
python3学习之路(9)函数
原文链接:http://www.cnblogs.com/linhaifeng/articles/6113086.html
如何定义一个函数
一般地,在一个变化的过程中,假设有两个变量x,y,若对于任意一个x都有唯一确定的一个y和它对应,那么就称x是自变量,y为因变量,y是x的函数。x的取值范围叫做这个函数的定义域,相应y的取值范围叫做函数的值域。如:y=2x+1,当x=4时,y=9;当x=9时,y=19
Python中定义的函数是逻辑结构化和过程化的一种编程方法。如:
def test(x):
'the function definitions'
y=2*x+1
return y
print(test(3))
其中,
def:定义函数的关键字
test:函数名
():内可定义形参
‘’:文档描述
x+=1:泛指代码块或程序逻辑处理部分
return:定义返回值,只返回结果,不打印结果,若需打印结果要另外操作
函数的运行方式:可以带参数也可以不带
函数名()
补充:
1.编程语言中的函数与数学意义的函数是截然不同的俩个概念,编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,数学定义的函数就是一个等式,等式在传入因变量值x不同会得到一个结果y,这一点与编程语言中类似(也是传入一个参数,得到一个返回值),不同的是数学意义的函数,传入值相同,得到的结果必然相同且没有任何变量的修改(不修改状态),而编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。至于具体如何实现和这么做的好处,且看后续的函数式编程。
为何使用函数
在不适用函数情况下写一个关于cpu\memory\disk等指标的使用量超过阀值时即发邮件报警的监控程序:
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
上述代码实现了功能,但代码重复部分过多,另外若要对邮件告警代码进行修改,则每个逻辑块都要进行修改
在使用函数后:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
上述代码则通过把重复代码提取出来,放在一个公共的地方,起个名字,然后直接调用这个名字。
总结使用函数的好处:
1.代码重用
2.保持一致性,易维护
3.可扩展性
return-返回值
return语句仅用于函数体内,不能用于函数外。当函数执行到return语句返回一个值后,return下面的代码不会再执行。
def erbiao():
print(1)
print(2)
return 0
print(3)
#调用函数:
erbiao()
#执行结果:
1
2
在函数中,当没有定义返回值时,Python解释器会隐式的返回None;
当返回值只有一个对象时,会打印该对象;
当返回值有多个对象时,会将多个对象组成一个元组,打印此元组
def test01():
'没有定义返回值'
pass
def test02():
'定义一个返回值'
return 0
def test03():
'定义多个返回值'
return 0, 10, 'hello', ['alex', 'lb'], {'WuDaLang': 'lb'}
t1 = test01()
t2 = test02()
t3 = test03()
print ('from test01 return is [%s]: ' % type(t1), t1)
print ('from test02 return is [%s]: ' % type(t2), t2)
print ('from test03 return is [%s]: ' % type(t3), t3)
#以下是打印结果
from test01 return is [<class 'NoneType'>]: None
from test02 return is [<class 'int'>]: 0
from test03 return is [<class 'tuple'>]: (0, 10, 'hello', ['alex', 'lb'], {'WuDaLang': 'lb'})
函数参数
参数可分为两种:形参和实参。
1、形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2、实参可以是常量、变量、表达式、函数等,无论是哪种、在进行函数调用时,他们都必须有确定的值,以便把这些值传给形参。因此应预先用赋值、输入等办法是参数获得确定值
def calc(x,y): #x,y为形参
res=x**y
return res
a=10
b=3
c=calc(a,b) #a,b为实参
print(c)
位置参数和关键字
位置参数,必须一一对应,不可多一,亦不可缺一,因为实参传给形参是顺序传入的。
def xyz(x,y,z):
print(x)
print(y)
print(z)
#调用函数:
xyz(1,2)
#执行结果:提示z形参缺少传入参数
Traceback (most recent call last):
File "D:/PyProject/test/test.py", line 5, in <module>
xyz(1,2)
TypeError: xyz() missing 1 required positional argument: 'z'
#调用函数:
xyz(1,2,3,4)
#执行结果:提示参数给多了
Traceback (most recent call last):
File "D:/PyProject/test/test.py", line 5, in <module>
xyz(1,2,3,4)
TypeError: xyz() takes 3 positional arguments but 4 were given
关键字参数,数量上仍然需要和形参一致,但无需一一对应
def xyz(x,y,z):
print(x)
print(y)
print(z)
#调用函数:
xyz(y=2,z=3,x=1)
#执行结果:
1
2
3
位置参数与关键字参数结合使用
两种传参方式结合使用时,位置参数必须在关键字参数左边,且位置参数也必须一一对应,位置不能放错,即:
def xyz(x,y,z):
print(x)
print(y)
print(z)
xyz(1,y=2,z=3)
位置参数也必须一一对应,位置不能放错,如:
def xyz(x,y,z):
print(x)
print(y)
print(z)
#调用函数:
xyz(1,x=2,z=3)
#执行结果:此处的用意是将y传入1、x传入2、z传入3,但解释器在解释代码时,会按照位置参数传参方式按顺序将1传给x,然后使用关键字传参方式将2再次传给x,此时x就获得2个值,会报错;可看到在函数调用时,一个参数只能获得一次传参。
Traceback (most recent call last):
File "D:/PyProject/test/test.py", line 5, in <module>
xyz(1,x=2,z=3)
TypeError: xyz() got multiple values for argument 'x'
默认参数,即在函数中给变量预先设定一个值,但在后期调用时,可重新给该变量赋值,且默认参数必须写在最后。
def xyz(x,z,y=4):
x+=1
y*=2
z-=3
res=x**y+z
return res
#给定三个值,调用函数
print(xyz(1,2,7))
#执行结果:
20
#给定两个值,调用函数
print(xyz(1,2))
#执行结果:
17
参数组-可变长参数(不定长参数),*args表示传入参数是元组,**kwargs表示传入参数是字典
定义的函数可能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名,执行时函数按照位置顺序将第一个参数传给x,然后将后续其他参数作为一个整体作为元组的一个元素传给不定长变量,若需要使用到这些未命名参数则可再次调用。如:
def abc(x,*args):
print(x)
print(args)
print(args[0])
print(abc(1,2,3,4,5))
#可看到以上只有1个变量,但传入五个值,其他参数会被作为未命名的变量参数传入args变量
#执行结果:函数将第一个参数传给x,然后将后续其他参数作为一个整体作为元组的一个元素传给变量,若需要使用到这些未命名参数则可再次调用
1
(2, 3, 4, 5)
2
def abc(x,*args):
print(x)
print(args)
print(args[0])
print(args[0][0]) #获取未命名元组中的值
print(abc(1,[1,2,3])) #传入一个元组给未命名的变量
#执行结果:
1 #x
([1, 2, 3],) #args未命名完整参数被整合为一个元组
[1, 2, 3]
1 #获取列表中第一个索引位置的值
#*args可以不传入参数,此时会显示一个空元组
def abc(x,*args):
print(x)
print(args)
print(abc(1))
#执行结果:
1
()
以上我们看到列表会在传参时被作为一个整体作为元组的一个元素传给变量,如何让函数遍历列表里的元素?使用*声明传入的参数是一个列表即可
看例子:
def abc(x,*args):
return(x,args,args[0])
#调用函数1:
print(abc(1,[2,3,4,5]))
#执行结果1:
1 #x得到传入参数1
([2, 3, 4, 5],) #args得到元组([2, 3, 4, 5],)
[2, 3, 4, 5] #获取生成的元组的第一个元组
#调用函数2:
print(abc(1,*[2,3,4,5]))
#执行结果2:
1 #x得到传入参数1
(2, 3, 4, 5) #args得到列表里元素被遍历后生成的新元组
2 #获取元组中的第一个元素
在不定长参数中,若传入的参数是列表,必须使用位置参数传入;若传入的参数是字典,或者是依据关键字传参,则必须使用关键字传参方式传参,使用**声明传入的参数是一个字典。
以上参数的传递方式都是按照参数位置顺序传入的,不定长参数也可以使用关键字参数传入参数:
def abc(x,**kwargs):
print(x)
print(kwargs)
abc(1,y=100,z=555)
#执行结果:
1
{'y': 100, 'z': 555}
不定长参数中位置参数与关键字参数同时使用可使得函数能接收任意长度的参数,即能同时接收列表和字典
def abc(x,*args,**kwargs):
print(x)
print(args)
print(kwargs)
abc(1,12,321,3,12,321,3,21,y=100,z=555)
#执行结果:
1
(12, 321, 3, 12, 321, 3, 21)
{'y': 100, 'z': 555}
def abc(x,*args,**kwargs):
print(x)
print(args)
print(kwargs)
abc(1,*[1,213,1,12312,321,321,312,12,312,3],**{'a':1,'b':2,'c':1231}) #同时传入列表和字典
全局变量和局部变量
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域为全局变量和局部变量。
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
当出现函数嵌套的情况,变量会一层一层的向外寻找对应的值。
n1=1
def v1():
n1='python'
return n1
print(n1)
print(v1())
#执行结果
1 #1是全局变量n1的值
python #python是函数内局部变量n1的值
#函数嵌套
n1='gbl' #先定义一个全局变量n1
def v1(): #定义一个最外层函数v1
n1=1 #在v1中将n1局部赋值为1
def v2(): #在v1中新定义一个函数v2
print(n1) #v2函数仅打印n1的值,不对n1重新赋值
return v2 #返回v2内存地址
#调用函数
a=v1() #将v1()赋值给a
print(a) #打印a的结果即v1()函数的执行结果
a() #a()转换后等同于v1()(),即执行v1函数里的v2函数
v1()() #执行v1函数里的v2函数
执行结果:
<function v1.<locals>.v2 at 0x00000000021B9620> #“return v2”返回的是v2的内存地址,print(a)的执行结果
1 #a()转换后等同于v1()(),执行v1函数里的v2函数的结果
1 #执行v1函数里的v2函数的结果
global和nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字。
在函数内部修改全局变量
n1=1
def v1():
global n1 #global关键字声明修改全局变量n1
print(n1)
n1='python'
print (n1)
print(n1)
v1()
#执行结果:
1
1
python
若要修改嵌套作用域(enclosing作用域,外层非全局作用域)中的变量则需要nonlocal关键字
def v1():
n1 = 1
def v2():
nonlocal n1
n1=200
print(n1)
v2()
print(n1)
v1()
函数的递归调用
在函数内部,可以调用其他函数。若在调用一个函数的过程中直接或间接调用自身本身。
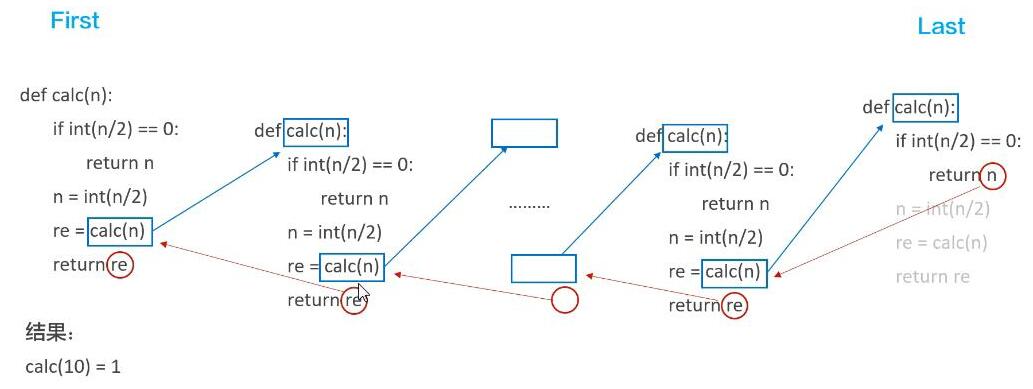
递归特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475
#_*_coding:utf-8_*_
#脚本说明:递归问路逻辑
__author__ = 'Linhaifeng'
import time
person_list=['alex','wupeiqi','yuanhao','linhaifeng']
def ask_way(person_list):
print('-'*60)
if len(person_list) == 0:
return '没人知道'
person=person_list.pop(0)
if person == 'linhaifeng':
return '%s说:我知道,老男孩就在沙河汇德商厦,下地铁就是' %person
print('hi 美男[%s],敢问路在何方' %person)
print('%s回答道:我不知道,但念你慧眼识猪,你等着,我帮你问问%s...' %(person,person_list))
time.sleep(3)
res=ask_way(person_list)
# print('%s问的结果是: %res' %(person,res))
return res
res=ask_way(person_list)
print(res)
## 匿名函数:lambda 匿名函数就是不需要显式的指定函数。 语法: ` lambda [arg1 [,arg2,.....argn]]:expression` #首先定义arg为形参,冒号后面的为逻辑表达式,此逻辑表达式一定是最终的执行逻辑,不可在里执行复杂的逻辑循环,如在lambda方法中定义if语句是不可取的
首先,定义一个简单的函数:
def calc(x,y):return (x+1)*100/y
print(calc(10,50))
执行结果:
22.0
匿名函数的定义此逻辑的方法:
calc=lambda x,y: ( x + 1 ) * 100 / y #首先定义x,y为形参,冒号后面的为逻辑表达式
print(calc(10,50))
执行结果:
22.0
是否简单一些呢?其实没有。我们先学习map函数再接着说lambda方法的妙用。
map函数
首先,如何利用一个列表的数字元素生成一个2次方后的新列表?
n1=[1,432,526,345,635,53534,345345]
new_n1=[]
for i in n1:new_n1.append(i**2)
print(new_n1)
当我们有新列表需要生成2次方时,则又需要重复以上代码。此时可以使用函数节省代码
n1=[1,432,526,345,635,53534,345345]
def map_test(arrary):
num=[]
for i in array:num.append(i**2)
return num
print(map_test(n1))
那么有新列表时,只需在函数中制定新列表即可。
在此代码逻辑上若需求变更为列表里的元素都自增1,是否需要重新修改源码呢?若每次需求变更都需要修改源码就很不方便了。
此时我们可以将这部分操作也提取成函数
n1=[1,432,526,345,635,53534,345345] #源列表
def add_one(x):return x+1 #自增一的函数
def reduce_one(x):return x-1 #自减一的函数
def square_self(x):return x**2 #自平方的函数
def map_test(func,array): #定义两个形参:func用于接收对列表要执行的操作,array接收要被处理的列表
ret=[] #定义一个新的空列表,用于保存处理后的数据
for i in array: #遍历列表
res=func(i) #执行操作,将新结果保存到res
ret.append(res) #将新数据追加到新列表
return ret #返回新列表
print(map_test(add_one,n1)) #调用函数
print(map_test(reduce_one,n1))
print(map_test(square_self,n1))
以上代码解决了每次修改逻辑还要修改已定代码的问题,但是这样还是不够方便,因为每次都需要重新定义一个操作方法。
还记得我们前面学习过lambda方法,没错,可以通过该方法再次将代码简化
n1=[1,432,526,345,635,53534,345345]
def map_test(func,array):
ret=[]
for i in array:
res=func(i)
ret.append(res)
return ret
print(map_test(lambda x:x+1,n1)) #自增1
print(map_test(lambda x:x-1,n1)) #自减1
print(map_test(lambda x:x**2,n1)) #自平方
其实在函数式编程中已有map方法完美实现了以上代码,也就是说我们直接调用map函数,不用写以上这些代码
n1=[1,432,526,345,635,53534,345345] #列表
res=map(lambda x:x+1,n1)
print(res)
print(list(res))
print(list(map(lambda x:x+1,n1)))
#执行结果:
<map object at 0x0000000001DC2358> #此方法的迭代器内存地址
[2, 433, 527, 346, 636, 53535, 345346]
[2, 433, 527, 346, 636, 53535, 345346]
map函数介绍
语法:map(function, iterable, ...)
------function -- 函数,有两个参数
------iterable -- 一个或多个序列
------map()会根据提供的函数对指定序列做映射。
第一个参数function以参数序列中的每一个元素调用function函数,返回包含每次function函数返回值的新列表或迭代器对象(Python 2.x 返回列表。Python 3.x 返回迭代器。)
返回值:
——Python 2.x返回列表
——Python 3.x返回迭代器
#计算平方数
>>>def square(x) :
... return x ** 2
...
#计算列表各个元素的平方
>>> map(square, [1,2,3,4,5]) #Python2返回列表
[1, 4, 9, 16, 25]
>>> list(map(square,[1,2,3,4,5])) #Python3返回迭代器内存地址,然后使用list方法手动生成列表
[1, 4, 9, 16, 25]
#使用lambda匿名函数
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) #Python2返回列表
[1, 4, 9, 16, 25]
>>> list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) #Python3返回迭代器内存地址,然后使用list方法手动生成列表
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) #Python2返回列表
[3, 7, 11, 15, 19]
>>> list(map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])) #Python3返回迭代器内存地址,然后使用list方法手动生成列表
[3, 7, 11, 15, 19]
filter函数
首先从一个列表中移除以non开头的元素
all_language=['python','shell','java','nonPy','nonShell','nonJava']
new_all_language=[]
for i in all_language:
if not i.startswith('non'):
new_all_language.append(i)
print(new_all_language)
那么作为功能性的代码块,建议都封装成函数调用
all_language=['python','shell','java','nonPy','nonShell','nonJava']
def filter_test(array):
new_all_language=[]
for i in array:
if not i.startswith('non'):
new_all_language.append(i)
return new_all_language
print(filter_test(all_language))
那么同样地,可以将操作列表的功能提取出来,以此提高函数的功能性
all_language=['python','shell','java','nonPy','nonShell','nonJava']
def filter_test(func,array): #定义两个形参,一个用于接收操作函数,一个用于接收数据参数
new_all_language=[]
for i in array:
if not func(i): #调用操作函数
new_all_language.append(i)
return new_all_language
print(filter_test(lambda n:n.startswith('non'),all_language)) #使用lambda随机函数直接简化操作函数的定义
print(filter_test(lambda n:n.endswith('ava'),all_language))
filter函数介绍
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,若要转换为列表,可以使用 list() 来转换。(Python 2.x 返回列表。Python 3.x 返回迭代器。)
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
语法:filter(function, iterable)
------function -- 判断函数
------iterable -- 可迭代对象
返回值:
——Python 2.x返回列表
——Python 3.x返回迭代器
用filter方法实现上述代码逻辑:
all_language=['python','shell','java','nonPy','nonShell','nonJava']
#res=filter(lambda n: not n.startswith('non'),all_language) #筛选不以non字符串开头的元素(not取反),将筛选后的结果保存到res变量,res此时保存的是迭代器对象
#non_res=list(res) #将迭代器对象转换为一个列表
#print(non_res)
print (list(filter(lambda n:not n.startswith('non'),all_language))) #上述三条逻辑的整合
print (list(filter(lambda n:not n.endswith('ava'),all_language))) #筛选出不以ava结尾的元素
reduce函数
同样,从一个需求入手,求一个所有元素之乘积
n1=[1,2,3,100]
res=1
for i in n1:
res*=i
print(res)
将之定义成函数
n1=[1,2,3,100]
def reduce_test(array):
res=1
for i in array:
res*=i
return res
print(reduce_test(n1))
同样地,将操作功能提取为一个函数
n1=[1,2,3,100]
def reduce_test(func,array):
res=1
for i in array:
res=func(res,i) #将操作功能提取,使用lambda方法实现
return res
print(reduce_test(lambda x,y:x*y,n1))
上述逻辑中存在一个问题,res=1,在乘法运算中此值会作为默认参数参与进来,得到的结果为乘数本身,在加法中此值就不能为1,否则结果会永远多1。可以这么解决这个问题
n1=[1,2,3,100]
def reduce_test(func,array):
res=array.pop(0) #在传入列表时,先将第一个删除并保存到res,那么在执行到这个逻辑后array=n1=[2,3,100]
for i in array: #array为[2,3,100],第一个数将作为res的初始值参与运算
res=func(res,i) #将操作功能提取,使用lambda方法实现
return res
print(reduce_test(lambda x,y:x*y,n1))
在实际代码逻辑中,res的初始值可能需要任意修改,此时就需要能手动指定初始值了,然后还需要的功能就是,在没有指定res初始值时,自动获取列表的第一个元素作为初始值:
n1=[1,2,3,100]
def reduce_test(func,array,res_init=None): #定义一个res_init的变量,默认值为None
if res_init is None: #当res_init为None,即收到传参时
res=array.pop(0) #将res的初始值设置为array.pop(0)
else:
res=res_init #res_init变量收到传参,则设定值为传入参数
for i in array:
res=func(res,i)
return res
print(reduce_test(lambda x,y:x*y,n1)) #未指定res初始值
print(reduce_test(lambda x,y:x*y,n1,100)) #指定res初始值
reduce函数介绍
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给reduce中的函数function(有两个参数)先对集合中的第1、2个元素进行操作,得到的结果再与第三个数据用function函数运算,最后得到一个结果。
在 Python3 中,reduce() 函数已经被从全局名字空间里移除了,它现在被放置在 fucntools 模块里,若想要使用它,则需要通过引入 functools 模块来调用 reduce() 函数:from functools import reduce
语法:reduce(function, iterable[, initializer])
——function -- 函数,有两个参数
——iterable -- 可迭代对象
——initializer -- 可选,初始参数
上述代码逻辑在reduce函数中已完整实现,因此使用reduce函数
from functools import reduce
n1=[1,2,3,100]
print(reduce(lambda x,y:x*y,n1))
print(reduce(lambda x,y:x*y,n1,100))
内置函数
Python3内置函数详细介绍地址:http://www.runoob.com/python3/python3-built-in-functions.html
官方Python3内置函数详细介绍地址:https://docs.python.org/3/library/functions.html
Python中fabs()与abs()区别:http://www.runoob.com/note/26621
#### max函数与min函数,不同数据类型间不可进行比较
1、max函数与min函数处理的是可迭代对象,相当于一个fox循环取出每个元素进行比较,注意:不同类型数据不能进行比较
2、每个元素进行比较,是从每个元素的第一个位置依次比较,若这一个位置分出大小,后面的都不需要比较了,直接得出这两元素的大小
#max函数取出给定元素中最大值
print('最大值',max(3+3,3*3,3**3))
最大值 27
#min函数取出给定元素中最小值
print('最小值',min(3+3,3*3,3**3))
最小值 6
#对于字符串求最大值和最小值,函数会按照字符先后顺序进行比较
>>> a=['age1','age0','age100','age300','age9']
>>> print(max(a))
age9
#高级用法
people=[
{'name':'alex','age':1000},
{'name':'wupei','age':10000},
{'name':'yuanhao','age':9000},
{'name':'linhaifeng','age':18},
]
print(max(people,key=lambda dic:dic['age'])) #key后为max的参数,max(people,key=lambda dic:dic['age'])意思是按照'age'此key的值作为比较大小的依据,
#lambda dic:dic['age']此代码相当于执行:
ret=[]
for item in people:
ret.append(item['age'])
print(max(ret))
sorted函数--对所有可迭代的对象进行排序操作
sort与sorted区别:1、sort是应用在list上的方法,sorted可以对所有可迭代的对象进行排序操作。2、list的sort方法返回的是对已经存在的列表进行操作,而内建函数sorted方法返回的是一个新的list,而不是在原来的基础上进行的操作。
语法:sorted(iterable, key=None, reverse=False)
——iterable -- 可迭代对象。
——key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
——reverse -- 排序规则,reverse=True降序 , reverse=False升序(默认)
#默认升序
>>> sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5]
#降序
>>>example_list = [5, 0, 6, 1, 2, 7, 3, 4]
>>> sorted(example_list, reverse=True)
[7, 6, 5, 4, 3, 2, 1, 0]
#对于字典,默认取出键进行比较排序
>>> sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'})
[1, 2, 3, 4, 5]
#列表内嵌字典,依据字典某个键的值进行降序排序
people=[
{'name':'alex','age':1000},
{'name':'wupei','age':10000},
{'name':'yuanhao','age':9000},
{'name':'linhaifeng','age':18},
]
print(sorted(people,key=lambda x:x['age'],reverse=True))
执行结果:
[{'name': 'wupei', 'age': 10000}, {'name': 'yuanhao', 'age': 9000}, {'name': 'alex', 'age': 1000}, {'name': 'linhaifeng', 'age': 18}]
#对字典进行value的排序
name_dic={
'erbiao': 11900,
'jude':1200,
'acp':300,
'user':1312
}
print(sorted(name_dic,reverse=True)) #按照key进行降序排序
print(sorted(name_dic,key=lambda key:name_dic[key],reverse=True)) #按照value进行降序排序,“lambda key:name_dic[key]”用于依据key遍历value,遍历出所有value后sorted再进行排序,仅返回key
print(sorted(zip(name_dic.values(),name_dic.keys()),reverse=True)) #按照value进行降序排序,遍历出所有value后sorted再进行排序,返回key:value组成的元组
执行结果:
['user', 'jude', 'erbiao', 'acp']
['erbiao', 'user', 'jude', 'acp']
[(11900, 'erbiao'), (1312, 'user'), (1200, 'jude'), (300, 'acp')]
zip函数
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
若各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表。
zip方法在Python2和Python3中的不同:在Python2中zip()返回的是一个列表,Python3中返回的是一个迭代器对象,但可使用list()转换来输出列表。
#两个可迭代对象按照索引位置一一打包压缩
a=[1,2,3]
b=['x','y','z']
c=['A','B','C','D']
zp1=zip(a,b)
print(zp1)
print(list(zp1))
#执行结果:
<zip object at 0x0000000002204B08> #返回迭代器对象
[(1, 'x'), (2, 'y'), (3, 'z')] #list转换为列表,将两个列表的元素按照索引位置打包成一个个元组
#元素个数不一致时返回列表长度与最短的对象相同
a=[1,2,3]
b=['x','y','z']
c=['A','B','C','D']
zp2=zip(a,c)
print(list(zp2))
#执行结果:
[(1, 'A'), (2, 'B'), (3, 'C')] #列表c中的D元素未进行打包
#字符串打包成元组
str100='i am erbiao'
zp3=zip(str100)
print(list(zp3))
#执行结果:
[('i',), (' ',), ('a',), ('m',), (' ',), ('e',), ('r',), ('b',), ('i',), ('a',), ('o',)] #将每个字符串拿出来,单独生成一个元组
#字典如何打包?
dict100={'name':'erbiao','age':1000,'gender':None}
zp4=zip(dict100.keys(),dict100.values()) #依次取出key/value
print(list(zp4))
print(list(zip(dict100.keys()))) #单独取出key
print(list(zip(dict100.values()))) #单独取出value
执行结果:
[('name', 'erbiao'), ('age', 1000), ('gender', None)] #将每次取出的键值对作为一个元组打包
[('name',), ('age',), ('gender',)] #将键作为元组打包
[('erbiao',), (1000,), (None,)] #将值作为元组打包
#“*zip”解压
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> zpab=zip(a,b)
>>> print(list(zpab))
[(1, 4), (2, 5), (3, 6)]
>>> a1,b1=zip(*zip(a,b))
>>> list(a1)
[1, 2, 3]
>>> list(b1)
[4, 5, 6]
拓展--如何取字典中value的最大/小值
#正确方法
>>> dict9999={'t1':1,'t2':913,'t45':9123,'t31':1203,'t123':1333,'t3333':12393}
>>> dict9999_zp=list(zip(dict9999.values(),dict9999.keys())) #使用zip将字典重新打包成元组形式,value在前,key在后
>>> dict9999_zp
[(1, 't1'), (913, 't2'), (9123, 't45'), (1203, 't31'), (1333, 't123'), (12393, 't3333')]
>>> max(dict9999_zp) #在调用max函数时,遍历出每个元组的第一个元素进行比较,并打印整个元组
(12393, 't3333')
#不太正确的方法:
>>> dict9999={'t1':1,'t2':913,'t45':9123,'t31':1203,'t123':1333,'t3333':12393}
>>> max(dict9999.values()) #仅取出最大的值,不取出键
12393
## 函数式编程 原文链接:http://www.voidcn.com/article/p-adjydlhd-dr.html
当下主流的编程方法有三种:函数式,面向过程,面向对象,三者相当于编程界的三个门派,每个门派有自己的独门秘籍,都是用来解决问题的。三种流派都是一种编程的方法论,只不过是各自的风格不同,在不同的应用场景下也各有优劣。
1、面向过程:找到解决问题的入口,按照一个固定的流程去模拟解决问题的流程
将一个大问题,分解成若干小问题,然后从头至尾一步一步解决,中间加上逻辑判断:
a.搜索目标,用户输入(配偶要求),按找要求到数据结构(字典)内检索合适的人物
b.表白,表白成功进入3,否则进入2
c.恋爱,恋爱成功进入4,否则返回1
d.见家长,家长同意进入5,家长说她是你失散多年的妹妹,返回1
e.结婚
违反开放封闭(OCP)原则,若有一天需要加入一种Monthly类型,无疑需要修改这个方法;
这样的代码风格会让接下来的开发者不假思索的进行延续,比方说需要根据不同的活动类型延期活动;
这样的代格违反了DRY原则,相同的代码框架却无法重用。
2、面向对象
3、函数式:函数式=编程语言定义的函数+数学意义的函数
通俗来讲,函数式就是用编程语言去实现数学函数。这种函数内对象是永恒不变的,要么参数是函数,要么返回值是函数,没有for和while循环,所有的循环都由递归去实现,无变量的赋值(即不用变量去保存状态),无赋值即不改变
函数式编程特征:
1、不可变数据:不用变量保存状态,不修改变量
2、第一类对象:函数即“变量”,函数接收的参数或函数返回值中包含函数,则此函数为高阶函数
3、尾调用优化(尾递归):
#例一:不可变:不用变量保存状态,不修改变量
#非函数式
a=1
def incr_test1():
global a
a+=1
return a
incr_test1()
print a
#函数式
n=1
def incr_test2(n):
return n+1
print incr_test2(2)
print n
#例二:第一类对象:函数即“变量”
# 函数名可以当做参数传递
# 返回值可以是函数名
#函数名可以当做参数传递
def foo(n):
print(n)
def bar(name):
print('my name is %s' %name)
foo(bar('erbiao'))
#返回值可以是函数名
def bar():
print('from bar')
def foo():
print('from foo')
return bar
v=foo()
v()
#例三:尾调用:在函数的最后一步调用另外一个函数(最后一步不一定是函数的最后一行)
#函数bar在foo内为尾调用
def bar(n):
return n
def foo(x):
return bar(x)
#函数bar1和bar2在foo内均为尾调用,二者在if判断条件不同的情况下都有可能作为函数的最后一步
def bar1(n):
return n
def bar2(n):
return n+1
def foo(x):
if type(x) is str:
return bar1(x)
elif type(x) is int:
return bar2(x)
#函数bar在foo内为非尾调用
def bar(n):
return n
def foo(x):
y=bar(x)
return y
#函数bar在foo内为非尾调用
def bar(n):
return n
def foo(x):
return bar(x)+1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号