
Python3学习之路(2)数据类型及各数据类型介绍
数据类型
数据类型简单的说有几种:Number(数字)、String(字符串)、Boolean(布尔)、List(列表)、Tuple(元组)、Byte(位)、set(集合)、Dictionary(字典)、Nnoe(空)。以下是数据类型转换方法:
|转换方法|说明|
- | :-: | -:
|int(x [,base ])|将x转换为一个整数|
|float(x )|将x转换到一个浮点数|
|complex(real [,imag ])|创建一个复数|
|str(x )|将对象 x 转换为字符串|
|repr(x )|将对象 x 转换为表达式字符串|
|eval(str )|用来计算在字符串中的有效 Python 表达式,并返回一个对象|
|tuple(s )|将序列 s 转换为一个元组|
|list(s )|将序列 s 转换为一个列表|
|chr(x )|将一个整数转换为一个字符|
|unichr(x )|将一个整数转换为 Unicode 字符|
|ord(x )|将一个字符转换为它的整数值|
|hex(x )|将一个整数转换为一个十六进制字符串|
|oct(x )|将一个整数转换为一个八进制字符串|
先插播一个常用函数的介绍:range()
range()一般用于创建一个整数列表,语法:range(m, n[, step])
该函数表示的整数列表范围是 m ≥ x < n
m: 计数从m开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
n: 计数到n结束,但不包括n。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
例:输出0~9数字
>>> for i in range(0,10):print(i)
...
0
1
2
3
4
5
6
7
8
9
例:输出0~10,每两个数输出一次
>>> for i in range(0,11,2):print(i)
...
0
2
4
6
8
10
如何查看数据类型?
>>> a='2adsfad67fa8ds6f'
>>> print(type(a))
<class 'str'>
各数据类型的可变与不可变性
我们都知道按照各数据类型的方法定义各种数据类型时,数据存储在内存中,不可变性就是说修改了数据的元素,或值后数据在内存中的内存编号也随之变动,反之该数据类型具有不可变性。内存编号用id(obj)来查询。
可变的有:列表,字典,集合
不可变的有:字符串、数字、元组
不同数据类型数据的访问访问方式
直接访问:数字
顺序访问:字符串、列表、元组
映射:字典
存储元素个数:
容器类型(能存放多个元素):列表、元组、字典
原子类型(仅能存放一个元素):数字、字符串
## 以下将介绍各数据类型
数字
Python3支持3中数字类型:
整型(int):有正负只分,通常被称为整型或整数,不带小数点(即使源数字有小数点,在重新整型后小数点及小数点以后的部分会完全忽略),另外,py3的整型没有限制大小,也就是说py3没有py2的Long类型。计算机由于使用二进制,所以,有时用十六进制表示整数比较方便,十六进制用0x前缀和0-9,a-f表示,例如:0xff00,0xa5b4c3d2,等等。
浮点型(float):整数部分和小数部分组成浮点数,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)。整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差
复数(complex):复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
数字类型转换
int(x):将x转换为一个整数。
float(x):将x转换到一个浮点数。
complex(x):将x转换到一个复数,实数部分为x,虚数部分为0。
complex(x, y):将x和y转换到一个复数,实数部分为x,虚数部分为y。x和y是数字表达式。
#数据类型的转换
>>> "2"+"3"
'23'
>>> int("2")+int("3")
5
#数字整形
>>> float("2")+int("3")
5.0
>>> int(2.6)
2
#变量赋值
>>> a=5
>>> b=2
>>> a * b
10
#int()默认输出的数是十进制的数。如何以16进制、8进制等输出一个数?
>>> num='555'
>>> print (int(num,base=10))
555
>>> print (int(num,base=8)) #指定输出进制数为8进制
365
>>> print (int(num,base=18)) #指定输出进制数为18进制
1715
>>> print (int(num,base=16)) #指定输出进制数为16进制
1365
#查询当前数字的二进制,至少用n位表示
>>> age=10
>>> r = age.bit_length()
>>> r
4
#将用户输入(即字符串)转换为数字(整数或浮点数)
#!/usr/bin/env python
>>> float(input("输入第一个数字:"))+float(input("输入第二个数字"))
输入第一个数字:10
输入第二个数字1000
1010.0
数学函数
|函数|返回值(描述)|
- | :-: | :-:
|abs(x)|返回数字的绝对值,如abs(-10) 返回 10|
|ceil(x)|返回数字的上入整数,如math.ceil(4.1) 返回 5|
|cmp(x, y)|若 x < y 返回 -1, 若 x == y 返回 0, 若 x > y 返回 1。 Python 3 已废弃。使用 (x>y)-(x<y) 替换。|
|exp(x)|返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045|
|fabs(x)|返回数字的绝对值,如math.fabs(-10) 返回10.0|
|floor(x)|返回数字的下舍整数,如math.floor(4.9)返回 4|
|log(x)|如math.log(math.e)返回1.0,math.log(100,10)返回2.0|
|log10(x)|返回以10为基数的x的对数,如math.log10(100)返回 2.0|
|max(x1, x2,...)|返回给定参数的最大值,参数可以为序列。|
|min(x1, x2,...)|返回给定参数的最小值,参数可以为序列。|
|modf(x)|返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。|
|pow(x, y)|x**y 运算后的值。|
|round(x [,n])|返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。|
|sqrt(x)|返回数字x的平方根。|
随机数函数
先导入随机函数模块:import random
|函数|描述|
- | :-: | -:
|choice(seq)|从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。|
|randrange ([start,] stop [,step])|从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1|
|random()|随机生成下一个实数,它在[0,1)范围内。|
|seed([x])|改变随机数生成器的种子seed。若你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。|
|shuffle(lst)|将序列的所有元素随机排序|
|uniform(x, y)|随机生成下一个实数,它在[x,y]范围内。|
三角函数
|函数|描述|
- | :-: | :-:
|acos(x)|返回x的反余弦弧度值。|
|asin(x)|返回x的反正弦弧度值。|
|atan(x)|返回x的反正切弧度值。|
|atan2(y, x)|返回给定的 X 及 Y 坐标值的反正切值。|
|cos(x)|返回x的弧度的余弦值。|
|hypot(x, y)|返回欧几里德范数 sqrt(xx + yy)。|
|sin(x)|返回的x弧度的正弦值。|
|tan(x)|返回x弧度的正切值。|
|degrees(x)|将弧度转换为角度,如degrees(math.pi/2) , 返回90.0|
|radians(x)|将角度转换为弧度|
数学常量
|常量|描述|
- | :-: | :-:
|pi|数学常量 pi(圆周率,一般以π来表示)|
|e|数学常量 e,e即自然常数(自然常数)。|
字符串
字符串在内存中一旦创建就不可修改,一旦修改或拼接,就会重新生成字符串。
字符串截取与切片
>>> var="hello"
>>> print("var[0]")
>>> print("var[0]:",var[0])
var[0]: h
>>> print("var[0:3]:",var[0:3]) #索引大于等于0,小于3,即0~2
var[0:3]: hel
>>> print('var[0:-1]',var[0:-1]) #-负数表示倒数,-1就是倒数第一位,此处的索引范围也就是大于等于0,但是小于最后一个位置的索引
var[0:-1] hell
字符串更新
var1 = 'Hello World!'
print ("已更新字符串 : ", var1[:6] + 'Runoob!')
已更新字符串 : Hello Runoob!
字符串:字符串在输出时必须使用单引号''或双引号“”引起,因此整数3和'3'是两个概念。字符串可用逗号‘,’拼接,如:
>>> print ('hello',"Erbiao")
hello Erbiao
转义字符
以下是Python支持的特殊字符列表:
|转义字符|描述|
- | :-: | :-:
|\|(在行尾时)续行符|
|\\|反斜杠符号|
|\'|单引号|
|\"|双引号|
|\a|响铃|
|\b|退格(Backspace)|
|\e|转义|
|\000|空|
|\n|换行|
|\v|纵向制表符|
|\t|横向制表符|
|\r|回车|
|\f|换页|
|\oyy|八进制数,yy代表的字符,例如:\o12代表换行|
|\xyy|十六进制数,yy代表的字符,例如:\x0a代表换行|
|\other|其它的字符以普通格式输出|
>>> print ('\\t可能包含4个空格')
\t可能包含4个空格
>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\
字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":
|操作符|描述|实例|
- | :- | :-: | :-:
|+|字符串连接 |a + b 输出结果: HelloPython|
||重复输出字符串|a2 输出结果:HelloHello|
|[]|通过索引获取字符串中字符|a[1] 输出结果 e|
|[ : ]|截取字符串中的一部分|a[1:4] 输出结果 ell|
|in|成员运算符 - 若字符串中包含给定的字符返回 True|'H' in a 输出结果 1|
|not in|成员运算符 - 若字符串中不包含给定的字符返回 True|'M' not in a 输出结果 1|
|r/R|原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。|print( r'\n' ) print( R'\n' )|
|%|格式字符串|请看下一节内容。|
字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符%s的字符串中。
例:
>>> print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
我叫 小明 今年 10 岁!
python字符串格式化符号:
|符号|描述|
- | :- | :-
|%c|格式化字符及其ASCII码|
|%s|格式化字符串|
|%d|格式化整数|
|%u|格式化无符号整型|
|%o|格式化无符号八进制数|
|%x|格式化无符号十六进制数|
|%X|格式化无符号十六进制数(大写)|
|%f|格式化浮点数字,可指定小数点后的精度|
|%e|用科学计数法格式化浮点数|
|%E|作用同%e,用科学计数法格式化浮点数|
|%g|%f和%e的简写|
|%G|%f 和 %E 的简写|
|%p|用十六进制数格式化变量的地址|
格式化操作符辅助指令:
|符号|功能|
- | :- | :-
|*|定义宽度或者小数点精度|
|-|用做左对齐|
|+|在正数前面显示加号( + )|
||在正数前面显示空格|
|#|在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X')|
|0|显示的数字前面填充'0'而不是默认的空格|
|%|'%%'输出一个单一的'%'|
|(var)|映射变量(字典参数)|
|m.n.|m 是显示的最小总宽度,n 是小数点后的位数(若可用的话)|
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。|
三引号
三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。
>>> para_str = """这是一个多行字符串的实例
... 多行字符串可以使用制表符
... TAB ( \t )。
... 也可以使用换行符 [ \n ]。
... """
>>> print (para_str)
这是一个多行字符串的实例
多行字符串可以使用制表符
TAB ( )。
也可以使用换行符 [
]。
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。一个典型的用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐
errHTML = '''
<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>
'''
cursor.execute('''
CREATE TABLE users (
login VARCHAR(8),
uid INTEGER,
prid INTEGER)
''')
字符串内建函数
|方法|描述|
- | :- | :-
|capitalize()|将字符串的第一个字符转换为大写|
|count(str, beg= 0,end=len(string))|返回 str 在string里面出现的次数,若 beg 或者 end 指定则返回指定范围内 str 出现的次数|
|bytes.decode(encoding="utf-8", errors="strict")|Python3中没有decode方法,但我们可以使用 bytes 对象的decode()方法来解码给定的bytes对象,这个 bytes 对象可以由str.encode()来编码返回。|
|encode(encoding='UTF-8',errors='strict')|以 encoding 指定的编码格式编码字符串,若出错默认报一个ValueError 的异常,除非errors指定的是'ignore'或者'replace'|
|endswith(suffix, beg=0, end=len(string))|检查字符串是否以obj结束,若beg或者end指定则检查指定的范围内是否以 obj 结束,若是,返回 True,否则返回 False.|
|startswith(str, beg=0,end=len(string))|检查字符串是否是以obj开头,是则返回True,否则返回False。若beg和end指定值,则在指定范围内检查。|
|expandtabs(tabsize=8)|把字符串string中的tab(\t)符号转为空格,tab符号默认的空格数是8。|
|find(str, beg=0 end=len(string))|检测 str 是否包含在字符串中,若指定范围 beg 和 end ,则检查是否包含在指定范围内,若包含返回开始的索引值,否则返回-1|
|index(str, beg=0, end=len(string))|跟find()方法一样,只不过若str不在字符串中会报一个异常.|
|isalnum()|若字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False|
|isalpha()|若字符串至少有一个字符并且所有字符都是字母则返回True, 否则返回False|
|isdigit()|若字符串只包含数字则返回True 否则返回False。支持检测①、②.....|
|isdecimal()|检查字符串是否只包含十进制字符,若是返回 true,否则返回 false。|
|isnumeric()|若字符串中只包含数字字符,则返回True,否则返回False,支持检测数字大写(一、二、....)|
|swapcase()|将字符串中大写转换为小写,小写转换为大写|
|lower()|转换字符串中所有大写字符为小写.|
|upper()|转换字符串中的小写字母为大写|
|islower()|若字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回True,否则返回False|
|isupper()|若字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True,否则返回False|
|isspace()|若字符串中只包含空白,则返回 True,否则返回False.|
|title()|返回"标题化"的字符串,即测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写,(见istitle()),不是大写开头的强制以大写形式输出,可以包含中文,但不允许只有中文|
|istitle()|若字符串是标题化的(见title())则返回True,否则返回False,可以包含中文,但不允许只有中文|
|join(seq)|以指定字符串作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串|
|len(string)|返回字符串长度|
|center(width, fillchar)|返回一个指定的宽度width居中的字符串,fillchar为填充的字符,默认为空格。|
|ljust(width[, fillchar])|返回一个原字符串左对齐,并使用fillchar填充至长度width的新字符串,fillchar默认为空格。|
|rjust(width,[, fillchar])|返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串|
|maketrans()|创建字符映射字典,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。两个字符串的长度必须相同,为一一对应的关系。|
|translate(table, deletechars="")|根据str给出的表(包含256个字符)转换string的字符, 要过滤掉的字符放到deletechars参数中|
|max(str)|返回字符串str中最大的字母。|
|min(str)|返回字符串str中最小的字母。|
|replace(old, new [, max])|把 将字符串中的str1替换成str2,若max指定,则替换不超过max次。|
|rfind(str, beg=0,end=len(string))|类似于find()函数,不过是从右边开始查找.|
|rindex( str, beg=0, end=len(string))|类似于index(),不过是从右边开始.|
|lstrip()|删除字符串左边的指定字符串,默认空格、tab、换行符,在指定字符串后,函数会将字符串拆分成一个个小的子串进行匹配清除,详细见表后示例|
|rstrip()|删除字符串末尾的指定字符串,默认空格、tab、换行符,在指定字符串后,函数会将字符串拆分成一个个小的子串进行匹配清除,详细见表后示例|
|strip([chars])|在字符串上执行lstrip()和rstrip()|
|partition(str)|用来根据指定的分隔符从左往右将字符串进行分割。若字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。指定分隔符(子串),结果中显示分隔符|
|rpartition(str)|类似于partition()方法,只是该方法是从目标字符串的末尾也就是右边开始搜索分割符。若字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。指定分隔符(子串),结果中显示分隔符|
|split(str="", num=string.count(str))|num=string.count(str)) 以str为分隔符(默认为空白字符,空格、tab、换行符)截取字符串,若num有指定值,则仅截取num个子字符串。指定分隔符(子串),结果中不显示分隔符|
|rsplit(str="", num=string.count(str))|num=string.count(str)) 以str为分隔符(默认为空白字符,空格、tab、换行符)截取字符串,若num有指定值,则仅截取num个子字符串。指定分隔符(子串),结果中不显示分隔符|
|splitlines([keepends])|按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,若参数keepends为False,不包含换行符,若为True,则保留换行符。|
|zfill (width)|返回长度为width的字符串,原字符串右对齐,前面填充0|
|isidentifier()|判断字符串是否可为合法的标识符,是返回True,否则返回False|
|isprintable()|判断字符串是否包含不可见字符如换行符,tab键等,不包含返回True,否则返回False|
|format()|格式化字符串的函数,详细见http://www.runoob.com/python/att-string-format.html|
部分字符串内建函数实例
#expandtabs()函数主要用于格式化字符串,如下例中test字符串包含一组信息,其中还有tab键,然后将每25个字符作为一个断句,不够的用空格补齐,形成字符格式化
>>> test='username\temail\tpassword\nerbiao\terbiao@qq.com\terbiao\nerbiao1\terbiao@qq.com\terbiao2\nerbiao3\terbiao@qq.com\terbiao'
>>> v = test.expandtabs(25)
>>> print(v)
username email password
erbiao erbiao@qq.com erbiao
erbiao1 erbiao@qq.com erbiao2
erbiao3 erbiao@qq.com erbiao
#isalnum()函数用于判断字符串中是否只包含字母和数字
>>> str1='erbiao+erbiao'
>>> str2='erbiaoerbiao1231'
>>> str1.isalnum()
False
>>> str2.isalnum()
True
#判断字符串是否是合法的标识符
#都知道:
变量定义的规则:
1、变量名只能是字母、数字或下划线的任意组合
2、变量名的第一个字符不能是数字
3、以下内置关键字不能声明为变量名['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
>>> a = '_de12'
>>> c = '3de12'
>>> b = 'dedef123_'
>>> print (a.isidentifier(),b.isidentifier(),c.isidentifier())
True True False
#判断字符串是否包含不可见字符,如换行符,tab键等
>>> test='aa0si-9asdm_adasdjlajdoi'
>>> test.isprintable()
True
>>> test100 = "username\tpasswd"
>>> test100
'username\tpasswd'
>>> test100.isprintable()
False
#判断字符串是否全部是空格
>>> a='1238'
>>> b='12 38'
>>> c=' '
>>> print(a.isspace(),b.isspace(),c.isspace())
False False True
#将一串字符串转化成标题,即将字符串中每个英文单词的首字母变成大写,可以包含中文,但不允许只有中文
>>> t1='there is title'
>>> t1.title()
'There Is Title'
#检测字符串是否是标题,即判断字符串中的英文单词是否都是首字母大写,其余字母是否都是小写,可以包含中文,但不允许只有中文
>>> t1='there is a title,标题'
>>> t1.istitle()
False
>>> t2=t1.title()
>>> t2.istitle()
True
#将序列中的元素以指定的字符连接生成一个新的字符串
>>> j1='我要吃饭饭'
>>> j2=' '
>>> j2.join(j1)
'我 要 吃 饭 饭'
>>> j3='-'
>>> j4='13411392667'
>>> j3.join(j4)
'1-3-4-1-1-3-9-2-6-6-7'
>>> j5='该方法用于将序列中的元素以指定的字符连接生成一个新的字符串'
>>> '!'.join(j5)
'该!方!法!用!于!将!序!列!中!的!元!素!以!指!定!的!字!符!连!接!生!成!一!个!新!的!字!符!串'
#指定填充字符串,并设置填充字符串的长度,然后将原字符串放在中间
>>> c1='居中字符串'
>>> c1.center(20,'*')
'*******居中字符串********'
#指定填充字符串,并设置填充字符串的长度,然后将原字符串放在左边
>>> c2='左对齐字符串'
>>> c2.ljust(20,'=')
'左对齐字符串=============='
#指定填充字符串,并设置填充字符串的长度,然后将原字符串放在右边
c3='右对齐字符串'
>>> c3.rjust(20,'9')
'99999999999999右对齐字符串'
#lstrip()、rstrip()、strip对首尾空白字符以及指定字符的清除
st1='\n123 321\t'
st2=st1.rstrip()
st3=st1.lstrip()
st4=st1.strip()
print('st2',st2)
print('st3',st3)
print('st4',st4)
命令执行结果:
st2
123 #st2清除了右边的tab
st3 123 321 #st3清除了左边边的换行符
st4 123 321 #st4清除了左右两边的tab和换行符
st5='33333erbiao44444'
st6=st5.lstrip('3')
st7=st5.rstrip('4')
st8=st5.strip('34')
print('st6',st6)
print('st7',st7)
print('st8',st8)
st9=st5.lstrip('3er')
st10=st5.rstrip('ao4')
命令执行结果:
st6 erbiao44444 #循环清除了左边所有的字符串3
st7 33333erbiao #循环清除了右边所有的字符串4
st8 erbiao #循环清除了左边所有的字符串3,以及右边的所有字符串4
st9 biao44444 #循环清除了左边所有字符串3和er字符串,先循环清除了所有字符串3,再次用3和e组合成新的字符串进行匹配清除,以此类推,最终也清除了er字符串
st10 33333erbi #循环清除了右边所有字符串4和字符串ao,先循环清楚了所有字符串4,再次用a和o形成新字符串进行匹配清除,以此类推,最终也循环查找ao4并清除之
#创建字符映射的字典,并转换之
>>> st100='abcde'
>>> st200='12345'
>>> st=str.maketrans(st100,st200) #创建字符串映射字典
>>> type(st)
<class 'dict'>
>>> st300='there is a example string.apple is a big company' #示例字符串
>>> st300.translate(st)
'th5r5 is 1 5x1mpl5 string.1ppl5 is 1 2ig 3omp1ny' #将示例字符串利用映射字典进行转换
#字符串替换
>>> 'userniubuerpasser'.replace('er','ER',2) #从左往右查找字符串er,且仅将前两个查找到的结果替换成ER
'usERniubuERpasser'
>>> 'userniubuerpasser'.replace('er','ER') #默认替换所有匹配到的结果
'usERniubuERpassER'
#字符串的分隔与切割---字符串切割成三元元组的情况,指定分隔符(子串),结果中显示分隔符
>>> st1000='usernamepasswd'
>>> st1000.partition('s') #partition('s') 从左往右寻找第一个s字符串,然后将左边的子串作为第一个子串,第二个为字符串分隔符(也是字符串的一分部),右边的子串作为第二个子串
('u', 's', 'ernamepasswd')
>>> st10001='susernamepasswd'
>>> st10001.partition('s') #分隔符为首的情况
('', 's', 'usernamepasswd')
>>> st1000='usernamepasswd'
>>> st1000.rpartition('s') #rpartition('s')与partition('s')类似,只是方向相反
('usernamepas', 's', 'wd')
#字符串的分隔与切割---指定分隔符(子串),结果中不显示分隔符
>>> st1000='usernamepasswd'
>>> st1000.split('s')
['u', 'ernamepa', '', 'wd'] #默认将指定分隔符全部找出,进行切割
>>> st1000.split('s',2)
['u', 'ernamepa', 'swd'] #指定分隔次数2后,从左至右寻找2次分隔符,并切割字符串2次
>>> st1000.split('s',1)
['u', 'ernamepasswd'] #指定分隔次数1后,从左至右寻找1次分隔符,并切割字符串1次
>>> st1000='usernamepasswd'
>>> st1000.rsplit('s')
['u', 'ernamepa', '', 'wd']
>>> st1000.rsplit('s',1) #与split('str',num)相似,只是方向相反
['usernamepas', 'wd']
#按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表
>>> st888='username\terbiao\npasswd\tebpasswd\nemail\terbiao@erbiao.com'
>>> st888.splitlines()
['username\terbiao', 'passwd\tebpasswd', 'email\terbiao@erbiao.com'] #以换行符切割,默认不显示换行符
>>> st888.splitlines(True)
['username\terbiao\n', 'passwd\tebpasswd\n', 'email\terbiao@erbiao.com'] #强制True后,以换行符为分隔符,将换行符后面的字符串切割
#检查字符串是否以指定子串结尾或开头
>>> 'erbiao'.startswith('e') #确定以字符串e开头返回True
True
>>> 'erbiao'.startswith('ao') #不是以字符串ao开头返回False
False
>>> 'erbiao'.endswith('ao') #确定以字符串ao结尾返回True
True
>>> 'erbiao'.endswith('b') #不是以字符串b开头返回False
False
#大写转小写,小写转大写
>>> 'AbCdEfGhIjKlMnOpQrStUvWxYz'.swapcase()
'aBcDeFgHiJkLmNoPqRsTuVwXyZ'
列表
Python有6个序列的内置类型,但最常见的是列表和元组。
list是一种有序可重复的集合,可以随时添加和删除其中的元素,元素或数据项不需要是相同的类型。序列中的每个元素都分配一个数字————它的位置,或称为索引,第一个索引是0,第二个索引是1,依此类推。
序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可,如:
list1=['1','2','3','4']
list2=['name','erbiao','age','101','learning','Python']
列表函数
|序号|函数|
- | :- | :-
|len(list)|列表元素个数|
|max(list)|返回列表元素最大值|
|min(list)|返回列表元素最小值|
|list(seq)|将元组转换为列表|
列表方法
|序号|方法|
- | :- | :-
|list.append(obj)|在列表末尾添加新的对象|
|list.count(obj)|统计某个元素在列表中出现的次数|
|list.extend(seq)|在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)|
|list.index(obj)|从列表中找出某个值第一个匹配项的索引位置|
|list.insert(index, obj)|将对象插入列表|
|list.pop([index=-1]])|移除列表中的一个元素(默认最后一个元素),并且返回该元素的值|
|list.remove(obj)|移除列表中某个值的第一个匹配项|
|list.reverse()|反向列表中元素|
|list.sort(cmp=None, key=None, reverse=False)|对原列表进行排序|
|list.clear()|清空列表|
|list.copy()|浅拷贝列表|
|copy.deepcopy(list)|深拷贝列表,需要先导入模块“import copy”|
使用range()函数生成一个列表
>>> a=list(range(10))
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
将一个字符串转换为列表
>>> str='871474621dhfadsnffsfmnsfsdnflas'
>>> list1=list(str)
>>> list1
['8', '7', '1', '4', '7', '4', '6', '2', '1', 'd', 'h', 'f', 'a', 'd', 's', 'n', 'f', 'f', 's', 'f', 'm', 'n', 's', 'f', 's', 'd', 'n', 'f', 'l', 'a', 's']
将列表转换成字符串
#当列表中既有数字也有字符串,只能通过for循环将每个元素转换成字符串再拼接在一起
listone=[11,22,33,33,'123','erbiao']
s=''
for i in listone:
s=s+str(i)
print(s)
#若只有字符串,则直接使用join方法
listtwo=['11','22','33','33','123','erbiao']
v=''.join(listtwo)
print(v)
获取列表中的值
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等
#获取第一个索引位置的元素值
>>> list1=['1','2','3','4']
>>> print(list1[0])
1
#从右侧开始读取倒数第二个元素
>>> person1=['name','erbiao','age','101']
>>> person1[-2]
'age'
#输入从第二个元素开始的所有元素
>>> person1=['name','erbiao','age','101']
>>> person1[1:]
['erbiao', 'age', '101']
查询元素是否存在于列表中
False表示结果为假也就是说查询的元素不存在于列表中,True则相反
>>> list1000=['erbiao ', 'erbiao ', 'erbiao ', 'erbiao ', 'erbiao ', 'erbiao ']
>>> 'python' in list1000
False
>>> 'erbiao ' in list1000
True
列表的重复生成
Python中 +号可用于组合列表,*号可用于重复列表
>>> list1000=['erbiao '] * 6
>>> list1000
['erbiao ', 'erbiao ', 'erbiao ', 'erbiao ', 'erbiao ', 'erbiao ']
列表的组合
Python中 +号可用于组合列表,*号可用于重复列表
#将两个列表相加
>>> nums=['1','2','3']+['4','5','6']
>>> nums
['1', '2', '3', '4', '5', '6']
#类似地
>>> nums = ['1', '2', '3', '4', '5', '6']
>>> nums += ['', '1233', '100']
>>> nums
['1', '2', '3', '4', '5', '6', '', '1233', '100']
列表的嵌套
列表除了能包含不同类型的数据,还能在列表里嵌套列表
>>> person=['name','erbiao','age','101','learning',['Python','Shell','C','Java']]
>>> print(person[5][1])
Shell
>>> print(person[5][2])
C
>>> person1=['name','erbiao','age','101','learning',['Python','Shell','C','Java',['easy','easy','medium']]]
>>> print(person1[5][4][1])
easy
#同时获取多个连续的值
>>> list2=['name','erbiao','age','101','learning','Python']
>>> print(list2[2:6])
['age', '101', 'learning', 'Python']
#同时或多个不连续的值
>>> list2=['name','erbiao','age','101','learning','Python']
>>> print(list2[1],list2[3],list2[5])
erbiao 101 Python
更新列表元素
list = ['Google', 'Baidu', 1997, 2003]
list[2] = 2001
>>> print (list)
['Google', 'Baidu', 2001, 2003]
list[2]=list[3]
>>> print (list)
['Google', 'Baidu', 2003, 2003]
末尾追加新元素
>>> learn = ['Python','Shell']
>>> learn.append('java')
>>> learn
['Python', 'Shell', 'java']
批量追加元素
>>> listone=[11,22,33,33,'123','erbiao']
>>> listtwo=['photo','shop','sop','photoshop','user']
>>> listone.extend(listtwo)
>>> listone
[11, 22, 33, 33, '123', 'erbiao', 'photo', 'shop', 'sop', 'photoshop', 'user']
>>> listone.extend('erbiao')
>>> listone
[11, 22, 33, 33, '123', 'erbiao', 'photo', 'shop', 'sop', 'photoshop', 'user', ['photo', 'shop', 'sop', 'photoshop', 'user'], 'e', 'r', 'b', 'i', 'a', 'o']
append方法与extend方法比较(append方法将添加的所有元素作为一个整体追加,而extend方法将新元素的列表中的所有元素循环追加到旧列表)
>>> listone=[11,22,33,33,'123','erbiao']
>>> listtwo=['photo','shop','sop','photoshop','user']
>>> listone.extend(listtwo)
>>> listone
[11, 22, 33, 33, '123', 'erbiao', 'photo', 'shop', 'sop', 'photoshop', 'user']
>>> listone.append(listtwo)
>>> listone
[11, 22, 33, 33, '123', 'erbiao', 'photo', 'shop', 'sop', 'photoshop', 'user', ['photo', 'shop', 'sop', 'photoshop', 'user']]
将元素插入指定索引位置
>>> py = ['python','funny']
>>> index=1
>>> py.insert(index,'is')
>>> print(py)
['python', 'is', 'funny']
py = ['python','funny']
>>> py.insert(1,"is")
>>> py.insert(0,"ia")
>>> py
['ia', 'python', 'is', 'funny']
删除列表元素
>>> py = ['python','funny']
>>> del py[1]
>>> py
['python']
#pop()函数用于移除列表中的一个元素(默认最后一个索引位置的元素),并且返回该元素的值
>>> list2 = ['name', 'erbiao', 'age', '101', 'learning', 'Python']
>>> list2.pop()
'Python'
>>> list2.pop(4)
'learning'
>>> list2
['name', 'erbiao', 'age', '101']
#remove()函数用于移除列表中某个值的第一个匹配项,注意是第一个匹配项
>>> list100 = ['1','1','2','2','3','3']
>>> list100.remove('1')
>>> list100
['1', '2', '2', '3', '3']
统计元素出现次数
>>> list100 = ['1', '2', '2', '3', '3','erbiao','erbiao','python','python','python',]
>>> list100.count('python')
3
找出某个元素第一个匹配项的索引位置
list100 = ['1', '2', '2', '3', '3','erbiao','erbiao','python','python','python',]
>>> list100.index('2')
1
反向元素索引位置,即元素反向排序
>>> list1=['1','2','7','4','6','5']
>>> list1.reverse()
>>> list1
['5', '6', '4', '7', '2', '1']
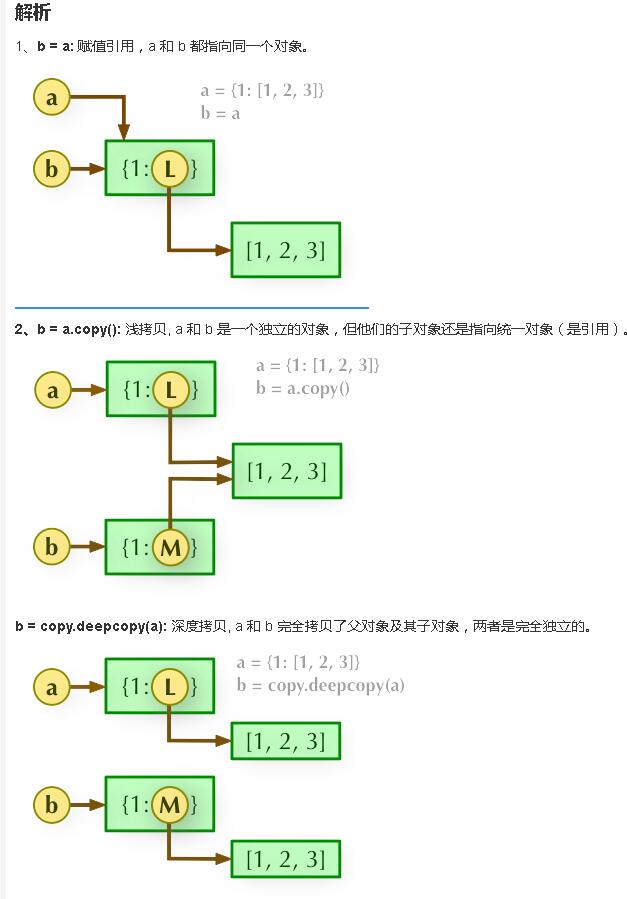
直接赋值、浅拷贝和深度拷贝解析
直接赋值:其实就是对象的引用(别名)。
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象,即只会拷贝第一层元素,嵌套的第二层或者更多层不会被拷贝,而是指向源。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
浅拷贝
>>> a=[[1,2],3,4] #原列表
>>> b=a.copy() #浅拷贝列表
>>> print(a,"\n",b)
[[1, 2], 3, 4]
[[1, 2], 3, 4] #拷贝前后列表相同
>>> b[0][0]=111111111111111111 #修改子对象(或非第一层的元素)
>>> b[2]=4444444444444444 #修改父对象(或第一层的元素)
>>> print(a,"\n",b)
[[111111111111111111, 2], 3, 4]
[[111111111111111111, 2], 3, 4444444444444444] #此时打印就可看见区别,父对象(或第一层元素)是拷贝的,但是子对象(或嵌套的非第一层元素)是指向的
深拷贝
>>> import copy #先导入模块
>>> a=[[1,2],3,4] #原列表
>>> b=copy.deepcopy(a) #深拷贝列表
>>> print(a,"\n",b) #拷贝前后列表相同
[[1, 2], 3, 4]
[[1, 2], 3, 4]
>>>
>>> b[0][0]=111111111111111111 #修改子对象(或非第一层的元素)
>>> b[2]=4444444444444444 #修改父对象(或第一层的元素)
>>>
>>> print(a,"\n",b)
[[1, 2], 3, 4]
[[111111111111111111, 2], 3, 4444444444444444] #此时打印就可看见区别,b是完全拷贝的,修改b完全不会影响到a
赋值、深拷贝、浅拷贝原理解析
元组
元组可看成特殊的列表,不同的是元组一经创建则一级元素不能修改,也不能添加/删除,但若元组的元素嵌套的一个列表或其他可被修改的数据类型,则可对该元素中的二级元素进行修改,详请关注后续示例。且列表使用'[]'将元素包含,而元组则使用'()',或不使用符号包含,另外建议在创建元组时,在最后一个元组后额外添加一个逗号
>>> a=('1','2','3',)
>>> b='4','5','6'
>>> type(a)
<class 'tuple'>
>>> type(b)
<class 'tuple'>
创建一个空元组
>>> tuple1=()
>>> type(tuple1)
单个元素的元组
单个字符的元组一定要在元素后面添加一个逗号,否则括号会被当做运算符使用。
>>> tup1=(1)
>>> tup2=('a')
>>> type(tup1)
<class 'int'>
>>> type(tup2)
<class 'str'>
>>> tup3=('100',)
>>> type(tup3)
<class 'tuple'>
元组查询
元组与字符串类似,可以进行截取,组合等
#查询单个元素
>>> tup1 = ('Google', 'Baidu', 1297, 2001,)
>>> print ("tup1[0]: ", tup1[0])
tup1[0]: Google
#查询多个连续元素
>>> tup2 = (1, 2, 3, 4, 5, 6, 7 ,)
>>> print ("tup2[1:5]: ", tup2[1:5])
tup2[1:5]: (2, 3, 4, 5,)
#读取倒数第三个元素
>>> tup4
('Google', 'Baidu', 1297, 2001, 1, 2, 3, 4, 5, 6, 7,)
>>> tup4[-3]
5
#显示第5个元素以及以后的元素
>>> tup4[4:]
(1, 2, 3, 4, 5, 6, 7,)
元组的连接组合
元组虽然无法增删修改,但可通过重新组合产生新的元组
>>> tup1 = ('Google', 'Baidu', 1297, 2001,)
>>> tup2 = (1, 2, 3, 4, 5, 6, 7, )
>>> tup4=tup1+tup2
>>> tup4
('Google', 'Baidu', 1297, 2001, 1, 2, 3, 4, 5, 6, 7,)
元组删除
元组无法删除其中元素,但可删除整个元组
>>> tup4
('Google', 'Baidu', 1297, 2001, 1, 2, 3, 4, 5, 6, 7,)
>>> del tup4
>>> tup4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'tup4' is not defined
元组运算符
元组和列表一样,也支持+ 号和 * 号进行运算
#计算元素个数
>>> tup4
('Google', 'Baidu', 1297, 2001, 1, 2, 3, 4, 5, 6, 7,)
>>> len(tup4)
11
#组合两个元组
>>> (1, 2, 3,) + (4, 5, 6,)
(1, 2, 3, 4, 5, 6)
#重复生成元组
>>> ('erbiao',) * 4
('erbiao', 'erbiao', 'erbiao', 'erbiao')
#查询元组是否存在
>>> 'erbiao' in (1,2,4)
False
>>> 1 in (1,2,4)
True
返回元组中元素的最大值
>>> tuple1111=1,2,3,4,5100,50001
>>> max(tuple1111)
50001
返回元组中元素的最小值
>>> tuple2 = ('5', '4', '8',)
>>> min(tuple2)
4
#### 统计元素出现次数
>>> tu2=('11','11','3','3','1','11',)
>>> tu2.count('11')
3
#### 从元组中找出某个值第一个匹配项的索引位置
>>> tu2=('11','11','3','3','1','11',)
>>> tu2.index('3')
2
将列表转换为元组
>>> list1234=['213','123214141','9103840','12341','902834234']
>>> tup77=tuple(list1234)
>>> type(tup77)
<class 'tuple'>
>>> tup77
('213', '123214141', '9103840', '12341', '902834234')
修改元组中二级列表元素的数据
>>> tu1=('erbiao','studying',['py2','py3'],)
>>> type(tu1)
<class 'tuple'>
>>> type(tu1[2])
<class 'list'>
>>> tu1[2][0]='567'
>>> tu1
('erbiao', 'studying', ['567', 'py3'])
>>> tu1[2]='567'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment #可看到元组不支持修改,但支持二级元素修改
## 字典 字典是另一种可变容器模型,且可存储任意类型对象。字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式: ``` {'key1': 'value1', 'key2': 'value2'}
键必须唯一,一个键若同时被赋值两次,后一个值会和键形成键值对,但值不必。值可取任何数据类型,但键必须不可变,如字符串、数字或元组,由于列表是可变的,所以列表不能做键,布尔值也可以做键,True做键时,会转换为1,False则为0。如:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
#### 创建一个空字典
dict1={}
type(dict1)
<class 'dict'>
#### 查询字典里的值
dict1 = {'Name':'erbiao','Age':'100','lesson':'python'}
type(dict1)
<class 'dict'>
dict1['Name']
'erbiao'
#### 修改字典信息
dict1 = {'Name':'erbiao','Age':'100','lesson':'python'}
dict1['Age'] = 1000
dict1
#### 添加键值对元素
添加一个新的键值对元素的方法,和修改键值对信息的方法相同,只是当键不存在时会自动添加
dict1 = {'Name': 'erbiao', 'Age': 1000, 'lesson': 'python'}
dict1['niubi'] = 'yes'
dict1
#### 删除字典元素与清空字典元素
删除字典元素
dict1
{'Name': 'erbiao', 'Age': 1000, 'lesson': 'python', 'niubi': 'yes'}
del dict1['lesson']
dict1
清空字典元素
dict1.clear()
dict1
{}
#### 字典内置函数
统计字典元素个数,即键总数
dict1 = {'Name':'erbiao','Age':'100','lesson':'python'}
len(dict1)
3
输出字典,以可打印的字符串表示
dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
str(dict)
"{'Name': 'Runoob', 'Class': 'First', 'Age': 7}"
#### 字典内置方法
清空字典,删除字典内所有元素
dict1.clear()
dict1
{}
字典的浅复制,浅复制是指当对象的字段值被复制时,字段引用的对象不会被复制·如一个对象有一个指向字符串的字段,且我们对该对象做了一个浅复制,那麽两个对象将引用同一个字符串
dict1 = {'Name':'erbiao','Age':'100','lesson':'python'}
dict2=dict1.copy()
dict2
创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值,语法:dict.fromkeys(seq[, value])
seq -- 字典键值列表。
value -- 可选参数, 设置键序列(seq)的值。
seq=('NAME','AGE','WORK','LEARN',)
DICT100 = dict.fromkeys(seq)
DICT100
{'NAME': None, 'AGE': None, 'WORK': None, 'LEARN': None}
DICT222 = dict.fromkeys(seq,222)
DICT222
返回指定键的值,若值不在字典中返回默认值,语法:dict.get(key, default=None)
key -- 字典中要查找的键。
default -- 若指定键的值不存在时,返回该默认值值。
dict333={'NAME': 222, 'AGE': 222, 'WORK': 222, 'LEARN': 222}
dict333.get('SEX','NA')
'NA'
dict333.get('NAME','NA')
222
setdefault()方法和get()方法类似, 若键不已经存在于字典中,将会添加键并将值设为默认值,语法:dict.setdefault(key, default=None).
若key在字典中,返回对应的值。若不在字典中,则插入key及设置的默认值default,并返回default,default默认值为None。
dict1
{'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.setdefault('Work',None)
dict1
检测键是否存在于字典中,若键在字典里返回true,否则返回false
dict333={'NAME': 222, 'AGE': 222, 'WORK': 222, 'LEARN': 222}
'user' in dict333
False
'NAME' in dict333
True
返回可遍历的(键、值)元组数组
dict1
{'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.items()
dict_items([('Name', 'erbiao'), ('Age', '100'), ('lesson', 'python')])
返回字典所有的键
dict1
{'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.keys()
dict_keys(['Name', 'Age', 'lesson'])
返回字典所有的值
dict1={'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.values()
dict_values(['erbiao', '100', 'python'])
将原字典的键值对更新到目标字典,已存在的键,值会被更新,不存在的键会添加到目标字典
dict1 = {'Name': 'erbiao', 'Age': '100', 'lesson': 'python', 'Work': None}
dict2 = {'Name': 'judy', 'Age': '100', 'lesson': 'python'}
dict1.update(dict2)
dict1
删除给定键的键值对,且返回被删除键的值,否则返回默认值,语法:pop(key[,default])
key: 要删除的键值
default: 若没有 key,返回 default 值
dict1={'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.pop('lesson')
'python'
dict1.pop('learn','Nothing to delete')
'Nothing to delete'
dict1.pop('Age','nothing to delete')
'100'
dict1
删除字典元素
dict1
{'Name': 'erbiao', 'Age': 1000, 'lesson': 'python', 'niubi': 'yes'}
del dict1['lesson']
dict1
清空字典元素
dict1.clear()
dict1
{}
popitem()方法随机返回并删除字典中的一对键和值(一般删除末尾对)。若字典已经为空,却调用了此方法,就报出KeyError异常。
dict1={'Name': 'erbiao', 'Age': '100', 'lesson': 'python'}
dict1.popitem()
('lesson', 'python')
dict1.popitem()
('Age', '100')
dict1
<br />
## 集合
集合是一个无序不重复元素的、可hash的序列,集合的元素必须是不可变类型,但是集合本身是可变的,可进行增删改查。可使用大括号{}或set()函数创建集合,注意:创建一个空集合必须用set()而不是{ },因为{ }是用来创建一个空字典。
另外,集合的forzenset方法,可将集合定义成不可变,此时则不能增删改,可查
s=forzenset('hello')
创建格式:
parame = {value01,value02,...}
或
set(value,)
#### set() 中参数注意事项
创建一个含有一个元素的集合
my_set = set(('apple',))
my_set
创建一个含有多个元素的集合
my_set = set(('apple','pear','banana'))
my_set
如无必要,不要写成如下形式
my_set = set('apple')
my_set
{'l', 'e', 'p', 'a'}
my_set1 = set(('apple'))
my_set1
#### 集合的去重功能
set1 = {'1','1','2','3','3','4','5'}
type(set1)
<class 'set'>
set1
#### 判断元素是否存在于集合
set2={'Alice','judy','Mary','April','July','Apple'}
'erbiao' in set2
False
'July' in set2
True
#### 集合与集合间的运算
seta=set('watermelon')
seta
{'n', 'r', 'e', 'a', 'w', 'l', 'o', 't', 'm'}
setb=set('pomegranate')
setb
交集,两个集合都包含的元素
seta&setb
将两个集合交集后,重新赋值。
seta=set('watermelon')
setb=set('pomegranate')
seta&setb
{'e', 'm', 'n', 'r', 'o', 'a', 't'}
seta.intersection_update(setb)
seta
检测两个集合是否有相同元素(或交集是否为空),有相同元素则返回False,否则返回True
setc.isdisjoint(setd)
True
setd.isdisjoint(sete)
False
并集,将两个集合组成一个去重后的结果集
seta | setb
差集,两个集合的差,一般指前一个集合(seta)减去后一个集合(setb)中重复的元素后,前一个集合(seta)所剩下的结果集,但注意:seta-setb并不等于setb-seta,如:
seta-setb
{'w', 'l'}
setb-seta
不同时存在两个集合的结果集
seta ^ setb
将不同时存在两个集合的结果集重新赋值到集合
seta=set('watermelon')
setb=set('pomegranate')
seta^setb
{'w', 'l', 'g', 'p'}
seta.symmetric_difference_update(setb)
seta
将存在于集合seta但不存在与集合setb的元素搜索出来并更新会集合seta,没有返回值。类似于先做一个seta-setb的操作,然后将结果重新赋值到seta
seta=set('watermelon')
setb=set('pomegranate')
seta-setb
{'w', 'l'}
seta.difference_update(setb)
print (seta)
检测一个集合是否是另一个集合的子集,是返回True,否则返回False,即判断一个集合的元素是否被包含在另一集合
s1={1,2,3}
s2={1,2}
s3={1,3,4}
s1.issubset(s2)
False
s2.issubset(s1)
True
s2.issubset(s3)
False
判断一个集合是狗屎另一集合的父集,是返回True,否则返回False
s1={1,2,3}
s2={1,2}
s1.issuperset(s2)
True
#### add()方法添加元素,若元素已存在,则不进行任何操作,将新元素作为一个整体添加到集合,只能接收不可变数据类型
set100={'BAIDU','ALIBABA','CNBLOGS','APPLE','HUAWEI'}
set100.add('GOOGLE')
set100
#### update()方法添加元素,将可迭代对象依次添加到集合,只能接收不可变且可迭代的数据类型
cname=set(('APPLE', 'GOOGLE', 'HUAWEI', 'BAIDU', 'ALIBABA', 'CNBLOGS'))
cname.update({'TUDOU','YOUKU'})
cname
{'APPLE', 'GOOGLE', 'TUDOU', 'HUAWEI', 'BAIDU', 'ALIBABA', 'CNBLOGS', 'YOUKU'}
cname.update(['TENCENT','JD'],['OFO','MOBIKE'])
cname
cname.update(12,"NEWONE") #int类型的数字12非可迭代对象
Traceback (most recent call last):
File "", line 1, in
TypeError: 'int' object is not iterable
cname.update([12,"NEWONE"]) #将元素变更为一个列表后,添加成功
cname
#### 移除元素
remove()方法若元素不存在删除会报错
cname
{'APPLE', 'GOOGLE', 'TUDOU', 'TENCENT', 'HUAWEI', 'BAIDU', 'ALIBABA', 'MOBIKE',
cname.remove('TUDOU')
cname
{'APPLE', 'GOOGLE', 'TENCENT', 'HUAWEI', 'BAIDU', 'ALIBABA', 'MOBIKE', 'JD', 'OFO', 'CNBLOGS', 'YOUKU'}
cname.remove('ERBIAO')
Traceback (most recent call last):
File "", line 1, in
KeyError: 'ERBIAO'
discard()方法若元素不存在删除不会报错,存在就删除,不存在不做任何处理
cname.discard('ERBIAO')
随机删除一个元素,并返回删除的元素,由于集合无序,完全随机删除
cname
{'APPLE', 'GOOGLE', 'TENCENT', 'HUAWEI', 'BAIDU', 'ALIBABA', 'MOBIKE', 'JD', 'OFO', 'CNBLOGS', 'YOUKU'}
cname.pop()
'APPLE'
cname
#### 统计元素个数
cname
{'GOOGLE', 'TENCENT', 'HUAWEI', 'BAIDU', 'ALIBABA', 'MOBIKE', 'JD', 'OFO', 'CNBLOGS', 'YOUKU'}
len(cname)
10
#### 复制集合
s1=s.copy()
#### 清空集合
cname.clear()
## 各数据类型的可变与不可变性
我们都知道按照各数据类型的方法定义各种数据类型时,数据存储在内存中,不可变性就是说修改了数据的元素,或值后数据在内存中的内存编号也随之变动,反之该数据类型具有不可变性。内存编号用id(obj)来查询。
可变的有:列表,字典,集合
不可变的有:字符串、数字、元组
## 不同数据类型数据的访问访问方式
直接访问:数字
顺序访问:字符串、列表、元组
映射:字典
<br />
## 存储元素个数:
容器类型(能存放多个元素):列表、元组、字典
原子类型(仅能存放一个元素):数字、字符串
<br />
## 补充:解压序列
#### 示例1:左边值必须和右边的值是一一对应的关系,否则会报错
a,b,c=(1,2,3)
a
1
b
2
c
3
#### 示例2:左边值必须和右边的值是一一对应的关系,否则会报错
a,b,c,d,e='hello'
a,b,c,d,e
('h', 'e', 'l', 'l', 'o')
#### 示例3:取列表的第一个值和最后一个值
l=[10,3,2,3,5,1,2,3,5,8,9]
a,*_,b=l
a
10
b
9
_ #下划线保存了中间所有的值
[3, 2, 3, 5, 1, 2, 3, 5, 8]
#### 示例4:取列表的前两个值和最后两个值
l=[10,3,2,3,5,1,2,3,5,8,9]
a,b,*_,c,d=l
a,b,c,d
(10, 3, 8, 9)
##### 示例5:交换f1和f2的值
f1=1
f2=2
f1,f2=f2,f1
f1
2
f2
1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号