
https://blog.csdn.net/qq_40991313/article/details/133942498
https://blog.csdn.net/qq_40991313/article/details/126646289?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22126646289%22%2C%22source%22%3A%22qq_40991313%22%7D
1. ElasticSearch 适用场景
由于Es使用倒排索引,所以ES更适合于根据词条搜索、模糊搜素的应用场景。
但由于倒排索引的创建是在词条上的,而不是某个文档字段,所以无法根据字段创建索引
2. 倒排索引
首先,将ES文档某条/某些字段添加standard(分词器)标识进行分词,得到一个个词条——>建立分词得到的词条和对应文档id的映射关系——>查询时,根据输入的词条映射到对应文档id,然后再通过id找到对应的文档

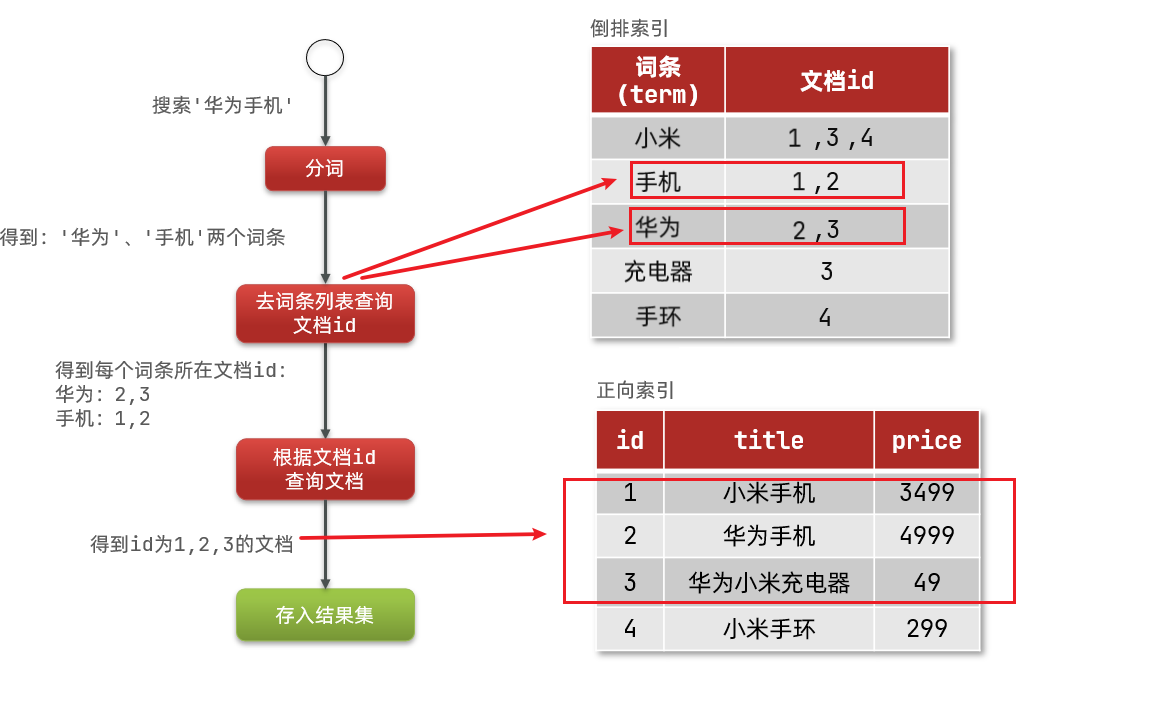
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
3 ES和Mysql对比

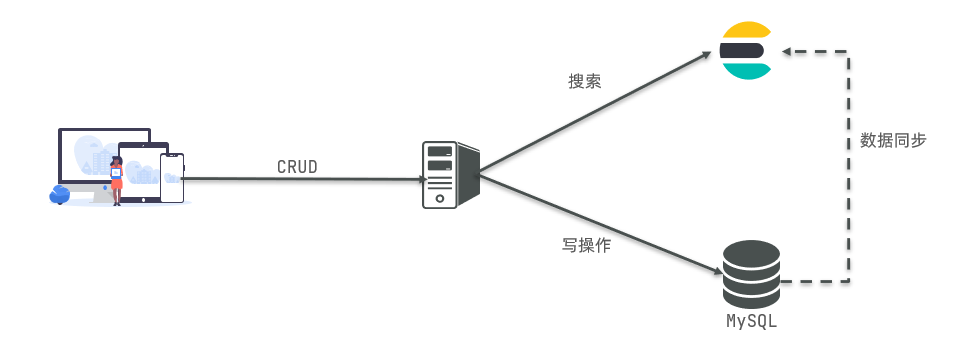
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
4 ES 索引库操作
ES索引库类似MySQL的表,mapping映射就类似于表的结构
4.1 查看索引库_cat集群信息
GET /_cat/nodes #查看所有节点。集群中会用到 GET /_cat/health #查看es健康状况 GET /_cat/master #查看主节点 GET /_cat/indices #查看所有索引 ,等价于mysql数据库的show databases;
4.2 Mapping里属性
#也可以用postman发put请求ip:9200/索引库名,带json数据实现 PUT /索引库名称 { "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" }, "字段名3":{ "properties": { "子字段": { "type": "keyword" } } } #, ...略 } } }
mapping是对索引库中文档的约束,常见的mapping属性包括:
properties:该字段的子字段。
type:字段数据类型,常见的简单类型有:
-
- 字符串:text(可分词的文本)、keyword(不可分词的精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- es的数组类型:es数组类型不用特别定义,支持每个字段有多个值,效果就相当于数组。例如索引库里"score":{"tupe":"integer"},文档可以"score":[1,2,3,4,5]
index:是否创建索引,默认为true
analyzer:使用哪种分词器,注意只有text类型可以设置分词器,其他类型设置分词器会报错mapper_parsing_exception
4.2.1 nested类型解决数组的扁平化处理
es数组的扁平化处理:es存储对象数组时,它会将数组扁平化,也就是说将对象数组的每个属性抽取出来,作为一个数组。因此会出现查询紊乱的问题。
示例:下面user字段是对象数组类型,因为数组扁平化处理,下面结果跟期望查询结果不符:
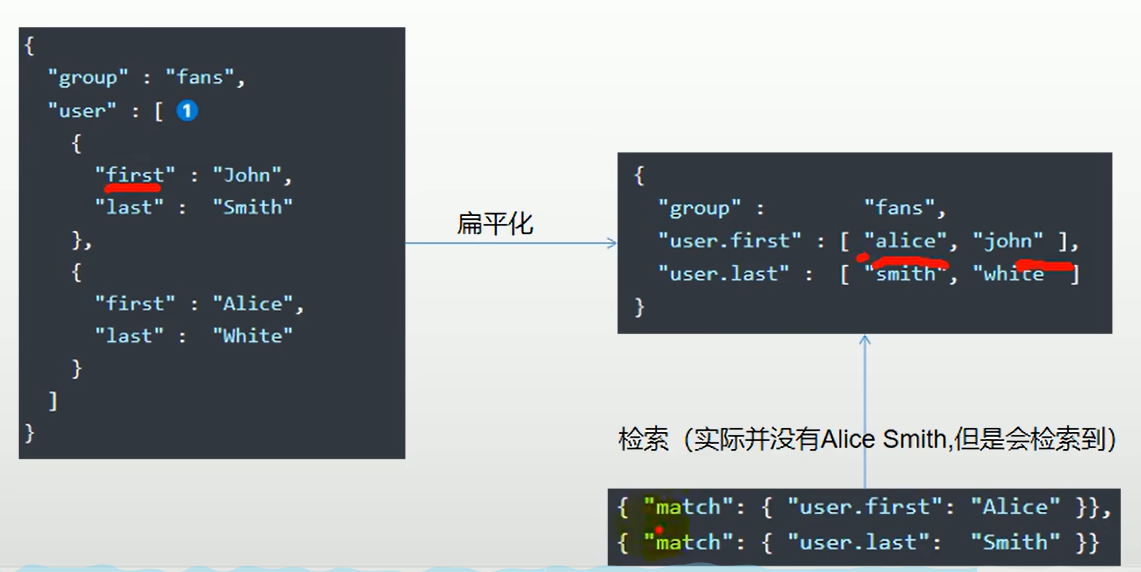
解决办法:使用nested子类类型:

4.3 索引库的CRUD
4.3.1 创建索引库 PUT/索引库名字
#也可以用postman发put请求ip:9200/索引库名,带json数据实现 PUT /索引库名称 { "mappings": { "properties": { "字段名":{ "type": "text", "analyzer": "ik_smart" }, "字段名2":{ "type": "keyword", "index": "false" } #, ...略 } } }
4.3.2 查询索引库 GET
GET/索引库名
4.3.3 删除索引库 DELETE
DELETE /索引库名
4.3.4 修改添加字段
由于es的mapping是不可变的,一旦定义了字段名并且这个字段已经写入了数据,那么就不能直接修改这个字段了。如果要修改必须重新创建一个新的索引(对应mysql就是新创建一个新表),同时将旧索引中的数据copy到新的索引中,然后将旧索引给删掉。
虽然es不能修改字段名,但可以新建字段。
4.3.4.1 新增字段
注意新增字段和创建索引都是用put指令,但新增字段在索引后有_mapping同时json最外层中没有mappings{}
PUT /索引库名/_mapping { "properties": { "新字段名":{ "type": "integer" } } }
4.3.4.2 修改字段 --重新索引
- 1 创建新索引
PUT /new_index { "mappings": { "properties": { "new_field": { "type": "text" // 根据你的需要选择合适的类型 }, // 其他字段定义... } } }
- 2 将旧索引中数据同步到新索引中 _reindex
如下例,使用_reindex将旧索引old_index数据copy到new_index中,同时将old_field字段值赋给new_field然后将old_field删除
// 1. 创建新索引并定义新映射 PUT /new_index { "mappings": { "properties": { "field_name": { "type": "new_type" // 修改后的类型 } } } } // 2. 使用reindex API迁移数据 POST /_reindex { "source": { "index": "old_index" }, "dest": { "index": "new_index" } } // 3. 别名切换(保持名称不变) POST /_aliases { "actions": [ { "remove": { "index": "old_index", "alias": "current_alias" } }, { "add": { "index": "new_index", "alias": "current_alias" } } ] }
- 3 验证新索引数据无误后将旧索引删除
DELETE /old_index
5 文档操作
5.1 创建文档
post/索引库名/_doc/documentId/{json文档}
#也可以用postman发post请求ip:9200/索引库名/_doc/文档id,带json数据实现 POST /索引库名/_doc/文档id { "字段1": "值1", "字段2": "值2", "字段3": { "子属性1": "值3", "子属性2": "值4" }, # ... }
5.2 查询文档
GET/索引库名/_doc/documentId --查询某一个id的文档
GET/索引库名/_search --查询这个索引库下所有文档
5.3 删除文档
DELETE/索引库名/_doc/documentId
5.4 修改/新增文档 put/post
全量修改是指将对应documentId的旧文档删除然后写入新的文档,documenId不变
增量修改是指原来documentId对应文档不删除,只是修改输入要改动的字段
5.4.1 全量修改 PUT/索引库名/_doc/documentId {json文档}
#POST也是全量修改 PUT /{索引库名}/_doc/文档id { "字段1": "值1", "字段2": "值2", // ... 略 }
5.4.2 增量修改 POST/索引库名/_update/documentId {json文档}
POST /heima/_update/1 { "doc": { "email": "ZhaoYun@itcast.cn" } }
参考文献: https://blog.csdn.net/qq_40991313/article/details/126807267?spm=1001.2014.3001.5501#4.RestAPI

 浙公网安备 33010602011771号
浙公网安备 33010602011771号