Hive的学习
首先利用python造一些假数据,来进行hive的学习:
代码如下:
# coding: utf-8
import random
import datetime
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# lastname 和 first 都是为了来随机构造名称
lastname = u"赵钱孙李周吴郑王冯陈褚卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜戚谢邹喻柏水窦章云苏潘葛奚范彭郎鲁韦昌马苗凤花方俞任袁柳酆鲍史唐费廉岑薛雷贺倪汤"
firstname = u"翩若惊鸿婉若游龙荣曜秋菊华茂春松髣髴兮若轻云之蔽月飘飖兮若流风之回雪远而望之皎若太阳升朝霞迫而察之灼若芙蕖出渌波"
#创建一个函数,参数start表示循环的批次:
def create_student_dict(start):
firstlen = len(firstname)
lastlen = len(lastname)
#创建一个符合正太分布的数列
scoreList = [int(random.normalvariate(100,50)) for _ in xrange(1,5000)]
#创建1万条记录,如果执行程序内存够大,可以调大
filename = str(start)+'.txt'
print filename
#每次循环都创建一个文件,文件名为:循环次数+'.txt',例如 1.txt
with open('./'+filename,mode='wr+') as fp:
for i in xrange(start * 40000,(start+1)*40000):
firstind = random.randint(1,firstlen-4)
model = {"s_no":u"xuehao_no_" + str(i),
"s_name":u"{0}{1}".format(lastname[random.randint(1,lastlen-1)],
firstname[firstind:firstind + 1]),
"s_brith":u"{0}-{1}-{2}".format(random.randint(1991,2000),
'0'+str(random.randint(1,9)),
random.randint(10,28)) ,
"s_age": random.sample([20,20,20,20,21,22,23,24,25,26],1)[0],
"s_sex": str(random.sample(['男','女'],1)[0]),
"s_score": abs(scoreList[random.randint(1000,4990)]),
's_desc': u"科技"
u"创新" * random.randint(1,20)
}
#写入数据到本地文件
fp.write("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\n".
format(model['s_no'],model['s_name'],model['s_brith'],model['s_age'],
model['s_sex'],model['s_score'],model['s_desc']))
#循环创建记录,一共是40000*500=2千万条数据
for i in xrange(1,501):
starttime = datetime.datetime.now()
create_student_dict(i)
赋予权限:确保文件有被执行的权限,代码如下:
chmod 777 init_student.py
生成数据,执行代码后,将在当前目录下生成500个文件:
python init_student.py
将文件上传到hdfs目录上:
hdfs dfs -put *.txt /tmp
在hive上创建student内部表:
create table if not exists test.student_tb_txt(
s_no string comment '学号',
s_name string comment '姓名',
s_birth string comment '生日',
s_age string comment '年龄',
s_sex string comment '性别',
s_score string comment '得分',
s_desc string comment '自我介绍'
)
row format delimited
fields terminated by '\t';
将hdfs上的文件导入到hive中:
HDFS文件导入数据命令:
LOAD DATA INPATH '/tmp/*.txt' INTO TABLE student_tb_txt;
本地文件导入数据命令:
LOAD DATA LOCAL INPATH '/tmp/*.txt' INTO TABLE student_tb_txt;
Hive表数据导入到本地
insert overwrite local directory '/root/hive_test/1.txt' select * from student_tb_txt;
Hive表数据导入到HDFS上
insert overwrite directory '/root/hive_test/1.txt' select * from student_tb_txt;
生成新表(行为表)
create table behavior_table as
select B.userid, A.movieid, B.rating, A.title
from movie_table A
join rating_table B
on A.movieid == B.movieid;
至此:student_tb_txt表的数据已经生成并加载完成。
创建第二张表:
# coding: utf-8
import random
import datetime
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#创建一个函数,参数start表示循环的批次:
def create_student_sc_dict(start):
#创建1万条记录,如果执行程序内存够大,可以调大
filename = str(start)+'.txt'
print start
#每次循环都创建一个文件,文件名为:循环次数+'.txt',例如 1.txt
with open('./'+filename,mode='wr+') as fp:
for i in xrange(start * 40000,(start+1)*40000):
#课程出现越多表示喜欢的人越多
course = random.sample([u'数学',u'数学',u'数学',u'数学',u'语文',u'语文',u'英语',u'物理',u'化学',u'生物'],1)[0]
model = {"s_no": u"xuehao_no_" + str(i),
"course":u"{0}".format(course),
"op_datetime": datetime.datetime.now().strftime("%Y-%m-%d"),
"reason": u"我非常非常非常" u"非常非常非常非常喜爱{0}".format(course)}
#写入数据到本地文件
line = "{0}\t{1}\t{2}\t{3}\n".format(model['s_no'],model['course'],model['op_datetime'],model['reason'])
fp.write(line)
#循环创建记录,一共是40000*500=2千万条数据
for i in xrange(1,501):
starttime = datetime.datetime.now()
create_student_sc_dict(i)
创建表:
create table if not exists test.student_sc_tb_txt(
s_no string comment "学号",
course string comment "课程名",
op_datetime string comment "操作时间",
reason string comment "选课原因"
)
row format delimited
fields terminated by '\t';
重复上面操作将数据导入到hive表中:
LOAD DATA INPATH '/tmp/*.txt' INTO TABLE student_sc_tb_txt;
开始第一个案例的学习:
union案例:
查询student_tb_txt表,每个年龄段最晚出生和最早出生的人的出生日期,并将其存入表student_stat中。
---创建一张新的统计表:
create table student_stat(a bigint,b string) partitioned by (tp string)
stored as textfile;
--开启动态分区
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;
--找出各个年龄段最早和最晚出生的信息,并将这两部分信息使用union进行合并写入
insert into table student_stat partition(tp)
select s_age,max(s_birth) stat,'max' tp
from student_tb_txt
group by s_age
union all
select s_age,min(s_birth) stat,'min' tp
from student_tb_txt
group by s_age;
这个union all 一共启动了 5个job,如下。
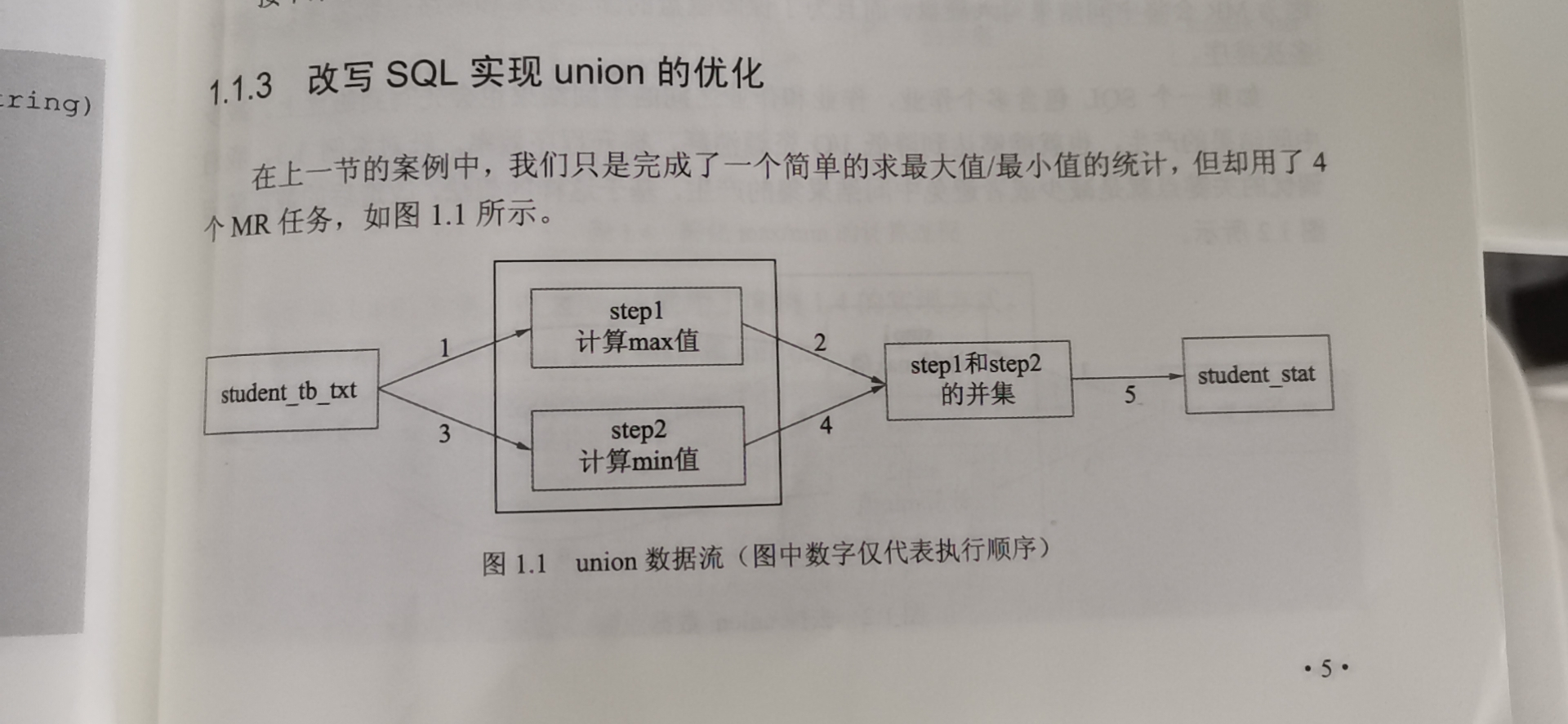
hive对union 这样的命令进行了优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号