![]()
import re
re模块
findall:查找所有符合规范的数据
第一个参数:匹配规则
第二个参数:被查找的字符串
返回值:list:所有符合规范的数据
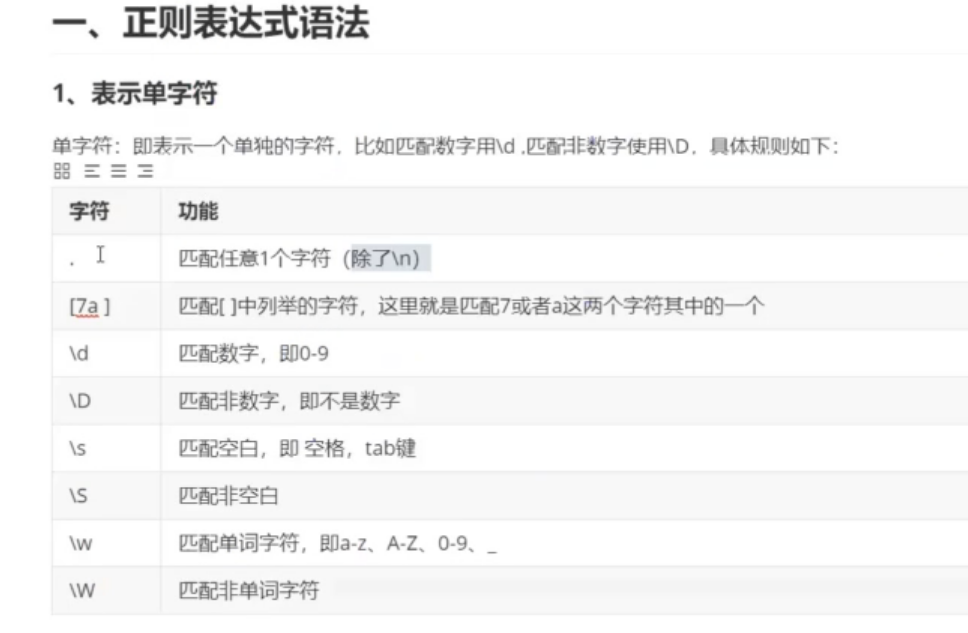
# 单字符:
s2 = "111\naaa"
# . 表示除\n之外的任意字符
res2 = re.findall(".",s2)
print(res2)
s3 = "111aa3333a222227890000vbaujndhbba..。!》2132--982a"
# [] 举例多个字符
res3 = re.findall("[0-9a-zA-Z]",s3)
print(res3)
s2 = "4567gh?-[:',>]jkTrue"
# \d:表示数字0-9
res2 = re.findall("\d",s2)
print(res2)
# \D:表示非数字(0-9除外,其他的都匹配)
res3 = re.findall("\D",s2)
print(res3)
s4 = " 67 nn"
# \s:表示空白键
res4 = re.findall("\s", s4)
print(res4)
# \S:表示非空白键
res4 = re.findall("\S", s4)
print(res4)
s5 = "pa12_?*&# %%^&你好"
# \w:表示单词字符(数字,字母,下划线):ps:中文也可以匹配到
res5 = re.findall("\w",s5)
print(res5)
# \W:表示非单词字符
res5 = re.findall("\W",s5)
print(res5)
# 表示数量
# {n}:表示前一个字符出现n次
s1 = "rd123456789011tfy13199889988guhijokd13199889928fgh99999999999jgf13199881988dgh"
res6 = re.findall("\d{11}",s1)
print(res6)
# 结果:['12345678901', '13199889988', '13199889928', '99999999999', '13199881988']
# {n,m}:表示前一个字符出现n-m次
s11 = 'a22b111cd1234567890aaa5555nnn777890mmmm'
res11 = re.findall("\d{3,5}", s11)
print(res11)
# 结果:['111', '12345', '67890', '5555', '77789']
# 贪婪模式:最符合匹配的规范之内,尽可能匹配更多的内容。默认开启了贪婪模式
# 非贪婪模式:最符合匹配的规范之内,尽可能匹配更少的内容。
# 使用?关闭贪婪模式
s11 = 'a22b111cd1234567890aaa5555nnn777890mmmm'
res11 = re.findall("\d{3,5}?", s11)
print(res11)
#结果:['111', '123', '456', '789', '555', '777', '890']
# {m,}:表示一个字符至少出现m次
s11 = 'a22b111cd1234567890aaa5555nnn777890mmmm'
res11 = re.findall("\d{3,}", s11)
print(res11)
# 结果:['111', '1234567890', '5555', '777890']
s12 = "abc123ccc1mmm234mmm1234"
# *:表示前一个字符串出现0次或者n次(0次以上)
res12 = re.findall("\d*", s12)
print(res12)
# 结果:['', '', '', '123', '', '', '', '1', '', '', '', '234', '', '', '', '1234', '']
# +:表示前一个字符出现1次或者n次(1次以上)
res12 = re.findall("\d+", s12)
print(res12)
# 结果:['123', '1', '234', '1234']
# 表示边界:
# \b 单词边界(最开头、空格、标点符号隔开的算单词边界)
s = "python123python567?python"
res = re.findall(r"\bpython",s)
print(res)
# 结果:['python', 'python']
# \B 非单词边界
res = re.findall(r"\Bpython",s)
print(res)
# 结果:['python']
s2 = "python123python123java567php"
# ^ 字符串开头
res2 = re.findall("^python123",s2)
print(res2)
# 结果:['python123']
# $字符串结尾
res2 = re.findall("567php$",s2)
print(res2)
# 结果:['567php']
s3 = "phone1234pwd456"
# |:可以匹配多个规范
res3 = re.findall("phone|pwd|456",s3)
print(res3)
# 结果:['phone', 'pwd', '456']
# ():表示匹配分组
data = '{"user":#user#,"pwd":#pwd#,"name":"#name#","age":"#age#"}'
res = re.findall("#(.*?)#",data)
print(res)
# 结果:['user', 'pwd', 'name', 'age']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号