
浏览器缓存机制
一、什么是浏览器缓存
简单来说浏览器缓存就是把一个已经请求过的web资源(如html页面、图片、js、数据等)拷贝一份副本储存在浏览器中。缓存会根据进来的情况保存顺出内容的副本。
当下一个请求来到的时候,如果是相同的url,缓存是根据缓存机制决定是直接使用副本响应访问请求,还是向原服务器再次发送请求。
比较常见的是浏览器会缓存访问过网站的网页,当再次访问这个url地址时,如果网页没有更新,就不会再次下载网页,而是直接用本地缓存的网页。
只有当网站明确标识资源已经更新,浏览器才会再次下载网页。
二、为什么使用缓存
(1)、减少网络带宽消耗
(2)、减少服务器压力
(3)、减少了网络延迟,加快了页面打开速度
三、浏览器HTTP请求流程
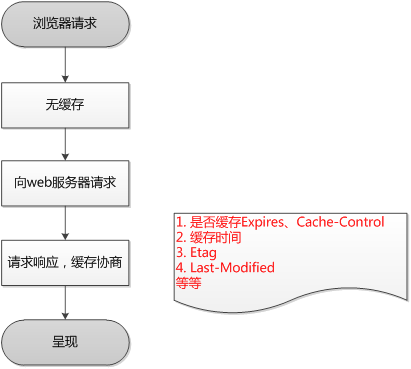
第一次请求:
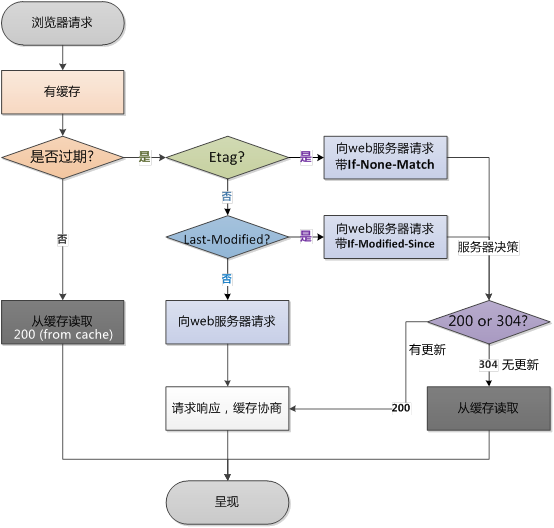
再次请求:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号