基础篇
- 01 注释,输出,变量定义与java工具
- 02 进制,变量与取模
- 03 自变,比较,三元与原码
- 04 判断,循环与输入
- 05 循环高级,数组与不换行输出
- 06 内存,方法与数据类型
- 07 快捷键
- 08 二维数组
- 09 类,对象与javabean
- 10 printf,this,与输入
- 11 练习
- 12 字符串及其比较与遍历
- 13 字符串高级,StringBuilder与StringJoiner
- 14 字符串拼接与对象
- 15 ArrayList定义与基本用法
- 16 集合练习,break高级及程序的结束
- 17 字符串首尾判断,面向对象进阶(静态)
- 18 继承(extends,super)
- 19 多态,包,final,权限修饰符和代码块
- 20 抽象,接口
- 21 接口进阶,内部类
- 22,23 项目——拼图
- 24 Math,System,Runtime
- 25 Object,Objects,BigInteger
- 26 BigDecimal,正则表达式,爬虫
- 27,28 时间类
- 29,30,31 包装类,常见算法
- 32,33,34,35 集合进阶
01 注释,输出,变量定义与java工具
public不大写
**String ** System大写
// 注释写代码上面
/* */ 多行注释
/*
* XXX
*/
or
/*XX
XX*/
*/ ** / 文档注释(给他人看)
/**
* XX
*/
idea中可用一下方式获取可折叠代码
//region 用来描述内部代码的话
代码块
//endregion
// 折叠后效果
用来描述内部代码的话
使用Ctrl + Alt + T可以快速插入
' '中只能为一个内容或制表符
" "一定为字符串
\t将前面字符串的长度补齐到8,或者8的倍数,最少补一个,最多补八个(即补至下一位八的倍数),用以对齐
System.out.println("abcd" + '\t');
System.out.println("abcd" + '\t' + "efgh");
数据类型 变量名 = 数据值;
计算时先算右边,再赋值
java为运行程序
javac为编译程序
javap为反编译程序
02 进制,变量与取模
- 0b开头为二进制(0,1)
- 0 开头为八进制(0~7)
- 0x开头为十六进制(0~9,a~f)
System.out.println(0b010);//二进制
System.out.println(0256);//八进制
System.out.println(0x26a);//十六进制
System.out.println(123);//十进制
小于3.3V为0,大于3.3V为1(电脑状态表示二进制)
任意进制转十进制:系数*基数的权次幂 相加(权从右往左从0开始,基数为进制,系数为每位的数) 如 0b110 为[1*(2^2)]+[1*(2^1)]+[0*(2^0)] = 6
- byte -128127(-2^52^5-1),256个值,1个字节
- short-32768~32767,2个字节
- int-2147483648~2147483647,4个字节
- long19位数,8个字节
long定义时数据值后要加L(小写亦可,易混)
float定义时数据值后面要加F(小写亦可)
//long n = 9999999999;错误: 整数太大
long n = 9999999999L;
float f = 29.01F;
取值范围:double>float>long>int>short>byte
可通过包装后的数据类型.MAX_VALUE获取最大值
sout(Integer.MAX_VALUE);
Java是强类型语言,不同类型的数据在计算时必须转为相同的数据类型
计算时,数据类型不同时,小范围数据默认先提升为另一个大范围数据类型(隐式转换),再计算
强制转换:目标数据类型 变量名 = (目标数据类型)被强制转换的数据,可能数据溢出
byte,short,char三种类型数据在运算时先提升为int,再进行计算
char隐式转换时将字符转化为ASCII码表中对应的序号
与字符串相加为拼接,不涉及隐式转换
标识符:给类,方法,变量取的名字
//键盘录入
import java.util.Scanner;//写在类的上面
Scanner sc = new Scanner(System.in);//写在方法里面
int i = sc.nextInt();
包名将域名反写,如www.baidu.com写为com.baidu.XXX以创建多级包
//除法
System.out.println(10 / 3);//3
System.out.println(10 / 6);//1
//只有整数参与结果也为整数,且不四舍五入
System.out.println(10.0 / 3);//3.3333333333333335
//有小数参与结果为小数,且结果可能不准
取模%应用场景:判断一个数是否能被另一个数除尽(斗地主发牌)
//拆分三位数
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个三位数");
int number = sc.nextInt();
int numberLocationThird = number % 10;
//int numberLocationSecond = (number - numberLocationThird) % 100 / 10;
int numberLocationSecond = number / 10 % 10;
//int numberLocationFirst = (number - numberLocationSecond * 10 - numberLocationThird) / 100;
int numberLocationFirst = number / 100 % 10;
System.out.println(numberLocationThird);
System.out.println(numberLocationSecond);
System.out.println(numberLocationFirst);
03 自变,比较,三元与原码
++自增1(放于变量后面先赋值后自增,反之则反之)
--自减1(同上)
int i = 10;
int a = i++;//a = 10,i = 11
int b = ++i;//b = 12,i = 12
//一般自成一行
i++;//i = 13
+=,-=,*=,/=,%=底层都隐藏了一个强制转换,使得下述结果成立
short s = 1;
s += 1;//此处1为int,s为short,相加结果应为int,却可无强转而赋值给short
!=不等
逻辑运算符:&逻辑与(同真方真);|逻辑或(同假方假);^逻辑异或(相同为假);!逻辑非(取反:真为假,假为真)
System.out.println(!true);//false
短路逻辑运算符:&&短路与;||短路或 前者不对就不用判断后面了,效率高
int a = 10;
int b = 20;
System.out.println(++a == 10 && ++b == 21); //false
System.out.println(a + " " + b);//a = 11 ,b = 20,没有执行++b
三元运算符:关系表达式?表达式1:表达式2 (如果关系表达式为true则执行表达式1,否则为2),三元运算符结果必须被使用
int a = 10;
int b = 20;
a > b ? a : b;//报错
int c = a > b ? a : b;//正确
System.out.println(a > b ? a : b);//正确
原码:十进制的二进制表示形式,最左边一位为符号位,0为正,1为负数
反码:整数反码为本身,负数反码为原码除符号位,剩余位置取反(0变为1,1变为0),用于负数计算(10000000不能用,跨0时不能用(由负数变为正数),如0b(-5) + 0b(6),原因:超出范围,0有两种表现形式,导致-0与+0变为两个数,因此比实际值少一,-2 + 1 不算跨0)
补码:在负数的反码的基础上加1(如:-1的原码为1000 0001,反码为 1111 1110,补码为 1111 1111)计算得到的值也为补码,机器中计算与存储的形式都为补码的形式,1111 1111为-128的补码,无原码,无反码
1字节 = 1bit(0000 0000共8bit)
强制转换将二进制前面部分删除,如int(300)的二进制为 0000 0000 0000 0000 0000 0001 0010 1100转换为byte,则将前面24个bit删去,变为0010 1100,及byte(44),注意:强转前后的二进制为补码形式,原因:计算机存储数据以补码的形式
隐式转换则为在前面加0
数字 & 数字以二进制形式计算,0为false,1为true,两者对应的都为1,结果才为1,最终结果以十进制形式表示,如:int(200) & int(10)为int(8)
0000 0000 0000 0000 0000 0000 1100 1000
0000 0000 0000 0000 0000 0000 0000 1010
————————————————————
0000 0000 0000 0000 0000 0000 0000 1000
同理,数字 | 数字相同,但以逻辑或形式计算
<<左移:向左移动,低位补,如
int a = 200;
System.out.println(a << 2);//800
//公式:左移一个即乘以一个2
|0000 0000 0000 0000 0000 0000 1100 1000|
00|00 0000 0000 0000 0000 0000 1100 100000|
同理,右移>>相同,但最高位补0或1(符号位,与原来数字相同),右移除2
无符号右移>>>,与右移相同,但高位补0,符号位与原来数字无关
对于float来说,其在内存中的位表示为b31b30...b0
则其对应的浮点数为val = (-1)b31 x 2(b30b29...b23)2 - 127 x (1.b22b21...b0)2
其中b31为符号位,记为S,b30b29...b23为指数位,记为E,b22b21...b0为分数位,记为N
则表达的浮点数为val = (-1)S x 2E - 127 x (1 + N)
由于浮点数使用了指数,所以它能表示的范围更大,但与之相对的,指数分布不均匀,精度较低
04 判断,循环与输入
if
//if的第一种用法,单条件
if(关系表达式){
语句体;
}
//语句体中,如果只有一句代码,大括号可省略,推荐写,int a = 100;算两句
if(关系表达式)
语句体;
//第二种,双条件
if(关系表达式){
语句体1;
}else{
语句体2;
}
//第三种,多条件
if(关系表达式1){
语句体1
}else if(关系表达式2){
语句体2
}
...
else{
语句体n+1
}//最后的else可省略
switch
//表达式类型:byte,short,int,char,枚举(JDK5以后),String(JDK7以后)
//无break则会使case穿透(即继续执行下一个case或default,即使不符合,第一个执行的一定是符合case的)
//case穿透可用于当多个case语句体重复时,以简化代码
case后的值只可为字面量,不能为变量,不能重复
switch(表达式){
case 值1://值可写多个如 1,2,3 若表达式的值为1或2或3时可执行,case穿透
语句体1;
break;
...
default:
语句体n+1;
break;//default可省略,但推荐写,可写在任意位置
}
//JDK12以后,可用以下形式省略break
switch(表达式){
case 值1 ->{
语句体1;
}
case 值2 ->{
语句体2;
}
...
default ->{
语句体n+1;
}
}
//若语句体只有一句,可省略大括号
switch(表达式){
case 值1 -> 语句体1;
case 值2 -> 语句体2;
...
default -> 语句体n+1;
}
// JDK12以后,若只是赋值,可用
String s = switch(number){
case 0 -> "0";
case 1 -> "1";
...
default -> "";
}; // 切记加分号结尾
if的第三种格式:一般用于对范围的判断
switch:把有限个数据一一列举出来,任选其一
//for循环
for(初始化语句;条件判断语句;条件控制语句){
循环体语句;
}
//初始化语句只执行一次
//每一次循环结束才执行条件控制语句
如
for(int i = 1;i <= 10;i++){
System.out.println(i);
}
初始化语句可放空
初始化语句;
for(;条件判断语句;条件控制语句){
循环体语句;
}
for(int i = 1,j = 1;i < j;i++;j--)
{
//初始化语句与条件控制语句可有多条
}
变量的作用范围属于所处的大括号
for循环中定义的变量,只在本次循环有效,一次循环结束后,该变量从内存中消失
idea中可用 **循环次数.fori ** + 回车快速生成for循环
初始化语句;
while(条件判断语句){
循环体语句;
条件控制语句;
}
如
int i = 1;
while(i <= 100){
System.out.println(i);
i++;
}
while循环可在只知反应结束条件的情况下使用
能使用for就能使用while
//只知结束条件
double height = 0.1;
int time = 0;
while (height <= 8844430){
time++;
height *= 2;
}
//回文数
//简便的
Scanner s = new Scanner(System.in);
System.out.println("请输入一个整数");
int number = s.nextInt();
int t = number;
int x = 0;
while(t != 0){
int ge = t % 10;
t /= 10;
x = x * 10 + ge;
}
System.out.println(x == number);
do...while:先循环,后判断,最后有分号
初始化语句;
do{
循环体语句;
条件控制语句;
}while(条件判断语句);
05 循环高级,数组与不换行输出
无限循环,如
for(;;){
System.out.println(" ");
}
//一般用while
while(true){
System.out.println(" ");
}
do{
System.out.println(" ");
}while(true);
无限循环下面不能写其它代码,因为无法执行到,除非有跳出语句(break;)
跳过语句(continue;)
for (int i = 1; i <= 5; i++) {
if(i == 3){
continue;//执行continue就不会执行外面一层大括号中的后续代码
}
System.out.println(i);//当i == 3时不执行
}
System.out.println(“ ”);//可执行
//执行break就不会执行本大括号内的代码了
//获取随机数
import java.util.Random;
Random r = new Random();
int number = r.nextInt(范围);//括号内为随机数的范围
int number01 = r.nextInt(10);//0~9
int number02 = r.nextInt(100) + 1;//1~100
//生成a~b的随机数
int number03 = r.nextInt(b - a + 1/* 数字个数*/) + a/*最开始的数*/;//a~b
//JDK17时可用
r.nextDouble(100.0);
数组的定义
//第一种
数据类型[] 数据名
int[] array;
//第二种
数据类型 数据名[]
int array[];
初始化:在内存中,为数组容器开辟空间,并将数据储存在容器的过程
数组的静态初始化
//数据类型[] 数组名 = new 数据类型[]{元素1,元素2...};
int[] array = new int[]{1,2,3};//完整格式
//数据类型[] 数组名 = {元素1,元素2...};
int[] array01 = {1,2,3};//简化格式
System.out.println(array01);//打印的为该数组容器的地址值,如 [I@4eec7777
数组创建完后,长度不能改变了
数组的动态初始化
//初始化时只指定数组长度,由系统为数组分配初始值
//数据类型[] 数组名 = new 数据类型[数组长度];
String[] array = new String[50];
array[0] = "张三";、
//数值默认初始化值规律
//整数类型:0,小数类型:0.0,字符类型:'\u0000' 空格,布尔:false,引用数据类型(包括String):null
地址值:[I@4eec7777中,[ 表示为一个数组,I 表示为该数组中的元素为int类型,@ 表示一个间隔符号(固定格式),4eec7777 数组真正的地址值(十六进制),但习惯于将整体称为地址值
索引:数组中从第一个数值开始为0,逐个加1
数组中的元素的访问:数组名[索引]
array01[0] = 2;//赋值,一旦赋值后,原来的值就不存在了
//遍历,取出所有数据的过程,数组名.length
//可用 数组名.length.fori 实现
//idea中可用 数组名.fori 实现
for (int i = 0; i < array01.length; i++) {
System.out.println(array01[i]);
}
int index = 0;
System.out.println(array01[index = 1]);// 打印的为1索引的元素
一个循环尽量只做一件事
动态初始化用于当只知元素个数时
静态初始化用于已知数据时
数组常见问题
//异常--Exception
//索引越界:访问了不存在的索引——ArrayIndexOutOfBoundsException
//找最大值时,max变量的初始值不能为0,原因:数组中元素均为负数,则有误
System.out.print();//不换行
06 内存,方法与数据类型
内存分配:栈,堆,方法区,本地方法栈,寄存器
栈:方法运行时使用的内存,比如main方法运行,进入方法栈中执行(被调用),结束后离开方法栈,变量也在栈内存的方法区里,在所属的方法中,地址值也在所属方法区,先进后出(最先调用的方法最后离开方法栈)
堆:存储对象或数组,new来创建的,都存储在堆内存,创建对象时,成员方法的地址也存储在其中
方法区:存储可以运行的class文件(临时存储),包括成员变量与方法
本地方法栈:JVM在使用操作系统功能时使用,与开发无关
寄存器:给CPU使用,与开发无关
int[] array = new int[2];//array实际上值为地址值
特殊情况
int[] array01 = array;//右边无new关键字
//所以此为把array的地址值赋值给array01,所以两者共用同一个地址值
//一者改变某个索引的值,另一个对应索引的值也会改变
方法是程序中最小的执行单元
public static 返回值类型 方法名(参数){
方法体;
return 返回值;
}
//-----------------------------------------------------------------------------
public static void main(String[] args){
getsum(10,20);//实参,实际参数,指方法调用中的参数,即已知具体值
}
public static void getSum(int sum1,int sum2){ //形参,形式参数,指方法定义中的参数,即不知具体值
int result = sum1 + sum2;
return;//即使为void,也可以使用return,用以结束方法,下面的语句无法执行到
}
一般把重复的代码或者具有独立功能的代码抽取到方法当中
当return后面写的是 变量名 = 要赋予的值 时,则返回值为要赋予的值,并且该变量的值也会相应改变
重载:在同一个类中定义了多个同名的方法,具有同种功能,但形参不同(个数,类型,类型顺序),与返回值无关
System.out.println("XXX");//先打印,后换行
System.out.print("XXX");//只打印
System.out.println();//只换行
基本数据类型:变量中存储的为真实值,赋的值也为真实值
引用数据类型:变量中存储的为地址值,赋的值也为地址值,两者共用同一地址值,一方改变改地址中的变量,另一者也会改变
07 快捷键
Ctrl + Alt + M: 自动抽取方法
Ctrl + /: 快速单行注释
Ctrl + Shift + /: 快速多行注释
Shift + F6: 变量批量修改
Ctrl + Alt + T: 快速添加代码块(如死循环)
Ctrl + P:查看创建对象时所需提供的数据
Alt + Enter: 对报错的内容进行操作
al();// 没有该方法,用alt + enter可以快速创建该方法,并将其传输的实参转为对应类型的形参
sc.next();// 用alt + enter可以快速创建对应类型的变量,以接收数据
Ctrl + Alt +V:可快速创建对应类型的变量,已接收数据,同上
Ctrl + Shift + U:快速将所选的单词等大写
Alt + 7:罗列出当前文件的所有类,类中的内部类,成员变量,成员方法,也可搜索
Ctrl + F12:与上的功能基本相同,但无法在调出的页面关闭前操作文件
Ctrl + Shift + Up/Down:将此行的内容向上移动
08 二维数组
二维数组
//静态初始化
//格式:数据类型[][] 数组名 = new 数据类型[][]{{元素1,元素2},{元素3,元素4}};
//简化:数据类型[][] 数组名 = {{元素1,元素2},{元素3,元素4}};
int[][] arr01 = new int[][]{{1,2},{3,4,5}};
int[][] arr02 = {{1,2},{3,4}};
//建议,方便观看
int[] arr03 = {
{1,2},
{3,4,5,6}
};
System.out.println(arr03[0]);//地址值,获取二维数组中第一个一维数组{1,2}
System.out.println(arr03[0][0]);//1
System.out.println(arr03[1][0]);//3
//动态初始化
int[][] array01 = new int[m][n];//m为多少个一维数组,n为每个数组可以放多少个元素
int[][] array02 = new int[m][];//只创建了二维数组,还未创建一维数组,可创建出长度不同的一维数组
09 类,对象与javabean
类的五大成员:属性,方法,构造方法,代码块,内部类
new 类名():可获取对应的对象,如Scanner
成员变量:代表属性(Fields),一般为名词,修饰符 数据类型 变量名称 = 初始化值; 一般无需指定初始化值,如姓名,每个人的姓名都不同,创建对象时一般都会修改,所以不用初始化值,定义在方法外
局部变量:定义在方法里
成员方法:代表行为,一般为动词
public class Phone{
//属性
String brand;// 默认修饰符为public 非static
double price;
//行为
public void call(){
System.out.println("手机在打电话");
}
}
public class PhoneTest{
public static void main(String[] args){
Phone p = new Phone();//创建对象
//给手机赋值
p.brand = "小米";
p.price = 1999.98;
//获取手机对象中的值
System.out.println(p.brand);
//调用手机中的方法
p.call();
}
}
类:是共同特征的描述。用来描述一类事物的类,叫做JavaBean类,无main方法;有main的为测试类
对象:是真实存在的具体实例,由new创建
建议:一个java文件中只写一个类
一个代码文件中可定义多个类,但时只能有一个类是public修饰的,public修饰的类名必须与java代码的文件名相同
面向对象三大特征:封装,继承,多态
封装:对象代表什么,就要封装对应的数据,并提供数据对应的行为。谁的状态变量,就把该行为放到谁那
public Door(){//对象代表门
boolean flag;//就要提供门对应的状态
public void open(){//并提供门的状态对应的行为:开门,关门
...
}
public void close(){
...
}
}
如:人画圆,需要人和圆两个类,画圆行为要封装到圆中,并提供半径属性;人关门,人只是给门一个力,真正的是门自己关起来的;张三看了李四,报道为张三持刀行凶,造成李四死亡,是李四死亡,死亡是李四的行为
private:修饰符,被修饰的成员只能在本类中才能访问,可通过setXX方法在其他类中进行赋值,用于判断成员变量被赋的值是否合法,用getXX方法获取变量值
this:因为就近原则,当成员变量与局部变量名称相同时,用name = name只是将局部变量name的值赋予其本身。当用this.name = name时是将局部变量name的值赋予成员变量name
构造方法:构造器,构造函数。作用:在创建对象的时候给成员变量进行赋值。不能手动调用,在创建时才会被调用。若没有写构造方法,虚拟机默认会加空参构造方法,若定义了构造方法,虚拟机不会给空参构造方法。可重载。
推荐:无论是否使用,都手写无参构造方法和带全部参数的方法
public class Student{
修饰符 类名(参数){//没有返回值类型,不能写return
方法体;
}
}
标准JavaBean:成员变量使用private修饰;提供至少两个构造方法;提供每一个成员变量对应的getXX()与setXX();类名见名知意
Alt +Insert:快速生成getXX/setXX/构造方法等方法
插件ptg:快速生成标准JavaBean
创建对象:1.加载class文件(当创建两个对象时,第二次不用再加载了),2.声明局部变量,3.在堆内存中开辟一个空间,4.默认初始化,5.显示初始化(直接给了值,如int i = 1; 0为默认初始值,1为显示初始值),6.构造方法初始化,7.将堆内存中的地址值赋值给左边的局部变量
10 printf,this,与输入
this本质:所在方法调用者(对象)的地址值
成员变量有默认初始值,局部变量无默认初始值,使用需赋值
System.out.printf("");//souf 第一部分参数,%s(占位) 第二部分参数,填充的数据 %d为整数
//如
System.ou.printf("你好啊%s","张三");//你好啊张三
System.ou.printf("%s你好啊%s","张三","李四");//张三你好啊李四
//注意一一对应,不能一对多
//printf不能换行
System.out.printf("我的年龄是%d",0);
Ctrl + P:查看创建对象时所需提供的数据
Scanner sc = new Scanner(System.in);
//第一套体系
sc.nextInt();//录入整数
sc.nextDouble();//录入小数
sc.next();//录入字符串
//遇到空格,制表符,回车就停止录入,这些符号的后面均不录入
//若有空格,如输入123 456
String s01 = sc.next();//输入123 456
System.out.println(s01);//123
String s02 = sc.next();
System.out.println(s02);//456
//第二套体系
sc.nextLine;//录入字符串,遇到回车才停止
//混用弊端
//先用nextInt()后用nexLine()会使nextLine()无法接收数据,只能接收第一次nextInt()输入的数据的第一个空格的后面的数据,如123 456 789,nextInt()录入的为123,nextLine()录入的为456 789
11 练习
练习
12 字符串及其比较与遍历
String对象一旦创建后就不能改变其值
String s = "abc";// 字符串创建后就不能改变
s = "abcdef";// 赋予其他值时,实际上是创建了新的字符串,并把它的地址值赋予s变量
s = s + "1"// 字符串拼接时,实际上创建了一个新的字符串,内容为abcdef1,并把其地址值赋予s
// 字符串创建方式
String s1 = "A";// 直接赋值,一般都用这个
String s2 = new String("要赋予的值");// 也可为空参
char[] chs = {'a','b','c','d'};
String s3 = new String(chs);// abcd
// 若想将字符串中某个内容改变,如abc变为Qbc,可把该字符串改为字符数组,再根据索引改值,然后用上述形式赋值
byte[] bytes = {97,98,99,100};
String s4 = new String(bytes);// abcd
// 网络中传输的都是字节信息,要把字节信息转换为字符串,可用上述形式
串池 StringTable 位置
- JDK7以前位于方法区
- JDK7以后位于堆空间
通过直接赋值形式的字符串都存储再串池中
String s1 = "abc";// 因为s1和s2都是通过直接赋值的形式创建的,且值相同
String s2 = "abc";// 所以当创建s2时,系统会在串池中查找是否有"abc",若有,直接赋值,地址值相同,否则创建,这样节约内存
char[] chs = {'a','b','c','d'};
String s3 = new String(chs);// new出来的,所以在堆中开辟空间
String s4 = new String(chs);// 又因为s4也用new形式创建,所以在堆中开辟新空间,地址值不同
==:若为基本数据类型(byte,short,int,long,double,float,char,boolean),比的是值,否则比的是地址值
输入的字符串如"abc",与代码中的字符串"abc"用==时为false,原因:输入的为new出的
比较:
// equals 比较字符串的值 对象1.equals(对象2)
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1 == s2);// false
System.out.println(s1.equals(s2));
// equalsIgnoreCase 忽略大小写,比较字符串的值 对象1.equalsIgnoreCase(对象2)
s2 = "ABC";
System.out.println(s1.equalsIgnoreCase(s2));
// 特别注意:
String s3 = "abc";
String s4 = "a" + "b" + "c";
System.out.println(s3 == s4);// true
// 原因:javac进行编译时会将非变量的字符串直接拼接 相当于 String s4 = "abc";
遍历
// 遍历字符串
String s = "钢门123吹小雪";
System.out.println(s.length());// 8 获取长度
System.out.println(s.charAt(0));// 钢 按索引获取字符
// 可通过以下方式进行char的比较
char c = 'm';
System.out.println(c >= 'a' && c <= 'z');//true
System.out.println(c >= '0' && c <= '9');//false
// s.forr 倒着遍历
13 字符串高级,StringBuilder与StringJoiner
截取
String phoneNumber = "12345678901";
String s = phoneNumber.substring(0,3);// 123
// 格式 变量名.subString(beginIndex,endIndex); 包左不包右,有返回值,不改变原变量的值
// 或者 变量名.subString(beginIndex); 从开始索引截至末尾,有返回值,不该变原变量的值
替换
String s = "你玩的真好,以后不要再玩了,TMD";
s = s.replace("TMD","***");
System.out.println(s);
//格式 变量名.replace(oldString,newString); oldString为字符串中原内容 有返回值,不对原变量改变
拼接
String s = "";
// 当拼接大量字符串时,该方法极慢,原因:字符串不可改变,每次改变都要新创建字符串,再赋值
for (int i = 0;i < 10000000;i++){
s = s + "abc";
}
StringBuilder sb = new StringBuilder("");// StringBuilder 可以看作为一个容器,创建后里面内容可变
// 因此,推荐用速度更快的append()方法
for (int i = 0;i < 10000000;i++){
sb = sb.append("abc");
}
变换
String s = "abc";
char[] cs = s.toCharArray();// 相当于char[] cs = {'a','b','c'};
顺序比较
String s1 = "a";
String s2 = "b";
s1.compareTo(s2);// 按字典顺序比较s1与s2,如果为-1则s1小于s2
StringBuilder
// StringBuilder 是java写好的类,java在底层对它做了一些特殊处理,使其被打印时为属性值,而非地址值
StringBuilder sb = new StringBuilder("abc");
//append 添加数据
sb.append(123); // 直接对sb操作 也有返回值,返回sb本身的地址值
//reverse 反转容器中内容
sb.reverse(); // 直接对sb操作 也有返回值,返回sb本身的地址值
//length 返回长度
int len = sb.length();
//toString 把StringBuilder 变为String
sb.toString();// StringBuilder 只是容器,无法被字符串赋值,需要转换为String类型进行后续操作
// 使用场景:字符串拼接与反转
链式编程:当我们在调用一个方法的时候,不需要变量接收他的结果,可以继续调用其他方法,如
int len = getString().substring(1).replace("A","Q").length();
StringBuilder sb = new StringBuilder("abc");
sb.append(123).append(0.1).append(true);// append方法返回了sb本身,sb可继续调用方法
StringJoiner
// 格式:StringJoiner sj = new StringJoiner(间隔符号);
StringJoiner sj1 = new StringJOiner("-");
// 格式:StringJoiner sj = new StringJoiner(间隔符号,开始符号,结束符号);
StringJoiner sj2 = new StringJOiner(",","[","]");
// add 对变量进行操作 返回容器本身 可用链式编程 只能添加字符串
sj1.add(1).add(2).add(3);// sj1 = 1-2-3
sj2.add(1).add(2).add(3);// sj2 = [1,2,3]
// length
System.out.println(sj1.length());// 5 sj1 = 1-2-3 共5个
// toString
String s = sj2.toString();
System.out.println(s);// [1,2,3]
14 字符串拼接与对象
String类型拼接时,一个加号会有两个对象
String s1 = "a";
String s2 = s1 + "b";
// 首先系统会先new一个StringBuilder对象(第一个对象)用于存储s1的值
// 然后系统会用append方法拼接
// 最后用toString方法将StringBuilder转化为字符串(第二个对象),然后存储在s2中
// JDK8以后字符串拼接原理
String s1 = "a";
String s2 = "b";
String s3 = s1 + s2;
// 首先系统系统会先预估字符串长度,然后创建等长度的数组,并将字符一一赋予,再拼接
StringBuilder是一个内容可变的容器
// StringBuilder 创建时默认会创建一个容量为16的字节数组
// 容量为最多能装多少,长度为实际能装多少
// 当容量不足时,StringBuilder会扩容:新容量 = 老容量 * 2 + 2,一次添加(有参或append)只可扩容一次
// 如果超出默认扩容的容量(如16扩容后为34),将会以实际长度为准(存储a~z,0~9时为36)
StringBuilder sb = new StringBuilder();
System.out.println(sb.capacity());// 获取容量
15 ArrayList定义与基本用法
集合ArrayList 长度可变
// ArrayList可自动扩容,不能直接存基本数据类型
import java.util.ArrayList;
// 泛型,用于限制集合存储数据类型<E>
// JDK7以前写法
ArrayList<String> list1 = new ArrayList<String>();//空参时默认长度为0
// JDk7以后写法
ArrayList<String> list2 = new ArrayList<>();
System.out.println(list2);// 结果为[],原因与String相同
用法
import java.util.ArrayList;
ArrayList<String> list = new ArrayList<>();
// 增 add(元素)
list.add("hello");
list.add("world");
System.out.println(list);// [hello, world]
// 删 remove(索引) remove(元素)
list.remove(0);// 返回被删除的元素
list.remove("world");// 返回布尔类型,不存在该内容时返回false,不报错
// 改 set(索引,元素)
list.set(1,"Alice");// 返回修改前的元素
// 查 get(索引)
String s = list.get(0);
// 长度 size()
int len = list.size();// 用于遍历
16 集合练习,break高级及程序的结束
添加基本数据类型,包装类
// int -> Integer char -> Character
// 除了上述两个其他基本数据类型的包装类都为首字母大写,如byte -> Byte
// 声明方法
ArrayList<Integer> list = new ArrayList<>();
list.add(1);// 在JDK5以后int与Integer可以相互转化
// 其他与int一样
break高级
// 标识符: 循环{
// 循环{
// break 标识符;
// }
//}
// 如下
int i = 0;
loop: while(true){
switch(i){
case 0:
i = 1;
break loop;// 跳出while(true)
default:
break;// 跳出switch,但不跳出while(true)
}
}
结束程序
System.exit(0);// 停止虚拟机运行 0代表正常退出
17 字符串首尾判断,面向对象进阶(静态)
// startsWith(内容) 判断字符串是否以该内容为开头
String s = "abcdefgh";
if(s.startsWith("a")){
System.out.println(true);
}
// endsWith(内容) 同理
static 静态 使成员变量的值公有化(共用变量的地址值),使类的方法可用 类.方法 进行调用
class A{
public static String a;// public 方便进行赋值与使用
public static void b1(){
}
public void b2(){
}
}
class B{
A a1 = new A();
A a2 = new A();
a1.a = "123";
sout(a2.a);// 123
// 调用方法
A.b1();
a1.b1();
A.b2();// 不可
a1.b2();// 可以使用对象调用
}
在加载字节码文件时,会在堆内存中生成静态存储位置(静态区),存储着所有的静态变量
而对象在类加载完后才通过new创建,所以静态变量优先于成员变量创建,静态变量不属于对象,属于类
静态变量推荐用类名调用:静态变量属于类,而非对象
/----------------------------------------------------------------------------/
实例变量即对象的成员变量
静态方法只能访问静态;非静态方法可以访问静态与非静态;静态方法无this,super关键字
public class Show(){
String name;
public void show1(){
// 非静态方法中隐藏了一个this,即形参 Show this ,所以可用this.成员变量
// 可在 method() 括号内写 Show this ,但调用方法时不能给其赋值
// this的值为虚拟机所给,为调用者的地址值
// 不能人为给他赋值,哪怕在 show1() 括号内写了Show this也不行
show2();// 实际上为 this.show2();
}
public void show2(){
}
public static void method(){
// 不可在 method() 括号内写 Show this ,否则报错
sout(name);// 报错,原因:没有对象,无法调用成员变量
// 调用成员变量与成员方法时,实际上要在其前面添加 this.
// 非静态方法有this,系统默认会调用
// 静态方法无this,无法调用对象的成员方法与成员变量
}
// 原因:非静态与对象有关,静态与对象无关
}
JDK8以前不管静态还是非静态都在方法区
JDK8以后静态变量存储在堆内存的静态存储位置(静态区)
/---------------------------------------------------------------------/
JavaBean类:用来描述一类事物的方法,可用来创建对象
测试类:检测其他类是否正确,有main方法
工具类:帮助我们做一些事情,但不描述任何事物,如Math,特点:私有化构造方法,不用来创建对象,方法都为静态
/----------------------------------------------------------------------------/
静态方法多用于测试类与工具类
String[] args:以前用于接收键盘录入的数据,现在没用,为了上下兼容而保留
录入的数据是IDE运行时的配置
红框内输入,用空格隔开,如123 456 789
则args为{"123","456","789"}
18 继承(extends,super)
命名:作用+父类名(如FileInputStream,File是该类的作用,InputStream是它的父类)
封装:对象代表什么,就要封装对应的数据,并提供数据对应的行为
若无封装,就需把原本被封装的对象的数据一一传入方法,要写很长,而封装只用传递对象
继承:当多个JavaBean类含有相同的成员变量与方法时,可将其封装入一个父类,子类可以使用父类中的成员变量与方法,提高了代码的复用性
// extends
public class Student extends Person{}
// 其中Student为子类(派生类),Person为父类(基类或超类)
// 使用时机:当类与类存在相同的内容,并满足子类是父类中的一种,可以考虑使用
// 如学生与老师都有名字等属性,都为人,可以使用继承
public class LiHua extends Cat,Animal{}//报错
// java只支持单继承(一子一父),支持多层继承(A继B,B继C,A为C间接父类,B为C的直接父类)
// java中每个类都直接或间接继承Object(若无继承,虚拟机会为其直接继承Object)
// 构造方法:父类的构造方法不可被继承
// 原因:构造方法与类名相同
// 成员变量:私有的成员变量可被继承,但无法调用
// 成员方法:虚方法表可被继承,否则不能
子类加载入方法区时,父类一并加入
继承的成员变量会存储在对象的空间中,与子类的成员变量共用同一对象的地址值,但一部分空间存储父类的成员变量(包括私有的,但无法调用),一部分存储子类
java会将父类中经常需要用的方法放在虚方法表中(非private 非static 非final),继承时把虚方法表交给子类,子类在其基础上添加自己类的虚方法
public class C{
public void c(){}
}
public class B extends C{
public void b(){}
}
public class A extends B{
public static void main(String[] args){
A a = new A();
a.c;
// 虚拟机会直接查A继承并添加后的虚方法表调用c,从而提高效率
// 若虚方法中没有,虚拟机则会一层一层往上找,直到找到再调用
}
}
Object有五个虚方法
继承中:
~成员变量的访问特点:就近原则
~优先级为 本类局部变量>本类成员变量>直接父类成员变量>间接父类成员变量
public class Fu{
String name = "Fu";
}
public class Zi extends Fu{
String name = "Zi";
public void ziShow(){
String name = "ziShow";
sout(name);// ziShow
sout(this.name);// Zi
sout(super.name);// Fu
// 使用super访问父类的成员变量与方法
// 若子类无同名变量,可用this关键字调用父类的成员变量
// 若 直接父类 与 间接父类 拥有同名变量,super调用 直接父类 的成员变量
// 不可用super.super.name调用间接父类的name,报错
// 静态方法不可调用super
}
}
~成员方法的访问特点:就近原则
~本类成员变量>直接父类继承的成员变量>间接父类继承的成员方法
// 方法的重写
// 当父类的方法不能满足子类的需求额时,需要进行方法重写
// 本质:将子类的方法覆盖虚方法表中的父类的虚方法
// 重写要求:
// 1)访问权限大于等于父类的
// 2)返回值类型子类必须小于等于父类
// 3) 方法名称,形参列表必须与父类一致
// 4) 只有添加到虚方法表中的方法可重写
// 5) 建议:重写的方法尽量与父类一致,方法体可不一致
// 返回值类型大小:父类>子类,同一直接父类的子类之间大小相同,只有有继承关系的类才有大小区别
public class Person{
public void eat(){
sout("不在吃饭");
}
}
public class Student extends Person{
// 重写需加上@Override,代码安全,若不是重写则会报错
@Override
public void eat(){
sout("在吃饭");
}
public void movement(){
this.eat();//自己的,若无自己的,则为继承的
super.eat();//继承的
}
}
public class Main{
public static void main(String[] args){
Student student = new Student();
student.movement();
}
}
~构造方法访问特点:不可继承;子类的构造方法默认先访问父类空参构造,以初始化父类中的数据
// 子类的构造方法第一句默认都是super();
// 不写也存在,必须第一行,即便第一行存在也不可以在其他行写
// 可手动调用父类有参构造方法
// 子类的全参构造需要把继承的成员变量加入,并在父类写上全参构造
// 然后子类通过super(实参);调用
this:理解为对象,对象的地址值为调用者本身,是局部变量
super:父类的存储空间
this():调用本类其他构造方法,则就不会添加super();了,原因:其他构造方法有super();,this()必须写第一行,当要给某些数据默认值时使用
19 多态,包,final,权限修饰符和代码块
多态(polymorphism):可以把new出的子类赋予父类和自己
class Person{}
class Student extends Person{}
// 多态 如下,将Student赋予Person
Person p = new Student();
Student s = new Student();
// 多态可以解决方法重构的麻烦
public void register(Student s){}
public void register(Person p){}
// 可变为
public void register(Person p){}
// 从而使代码减少,
// 根据传递的对象,调用的方法的内容也不同如Person.show()与Student.show()
多态前提:
1)有继承、实现关系
2)有父类引用指向子类对象,如Person p = new Student();Person指向了Student
3)有方法重写
多态好处:使用父类作为参数,可以接收说有子类对象
调用成员变量:编译看左边,运行也看左边
public class Fu{
String name = "Fu";
}
public class Zi extends Fu{
String name = "Zi";
}
Fu f = new Zi();
sout(f.name);//Fu 运行看的是左边的Fu中的name
// 若Fu没有name则编译错误,并报错
// 我的理解:name没有重写概念,所以虚拟机在查看父类的成员变量时,无法发现子类的同名变量
// 讲解:f是Fu类型的,所以默认从父类找
调用成员方法:编译看左边,运行看右边
public class Fu{
public void show(){
sout("Fu");
}
}
public class Zi extends Fu{
@Override
public void show(){
sout("Zi");
}
}
Fu f = new Zi();
f.show();//Zi 运行看的是右边的Zi中的show方法
// 若Fu没有show方法,则编译错误,并报错(要求:方法重写)
// 我的理解:运行时虚拟机会查看父类的show方法,若方法被重写,则调用重写的方法,否则调用父类
// 讲述:如果方法被重写,那么虚方法表中的方法被覆盖,调用时调用被覆盖的
// 若Fu有show方法,子类没有,则调用子类继承的show方法
在java中加载字节码文件时,先加载父类,在加载子类
多态优势
(1)在多态形势下,右边的对象可以实现解耦合,编译扩展与维护
Person p = new Student();
p.work();// 若业务发生改变时,后续代码无需修改,只用改变Student即可
// 如不想让学生工作,而让老师,只需,将Student()改为Tearcher()
(2)定义方法时,使用父类作参数,可以接收所有的子类对象,体现多态的扩展性与便利
ArrayList list = new ArrayList();
list.add(Object e);
// 若集合无泛型,则可添加任意元素,add()方法的形参类型为Object,所以可放入任意元素
// 这样就不用为每个对象都写一个add方法了
多态弊端:使用多态时,只会调用父类具有的方法,不能调用子类的特有功能,原因:编译看左边
解决方案
Animal a = new Dog();
Dog d = (Dog)a;
// 转化时会将父类的变量值,地址值赋予子类 继承 或 同名同类型 的变量
// 若转为其他类型,则会报错,如下
Cat c = (Cat)a;
c.catchMouse();//报错
// 避免,可进行类型判断后再转换
// JDK14以前
if(a instanceof Dog){
Dog d = (Dog)a;
d.lookHome();
}else if(a instanceof Cat){
Cat c = (Cat)a;
c.catchMouse();
}else{
sout("没有这个类型,无法转化");
}
// JDK14以后
if(a instanceof Dog d){
// 先判断a是否为Dog类型,如果是,将a转化为Dog类型,变量名为d
d.lookHome();
}
包名:公司域名反写+包的作用
package com.itheima.domin;//domin存放JavaBean类
// 使用其他类时,需要使用全类名,如
com.itheima.domin.Student s = new com.itheima.domin.Student();
// 为了简化,java使用了import关键字,将该类导入
// java默认会在本目录下查找类,所以本目录下可以不导包
// 导入重名类时,需用全类名(包名.类名),导包会冲突,报错
// java.lang不需要导入,直接使用,如String
// import需要导入类,而非包
// 格式 import 包名.类名
final:
~类:不能被继承
~方法:不能被重写
~变量:叫做常量,只能赋值一次,作为系统配置信息,方便维护,提高代码可读性,做枚举
public final void show(){}// final修饰方法,代表一种规则
final class Fu{}// final修饰类,不让该类的方法被重写,给别人使用源码时才有可能使用
final int ABC = 10;// final修饰变量,值不可改变
// 常量名若只有一个单词,全大写;多个,全大写,写每个单词用下滑线分开,如APPLE_COUNT
// 若为基本数据类型,变量存储的数据不可变
// 若为引用数据类型,变量的地址值不变,但里面的内容可变
// 字符串不可变就与final,private有关
// final使字符串的地址值不可变,private使这个字符串的地址无法获取(byte[]存储字符串)
native:修饰方法,调用本地c语言,汇编语言,在java中看不到方法体,与操作系统进行交互
// 如Object类中
public final native Class<?> getClass();// 获取本地字节码文件
权限修饰符及作用范围:
~private:同一类,可将本类中共性代码抽取出一个方法,该方法private,仅供本类使用
~空着不写(缺省、默认):同上,同包其他类
~protected:同上,不同包下的子类
~public:同上,不同包的无关类
代码块:
~局部代码块
psvm(){
{
// 可以单独使用,但里面定义的外面无法访问
}
}
~构造代码块:写在成员位置的代码块,可以把多个构造方法执行的抽取出来
缺点:不够灵活,若有个别构造方法不想执行构造代码块中的内容,无法做到
现在可通过将代码抽取到一个构造方法或方法中,然后调用
public class Student{
private String name;
public Student(){
sout("123");
}
public Student(String name){
sout("123");
this.name = name;
}
}
// 可将上述代码加入构造代码块,以简化代码
public class Student{
private String name;
{
sout("123");// 构造时调用,优先于构造方法执行
// 无论该构造代码块放于构造方法前还是后面
}
public Student(){
}
public Student(String name){
this.name = name;
}
}
~静态代码块:随着类的加载而加载,并自动触发,只执行一次
使用场景:在类加载的情况下,对成员变量初始化
public Student{
static {
sout("静态代码块执行了");
}
}
20 抽象,接口
抽象
抽象修饰符:abstract
抽象方法:将共性方法提取到父类,但每个之类执行后不同,所以父类中的不能确定具体的方法体,该方法就可以定义为抽象方法
抽象类:如果类中有抽象方法,该类就必须为抽象类
// 抽象方法
// 格式:public abstract 返回值类型 方法名(参数列表);
public abstract void work();
// 抽象类
// 格式:public abstract class 类名{}
public abstract class Person{}
注意事项:
(1)抽象类不能实例化(创建对象)
(2)抽象类不一定有抽象方法,抽象方法一定在抽象类或接口
(3)可以有构造方法,子类的构造方法可以调用 super(参数);
(4)抽象类的子类,要么重写抽象类中所有的抽象方法,要么是抽象类
意义:团队项目中,用于规范代码,统一方法,方便调用
/---------------------------------------------------------------------/
接口
接口修饰符:interface
接口调用:implements
意义:规范代码,统一方法
如 兔子,青蛙,狗都继承于动物,青蛙与狗会游泳,但兔子不会,因此需要给青蛙与狗一个单独的方法,但若是都写,代码可能不规范如 swim 与 swimming,因此需要接口
需要的是功能,而不是继承体系时,使用接口
接口是一种规则,是对行为的抽象
// 定义 public interface 接口名{}
// 接口不能实例化
// 接口中的方法不能有方法体,要为抽象方法
// 接口与类之间是实现关系,可以实现多个接口
// 使用 public class 类名 implements 接口名1,接口名2{}
// 格式 public class 类名 extends 父类 implements 接口名1,接口名2{}
// 接口的子类(实现类),要么重写接口中所有的抽象方法,要么是抽象类
成员变量:只能是常量,默认修饰符:public static final 没加会默认加,必须附默认值
public interface Swim{
String name;//报错
String name = "123";//正常,相当于如下
public static final String name = "123";
}
构造方法:没有
成员方法:
(1)JDK7以前只能写抽象方法,默认修饰符:public abstract
(2)JDK8接口可以定义有方法体的方法了
(3)JDK9接口可定义私有方法了
类与类的关系:继承关系,只能单继承,可多层继承
类和接口的关系,实现关系,可以多实现,多接口有重名,只用重写一次
接口与接口的关系:继承关系,可以单继承,也可以多继承,若类继承子接口,也需把其继承的抽象方法全部重写
21 接口进阶,内部类
默认方法
JDK8以后允许在接口定义默认方法,需用default修饰
// 定义格式 public default 返回值类型 方法名(参数列表){}
public default void show(){}
注意事项:
~默认方法不是抽象类,不强制重写,但如果被重写,需去掉default(重写的方法不加,接口不变)
~public可以省略,default不可省略
~如果实现了多个接口,多个接口中存在相同名字的默认方法,子类必须重写
接口中的默认方法若没被重写,对象可调用该方法(相当于继承下的方法)
// 在类中调用该类实现的接口中的默认方法
public interface Inter{
public default void m(){}
}
public class A{
@Override
public void m(){
Inter.super().m();
}
}
静态方法
JDK8以后允许在接口定义静态方法,需用static修饰
// 定义格式:public static 返回值类型 方法名(参数列表){}
public static void show(){}
注意事项:
~静态方法只能通过接口名调用,不能通过实现类名或对象名调用,不能重写
~public可省略,static不可省略
私有方法
JDK9新增的方法
// 普通私有方法定义格式:private 返回值类型 方法ming(参数列表){}
private void work(){}
// 普通私有方法给 默认方法 服务
// 静态私有方法定义格式:private static 返回值类型 方法ming(参数列表){}
private static void work(){}
// 静态私有方法给 静态方法 服务
接口的应用
接口的多态:如果方法的参数写成接口,则可传递所有的实现类对象
public interface F{}
public class A implements F{
public void work(F f){}
}
// 接口类型 变量名 = new 实现类对象();
F f = new A();
遵守多态规则:编译看左边,运行看右边
适配器设计模式
设计模式:是一套被反复使用,多数人知晓的,经过分类编目的,代码设计经验的总结
使用设计模式为了可重用代码,让代码更容易被他人理解,保证代码可靠性,程序的重用性
简单理解:设计模式就是各种套路
适配器设计模式:解决接口与接口实现类之间的矛盾问题
若一个接口有多个抽象方法,但只要用个别的方法时,若全部重写,代码会阅读不便
因此需要一个中转类,实现该接口,然后让需要实现个别功能的类继承该类,再重写个别方法
该类一般为抽象类,名字为XXXAdapter
内部类
在一个类中再定义一个类
外部类:普通类
内部类:定义在普通类中的类
外部其他类:也是普通类,只是相对而言
定义情况:内部类表示的事物,是外部类的一部分,且内部类单独存在无意义,如发动机类可定义在汽车类中,发动机要依赖车
内部类的访问特点:
~内部类可以直接访问外部类的成员,包括私有
~外部类要创建内部类的成员,必须创建对象
内部类分类:成员内部类,静态内部类,局部内部类,匿名内部类
除匿名内部类外,其他了解即可
成员内部类
写在成员位置,属于外部类的成员
能修饰成员变量的修饰符,也能修饰成员内部类
静态修饰的不是成员内部类
JDK16以前成员内部类中不能定义静态变量的
public class Outer {
class Inner {
}
public Inner getInner(){
return new Inner();
}
}
Outer o = new Outer();
// 创建方式一
// 在外部类创建方法用于创建内部类对象
Outer.Inner oi = new Outer.getInner();
// 或者
Outer.Inner oi = o.getInner();
// 创建方式二
// 使用 外部类.内部类 变量名 = 外部类对象.内部类对象
Outer.Inner oi = new Outer().new Inner();
// 或者
Outer.Inner oi = o.new Inner();
无论外部类的成员变量是否为private,内部类均可访问,可通过new 外部类.成员变量(默认值)或外部类.this.成员变量访问
public class Outer {
private int a = 10;
class Inner {
private int a= 20;
public void show(){
int a = 30;
System.out.println(new Outer().a);// 10
System.out.println(Outer.this.a);// 10
System.out.println(this.a);// 20
System.out.println(a);// 30
}
}
}
Outer.Inner oi = new Outer().new Inner();
oi.show();
不可通过内部类对象调用外部类的成员变量与方法
外部类与内部类在内存中是两个独立的字节码文件
$用于内部类的命名,系统命名,如内部类Inner的字节码文件Outer$Inner.class
因为new Outer().new Inner()中有两个new,所以在堆中开辟两个空间,外部类与内部类,在内部类中有一个隐藏的成员变量外部类名 this,不可通过内部类对象访问
静态内部类
只能访问内部类中的静态变量和静态方法,如果想要访问非静态的还需创建对象
// 创建静态内部类对象
// 外部类.内部类 对象名 = new 外部类.内部类();
// new的实际上是内部类
// 调用静态方法的格式:外部类.内部类.方法名();
静态内部类不能使用外部类.this.成员变量,可以使用new 外部类.成员变量
静态内部类的方法不能直接访问外部类的非静态成员变量,但可以访问静态
局部内部类
将类定义到方法内,类似局部变量,不可用权限修饰符,可修饰final,
外界无法直接使用,需要在方法内部创建对象并使用
该类可访问方法内局部变量与外部类的成员变量
很少用
匿名内部类
包括:继承与实现关系,方法的重写,创建对象
可以写在成员位置,也可写在局部位置
// 格式:
// new 类名或接口名(){
// 重写方法;
// };
new Inter(){
@Override
public void show(){
}
};
new Test(){
@Override
public void show(){
}
};
匿名内部类实际上是大括号(包括大括号)中的内容,new是创建该匿名内部类的对象
小括号的意思是调用了该匿名内部类的空参构造
Inter与后面的匿名内部类是实现关系
Test与后面的匿名内部类是继承关系,可以使用super进行调用Test中的方法
实际上并非没有名字,该匿名内部类的字节码文件名如Test$1.class
// 该文件反编译后结果
class com.nomit.study.learn.twentySecondDay.Test$1 implements com.nomit.study.learn.twentySecondDay.Swim {
com.nomit.study.learn.twentySecondDay.Test$1();
public void swim();
}
// 类名为 Test$1 实现了 Swim接口
使用场景:
~可以把匿名内部类的对象赋值给实现的接口
~当方法的参数时接口或者这个类时,以接口为例,可以传递这个接口的实现类对象,如果实现类只要使用一次,可使用匿名内部类简化
可以在匿名内部类的结尾通过 . 调用其中的所有方法,私有也可
22,23 项目——拼图
图形化界面:GUI
组件:JFrame,JMenuBar,JLabel....
JFrame:最外层的窗体
JMenuBar:最上层的菜单
JLabel:管理文字和图片的容器
JFrame
// JFrame
JFrame jFrame = new JFrame();// 创建对象时,就会创建窗体
jFrame.setSize(width,height);// 设置窗体大小
jFrame.setVisible(true);// 设置界面可视性,默认隐藏
jFrame.show();// 也是让窗口显示,但已过时,不推荐,与之相对有hide()方法
// JFrame可以理解为一个JavaBean类
// 属性(宽 高) 行为
将界面写为对象,如登入界面LoginJFrame,并继承于JFrame,则新建LoginJFrame对象时,就会创建登入界面窗体,该窗体涉及的逻辑代码都可以写于该类
通过对象的空参构造,来对对象初始化,其中setVisible()方法最后使用
// 标题
jFrame.setTitle("拼图");
// 置顶
jFrame.setAlwaysOnTop(true);
// 居中
jFrame.setLocationRelativeTo(null);
// 关闭模式
jFrame.setDefaultCloseOperation(3);
// JFrame已经实现了该接口,子类可直接使用
// 也可以通过实现WindowConstants接口,获取对应常量,如上述可表示为
jFrame.setDefaultCloseOperation(EXIT_ON_CLOSE);
// 也可通过接口名.常量进行调用
JMenuBar
~Jmenu
~~JmenuItem
// 初始化菜单
// 创建菜单对象
JMenuBar jMenuBar = new JMenuBar();
// 创建菜单上的选项对象
JMenu functionJMenu = new JMenu("功能");// 调用有参构造,设置选项的内容
JMenu aboutJMenu = new JMenu("关于我们");
// 创建选项下面的条目对象
JMenuItem replayItem = new JMenuItem("重新游戏");
JMenuItem reLoginItem = new JMenuItem("重新登入");
JMenuItem closeItem = new JMenuItem("关闭游戏");
// 前三个为功能中的选项,所以与下面隔开,以便查看
JMenuItem accountItem = new JMenuItem("公众号");
// 将每个选项下面的条目加入到菜单选项中
functionJMenu.add(replayItem);
functionJMenu.add(reLoginItem);
functionJMenu.add(closeItem);
aboutJMenu.add(accountItem);
// 将选项添加到菜单中
jMenuBar.add(functionJMenu);
jMenuBar.add(aboutJMenu);
// 给整个界面设置菜单
jFrame.setJMenuBar(jMenuBar);
可以在JMenu中放入JMenu,然后在被放入的JMenu中添加JMenuItem,以形成分支
推荐:将功能抽取到特定方法,以便后续对代码的改动,如与初始化窗体有关的可放在initJFrame()方法中,与初始化菜单有关的,可放在initJMenuBar()中,其中init为初始化
JLabel
// 初始化图片前需要先删掉已经存在的
jFrame.getContentPane().removeAll();
// 创建ImageIcon对象
ImageIcon icon = new ImageIcon(文件路径);
// 字符串中\需要转义,所以需要用\\代替\
// 创建JLabel对象
JLabel jLabel = new JLabel(icon);
// 把容器添加到页面
jFrame.add(jLabel);// 默认放在界面正中央
坐标以菜单下的左上角为原点
JFrame中除了标题栏和菜单栏外,还有一个隐藏的容器(Panel),存储所有组件,若没特殊要求,组件会在中间位置(默认)
// 初始化界面
// 取消默认的居中放置
jFrame.getContentPane().setLayout(null);
// 初始化图像
// 创建ImageIcon对象
ImageIcon icon = new ImageIcon(文件路径);// 若文件不存在,则空白
// 字符串中\需要转义,所以需要用\\代替\
// 创建JLabel对象
JLabel jLabel = new JLabel(icon);
// 在添加前指定图片位置
jLabel.setBounds(x,y,width,height);// x,y是左上角坐标,width与height是图片大小
// 给图片添加边框
jLabel.setBorder(Border接口的实现类的对象);
// 可以在api文档中查看java自带的该接口的实现类
// 其中BevelBorder更好看些
jLabel.setBorder(new BevelBorder(0));
// BevelBorder.RAISED,即0为图片凸起
// BevelBorder.LOWERED,即1为图片凹下,
//
// 把容器添加到页面
jFrame.add(jLabel);
// 添加完后刷新一下界面
this.getContentPane().repaint();
一维数组不方便锁定图片的位置,因此采取二维数组的形式,存储图片对应的序号,以便移动时交换图片的位置
注意:先加载的图片位于后加载的图片的上方
// 添加文字
JLabel stepCount = new JLabel("步数:" + step);//要显示的文字
stepCount.setBounds(50,30,100,20);
stepCount.setFont(new Font("微软雅黑",0,10));// 文字的字体与大小
jFrame.add(stepCount);
// 去除按钮默认边框
jbt.setBorderPainted(false);
// 去除按钮默认背景
jbt.setContentAreaFilled(false);
事件
事件源:按钮,图片,窗体
事件:某些操作
绑定监听:当事件源发生了某个时间,则执行某段代码
~键盘监听:KeyListener
~鼠标监听:MouseListener
~动作监听:ActionListener,鼠标与键盘的精简版,监听鼠标只能点击,监听键盘只有空格
ActionListener
// 创建一个按钮对象JButton
JButton jbt = new JButton("点我啊");
// 设置位置
jbt.setBounds(0,0,100,50);
// 添加动作监听
jbt.addActionListener(ActionListener的实现类对象);
// 可以用匿名内部类,也可以创建一个类
// 给jbt对象添加一个动作监听(鼠标左键点击,空格)
// 也可以使该类实现ActionListener,并重写其中的方法
// 然后将this传入,如
jbt.addActionListener(this)
// 把按钮添加在Panel容器
jFrame.getContentPane().add(jbt);
jFrame.add(jbt);
// 两种方法都可以
// 在实现了ActionListener的类中,重写其中的方法后,在该方法可使用
Object source = e.getSource();// 获取被按下的按钮对象
if(source == jbt1){
jbt1.setSize(200,200);
}else if(source == jbt2){
jbt2.setLoction(r.nextInt(500),r.nextInt(500));// 改变按钮位置
}
MouseListener
// 给按钮绑定MouseListener
jbt.addMouseListener(接口的实现类对象);
// 细节与ActionListener出入不大
// 其中,松开比单击事件触发更早
// 共有点击,按住不松,松开按键,滑入,滑出五个事件
keyListener
// 共有按住,松开,键入键(局限性较大,Alt等键无法监听,一般不用)三个事件
// 给整个窗体添加监听
jFrame.addKeyListener(接口的实现类对象);
// 其中在keyPressed方法中写的代码,若按住一个按键不松,则会重复调用
在keyReleased编写,按一次只执行一次
路径
绝对路径:从盘符开始
相对路径:从当前项目开始,如 day-code\image\background.png,day-code为本模块名
异常并不会使程序结束,而会在控制台报错
弹窗
JDialog
JDialog jDialog = new JDialog();
JLabel jLabel = new JLabel(new ImageIcon(图片路径));
// 设置图片在弹窗的什么位置
jLabel.setBounds(0,0,258,258);
// 把图片加到弹窗
jLabel.getContentPane().add(jLabel);
// 设置弹窗大小
jDialog.setSize(344,344);
// 置顶弹窗
jDialog.setAlwaysOnTop(true);
// 让弹窗居中
jDialog.setLocationRelativeTo(null);
// 弹窗不关闭,无法操作下面的页面
jDialog.setModal(true);
// 显示弹窗
jDialog.setVisible(true);
输入框
JTextField:明文显示的输入框
JPasswordField:密文显示的输入框
打包
考虑因素:一定要有图形化界面,代码,资源,jdk要打包
1.把所有带啊吗打包成一个压缩包。jar后缀
2.把jar包转化为exe安装包
3.把上一步的exe,图片,JDK整合在一起,变成最后的exe文件
需要软件exe4j,innosetup
24 Math,System,Runtime
Math
// 以下省略打印
// abs 获取绝对值,absolute
Math.abs(-2);//2
// 若负数为该类型的最小值,则它的绝对值是原值,原因:溢出
Math.absExact(-2);// 若产生溢出,则报错
// ceil 向上(更大的数)取整,天花板,负数去尾
Math.ceil(5.1);// 6
Math.ceil(-12.56);// -12
Math.ceil(5);// 5.0
// floor 向下取整,地板,整数去尾
Math.floor(5.8);// 5.0
Math.floor(5.0);// 5.0
Math.floor(-12.56);// -13.0
//round 四舍五入(不看符号,只看值)
Math.round(12.34);// 12.0
Math.round(12.54);// 13
Math.round(-12.34);// -12
Math.round(-12.54);// -13
// max 获得最大的数
Math.max(20,30);// 30
// min 获得最小的数
Math.min(20,30);// 20
// pow(a,b) 返回a的b次方值
Math.pow(2,3);// 8
Math.pow(2,0.5);// 1.4....
Math.pow(2,-2);// 0.25
// 一般b传递的大于等于1
// sqrt 求平方根
Math.sqrt(4);// 2
// cbrt 求立方根
Math.cbrt(8);// 2
//random 返回[0.0,1.0)的随机数
Math.random();
// 一般不用,比较麻烦
System
计算机的时间原点,1970年1月1日 00:00:00,C语言的生日
因为时差原因,中国的原点为1970年1月1日 08:00:00
1 s = 1000 ms
// exit 终止虚拟机
System.exit(0);
// 0:正常停止
// 1:异常停止
// currentTimeMillis(); 返回当前系统时间,以毫秒值形式
// 从时间原点到该代码执行时,过了多少毫秒
System.currentTimeMillis();//long类型
// 可以用于计算代码运行的效率
// arraycopy(数据源数组,起始索引,目的地数组,起始索引,拷贝个数); 数组拷贝
int[] arr1 = {1,2,3,4,5,6,7,8,9,10};
int[] arr2 = new int[10];
System.arraycopy(arr1,0,arr2,0,10);// 把arr1的数据拷贝到arr2
// 如果都是基本数据类型,那两者类型必须一致
// 超出范围也报错
// 如果都是引用数据类型,那么子类可以赋值给父类,即多态
Runtime
// 通过getRuntime()获取当前操作系统的运行环境对象,构造私有,方法非静态
// 这样,不管在哪里获取,都是同一个对象
Runtime r = Runtime.getRuntime();
// exit 与System一样,System调用了它
r.exit(0);
// avilableProcessors 获取Cpu线程数
sout(r.availableProcessors());// 2
// maxMemory 获取JVM能从系统获取的总内存大小(单位byte)
sout(r.maxMemory() /1024 / 1024);// 996
// totalMemory 获取JVM已经从系统获取的总内存大小(单位byte)
sout(r.totalMemory() /1024 / 1024);// 64
// freeMemory 获取JVM剩余的内存大小(单位byte)
sout(r.freeMemory /1024 / 1024);// 62
// exec(String command) 运行cmd命令
r.exec("notepad");
// 需要处理异常
shutdown -s:默认一分钟,-s -t:在t后面指定时间,要有空格 -r :关机并重启 -a:取消
25 Object,Objects,BigInteger
Object
Object是java中的顶级父类
// Object只有空参构造,原因:没有一个属性是所有类共有的
// toString 返回对象的字符串形式
Object obj = new Object();
String str1 = obj.toString();
System.out.println(str1);// java.lang.Object@4eec7777
// 前面是包名加类名,中间是@,固定格式,后面是地址值
// 与数组的类似,但前面的包名加类名变成了[
// 实际上直接打印对象也是一样的
// 原因:当打印对象时,底层会调用toString方法,返回的是地址值
// 可以重写对象的toString方法
// equals 比较两个对象是否相等
// clone 对象克隆
// 把账号数据转移到其他服务器
User u1 = new User(1,"name",23);
// 若要使用clone,需要重写,然后再重写的方法中调用父类的clone方法,原因:protected修饰
// 且User类要实现Cloneable接口,它没抽象方法,代表标记接口
Object u2 = u1.clone();// 要处理异常
// 两者地址值不同
如果打印对象时想要的结果为它的属性,可以重写toString方法,利用ptg插件可以一键做到
也可以用Alt + Insert重写该方法
标记接口:一个接口中没有抽象方法
Student stu1 = new Student();
Student stu2 = new Student();
sout(stu1.equals(stu2));// false
// 原因:Student没有重写equals方法,所以使用的是Object的equals方法
// 而Object的方法中比较的是两者的地址值是否相同,两者均new,所以false
// 可以用Alt + Insert重写该方法
// 不能用ptg插件
String s = "abc";
StringBuilder sb = new StringBuilder("abc");
sout(s.equals(sb));
sout(sb.equals(s));
// 均为false
// 第一个看String的方法,比较是否为字符串和值
// 第二个看StringBuilder的方法,比较地址值,未重写
浅克隆:将一个对象中的数据的值或地址值一一赋予给另一个对象中的属性
深克隆:如果是基本数据类型,则直接拷贝值,如果是引用数据类型,则会重新创建,然后把其中的值赋予,地址值不同,如果是字符串,则会复用,原因:在串池中存在
Object的clone为浅克隆,深克隆可自己重写,一般使用第三方工具(非官方的代码 Gson),该代码需导入到项目,并存储到模块名下的lib文件夹中
Objects
工具类,用类名调用方法
若一个对象的值为null,则不可使用其中的方法
可以自己检测对象是否为null,也可以使用Objects
// equals 若非同一个对象,则先做非空判断,再比较两个对象,调用的为对象中的equals方法
Objects.equals(对象1,对象2);
// isNull 判断对象是否为null,为null返回true
Objects.isNull(对象);
// nonNull 判断对象是否为null,为null返回false
BigInteger
比long更大
有上限,但非常大
对象一旦创建内部的值不可变,为引用数据类型
// 使用构造方法
// BigInteger(int num,Random rnd); 获取随机大整数,范围(0 ~ (2的num次方 - 1))
// BigInteger(String val); 获取指定的大整数
// val中非整数报错
// BigInteger(String val,int radix); 获取指定进制的大整数
// val的进制为radix,获取到的大整数为十进制
// 使用静态方法
// BigInteger.valueOf(long val)
// 不可超出long的取值范围
优化:BigInteger内部已经创建了-16~16的对象,获取时不会再创建对象了
若值比较小,推荐用静态方法valueOf
常见成员方法
BigInteger bg1 = BigInteger.valueOf(2);
BigInteger bg2 = BigInteger.valueOf(2);
// 都是通过对象调用
// add 加
// subtract 减
// multiply 乘
// divide 除
// divideAndRemainder 获取商与余数
bd1.divideAndRemainder(bd2);
// 获取的结果类型BigInteger[] 长度为2,0为商,1为余数
// equals 比较
bd1.equals(bd2);
// pow 次幂
bd1.pow(2);// 只能传入int类型
// max/min 返回最大值/最小值
bd1.max(bd2).sout();// 3
// 结果为大的BigInteger的地址值
// intValue 转为int类型,多余溢出
bd1.intValue();
// longValue
// doubleValue
原理
将数据的补码按每32个位为一组(110 有三位),存入数组中,数组有最大长度2147483647,但目前电脑存储不了这么多,将近能存储的最大数字位42亿的21次方,所以认为其几乎无限
26 BigDecimal,正则表达式,爬虫
BigDecimal
小数运算结果不精确,原因:小数的二进制,如0.9的小数部分二进制为11100110011001100.....,这样依旧无法精确,只是接近,计算时,因小数类型的长度有限,被舍弃的部分导致了运算不精确
BigDecima是不可变的、任意精度的有符号十进制数
// BigDecima(double val) 因为double的不精确,会导致该BigDecima不精确
// 所以不建议使用
// BigDecima(String val)
// valueOf(doule/long val)
// 若未超过double取值范围,建议使用静态方法
// 该静态方法中将传入的double变成了字符串,所以精确度较高
其中0~10的整数对应的BigDecimal已经创建,通过valueOf(long val)可获取,就不会再重新创建了
BigDecimal bd1 = BigDecimal.valueOf(10.0);
BigDecimal bd2 = BigDecimal.valueOf(3.0);
// add
bd1.add(bd2);
// subtract
// multiply
// divide(BigDecimal val)
// 除的尽可用,除不尽不可用
// 返回值为BigDecimal,若除后为X.0,则返回的为X,如10.0除2.0返回5
// divide(BigDecimal val,精确几位,舍入模式)
bd1.divide(bd2,2,BigDecimal.ROUND_HALF_UP);// 以前的写法,指保留两位,四舍五入
// 改写法JDK9过时了
bd1.divide(bd2,2,RoundingMode.HALF_UP);// 现在的写法
// 通过API帮助文档查看舍入模式
原理
举例:使用new BigDecimal(String val),java会对val进行遍历,得到每一个元素的ascii码,如"0.226"为[48,46,50,50,54],点也在其中,负号也会存在其中第一位,正号不存
正则表达式
// 要求:6位及20位以内,0不能开头,必须全是数字
String s = "1234567890";
// 格式:s.matches(正在表达式);
s.matches("[1-9]\\d{5,19}");
// [1-9]为第一个数字为1~9组成
// \\d代表后面的全由数字组成
// {5,19}意思为除第一位外后面还有5~19位
作用:(1)检验字符串是否满足规则(2)在一段文本中查找内容
字符类
正则表达式中[]表示范围
以下只匹配一个字符,只能一对一,若一对多则false,如[abc]的事例
若只有一个要求可删去中括号
[abc] 只能是a,b或c
"ab".matches("[abc]")// false
"ab".matches("[abc][abc]")// true
"a".matches("a")// true
[^abc] 除了a,b,c
"a".matches("[^abc]")// false
[a-zA-Z] a到z A到Z
"a".matches(["[a-zA-Z]"])// true
"0".matches(["[a-zA-Z]"])// false
"0".matches(["[a-zA-Z0-9]"])// true
[a-d[m-p]] a到d或m到p,同上,为了方便阅读
[a-z&&[def]] 在a-z与def中取交集,即d,e或f
&&为交集 [a-z&&[def]]
& 为包含& [a-z&[def]]
[a-z&&[^bc]] 在a-z中,出去bc都可,等同于[ad-z]
[a-z&&[^m-p]] 与上类似,等同于[a-lq-z]
预定义字符
因为java中\为转义字符,所以若想在字符串中使用\需要\
以下只匹配一个字符,只能一对一,若一对多则false,如\d的事例
除事例外,一个\代表两个\
. 任何字符
正则表达式中若想要表达含有.的需要转义
java中若想在正则表达式中使用\需要转义
所以共需转义两次,使用\\.
\d 一个数字[0-9]
"12".matches("\\d\\d")// true
\D 非数字[^0-9]
\s 一个空白字符[\t\n\x0B\f\r]
\S 一个非空白字符[^\s]
\w 英文,数字,下划线[a-zA-Z_0-9]
\W 非英文,数字,下划线[^\w]
数量词
也可以用来判断长度
X为字符类或预定义类
X? 一次或0次
"ad".matches("[abc]?")// false
"".matches("[abc]?")// true
"a".matches("[abc]?")// true
X* 0次或多次(包括1次)
X+ 一次或多次
X{n} 正好n次
X{n,} 至少n次
X{n,m} 至少n次,但不超过m次
通过API文档中的Pattern可查看可用正则表达式
使用小括号以达到分组的效果
如:(\.[a-zA-Z]{2,3}){1,2}代表小括号中的内容出现1~2次
使用|以对同一段数据进行多个规则的判断(写在方括号里表并集)
如:24小时的正则表达式,对小时的数字进行规范
([01]\\d|2[0-3])
括号起来方便阅读
^(正则表达式)$,若出现这种正则表达式,^代表从头开始,$代表到结尾,因java中所用的matches方法默认从头开始,到结尾结束,所以可以不用
(?i)abc 在匹配中忽略(?i)后面的大小写
a((?i)b)c 只忽略b的大小写
爬虫
Pattern:表示正则表达式
Matcher:文本匹配器
String str = "Java自从95年问世以来,经历了很多版本,目前企业中用的最多的是Java8和Java11," + "因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
// 获取字符串中所有的JavaXX
Pattern p = Pattern.compile("Java\\d{0,2}");
Matcher m = p.matcher(str);
// 拿着文本匹配器从头开始读取,寻找是否有满足规则的字符串,返回boolean
// 在底层还会记录起始索引和结束索引+1,原因substring包头不包尾
// 只有第一个满足条件的会被截取
boolean b = m.find();
String s1 = m.group();
System.out.println(s1);// Java
// 第二次再调用find,继续向下读取
b = m.find();
String s2 = m.group();
System.out.println(s2);// Java8
// 因为数量的未知,需要使用循环
Pattern p = Pattern.compile("Java\\d{0,2}");
Matcher m = p.matcher(str);
while (m.find()){
System.out.println(m.group());
}
从网络上爬取,暂时未学
URL url = new URL("http://sfzdq.uzuzuz.com/sfz/230182.html");
URLConnection conn = url.openConnection();
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
String regex = "[1-9]\\d{17}";
Pattern pattern = Pattern.compile(regex);
while((line = br.readLine()) != null){
Matcher matcher = pattern.matcher(line);
while(matcher.find()){
System.out.println(matcher.group());
}
}
br.close();
贪婪爬取
String regex = "Java(?=8|11|17)";
// 意思为获取后面带8,11或17的Java,只获取Java,即括号前的数据
// ?为占位
// =为寻找时包含后面的数据,获取时不包含
String regex = "Java(?:8|11|17)";
// 意思为获取后面带8,11或17的JavaXX,包括版本号
// ?为占位
// :为寻找时包含后面的数据,获取时也包含
String regex = "Java(?!8|11|17)";
// 意思为获取满足包含Java的数据,但不获取后面有8,11或17的Java
// !为去除满足带感叹号后面的数据,如Java18满足,但Java17不满足
// !为寻找时不包含后面的数据,获取时也不包含
贪婪爬取:在爬取数据时尽可能多获取数据
非贪婪爬取:在爬取数据时尽可能少获取数据
// 在Java中默认为贪婪爬取
String regex1 = "ab+";
// 若在数量词*或+后面添加?,那么是非贪婪爬取
String regex2 = "ab+?";
正则表达式在字符串方法中的使用
String s = "小诗诗dqwefqwfqwfwq12312小丹丹dqwefqwfqwfwq12312小惠惠";
// matcher(String regex) 判断
// replaceAll(String regex,String replacement) 替换
// 将满足正则表达式的数据替换为replacement中的数据
String result = s.replaceAll("\\w+", "vs");// 小诗诗vs小丹丹vs小惠惠
// split(String regex) 切割
// 将满足条件的数据切除,左右的数据放于数组
String[] ss = s.split("\\w+");// {"小诗诗","小丹丹","小惠惠"}
方法的形参为regex,则为正则表达式
分组
即小括号
每组都有组号,即序号,从1开始,连续不间断,以左括号为基准,最左边为第一组,依次往下
如:(\\w(\\w))(\\w)共有三组
捕获分组
即把这一组的数据拿出来,再用一次
//需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
//举例: a123a b456b 17891 &abc& a123b(false)
String regex1 = "(.).+\\1";// \\x为把第x组的数据再拿出来
//需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符
//举例: abc123abc b456b 123789123 &!@abc&!@ abc123abd(false)
String regex2 = "(.+).+\\1";
// 系统会进行多次匹配,直到找到正确(如第一个以abc开头,发现也可以以abc结尾)或结束
//需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致
//举例: aaa123aaa bbb456bbb 111789111 &&abc&&
String regex3 = "((.)\\2*).+\\1";
在正则表达式内使用\\;在正则表达式外部使用$
// 把重复的替换为单独的
String s = "我要学学编编编编程程程程程程";
System.out.println(s.replaceAll("(.)\\1+", "$1"));// 我要学编程
// 不用多次替换的原因:replaAll会将所有满足条件的都替换为对应的字符串
非捕获分组
仅仅括起来,但没组号,如(?=) (?😃 (?!)
更多的使用(?😃,原因:查找包括,获取也包括
27,28 时间类
同一条经线的时间是一样的
本初子午线以东加时间,以西减时间
以前:英国格林尼治的时间(GMT)为标准时间
现在:原子钟作为世界标准时间(UTC)
中国时间:东八区,即加8小时
Date
// 空参构造创建,默认表示系统当前时间
Date d1 = new Date();
System.out.println(d1);// Fri Jul 28 14:46:07 CST 2023
// 有参构造创建,表示指定时间,即从时间原点开始,过了X毫秒的时间
Date d2 = new Date(0L);
System.out.println(d2);// Thu Jan 01 08:00:00 CST 1970
SimpleDateFormat
格式化:把时间的格式改变
解析:把字符串表示的时间变为Date对象
// y 年
// M 月
// d 日
// H 时
// m 分
// s 秒
// E 星期
string pattern = "yyyy-MM-dd HH:mm:ss EE";
// 符合格式的如 2023-11-11 13:27:06 周六
Date d1 = new Date(0L);
// SimpleDateFormat() 使用默认格式
SimpleDateFormat sdf1 = new SimpleDateFormat();
// SimpleDateFormat(String pattern) 使用指定格式
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
String str2 = sdf2.format(d1);
System.out.println(str2);// 1970年01月01日 08:00:00
// format() 格式化,将日期对象变为字符串
String str1 = sdf1.format(d1);// 1970/1/1 上午8:00
// parse() 解析:将字符串变为日期对象
// 创建的SimpleDateFormat对象的格式要与字符串中的一致
String str3 = "2023-11-11 11:11:11";
SimpleDateFormat sdf3 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d2 = sdf3.parse(str3);
注意:0:01:00 与 0:0:0是同种格式
Calendar
应用场景:可单独修改,获取年,月,日
Calendar是抽象类
// 通过Calendar.getInstance()获取日历子类对象
Calendar c = Calendar.getInstance();
// 通过getInstance可获取针对所在时区的日历
// 会把时间中的纪元,年,月,日,时,分,秒,日期,等等信息放入数组
// getTime()
c.getTime();// 获取的为Date对象
// setTime(Date date)
// 如果获取的是月,则从0开始,到11截至,需要在获取的数据上加1
// 因为在外国人眼中周日是一周中的第一天,所以1为周日
Date d = new Date(0L);
c.setTime(d);
// getTimeInMillis()
// setTimeInMillis(long millis)
// get(int Field) 获取某个字段(属性或成员变量)的信息
c.get(Calendar.YEAR);// 共十七个字段可获取
c.get(Calendar.DAY_OF_WEEK);// 获取星期,但以周日开始
// Calendar.DATE 与 Calendar.DAY_OF_MONTH 一样
// set(int field,int value) 修改某个字段的值
c.set(Calendar.YEAR,2023);
// 注意
// 改前 2023,x
c.set(Calendar.MONTH,12);//因为1~12月的值为0~11,所以超出的会被计入下一年中
// 即 2023,1
// 其他同理,超出的算下一个的
// add(int field,int amount) 为某个字段增加或减少某个值
c.add(Calendar.YEAR,1);// 加一年
c.add(Calendar.YEAR,-1);// 减一年
JDK8新增时间类
优点:代码简便,多线程下JDK7的时间类会导致数据安全问题,但由于JDK8的时间类的对象不可变的原因,解决了这个问题
Date类:ZoneId,Instant,ZoneDateTime
日历类:LocalDate,LocalTime,LocalDateTime
日期格式化类:DateTimeFormatter
工具类:Duration,Period,ChronoUnit
ZoneId 时区
时区格式:洲名/城市名或国家名/城市名
// getAvailableZoneIds() 获取支持的所有时区
Set<String> zoneIds = ZoneId.getAvailableZoneIds();
System.out.println(zoneIds.size());
// systemDefault() 获取系统默认时区
ZoneId z = ZoneId.systemDefault();
System.out.println(z);
// of() 获取一个指定的时区
ZoneId of = ZoneId.of("Asia/Shanghai");// 如果时区不存在,则报错
System.out.println(of);
Instant 时间戳
获取的不带时区,须在基础上加8个小时
// now() 获取当前时间的Instant对象
Instant i = Instant.now();
System.out.println(i);
// ofXxxx() 根据(秒/毫秒/纳秒)获取Instant对象
Instant instant1 = Instant.ofEpochMilli(0L);// 毫秒
Instant instant2 = Instant.ofEpochSecond(1L);// 秒
Instant instant3 = Instant.ofEpochSecond(1L, 1000000000L);// 秒与纳秒
// atZone() 指定时区
ZonedDateTime zdt = Instant.now().atZone(ZoneId.systemDefault());
// isXxx() 判断系列的方法(Before,After)
Instant instant4 = Instant.ofEpochMilli(0L);
Instant instant5 = Instant.ofEpochMilli(1000L);
boolean result1 = instant4.isBefore(instant5);
// minusXxx() 减少时间系列的方法(Millis,Seconds,Nanos)
Instant instant6 = Instant.ofEpochMilli(3000L);
Instant instant7 = instant6.minusSeconds(1L);
// 由于JDK8新增的时间类对象不可变的特性,所以原值不变,返回新值
// plusXxx() 增加时间系列的方法
// 类似minusXxx()
ZonedDateTime 带时区的时间
// now() 获取当前时间的ZoneDateTime
// ofXxx() 获取指定时间的对象
// withXxx() 修改时间
// minusXxx() 减少时间
// plusXxx() 增加时间
DateTimeFormatter 用于时间的格式化和解析
// ofPattern() 获取格式对象
// format()
LocalDate
年,月,日
LocalTime
时分秒
LocalDateTime
年,月,日,时分,秒
// now() 获取当前时间对象
LocalDate localDate1 = LocalDate.now();
// of() 获取指定时间对象
LocalDate localDate2 = LocalDate.of(2023,12,31);//年,月,日
// getXxx() 获取日历中的信息
Month month = localDate1.getMonth();
// month的值为英文的月份
moth.getValue();// 通过该方法可以获取数字的月份
int month = LocalDate1.getMonthValue();// 也可以通过该方法直接获取
// 其他同理
// isXxx() 比较两个LocalTime
// withXxx() 修改时间
// minusXxx() 减少时间
// plusXxx() 增加时间
// toLocalDate() LocalDateTime转LocalDate
LocalDate localDate = LocalDateTime.now().toLocalDate();
// toLocalTime() LocalDateTime转LocalTime
// 类似上
// isLeapYear() 判断是否为闰年
Duration
用于计算两个时间的间隔(秒,纳秒)
// between()
Duration d = Duration(birthDay,today);
// toXxx()
d.toDays();// 转成总共的天数
获取总日,时,分,秒,毫秒,纳秒(整数)
Period
用于计算两个日期的间隔(年,月,日)
// between()
Period p = Period(birthDay,today);
sout(p);// 如:P22Y6M17D,即Period对象,相差22年,6月,17天
// getXxx()
p.getMonths();
// toTotalMonths() // 获取总月数
获取总年,月(整数)
ChronoUnit
用于计算两个日期的间隔
最常用
// ChronoUnit.XXXX.between();
String year = ChronoUnit.YEARS.between(birthday,today);
29,30,31 包装类,常见算法
包装类
基本数据类型所对应的应用数据类型,即用一个对象包装数据
若无包装类,则形参类型为Object时,无法将基本数据类型传入,程序会有局限性
JDK5以前,获取Integer对象需要new或者通过静态方法valueOf
// 构造方法
Integer i1 = new Integer(1);
Integer i2 = new Integer("1");
// new出的对象地址值不同
// valueOf()
Integer i3 = Integer.valueOf(1);
Integer i4 = Integer.valueOf("1");
Integer i5 = Integer.valueOf("1",8);// 通过进制创建
// valueOf() 获取的对象在-128~127间,对象的地址值不变,Integer类已经创建了这些对象
// 使用valueOf()时返回这些对象
// 通过直接赋值的方式获取的如果也在这个范围内,获取的对象也是已经创建好的
// 获取的对象不可改变,赋予新的值后,地址值改变
Integer i8 = Integer.valueOf(128);
Integer i9 = i8;
i8 = 129;
System.out.println(i9);// 128
// 由于JDK5以前包装类的特性,计算时需经历拆箱与装箱
int num = i1.intValue() + i2.intValue();// 拆箱
Integer i = new Integer(num);// 装箱
JDK5以后提出了自动装箱和自动拆箱机制
// 自动装箱
Integer i = 10;
// 在底层自动调用了valueOf方法得到对象
// 自动拆箱
int num = new Integer.valueOf(10);// 仅举例不代表构造方法及其他不会
Integer类型与int类型相加结果为int类型,原因:Integer是引用数据类型,无法运算,但在java的自动拆装箱的功能下,可以将其变为基本数据类型,然后再运算
静态方法
// parseInt(String s) 转换字符串为int
int i = Integer.parserInt("123");
// 非数字报错
// 八种包装类中,除了Character外,都有parseXxx()方法
// toBinaryString(int i) 得到二进制
// toOctalString(int i) 得到八进制
// toHexString(int i) 得到十六进制
常见算法
查找算法
基础查找
一个一个按顺序查找
public static boolean basicSearch(int[] arr,int target){
// 一个一个按顺序查找
for (int i = 0; i < arr.length; i++) {
// 如果找到返回true
if (arr[i] == target){
return true;
}
}
// 没有找到,返回false
return false;
}
二分查找
数组必须有序
1.定义min为0,max为数组最大索引,mid为两者和的一半(整数,小数舍去),
2.如果mid对应的数据大于目标值,max = mid - 1,重新获取mid的值,
3.如果mid对应的数据小于目标值,min = mid + 1,重新获取mid的值,
4.重复执行,直到获取到目标值,此时mid即为其索引,
5.如果min大于max,说明不存在目标值
public static int binarySearch(int[] arr,int target){
// 定义min为0
int min = 0;
// max为数组最大索引
int max = arr.length - 1;
// 如果min大于max,说明不存在目标值
while (min <= max){
// mid为两者和的一半(整数,小数舍去)
int mid = (min + max) / 2;
// 获取到目标值,此时mid即为其索引
if (arr[mid] == target){
return mid;
}
// 判断大小
if (arr[mid] < target){
// mid对应的数据小于目标值
min = mid + 1;
}else {
// mid对应的数据大于目标值
max = mid - 1;
}
}
return -1;
}
插值查找
若一个数列分布比较均匀或很均匀,如{2,4,6,8,10}
可利用公式查找
$$
mid = min + \frac {target - arr[min]}{arr[max] - arr[min]} \times (max - min)
$$
该方法是二分法的改进
斐波那契查找
该方法是二分法的改进
解释:
因为斐波那契数列的相邻连两个值的比逐渐接近于黄金分割比,所以用其中的值代替mid的索引
$$f(k) = f(k - 1) + f(k - 2)$$
其中f(k)与f(k-1)的值比接近黄金分割比
所以想要mid为数组的黄金分割点,需将f(k)作为整体长度,则f(k-1) - 1为mid的值(索引包括0)
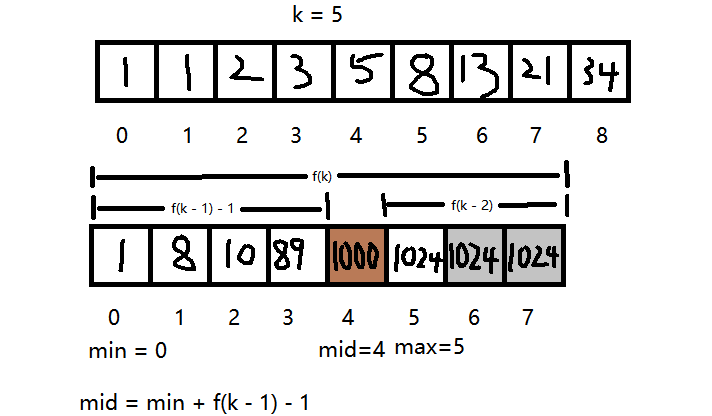
mid对应的值大于目标值,事例:在数组 {1,8,10,89,1000,1024} 中
因为数组的长度为6,所以f(k)的值是最接近6,且大于6的,所以k = 5
因为要使f(k)的值作整个数组的长度,所以会对数组进行扩容,且扩容的内容的值为最后一个数据的值
由公式
$$
mid = min + f(k - 1) - 1
$$
可得mid的值为4
如查找 89
因为索引4对应的数据的值大于目标值,所以max = mid - 1
因为mid左边的长度为f(k - 1) - 1,所以可近似认为其为f(k - 1),因此 新的k值 为 旧的k - 1
而f(k - 1) 与 f(k - 2)的值比接近黄金分割比 ,所以可以继续往下分割
综上,当mid对应的值大于目标值时,k--
如查找1024
因为索引4对应的数据的值小于目标值,所以min = mid + 1
因为mid右边的长度为f(k - 2),所以 新的k值 为 旧的k值 - 2
而f(k-2) 与 f(k - 3)的值比接近黄金分割比,所以可以继续往下分割
综上,当mid对应的值小于目标值时,k -= 2
注意:获取的索引值要为最小的那个,因为最后一个的值有被复制,可能会返回大于原数组长度的索引
分块查找
在无序中有序
把数组分成n份小块,前一块的最大数据,小于后一块的最小数据
块数数量一般等于数字的个数开根号,比如16个数字一般分为4块
每一块都创建对象,记录每一块的最大值,起始索引,结束索引,该对象称为索引表
然后通过方法获取目标值在哪一块
private static int findNumberRange(Block[] blockArr, int number) {
for (int i = 0; i < blockArr.length; i++) {
if (blockArr[i].getMax() >= number){
return i;
}
}
return -1;
}
各块间最大值有序
拓展思想
记录最小值,可以应对各块间最大值无序的情况
哈希查找
分块查找的优化
排序算法
冒泡排序
效率一般
把相邻的数据两两比较,小放前面,大放后面
选择排序
效率一般
从0索引开始,拿着每个索引上的元素跟后面的元素一次比较,调整位置
插入排序
效率较高
共有N个数据,把0索引到n索引的有序数据看作有序,另外的数据看作为无序,通过遍历得到每个无序的数据,并将其插入到有序数据中,如有相同,插后面
public static void sort(int[] arr,int startIndex){
// startIndex为无序部分的开始索引
for (int i = startIndex; i < arr.length; i++) {
int j = i;
while (j > 0 && arr[j] < arr[j - 1]){
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
j--;
}
}
}
快速排序
效率高
递归算法:方法中调用本身,可能会有栈内存溢出的异常,每次调用都会将该方法加载到栈内存
注意:递归一定要有出口,即停止调用,在每一次再次调用方法时,参数一定比上一次更靠近出口
第一轮:把0索引的数字当作基准数,确定基准数的正确位置,比基准数小的全在左边,大的在右边
基准数归位,基准数到达正确的位置
第二轮:在基准数的左边确认新的基准数及其位置,在基准数的右边确认新的基准数及其位置,重复执行,直到起始索引大于终止索引
public static void sort(int[] arr,int i,int j){
int start = i;
int end = j;
// 退出递归
if (start > end){
return;
}
// 定义基准数
int baseNumber = arr[i];
// 找到基准数的合适位置
while (start != end) {
// 先移动右边的指针
while (true) {
if (end <= start || arr[end] < baseNumber) {
break;
}
end--;
}
// 再移动左边的指针
while (true) {
if (end <= start || arr[start] > baseNumber) {
break;
}
start++;
}
int temp = arr[start];
arr[start] = arr[end];
arr[end] = temp;
}
// 基准数归位
int temp = arr[i];
arr[i] = arr[start];
arr[start] = temp;
// 基准数左边递归操作
sort(arr,i,start - 1);
// 基准数右边递归操作
sort(arr,start + 1,j);
}
如果start比end先移动,则在基准数归位时,会把大于基准数的数移动到左边
Arrays
int[] arr1 = {1,2,3,4,5,6,7,8,9,10};
// toString(数组) 把数组拼接成一个字符串
System.out.println(Arrays.toString(arr1));
// [1,2,3,4,5,6,7,8,9,10]
// binarySearch(数组,查找的元素) 二分法查找元素
// 要求:必须有序,且是升序
// 如果不存在返回(-插入点-1),插入点为该元素应在位置
// 如:20大于10,所以20应在10后面,而最大索引为9,则插入点为10
// 减1的原因:如果查找数字0,0应在1前面,而数组的索引最小为0,所以插入点为最小的0,所以要减1
System.out.println(Arrays.binarySearch(arr1,9));// 8
System.out.println(Arrays.binarySearch(arr1,20));// 11
// copyOf(原数组,新数组长度) 拷贝数组
// 调用了System.arrayCopy()
// 如果新数组的长度小于老数组,部分拷贝
// 如果新数组的长度大于老数组,补上默认初始化值
int[] arr2 = Arrays.copyOf(arr1,15);
System.out.println(Arrays.toString(arr2));
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 0, 0, 0, 0, 0]
// copyOfRange(原数组,起始索引,终止索引) 拷贝数组(指定范围)
// 包头不包尾
int[] arr3 = Arrays.copyOfRange(arr1,0,5);
// fill(数组,元素) 填充数组
Arrays.fill(arr3,100);
System.out.println(Arrays.toString(arr3));
// [100, 100, 100, 100, 100]
// sort(数组) 按默认方法进行排序
// 使用快速排序,排为升序
int[] arr4 = {1,5,6,4,8,2,9,3,7};
Arrays.sort(arr4);
System.out.println(Arrays.toString(arr4));
// [1, 2, 3, 4, 5, 6, 7, 8, 9]
// sort(数组,排序规则) 按指定的方法排序
// 只能给引用数据类型排序
// 底层原理:利用插入排序与二分查找
// 默认把0索引当作有序,1索引及其以后为无序
// 遍历无序序列得到每一个元素,假设当前遍历的元素为A元素
// 把A元素往有序序列中插入,利用二分查找确定其插入点
// 使用A元素与插入点的元素比较,比较的规则就是compare中的方法体
// 返回值为负数,则A继续与前面的数据比较
// 返回值为正数或0,则A继续与后面的数据比较
// 直到确认其位置
Integer[] arr5 = {6,7,5,9,1,2,8,4,3};
Arrays.sort(arr5,new Comparator<Integer>(){
// 参数o1:在无序序列中得到的元素
// 参数o2:有序序列中的元素
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
System.out.println(Arrays.toString(arr5));
// [9, 8, 7, 6, 5, 4, 3, 2, 1]
Lambda
简化匿名内部类的书写
Arrays.sort(arr5,(Integer o1, Integer o2) -> {
return o2 - o1;
}
);
面向对象:先找对象,让对象做事情
函数式编程:一种思想特点,忽略了面向对象的复杂语法,强调做什么,而不是谁去做
JDK8出现的新语法形式
() -> {
}
注意
~Lambda表达式只可以用来简化匿名内部类的书写
~Lambda表达式只能简化函数式接口的匿名内部类写法
函数式接口:有且仅有一个抽象方法的接口,接口上方可以加@FunctionalInterface,不满足要求报错
Lambda的省略写法
核心:可推导,可省略
~参数类型可以省略不写
~如果只有一个参数,小括号可以省略不写,省略小括号就必须省略参数类型
~如果Lambda表达式的方法体只有一行,大括号,分号,return可以省略不写,需同时省略
多参数不能省略小括号原因:匿名内部类被使用时,一般都是方法的实参,而实参间用逗号隔开,会使java无法分辨(推导)出其参数,如a(1,( a1,a2) -> {})变为a(1,a1,a2 -> {}),难以分清
// 第一种与第三种省略,return o1 - o2;中return与分号被省略
Arrays.sort(arr, (o1, o2) -> o1 - o2);
// 若只有一个参数,假设
Arrays.sort(arr, o1 -> o1 - 2);
32,33,34,35 集合进阶
单列集合:一次添加一个数据
双列集合:一次添加一对数据(如python中的字典)
Collection
是单列集合的顶层接口
Collection<String> coll = new ArrayList<>();
// add(E e) 把给定的对象添加到当前集合
// 如果向List系列中添加数据,永远返回true,原因:可重复
// 如果向Set系列中添加数据,如果存在,返回false,添加失败
coll.add("a");
System.out.println(coll);// [a]
// clear() 清空当前集合所有的元素
coll.clear();
System.out.println(coll);//[]
// remove(E e) 把给定的对象在元素中删除
// 因为Collection的实现类中,set系列没有索引
// 所以共性中没有按索引删除的方法
coll.add("aaa");
coll.add("bbb");
coll.remove("aaa");
System.out.println(coll);// [bbb]
// contains(Object obj) 判断当前集合是否包含指定的对象
// 依赖equals方法进行判断
System.out.println(coll.contains("aaa"));// false
// isEmpty() 判断当前集合是否为空
// 空为true
System.out.println(coll.isEmpty());
// size() 返回当前集合的长度
System.out.println(coll.size());
通用遍历
迭代器遍历,增强for遍历(不依赖索引遍历),Lambda表达式遍历
迭代器遍历
Iterator
想要删除元素时使用
Collection<String> coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
// iterator() 获取迭代器对象,默认指向0索引
Iterator<String> it = coll.iterator();
// hasNext() 判断当前位置是否有元素,有则false
while(it.hasNext()) {
// next() 获取当前位置的元素,并将迭代器对象移向下一个位置
String str = it.next();
System.out.println(str);
// remove() 删除当前指针的前一个元素
// 又因为使用next()方法后指针移向了下一个元素,所以修改的就是next()获取的元素
if(str.equals("bbb")){
it.remove();
}
}
注意:
~迭代器遍历完毕后指针不会复位,需重新创建
~若在hasNext为false的情况下,依旧使用next,则会报错NoSuchElementException
~在循环中只能用一次next方法,不然可能会发生上述的错误
~迭代器遍历时,不能用集合的方法进行增加或删除元素,会报错
~每次使用next方法时,都会对数组的修改次数进行判断,所以在调用后修改数据,直到下一次调用next方法,否则不会报错
增强for遍历
增强for出现于JDK5,底层就是Iterator迭代器,是为了简化迭代器代码
只有所有的单列集合和数组可用增强for
不可删除元素
// 格式
for(元素的数据类型 变量名: 数组或集合){
}
// s会依次表示集合中的每一个数据
// 修改s的值,若修改的是地址值,则不会影响coll中的值
// 若修改s对象或数组等内部中属性或元素的值,则可以改变
// 一些一旦创建就无法修改的值,修改时就是修改地址值(如String,Integer,BigInteger)
for (String s: coll){
System.out.println(s);
}
使用 数组名.for 可快速生成
Lambda表达式遍历
不可删除元素
// forEach()
// 方法的底层会依次遍历集合,并将值传给s
// s为集合中的每一个数据
coll.forEach(s -> System.out.println(s));
List系列
List为接口,不可直接创建
特点:添加的元素是有序的(添加时的顺序与遍历时的顺序相同),可重复的,有索引的
ArrayList,LinkedList,Vector(在1.2时被淘汰了)
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
// add(int index,E element) 在指定索引插入元素
// 原来索引上的元素会依次往后移
list.add(1,"q");
System.out.println(list);// [a,q,b,c]
// remove(int index) 删除指定索引上的元素,返回被删除的元素
// 若list的泛型为Integer等整数类型,则使用remove方法时
// 形参会默认为index,即按索引查找
// 原因:调用方法时,优先会调用实参与形参类型一致的方法
// 按元素查找的形参类型为Object(即Integer等),而索引为int
// 若要使用按元素查找,需先对int手动装箱,然后再调用
String s = list.remove(1);
System.out.println(s);// q
// set(int index,E element) 修改指定索引上的数据,返回被修改的元素
String str = list.set(0, "Q");
System.out.println(list);// [Q,b,c]
System.out.println(str);// a
// get(int index) 返回指定索引上的元素
String s1 = list.get(0);
遍历方式
包括迭代器遍历,增强for遍历,Lambda表达式遍历
以及List独有的列表迭代器遍历与普通for循环
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
// 迭代器
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
System.out.println(s);
}
// 增强for
for (String s : list) {
System.out.println(s);
}
// Lambda表达式
list.forEach(s -> System.out.println(s));
// 普通for
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 列表迭代器
ListIterator<String> lit = list.listIterator();
while(lit.hasNext()){
String s = lit.next();
if (s.equals("a")){
// 使用迭代器本身的add方法,不会报错
lit.add("123");
}else if (s.equals("b")){
// 使用迭代器本身的remove方法,不会报错
lit.remove();
}else if (s.equals("c")){
// 使用迭代器本身的set方法,不会报错
lit.set("ppp");
}
}
list.forEach(s -> System.out.println(s));
//a 123 ppp,添加了123,删除了b,将c改为ppp
其中,若想删除元素,使用迭代器
若想添加或修改元素,使用列表迭代器
仅仅想遍历,使用Lambda表达式或增强for
若想操作索引,使用普通for
ArrayList
数据类型:数组
默认长度:0
当添加第一个元素后,底层会创建一个新的长度为10的数组,该数组名字为elementData
存满后,扩容1.5倍
一次添加多个元素,1.5倍还放不下,则新创建的数组以实际为准
// addAll() 批量添加数据
list1.addAll(list2);
其中的modCount变量为变化的次数g'g'g'g'g'g'g'g'g'g'g'g'g'g'g'g'g'g'g
LinkedList
数据结构:双向链表
// 了解就好,很少使用
// addFirst() 在头结点插入指定元素
// addLast() 将指定元素追加到末尾
// getFirst() 获取第一个元素
// getLast() 获取最后一个元素
// removeFirst() 删除并返回第一个元素
// removeLast() 删除并返回最后一个元素
内部类Node的对象为一个结点
LinkedList对象一旦创建,就会创建头结点与尾结点,但都是默认初始化值null
Set系列
Set为接口
特点:添加的元素是无序的,不重复的(用于数据的去重),无索引的
HashSet,LinkedHashSet(HashSet子类),TreeSet
无序性
Set<String> s = new HashSet<>();
s.add("aaa");
s.add("bbb");
s.add("ccc");
System.out.println(s);// [aaa,ccc,bbb]
HashSet
采用哈希表的数据结构存储
存储自定义对象时,必须重写equals与hashCode方法
去重默认使用HashSet,除非要求有序,因为LinkedHashSet消耗资源更多
底层原理
1)首先会创建一个默认长度为16,默认加载因子为0.75的数组,数组名为table(重要)
2)然后根据公式算出存入位置
3)判断当前位置是否为null,是null则存
4)如果不是null,调用equals方法比较
5)一样则不存,不同则存入数组,并形成链表
JDK8以前:新元素存入数组,老元素挂下面
JDK8以后:新元素挂老元素下面
当数组长度为 长度 * 加载因子 时进行扩容,扩容两倍
当链表的长度大于8,而且数组的长度大于等于64时,当前链表转换为红黑树 (JDK8以前没有)
HashSet无序性
添加时按照hashCode来存储,导致了存入的元素的先后位置的不同
无索引
hashSet底层有数组,链表,红黑树,导致索引难以定义
无重复
再添加时会比较hashCode与equals两个方法进行比较,相同的就不会存入了
LinkedHashSet
HashSet的子类
但有序
原理:底层数据结构依旧是哈希表,只是每个元素有额外多了一个双链表记录存储顺序
存入的第一个元素会存着下一个元素的地址值,下一个元素又存着上一个元素的地址值
TreeSet
可排序,默认按从小到大的顺序
数据结构:红黑树
排序规则:
~对于数值类型:Integer,Double,默认按照从小到大的顺序排列
~对于字符、字符串类型:按照字符在ASCII码表的数字升序进行排序,短的在其他字符都相同的情况下更小
如:aaa在aaaa前面
~自定义类:自己定义比较方式
默认使用第一种方式,第一种方式不能实现,再使用第二种方式
当方式一与方式二同时存在时,以方式二为主
第一种排序方式
默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则
自定义类要实现Comparable接口
不必重写equals与hashCode方法
根据重写的compareTo方法的返回值进行判断
~返回值为0,则认为是同一元素,舍弃
~为负数,则认为其更小,存左边
~为正数,则认为其更大,存右边
根据上述的规则,可以对其进行排序
添加根节点时,根节点会与自己比较
@Override
public int compareTo(Student o) {
return this.getAge() - o.getAge();
}
第二种排序方式
比较器排序:创建TreeSet对象时,传递比较器Comparator指定规则
实际传的是Comparator实现对象,可用匿名内部类,或Lambda表达式
// o1为当前要添加的元素,o2为存在的元素
// 返回值规则同 自然排序
TreeSet<String> ts = new TreeSet<>(
(o1, o2) -> {
int i = o1.length() - o2.length();
return i == 0 ? o1.compareTo(o2) : i;
});
使用场景
-
如果想要集合中的元素重复,使用ArrayList集合
-
如果集合中增删操作明显多于查询,使用LinkedList集合
-
如果想要对集合中的元素去重,使用HashSet集合
-
如果想要去重,且保证存储顺序,使用LinkedHashSet集合
-
如果想要对元素排序,使用TreeSet集合
数据结构
计算机底层存储,组织数据的方式
指数据相互之间是以什么方式排列在一起的
数据结构是为了更加方便的管理和使用数据
八大基础结构:栈,队列,数组,链表,二叉树,二叉查找树,平衡二叉树,红黑树
栈
特点:后进先出,先进后出
数据进入栈的过程称为压栈/进栈
数据离开栈的过程称为弹栈/出栈
最上面的数据称为栈顶元素
最下面的数据称为栈底元素
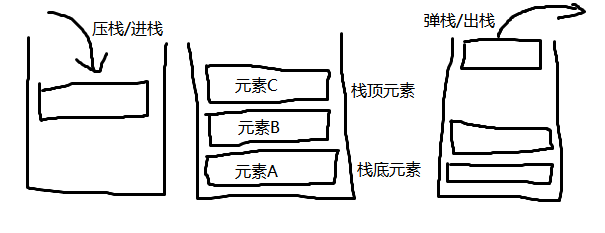
栈内存运用的也是这种思想
队列
先进先出,后进后出
要求:数据从后端进,从前端出
从后端进队列叫入队列
从前端出队列叫出队列
类似买票排队
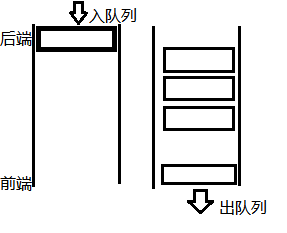
数组
查询效率高:通过地址值和索引定位,查询任意数据耗时相同(元素在内存中是连续存储的)
删除效率低:将原始数据删除,同时每个数据前移
添加效率低:将每个数据后移,再将指定元素添加
链表
查询效率低:无论查询哪一个数据都要从头结点开始找
删除效率高:不用移动其他结点
添加效率高:不用移动其他结点
每一个元素称为结点,每个结点都是独立的对象,所以都有独立的地址值,在内存中不连续
结点中存储了本结点要存储的数据,同时存储了下一个结点的地址值
第一个被创建的结点为头结点,若无后续的结点,则再下一个结点的地址值的位置上存储^
在每次创建完新结点后,将该结点的地址值赋予前一结点的存储下一个地址值的位置上
单向链表:只能从前往后找
双向链表:可以从后往前找,该链表的结点中存储了本结点的值,上一个结点的地址值,下一个结点的地址值,当查询第几个元素时,查询效率提升
树
每个元素都是一个节点(结点),即Node
每一个节点都关联两个节点
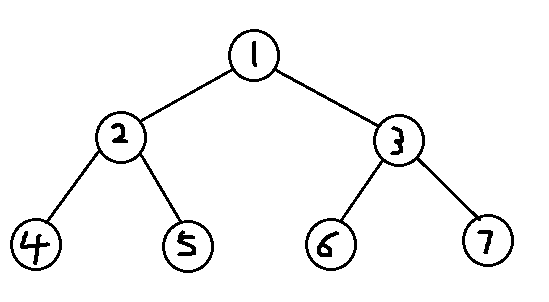
父节点:节点2是节点4与节点5的父节点
左子节点:节点4为节点2的左子节点
右子节点:节点5为节点2的右子节点
节点4无左子节点与右子节点
内部结构:每一个节点都是一个独立的对象,存储着值,父节点的地址,左子节点的地址,右子节点的地址
度:每一个节点的子节点数量,在二叉树中,任意节点的度<=2
树高:即树的总层数,上图共有3层
根节点:最顶层的节点
根节点的左子树:即根节点的左子节点作为根节点所产生的树
根节点的右子树:即根节点的右子节点作为根节点所产生的树
二叉树
即每一个节点存储的值并没有什么规律
弊端:没规律,查找效率低
遍历方式
前序遍历
从根节点开始,按照当前节点,左子节点,右子节点的顺序遍历
类似沿着外圈跑步,已经跑过的地方不再算入,直到回到起点
按照中序的图,则为A B D E C F G
中序遍历
最重要
从最左边的子节点开始,然后按照左子节点,当前节点,右子节点的顺序遍历
即将每一个节点都投影到最低层
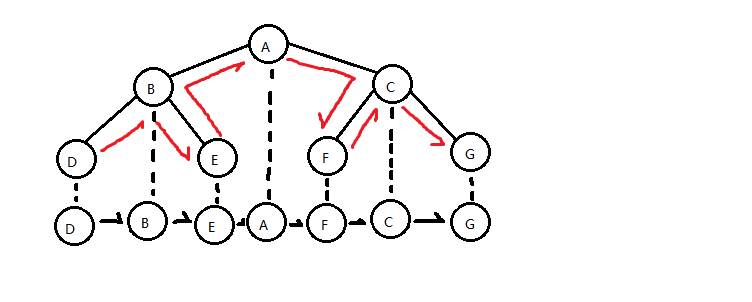
按照如图,则为D B E A F C G
在二叉查找树,按中序遍历的方式,获取的元素是从小到大的
后序遍历
从最左边的子节点开始,然后按照左子节点,右子节点,当前节点的顺序遍历
按照中序的图,则为D E B F G C A
层序遍历
从根节点开始一层一层的遍历,每一层从左到右依次获取
按中序的图,则为A B C D E F G
二叉查找树
又叫二叉排序树,二叉搜索树
查找效率较高
特点
~每一个节点上最多有两个子节点
~任意节点的左子树上的值,都小于当前节点
~任意节点的右子树上的值,都大于当前节点
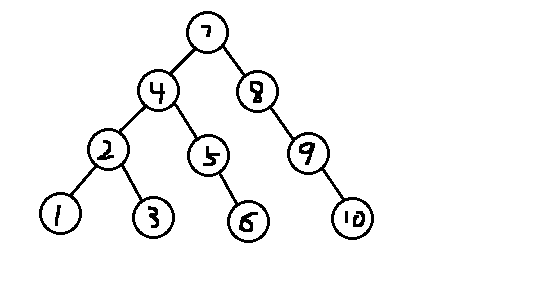
添加规则:小的存左边,大的存右边,一样的不存
查找规则:小的查左边,大的查右边,一样的返回,不存就false
弊端:极度依赖于第一个元素(根节点)的值的大小,可能会出现只有右子树或左子树的情况,导致左右子树高度差极大,与链表无异,查找效率低
如存7,8,9,10,就没有根节点的左子树
平衡二叉树
高度平衡
规则:任意节点左右子树高度差不超过1
查找效率较高
旋转机制:当添加一个节点后,该树不再是平衡二叉树时触发
弊端:添加节点时,旋转次数多,消耗资源大,旋转消耗性能很大
左旋
确定支点:从添加的节点开始,不断的往父节点找到第一个不平衡的节点
第一种情况
将支点作为右子节点的左子节点,右子节点与支点的父节点相连
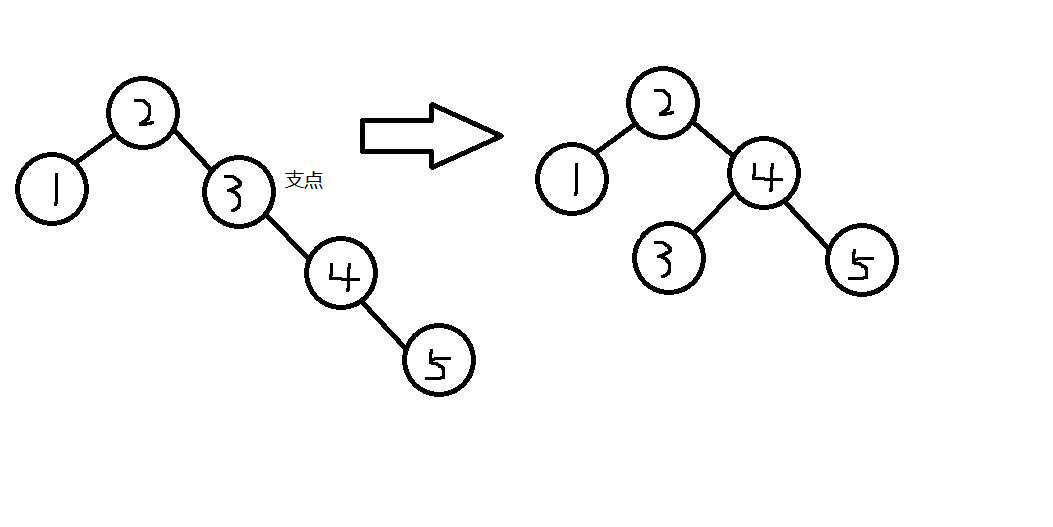
第二种情况
当支点是根节点时,将根节点的右子节点当作新的根节点,支点为新的根节点的左子节点,将原右子节点的左子树作为支点的右子树
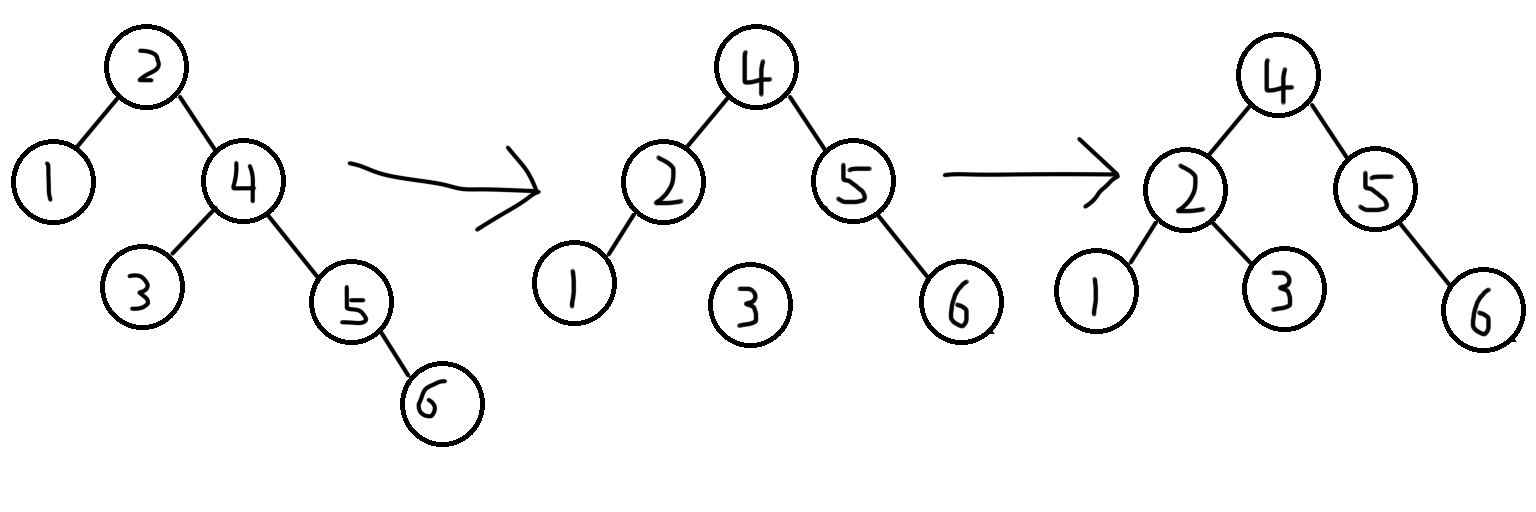
右旋
与左旋类似
旋转情况
哪边高,向另一边旋转
左左
当支点的左子树的左子树有节点插入,导致不平衡,支点左边更高
使用一次右旋
左右
当支点的左子树的右子树有节点插入,导致不平衡,支点左边更高
先局部左旋(支点的左子节点),使其变为左左的情况,再右旋
参考右左型
右左
当支点的右子树的左子树有节点插入,导致不平衡,支点右边更高
先局部右旋(支点的右子节点),使其变为右右的情况,再左旋
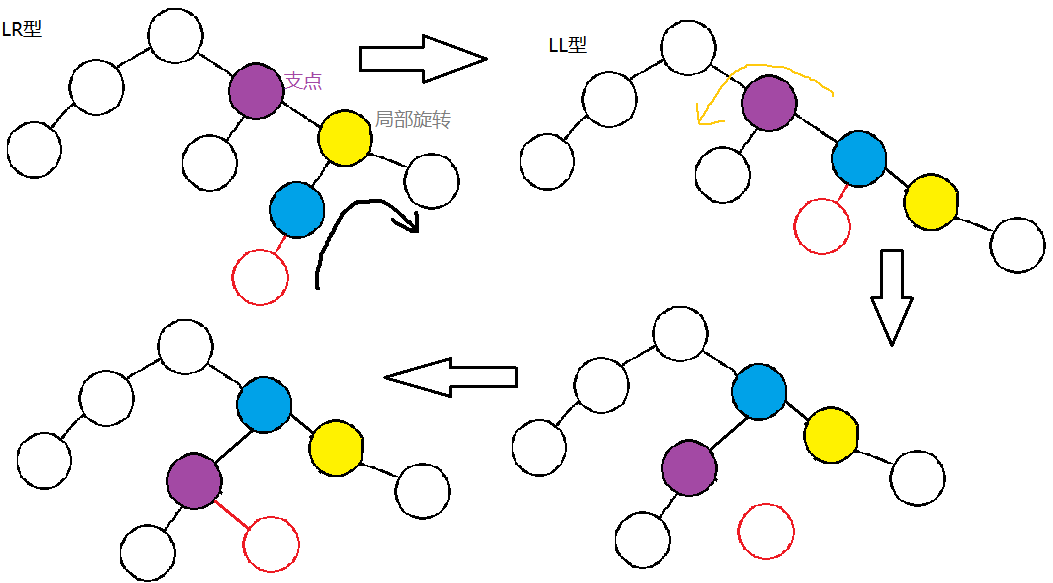
右右
当支点的右子树的右子树有节点插入,导致不平衡,支点右边更高
使用一次右旋
红黑树
是一种自平衡二叉查找树
1972年出现,被称为平衡二叉B树,1978年修改为红黑树
红黑树的每一个节点上都有存储表示节点的颜色
每一个节点可以是红或黑,红黑树不是高度平衡的,它通过“红黑规则”进行实现的
内部结构:包括树的内部结构,以及颜色属性
增删改查性能较好
红黑规则
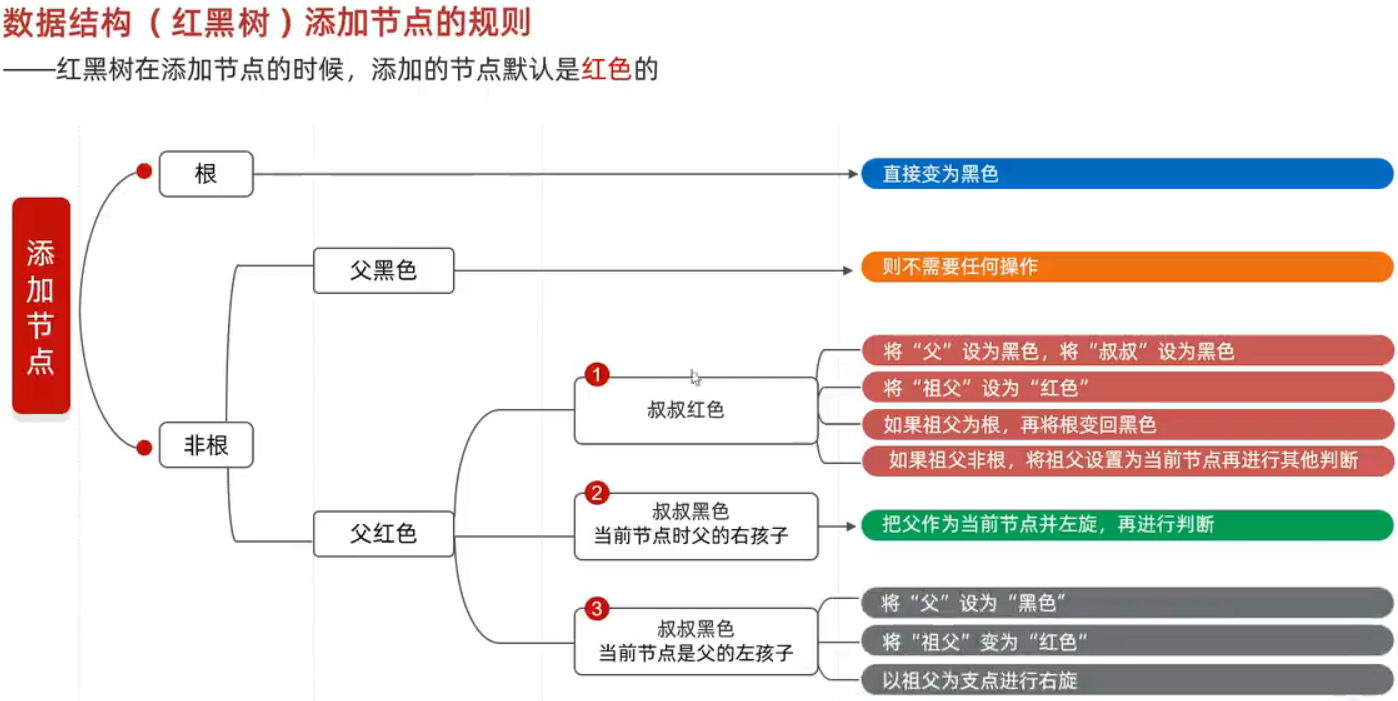
1)每一个节点必须是红色或黑色的
2)根节点必须是黑色
3)如果一个节点没有子节点或父节点,该节点对应的指针属性为Nill,Nill视为叶节点,必须为黑色
4)如果某一个节点是红色,那它的子节点必须为黑色,不能出现两个红色节点相连
5)每一个节点,从该节点到其所有的后代叶节点的简单路径上,均包含相同数目的黑色节点
叶节点中没有数据,仅用于判断是否满足要求的
简单路径:只可前进,不可后退
添加节点的规则
默认颜色:红色(效率高,调整次数少)
哈希表
JDK8以前的组成:数组 + 链表
JDK8的组成:数组 + 链表 + 红黑树
哈希表底层数组的索引公式:
int index = (数组长度 - 1) & 哈希值;
哈希值
哈希表的灵魂
是对象的整数表现形式
根据hashCode方法计算出,定义在Object中,默认使用地址值计算,但意义不大
所以在一般情况下,会重写hashCode方法,利用对象内部的属性计算
若没有重写,不同的对象计算出的哈希值不同
重写后属性相同的哈希值相同
哈希碰撞:不同属性值或不同地址值计算出的哈希值也有可能相同
sout("abc".hashCode());
sout("acD".hashCode());
泛型
JDK5中引入的特性,可以在编译阶段约束操作的数据类型
// 格式 <数据类型>
泛型只支持引用数据类型,原因:基本数据类型不能转Object
如果没有指定类型,默认所有数据类型均为Object,导致无法使用元素的特有属性
好处:统一数据类型,避免了强转时可能出现的异常
Java中的泛型是伪泛型,只在编译期间有效,实际上存的元素在底层仍为Object,但在取出时,底层会按泛型强转
在class字节码文件是没有泛型的
编译过程中泛型消失的过程称为泛型的擦除
// java文件中
ArrayList<String> list = new ArrayList<>();
// 字节码文件中
ArrayList list = new ArrayList();
泛型类
当一个类中某个变量的数据类型不确定时,就可以定义带泛型的类
// 格式
// 修饰符 class 类名<类型>{
//
// }
public class ArrayList<E>{
}
// 或多泛型
public class ArrayList<E,N>{
}
E可以理解为变量,记录数据的类型,可以写成T,E,K,V等,方便理解
泛型方法
若只有个别方法形参类型不确定的话,可以使用泛型方法
将泛型定义在方法上,只能在本方法上使用
// 格式
// 修饰符 <类型> 返回值类型 方法名(类型 变量名){
//
// }
public static <E> void show(E e){
}
public static <T extends Student
& Comparable<Student> & KeyListener> test(ArrayList<T> list){
// 要求:传入的对象类型,需要继承Student(或Student本身
// 并实现Comparable<Student>与KeyListener>接口
// 注意:可以写多个接口,但只能写一个类(可以不写)
}
使用可变参数,可以实现一次性获得多个数据
// 格式
// 修饰符 返回值类型 方法名(类型...变量名){
//
// }
public void addAll(ArrayList<String>,String...s){
// s为数组,长度为用户给的实参(不包括数组的实参)
}
泛型接口
// 格式
// 修饰符 interface 接口名<类型>{
//
// }
public interface List<E> {
}
实现泛型接口,要么指明数据类型,要么延续泛型
public class MyArrayList1 implements List<String>{
}
或
public class MyArrayList2 implements List<E>{
}
泛型的继承与通配符
泛型的继承
泛型不具备继承性,但数据具备继承性
即泛型写的是什么类型,就只能传递什么类型,即父类泛型的形参不能传子类泛型
public static void method(ArrayList<Fu> list){
}
ArrayList<Fu> list1 = new ArrayList<>();
ArrayList<Zi> list2 = new ArrayList<>();
method(list1);// 不报错
method(list2);// 报错,不能泛型不具备继承性,是并列关系
// 但可以将子类的对象传给父类的集合
list1.add(new Zi());
但数据具备继承性
public static void method(Fu f){
}
method(new Fu());// 不报错
method(new Zi());// 不报错
通配符
用以限定传入的数据类型范围
应用场景:只能传递某个继承体系中的对象
// ? extends E: 可以传入E,或E所有的子类
public void method(ArrayList<? extends Ye> list){
}
// ? super E: 可以传入E,或E所有的父类
public void method(ArrayList<? super Zi> list){
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号