:
- 识别并量化了并行思考中普遍存在的跨轨迹冗余问题,发现超过 80% 的计算资源被用于生成等价的思考路径,造成了巨大的计算浪费。
- 提出了 DeepPrune,一种结合了训练的判断模型与在线贪心聚类的新框架,能够在有效剪枝冗余推理轨迹的同时,保留答案的多样性。
- 大量离线和在线实验表明,本文的方法在不牺牲准确率的前提下,可将token消耗降低高达95%,在多个推理基准和模型架构上显著优于现有基线方法。
Preliminaries
问题定义
问题可定义为:设计一种方法,简化一个思考路径集合,将集合中冗余的部分删去:当两条路径的相似度高于某个阈值时,就仅保留其中一个。因此问题的关键是设计一种衡量相似度的方法。考虑到并行思考大多只看最终结果,本文将相似度简化为最终结果是否一致。
因此,本文的方法也仅局限于有确定答案的问题。
路径冗余是高效并行思考的瓶颈
作者使用以下 4 个思考模型:
- DeepSeek-R1-Distill-Llama-8B
- Qwen3-4B-Thinking-2507
- GLM-4.5-Air
- QwQ-32B
在来自 MATH500、AIME24、AIME25、GPQA 等数据集上选取的 115 个问题上,针对每个问题分别生成 16 条思考路径。16 条路径两两配对,将产生 120 个对,因此每个模型一共有约 13000 个对。
随后,作者使用来自 DeepScaleR 中的基于规则的奖励函数来验证每对的答案是否一致。结果如下:
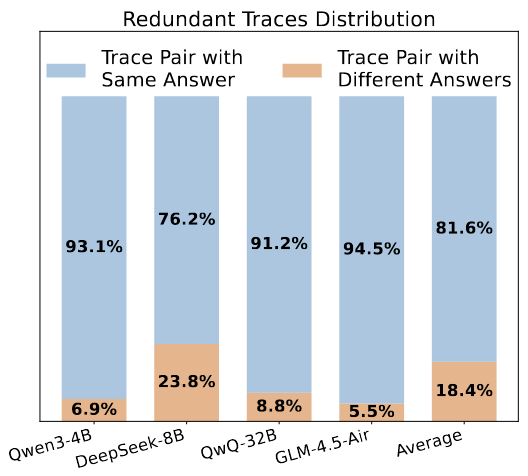
这一结果说明即使在一个比较少的轨迹预设(16 条)下,冗余率也非常高。
随后作者探究能否通过轨迹早期的部分能否预测最终的结果。针对两种方法进行评估:
- 浅层语义相似性:使用 SentenceBERT 计算两条轨迹前 700 个 token 之间的余弦相似度。该相似度得分作为二分类任务的特征。ROC 曲线的 AUROC 仅为 0.58,略优于随机猜测(AUROC=0.5)。
- 基于 LLM 的深度比对:采用 Qwen3-4B-Instruct 模型在零样本设置下进行比对。设计一条 prompt,指导模型比较两条长度为 700 token 的未完成轨迹,并判断它们是否会得出相同的答案。该分类器的 ROC 曲线达到了 0.68 的 AUROC,显著优于 SentenceBERT,但仍然不够好。
补充说明:AUROC 是一个用来评估二元分类模型性能的指标。它衡量的是模型将正例样本排在负例样本前面的能力。AUROC 的值介于 0 和 1 之间,值越接近 1,表示模型的性能越好。
- AUROC = 1:完美的分类器。
- AUROC = 0.5:随机猜测的分类器(无区分能力)。
- AUROC < 0.5:比随机猜测还差(通常意味着标签可能被反转了)。

DeepPrune
分类模型的训练
探索了两种不同的截断策略:
- 固定长度,即保留轨迹中前 k 个 token。
- 固定思考步数:通过一些 CoT 关键词(wait, thus, since)来确定思考步数,然后保留前 k 步。
judge model 在 Qwen3-4B-Instruct 上微调得到。由于两类(相同路径和不同路径)的数量是严重不均衡的,作者采用 focal loss 和将少数类(即不同路径)扩大两倍的方法来克服这种不均衡。
实时剪枝
作者使用一种贪婪聚类算法来排除冗余路径。
这里我也没太看懂逻辑。问了 Gemini 之后梳理出来的。不一定准确。
在推理过程中,维护一个路径类的集合 \(C=\{c_1,c_2,\dots,c_m\}\),其中的每类 \(c_j\) 都对应一组路径,这组路径将导向同一个结果。
设置一个超参数 \(K\)(作者设置为 32),表示推理过程中 \(C\) 的最大长度(最多有几类),如果未达到 \(K\),则按照以下的规则进行聚类,否则终止聚类过程。
通过公式 \(p=\text{min}(K_1, |c_j|)\) 来确定 \(p\),表示从一个特定的类中采样的路径数量。\(K_1\) 也是超参数,作者设置为 10。也就是说,采样的路径数量将不超过 10。
对于一个新产生的路径 \(t_i\),从每个类 \(c_j\) 中随机抽取 \(p\) 条路径,然后使用以下公式来计算 \(t_i\) 和类 \(c_j\) 的相似度:
这里 \(J_\theta\) 就是前面微调的分类器,此公式的大意是,分别计算 \(t_i\) 和 \(c_j\) 中抽出的每一条路径的相似度,然后取平均值作为 \(t_i\) 和 \(c_j\) 的相似度。
如果这相似度大于阈值 \(\tau\)(作者设置为 0.5),则将 \(t_i\) 归入相似度最高的 \(c_j\) 中,否则,设立一个新的类容纳 \(t_i\)。
这种贪婪聚类方法避免了穷举式地将 \(t_i\) 与其他所有路径对比,减少了计算量。
下一步需要确定让哪些路径走到最后。需要注意到分类器存在两个问题:
- 过度自信(Over-confident):分类器觉得大部分路径都差不多,导致几乎所有路径都被分到了同一个巨大的簇里。这会导致这个最大的簇 \(c_\text{max}\) 包含太多冗余路径。
- 过度谨慎(Over-cautious):分类器觉得任何两条路径之间都有细微差别,不愿意把它们归为一类。结果就是,每个簇里只有一条路径(\(|c|=1\)),聚类操作等于什么都没做。
为了缓解上述问题,使用以下的多数投票步骤:
先选出包含最多轨迹的类 \(c_\text{max}\)。
然后分情况:
- 如果每个类都只有一条轨迹,则直接放弃聚类结果,然后从所有路径中随机选取 \(K_3\) (作者设置为 64)条路径,让它们进行到最后。
- 如果有至少一个类有多于一条轨迹,则从 \(c_\text{max}\) 中选取 \(k^*\) 条轨迹进行到最后,其中 \(k^*=\text{min}(K_2, |c_\text{max}|)\),作者设置 \(K_2=10\)。
最后,在结果中选取出现次数最多的那个结果作为最终的结果。
实验
只记录一下结论:
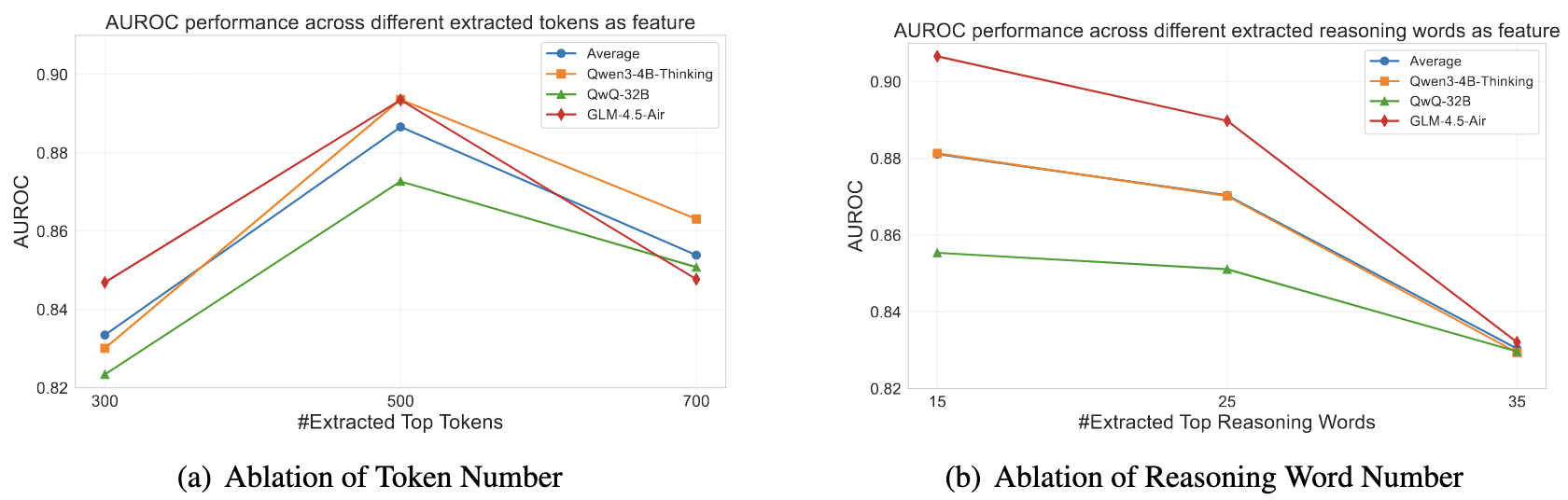
- 相比按 token 数量截断,思考步骤对齐可以提供更可靠的等价答案预测信号。
- 仅使用过采样会严重降低性能,必须搭配 focal loss 才行。
- DeepPrune 在 token 效率方面始终优于基于置信度的剪枝方法,且能更稳定地保持准确率。
关于 token 截断和思考关键词截断的对比分析:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号