
NLP常用激活函数
参考博客
https://blog.csdn.net/weixin_41417982/article/details/81437088
https://blog.csdn.net/muyao987/article/details/106829342
激活函数的作用
激活函数将线性变换转换为非线性的。作用于上层节点的输出和下层节点的输入之间,也可以看作是上层节点的最后一步。
常用的几个激活函数
sigmoid
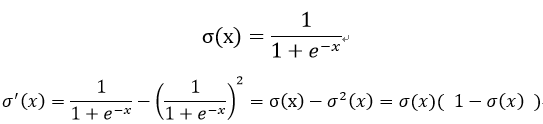
函数图像图下:
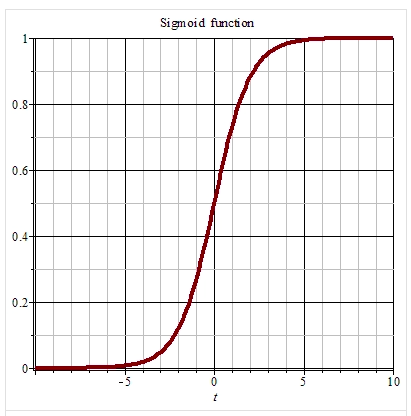
导数图像如下:
优点:
- 函数范围为(0,1),函数具有很好的对称性。
- 导数容易求出来。
缺点:
- 可以看到在趋于正无穷或负无穷时,函数趋**滑状态。但输入超过一定范围以后,函数就不敏感了。x较大时,导数接*0,导致参数长时间得不到更新。因此除了输出层是一个二分类问题,其他基本不用它。
- 输出non-zero center,不是关于原点对称的。
- 幂运算耗时
pytorch的实现:torch.sigmoid()
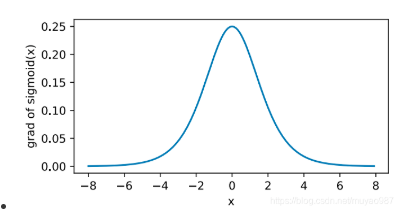
tanh(双曲正切)
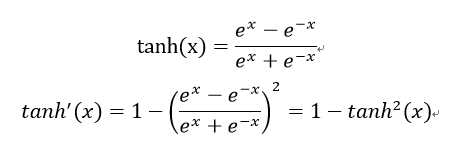
函数图像如下:
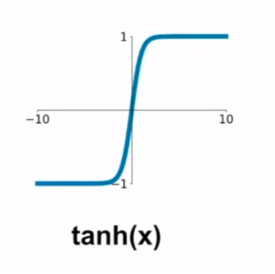
导数图像如下:
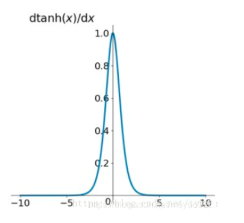
优点:解决了Sigmoid函数的不是zero-centered输出问题(y轴方向均值为0)
缺点:在两边仍然有梯度消失和幂运算耗时的问题。
pytorch的实现:torch.tanh()
ReLU
ReLU(x) = max( 0 , x )
函数图像如下:
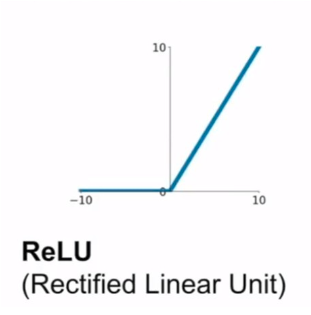
导数图像如下:
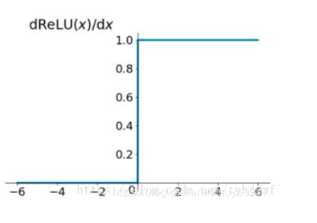
优点:
- 正区间解决了梯度消失的问题
- 计算速度非常快,只需要判断输入是否大于0
- 收敛快于sigmoid和tanh
缺点:
- 输出non-zero center,不是关于原点对称的。
- Dead ReLU Problem,某些神经元可能永远不会被激活,导致相应的参数永远不能被更新,原因是(1)参数初始化的问题,这种情况比较少见。(2)学习率太大导致参数更新太大。
Leaky ReLU
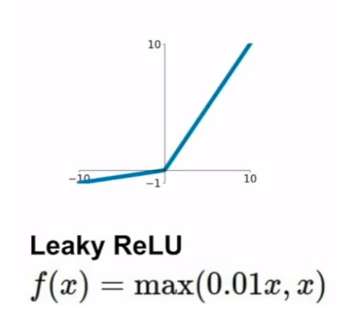
导数图像如下:
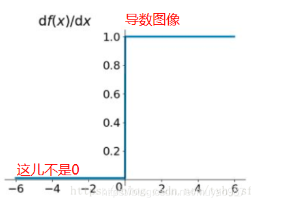
优点:不会有Dead ReLU Problem
缺点:性能不如ReLU
Maxout
Maxout相当于一层神经元网络
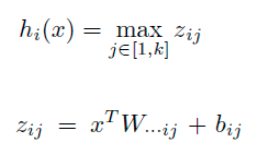
权重w是一个大小为(d,m,k)三维矩阵,b是一个大小为(m,k)的二维矩阵,这两个就是我们需要学习的参数。如果我们设定参数k=1,这时网络就类似于普通的MLP网络。
softmax
见https://blog.csdn.net/weixin_37136725/article/details/53884173(图片好像没有显示出来)
https://www.cnblogs.com/maybe2030/p/5678387.html?utm_source=tuicool&utm_medium=referral
激活函数的使用经验
-
最好不用sigmoid,不如tanh,更不如ReLU 和 Maxout
- 尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
- 如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号