spark操作Mysql的外部数据源
//创建spark数据库
create database spark;

//创建userinfor表
create table userinfor( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, age INT not null, PRIMARY KEY (id) );
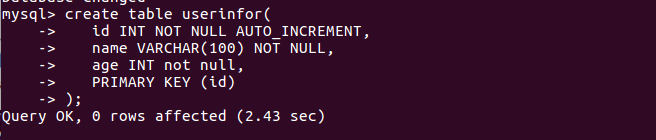
//向userinfor表中插入三条数据
insert into userinfor (name,age) values("Michael",20); insert into userinfor (name,age) values("Andy",30); insert into userinfor (name,age) values("Justin",19);
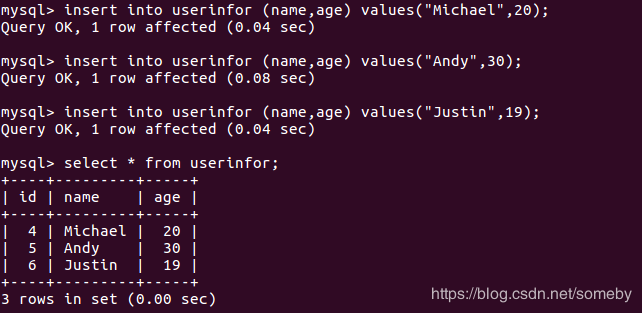
//创建scoreinfor表
create table scoreinfor( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, score INT not null, PRIMARY KEY (id) );
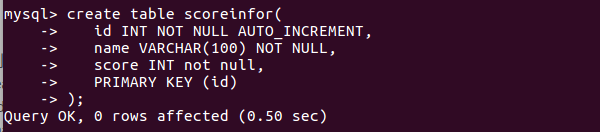
//向scoreinfo表中插入三条数据
insert into scoreinfor (name,score) values("Michael",98); insert into scoreinfor (name,score) values("Andy",95); insert into scoreinfor (name,score) values("Justin",91);
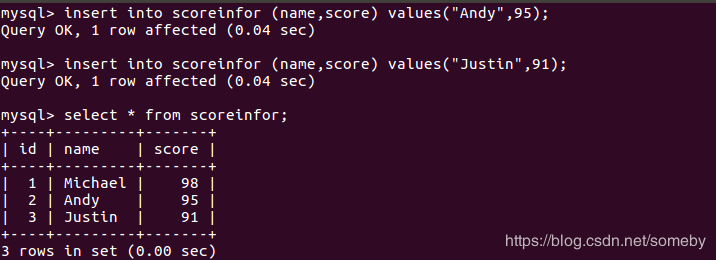
//创建jion后的存储表userscoreinfor表
create table userscoreinfor( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, age INT not null, score INT not null, PRIMARY KEY (id) );
一、spark-shell操作mysql数据
scala> val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://192.168.134.133:3306/spark").option("dbtable","spark.userinfor").option("user","root").option("password","root").option("driver","com.mysql.jdbc.Driver").load()
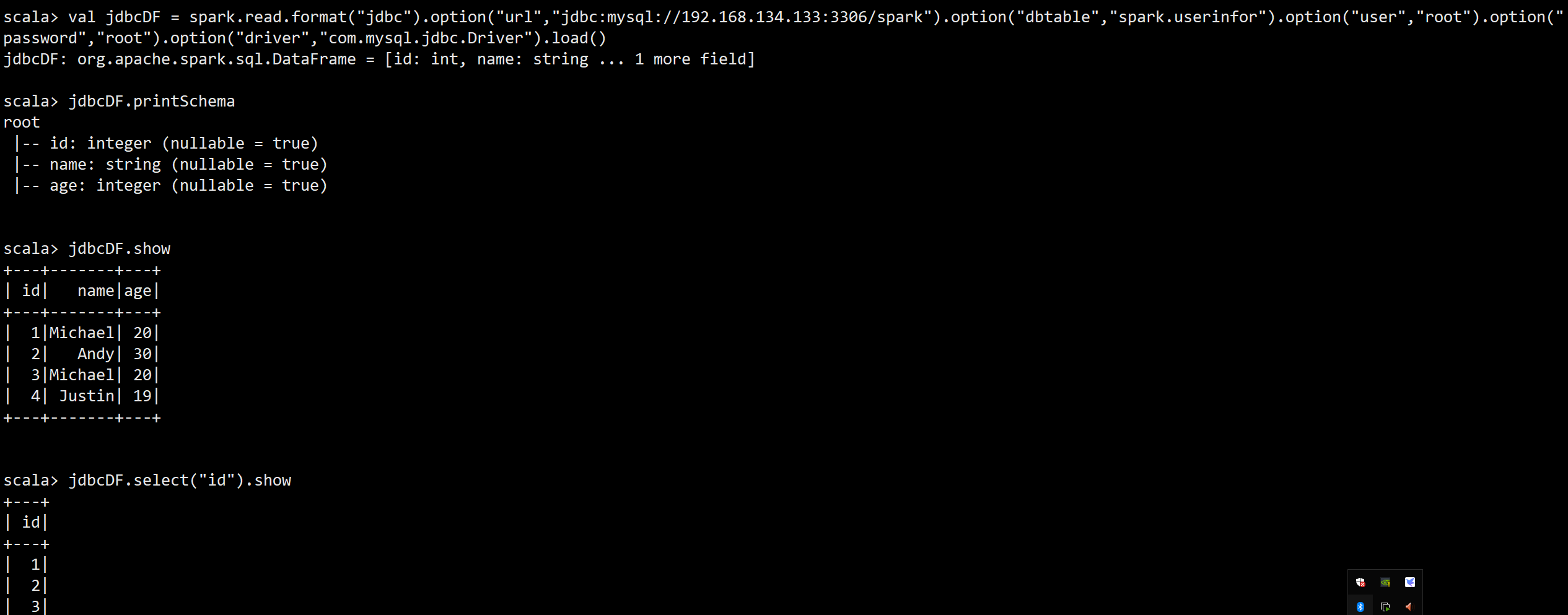
二、代码操作
Java代码示例:
package SparkSQL; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.PairFunction; import org.apache.spark.api.java.function.VoidFunction; import org.apache.spark.sql.*; import org.apache.spark.sql.types.DataTypes; import org.apache.spark.sql.types.StructField; import org.apache.spark.sql.types.StructType; import scala.Tuple2; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** * FileName: SparkSQLJDBCToMySQL * Author: hadoop * Email: 3165845957@qq.com * Date: 18-11-8 下午11:37 * Description: */ public class SparkSQLJDBCToMySQL { public static void main(String[] args) { //创建SparkConf用于读取系统信息并设置运用程序的名称 SparkConf conf = new SparkConf().setAppName("SparkSQLJDBCToMySQL").setMaster("local"); //创建JavaSparkContext对象实例作为整个Driver的核心基石 JavaSparkContext sc = new JavaSparkContext(conf); //设置输出log的等级,可以设置INFO,WARN,ERROR sc.setLogLevel("ERROR"); //创建SQLContext上下文对象,用于SqL的分析 SQLContext sqlContext = new SQLContext(sc); /** * 1.通过format("jdbc")的方式来说明SparkSQL操作的数据来源是JDBC, * JDBC后端一般都是数据库,例如去操作MYSQL.Oracle数据库 * 2.通过DataframeReader的option方法把要访问的数据库信息传递进去, * url:代表数据库的jdbc链接的地址和具体要连接的数据库 * datable:具体要连接使用的数据库 * 3.Driver部分是SparkSQL访问数据库的具体驱动的完整包名和类名 * 4.关于JDBC的驱动jar可以使用在Spark的lib目录中,也可以在使用 * spark-submit提交的时候引入,编码和打包的时候不需要这个JDBC的jar */ DataFrameReader reader = sqlContext.read().format("jdbc");//指定数据来源 reader.option("url","jdbc:mysql://localhost:3306/spark");//指定连接的数据库 reader.option("dbtable","userinfor");//操作的表 reader.option("driver","com.mysql.jdbc.Driver");//JDBC的驱动 reader.option("user","root"); //用户名 reader.option("password","123456"); //用户密码 /** * 在实际的企业级开发环境中,如果数据库中数据规模特别大,例如10亿条数据 * 此时如果用DB去处理的话,一般需要对数据进行多批次处理,例如分成100批 * (受限于单台Server的处理能力,)且实际的处理可能会非常复杂, * 通过传统的Java EE等技术很难或者不方便实现处理算法,此时采用sparkSQL * 获得数据库中的数据并进行分布式处理就可以非常好解决该问题, * 但是由于SparkSQL加载DB的数据需要时间,所以一般会SparkSQL和具体操作的DB之 * 间加上一个缓冲层,例如中间使用redis,可以把SparkSQL处理速度提高到原来的45倍; */ Dataset userinforDataSourceDS = reader.load();//基于userinfor表创建Dataframe userinforDataSourceDS.show(); reader.option("dbtable","scoreinfor"); Dataset scoreinforDataSourceDs = reader.load();//基于scoreinfor表创建Dataframe //将两个表进行jion操作 JavaPairRDD<String,Tuple2<Integer,Integer>> resultRDD = userinforDataSourceDS.javaRDD().mapToPair(new PairFunction<Row,String,Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(Row row) throws Exception { return new Tuple2<String,Integer>(row.getAs("name"),row.getAs("age")); } }).join(scoreinforDataSourceDs.javaRDD().mapToPair(new PairFunction<Row,String,Integer>() { private static final long serialVersionUID = 1L; @Override public Tuple2<String, Integer> call(Row row) throws Exception { return new Tuple2<String,Integer>(row.getAs("name"),row.getAs("score")); } })); //调用RowFactory工厂方法生成记录 JavaRDD<Row> reusltRowRDD = resultRDD.map(new Function<Tuple2<String, Tuple2<Integer, Integer>>, Row>() { @Override public Row call(Tuple2<String, Tuple2<Integer, Integer>> tuple) throws Exception { return RowFactory.create(tuple._1,tuple._2._1,tuple._2._2); } }); /** * 动态构造DataFrame的元数据,一般而言,有多少列以及每列的具体类型可能来自于json文件,也可能来自于数据库 */ List<StructField> structFields = new ArrayList<StructField>(); structFields.add(DataTypes.createStructField("name", DataTypes.StringType,true)); structFields.add(DataTypes.createStructField("age", DataTypes.IntegerType,true)); structFields.add(DataTypes.createStructField("score", DataTypes.IntegerType,true)); //构建StructType,用于最后DataFrame元数据的描述 StructType structType = DataTypes.createStructType(structFields); //生成Dataset Dataset personDS = sqlContext.createDataFrame(reusltRowRDD,structType); personDS.show(); /** * 1.当Dataframe要把通过SparkSQL,core、ml等复杂操作的数据写入数据库的时候首先是权限的问题,必须确保数据库授权了当前操作SparkSQL的用户; * 2.Dataframe要写数据到DB的时候,一般都不可以直接写进去,而是要转成RDD,通过RDD写数据到DB中, */ personDS.javaRDD().foreachPartition(new VoidFunction<Iterator<Row>>(){ @Override public void call(Iterator<Row> rowIterator) throws Exception { Connection connection = null;//数据库连接 Statement statement = null; // try{ connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/spark","root","123456"); statement = connection.createStatement(); while (rowIterator.hasNext()){ String sqlText = "insert into userscoreinfor (name,age,score) values ("; Row row = rowIterator.next(); String name = row.getAs("name"); int age = row.getAs("age"); int score = row.getAs("score"); sqlText+="'"+name+"',"+"'"+age+"',"+"'"+score+"')"; statement.execute(sqlText); } }catch (SQLException e){ e.printStackTrace(); }finally { if (connection != null){ connection.close(); } } } }); } }
Scala代码示例:
package SparkSQL import java.sql.{Connection, Driver, DriverManager, SQLException, Statement} import org.apache.spark.sql.{Row, RowFactory, SQLContext} import org.apache.spark.{SparkConf, SparkContext} /** * FileName: SparkSQLJDBCMySQLScala * Author: hadoop * Email: 3165845957@qq.com * Date: 18-11-9 上午9:27 * Description: * */ object SparkSQLJDBCMySQLScala { def main(args: Array[String]): Unit = { //创建SparkConf用于读取系统信息并设置运用程序的名称 val conf = new SparkConf().setMaster("local").setAppName("SparkSQLJDBCMySQLScala") //创建JavaSparkContext对象实例作为整个Driver的核心基石 val sc = new SparkContext(conf) //设置输出log的等级,可以设置INFO,WARN,ERROR sc.setLogLevel("INFO") //创建SQLContext上下文对象,用于SqL的分析 val sqlContext = new SQLContext(sc) /** * 1.通过format("jdbc")的方式来说明SparkSQL操作的数据来源是JDBC, * JDBC后端一般都是数据库,例如去操作MYSQL.Oracle数据库 * 2.通过DataframeReader的option方法把要访问的数据库信息传递进去, * url:代表数据库的jdbc链接的地址和具体要连接的数据库 * datable:具体要连接使用的数据库 * 3.Driver部分是SparkSQL访问数据库的具体驱动的完整包名和类名 * 4.关于JDBC的驱动jar可以使用在Spark的lib目录中,也可以在使用 * spark-submit提交的时候引入,编码和打包的时候不需要这个JDBC的jar */ val reader = sqlContext.read.format("jdbc") reader.option("url", "jdbc:mysql://localhost:3306/spark") //指定连接的数据库 reader.option("dbtable", "userinfor") //操作的表 reader.option("driver", "com.mysql.jdbc.Driver") //JDBC的驱动 reader.option("user", "root") //用户名 reader.option("password", "123456") //用户密码 /** * 在实际的企业级开发环境中,如果数据库中数据规模特别大,例如10亿条数据 * 此时如果用DB去处理的话,一般需要对数据进行多批次处理,例如分成100批 * (受限于单台Server的处理能力,)且实际的处理可能会非常复杂, * 通过传统的Java EE等技术很难或者不方便实现处理算法,此时采用sparkSQL * 获得数据库中的数据并进行分布式处理就可以非常好解决该问题, * 但是由于SparkSQL加载DB的数据需要时间,所以一般会SparkSQL和具体操作的DB之 * 间加上一个缓冲层,例如中间使用redis,可以把SparkSQL处理速度提高到原来的45倍; */ val userinforDataSourceDS = reader.load() //基于userinfor表创建Dataframe userinforDataSourceDS.show() reader.option("dbtable","scoreinfor") val scoreinforDataSourceDS = reader.load()//基于scoreinfor表创建Dataframe scoreinforDataSourceDS.show() //将两个表进行jion操作 val result = userinforDataSourceDS.rdd.map(row=>(row.getAs("name").toString,row.getInt(2))).join(scoreinforDataSourceDS.rdd.map(row=>(row.getAs("name").toString,row.getInt(2)))) //将两个表进行jion操作 val resultRDD = result.map(row=>{ val name = row._1.toString val age:java.lang.Integer = row._2._1 val score:java.lang.Integer = row._2._2 RowFactory.create(name,age,score) }) /** * 1.当Dataframe要把通过SparkSQL,core、ml等复杂操作的数据写入数据库的时候首先是权限的问题,必须确保数据库授权了当前操作SparkSQL的用户; * 2.Dataframe要写数据到DB的时候,一般都不可以直接写进去,而是要转成RDD,通过RDD写数据到DB中, */ val userscoreinforDS = sqlContext.createDataFrame(resultRDD.map(row => PersonAgeScore(row.getString(0),row.getInt(1),row.getInt(2)))) userscoreinforDS.show() userscoreinforDS.foreachPartition(row=>{ var connection:Connection = null var states:Statement = null; try { connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/spark", "root", "123456") states = connection.createStatement() while (row.hasNext){ var sqlText = "insert into userscoreinfor (name,age,score) values (" val line = row.next val name = line.getAs("name").toString val age:java.lang.Integer = line.getAs("age") val score:java.lang.Integer = line.getAs("score") sqlText += "'" + name + "'," + age + "," + score + ")" println(sqlText) states.execute(sqlText) } }catch { case e: SQLException=>{ e.printStackTrace() } }finally { if (connection != null) connection.close() } }) } }
运行结果:
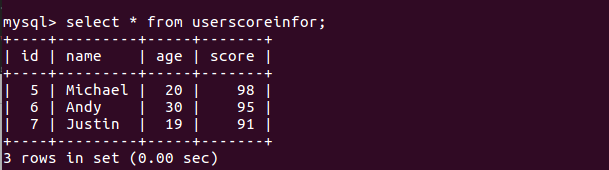
注意:在在idea上运行代码时候,遇到问题
1.Exception in thread "main" java.lang.ClassNotFoundException: com.mysql.jdbc
解决:将mysql-connector-java-5.1.40-bin.jar引入工程中
2.msyql Caused by: java.net.ConnectException: 拒绝连接 (Connection refused)
解决:数据库配置是localhost,连接应该为jdbc:mysql://localhost:3306/spark

 浙公网安备 33010602011771号
浙公网安备 33010602011771号