2022_BUAA_OO第一单元总结
写在前面
首先祝贺我自己还算比较平稳地完成了OO的第一单元任务,尽管在强测中丢失了一些分数,但是在完成三次作业后,第一单元的设计过程还是给我带来了很大的启发。在本次博客中,我将从作业架构、Bug分析、课程体会、单元总结四个方面介绍我OO第一单元的旅程。
一、作业架构
从我个人的理解出发,OO作业有一大特点就是"架构依赖"——只有建立起好的架构设计,我们才能在每一个层次舒服地使用数据结构进行数据处理。我与许多位同学讨论过架构设计的基本思路,能够在基准路线上达成一致;至于具体的实现方法,则不尽相同。我认为我的架构并不十分完善,更说不上优秀,但还是有一些优点,还是值得记录一下,以便日后思考、总结、避雷。
三次作业的UML类图及分析
此处首先声明,由于本人的代码实现中不存在继承关系、也不存在接口实现,但是的确具有一定的层次划分,故而UML类图中可能会根据需要添加一些箭头以表示层次间的关系,请不要误读。另外,一些用于测试或是没有使用的方法和变量就不在类图中列出了。
第一次作业
架构及实现方法简析
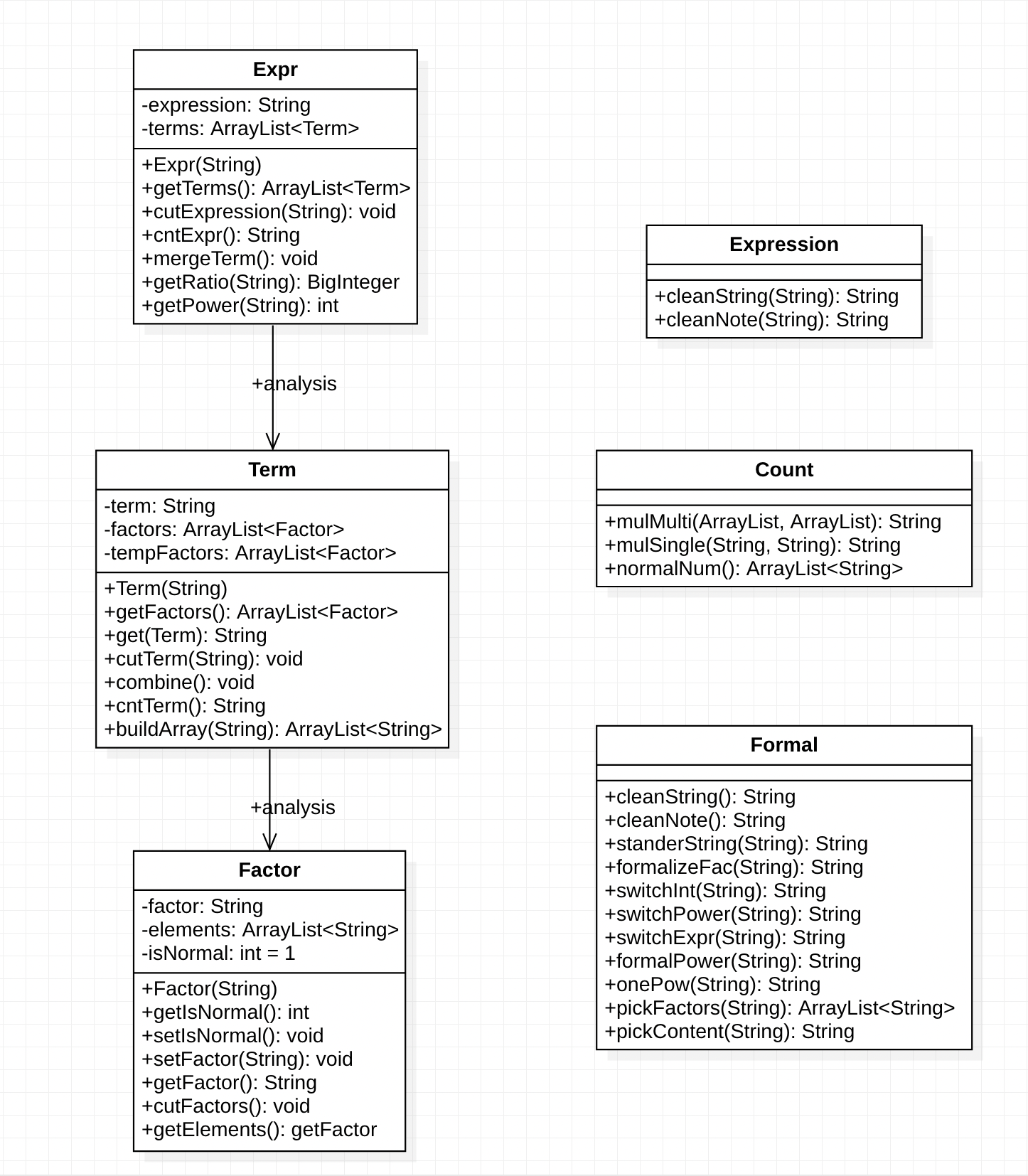
第一次作业的基本思路是利用正则表达式进行自上而下的解析,从而得到结果进行计算。由于不包含嵌套括号,只需一次解析即可计算结果。依照下面的层级进行解析计算即可。
表达式\longrightarrow项\longrightarrow因子
$$
为此,设计了Expr、Term、Factor这三个类。首先重写了Expr的构造方法,在构造Expr时需要给入一个String作为表达式输入;Expr中的cutExpression方法将会使用正则匹配的方法切分这一表达式,并将得到的子串用于构造一个Term,存入Expr自带的一个ArrayList<Term>容器当中(这是参考了第一次实验的写法)。通过不断的遍历,可以将表达式彻底切分为一个一个的Term,并在Expr层次中存储,便于在此层次调用下一层次的Term。这便是解析的第一步。自然而然地,我们便会联想到解析的第二步该怎么做——在Term类和Factor类中再次建立一层这样的关系。这样一来,我们就建立了一个三层的层次关系,并且能够自上而下地将表达式解析为因子。
解析完毕,我们需要的是计算,与刚刚解析过程的自上而下相反,这是一个自下而上的过程。只要解析的思路足够清晰,就会发现我们只需要在Term层次乘法计算其Factor并返回结果、在Expr层次加法计算Term并返回结果就好了。不过在此处我遇到了一个难题——处理的目标是字符串,其中有乱七八糟的x、2*x、x**3这样的因子,它们要如何做加法?如何做乘法?经过与同学的讨论,我在解析的过程中添了一笔——将所有的因子都归范围a*x**b的标准形式。这样的好处不言而喻,只需在计算的时候提出系数(Ratio)和幂(Power)的部分即可进行普遍的计算。至此,一套清晰的解析思路就完成了;也正是这一次的分析,为我准备好了后面两次作业的指导思想。
除了主要的解析思路之外,为了易于对字符串进行处理,我构造了一个Formal类用于存放常用的处理字符串的方法,并将它们定义为静态方法(如除空白符、合并冗余符号、字符串转BigInteger等);另外,构造了一个Count类存放多项式乘多项式的方法,计算的过程会调用这个类的方法。如此一来,整体的架构和层次便比较清晰了。
架构优缺点与艰辛的实现过程
优点:从总体上评价这次架构,是主体通透的的。自上而下和自下而上的两个过程都比较清晰;静态方法的构造提高了代码的复用率;且这是在我不知道递归下降的处理方法时想出来的,这使得我在后面的作业中都可以沿用这一套方法。其它的一些思路也很值得以后参考。至少在架构设计上,避免了"重构"。
缺点:当然,毕竟是第一次作业,缺点总是有的,这里主要映射在一些细节上。例如,对于因子中的表达式项,我并未打算继续将其作为表达式继续解析处理,而是看作一个因子,在当层就计算得到结果并向上返回。这样做有许多缺点:
-
不能解析含有嵌套括号的表达式(虽然题目没有要求,但主要原因是我没有想到)
-
极大削弱了代码的可扩展性(如果要添加一些其他的因子怎么办?又要重写一遍Factor层的计算?)
-
提高了解析与计算的耦合度
这是一个非常致命的缺点。从架构上不仅不健康,还使得我书写代码的时候思路非常混乱:既要解析,又要计算。这直接导致了我第二次作业的彻底重构。
其它的缺点中比较令我印象深刻的还有:
-
没提前规范好项和表达式的符号——这里缺一个"+",那里又有一个"+"
-
乘法计算的割裂。我将乘法分为单项式相乘、单项式乘多项式、多项式相乘,这其实很笨——但归根结底,这一缺陷延伸自上面提到的"致命的缺点"。我固执地将只解析了一遍的因子看作"一切的终结",导致我割裂了乘法计算。
-
加法计算写在了解析层次当中。我在Expr内书写了一个"表达式加法"的方法,其实这样不好,这会提高计算和解析的耦合度。
-
复用代码考虑不周。例如,取出括号中的内容应是非常常用的方法,但我却在很多类中都写了一遍这个方法;或许写作一个静态方法(当然,更加优秀的结构可以写作继承方法)是更好的选择。
种种......
不过,即便是拥有了正确的架构设计,想要将架构顺利实现也是非常有难度的。在第一次作业实现的过程中,我遇到了很多问题,磕磕绊绊地才完成了这一次作业。这里的难度主要源自:
-
本人刚开始接触Java,很多方法的使用实在是不熟练,不知道该如何利用数据结构解决问题
-
边界情况的疏忽。出现0次幂多项式怎么办?出现复杂的多项式怎么办?
-
种种不熟练导致的设计不统一。如将复用率高的代码进行抽离是实现过程中想到的方法,导致代码混乱。
-
解析和计算的耦合过高,导致思路混乱。这一点在上面也提到过了。
-
正则表达式的构建过于麻烦,极其容易出错。
基于上面的种种原因,仅仅在第一次作业,我就经历了一次重构、一次为时一天的Debug阶段,归根结底其原因是架构的细节没有设计好。于是乎在第二次作业中,我对其中的一些方面进行了一定的改进。
基于度量分析第一次作业的程序结构(除MainClass)
代码规模
| Class | 属性个数 | 方法个数 | 代码规模/行 |
|---|---|---|---|
| Count | 0 | 4 | 66 |
| Expr | 2 | 9 | 100 |
| Expression | 0 | 2 | 30 |
| Factor | 3 | 9 | 59 |
| Formal | 0 | 11 | 207 |
| Term | 3 | 9 | 96 |
类的OO度量
| Class | OCavg | OCMax | WMC |
|---|---|---|---|
| homework.Count | 2.75 | 4.0 | 11.0 |
| homework.Expr | 2.2222222222222223 | 8.0 | 20.0 |
| homework.Factor | 1.4444444444444444 | 3.0 | 13.0 |
| homework.Formal | 3.5454545454545454 | 11.0 | 39.0 |
| homework.Term | 1.8888888888888888 | 4.0 | 17.0 |
| homework.Test | 3.0 | 3.0 | 3.0 |
| task.Expression | 2.5 | 4.0 | 5.0 |
| Average | 2.369565217391304 | 4.75 | 13.625 |
方法复杂度分析
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| homework.Count.normalNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.getExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.getPower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.getRatio(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.getElements() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.getFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.getIsNormal() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.setElements(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.setFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.setIsNormal(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.cleanNote(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.standerString(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.MainClass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.Term(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.getTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.setTerm(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Expression.cleanNote(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.Expr(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Expr.cntExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Expr.cutExpression(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Expr.printTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Factor.printElements() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Formal.pickContent(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Formal.pickFactors(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Term.buildArray(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Term.cutTerm(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Term.printFactor() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Count.mulSingle(String, String) | 2.0 | 1.0 | 3.0 | 3.0 |
| homework.Factor.Factor(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| homework.Formal.switchPower(String) | 2.0 | 3.0 | 1.0 | 3.0 |
| homework.Term.cntTerm() | 2.0 | 2.0 | 3.0 | 3.0 |
| homework.Test.testMulti() | 2.0 | 1.0 | 3.0 | 3.0 |
| homework.Count.mulMulti(ArrayList, ArrayList) | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Factor.cutFactors() | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Formal.formalizeFac(String) | 3.0 | 3.0 | 3.0 | 3.0 |
| homework.Formal.onePow(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Formal.switchInt(String) | 3.0 | 3.0 | 1.0 | 3.0 |
| homework.Formal.cleanString(String) | 4.0 | 1.0 | 3.0 | 4.0 |
| task.Expression.cleanString(String) | 4.0 | 1.0 | 3.0 | 4.0 |
| homework.Count.mergeFactor(String) | 5.0 | 1.0 | 3.0 | 4.0 |
| homework.Term.combine() | 5.0 | 1.0 | 4.0 | 4.0 |
| homework.Formal.formalPower(String) | 10.0 | 1.0 | 6.0 | 6.0 |
| homework.Expr.mergeTerm() | 11.0 | 2.0 | 8.0 | 8.0 |
| homework.Formal.switchExpr(String) | 28.0 | 2.0 | 9.0 | 11.0 |
| Total | 102.0 | 55.0 | 100.0 | 109.0 |
| Average | 2.217391304347826 | 1.1956521739130435 | 2.1739130434782608 | 2.369565217391304 |
总体的工程量并不算巨大,但由于复用代码的规划不佳,导致我在第一次作业中书写了许多冗余的方法,故而第三个表格十分冗长。类与类之间的界限算是比较明确,但是很多细节还是有待提高,这会体现在第二次作业中。
第二次作业
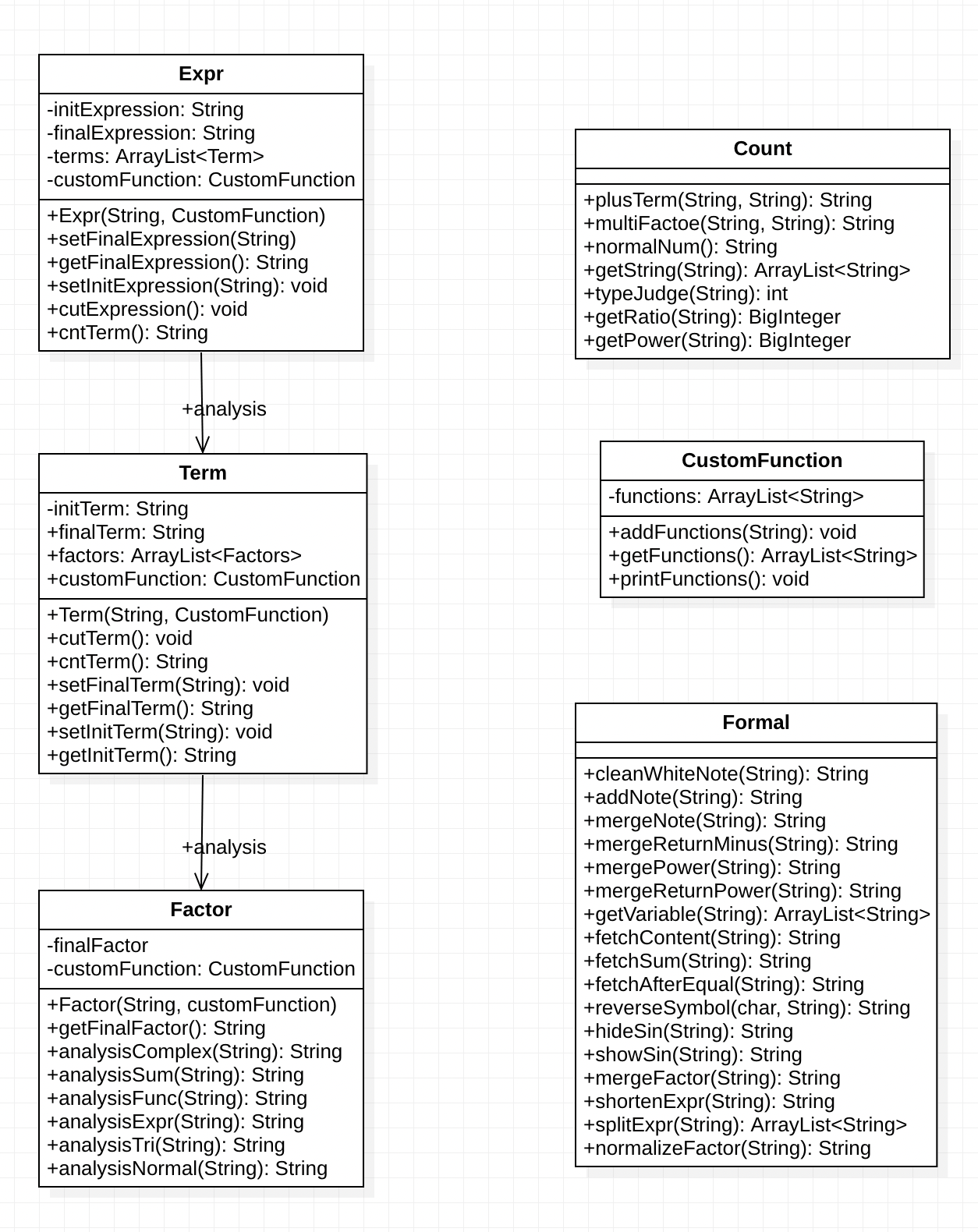
架构方法及实现简析
第二次作业相比第一次作业,增加了表达式的扩展内容。这其中最主要的改动包括:
-
新增自定义函数因子,不可递归定义、不可递归调用。
-
新增求和函数因子,只能单独使用。
-
新增sin、cos三角函数。
当然,具体到细节层面还包括一些数据限制、IO修改等,不过这些改动只要是做过作业的同学都心知肚明。我认为我们最需要关注的就是因子种类的复杂化和括号层次的加深。经历了第一次作业的毒打后,我决定先深度设计架构——包括各种细节——然后再进行具体实现。总体的解析思想没有发生特别大的变化,但我开始进行递归解析的尝试。
表达式\longrightarrow项\longrightarrow因子\longrightarrow整数因子、幂函数因子、三角函数因子、表达式因子、自定义函数因子、求和函数因子
$$
上面是一次解析的完整过程。相比于第一次作业,我在因子解析的时候增加了类型判断的系列方法,并且对每一种因子专门书写了一个类用于其标准化。为了便于计算,我将因子分出两个基本类:
三角函数因子:[+-][(sin)|(cos)][(expression)]**n
$$
普通因子:[+-]a*x**b
$$
这两类因子是计算的根源——当然,第二次作业的三角函数因子自带的表达式内部还不需要计算——进行多轮解析的目标就是为了得到这两类因子。于是乎,除了这两类因子外的所有因子,我都将其看作表达式对待,送入一个新的Expr进行解析。进行了足够轮次的解析后,总能够得到最基本的两类因子。然后我们可以通过自下而上的计算,得到最终的结果。
在Expr、Term和Factor类仍旧是写入了一些变量和解析、计算的方法。另外,在第一次作业的基础上抽离出了一些复用率高的方法,写入Formal类成为静态方法;强化了Count类,用于存放加法和乘法的方法;新建了一个CustomFunction类,用于存放自定义函数,便于各层次使用。
优化
在第二次作业当中,对第一次作业的一些不足之处进行了优化:
-
符号归一化。每次一解析出的内容,都会经过一个
addNote方法来添加串首符号,才能够被继续解析处理。 -
抛弃正则的切分识别方法,改用模拟栈的循环遍历进行项和因子的切分。这是一个非常大的改进,例如对于表达式:
-a+(b-c)
$$
进行将表达式切分为项的模拟。从第一个字符开始遍历,并在循环之初设置一个int类型的变量pairBracket,用于记载括号层数,其初始值为0。遇到左括号加上1,遇到右括号减去1;第一次遇到加减号,则进入一个内层循环,开始摘取切分个体的内容。摘取过程中,再次遇到加减号且括号层数为0,则结束摘取。即对上面表达式摘取的结果就是得到了两个项:
-a、+(b-c)
$$
很显然,这种方法也适用于"将项切分为因子"的过程。当然,遇到一些特殊情况需要特殊的处理,在此不赘述。
-
进一步降低计算和解析的耦合度。本次,我直接将所有的计算方法搬出了解析类,于是写代码的时候感到十分的清晰:该写什么就写什么,不会出现第一次作业的混乱现象。
-
代码复用优化。进一步归纳了复用率高的方法,并写入静态方法类中。
-
除去了不需要的类与方法
这些优化使得我在实现基本功能时更加顺利。但是本次设计在设计和细节上也有许多考虑不周之处,使得我在强测中丢失很不少分数,这会在下面做介绍。
缺点
本次设计的缺点也是很明显的。
-
采用ArrayList容器放置基本因子,使得加减乘计算、合并同类项以及化简的操作十分困难。这是因为当时我不会使用HaspMap存放数据,我在这里吃了很大的亏。
-
没有考虑一些新增因子对计算带来的麻烦。这使得我的计算方法也非常丑陋且麻烦,无法将三角函数合并而只能直接追加到已有表达式的后方,丢失了很多性能分。这里的失误和第一个缺点也有很大的联系。
-
对细节的考虑不周(0次幂的符号、自定义函数的符号都没有考虑周全)
-
将多项式因子仍看作一个"因子",导致因子层次还需要考虑加法。(这一点在第三次作业中进行了力所能及的优化的尝试)
-
基本项还不够基本。将三角函数和幂函数区分开来看待,其实并不优越,反而会带来很多麻烦,因为这会使得我们缺少统一的处理方法。
总的来讲,这一次的设计其实是有一些不全面的——对解析的过程做了很好的规划设计,但是对计算、化简的考虑十分不周全,导致到最后只能提交一个破烂的版本;写好的优化版本也是Bug层出不穷。由于对细节考虑不周,在强测中也失掉了三个点的分数,非常不值得。在第三次作业中,我在这些方面进行了一些优化尝试,不过结果还是不尽人意,编程能力还是有待加强啊。
基于度量分析第二次作业的程序结构(除MainClass)
代码规模
| Class | 属性个数 | 方法个数 | 代码规模/行 |
|---|---|---|---|
| Count | 0 | 7 | 110 |
| CustomFunction | 1 | 3 | 26 |
| Expr | 4 | 6 | 80 |
| Factor | 2 | 8 | 244 |
| Formal | 0 | 17 | 256 |
| Term | 4 | 7 | 92 |
类的OO度量
| homework.Count | 2.5714285714285716 | 8.0 | 18.0 |
|---|---|---|---|
| homework.CustomFunction | 1.3333333333333333 | 2.0 | 4.0 |
| homework.Expr | 2.3333333333333335 | 8.0 | 14.0 |
| homework.Factor | 4.375 | 8.0 | 35.0 |
| homework.Formal | 3.6470588235294117 | 18.0 | 62.0 |
| homework.MainClass | 2.0 | 2.0 | 2.0 |
| homework.Term | 2.4285714285714284 | 10.0 | 17.0 |
| Average | 3.1020408163265305 | 8.0 | 21.714285714285715 |
方法复杂度分析
| homework.Count.getPower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
|---|---|---|---|---|
| homework.Count.getRatio(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Count.normalNum() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Count.plusTerm(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.CustomFunction.addFunctions(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.CustomFunction.getFunctions() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.Expr(String, CustomFunction) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.getFinalExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.setFinalExpression(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Expr.setInitExpression(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Factor.getFinalFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.hideSin(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.mergeNote(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.mergePower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.mergeReturnMinus(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.mergeReturnPower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.shortenExpr(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Formal.showSin(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.Term(String, CustomFunction) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.getFinalTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.getInitTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.setFinalTerm(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.Term.setInitTerm(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| homework.CustomFunction.printFunctions() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Expr.cntTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Formal.addNote(String) | 1.0 | 2.0 | 1.0 | 2.0 |
| homework.MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Term.cntTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| homework.Count.typeJudge(String) | 2.0 | 2.0 | 1.0 | 2.0 |
| homework.Factor.Factor(String, CustomFunction) | 2.0 | 1.0 | 2.0 | 2.0 |
| homework.Formal.cleanWhiteNote(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Formal.fetchContent(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Formal.fetchSum(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| homework.Formal.normalizeFactor(String) | 3.0 | 3.0 | 3.0 | 3.0 |
| homework.Factor.analysisComplex(String) | 4.0 | 5.0 | 5.0 | 5.0 |
| homework.Factor.analysisNormal(String) | 5.0 | 3.0 | 3.0 | 3.0 |
| homework.Formal.fetchAfterEqual(String) | 5.0 | 1.0 | 3.0 | 4.0 |
| homework.Factor.analysisSum(String) | 6.0 | 2.0 | 3.0 | 5.0 |
| homework.Count.multiFactor(String, String) | 7.0 | 1.0 | 4.0 | 4.0 |
| homework.Formal.getVariable(String) | 7.0 | 1.0 | 4.0 | 4.0 |
| homework.Factor.analysisExpr(String) | 9.0 | 3.0 | 5.0 | 5.0 |
| homework.Factor.analysisFunc(String) | 11.0 | 4.0 | 6.0 | 8.0 |
| homework.Factor.analysisTri(String) | 12.0 | 2.0 | 6.0 | 6.0 |
| homework.Formal.reverseSymbol(char, String) | 15.0 | 2.0 | 5.0 | 7.0 |
| homework.Count.getSingle(String) | 19.0 | 8.0 | 8.0 | 8.0 |
| homework.Expr.cutExpression() | 19.0 | 8.0 | 8.0 | 8.0 |
| homework.Formal.splitExpr(String) | 19.0 | 8.0 | 8.0 | 8.0 |
| homework.Term.cutTerm() | 28.0 | 8.0 | 9.0 | 10.0 |
| homework.Formal.mergeFactor(String) | 46.0 | 6.0 | 17.0 | 18.0 |
| Total | 233.0 | 100.0 | 141.0 | 152.0 |
| Average | 4.755102040816326 | 2.0408163265306123 | 2.877551020408163 | 3.1020408163265305 |
由于许多地方采用了循环遍历的分析手段,导致部分类和方法的复杂度有所提高。Formal类和Factor类承担了最重要的解析任务,故而其复杂度最高。但是我对程序的耦合程度和部分类的复杂度还是比较满意的——实现解析和计算两个功能部分的代码区分的比较开,且Expr类和Term类的复杂度都不高。
第三次作业
经过第二次作业的考验,我认为我对解析和计算两个部分的关系已经有了比较好的了解,就没有再使写额外的静态方法进行计算操作,而是全部写在了类层次当中。
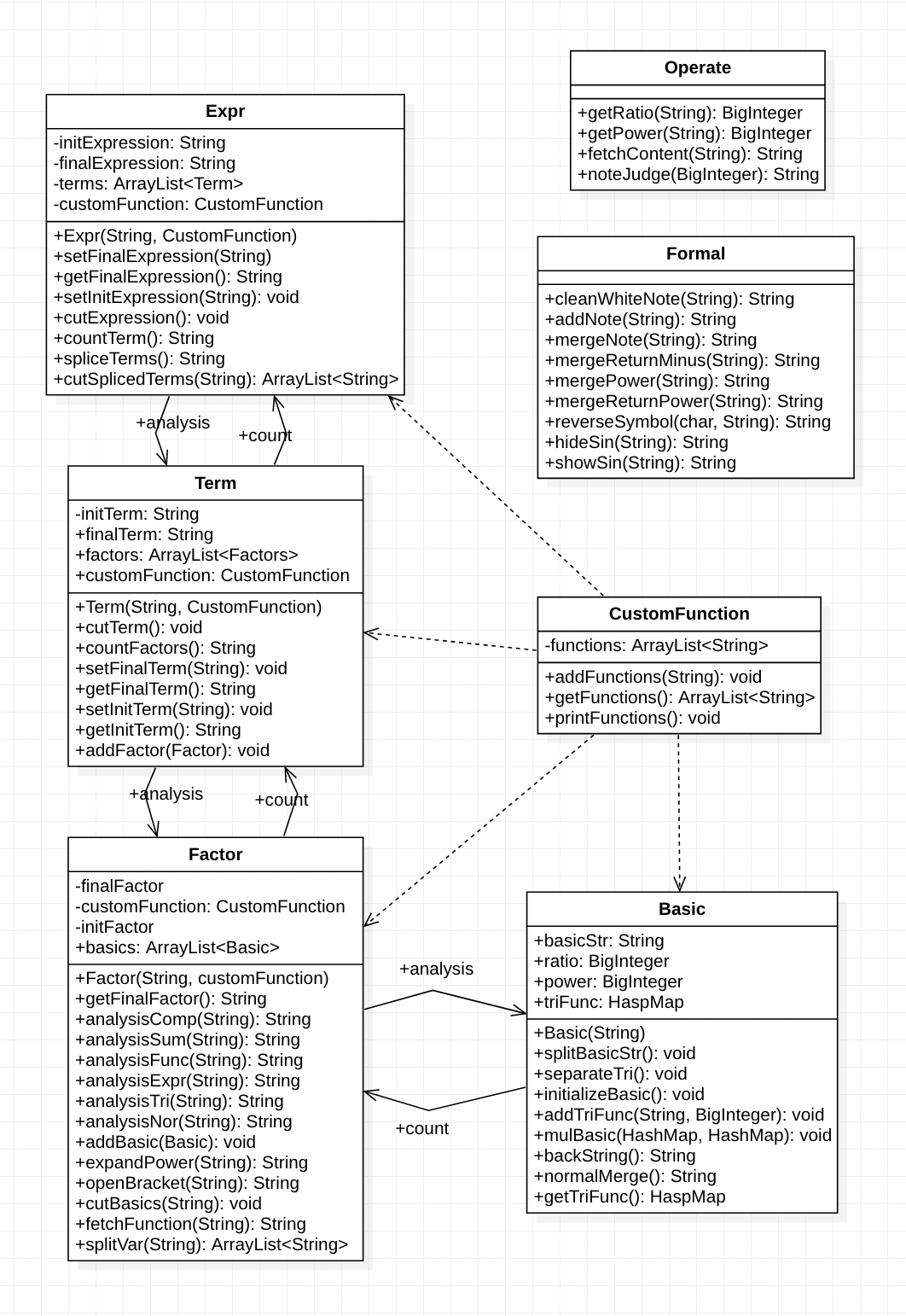
解析的基本思路没有发生变化,但是为了更好地进行存储计算,在层次里新增了一个Basic类,用于应对Factor是多项式的情况;另外,将基本的因子进行了重新规范,我给它起名叫做"基本项":
[+-]a*x**b*[((sin)|(cos))(expression)**n]*
$$
这样的好处不言而喻——我们在计算的时候终于不用左右兼顾,直接对上面的格式写一个计算的方法就好。为了这样的优化,Basic类要有这些功能:
-
存储a*x**b的系数和幂
-
使用容器HashMap存储三角函数的三角部分和指数部分
-
将存储的数据组合成字符串,向上返回
且由于HaspMap的特性,在解析的时候就可以进行简单的同类项合并(遍历key集合即可),我认为这样的存储方法和结构是很优越的。
优化
本次作业相对第二次作业的优化其实并不多,因为在主要的数据结构和字符串处理上第二次作业已经做得比较好了。比较大的进步是在新增一个Basic层次之后,复杂因子及三角函数的计算变得简单了起来。其余还有一些小的修改:
-
改进了自定义函数的参数识别方法。之前是使用
split()方法直接劈分形如f(x,sin(x),x**3)这样的式子得到参数。但当函数能够递归调用之后,这样的方法在遇到f(x,f(x,x))时便会出错。对此,我采用了之前提到过的"模拟栈+循环遍历"的办法解决了问题。(栈真是个好东西!) -
将计算的方法融合到了层次结构中,减少了静态方法的声明。
-
优化了带幂函数的表达式因子的解析方法。原本是直接对其进行展开计算,现在改为展开后继续解析并计算。
失败的性能优化尝试
在修改了存储结构后,新的结构理论上应该更便于性能优化。然而我由于忙于其他事情,始终没能抽出时间完成这一部分,在强测中丢失了性能分。这算是一个遗憾吧
基于度量分析第三次作业的程序结构(除MainClass)
代码规模
| Class | 属性个数 | 方法个数 | 代码规模/行 |
|---|---|---|---|
| Basic | 4 | 16 | 193 |
| CustomFunction | 1 | 3 | 26 |
| Expr | 4 | 11 | 158 |
| Factor | 4 | 21 | 317 |
| Formal | 0 | 9 | 75 |
| Term | 4 | 11 | 126 |
| Operate | 0 | 4 | 41 |
类的OO度量
| task.Basic | 2.8125 | 11.0 | 45.0 |
|---|---|---|---|
| task.CustomFunction | 1.3333333333333333 | 2.0 | 4.0 |
| task.Expr | 3.090909090909091 | 8.0 | 34.0 |
| task.Factor | 2.9047619047619047 | 8.0 | 61.0 |
| task.Formal | 2.0 | 7.0 | 18.0 |
| task.MainClass | 2.0 | 2.0 | 2.0 |
| task.Operate | 1.5 | 2.0 | 6.0 |
| task.Term | 2.3636363636363638 | 10.0 | 26.0 |
| Average | 2.5789473684210527 | 6.25 | 24.5 |
方法复杂度分析
| task.Basic.getBasicStr() | 0.0 | 1.0 | 1.0 | 1.0 |
|---|---|---|---|---|
| task.Basic.getPower() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.getRatio() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.getTriFunc() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.initializeBasic() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.separateTri() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.setBasicStr(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.setPower(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.setRatio(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.CustomFunction.addFunctions(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.CustomFunction.getFunctions() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Expr.Expr(String, CustomFunction) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Expr.getFinalExpression() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Expr.setFinalExpression(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Expr.setInitExpression(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.Factor(String, CustomFunction) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.addBasic(Basic) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.analysisFunc(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.getBasics() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.getFinalFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.getInitFactor() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.opedBracket(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.setFinalFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Factor.setInitFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.hideSin(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.mergeNote(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.mergePower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.mergeReturnMinus(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.mergeReturnPower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Formal.showSin(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Operate.getPower(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Operate.getRatio(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.Term(String, CustomFunction) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.getFinalTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.getInitTerm() | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.setFinalTerm(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Term.setInitTerm(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| task.Basic.backString() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.CustomFunction.printFunctions() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Expr.printFinalTermAndFinalFactor() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Expr.printTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Expr.printTermAndFinalFactor() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Expr.spliceTerms() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Formal.addNote(String) | 1.0 | 2.0 | 1.0 | 2.0 |
| task.MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Operate.fetchContent(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Operate.noteJudge(BigInteger) | 1.0 | 2.0 | 1.0 | 2.0 |
| task.Term.printFactor() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Term.printFinalFactor() | 1.0 | 1.0 | 2.0 | 2.0 |
| task.Basic.Basic(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| task.Basic.mulBasic(HashMap, HashMap) | 2.0 | 1.0 | 3.0 | 3.0 |
| task.Factor.analysisExpr(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| task.Factor.analysisFactor(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| task.Factor.analysisTri(String) | 2.0 | 1.0 | 2.0 | 2.0 |
| task.Factor.fetchFunction(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| task.Factor.getFunction(String) | 3.0 | 1.0 | 4.0 | 4.0 |
| task.Formal.cleanWhiteNote(String) | 3.0 | 1.0 | 3.0 | 3.0 |
| task.Basic.addTriFunc(String, BigInteger) | 4.0 | 3.0 | 4.0 | 4.0 |
| task.Basic.backMergedString() | 4.0 | 1.0 | 3.0 | 3.0 |
| task.Factor.analysisComp(String) | 4.0 | 1.0 | 5.0 | 5.0 |
| task.Factor.analysisSum(String) | 4.0 | 1.0 | 3.0 | 3.0 |
| task.Factor.expandPower(String) | 4.0 | 2.0 | 4.0 | 4.0 |
| task.Factor.analysisNor(String) | 5.0 | 1.0 | 3.0 | 3.0 |
| task.Term.countFactors() | 7.0 | 1.0 | 5.0 | 5.0 |
| task.Expr.countTerms() | 9.0 | 4.0 | 6.0 | 6.0 |
| task.Factor.findPos(String, String) | 9.0 | 3.0 | 7.0 | 8.0 |
| task.Factor.splitVar(String) | 15.0 | 7.0 | 6.0 | 8.0 |
| task.Formal.reverseSymbol(char, String) | 15.0 | 2.0 | 5.0 | 7.0 |
| task.Expr.cutSplicedTerms(String) | 17.0 | 8.0 | 6.0 | 8.0 |
| task.Factor.cutBasics(String) | 17.0 | 8.0 | 6.0 | 8.0 |
| task.Expr.cutExpression() | 19.0 | 8.0 | 8.0 | 8.0 |
| task.Basic.splitBasicStr() | 20.0 | 10.0 | 10.0 | 11.0 |
| task.Basic.normalMerge() | 24.0 | 11.0 | 10.0 | 11.0 |
| task.Term.cutTerm() | 28.0 | 8.0 | 9.0 | 10.0 |
| Total | 236.0 | 140.0 | 182.0 | 196.0 |
| Average | 3.1052631578947367 | 1.8421052631578947 | 2.3947368421052633 | 2.5789473684210527 |
真是太多表格了!这只能怪我重构了三次(笑)。不过肉眼可见,第三次作业的复杂度和结构相对于第二次作业也有了提升。这说明我对结构的掌握也有了一定的提升毕竟重构了三次。
小结
完成第一单元的任务后,我感觉还是收获良多。虽然没有体会到迭代开发的乐趣,但是在经过了多次重构以及层次架构设计
二、Bug分析
公测与互测
首先列出我在三次公测与互测中的测试情况
| 作业次数 | 弱中测 | 强测 | 互测 |
|---|---|---|---|
| Homework1 | 通过 | 通过 | 0/21 |
| Homework2 | 通过 | 三个点WA | 1/11 |
| Homework3 | 通过 | 通过 | 4/12 |
第一次作业的完成情况最佳、第三次之、第二次再次。但得分并不能准确反映我对题目和编程思想的理解,我认为我在第三次作业中的收获是最大的。不过,分数并不重要,分析总结自己的错误,吸取经验教训才是最重要的,我将举出并分析我在测试中程序犯下的经典错误。
Homework1
在第一次作业中,尽管没有被发现Bug,但是作业截止前的Debug阶段还是让我难以消受。
零次幂:忘记对零次幂表达式因子的特殊处理,发生了运行时错误。
正则表达式出错:正则表达式无法判断一些输入情况,属于考虑上的疏忽。但不得不承认正则表达式的切分方法很容易出错。这也导致我在第二次作业中更换了切分的方法
Homework2
第二次作业的问题主要也是由于考虑不周。
自定义函数符号出错(强测):自定义函数解析完毕向上返回的时候,忘记按照规范在串首判断是否需要添加符号,导致有时正负解析错误。
零次幂(强测、互测):表达式因子出现零次幂时,直接返回1,忘记根据其符号判断是否需要返回-1
Homework3:
第三次作业的问题在互测被发现了。
变号出错(互测):一般计算-(a+b)这样的式子时,要先计算内部,再反转符号;而我的程序先反转了内部的符号,再进行计算。这是一个比较大错误,我也很惊讶这个错误没在强测中被测出来。
求和函数sum(互测):本次作业中,求和函数可能是这种形式:
sum(i,s,e,i**2)
$$
在正常的输入输出当中,形如2**3这种数据是非法的;但是根据求和函数的定义,上面这种情况却是可能出现的!但我的程序并没有对这种"合法的非法情况"进行考虑,故而发生了运行时错误。修复这个Bug,只需要在替换所有的i时套上括号即可。
小结:
总体上来讲,我做的还是比我的预期好很多的。尽管很多分数都不应该丢掉,但是对于编程能力较弱的我来说,还是应该一步一步来。本次的Bug有很多都边界情况发生了问题;也有一些逻辑上的问题。很多师兄建议我学习一下自动化测试的方法,我现在也开始深感其必要性,毕竟程序员要对自己的代码负责
Hack
介绍完我的Bug,也要介绍一下我"帮别人Debug"的思路。其实我并不是一个热衷于Hack别人的人,但是这个阶段还是比较有意思的;活跃度也关乎成绩。我Hack别人的主要思路大致如下:
-
边界。我犯的错误,别人也可能反。在给自己的程序Debug过程中,会使用零次幂、0+0、超长整数等边界情况进行测试
-
针对优化进行的攻击。有的同学会进行一些追求极致性能的优化,这会使得他们在一些简单情境下犯错。
-
针对解析方法进行的攻击。尤其是正则解析法,这种解析方法很容易出错。
-
共享数据。一些同学提供的测试点也很有参考价值
由于不会自动化测试,我的Hack并不算猛烈。但不能因为要Hack而去学习测试,学习测试永远是为了自我提高
三、总结分析
1.设计体会
由于最初的架构不佳,几乎每一次作业我都进行了一次重构。不过,虽然代码在不断重构,设计思想却是不断迭代的。从最初的只能解析一层的、计算和解析糅合在一起的程序,到最后的能够进行多层解析、耦合度低的程序,这期间设计的思想是经过了很大的完善和修补的;为了顺利编写代码,我用于设计而写的手稿也有几张草稿纸之多,尽自己所能规范了每一处的细节处理方法。唯一可惜的就是重构占去了我很多的时间,导致我没能够进行很多的优化,这算是第一单元的一些遗憾了。不过还是在第一单元的设计过程中收获良多,"领会精神"永远是更重要的。
2.本阶段OO课程的心得体会
首先一个字:难!
到目前为止的OO作业,包括pre、第一单元、上机训练,都给我一种很强的压迫感。作业截止时间的紧迫、程序量的巨大、对Java语言的陌生、设计思路的新颖,对我来说都是很大的阻力。听吴际老师说,以后会将pre课程放入暑期学期单独开课,我私以为这是很好的做法,毕竟不是人人都有很好的编程基础,或者说是几天速成的自学能力,或者说是愿意在寒假预习。有Java基础的同学,对各种数据结构的使用应当是信手拈来。当然,想要解决难题,也不仅仅要靠基础,还需要学会自己搜索资源、积极与同学讨论交流设计思想,这都是解决困难的很好的办法。我希望未来的OO课程在不失去难度的同时,能够让更多人更好地上手。
另外,助教团队的高度负责精神也让我很是感动。精心设计的题目和指导书、面对突发情况的高效解决、对同学疑问的耐心解答等,都是每位同学有目共睹的。北航六系许多优秀的课程也都是在强大的助教团队下打磨而成。我感到很幸运,能在如此优秀的助教团队的陪伴下学习这门课程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号