

面试题2
第一部分 Python基础篇
https://blog.51cto.com/u_12501506/5138726
简述解释型和编译型编程语言?
计算机不理解高级语言,任何高级语言想要被计算机运行,都必须通过转换器(解释器或编译器)转换成计算机语言。
转换方式有两种编译和解释,由此高级语言也分为编译型语言和解释型语言,主要区别在于编译型是源程序编译后可在平台上运行,解释型是在运行期间才编译会有点慢,所以前者运行速度快,后者跨平台性好
Python解释器种类以及特点?
CPython:由C语言开发的python解释器,也是标准的python解释器,是使用最广泛的python解释器。
JPython:运行在Java上的解释器。可以将python源码编译成JVM字节码,由JVM执行对应的字节码,因为可以很好的与JVM集成。
IPython:是基于Cpython之上的一个交互式解释器。
请至少列举5个 PEP8 规范(越多越好)
代码编排:
1 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
2 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
3 类和top-level函数定义之间空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
文档编排:
1 模块内容的顺序:模块说明和docstring—import—globals&constants—其他定义。其中import部分,又按标准、三方和自己编写顺序依次排放,之间空一行。


#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/05/17 10:46 # @Author : MJay_Lee # @File : tcp_server.py # @Contact : limengjiejj@hotmail.com import os import sys from tcp_server import online_user from threading import currentThread from lib import common from interface import common_interface, admin_interface, user_interface conn_pool = ThreadPoolExecutor(10) # 互斥锁为了限制多个线程同时登录一个ID时进行写操作带来的误区 mutex = Lock() # 之所以把mutex放在online_user.py文件中,是因为避免文件的交叉引用 online_user.mutex = mutex def foo1 def foo2
2 不要在一句import中多个库,比如import os, sys不推荐。
3 如果采用from XX import XX引用库,可以省略‘module.’,都是可能出现命名冲突,这时就要采用import XX。
from myclass import MyClass from foo.bar.yourclass import YourClass # 如果和本地名字有冲突: import myclass import foo.bar.yourclass
空格的使用:
(总体原则 避免不必要的空格)
注释:
(总体原则 英文 简明)
- 与代码自相矛盾的注释比没注释更差。修改代码时要优先更新注释!
- 注释是完整的句子。如果注释是断句,首字母应该大写,除非它是小写字母开头的标识符(永远不要修改标识符的大小写)。
- 如果注释很短,可以省略末尾的句号。注释块通常由一个或多个段落组成。段落由完整的句子构成且每个句子应该以点号(后面要有两个空格)结束,并注意断词和空格。
- 非英语国家的程序员请用英语书写你的注释,除非你120%确信代码永远不会被不懂你的语言的人阅读。
- 注释块通常应用在代码前,并和这些代码有同样的缩进。每行以 '# '(除非它是注释内的缩进文本,注意#后面有空格)。注释块内的段落用仅包含单个 '#' 的行分割。
- 慎用行内注释(Inline Comments) 节俭使用行内注释。 行内注释是和语句在同一行,至少用两个空格和语句分开。行内注释不是必需的,重复罗嗦会使人分心。不要这样做:
# 正确写法 x = x + 1 # Compensate for border # 错误写法 x = x + 1 # do nothing
命名:
(总体原则,新编代码必须按下面命名风格进行,现有库的编码尽量保持风格。)
- b(单个小写字母)
- B(单个大写字母)
- lowercase(小写串)
- lower_case_with_underscores(带下划线的小写)
- UPPERCASE(大写串)
- UPPER_CASE_WITH_UNDERSCORES(带下划线的大写串)
- CapitalizedWords(首字母大写的单词串或驼峰缩写)
- 类的方法第一个参数必须是self,而静态方法第一个参数必须是cls。
- mixedCase(混合大小写,第一个单词是小写)
- Capitalized_Words_With_Underscores(带下划线,首字母大写,丑陋)
编码建议:
1 编码中考虑到其他python实现的效率等问题,比如运算符‘+’在CPython(Python)中效率很高,都是Jython中却非常低,所以应该采用.join()的方式。
2 尽可能使用‘is’‘is not’取代‘==’,比如if x is not None 要优于if x。
3 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。
4 异常中不要使用裸露的except,except后跟具体的exceptions。
5 异常中try的代码尽可能少。比如:
try: value = collection[key] except KeyError: return key_not_found(key) else: return handle_value(value) 要优于 try: return handle_value(collection[key]) except KeyError: # Will also catch KeyError raised by handle_value() return key_not_found(key)
6 使用startswith() and endswith()代替切片进行序列前缀或后缀的检查。
7 使用isinstance()比较对象的类型。比如
Yes: if isinstance(obj, int): 优于 No: if type(obj) is type(1):
8 判断序列空或不空,有如下规则
Yes: if not seq: if seq:
优于
No: if len(seq) if not len(seq)
9 字符串不要以空格收尾。
10 二进制数据判断使用 if boolvalue的方式。
通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011”
v2 = int(v,base = 2)
十进制转换成二进制:v = 18
v10 = bin(v)
八进制转换成十进制:v = “011”
v8 = int(v,base = 8)
十进制转换成八进制:v = 30
v10 = oct(v)
十六进制转换成十进制:v = “0x12”
v16 = int(v,base = 16)
十进制转换成十六进制:v = 87
v10 = hex(v)
python递归的最大层数?
Python的最大递归层数是可以设置的,默认的在window上的最大递归层数是 998。
可以通过sys.setrecursionlimit()进行设置,但是一般默认不会超过3925-3929这个范围。
求结果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
a 1 b 2 c False d True
求结果:加减乘除 > 比较 > not and or。(绝招:加括号)
v1 = 1 or 3
# 1
v2 = 1 and 3
# 3
v3 = 0 and 2 and 1 # 0
v4 = 0 and 2 or 1 # 1
v5 = 0 and 2 or 1 or 4 # 1
v6 = 0 or False and 1 # False
ascii、unicode、utf-8、gbk 区别?
它们本质上都是字符与二进制的关系对照表,都维护这自己的一套规则,使用的不同的编码保存文件时,硬盘的文件中存储的0/1的规则也是不同的。以某个编码的形式进行保存文件,以后就要以这种编码去打开这个文件。否则就会出现乱码。
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对unicode字符集的码位进行压缩了)
字符串类型(str),在程序中用于表示文字信息,本质上是unicode编码中的二进制。
字节类型(bytes)可表示文字信息,本质上是utf-8/gbk等编码的二进制(对unicode进行压缩,方便文件存储和网络传输。)
默认Python解释器是以UTF-8编码的形式打开文件。
如果想要修改Python的默认解释器编码:# -*- coding:gbk -*-
字节码和机器码的区别?
机器码是电脑 CPU 直接读取运行的机器指令,运行速度最快,但是非常晦涩难懂,也比较难编写
字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
三元运算规则以及应用场景?
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值格式
结果 = 条件成立取值 if 条件 else 条件不成立取值
列举常见的内置函数?
map()
map()根据提供的function(函数)对指定的iterable(一个或多个序列可迭代对象( 列表 元组 字典))做映射。
map()函数的语法是:
map(function,iterable,……)
它的结果是返回值一个列表(注意python2是列表,python3是迭代器)
这个函数的意义是将function应用于iterable的每一个元素,结果以列表的形式返回((注意python2是列表,python3是迭代器))
>>> def square(x) : # 计算平方数 ... return x ** 2>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 [1, 4, 9, 16, 25] >>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25]
reduce()
reduce() 函数会对参数序列中元素进行累积。
reduce() 函数语法:
reduce(function, iterable[, initializer])
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
Python3.x reduce() 已经被移到 functools 模块里,如果我们要使用,需要引入 functools 模块来调用 reduce() 函数:
from functools import reduce def add(x, y) : # 两数相加 return x + y sum1 = reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5 sum2 = reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数 print(sum1) # 15 print(sum2) # 15
filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
语法:
filter(function, iterable)
filter()接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
Python2.7 返回列表,Python3.x 返回迭代器对象
# 过滤列表中奇数
def is_odd(n): return n % 2 == 1 newlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) print(newlist) # [1, 3, 5, 7, 9]
enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
语法:
enumerate(sequence, [start=0])
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置的值。
>>> seq = ['one', 'two', 'three'] >>> for i, element in enumerate(seq): ... print i, element ... 0 one 1 two 2 three
zip()
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。利用 * 号操作符,可以将元组解压为列表。
zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换。
语法:
zip([iterable, ...])
>>> a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象 >>> zipped <zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表 [(1, 4), (2, 5), (3, 6)] >>> list(zip(a,c)) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式 >>> list(a1) [1, 2, 3] >>> list(a2) [4, 5, 6] >>>
hasattr() getattr() setattr()
hasattr() 函数用于判断对象是否包含对应的属性。如果对象有该属性返回 True,否则返回 False。
语法:
hasattr(object, name)
class Coordinate: x = 10 y = -5 z = 0 point1 = Coordinate() print(hasattr(point1, 'x'))print(hasattr(point1, 'no')) # 没有该属性
。。。。。。。
True
False
getattr() 函数用于返回一个对象属性值。
语法:
getattr(object, name[, default])
>>>class A(object): ... bar = 1 ... >>> a = A() >>> getattr(a, 'bar') # 获取属性 bar 值 1
>>> getattr(a, 'bar2') # 属性 bar2 不存在,触发异常 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'A' object has no attribute 'bar2'
>>> getattr(a, 'bar2', 3) # 属性 bar2 不存在,但设置了默认值 3 >>>
setattr() 函数对应函数 getattr(),用于设置属性值,该属性不一定是存在的。
语法:
setattr(object, name, value)
>>>class A(object): ... bar = 1 ... >>> a = A() >>> getattr(a, 'bar') # 获取属性 bar 值 1 >>> setattr(a, 'bar', 5) # 设置属性 bar 值 >>> a.bar 5
xrange和range的区别?
range: range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列。注意这里是生成一个序列。
xrange的用法与range相同,即xrange([start,] stop[, step])根据start与stop指定的范围以及step设定的步长,他所不同的是xrange并不是生成序列,而是作为一个生成器。即他的数据生成一个取出一个。
所以相对来说,xrange比range性能优化很多,因为他不需要一下子开辟一块很大的内存,特别是数据量比较大的时候。
注意:
1、xrange和range这两个基本是使用在循环的时候。
2、 当需要输出一个列表的时候,就必须要使用range了。
文件操作时:xreadlines和readlines的区别?
xreadlines返回的是一个生成器类型,python3已经没有改方法.(直接使用for循环迭代文件对象)
with open(path, 'rb') as infile: for line in infile: print(line)
readlines返回的是一个列表: [‘第一行\n’, ‘第二行\n’, ‘第三行’]
with open(path, 'rb') as infile: content = infile.readlines() print(content)
字符串、列表、元组、字典每个常用的5个方法?
字符串
startswith() 判断字符串是否以 XX 开头?得到一个布尔值
endswith() 判断字符串是否以 XX 结尾?得到一个布尔值
isdecimal() 判断字符串是否为十进制数?得到一个布尔值
strip() 去除字符串两边的 空格、换行符、制表符,得到一个新字符串
split() 字符串切割,得到一个列表
format() 格式化字符串,得到新的字符串
join() 字符串拼接,得到一个新的字符串
v1.encode("gbk") 字符串类型转换为字节类型
v1.decode("utf-8") 字节转为字符串类型
replace() 字符串内容替换,得到一个新的字符串,原变量还是不变
name = "llppll"
newname = name.replace("l","p")
lower()/upper() 字符串变小写/大写,得到一个新字符串
列表
append 追加,在原列表中尾部追加值
extend 批量追加,将一个列表中的元素逐一添加另外一个列表
insert 插入,在原列表的指定索引位置插入值
remove 在原列表中根据值删除(从左到右找到第一个删除)【慎用,里面没有会报错】
pop 在原列表中根据索引踢出某个元素(根据索引位置删除)
clear 清空原列表
index 根据值获取索引
sort 列表元素排序
字符串排序的本质?unicode码点
注意:排序时内部元素无法进行比较时,程序会报错(尽量数据类型统一)。
reverse 反转原列表
字典
get() 获取值
update() 更新字典键值对
setdefault() 设置值
keys() 获取所有的键
values() 获取所有的值
items() 获取所有的键值
pop() 移除指定键值对
popitem() 按照顺序移除(后进先出)
py3.6后,popitem移除最后的值
py3.6之前,popitem随机删除
lambda表达式格式以及应用场景?
lambda表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
lambda 参数:函数体 (只支持单行代码) 。 将函数体返回
应用在函数式编程中 应用在闭包中。
pass的作用?
1、空语句 do nothing
2、保证格式完整,保证语义完整
3、占位语句
*arg和**kwarg作用
# 定义处用( 收集参数) # *arg 普通 收集参数 : 收集多余没人要的普通实参 # **kwargs 关键字 收集参数: 收集多余没人要的关键字实参 # 调用处用 # 聚合打散作用
形式参数 *args, **kwargs 可接任意个参数
*args:收集位置参数 输出元组格式
**kwargs:收集关键字参数 输出字典格式
定义处:
def f1(*args,**kwargs): print(args) print(kwargs) f1('a','b','c',i=3,j=4) ('a', 'b', 'c') {'j': 4, 'i': 3}
调用处:
def test_args_kwargs(arg1, arg2, arg3): print("arg1:", arg1) print("arg2:", arg2) print("arg3:", arg3) # args调用 args = ("two", 3, 5) test_args_kwargs(*args) #result: arg1: two arg2: 3 arg3: 5
# kwargs调用
kwargs = {"arg3": 3, "arg2": "two", "arg1": 5} test_args_kwargs(**kwargs) #result arg1: 5 arg2: two arg3: 3
Python的可变类型和不可变类型?
不可变数据类型更改后地址发生改变,可变数据类型更改地址不发生改变;
可变数据类型没有开辟新的内存空间,而不可变数据类型需要开辟新的内存空间;
可变类型:列表,字典,集合
不可变类型:字符串,元组,整数
Python 字典(Dictionary) fromkeys()方法
语法:
dict.fromkeys(seq[, value])
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值默认为 None。。
求结果:fromkeys的append和赋值修改
v = dict.fromkeys(['k1','k2'],[])
v['k2'].append(666)
print(v)
v['k1'] = 777
print(v)
结果:
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}
结论:fromkeys方法并不适用来创建多个对象,因为我如果改变了某一个对象中的某个属性,那么其余对象都会被改变。
但如果就想要呈现这种(连坐的)效果,那么可以这个方法。
一行代码实现9*9乘法表
步骤一:生成每一行中的公式列表
[['{}*{}={}'.format(i,j,i*j) for j in range(1,i+1)] for i in range(1,10)]
输出:
[['1*1=1'], ['2*1=2', '2*2=4'], ['3*1=3', '3*2=6', '3*3=9'], ['4*1=4', '4*2=8', '4*3=12', '4*4=16'], ['5*1=5', '5*2=10', '5*3=15', '5*4=20', '5*5=25'], ['6*1=6', '6*2=12', '6*3=18', '6*4=24', '6*5=30', '6*6=36'], ['7*1=7', '7*2=14', '7*3=21', '7*4=28', '7*5=35', '7*6=42', '7*7=49'], ['8*1=8', '8*2=16', '8*3=24', '8*4=32', '8*5=40', '8*6=48', '8*7=56', '8*8=64'], ['9*1=9', '9*2=18', '9*3=27', '9*4=36', '9*5=45', '9*6=54', '9*7=63', '9*8=72', '9*9=81']]
步骤二:行中每个公式之间用空格拼接
[' '.join(['{}*{}={}'.format(i,j,i*j) for j in range(1,i+1)]) for i in range(1,10)]
输出:
['1*1=1', '2*1=2 2*2=4', '3*1=3 3*2=6 3*3=9', '4*1=4 4*2=8 4*3=12 4*4=16', '5*1=5 5*2=10 5*3=15 5*4=20 5*5=25', '6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36', '7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49', '8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64', '9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81']
步骤三:行与行之间用换行符拼接
'\n'.join([' '.join(['{}*{}={}'.format(i,j,i*j) for j in range(1,i+1)]) for i in range(1,10)])
输出:
'1*1=1\n2*1=2 2*2=4\n3*1=3 3*2=6 3*3=9\n4*1=4 4*2=8 4*3=12 4*4=16\n5*1=5 5*2=10 5*3=15 5*4=20 5*5=25\n6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36\n7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49\n8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64\n9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81'
最后print打印输出
print('\n'.join([' '.join(['{}*{}={}'.format(i,j,i*j) for j in range(1,i+1)]) for i in range(1,10)]))
输出:
1*1=1 2*1=2 2*2=4 3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 4*3=12 4*4=16 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
如何安装第三方模块?以及用过哪些第三方模块?
pip(最常用)安装
使用pip去安装第三方模块也非常简单,只需要在自己终端执行:pip install 模块名称
默认安装的是最新的版本,如果想要指定版本:
pip3 install 模块名称==版本
pip默认是去 https://pypi.org 去下载第三方模块(本质上就是别人写好的py代码),国外的网站速度会比较慢,为了加速可以使用国内的豆瓣源 阿里云
源码安装
如果要安装的模块在pypi.org中不存在 或 因特殊原因无法通过pip install 安装时,可以直接下载源码,然后基于源码安装
-
下载requests源码(压缩包zip、tar、tar.gz)并解压。
下载地址:https://pypi.org/project/requests/#files
-
进入目录
-
执行编译和安装命令
python3 setup.py build
python3 setup.py install
wheel安装
内置模块:
os (操作文件系统的模块,它是Python程序与操作系统进行交互的接口 对目录和文件的一般常用操作)
sys (负责程序与 Python 解释器的交互,并提供了一系列的属性和方法,用于操控 Python 运行时的环境.version(解释器版本) .path(模块导入路径))
shutil (作为os模块的补充,提供了复制、移动、删除、压缩、解压等操作)
random (生成随机数)
xml (解析xml 即序列化和反序列化)
configparser (用来读取配置文件的包)
time
datetime
re
json
hashlib (哈希算法)
至少列举8个常用模块都有那些?
1、Requests模块
这是一个Python中的第三方模块,通常在需要对网页进行请求的时候使用,由urllib3和httplib支持,当我们使用这个模块时,通常有两种方式请求方法,分别是:get()方法和post()方法,两种方法的不同就在于是否需要参数,如果想要将参数传递到url链接中的时候,需要使用到post()方法带上网页的请求头信息然后再对这个方法进行调用。
2、Django模块
之前说的最多的,它是web开发中的一个框架,主要的优点是开发的速度快,并且可扩展性强,在Python中,使用它可以和其他的框架连接起来,并且它还具备了其他给诺基亚的一些复杂的开发特性,能够制作良好的企业级网站。
3、BeautifulSoup模块
当我们去获取一个web的时候,这个是一个不错的模块,在这个模块中,提供了一些简单的方法,可以用于导航、搜索和修改解析数据,如果要将传入的文档转换为Unicode和传出的文档转换为UTF-8时,不用去考虑编码,因为在Beautiful Soup是无法检测编码,如果是在这种情况下,我们需要指定一个原始的编码,然后再使用Beautiful Soup进行解析,这个时候不管给它什么都学,它都可以进行遍历。
4、Selenium模块
Selenium模块是用来实现网站的自动化的,可以将我们自己开发的网站或制作一个机器人将与其他网站互动。还可以使用模拟的方式进行一系列的操作。
5、Pandas模块
Pandas模块时候对大量的数据进行处理,通过那规范的五个步骤对数据进行处理和分析,处理数据的五个步骤为:装载、准备、操作、建模和分析。
Flask Scrapy numpy pillow-python pymysql pip
re的match和search区别?
match只找字符串的开始位置(从0位置开始匹配 如果都匹配成功返回),
而search是全盘查找直到找到一个匹配
什么是正则的贪婪匹配?
1、贪婪匹配
总是尝试匹配尽可能多的字符
2、非贪婪匹配
是尝试匹配尽可能少的字符
import re secret_code = 'hadkfalifexxIxxfasdjifja134xxlovexx23345sdfxxyouxx8dfse' b = re.findall('xx.*xx',secret_code) # 贪婪匹配 print (b) # ['xxIxxfasdjifja134xxlovexx23345sdfxxyouxx'] c = re.findall('xx.*?xx',secret_code) # 非贪婪匹配 print(c) # ['xxIxx', 'xxlovexx', 'xxyouxx']
贪婪格式:xx.*xx
非贪婪格式:xx.*?xx
区别重点在:.* 和 .*?
求结果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
In [32]: a = [i % 2 for i in range(10)] In [33]: a Out[33]: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
In [34]: b = (i%2 for i in range(10)) In [35]: b Out[35]: <generator object <genexpr> at 0x000000000552E938> # 发生器对象
如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
In [56]: a = '1,2,3' In [57]: list(a) Out[57]: ['1', ',', '2', ',', '3']
如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
[ i*i for i in range(1,11)]
一行代码实现删除列表中重复的值 ?
In [75]: a = [1,2,3,4,5,1,2,3,4,5] In [76]: set(a) Out[76]: {1, 2, 3, 4, 5}
如何在函数中设置一个全局变量 ?
global aaa
logging模块的作用?以及应用场景?
可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息;
print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据;logging则可以由开发者决定将信息输出到什么地方,以及怎么输出;
请用代码简答实现stack
class Stack(object): def __init__(self): self.stack = [] def push(self, value): # 进栈 self.stack.append(value) def pop(self): #出栈 if self.stack: self.stack.pop() else: raise LookupError(‘stack is empty!‘) def is_empty(self): # 如果栈为空 return bool(self.stack) def top(self): #取出目前stack中最新的元素 return self.stack[-1]
常用字符串格式化哪几种?
In [88]: "hello %s"%('word') Out[88]: 'hello word' In [89]: 'hellow {}'.format('word') Out[89]: 'hellow word'
简述 生成器、迭代器、可迭代对象 以及应用场景?
什么是迭代器 dir(数据) => 查看该数据的内部成员 # 官方说法 具有 __iter__() 和 __next__() 两个方法的是迭代器 具有 __iter__() 可迭代对象 # 理解说法 迭代器: 迭代数据的 工具 可迭代对象:可以迭代的 数据 可迭代对象 =>(转变) 迭代器 (可迭代对象到迭代器的过程) 把不能够直接通过next获取的数据 =>(转变) 可以直接被next获取数据 生成器:
本质就是迭代器,可以自定义迭代的逻辑 创建方式两种 (1) 生成器表达式(推导式) a = (i for i in range(10)) # 返回的是生成器对象 (2) 生成器函数 (含有yield 关键字)
用Python实现一个二分查找的函数。
# 二分查找:折半查找从有序列表的初始候选区li[0:n]开始, # 通过对待查找的值与候选区中间值的⽐较,可以使候选区减少⼀半。 def bin_search(data_set, val): left = 0 right = len(data_set) - 1 while left <= right: # 候选区有值 mid = (left + right) // 2 if data_set[mid] == val: return mid elif data_set[mid] > val: # 带查找的值在mid左侧 right = mid - 1 else: # li[mid] < val 带查找的值在mid右侧 left = mid + 1 else: return None
谈谈你对闭包的理解?
# 闭包: # (1)互相嵌套的两个函数,内函数使用了外函数的局部变量 # (2)外函数把内函数返回 出来的过程,是闭包,内函数是闭包函数;
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。
但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
os和sys模块的作用?
sys模块主要是用于提供对python解释器相关的操作
OS模块是Python标准库中的一个用于访问操作系统功能的模块,使用OS模块中提供的接口,可以实现跨平台访问
如何使用python删除一个文件?
os.remove(path)
谈谈你对面向对象的理解?
面向对象就是将一些零散的具有相同功能的属性方法通过类封装起来,实现模块化
Python面向对象中的继承有什么特点?
在继承中基类的构造(init()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。有别于C#
在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数
Python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
面向对象深度优先和广度优先是什么?
区别主要体现在继承上
Python2.x 找父类初始化函数时, 经典类 按深度优先查找 新式类 按广度优先查找(正式支持是2.3)
Python3.x 找父类初始化函数时, 新式类 都是广度优先查找
在子类继承多个父类时,属性查找方式分深度优先和广度优先两种。
当类是经典类时,多继承情况下,在要查找属性不存在时,会按照深度优先方式查找下去。
当类是新式类时,多继承情况下,在要查找属性不存在时,会按照广度优先方式查找下去
对于算法来说 无非就是时间换空间 空间换时间
- 深度优先不需要记住所有的节点, 所以占用空间小, 而广度优先需要先记录所有的节点占用空间大
- 深度优先有回溯的操作(没有路走了需要回头)所以相对而言时间会长一点
深度优先采用的是堆栈的形式, 即先进后出
广度优先则采用的是队列的形式, 即先进先出
面向对象中super的作用?
super 是个类,调用 super() 的时候,实际上是实例化了一个 super 类super 包含了两个非常重要的信息: 一个 MRO表 以及 MRO 中的一个类
super()的作用不是查找父类,而是找MRO列表的上一个类(C3算法)
super()和父类没有任何实质性的关系,只是有时候能调用到父类而已。
在单继承的情况下,super()永远调用的是父类/父对象
super()多用于菱形继承
格式: super().方法() # python3的格式
是否使用过functools中的函数?其作用是什么?
Python的functools模块用以为可调用对象(callable objects)定义高阶函数或操作。
简单地说,就是基于已有的函数定义新的函数。所谓高阶函数,就是以函数作为输入参数,返回也是函数。
通常情况下,只要是可以被当做函数调用的对象就是这个模块的目标。
列举面向对象中带双下划线的特殊方法,如:__new__、__init__
__init__初始化魔术对象,当一个对象被实例化时自动触发
__new__ 当一个对象被实例化前自动触发,通过传递参数判断对象是否被创建或其他
__del__当一个对象没有任何引用是被触发,回收内存
__call__将对象当作函数调用时触发
如何判断是函数还是方法?
函数:
函数是封装了一些独立的功能,可以直接调用,python内置了许多函数,同时可以自建函数来使用。
方法:
方法和函数类似,同样封装了独立的功能,但是方法是需要通过对象来调用的,表示针对这个对象要做的操作,使用时采用点方法。
静态方法和类方法区别?
类中不仅可以有 methods,还可以有变量,这些变量称为类属性
类中的方法分为3类:
1. 实例方法 instance method
不使用装饰器
类中的所有方法,如果第一个参数是 self,就是 instance(实例) method, self 是创建的类实例,实例方法与实例即对象相关。
(self 可以改成别的名称,但使用 self 是convention习惯,self 是类实例, ),
2. 类方法 class method
使用装饰器@classmethod 装饰
类方法的第一个参数总是 cls。如果方法需要类的信息,用 @classmethod 对其进行装饰, 类方法经常被用作 factory,例如如下代码中的 hardcover 和 paperback 两个 class method 方法就是可用于创建对象的 factory。
类方法通过@classmethod装饰器实现,类方法和普通方法的区别是, 类方法只能访问类变量,不能访问实例变量
(cls 可以改成别的名称,但使用 cls 是convention)
3. 静态方法 static method
使用 @staticmethod 装饰
静态方法并不是真正意义上的类方法,它只是一个被放到类里的函数而已。
尽管如此,仍然称之为方法,但它没有关于 class 或 object 的任何信息,所以它实际上是一个独立的函数,只是被放到了类里,静态方法既没有 self 也没有 cls 参数 。(静态方法可以访问类属性 可以通过对象和类来访问,例如 Book.TYPES)
静态方法通常用于组织代码,例如如果认为将某个函数放到某个类里,整体代码会因此更符合逻辑,于是可以将这个函数变成该类的静态方法。所以如果需要在类里放一个函数进去,此函数不会用到任何关于类或实例的信息,那么就可以用 @staticmethod 对其进行装饰。
静态方法中只能调用静态成员或者方法,不能调用非静态方法或者非静态成员(如果静态方法想调用非静态方法或者非静态成员需要先实例化即先new一个),而非静态方法既可以调用静态成员或者方法又可以调用其他的非静态成员或者方法。
三种方法中,实例方法和类方法用得最多,静态方法不常用。
列举面向对象中的特殊成员以及应用场景
1. __doc__ 描述类的信息

class Foo(object): # 单引号和双引号都可以 """这里描述类的信息""" def func(self): pass print(Foo.__doc__)
显示的结果:
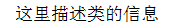
2. __call__ 对象后面加括号,触发执行
# __call__方法的执行是由对象加括号触发的,即:对象()或者 类()()
class Foo(object):
def __call__(self, *args, **kwargs):
print("running call", args, kwargs)
foo = Foo()
foo(1, 2, 3, name = "UserPython")
Foo()(1, 2, 3, name = "UserPython")
显示的结果:
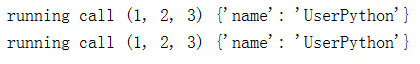
3. __dict__ 查看类或对象中的所有成员
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
foo = Foo("UserPython", 17)
print(Foo.__dict__) #打印类里的所有属性,不包括实例属性
print(foo.__dict__) #打印所有实例属性,不包括类属性
显示的结果:
{'__weakref__': <attribute '__weakref__' of 'Foo' objects>, '__init__': <function Foo.__init__ at 0x0000000000BB0730>, '__dict__': <attribute '__dict__' of 'Foo' objects>, '__module__': '__main__', '__doc__': None}
{'name': 'UserPython', 'age': 17}
4. __str__ 如果一个类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return "<obj:%s>" % self.name
foo = Foo("UserPython", 17)
print(foo) #>>><obj:UserPython>
显示的效果为:
<obj:UserPython>
5. __getitem__ 、 __setitem__ 、__delitem__ 用于索引操作,如字典。分别表示获取、设置、删除数据
class Foo(object):
def __getitem__(self, key):
print("__getitem__", key)
def __setitem__(self, key, value):
print("__setitem__", key, value)
def __delitem__(self, key):
print("__delitem__", key)
foo = Foo()
foo["name"] = "UserPython" #>>>__setitem__ name UserPython 触发__setitem__
foo["name"] #>>>__getitem__ name 触发__getitem__
del foo["name"] #>>>__delitem__ name 触发__delitem__
显示的结果为:

6. __new__ 、__metaclass__
class Foo(object):
def __init__(self, name):
self.name = name
foo = Foo("UserPython")
'''''
上述代码中,foo是通过Foo类实例化的对象,其实,不仅foo是一个对象,Foo类本身也是一个对象,因为在Python中一切事物都是对象。
如果按照一切事物都是对象的理论:foo对象时通过执行Foo类的构造方法创建,那么Foo类对象应该也是通过执行某个类的构造方法创建。
'''
print(type(foo))
print(type(Foo))
# 所以,foo对象是Foo类的一个实例,Foo类对象是type类的一个实例,即:Foo类对象是通过type类的构造方法创建。那么,创建类就可以有两种方式了
显示的结果为:

# 普通方式
class Foo(object):
def func(self):
print("hello UserPython")
# 特殊方式
def func(self):
print("hello %s" % self.name)
def __init__(self, name, age): #构造方法
self.name = name
self.age = age
# 创建了一个type类,然后用type类实例化了一个Foo类,由于Foo本身是一个类,所以Foo又实例化了一个对象foo
Foo = type('Foo', (object, ), {"func" : func, "__init__" : __init__})
foo = Foo("UserPython", 19)
foo.func()
print(type(Foo))

显示的结果为:

1、2、3、4、5 能组成多少个互不相同且无重复的三位数
ls = [1,2,3,4,5]
for i in ls:
for j in ls:
for m in ls:
if i != j and i != m and j != m:
print(i,j,m)
什么是反射?以及应用场景?
是指程序可以访问、检测和修改它本身状态或行为的一种能力。
在程序运行时可以获取对象类型定义信息,例如,Python中的type(obj)将返回obj对象的类型,这种获取对象的type、attribute或者method的能力称为反射。
通过反射机制,可以用来检查对象里的某个方法,或某个变量是否存在。
也就是可以通过字符串映射对象的方法或者属性。
Python反射常用的内置函数:(这些函数都是通过反射机制执行)
type(obj):返回对象类型
isinstance(object, classinfo):判断一个对象是否是一个已知的类型,类似 type()
callable(obj):对象是否可以被调用
dir([obj]):返回obj属性列表
getattr(obj, attr):返回对象属性值
hasattr(obj, attr):判断某个函数或者变量是否存在
setattr(obj, attr, val):给模块添加属性(函数或者变量)
delattr(obj, attr):删除模块中某个变量或者函数
反射的应用场景:
动态调用
从前面举的例子中,我们了解到可以通过字符串来获取对象的属性(getattr()),这是非常有用的一个功能。比如,一个类中有很多方法,它们提供不同的服务,通过输入的参数来判断执行某个方法,一般的使用如下写法:
class MyService(): def service1(self): print("service1") def service2(self): print("service2") def service3(self): print("service3") if __name__ == '__main__': Ser = MyService() s = input("请输入您想要的服务: ").strip() if s == "service1": Ser.service1() elif s == "service2": Ser.service2() elif s == "service3": Ser.service3() else: print("error!")
如果函数比较少这样写没有太大问题,如果有很多,这样写就比较复杂了,需要写大量else语句,可以使用反射机制来写:
if __name__ == '__main__': Ser = MyService() s = input("请输入您想要的服务: ").strip() if hasattr(Ser, s): func = getattr(Ser, s) func() else: print("error!")
这样是不是简洁了很多,上面的例子中,通过反射,将字符串变成了函数,实现了对对象方法的动态调用。
动态属性设置
可以通过setattr()方法进行动态属性设置,在使用scapy库构造报文时,我们需要设置某些报文字段,然而网络协议的报文字段很多,在需要设置大量字段时,一个一个的赋值就很麻烦:
>>> ls(IP) version : BitField (4 bits) = ('4') ihl : BitField (4 bits) = ('None') tos : XByteField = ('0') len : ShortField = ('None') id : ShortField = ('1') flags : FlagsField = ('<Flag 0 ()>') frag : BitField (13 bits) = ('0') ttl : ByteField = ('64') proto : ByteEnumField = ('0') chksum : XShortField = ('None') src : SourceIPField = ('None') dst : DestIPField = ('None') options : PacketListField = ('[]')
可以使用setattr()方法来赋值:
from scapy.all import * fields = {"version":4, "src":"192.168.0.1","dst":"192.168.10.1"} ip = IP() for key, val in fields.items(): setattr(ip, key, val)
metaclass作用?以及应用场景?
什么是metaclass?
MetaClass元类,本质也是一个类,但和普通类的用法不同,元类它可以对普通类内部的定义(包括类属性和类方法)进行动态的修改。可以这么说,使用元类的主要目的就是为了实现在创建普通类时,能够动态地改变类中定义的属性或者方法。
举个例子:根据实际场景的需要,我们要为多个类添加一个 name 属性和一个 say() 方法。显然有多种方法可以实现,但其中一种方法就是使用 MetaClass 元类。
metaclass是Python2的写法,代表指定该类的元类。
Python3中对应的写法是class 要定义的类名(metaclass=元类名)
用法:
如果在创建类时,想用 MetaClass 元类动态地修改内部的属性或者方法,则普通类的创建过程将变得复杂:先创建 MetaClass 元类,然后用元类去创建类(定义普通类时指定元类),最后使用该类的实例化对象实现功能。
如果想把一个类设计成 MetaClass 元类,其必须符合以下条件:
- 必须显式继承自 type 类;
- 类中需要定义并实现 __new__() 方法,该方法一定要返回该类的一个实例对象,因为在使用元类创建类时,该 __new__() 方法会自动被执行,用来修改新建的类。
定义一个 MetaClass 元类:
#定义一个元类 class FirstMetaClass(type): # cls代表动态修改的类 # name代表动态修改的类名 # bases代表被动态修改的类的所有父类 # attr代表被动态修改的类的所有属性、方法组成的字典 def __new__(cls, name, bases, attrs): # 动态为该类添加一个name属性 attrs['name'] = "C语言中文网" attrs['say'] = lambda self: print("调用 say() 实例方法") return super().__new__(cls,name,bases,attrs)
# 此程序中,首先可以断定 FirstMetaClass 是一个类。其次,由于该类继承自 type 类,并且内部实现了 __new__() 方法,因此可以断定 FirstMetaCLass 是一个元类。
可以看到,在这个元类的 __new__() 方法中,手动添加了一个 name 属性和 say() 方法。这意味着,通过 FirstMetaClass 元类创建的类,会额外添加 name 属性和 say() 方法。
通过 FirstMetaClass 元类创建的类:
# CLanguage通过元类创建的类 # 定义类时,指定元类 class CLanguage(object,metaclass=FirstMetaClass): pass clangs = CLanguage() print(clangs.name) clangs.say()
# 可以看到,在创建类时,通过在标注父类的同时指定元类(格式为metaclass=元类名),
# 则当 Python 解释器在创建这该类时,FirstMetaClass 元类中的 __new__ 方法就会被调用,从而实现动态修改类属性或者类方法的目的。
输出结果为:
C语言中文网
调用 say() 实例方法
显然,FirstMetaClass 元类的 __new__() 方法动态地为 Clanguage 类添加了 name 属性和 say() 方法,因此,即便该类在定义时是空类,它也依然有 name 属性和 say() 方法。
对于 MetaClass 元类,它多用于创建 API
元类是生成类的工厂,就像类是生成对象实例的工厂。
在Python中所有类的默认元类是type,如果需要自定义类的生成方式,例如给类添加特定的属性,那么就需要替换默认元类为你自己编写的元类,此时就要用到metaclass语法。
一个重要的使用场景:
就是ORM框架,因为数据库模型类的编写者是无法预知这个类可能有哪些字段的,所以必须要利用元类动态地生成这个类
#一、首先定义Field类,它负责保存数据库表的字段名和字段类型 class Field(object): def __init__(self, name, column_type): self.name = name self.colmun_type = column_type def __str__(self): return '<%s:%s>' % (self.__class__.__name__, self.name) class StringField(Field): def __init__(self, name): super().__init__(name, 'varchar(100)') class IntegerField(Field): def __init__(self, name): super().__init__(name, 'bigint') #二、定义元类,控制Model对象的创建 class ModelMetaClass(type): def __new__(cls, name, bases, attrs): if name == 'Model': return super().__new__(cls, name, bases, attrs) mappings = dict() for k,v in attrs.items(): #保持类属性和列的映射关系到mappings字典 if isinstance(v,Field): print('Found mapping:%s==>%s' % (k, v)) mappings[k] = v for k in mappings.keys(): #将类属性移除,是定义的类字段不污染User类属性,只在实例中可以访问这些key attrs.pop(k) attrs['__table__'] = name.lower() #假设表名为类名的小写,创建类时添加一个__table__属性 attrs['__mappings__'] = mappings #保持属性和列的关系映射,创建类时添加一个__mappings__属性 return super().__new__(cls, name, bases, attrs) #三、Model基类 class Model(dict, metaclass=ModelMetaClass): def __init__(self, **kwargs): super().__init__(**kwargs) def __getattr__(self, key): try: return self[key] except KeyError: raise AttributeError("'Model' object has no attribute '%s'" % key) def __setattr__(self, key, value): self[key] = value def save(self): fields = [] params = [] args = [] for k,v in self.__mappings__.items(): fields.append(v.name) params.append('?') args.append(getattr(self,k,None)) sql = 'insert into %s (%s) values (%s)' % (self.__table__,','.join(fields),','.join(params)) print('SQL:%s' % sql) print('ARGS:%s' % str(args)) #我们想创建类似Django的ORM,只要定义字段就可以实现对数据库表和字段的操作 #最后、我们使用定义好的ORM接口,使用起来非常简单 class User(Model): id = IntegerField('id') name = StringField('username') email = StringField('email') password = StringField('password') user = User(id=1,name='Job',email='job@test.com',password='pw') user.save() #输出 #Found mapping:password==><StringField:password> #Found mapping:id==><IntegerField:id> #Found mapping:email==><StringField:email> #Found mapping:name==><StringField:username> #SQL:insert into user (email,id,password,username) values (?,?,?,?) #ARGS:['job@test.com', 1, 'pw', 'Job']
super()
super是用来调用父类的一个方法,(调用父类就涉及到了继承)
super() 是用来解决多重继承问题的:直接用 类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表(C3算法), 其实也就是继承父类方法时的顺序表。
用尽量多的方法实现单例模式。
什么是单例模式?
# 单例(态)模式 : 这个类无论实例化多少次,都有且只有一个对象
所谓单例就是所有引用(实例、对象) 拥有相同的状态(属性)和行为(方法) 同一个类的 所有实例天然拥有相同的行为(方法), 只需要保证同一个类的 所有实例具有相同的状态(属性)即可
"""
目的:节省内存空间,提高运行效率,应用在多人操作场景中.
普通类:每生成一个对象,都会在内存中占用空间,
单例模式:可以减少对象的创建;
使用场景:多人操作时,公用同一个类:比如操作mysql的增删改查
"""
from threading import Lock class Ceshi(): __obj = None # 首先保证obj私有属性 lock = Lock() # 加锁:避免多线程 没防住创建多个对象( 我用的时候其他人排队) def __new__(cls,*args,**kwargs): # 控制创建对象 with cls.lock: # 上锁(解锁) 上锁必须把缩进里的代码执行完后 才会给你解锁 下一个线程再操作它 if not cls.__obj: # 判断cls.__obj 是否存值 None 空的 (没有对象给你创建一个对象 有对象就不会创建的了 直接把私有的对象返回) cls.__obj = object.__new__(cls) # 借助爸爸类object:来创建对象(cls:为哪个类创建对象)cls.__obj:用私有属性来存储父类创建的对象 return cls.__obj obj1 = Ceshi() obj2 = Ceshi() obj3 = Ceshi() print( id(obj1) , id(obj2) , id(obj3)) # 地址都一样
通过控制类的__new来实现单例:
class Singleton(object): def __new__(cls, *args, **kwargs): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 1
通过设置静态变量来实现单例:
class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 1
通过装饰器实现单例:
from functools import wraps def singleton(cls): instances = {} @wraps(cls) def getinstance(*args, **kw): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass(object): a = 1
装饰器的写法以及应用场景
# 装饰器: 再不改变原有代码的情况下,为原函数扩展新功能
# 闭包:
# (1)互相嵌套的两个函数,内函数使用了外函数的局部变量
# (2)外函数把内函数返回 出来的过程,是闭包,内函数是闭包函数;
# 装饰器的本质就是闭包
# 应用:1、登录认证,2、框架(django, flask, 和路由分发:@app.route("/",method=["GET","POST"]))
装饰器是一个工厂函数,接受一个函数作为参数,然后返回一个新函数,其闭包中包含被装饰的函数。
有了装饰器,可以提取大量函数中与本身功能无关的类似代码 ( 这块在Flask中用于定义路由的@app.route,就是一个很好的例子),达到代码重用的目的。
可应用于插入日志、性能测试、事务处理等方面。
def deco(func): def warpper(*args, **kwargs): print(‘start‘) func(*args, **kwargs) print(‘end‘) return warpper @deco def myfunc(parameter): print("run with %s" % parameter) myfunc("something")
异常处理写法以及如何主动跑出异常(应用场景)
try: pass except Exception as e: print(str(e)) else: pass finally: pass #主动抛出异常 raise TypeError("error!")
什么是面向对象的mro
Method Realtion Order 用来制作一个继承关系的列表
MRO列表的制作原则:
1.子类永远在父类的前面
2.如果继承了多个父类,那么按照()中的顺序在列表中摆放
3.如果多个类同时继承了一个父类,孙子类中只会选取第一个父类中的父类的该方法
isinstance作用以及应用场景?
检查对象是否是对应类的对象

写代码并实现:
给定一个由编码器组成的数组,返回两个数字的索引,使它们加起来成为一个特定的目标。你可以假设每一个输入都会只有一个解决方案,您可能不会使用相同的元素两次。
例子:
给定nums =[2,7,11,15],目标= 9,
因为nums[0] + nums[1] = 2+ 7= 9,
return[0,1]
nums = [1,2,3,4,5,] target = 6 index = [] for i in range(len(nums)): for j in range(i,len(nums)): # 不使用相同的元素两次 if nums[i]+nums[j] == target: li = [] li.append(i) li.append(j) index.append(li) print(index) # [[0, 4], [1, 3], [2, 2]] # 索引
json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
字符串、列表、字典、数字、布尔值、None
自定义cls类
import json from datetime import datetime, date class ComplexEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') elif isinstance(obj, date): return obj.strftime('%Y-%m-%d') else: return json.JSONEncoder.default(self, obj) print(json.dumps({'now': datetime.now()}, cls=ComplexEncoder)) # {"now": "2023-02-06 18:06:45"}
json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json a = json.dumps({'nh':'你好'},ensure_ascii=False) print(a) # {"nh": "你好"}
什么是断言?应用场景?
断言条件为真时代码继续执行,否则抛出异常,这个异常通常不会去捕获他.我们设置一个断言目的就是要求必须实现某个条件
assert断言——声明其布尔值必须为真判定,发生异常则为假。
设置一个断言目的就是要求必须实现某个条件。
执行测试用例的时候经常用到
有用过with statement(语句)吗?它的好处是什么?
with语句的作用是通过某种方式简化异常处理,它是所谓的上下文管理器的一种
用法举例如下:
with open('output.txt', 'w') as f: f.write('Hi there!')
当你要成对执行两个相关的操作的时候,这样就很方便,以上便是经典例子,with语句会在嵌套的代码执行之后,自动关闭文件。
这种做法的还有另一个优势就是,无论嵌套的代码是以何种方式结束的,它都关闭文件。
如果在嵌套的代码中发生异常,它能够在外部exception handler catch异常前关闭文件。如果嵌套代码有return/continue/break语句,它同样能够关闭文件。
我们也能够自己构造自己的上下文管理器
我们可以用contextlib中的context manager修饰器来实现,比如可以通过以下代码暂时改变当前目录然后执行一定操作后返回。
from contextlib import contextmanager import os @contextmanager def working_directory(path): current_dir = os.getcwd() os.chdir(path) try: yield finally: os.chdir(current_dir) with working_directory("data/stuff"): # do something within data/stuff # here I am back again in the original working directory
使用代码实现查看列举目录下的所有文件。
import os # 使用os.listdir dir_aim = input('请输入目标路径:') for filename in os.listdir(dir_aim): print(filename) # 使用os.walk递归遍历 for root,dirs,files in os.walk(dir_aim): print('root:',root) if files: print('files:') for file in files: print(file) print('') if dirs: for dir in dirs: print(dir)
简述 yield和yield from关键字。
http://events.jianshu.io/p/dda2003e1aa2
yield:
1:可迭代、迭代器、生成器
区分区分一个对象是否是可迭代、迭代器、还是生成器呢?
from collections.abc import Iterable, Iterator, Generator isinstance(obj, Iterable) # 可迭代对象 isinstance(obj, Iterator) # 迭代器 isinstance(obj, Generator) # 生成器
Iterable:
可迭代对象:一般在python中像字符串,list, dict, tuple, set, deque等都是可迭代对象,
从表象上看他们都可以使用 for 来循坏迭代,但实际上他们并不是迭代器,也不是生成器。
因为一个对象只要实现了__iter__ 方法的,均可称为可迭代对象。
(可迭代对象,是其内部实现了,__iter__ 这个魔术方法。)
(可以通过,dir()方法来查看是否有__iter__来判断一个变量是否是可迭代的。)
Iterator:
迭代器,一般对象只要实现了__next__ 与 __iter__ 方法的均可称为生成器对象,因为它可以不用for循序来间断的获取元素值(next(obj)).
2:如何运行/激活生成器
3:生成器的执行状态
4:从生成器过渡到协程:yield

 浙公网安备 33010602011771号
浙公网安备 33010602011771号