hive grouping sets和GROUPING__ID的用法
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
grouping sets根据不同的维度组合进行聚合,等价于将不同维度的group by的结果进行 union all,简单来说就是将多个不同维度的group by逻辑写在了 一个sql中。
数据准备:
vim /root/test.txt
2015-03,2015-03-10,cookie1
2015-03,2015-03-10,cookie5
2015-03,2015-03-12,cookie7
2015-04,2015-04-12,cookie3
2015-04,2015-04-13,cookie2
2015-04,2015-04-13,cookie4
2015-04,2015-04-16,cookie4
2015-03,2015-03-10,cookie2
2015-03,2015-03-10,cookie3
2015-04,2015-04-12,cookie5
2015-04,2015-04-13,cookie6
2015-04,2015-04-15,cookie3
2015-04,2015-04-15,cookie2
2015-04,2015-04-16,cookie1
将数据导入到hdfs目录上:
hdfs dfs -put /root/test.txt /tmp
创建表
use test;
create table cookie5(month string, day string, cookieid string)
row format delimited fields terminated by ',';
load data inpath "/tmp/test.txt" into table cookie5;
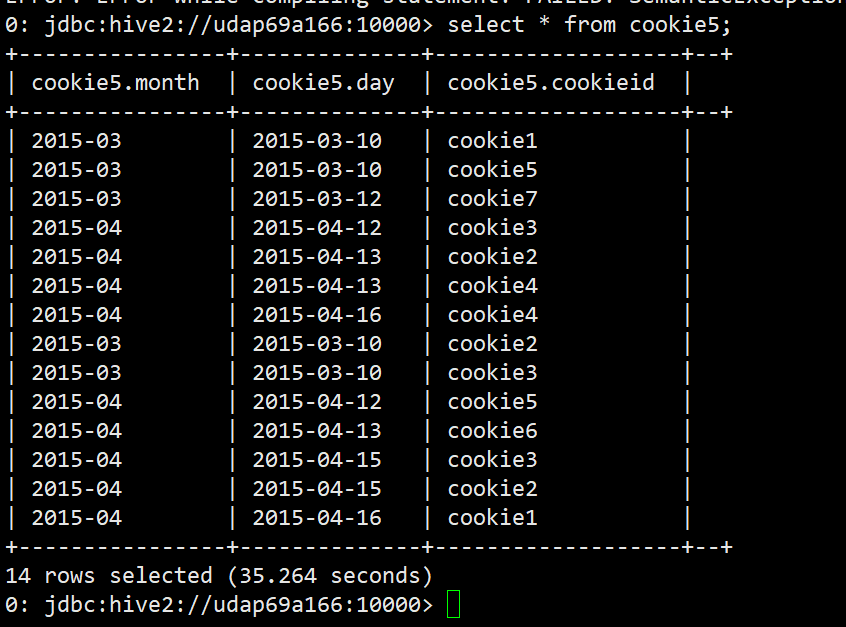
select * from cookie5;
开始使用grouping sets
来条sql语句:
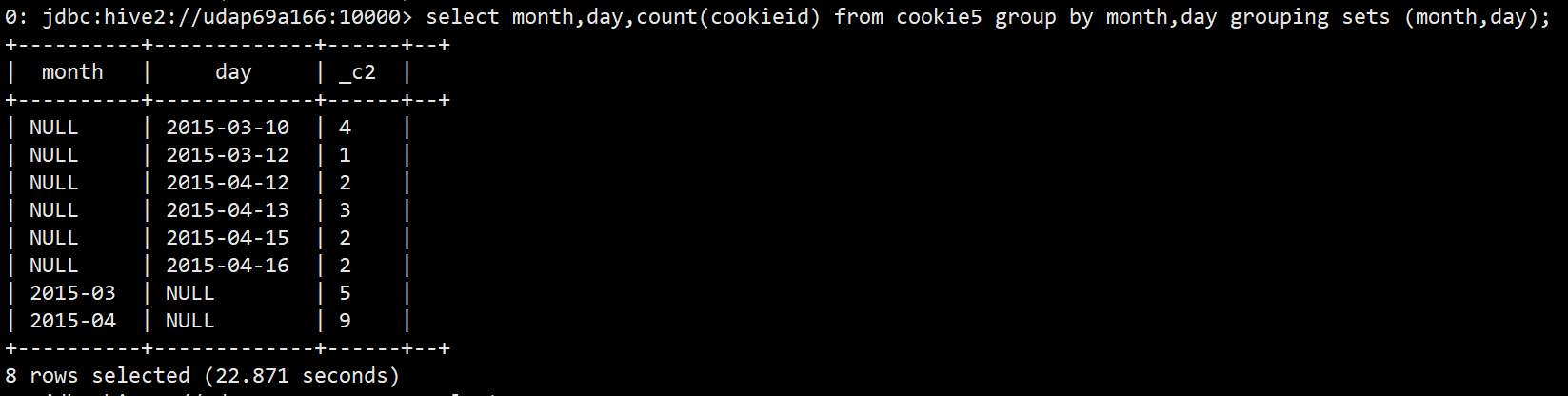
select
month,day,count(cookieid)
from cookie5
group by month,day
grouping sets (month,day);
查询结果如下:
上面这个sql等同于多个group by + union all
select month,NULL as day,count(cookieid) as nums from cookie5 group by month
union all
select NULL as month,day,count(cookieid) as nums from cookie5 group by day;
注意点:使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。union all的表字段必须匹配,也就是上文的month 需要用 NULL as month 来进行填充。
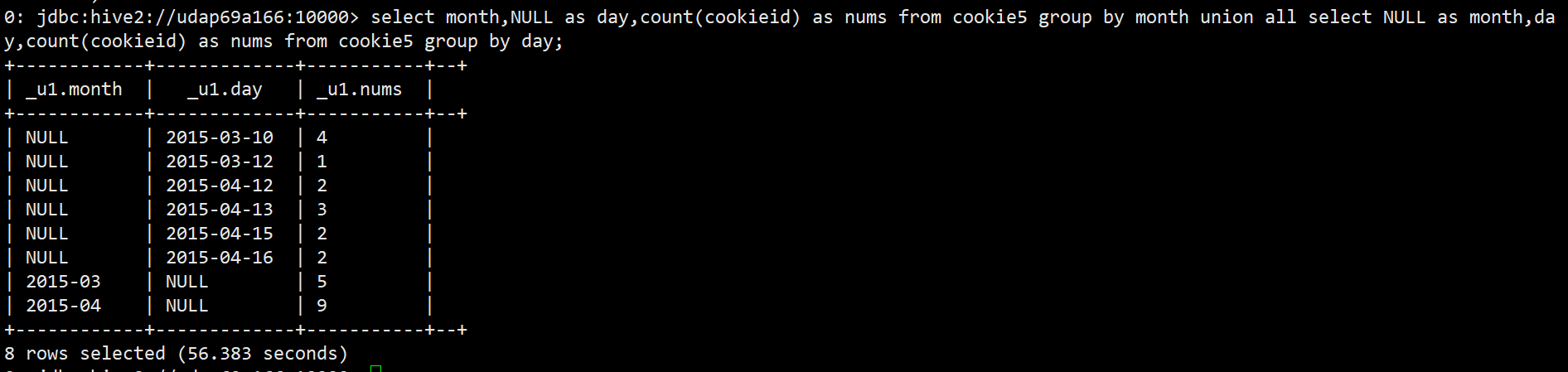
结果一致!但是grouping sets速度要比group by + union 快!!!!!
但是有引出一个问题?为什么grouping sets 要比 group by + union 速度要快?
首先:用explain来解释下hive执行计划:
explain select month,day,count(cookieid) from cookie5 group by month,day grouping sets (month,day);
执行计划如下:
+----------------------------------------------------+--+ | Explain | +----------------------------------------------------+--+ | STAGE DEPENDENCIES: | | Stage-1 is a root stage | | Stage-0 depends on stages: Stage-1 | | | | STAGE PLANS: | | Stage: Stage-1 | | Map Reduce | | Map Operator Tree: | | TableScan | | alias: cookie5 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Select Operator | | expressions: month (type: string), day (type: string), cookieid (type: string) | | outputColumnNames: month, day, cookieid | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Group By Operator | | aggregations: count(cookieid) | | keys: month (type: string), day (type: string), '0' (type: string) | | mode: hash | | outputColumnNames: _col0, _col1, _col2, _col3 | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | Reduce Output Operator | | key expressions: _col0 (type: string), _col1 (type: string), _col2 (type: string) | | sort order: +++ | | Map-reduce partition columns: _col0 (type: string), _col1 (type: string), _col2 (type: string) | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | value expressions: _col3 (type: bigint) | | Reduce Operator Tree: | | Group By Operator | | aggregations: count(VALUE._col0) | | keys: KEY._col0 (type: string), KEY._col1 (type: string), KEY._col2 (type: string) | | mode: mergepartial | | outputColumnNames: _col0, _col1, _col3 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | pruneGroupingSetId: true | | Select Operator | | expressions: _col0 (type: string), _col1 (type: string), _col3 (type: bigint) | | outputColumnNames: _col0, _col1, _col2 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | File Output Operator | | compressed: false | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | table: | | input format: org.apache.hadoop.mapred.TextInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | | | | Stage: Stage-0 | | Fetch Operator | | limit: -1 | | Processor Tree: | | ListSink
再看另外一个:
explain select month,NULL as day,count(cookieid) as nums from cookie5 group by month union all select NULL as month,day,count(cookieid) as nums from cookie5 group by day;
+----------------------------------------------------+--+ | Explain | +----------------------------------------------------+--+ | STAGE DEPENDENCIES: | | Stage-1 is a root stage | | Stage-2 depends on stages: Stage-1, Stage-3 | | Stage-3 is a root stage | | Stage-0 depends on stages: Stage-2 | | | | STAGE PLANS: | | Stage: Stage-1 | | Map Reduce | | Map Operator Tree: | | TableScan | | alias: cookie5 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Select Operator | | expressions: month (type: string), cookieid (type: string) | | outputColumnNames: month, cookieid | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Group By Operator | | aggregations: count(cookieid) | | keys: month (type: string) | | mode: hash | | outputColumnNames: _col0, _col1 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Reduce Output Operator | | key expressions: _col0 (type: string) | | sort order: + | | Map-reduce partition columns: _col0 (type: string) | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | value expressions: _col1 (type: bigint) | | Reduce Operator Tree: | | Group By Operator | | aggregations: count(VALUE._col0) | | keys: KEY._col0 (type: string) | | mode: mergepartial | | outputColumnNames: _col0, _col1 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Select Operator | | expressions: _col0 (type: string), UDFToString(null) (type: string), _col1 (type: bigint) | | outputColumnNames: _col0, _col1, _col2 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | File Output Operator | | compressed: false | | table: | | input format: org.apache.hadoop.mapred.SequenceFileInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe | | | | Stage: Stage-2 | | Map Reduce | | Map Operator Tree: | | TableScan | | Union | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | File Output Operator | | compressed: false | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | table: | | input format: org.apache.hadoop.mapred.TextInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | | TableScan | | Union | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | File Output Operator | | compressed: false | | Statistics: Num rows: 2 Data size: 756 Basic stats: COMPLETE Column stats: NONE | | table: | | input format: org.apache.hadoop.mapred.TextInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | | | | Stage: Stage-3 | | Map Reduce | | Map Operator Tree: | | TableScan | | alias: cookie5 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Select Operator | | expressions: day (type: string), cookieid (type: string) | | outputColumnNames: day, cookieid | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Group By Operator | | aggregations: count(cookieid) | | keys: day (type: string) | | mode: hash | | outputColumnNames: _col0, _col1 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | Reduce Output Operator | | key expressions: _col0 (type: string) | | sort order: + | | Map-reduce partition columns: _col0 (type: string) | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | value expressions: _col1 (type: bigint) | | Reduce Operator Tree: | | Group By Operator | | aggregations: count(VALUE._col0) | | keys: KEY._col0 (type: string) | | mode: mergepartial | | outputColumnNames: _col0, _col1 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | +----------------------------------------------------+--+ | Explain | +----------------------------------------------------+--+ | Select Operator | | expressions: UDFToString(null) (type: string), _col0 (type: string), _col1 (type: bigint) | | outputColumnNames: _col0, _col1, _col2 | | Statistics: Num rows: 1 Data size: 378 Basic stats: COMPLETE Column stats: NONE | | File Output Operator | | compressed: false | | table: | | input format: org.apache.hadoop.mapred.SequenceFileInputFormat | | output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat | | serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe | | | | Stage: Stage-0 | | Fetch Operator | | limit: -1 | | Processor Tree: | | ListSink | | | +----------------------------------------------------+--+
比较:通过explain ,当用grouping sets时,只有2个stage,只有一次reduce,而当用group by + union时,有4个stage,发生了两次reduce。那么肯定用grouping sets时,速度会快。
GROUPING__ID的使用:
来条sql语句:
select
month,
day,
count(distinct cookieid) as uv,
GROUPING__ID
from cookie5
group by month,day
grouping sets (month,day)
order by GROUPING__ID;

效果等价于:
SELECT month,NULL as day,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day;
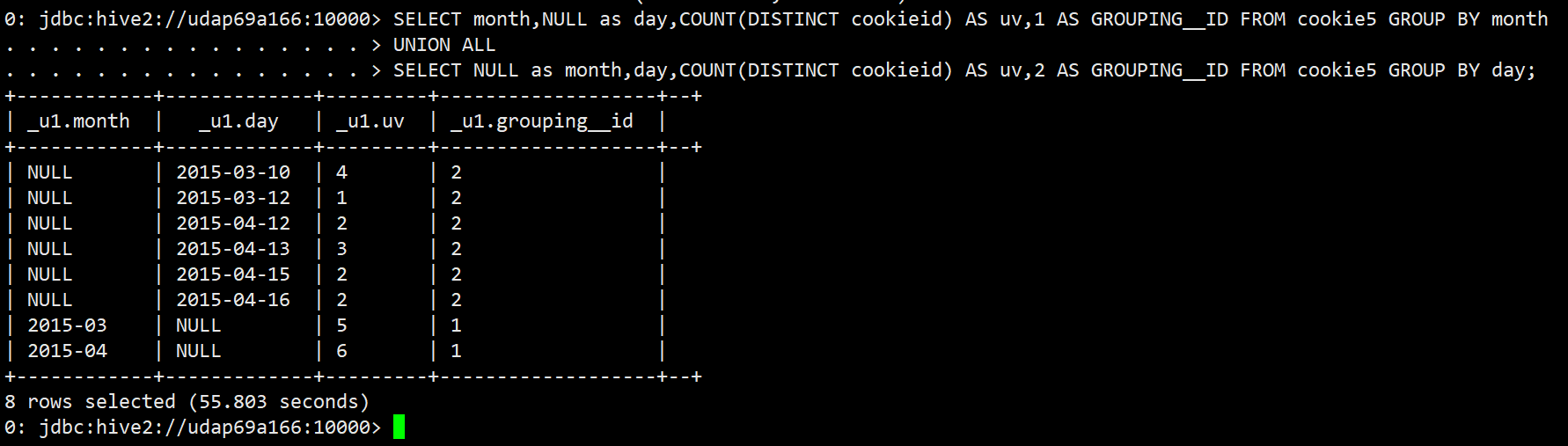
结果说明
第一列是按照month进行分组
第二列是按照day进行分组
第三列是按照month或day分组是,统计这一组有几个不同的cookieid
第四列grouping_id表示这一组结果属于哪个分组集合,根据grouping sets中的分组条件month,day,1是代表month,2是代表day
再来个例子:
SELECT month, day,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie5
GROUP BY month,day
GROUPING SETS (month,day,(month,day))
ORDER BY GROUPING__ID;
等价于:
SELECT month,NULL as day,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month
UNION ALL
SELECT NULL as month,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day;
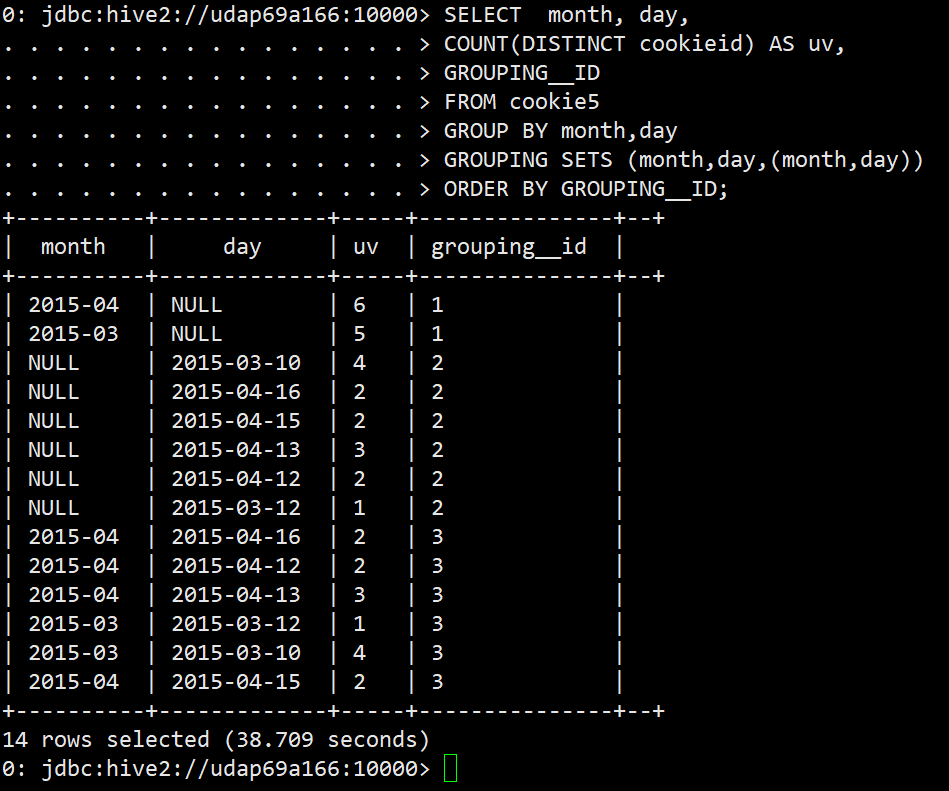
GROUPING SETS (month,day,(month,day)) 这个的意思是 按三个维度来进行统计 1.按月 2 按天 3 按 月和天 ,结果也能证明这一个观点。
结束! 转自:https://www.cnblogs.com/qingyunzong/p/8798987.html#_label2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号