
1 一级缓存与二级缓存
https://blog.csdn.net/qq_62112907/article/details/148400431
Mybatis提供一级缓存和二级缓存机制来提升查询性能
| 一级缓存 | 二级缓存 | |
| 作用域 |
单个sqlSession中,默认开启 SqlSession session = sqlSessionFactory.openSession(); UserMapper mapper = session.getMapper(UserMapper.class); // 第一次查询,访问数据库 User user1 = mapper.selectUserById(1); // 第二次查询相同SQL和参数,从一级缓存获取 User user2 = mapper.selectUserById(1); session.close();
|
mapper级别(同一个mapper中多个sqlsessin共享),需要手动开启 <!-- UserMapper.xml --> <mapper namespace="com.example.UserMapper"> <cache /> <!-- 启用二级缓存 --> </mapper> SqlSession session1 = sqlSessionFactory.openSession(); SqlSession session2 = sqlSessionFactory.openSession(); |
| 过程示意图 | SqlSession1 → 执行查询 → 将结果存入UserMapper缓存区 ↗ 后续查询(其他SqlSession) → 重新从数据库读取结果存入对应缓存区 ↘ SqlSession2 → 执行相同查询 → 重新从数据库读取结果存入对应缓存区 |
SqlSession1 → 执行查询 → 将结果存入UserMapper缓存区 |
| 存储位置 | 内存中hashmap | 内存/磁盘中(可配置第三方缓存如redis或ehcache) |
| 失效策略 |
针对当前sqlsession执行增、删、改操作 sqlsession执行clearCache操作 sql查询语句或者参数变化 跨sqlsession操作 |
执行insert delete update会清空缓存
|
| 序列化 | 不需要 | 实体类必须实现 Serializable 接口,因为二级缓存是跨会话的需要在不同会话间传递;另外二级缓存是要存储到磁盘或第三方缓存 |
| 适用场景 | 会话内重复查询 | 适用共享读 |
sqlSession:代表与数据库的一次会话,可以以以下两种方式和数据库进行操作:
1)提供selectOne selectList insert update delete进行数据库操作


<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "https://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.thb.mapper.UserMapper"> <resultMap type="com.thb.model.User" id="userResultMap"> <id property="id" column="id"/> <result property="userName" column="user_name"/> <result property="homeTown" column="home_town"/> </resultMap> <select id="selectOneUser" resultMap="userResultMap"> select id, user_name, home_town from user where id = #{id} </select> </mapper> 此时定义一个空的UserMapper.java接口文件就可以,因为没有使用SqlSession的getMapper(Class<T> type)函数。但如果不定义UserMapper.java接口文件,就会报错,因为UserMapper.xml文件中使用了命名空间<mapper namespace="com.thb.mapper.UserMapper"> package com.thb.mapper; public interface UserMapper { } package com.thb; import java.io.IOException; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import com.thb.model.User; public class Demo { public static void main(String[] args) throws IOException { Demo demo = new Demo(); demo.dataProcess(); } public void dataProcess() throws IOException { SqlSessionFactory sqlSessionFactory = SqlSessionFactoryManager.getSqlSessionFactory(); // 取得一个SqlSession try (SqlSession session = sqlSessionFactory.openSession()) { User user = session.selectOne("selectOneUser", 2); System.out.println("id = " + user.getId()); System.out.println("userName = " + user.getUserName()); System.out.println("homeTown = " + user.getHomeTown()); } } }
2)通过getMappper()获取mapper接口实例:UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
工作流程

避坑指南
脏读问题:
- 避免跨 Mapper 关联(如 JOIN 查询)查询使用二级缓存
- 解决方案:在关联 Mapper 中添加 <cache-ref namespace="..."/> 建立缓存引用
事务提交:
- 二级缓存需在 SqlSession 提交后生效,确保及时调用 commit()
分布式环境:
- 默认二级缓存不适用于集群,需集成 Redis 等分布式缓存
性能优化
- 设置 flushInterval 控制自动刷新频率
- 使用只读缓存(readOnly="true")提升读取性能
- 对大数据量结果集启用分页,避免缓存溢出
2 resultType和resultMap区别
resultType和resultMap都用于设置mybatis增删改查后返回的数据类型,两者只能使用一个。
resultType:指定实体类的全限定名或首字母小写的类名,MyBatis 会自动将查询的结果映射成对应实体类。适用于数据库字段名和实体类属性名一致的情况。
resultMap: 给列起别名并查询所有。适用于数据库字段名和实体类属性名不同的情况。mybatis默认会进行驼峰转换。
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 映射配置文件 UserMapper.xml--> <!--namespace名称空间,该命名空间和对应mapper接口的全限定名一致--> <mapper namespace="package1.mapper.UserMapper"> <select id="selectAll" resultType="package1.pojo.User"> select * from tb_user; </select> </mapper> <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.itheima.mapper.BrandMapper"> <!--给列名起别名,让列名和成员变量一致,实现赋值--> <resultMap id="brandResultMap" type="brand"> <!-- id:完成主键字段的映射 column:表的列名 property:实体类的属性名 result:完成一般字段的映射 column:表的列名 property:实体类的属性名 --> <result column="brand_name" property="brandName"/> <result column="company_name" property="companyName"/> </resultMap> <select id="selectAll" resultMap="brandResultMap"> select * from tb_brand; </select> </mapper>
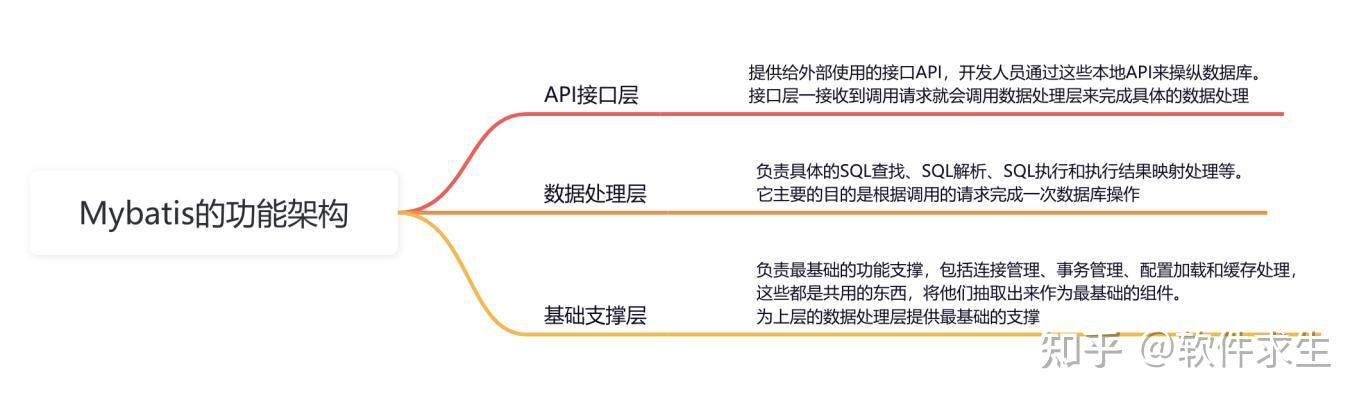
Mybatis架构
mybatis架构如下:
- API层:负责接口暴漏 可理解为代码中interface接口
- 数据处理层:负责执行sql和结果映射
- 基础支撑层:负责数据库连接、事务、插件等支撑
Mybatis底层原理
1 配置文件的加载与解析
mybatis-config.xml加载与解析
mybatis配置文件mybatis-config.xml包含了mybatis各种配置信息(数据库连接信息、事务管理器、mapper映射文件地址等),mybatis通过sqlsessionFactoryBuilder来加载与解析配置文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 1. 全局设置 --> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <!-- 开启驼峰命名转换 --> <setting name="cacheEnabled" value="true"/> <!-- 启用二级缓存 --> </settings> <!-- 2. 类型别名(可选) --> <typeAliases> <package name="com.example.model"/> <!-- 自动扫描包下的类作为别名 --> </typeAliases> <!-- 3. 环境配置 --> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments> <!-- 4. Mapper映射文件配置(重点部分) --> <mappers> <!-- 方式1:使用resource属性指定单个XML映射文件 --> <mapper resource="mapper/UserMapper.xml"/> <!-- 方式2:使用class属性指定Mapper接口 --> <mapper class="com.example.mapper.OrderMapper"/> <!-- 方式3:使用package属性批量注册 --> <package name="com.example.mapper"/> <!-- 方式4:使用url属性指定绝对路径(不推荐) --> <!-- <mapper url="file:///C:/mappers/ProductMapper.xml"/> --> </mappers> </configuration>
上边mybatis-config.xml文件中<environments>:mybatis运行环境,包含数据库配置信息和事务管理器
- <transactions>:事务管理器
- <dataSource>数据库配置信息
- <mappers>用于注册mapper xml配置文件或者mapper接口,可见配置文件加载与解析阶段也会加载mapper.xml文件。如方式3中使用<package>会扫描这个包下所有mapper接口。当解析到<package>标签时,XMLConfigBuilder会扫描指定包下的所有接口,并将这些接口注册到Configuration对象中;对于<mapper>标签指定的映射文件,XMLConfigBuilder会进一步解析映射文件中的 SQL 语句、参数映射、结果映射等信息,并将这些信息也注册到Configuration对象中
整个解析过程中,xmlconfigureBuilder会将解析得到的配置信息保存到Configuration对象中,Configuration对象是mybatis运行时核心配置对象,它包含mybatis运行时所需数据库连接信息、事务管理器、mapper映射信息等
2 创建sqlSession
sqlSession代表java与数据库一次会话,内部管理jdbc连接,提供crud操作方法
SqlSession session = sqlSessionFactory.openSession(); UserMapper userMapper = session.getMapper(UserMapper.class);
3 mapper方法调用
User user = userMapper.selectById(1);
在mybatis中,通常通过sqlsession获取mapper接口的代理对象来执行sql。mapper代理对象通过jdk动态代理来实现。
这里为什么用动态代理呢?其实是为了实现mapper接口和mapper.xml中sql解耦
当我们调用userMapper.selectUserById(1)时,实际上是调用了代理对象的方法 。代理对象的invoke方法会根据 Mapper 接口的方法名和参数,找到对应的 SQL 语句(这些信息在解析 Mapper 映射文件时已经注册到Configuration对象中),然后通过SqlSession执行 SQL 语句,并将结果返回.
4 SQL解析
4.1 缓存检查,缓存存在直接返回
-
先查询二级缓存(
CachingExecutor) -
再查询一级缓存(
BaseExecutor.localCache)
4.2 SQL执行
mapper.xml中或者mapper接口中sql语句最终都会被解析成内部的 MappedStatement
根据方法参数生成BoundSql,替换掉sql中#{}或者${}
通过preparedStatement执行sql :PreparedStatement.execute()
4.3 SQL结果返回
ResultSetHandle处理结果,根据ResultMap进行对象属性映射
示例:
想象一个流程: 你写了 select * from user where id = #{id} MyBatis 会: 解析这条语句,生成 MappedStatement。 用你传入的参数构造 BoundSql。 用 JDBC 执行语句。 拿到结果 ResultSet,交给 ResultSetHandler 处理
Mybatis的mapper为什么是接口
MyBatis 的 Mapper 使用接口而不是实现类,这种设计有以下几个主要原因:
1. 动态代理机制
MyBatis 在运行时通过 Java 动态代理技术为 Mapper 接口生成代理对象,不需要开发者编写具体的实现类。这大大减少了样板代码。
2. 解耦与简化
-
接口与实现分离:接口只定义方法签名,实现由 MyBatis 框架处理
-
避免手动实现:开发者不需要编写重复的 JDBC 代码
3. XML/SQL 映射
-
接口方法与 XML 映射文件中的 SQL 语句通过方法名和命名空间自动关联
-
这种声明式编程方式更符合现代框架的设计理念
4. 类型安全
-
接口提供了编译时类型检查,比纯字符串方式更安全
-
方法参数和返回值都有明确的类型定义
5. IDE 支持
接口可以被 IDE 更好地支持,提供:
-
代码自动补全
-
方法跳转
-
重构支持
6. 易于测试
接口可以很容易地被 Mock,便于单元测试。
7. 多形式支持
虽然通常与 XML 配合使用,但 MyBatis 也支持:
-
注解方式(直接在接口方法上写 SQL 注解)
-
动态 SQL 构建
这种设计是 MyBatis 的核心特性之一,使得数据库操作更加简洁和类型安全,同时保持了足够的灵活性。
Mybatis动态SQL底层实现
Mybatis动态标签:
- <if> 条件判断,类似java中if <if test="name !=null> name=#{name}</if>
- <where> 动态构造sql中where语句,处理where条件中多余的and or和where <where> <if name!=null> and name=#{name}</if><if type!=null> and type=#{type}</type>
- <choose> <when>...<when> <otherwise> 条件选择,类似java中switch。进行单条件判断结合where返回第一个满足条件的when如果都不满足则返回otherwise ,作用和if类似 <choose><when name!=null> and name=#{name}</when><when type!=null> and type=#{type}</when><otherwise> and active=#{active}</otherwise>
- <set> 动态管理update语句中set子句,动态去掉set中逗号,和<if>一起使用 <Update id="UpdateUser>update User <set><if name!=null>,name=#{name}</if><if type!=null>,type=#{type}</if></set></update>
- <foreach> 遍历几何数据常用于批量处理,进行逐条操作 <Insert id="InsertUser"> insert into User (name,type) values <if list!=null and list.size()>0> <foreach collection="list" item="user" open="(" close=")" separator=","> name=#{user.name},type=#{name.type} </foreach> </if></insert>
- <trim> 动态拼接sql语句 <select id="selectByParams result="User"> select * from User <trim prefix="where" prefixOverride="and|or"><if name!=null> and name=#{name}</if><if type!=null> or type=#{type}</if></trim></select>
处理流程
-
解析阶段:
-
XML 映射文件被解析为包含各种 SqlNode 的树形结构
-
每个动态标签(
<if>--ifSqlNode,<where>--whereSqlNode等)都对应特定的 SqlNode 实现
-
-
SQL 拼接阶段:
-
执行时根据参数值动态评估条件
-
通过
apply()方法递归处理所有 SqlNode -
符合条件的 SQL 片段被拼接到 DynamicContext 中
-
-
参数处理阶段:
-
处理
#{}占位符,生成参数映射 -
最终生成可执行的 PreparedStatement
-
Mapper 接口: List<User> selectByCondition(@Param("name") String name, @Param("age") Integer age); XML映射: <select id="selectByCondition" resultType="User"> SELECT * FROM user WHERE 1=1 <if test="name != null"> AND name = #{name} </if> <if test="age != null"> AND age = #{age} </if> </select> 底层执行流程: 解析阶段: 将 XML 解析为 MixedSqlNode,包含: TextSqlNode ("SELECT * FROM user WHERE 1=1") IfSqlNode (条件1) IfSqlNode (条件2) 执行阶段: // IfSqlNode 核心源码 public boolean apply(DynamicContext context) { if (evaluator.evaluateBoolean(test, context.getBindings())) { contents.apply(context); return true; } return false; } 参数处理: 使用 OGNL 解析 test 表达式 通过 MetaObject 获取参数值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号