
ClickHouse作为开源的列式存储数据库,具有卓越的查询性能和在线实时分析功能。旨在快速执行复杂的聚合查询,能够处理海量的数据集。 clickHouse表是一个大宽表,可能上百个列,减少join过程消耗
clickHouse列式存储原理
- 按列独立存储,在对应clickHouse partition中,某一列的部分数据会独立存储。而行式存储是把所有列数据存储。
- partition存储,数据首先按照分区键partition by划分为不同的分区,然后每个分区内列数据独立存储
ClickHouse数据分布
-
不是所有数据物理上连续:虽然逻辑上同一列的数据是连续的,但物理存储上可能分布在不同的文件中(不同分区、不同数据部分)。
-
压缩单元:数据会按压缩块(compressed blocks)存储,通常每个压缩块包含64KB到1MB的未压缩数据。
-
本地化存储:在分布式表的情况下,数据会根据分片键分布在不同的服务器节点上。
稀疏索引
-- 按月分区,按天排序 CREATE TABLE logs ( timestamp DateTime, user_id UInt32, event_type String ) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) ORDER BY (toDate(timestamp), user_id);
一般情况下,在创建表时需要指定Primary key,如上边scripts中没有指定Primary key会默认order by字段为主键
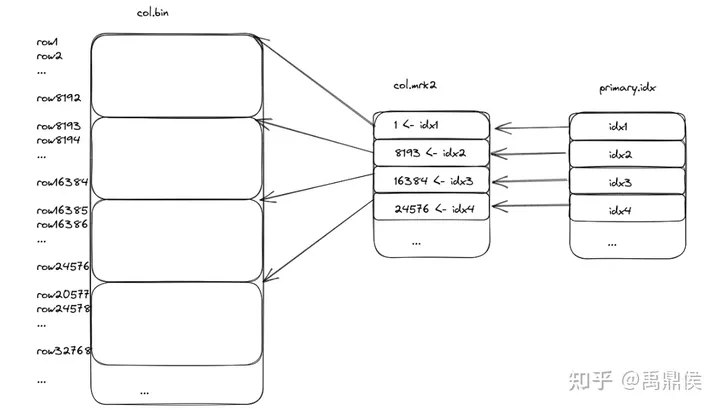
ClickHouse中稀疏索引区别于Mysql的行级索引。行级索引就是一行一个索引,每个索引都可以定位到某一行数据;ClickHouse中稀疏索引是在索引粒度上创建索引,默认一个索引粒度包含8192,所以clickhouse是8192条数据才会创建一个索引.通过稀疏索引可以定位更多的数据,但只能定位到索引粒度的第一行,但由于主键创建必须指定order by,主键必须是order by字段的前缀字段。这样可以继续根据有序的主键在索引粒度中查找
ClickHouse效率高原因
- 1. ClickHose是按列存储在磁盘上,每列单独存储在自己的文件中,每列都有自己的元数据和压缩算法;ClickHouse查询某一列时,只会去这样一列存储文件加载这一列,而mysql在查询某一列时,会加载整行信息,然后再过滤出查询的这一列,所以在按列查询上ClickHouse更快

采用行式存储时,数据在磁盘上的组织结构为
![]()
采用列式存储,数据在磁盘上组织结构为
![]()
- 2. partition分布式存储
partition分区内列数据独立存储,查询时自动过滤掉不符合的分区
- 3 向量化查询执行
查询结果是数据列块而不是某一行
- 4 并行处理能力
利用cpu并行处理查询,支持分布式查询
- 5 智能索引机制
ClickHouse智能索引
1. 主键索引(稀疏索引) -- 一级索引
-
非唯一索引:允许重复主键值,避免唯一性检查开销
-
稀疏存储:不是每行都建索引,而是每N行一个标记(默认8192行)
-
排序存储:数据按主键顺序物理存储
主键作用:①主键索引是稀疏索引,每n行会创建一个索引标记,可快速定位定位数据块,显著减少IO交互 ②clickhouse中主键顺序决定了数据顺序存储,通过主键稀疏索引快速定位到数据块,同时基于数据按照主键顺序的物理存储快速定位到对应数据条
③配合partition by快速跳过无关分区 ④数据合并优化,相同主键范围数据会被合并
2 跳数索引 --二级索引
ClickHouse 特有的二级索引机制,用于标记哪些数据块包含目标数据,用于快速跳过不相关的数据块。跳数索引多用于:①多在where出现的字段②高基数字段(重复少)③过滤性强字段(如active等)
常见类型
| 索引类型 | 描述 | 适用场景 |
|---|---|---|
| minmax | 存储每个块的min/max值 | 范围查询(>, <, BETWEEN) |
| set | 存储块的唯一值集合 | 等值查询(=, IN) |
| bloom_filter | 布隆过滤器 | 高基数等值查询 |
| ngrambf_v1 | N-gram布隆过滤器 | 字符串搜索 |
| tokenbf_v1 | 分词布隆过滤器 | 文本搜索 |
ALTER TABLE hits ADD INDEX user_idx UserID TYPE bloom_filter GRANULARITY 4; //GRANULARITY 4:表示每4个8192行数据块生成一个索引条目
ALTER TABLE hits ADD INDEX date_idx EventDate TYPE minmax GRANULARITY 2;
3 分区索引 partition by
-
分区键裁剪:自动跳过不相关分区
-
多级分区:支持按时间、哈希等多维度分区
-
分区内有序:每个分区内数据仍按主键排序
ClickHouse适用场景
ClickHouse的高效查询特别适合:
-
大规模数据分析(OLAP)
-
需要扫描大量数据的聚合查询
-
时间序列数据分析
-
实时报表生成
-
用户行为分析等场景
总结:ClickHouse通过列式存储、向量化执行、智能索引和并行处理等创新设计,在分析型查询场景下实现了比传统行式数据库高1-2个数量级的查询性能。
如何优化ClickHouse中的查询?
-
索引创建:虽然ClickHouse不支持传统意义上的索引,但它有主键、分区键等机制来加速查询。
-
数据预聚合:预先计算常用的汇总数据,如总和、平均值等,可以显著提高查询速度。
-
表设计:合理规划表结构,包括选择合适的引擎类型、定义有效的分区策略等。
-
查询重写:简化SQL语句,去除冗余操作,确保最优化的查询逻辑
ClickHouse引擎类型
clickhouse引擎命名大小写敏感,其引擎类型为
TinyLog:以列文件形式存储在磁盘上,不支持索引,没有并发控制。一般存储少量数据的小表
Memory:内存引擎
数据以未压缩形式存储在内存中,服务器重启后数据会丢失。但由于数据存储在内存所以查询效率特别高,但它不支持索引
MergeTree:clickhouse最强大引擎
-
表级引擎:决定单个表的数据存储方式
-
列式存储:数据按列存储,高效压缩
-
主键索引:支持稀疏索引加速查询,存储数据的物理结构按主键排序。这使得通过建立比较小的稀疏索引来加快数据索引
-
数据分区:支持按分区管理数据
-
后台合并:自动合并数据部分(parts)
- 支持抽样:允许用户只处理数据据一部分而不是全集,适用于大数据规模近似计算。抽样子句:
select * from ClickHouseTable SAMPLE 1/10; //随机采样1/10
select * from ClickHouseTable SAMPLE 1/10 SAMPLE BY name; 按照特定列name随机采样1/10
ClickHouse分区合并
分区的目的就是:①提升存储空间 ②存储空间划分,降低扫描范围,提升查询效率。面对分区查询clickhouse会以分区为单位并行处理
任何一个批次数据的写入都会创建一个新分区存储,不会直接纳入已存在的分区(就算创建表时按照某个日期分区,再插入时这个日期满足已存在的某个分区也不会直接写入到那个已存在的分区)。而是在一定时间后clickhouse自动执行合并操作(也可以手动操作通过optimize立即生效),把临时分区数据合并到已有的分区中,已存在的旧分区目录不会立即删除而是在一定时间后通过后台任务删除
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值
- Level:取同一分区内最大Level值+1
比如,开始状态下,表已存在如下数据,根据日期分区,2020-06-01、2020-06-02共两个分区
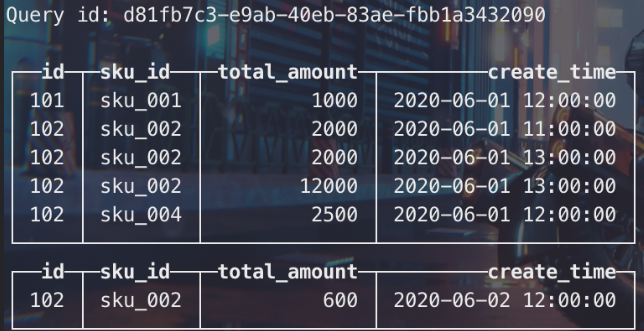
基于已存数据,在执行一下插入操作
insert into t_order_mt values (101,'sku_001',1000.00,'2020-06-01 12:00:00') , (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
查看数据并没有纳入任何分区,而是新产生了一个分区:
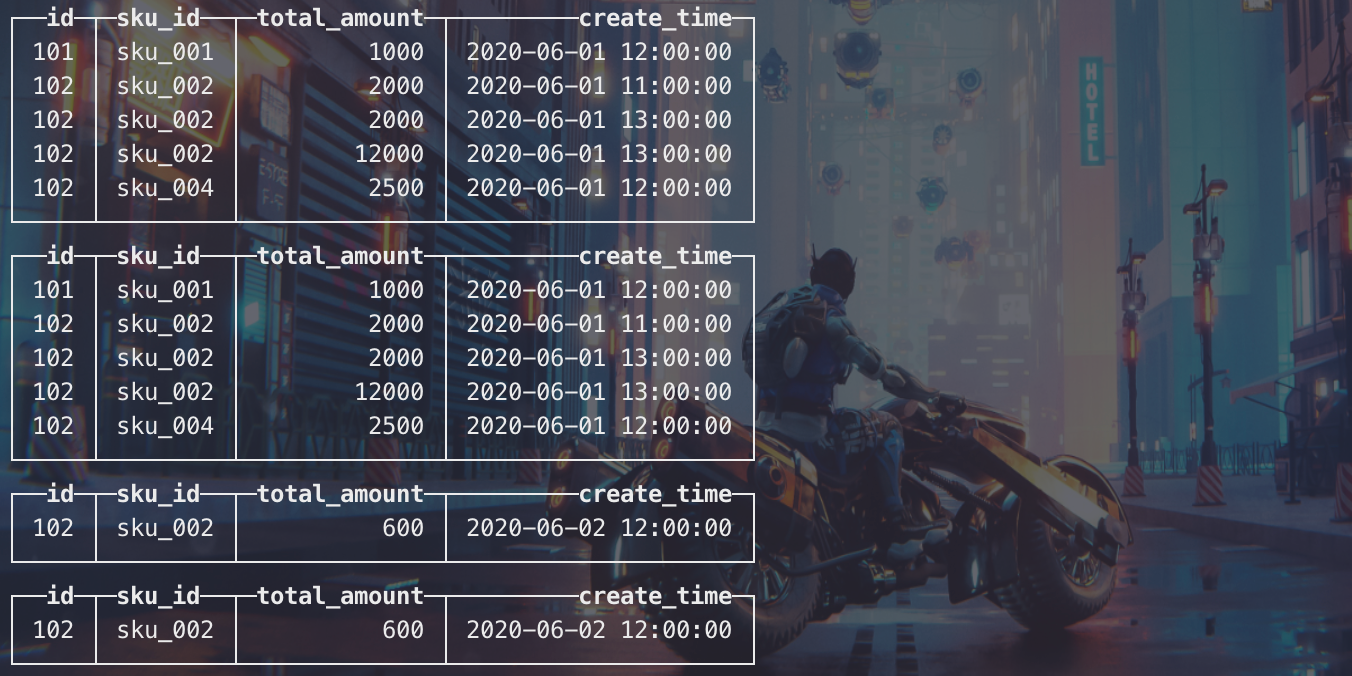
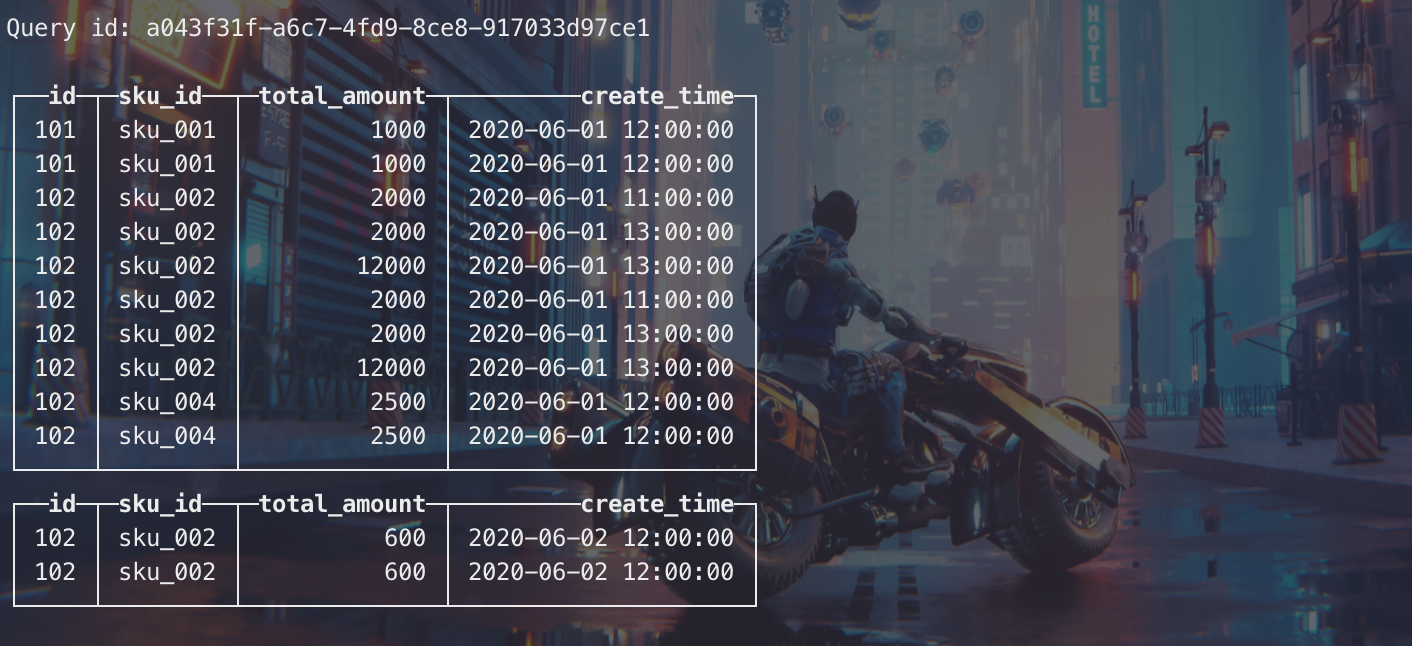
手动optimize之后可见分区合并了
ClickHouse数据类型
- 1 数值类型:int float decimal
- 2 字符串类型:String FixedString(定长) UUID
- 3 事件类型:Date DateTime DateTime64(较DateTime到纳米级别'2023-05-15 14:30:00.123456')
- 4 复合类型:
Array数组: 在同一个数组内可以包含多种数据类型,例如数组[1,2.0]是可行的。但各类型之间必须兼容,例如数组[1,'2']则会报错。
CREATE TABLE array_example ( id UInt32, tags Array(String), values Array(Float64) ) ENGINE = MergeTree() ORDER BY id; -- 插入数据 INSERT INTO array_example VALUES (1, ['tag1', 'tag2'], [1.1, 2.2, 3.3]);
--查询数据
SELECT
arrayMap(x -> x * 2, values) AS doubled_values,
arrayFilter(x -> x > 2, values) AS filtered_values,
arrayJoin(tags) AS expanded_tags -- 将数组展开为多行
FROM array_example;
Tuple元组:同一元组中数据类型可以是任意的
CREATE TABLE tuple_example ( id UInt32, coordinates Tuple(Float64, Float64), user_info Tuple(String, UInt8, Date) ) ENGINE = MergeTree() ORDER BY id; -- 插入数据 INSERT INTO tuple_example VALUES (1, (12.34, 56.78), ('John', 30, '1990-01-01'));
SELECT
coordinates.1 AS latitude,
coordinates.2 AS longitude,
user_info.3 AS birth_date
FROM tuple_example;
Nested嵌套
嵌套类型本质是一种多维数组的结构。嵌套表中的每个字段都是一个数组,并且行与行之间数组的长度无须对齐,在同一行数据内每个数组字段的长度必须相等。
插入数据时候每一个nestd字段要需要一个数组。
CREATE TABLE nested_example ( id UInt32, user Nested( name String, age UInt8, hobbies Array(String) ) ) ENGINE = MergeTree() ORDER BY id; -- 插入数据 INSERT INTO nested_example VALUES (1, ['Alice', 'Bob'], [25, 30], [['reading', 'hiking'], ['gaming']]); // ['Alice', 'Bob'], [25, 30]是属于同一行,字段长度要一样;
SELECT
id,
arrayJoin(arrayZip(user.name, user.age, user.hobbies)) AS user_data
FROM nested_example;
ClickHouse DDL
1 创建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2 ) ENGINE = MergeTree() ORDER BY expr [PARTITION BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...] [SETTINGS name=value, ...]
- PARTITION BY:分区键,用于指定数据以何种标准进行分区。分区键可以是单个列字段、元组形式的多个列字段、列表达式。如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
- ORDER BY 决定了每个分区中数据的排序规则;主键必须是order by字段的前缀字段;在ReplactingmergeTree中,order by相同的被认为是重复的数据;在SummingMergeTree中作为聚合的维度列;
- PRIMARY KEY 决定了一级索引(primary.idx),默认情况下,主键与排序键(ORDER BY)相同,所以通常使用ORDER BY代为指定主键。一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排序。与其他数据库不同,MergeTree主键允许存在重复数据;
- SAMPLE BY:抽样表达式,用于声明数据以何种标准进行采样。抽样表达式需要配合SAMPLE子查询使用;
- SETTINGS:index_granularity:索引粒度,默认值8192。也就是说,默认情况下每隔8192行数据才生成一条索引;
- SETTINGS:index_granularity_bytes:在19.11版本之前,ClickHouse只支持固定大小的索引间隔(index_granularity)。在新版本中增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,由index_granularity_bytes参数控制,默认10M;
- SETTINGS:enable_mixed_granularity_parts:设置是否开启自适应索引间隔的功能,默认开启。
2 基于已有表复制表,两张表结构完全相同
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
3 从表函数创建表
表函数:就是能创建表的函数
CREATE TABLE Orders ENGINE = MergeTree ORDER BY OrderID AS SELECT * FROM mysql('10.42.134.136:4000', 'databas', 'Orders', 'root', '1234')
AS之后的select * ...就是表函数
4 分布式集群建表
CREATE、ALTER、DROP、RENMAE及TRUNCATE这些DDL语句,都支持分布式执行。这意味着,如果在集群中任意一个节点上执行DDL语句,那么集群中的每个节点都会以相同的顺序执行相同的语句.
将一条普通的DDL语句转换成分布式执行十分简单,只需加上ON CLUSTER cluster_name声明即可。
例如,执行下面的语句后将会对ch_cluster集群内的所有节点广播这条DDL语句
CREATE TABLE partition_v3 ON CLUSTER ch_cluster( //ch_cluster是集群名字 ID String, URL String, EventTime Date ) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventTime) ORDER BY ID
5 创建临时表 TEMPORAY
临时表特点:
- ①临时表是基于会话创建的,其引擎是Memory,会话结束临时表就会删除
- ②临时表不属于任何数据库,所以创建时没有数据库名(db_name)也没有数据库引擎参数
- ③ 当临时表和普通表重名时优先读取临时表中数据
6 创建分区表 partition by
ClickHouse创建表语句关键字解析
1 空值 非空值 关键字
clickhouse默认是可以空
CREATE TABLE example ( id UInt32, -- 默认允许NULL name String, -- 默认允许NULL age UInt8 NOT NULL, -- 声明NOT NULL(但实际不强制约束) email Nullable(String) -- 显式声明可为NULL ) ENGINE = MergeTree() ORDER BY id;
2 字段默认表达式
[DEFAULT|MATERIALIZED|EPHEMERAL|ALIAS expr1]
一般表达式
DEFAULT expr
正常默认值。如果INSERT查询未指定相应的列,则将通过计算相应的表达式来填充它。
物化表达式
MATERIALIZED expr
物化字段列。这样的字段不能在INSERT语句中指定值插入,因为这样的字段总是通过使用其他字段计算出来的。不会出现在SELECT *查询的返回结果集中。
临时表达式
EPHEMERAL expr
临时字段列。这样的列不存储在表中,不能被SELECT 查询,但可以在CREATE语句的默认值中引用。
别名表达式
ALIAS expr
字段别名。这样的列根本不存储在表中。其值不能插入到表中,并且在通过SELECT * 查询,不会出现在结果集。如果在查询分析期间扩展了别名,则可以在SELECT中使用它。
3 主键 Primary key
主键就是稀疏索引中每n行创建的索引标记
主键作用:①主键索引是稀疏索引,每n行会创建一个索引标记,可快速定位定位数据块,显著减少IO交互 ②clickhouse中主键顺序决定了数据顺序存储,通过主键稀疏索引快速定位到数据块,同时基于数据按照主键顺序的物理存储快速定位到对应数据条
③配合partition by快速跳过无关分区 ④数据合并优化,相同主键范围数据会被合并
主键创建两种方式: -- 内部定义 CREATE TABLE db.table_name ( name1 type1, name2 type2, ..., PRIMARY KEY(expr1[, expr2,...])] ) ENGINE = engine; -- 外部定义 CREATE TABLE db.table_name ( name1 type1, name2 type2, ... ) ENGINE = engine PRIMARY KEY(expr1[, expr2,...]);
警告:不能在一个查询中以两种方式组合。
4 约束键 CONSTRAINT
在创建表时对约束列进行插入值的判断
CREATE TABLE products ( id UInt32, price Decimal(10,2), CONSTRAINT price_check CHECK price > 0 )
5 TTL (和Mongo使用类似)
它表示数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,则会以先到期的那个为主。
无论是列级别还是表级别的TTL,都需要依托某个DateTime或Date类型的字段
.//列级ttl CREATE TABLE ttl_table_v1( id String, create_time DateTime, code String TTL create_time + INTERVAL 10 SECOND, type UInt8 TTL create_time + INTERVAL 10 SECOND ) ENGINE = MergeTree PARTITION BY toYYYYMM(create_time) ORDER BY id //表级ttl CREATE TABLE ttl_table_v2( id String, create_time DateTime, code String TTL create_time + INTERVAL 1 MINUTE, type UInt8 )ENGINE = MergeTree PARTITION BY toYYYYMM(create_time) ORDER BY create_time TTL create_time + INTERVAL 1 DAY
数据库引擎分析
数据库引擎是区别于表引擎(MergeTree)的数据库级别引擎,用于定义整个数据库行为和存储方式机制。
数据库引擎分类:
1 automic
CREATE DATABASE db_name ENGINE = Atomic;
核心特性:
-
✅ 原子性操作:支持原子级的
DROP/RENAME/EXCHANGE TABLES操作 -
🔄 元数据一致性:通过 ZooKeeper 保证集群元数据同步
-
🆔 UUID 标识:表使用唯一UUID而非名称标识,路径如
/store/xxx/xxx/ -
📦 数据隔离:每个表数据独立存储,避免相互影响
-
⏱ TTL 支持:数据库级数据过期策略
适用场景:生产环境推荐使用,特别是集群部署
2 mysql引擎 可以理解为clickhouse是mysql的代理
MySQL引擎用于将远程的MySQL服务器中的表映射到ClickHouse中,并允许您对表进行INSERT和SELECT查询,以方便您在ClickHouse与MySQL之间进行数据交换。
作为 MySQL 的代理层,不存储数据,将查询将查询转换为 MySQL 的 SQL 执行
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此您可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作。
但无法对其执行操作:RENAME、CREATE TABLE和ALTER
CREATE DATABASE mysql_db ENGINE = MySQL( 'mysql_host:3306', 'mysql_db', 'user', 'password' );
使用例子:


mysql> USE test; Database changed mysql> CREATE TABLE `mysql_table` ( -> `int_id` INT NOT NULL AUTO_INCREMENT, -> `float` FLOAT NOT NULL, -> PRIMARY KEY (`int_id`)); Query OK, 0 rows affected (0,09 sec) mysql> insert into mysql_table (`int_id`, `float`) VALUES (1,2); Query OK, 1 row affected (0,00 sec) mysql> select * from mysql_table; +------+-----+ | int_id | value | +------+-----+ | 1 | 2 | +------+-----+ 1 row in set (0,00 sec) ClickHouse中的数据库,与MySQL服务器交换数据: CREATE DATABASE mysql_db ENGINE = MySQL('localhost:3306', 'test', 'my_user', 'user_password') SHOW DATABASES ┌─name─────┐ │ default │ │ mysql_db │ │ system │ └──────────┘ SHOW TABLES FROM mysql_db ┌─name─────────┐ │ mysql_table │ └──────────────┘ SELECT * FROM mysql_db.mysql_table ┌─int_id─┬─value─┐ │ 1 │ 2 │ └────────┴───────┘ INSERT INTO mysql_db.mysql_table VALUES (3,4) SELECT * FROM mysql_db.mysql_table ┌─int_id─┬─value─┐ │ 1 │ 2 │ │ 3 │ 4 │ └────────┴───────┘
3 MaterializedMySQL
核心能力:
-
🔄 实时同步:基于 MySQL binlog 实现数据同步
-
🏗 自动建表:将 MySQL 表转为 ReplacingMergeTree 表
-
⚡ 高性能查询:在 ClickHouse 执行分析查询不影 MySQL
4 Lazy引擎
CREATE DATABASE lazy_db ENGINE = Lazy(expire_after_seconds);
核心能力:
-
💤 延迟加载:表只在首次访问时加载到内存
-
🕒 自动卸载:超过指定时间未访问自动从内存清除
-
📊 适用场景:大量小表且访问频率低的监控系统
MergeTree
MergeTree是clickhouse表引擎之一,大小写敏感
其特点为:
支持主键索引:存储数据的物理结构按主键排序。这使得通过建立比较小的稀疏索引来加快数据索引
支持分区:若指定分区键的话支可以使用分区。在相同数据集和相同结果集的情况下ClickHouse中某些带分区的操作会比普通操作更快
支持数据副本:ReplicatedMergeTree提供了数据副本功能
支持抽样:允许用户只处理数据据一部分而不是全集,适用于大数据规模近似计算。抽样子句:
select * from ClickHouseTable SAMPLE 1/10; //随机采样1/10 select * from ClickHouseTable SAMPLE 1/10 SAMPLE BY name; 按照特定列name随机采样1/10
主键选择
参考: https://cloud.tencent.com/developer/article/2394967
https://blog.csdn.net/qq_44766883/article/details/126707335

 浙公网安备 33010602011771号
浙公网安备 33010602011771号