

协同过滤
基于余弦相似度的协同过滤推荐算法
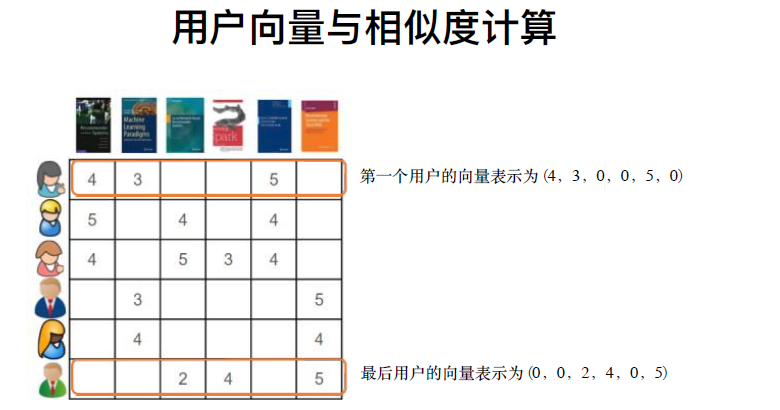

1、导入原始数据


1,1,4 1,2,3 1,5,5 2,1,5 2,3,4 2,5,4 3,1,4 3,3,5 3,4,3 3,5,4 4,2,3 4,6,5 5,2,4 5,6,4 6,3,2 6,4,4 6,6,5
import numpy as np import pandas as pd from sklearn.metrics.pairwise import cosine_similarity data = pd.read_csv('example.txt', header = None, names = ['user', 'product_id', 'score'])
将其转换成矩阵数据形式,行代表每一个用户,列代表每一个产品,值为每个用户对不同产品的打分情况
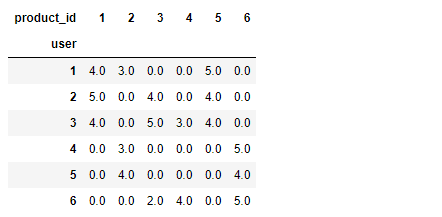
freq_matrix = data.pivot(index = 'user', columns = 'product_id', values = 'score') freq_matrix = freq_matrix.fillna(0)
得到 freq_matrix 如下:
2、计算用户的余弦相似度
# 使用函数算出相似矩阵
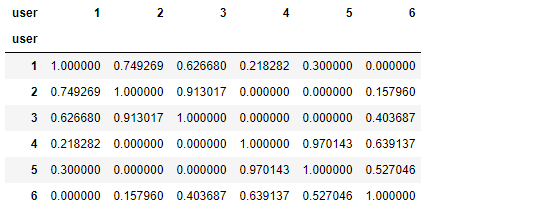
user_similar_matrix = cosine_similarity(freq_matrix) # cosine_similarity计算的是行与行之间的相似性,行是用户就是基于用户的相似性 # 加上必要的列名和行名,这里是因为是基于用户的,所有可以将user的index同时设置成这里的index与columns user_similar_matrix = pd.DataFrame(user_similar_matrix, index = freq_matrix.index, columns = freq_matrix.index)
得到余弦相似度矩阵:
3、计算推荐的产品得分
根据相似度矩阵和原始打分矩阵,将和当前用户行为最相似的k个用户看过的,但是当前用户没看过的产品,推荐给当前用户,并计算推荐得分
例如:针对用户1,其3号产品没有看过,取与其最相似的2个用户,计算3号产品的推荐得分
(1)用相似度矩阵找出与用户1最相似的2个用户:
与用户1最相似的2个用户是用户2和3

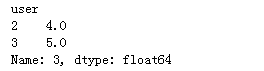
k = 2 #固定用户id和商品id,单独进行推荐的分数的计算 user_id = 1 item_id = 3 #在freq_matrix找出这个物品所有的用户的评分 item_id_col = freq_matrix.loc[:, item_id] #找到和当前用户id最为相似的前k的用户,使用user_similar_matrix similar_id_values = user_similar_matrix.loc[user_id, :].sort_values()[-(k+1):-1] # similar_id_values = user_similar_matrix.loc[user_id, :].sort_values(ascending=False)[1:k+1] # 给similar_id_value排序 similar_id_values = similar_id_values.sort_index() similar_id_values
结果为:

(2)用原始打分矩阵计算推荐产品的得分
用户1没有看过3号产品,结合用户2给3号产品的打分是4分,用户3给3号产品的打分是5分,根据相似度进行加权打分,有

3号产品给1号用户的推荐得分为:
(0.749269 * 4 + 0.62668 * 5) / (0.749269 + 0.2668) = 4.45545
# 将最相似的两个用户对当前item_id这个物品评分提取出来 score = freq_matrix.loc[similar_id_values.index, item_id]
结果为:
# 设计函数,计算向量和向量之间的点乘 def vector_product(v1, v2): v1 = np.mat(v1).T v2 = np.mat(v2).T return np.array(v1.T * v2)[0][0]
# 可以对用户的分数,判断,如果大于0,为True,如果等于0,为False # 这一步是为了方便我们最后的分数的计算 score_above_0 = (score > 0).astype(int)
结果为:

#计算分数的加权平均 above_score = vector_product(similar_id_values, score) #计算分母 below_score = vector_product(similar_id_values, score_above_0) #计算推荐分数 above_score/below_score
结果为:
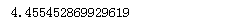
将上述步骤编辑为函数,可以直接根据用户和产品计算出推荐得分:
def vector_product(v1, v2): v1 = np.mat(v1).T v2 = np.mat(v2).T return np.array(v1.T * v2)[0][0] def cal_recommend_index(k, user_id, item_id, freq_matrix, user_similar_matrix): item_id_col = freq_matrix.loc[:, item_id] similar_id_values = user_similar_matrix.loc[user_id, :].sort_values()[-(k+1):-1] similar_id_values = similar_id_values.sort_index() score = item_id_col[similar_id_values.index] if np.sum(score) == 0: return 0 score_above_0 = (score > 0).astype(int) above_score = vector_product(similar_id_values, score) below_score = vector_product(similar_id_values, score_above_0) return above_score/below_score

(3)计算最终的全部推荐结果
# 获得与原始打分表格结构一致的全0矩阵,用来保存推荐得分 predict_matrix = pd.DataFrame(np.zeros(freq_matrix.shape), index = freq_matrix.index, columns = freq_matrix.columns)
计算并保存推荐得分
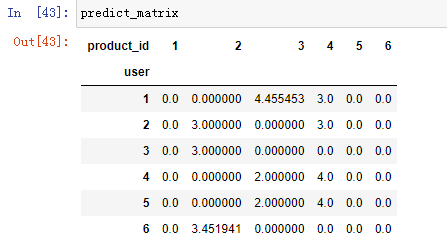
for user_id in freq_matrix.index: for item_id in freq_matrix.columns: # 假如说这个商品是等于0,的话,就暗示着,可能需要对当前的user_id来进行推荐 if freq_matrix.loc[user_id,item_id] == 0 : final_score = cal_recommend_index(k = 2, user_id = user_id, item_id = item_id, freq_matrix = freq_matrix, user_similar_matrix = user_similar_matrix) # 计算出来的分数,填到predict_matrix里面所对应的这个位置 predict_matrix.loc[user_id, item_id] = final_score
结果为:
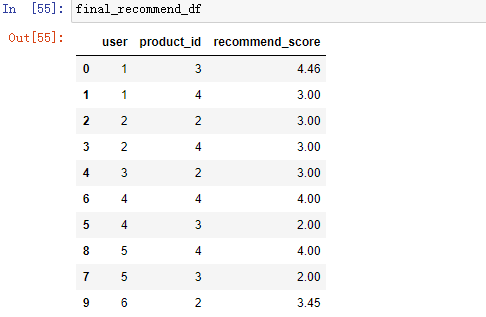
# 保留两位小数 predict_freq_matrix = np.around(predict_matrix,2) # 去除为0的值 predict_freq_matrix.replace(0, np.nan).stack() # 转换predict_freq_matrix为原来的data的格式 final_recommend_df = predict_freq_matrix.replace(0, np.nan).stack().reset_index() #重命名列名,将0替换为recommend_score final_recommend_df = final_recommend_df.rename({0 : 'recommend_score'}, axis = 1) # final_recommend_df.rename(columns={0: 'recommend_score'}) # 按照用户进行生序排序,再按照分数进行降序的排序 final_recommend_df = final_recommend_df.sort_values(['user', 'recommend_score'], ascending = [True, False])
结果为:
4、封装推荐算法函数
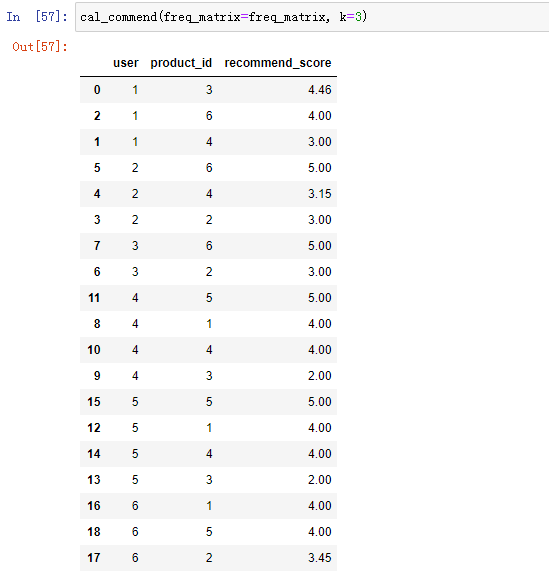
# 向量相乘 def vector_product(v1, v2): v1 = np.mat(v1).T v2 = np.mat(v2).T return np.array(v1.T * v2)[0][0] # 计算推荐得分 def cal_recommend_index(k, user_id, item_id, freq_matrix, user_similar_matrix ): item_id_col = freq_matrix.loc[:, item_id] similar_id_values = user_similar_matrix.loc[user_id, :].sort_values()[-(k+1):-1] similar_id_values = similar_id_values.sort_index() score = item_id_col[similar_id_values.index] if np.sum(score) == 0: return 0 score_above_0 = (score > 0).astype(int) above_score = vector_product(similar_id_values, score) below_score = vector_product(similar_id_values, score_above_0) return above_score/below_score # 最终推荐结果 def cal_commend(freq_matrix, k = 2): user_similar_matrix = cosine_similarity(freq_matrix) user_similar_matrix = pd.DataFrame(user_similar_matrix, index = freq_matrix.index, columns = freq_matrix.index) predict_matrix = pd.DataFrame(np.zeros(freq_matrix.shape), index = freq_matrix.index, columns = freq_matrix.columns ) for user_id in freq_matrix.index: for item_id in freq_matrix.columns: if freq_matrix.loc[user_id, item_id] == 0: final_score = cal_recommend_index(k, user_id = user_id, item_id = item_id, freq_matrix = freq_matrix, user_similar_matrix = user_similar_matrix) predict_matrix.loc[user_id, item_id] = final_score predict_freq_matrix = np.around(predict_matrix, 2) final_recommend_df = predict_freq_matrix.replace(0, np.nan).stack().reset_index() final_recommend_df = final_recommend_df.rename(columns = {0: 'recommend_score'}) final_recommend_df = final_recommend_df.sort_values(['user', 'recommend_score'], ascending = [True, False]) return final_recommend_df
结果为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号