类别不均衡问题与损失函数loss
1、样本不均衡问题
主要分为以下几类:
1)每个类别的样本数量不均衡
2)划分样本所属类别的难易程度不同
2、Focal loss
focal loss用来解决难易样本数量不均衡,重点让模型更多关注难分样本,少关注易分样本。
假设正样本(label=1)少,负样本多,定义focal loss如下
Loss = -[alpha*(1-y_hat)^2yln(y_hat)
+ (1-alpha)y_hat^2(1-y)*ln(1-y_hat)]
其中y_hat:(batch, seq, tags),预测出的
y: (batch, seq, tags)
alpha:(1, 1, tags)
alpha是超参数,是正样本损失占总体的比例,初始化为 少数样本/总样本 的比值,调整策略如下,正样本的precision<recall时,训练更关注正样本,alpha调低,反之调高。
调整策略也可以为:
正类的识别正确率与负类的识别正确率
3、GHM loss
GHM用来解决难分样本中的离群点。模型不应过多关注易分样本,也不应过多关注离群很远的难分样本(特别难分的)。
4、加权loss
用来解决样本类别数量不均衡问题,某些类别的样本特别多或特别少。
——————————————
模型层面主要是通过加权Loss,包括基于类别Loss、Focal Loss和GHM Loss三种加权Loss函数;
为了解决样本不均衡的问题,最简单的是基于类别的加权Loss,具体公式如下:
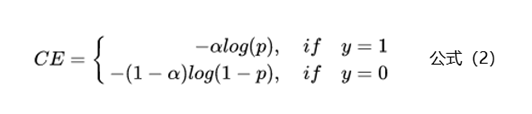
基于类别加权的Loss其实就是添加了一个参数a,这个a主要用来控制正负样本对Loss带来不同的缩放效果,一般和样本数量成反比。还拿上面的例子举例,有100条正样本和1W条负样本,那么我们设置a的值为10000/10100,那么正样本对Loss的贡献值会乘以一个系数10000/10100,而负样本对Loss的贡献值则会乘以一个比较小的系数100/10100,这样相当于控制模型更加关注正样本对损失函数的影响。通过这种基于类别的加权的方式可以从不同类别的样本数量角度来控制Loss值,从而一定程度上解决了样本不均衡的问题。
上面基于类别加权Loss虽然在一定程度上解决了样本不均衡的问题,但是实际的情况是不仅样本不均衡会影响Loss,而且样本的难易区分程度也会影响Loss。基于这个问题2017年何恺明大神在论文《Focal Loss for Dense Object Detection》中提出了非常火的Focal Loss,下面是Focal Loss的计算公式:
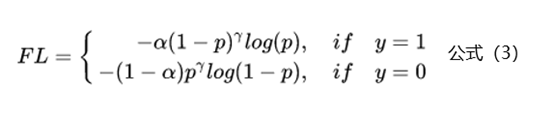
相比于公式2来说,Focal Loss添加了参数γ从置信的角度来加权Loss值。假如γ设置为0,那么公式3蜕变成了基于类别的加权也就是公式2;下面重点看看如何通过设置参数r来使得简单和困难样本对Loss的影响。当γ设置为2时,对于模型预测为正例的样本也就是p>0.5的样本来说,如果样本越容易区分那么(1-p)的部分就会越小,相当于乘了一个系数很小的值使得Loss被缩小,也就是说对于那些比较容易区分的样本Loss会被抑制,同理对于那些比较难区分的样本Loss会被放大,这就是Focal Loss的核心:通过一个合适的函数来度量简单样本和困难样本对总的损失函数的贡献。
参考资料:
https://blog.csdn.net/angel_hben/article/details/103369346
https://zhuanlan.zhihu.com/p/321323696
https://www.zhihu.com/question/66408862/answer/1647753758
https://zhuanlan.zhihu.com/p/80594704
posted on 2022-04-15 09:05 enhaofrank 阅读(1319) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号