RAG(检索增强生成)笔记
RAG(检索增强生成)是一种结合信息检索与大语言模型(LLM)生成能力的技术,通过动态调用外部知识库解决LLM的固有缺陷
一、RAG的核心价值
- 突破LLM三大瓶颈
- 知识固化:预训练数据无法更新 → RAG通过实时检索外部知识库(如企业文档、最新新闻)确保信息时效性。
- 生成内容缺乏依据 → RAG引用检索结果作为生成依据,减少事实性幻觉。
- 幻觉问题:
事实性幻觉:指模型生成的内容与可验证的现实世界事实不一致
忠实性幻觉:指模型生成的内容与用户的指令或上下文不一致- 领域局限:通用模型难以处理专业问题 → RAG可对接垂直领域知识库(如法律条文、医学文献)。
- 技术优势
- 低成本适配:无需微调模型,仅需更新知识库即可扩展能力。
- 可解释性:生成答案可追溯至检索段落(如标注引用)。
- 安全可控:通过权限管理知识库内容,过滤敏感信息。
二、RAG全流程解析
阶段1:数据预处理与索引
- 知识库构建:
- 文档载入
这是知识库构建的初始阶段,需要解析非结构化文档(如PDF、Markdown等),提取其中的文本、图表等信息,并转换为计算机可处理的数据形式。例如,医学研究报告中的文字和图表需被解析为可分析的数据。 - 文档分割
将文档内容按标点符号或语义单元拆分为词组或句子,需平衡分割长度以保持语义连贯性。例如,法律条文需按逻辑段落拆分,避免过度碎片化或过长。常见策略包括:
- 固定长度分块:按字符或Token数切分。
- 语义分块:基于句子边界或主题分割(如NLP模型识别段落主旨)。
- 重叠策略:相邻块间部分重叠,避免上下文断裂。
- 向量化
使用深度学习模型(如BERT、Sentence-BERT)将文本转换为高维向量,捕捉语义信息。常用方法包括:
- 词嵌入模型:Word2Vec、GloVe等。
- 上下文相关模型:BERT、GPT等生成动态向量。
- 现代化存储
将向量化后的数据存入向量数据库(如Milvus、Pinecone),支持高效相似性检索。存储时可能采用以下优化:
- 索引结构:HNSW、IVF等算法加速近似最近邻(ANN)搜索。
- 压缩技术:乘积量化(PQ)降低存储开销。
阶段2:实时检索与重排序
- 文档载入
- 用户查询处理:
- 问题向量化:使用Embedding模型(如BERT、Sentence-BERT)将用户问题转换为高维向量,捕捉语义信息。
- 向量数据库查询:在向量数据库(如Milvus、Pinecone)中检索与问题向量相似度最高的Top K段落,按相似度排序返回。
阶段3:上下文构建与生成
- 答案生成:
- 提示词工程:将检索段落与用户问题拼接为增强Prompt(如“参考以下内容回答:...”)。
- LLM生成:生成模型(如GPT-4)基于上下文生成自然语言答案。若检索无结果,模型拒绝回答以避免幻觉。
- 后处理:标注引用来源、过滤低置信度结果。
三、高级优化策略
- 检索增强:动态滑动窗口分块、混合检索(向量+BM25)提升召回率
召回率=TP/(TP+FN)
其中,TP(真正例)是模型正确预测的正类样本数,FN(假负例)是实际为正类但被模型漏检的样本数
示例1:医疗诊断场景
假设一个癌症检测模型对100名患者进行筛查:
实际患癌人数(正类):20人
模型正确识别的患癌人数(TP):18人
漏诊的患癌人数(FN):2人
召回率计算:
Recall=18/(18+2)=0.9(90%)
表示模型成功检测出90%的真实患癌病例 - 生成控制:迭代生成(如自增强RAG)提升一致性,知识图谱辅助逻辑推理。
动态滑动窗口分块
动态滑动窗口原是图像处理中常用的方法,类似的逻辑应用在文档处理上。通过步长和窗口大小提取互相交叉的文本内容。
- 核心作用:通过动态调整文档分块的边界,解决固定分块导致的前后不相关问题,提升检索片段的相关性。
- 实现方式:
- 滑动窗口算法:将文档划分为重叠或动态调整的窗口(如每段前后保留部分上下文),确保关键信息不被截断。
- 应用场景:长文本处理(如法律条文、技术文档),避免因固定分块丢失关键语义。
混合检索(向量+BM25)
- 核心作用:结合语义向量检索(稠密向量)和关键词检索(BM25),互补两者的优势,覆盖更全面的相关文档。
- 实现方式:
- BM25检索
BM25是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法。BM25的核心思想是基于词频(TF)和逆文档频率(IDF),同时还引入了文档的长度信息来计算文档D和查询Q之间的相关性。
BM25算法的基本公式如下:
- BM25检索
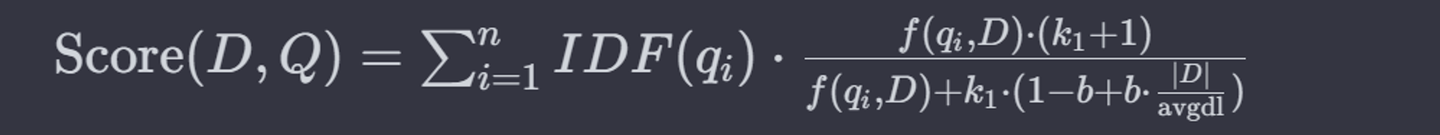
其中:
Score(D,Q) 是文档 D 与查询 Q 的相关性得分。
qi 是查询的第 i 个词。
f(qi, D)是词 qi 在文档 D 中的频率。
IDF(qi) 是词qi 的逆文档频率。
|D| 是文档 D的长度。
avgdl是所有文档的平均长度。
k1 和 b 是可调的参数,通常 k1 在1.2到2之间, b通常设为0.75。
IDF
IDF(Inverse Document Frequency,逆文档频率)是衡量一个词在整个语料库中重要性的指标,其核心思想是:如果一个词在越少的文档中出现,则其区分能力越强,IDF值越高。罕见的词通常有更高的IDF值。以下是具体计算方法:
计算公式
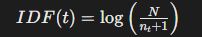
其中:
N 是语料库中文档的总数;
n下标t 是包含词 t 的文档数量;加 1 是为了避免分母为零(平滑处理)
- 向量检索:使用Embedding模型(如BERT)捕捉语义相似性,解决同义词和长尾查询问题。
- 结果合并:归一化两种检索的分数后加权融合(如向量权重0.6,BM25权重0.4),或取并集去重。
- 混合检索优势:
- 短查询:BM25精准匹配关键词
- 长查询:向量检索捕捉语义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号