文本相似性算法
相似度计算关键组件相似度计算方法有2个关键组件:表示模型、度量方法。
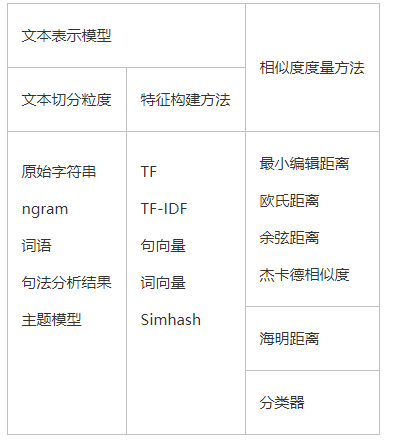
常见的文本表示模型和相似度度量方法
前者负责将物体表示为计算机可以计算的数值向量,也就是提供特征。
后者负责基于前面得到的数值向量计算物体之间的相似度。欧几里得距离、余弦距离、Jacard相似度、最小编辑距离
距离的度量方式欧几里得距离

使用python计算欧式距离:
distance = numpy.linalg.norm(vec1 - vec2)
相似度为:
similarity = 1.0/(1.0 + np.linalg.norm(dataA - dataB))
余弦距离余弦距离的计算方式:
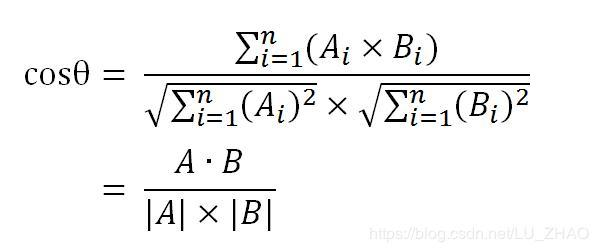
与欧氏距离的区别:
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)
Jacard相似度
Jaccard距离也称为杰卡德距离,一般用来度量两个集合间的相似度大小。假设两个结合为A和B,那么两者的jaccard相似度计算式为:
jaccrad距离的思想很简单,两个集合共有的元素越多,二者越相似。
最小编辑距离
最小编辑距离是一种经典的距离计算方法,用来度量字符串之间的差异。它认为,将字符串A不断修改(增删改)、直至成为字符串B,所需要的修改次数代表了字符串A和B的差异大小。当然了,将A修改为B的方案非常多,选哪一种呢?我们可以用动态规划找到修改次数最小的方案,然后用对应的次数来表示A和B的距离。
simhash算法
常见的余弦夹角算法、欧式距离、Jaccard相似度、最长公共子串、编辑距离等。这些算法对于待比较的文本数据不多时还比较好用,如果我们的每天采集的数据以千万计算,性能就是一个非常大的瓶颈。传统的hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果相等,说明原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。所以hash算法只适合相同性的检测而不适合相似性检测。理想当中的hash函数,需要对几乎相同的输入内容,产生相同或者相近的hash值,换言之,hash值的相似程度要能直接反映输入内容的相似程度,故md5等传统hash方法也无法满足我们的需求。
参考资料:
1、文本内容相似度计算方法:simhash – 标点符 (biaodianfu.com)
2、深度学习-5.短文本相似度计算 - 知乎 (zhihu.com)
3、计算文本相似度的常用算法_氧小氢的博客-CSDN博客_文本相似度算法
4、文本相似度-bm25算法原理及实现 - 简书 (jianshu.com)
5、https://blog.csdn.net/weixin_42510210/article/details/114483739
6、基于simhash的文本去重原理 - 知乎 (zhihu.com)
posted on 2022-05-18 11:01 enhaofrank 阅读(540) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号