
只有 1% 的标记异常,⼤多数半监督⽅法可以胜过最好的⽆监督⽅法,证明了监督的重要性; (iii) 在受 控环境中,我们观察到针对特定异常类型的最佳⽆监督⽅法甚⾄优于半监督和完全监督⽅法,揭⽰了理解数据特征 的必要性; (iv) 半监督⽅法显⽰出在噪声和损坏数据中实现鲁棒性的潜⼒,这可能是由于它们在使⽤标签和特征选 择⽅⾯的效率。
没有⼀种⽆监督⽅法在统计上优于其 他⽅法。我们还注意到⼀些基于 DL 的⽆监督⽅法,如 DeepSVDD 和 DAGMM,⽐浅层⽅法差得惊⼈。如果没有标签信息 的指导,基于 DL 的⽆监督算法更难训练(由于超参数更多),也更难调整超参数,导致性能不尽如⼈意。
当可⽤的标签信息有限时,半监督⽅法优于监督⽅法。对于γl ≤ 5%,即在训练期间只有不到5%的标记异常可⽤,半监督 ⽅法的检测性能(中值 AUCROC= 75.56% for γl = 1%和 AUCROC= 80.95% for γl = 5%)通常优于全监督算法(对 于γl = 1%, AUCROC= 60.84% ,对于γl = 5% ,AUCROC= 72.69% )。对于⼤多数半监督⽅法,仅1%的标记异常就⾜ 以超越最好的⽆监督⽅法(如图 4b 中的虚线所⽰),⽽⼤多数监督⽅法需要10%的标记异常才能实现。我们还展⽰了 关于增加γl的算法性能的改进,并注意到在有⼤量标记异常的情况下,半监督和监督⽅法具有可⽐的性能。将这些放在⼀ 起,我们验证了半监督⽅法在更有效地利⽤有限标签信息⽅⾯的假设优势。
最新的⽹络架构,如 Transformer 和新兴的集成⽅法,在 AD 中产⽣了有竞争⼒的性能。图 4b 显⽰ FTTransformer 和 XGB(oost)和 CatB(oost) 等集成⽅法在所有标签通知算法中提供了令⼈满意的检测性能,即使这些⽅法不是专⻔为 异常检测任务提出的。对于γl = 1%, FTTransformer 的 AUCROC 和集成⽅法的中值 AUCROC 分别为74.68%和 76.47%,优于所有标签通知⽅法的中值 AUCROC 72.91%。
基于树的集成(在表格 AD 中)的出⾊性能与⽂献[20、58、170 ] 中的发现⼀致,这可能归功于它们通过聚合处理不平衡 AD 数据集的能⼒。
运⾏时分析发现 HBOS、COPOD、ECOD 和 NB 是 最快的,因为它们独⽴处理每个特征。相⽐之下,XGBOD、ResNet 和FTTansformer 等更复杂的表⽰学习⽅法的计算量 很⼤。在选择算法时应考虑这⼀点。

Semi- (left of each subfigure) and supervised (right) algorithms’ performance on different types of anomalies with varying levels of labeled anomalies. Surprisingly, these label-informed algorithms are inferior to the best unsupervised method except for the clustered anomalies.

⽆监督算法的性能在很⼤程度上取决于其假设与潜在异常类型的⼀致性。正如预期的那样,对于局部异常,局部异常因 ⼦ (LOF) 在统计上优于其他⽆监督⽅法(图 5a),⽽使⽤第 k 个(全局)最近邻距离作为异常分数的KNN是统计上最 好的检测器全球异常(图5b)。同样,没有⼀种算法对所有类型的异常都表现良好; LOF在局部异常上取得了最好的 AUCROC(图 5a),在依赖性异常上取得了第⼆好的 AUCROC 排名(图 5c),但在集群异常上表现不佳(图 5d)。 从业者应根据底层任务的特点选择算法,并考虑可能涵盖更多⾼兴趣异常类型的算法。
对于局部、全局和依赖异常,⼤多数标签通知⽅法⽐每种类型(对应于 LOF、KNN 和 KNN)的最佳⽆监督⽅法表现更差。 例如,当γl ≤ 50% 时, XGBOD 对局部异常的检测性能不如最好的⽆监督⽅法 LOF ,⽽其他⽅法在所有情况下的性能 都⽐ LOF 差(⻅图 6a)。为什么标签通知算法不能在这种情况下击败⽆监督⽅法?我们认为,部分标记的异常⽆法很好地捕获特定 类型异常的所有特征,并且学习此类决策边界具有挑战性。例如,不同的局部异常通常表现出不同的⾏为,如 图 3a 所⽰,这可能更容易通过⾮监督⽅法中“局部性”的通⽤定义⽽不是特定标签来识别。因此,不完整的 标签信息可能会使学习过程产⽣偏差这些标签通知⽅法,这解释了与最好的⽆监督⽅法相⽐,它们的性能相 对较差。这⼀结论通过聚类异常的结果进⼀步验证(⻅图 6d),其中标签通知(尤其是半监督)⽅法优于 最好的⽆监督⽅法 OCSVM,因为很少有标记的异常已经可以表⽰集群异常中的相似⾏为。

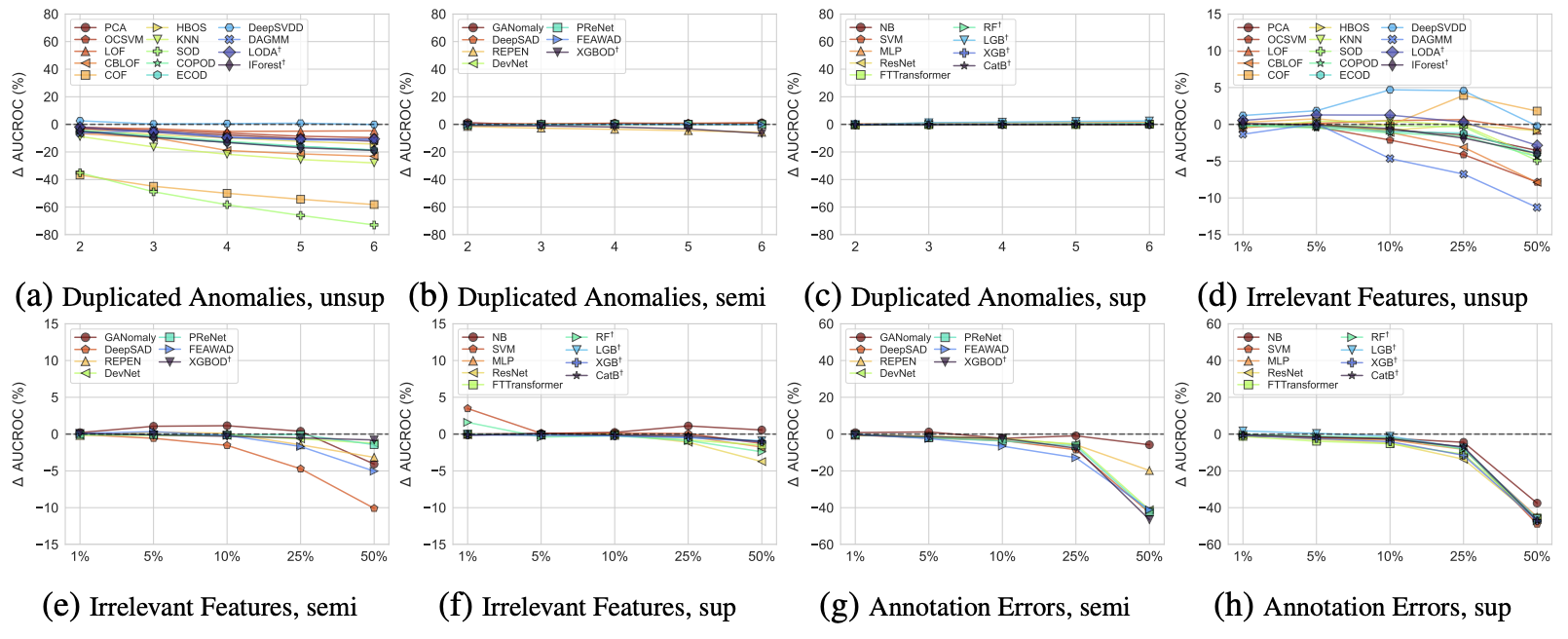
⽆监督⽅法更容易出现重复异常。如图 7a 所⽰,⼏乎所有⽆监督⽅法都受到重复异常的严重影响。他们的 AUCROC 随着 重复的增加成⽐例地恶化。当异常重复6次时,⽆监督⽅法的中值ΔAUCROC为-16.43%,⽽半监督⽅法为-0.05% (图 7b) 和监督⽅法为0.13% (图 7c)。⼀种解释是,⽆监督⽅法通常假设基础数据是不平衡的,只有较⼩⽐例的异常它们依赖 于这种假设来检测异常。随着更多的重复异常,基础数据变得更加平衡,并且违反了异常的少数假设,导致⽆监督⽅法的退 化。不同的是,在标签的帮助下,更平衡的数据集不会显着影响半监督和全监督⽅法的性能。
由于特征选择,不相关的特征对监督⽅法的影响很⼩。与⽆监督和⼤多数半监督⽅法相⽐,监督⽅法的训练过程完 全由数据标签(y) 指导,因此由于直接(或间接)特征选择过程。例如,像 XGBoost 这样的集成树可以过滤不相关 的特征。如图 7f 所⽰,当 50% 的输⼊特征被均匀噪声破坏时,即使是此设置中性能最差的监督算法(例如 ResNet)也会产⽣≤ 5%的退化,⽽⾮监督和半监督⽅法可能⾯临⾼达10% 的降解。此外,监督⽅法(以及 DevNet 等⼀些半监督⽅法)的稳健性能表明标签信息可能有助于特征选择。此外,图 7f 显⽰次要的不相关特征(例如 1%) 有助于作为正则化的监督⽅法更好地泛化。
半监督和全监督⽅法都显⽰出对微⼩注释错误的强⼤恢复能⼒。 尽管当注释错误严重时这些⽅法的检测性能会显着降低(如图 7g 和 7h 所⽰),但它们在较⼩注释错误⽅⾯的 性能下降是可以接受的。 5%注释错误的半监督和完全监督⽅法的中值ΔAUCROC分别为−1.52%和−1.91% 。 话虽如此,标签通知⽅法在实践中仍然是可以接受的,因为注释错误应该相对较

 浙公网安备 33010602011771号
浙公网安备 33010602011771号