Text2SQL 技术介绍
Text2SQL(Text-to-SQL)是一种将自然语言转换为结构化查询语言(SQL)的技术,旨在降低非技术人员与数据库交互的门槛,使其能够通过日常语言直接获取数据。
Text2SQL存在许多问题,涉及多表关联、嵌套查询时,模型易生成错误的SQL。
优化数据集和探索新的智能体框架能够优化这种场景。
下文通过探索数据集和Tool-SQL来寻找突破口。
- Text2SQL技术原理与流程
- 核心流程:
- 自然语言理解:解析用户输入,提取实体(如表名、字段名)、操作意图(如查询、统计)及条件(如时间、数值范围)。
- 语义解析:将自然语言映射为逻辑形式(如抽象语法树),并结合数据库模式(Schema)理解表间关系。
- SQL生成:生成符合语法和数据库约束的SQL语句,涉及模板填充或序列生成模型(如Transformer)。
- 关键技术:
- 深度学习模型:如BERT、T5、GPT等预训练模型,用于提升语义理解和生成准确性。
- RAG技术:结合检索增强生成(Retrieval-Augmented Generation),通过外部知识库优化生成结果。
- 发展历程
- 早期阶段(1960s-2010s):基于规则和模板,如LUNAR系统用于阿波罗任务的地质分析。
- AI驱动阶段(2010s后):引入统计机器翻译和神经网络,提升复杂查询处理能力。
- 大模型时代(2020s后):基于LLM(如Codex、SQLCoder)实现高精度生成。
- 主流数据集
-
数据集:
-
Spider:
描述:Spider 是一个大规模的人工标注数据集,设计用于复杂和跨域的语义解析及文本到 SQL 任务。它包含多种数据库模式,适合测试模型在复杂查询(如多表连接、聚合操作)上的能力。
统计数据:
数据库数量:200
问题总数:8655
训练集:7000 个问题
开发集:1000 个问题
测试集:2147 个问题(隐藏)
用途:广泛用于评估跨域泛化能力,特别适合研究复杂 SQL 查询生成。
URL:Spider GitHub -
WikiSQL:
描述:WikiSQL 基于 Wikipedia 表格构建,包含自然语言问题和对应的 SQL 查询,专注于简单查询,主要涉及 SELECT、FROM 和 WHERE 子句。
统计数据:
表格数量:超过 25,000
自然语言问题和 SQL 查询对:超过 80,000
局限性:查询相对简单,无多表链接,适合初级模型评估。
URL:WikiSQL GitHub -
UNITE:
描述:UNITE 是一个统一的基准测试,整合了 18 个公开的文本到 SQL 数据集,旨在提供更全面的评估框架。
统计数据:
表格数量:超过 25,000
自然语言问题和 SQL 查询对:超过 80,000
局限性:查询相对简单,无多表链接,适合初级模型评估。
URL:WikiSQL GitHub -
SParC 和 CoSQL:
描述:SParC 和 CoSQL 是对话式文本到 SQL 数据集,处理多轮对话场景,其中每个问题可能依赖于之前的上下文。
URL
SParC:SParC GitHub
CoSQL:CoSQL GitHub -
ATIS:
描述:ATIS(航空旅行信息系统)是一个较早的领域特定数据集,来自航空领域,包含航班、票价等信息。
URL
ATIS:ATIS GitHub
-
这些数据集的分类可以基于以下特性:
单轮 vs. 对话式:Spider 和 WikiSQL 是单轮,SParC 和 CoSQL 是对话式。
查询复杂度:WikiSQL 偏向简单,Spider 和 UNITE 包含复杂查询。
领域特定性:ATIS 是领域特定,Spider 和 UNITE 是跨域。
规模:UNITE 规模最大,涵盖多个数据集。
处理生成SQL导致数据库不匹配问题的Tool-SQL
Tool-SQL:一个工具辅助的智能体框架,检查并纠正 SQL 查询中的错误。
运用多种工具来诊断 SQL 查询中的问题,并利用基于 LLM 的智能体根据这些工具提供的反馈有针对性地优化这些查询。
Text-to-SQL能纠正SQL查询的执行错误。但在处理数据库不匹配问题上仍然显得不足。
1.1 条件不匹配(Mismatch of Conditions)
SQL 查询中条件子句的不匹配可能导致空结果或错误结果。
在真实场景中,用户问题的多样性和不规则性导致 LLMs 难以将问题与数据库精准对齐并生成正确的 SQL 条件子句。
上图中,Country字段在T1表中,可是生成的SQL选择了错误的表->模型弄混了表下面的字段。
即使选择了正确的表,也可能选择了错误的字段。比如大模型分不清是需要Directed_by还是Written_by才能完成任务.
还可能生成错误的条件。比如用户提及了"todd casey",实际需要的是"Todd Casey"
1.2 更严格约束的不匹配(Mismatch of Stricter Constraints)
在现实生产情况下,SQL往往有更严格,受到SQL的固有特性以及用户自定义的规则制约。
SQL 的固有特性可能涉及与外键关系或列数据类型相关的限制。
用户自定义的规则可能包含诸如“NULL”值或特定数据格式等强制流程。
Tool-SQL设计了两个特定工具来解决上述问题:
• (1)数据库检索器,当 SQL 条件子句与数据库中的任何条目均不匹配时,通过检索相似的数据库单元作为反馈来协助基于 LLM 的代理。
检索器检查条件动作的参数是否与数据库中的条目匹配。若不匹配。提供类似参考字段。
通过检索器能够对齐字段。
• (2)错误检测器,诊断更广泛的错误,包括执行错误以及由 SQL 规则或领域专家定义的更严格约束的不匹配。
由于不熟悉特定领域大语言模型生成的SQL容易产生幻觉,所以需要错误检测。
诊断过程重点检测基于 SQL 特性的以下错误:
• 1)外键关系不匹配
• 2)“JOIN”操作的冗余或缺失
• 3)条件子句中列类型不匹配
• 4)“GROUP BY”子句的缺失或不当使用
- 模块化动作空间构建
将SQL语法解耦为原子化子句(SELECT/WHERE/JOIN等),并为每个子句封装独立的Python函数,形成智能体的可执行动作库。智能体通过组合这些函数生成动作指令链,而非直接输出原始SQL语句。 - 沙盒化执行验证
在Python解释器中构建隔离环境运行动作序列,通过插件化工具集实现多维度校验:
语法校验工具:检测子句组合的语法兼容性
语义校验工具:验证列名、表关系的数据库元数据一致性
逻辑校验工具:分析过滤条件冲突等业务逻辑问题
性能校验工具:预判潜在的全表扫描等低效操作 - 定向反馈学习机制
每个校验工具具备错误模式识别能力,当检测到异常时:
定位具体出错的子句函数及参数
提供包含修正建议的上下文反馈(如"WHERE条件中的时间区间需包含索引列") - 迭代式优化流程
采用闭环优化策略:
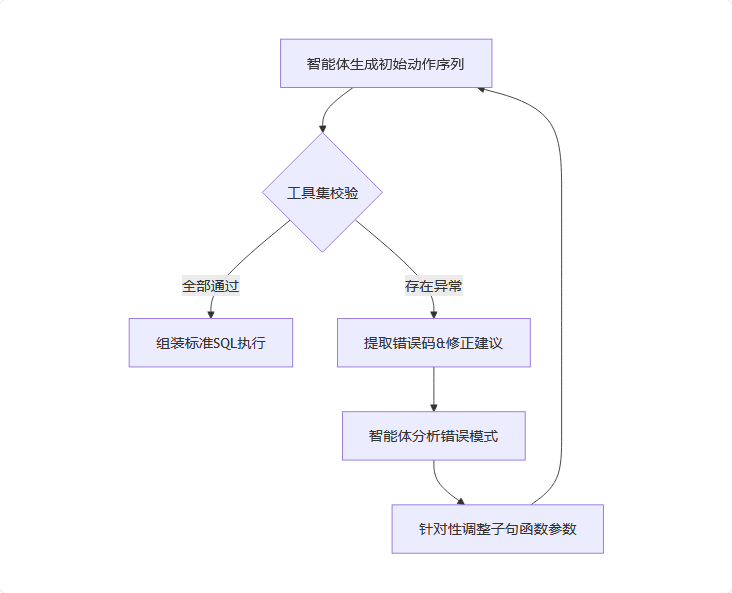
上述工具具有可扩展性,例如,真实世界场景中,对列数据处理有特定要求时,工具可以扩展以检测是否排除了“NULL”值或是否正确处理了具有特定格式的列。
效果评估
评估指标
执行准确率(EX)和精确匹配准确率(EM)这两项在Text-to-SQL任务中常用的评估指标来评估Tool-SQL的表现。
执行准确率(EX)定义:计算SQL执行结果正确的数量在数据集中的比例。
缺点:存在高估的可能。因为一个完全不同的非标准的SQL可能查出于与标准SQL相同的结果(例如,空结果),这时也会判为正确。
精确匹配准确率(EM)计算模型生成的SQL和标注SQL的匹配程度。
缺点:存在低估的可能。如一个SQL执行结果是正确的,但于标注SQL的字符串并非完全匹配
对于给定的问题可能存在多个正确的SQL查询,EM指标可能会将部分正确的SQL查询判定为不正确。所以,Tool-SQL将执行准确率用作主要评估指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号