【综述】AI智能体时代下的记忆
https://arxiv.org/pdf/2512.13564
摘要
记忆已经出现,并将继续作为基于基础模型的智能体(agent)的一项核心能力。它支撑着长时程推理、持续适应,以及与复杂环境的有效交互。随着关于智能体记忆的研究迅速扩展并获得前所未有的关注,该领域也变得日益碎片化:纳入“智能体记忆”范畴的既有工作,往往在研究动机、实现方式、关键假设与评测协议上存在显著差异;同时,各类定义松散的“记忆”术语不断涌现,进一步遮蔽了概念清晰度。传统的分类方式(如长/短期记忆)已不足以刻画当代智能体记忆系统的多样性与动态性。
本综述旨在提供对当前智能体记忆研究的最新且全面的图景。我们首先清晰界定智能体记忆的范围,并将其与相关概念(如 LLM 记忆、检索增强生成(RAG)与上下文工程)区分开来。随后,我们以“形式(forms)—功能(functions)—动态(dynamics)”的统一视角来审视智能体记忆:在形式层面,我们识别出三种主流实现——词元级(token-level)记忆、参数记忆(parametric memory)与潜在记忆(latent memory);在功能层面,我们超越粗粒度的时间划分,提出更细致的分类,将其区分为事实记忆(factual memory)、经验记忆(experiential memory)与工作记忆(working memory);在动态层面,我们分析智能体在与环境交互过程中,记忆如何随时间形成、演化并被检索。
为支持实证研究与工程开发,我们整理并总结了代表性基准测试与开源记忆框架。除梳理现状之外,我们还提出面向未来的研究展望,涵盖若干新兴前沿方向:面向自动化的记忆设计、强化学习与记忆系统的深度融合、多模态记忆、多智能体系统的共享记忆,以及可信性相关问题。我们希望本综述不仅能作为现有工作的参考,也能为将“记忆”重新视为未来智能体智能设计中的一等原语提供概念基础。
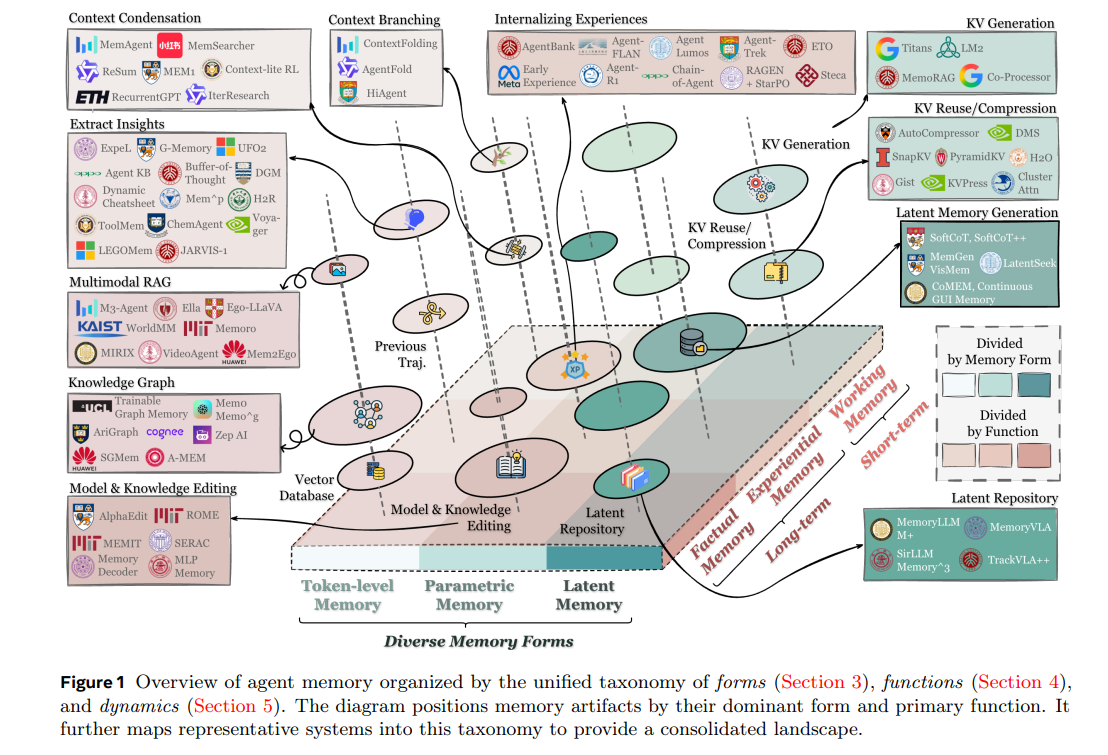
引言
过去两年见证了越来越强大的大型语言模型(LLMs)向强大的人工智能智能体的迅猛发展。这些基于基础模型的人工智能智能体在诸如深度研究、软件工程和科学发现等多个领域展示了显著的进步,不断推动着通往人工通用智能(AGI)的进程。尽管早期对“智能体”的概念非常多样化,但社区内逐渐形成了共识:除了纯粹的LLM骨干之外,一个智能体通常还具备推理、规划、感知、记忆和工具使用等能力。其中一些能力,如推理和工具使用,已经通过强化学习在模型参数中得到了很大程度上的内化,而另一些仍然严重依赖于外部智能体框架。这些组件共同作用,将LLMs从静态条件生成器转变为可学习的策略,能够与多样化的外部环境互动,并随着时间自适应地进化。
在这些智能体功能中,记忆作为基石尤为突出,它明确地使那些参数无法快速更新的静态LLMs转变为能够通过环境互动持续适应的自适应智能体。从应用角度来看,许多领域要求智能体具有主动的记忆管理能力,而不是短暂且易忘的行为:个性化聊天机器人、推荐系统、社会模拟以及金融调查都依赖于智能体处理、存储和管理历史信息的能力。从发展的角度看,AGI研究的一个定义性目标是赋予智能体通过环境互动实现持续进化的潜力,这一能力从根本上基于智能体的记忆。
智能体记忆需要新的分类
鉴于智能体记忆系统日益重要的地位和社区的关注,提供一个关于当代智能体记忆研究的最新视角变得既及时又必要。提出新分类法和综述的动机有两点:
- 现有分类法的局限性:虽然最近的一些综述提供了有价值的全面概述,但它们的分类法是在许多方法论快速进步之前开发的,因此不能完全反映当前研究领域的广度和复杂性。例如,2025年出现的新方向,如从过去经验中提炼可重用工具的记忆框架,或增强测试时扩展方法的记忆增强方法,在早期的分类方案中仍然代表性不足。
- 概念碎片化:随着与记忆相关的研究的爆炸性增长,这一概念本身变得越来越广泛和碎片化。研究人员经常发现,声称研究“智能体记忆”的论文在实现、目标和基本假设方面存在巨大差异。多样化术语(声明性、情节性、语义性、参数性记忆等)的激增进一步模糊了概念清晰度,突显了迫切需要一个能够统一这些新兴概念的一致分类法。
因此,本文旨在建立一个系统框架,以调和现有定义,弥合新兴趋势,并阐明智能体系统中记忆的基本原理。具体来说,本综述旨在解决以下关键问题:
关键问题
- ① 如何定义智能体记忆,以及它与相关概念(如大语言模型记忆、检索增强生成(RAG)和上下文工程)之间的关系是什么?
- ② 形式: 智能体记忆可以采用哪些架构或表示形式?
- ③ 功能: 为什么需要智能体记忆,它服务于哪些角色或目的?
- ④ 动态性: 智能体记忆如何随时间运作、适应和演变?
- ⑤ 前沿: 推进智能体记忆研究的有前景的前沿领域有哪些?
为了解决问题 ① ,我们首先在 第2节 中为基于LLM的智能体和智能体记忆系统提供正式定义,并详细比较智能体记忆与相关概念,如LLM记忆、RAG和上下文工程。按照“形式-功能-动态”三角形,我们对智能体记忆进行结构化概述。问题 ② 涉及记忆的架构形式,我们在 第3节 中讨论了这一点,强调了三种主流实现:令牌级、参数化和潜在记忆。问题 ③ 关注记忆的功能角色,我们在 第四节 中解决了这个问题,区分了记录来自智能体与用户和环境互动的知识的事实记忆;通过任务执行逐步增强智能体解决问题能力的经验记忆;以及在单个任务实例期间管理工作空间信息的工作记忆。问题 ④ 专注于智能体记忆的生命周期和操作动态,我们按顺序介绍了记忆形成、检索和演变的过程。
在通过“形式-功能-动态”视角审视现有研究后,我们进一步提供了关于智能体记忆研究的观点和见解。为了促进知识共享和未来发展,我们首先在第6节中总结了关键基准和框架资源。在此基础上,我们接着探讨了第7节中几个新兴但尚未充分发展的研究前沿,包括面向自动化的记忆设计、强化学习(RL)的集成、多模态记忆、多智能体系统的共享记忆以及可信问题。
贡献
本综述的贡献可以总结如下:
(1) 我们从“形式-功能-动态”的角度提出了一个最新的多维度智能体记忆分类法,提供了一个结构化的视角来理解该领域的当前发展。
(2) 我们深入讨论了不同记忆形式和功能目的的适用性和相互作用,提供了关于如何将各种记忆类型有效对齐于不同的智能体目标的见解。
(3) 我们研究了智能体记忆中出现的有前景的研究方向,从而概述了未来的机会并指出了前进的道路。
(4) 我们汇编了一系列全面的资源,包括基准测试和开源框架,以支持研究人员和实践者进一步探索智能体记忆系统。
前提:智能体和记忆定义
基于LLM的智能体越来越多地作为交互系统的决策核心,这些系统在一段时间内运行,操纵外部工具,并与人类或其他智能体协调。为了在这种环境中研究记忆,我们首先以一种涵盖单智能体和多智能体配置的方式形式化基于LLM的智能体系统。然后,我们通过读/写交互将记忆系统与智能体的决策过程相结合,从而能够统一处理任务内部(试验内/短期记忆)和跨任务(试验间/长期记忆)出现的记忆现象。
基于LLM的智能体系统
智能体与环境
令 \(\mathcal{I} = \{1,\dots,N\}\) 表示智能体的索引集,其中 \(N=1\) 对应单智能体情况(例如,ReAct),而 \(N>1\) 代表多智能体设置,如辩论或规划者-执行者架构。
环境由状态空间 \(\mathcal{S}\) 描述。在每个时间步 \(t\),环境根据受控随机转换模型进行演化
其中 \(a_t\) 表示在时间 \(t\) 执行的动作。在多智能体系统中,这种抽象允许顺序决策(每次只有一个智能体采取行动)或通过环境中介效应进行隐式协调。每个智能体 \(i \in \mathcal{I}\) 接收到观察
其中 \(h_t^i\) 表示智能体 \(i\) 可见的交互历史部分。该历史可能包括先前的消息、中间工具输出、部分推理轨迹、共享工作区状态或其他智能体的贡献,具体取决于系统设计。
\(\mathcal{Q}\) 表示任务规范,如用户指令、目标描述或外部约束,在任务内被视为固定,除非另有说明。
动作空间
基于大型语言模型(LLM)的智能体的一个显著特点是其动作空间的异质性。与其将动作限制为纯文本生成,智能体可以在多模态和语义结构化的动作空间中操作,包括:
- 自然语言生成,例如产生中间推理、解释、响应或指令。
- 工具调用动作,调用外部API、搜索引擎、计算器、数据库、模拟器或代码执行环境。
- 规划动作,明确输出任务分解、执行计划或子目标规范以指导后续行为。
- 环境控制动作,智能体直接操纵外部环境(例如,在实体环境中导航、编辑软件仓库或修改共享记忆缓冲区)。
- 通信动作,通过结构化消息与其他智能体进行协作或谈判。
尽管这些动作在语义上各不相同,但它们都是通过一个基于上下文输入条件的自回归LLM主干产生的。形式上,每个智能体 \(i\) 遵循一个策略
其中 \(m_t^i\) 是在2中定义的记忆衍生信号。
该策略可能在发出可执行动作之前内部生成多步骤推理链、潜在审议或草稿计算;此类内部过程被抽象化且未被显式建模。
交互过程与轨迹
系统的一次完整执行会产生一条轨迹
其中 \(T\) 由任务终止条件或系统特定的停止标准决定。在每一步中,轨迹反映了(i)环境观察、(ii)可选的记忆检索、(iii)基于大语言模型的计算和(iv)驱动下一步状态转换的动作执行之间的交织。
这种表述涵盖了从单个智能体通过工具增强解决推理任务到角色专业化的智能体团队协作开发软件或进行科学研究等一系列广泛的自主系统。接下来我们将形式化集成到这个智能体循环中的记忆系统。
智能体记忆系统
当基于大语言模型的智能体与环境交互时,其瞬时观察 \(o_t^i\) 往往不足以进行有效的决策。因此,智能体依赖于从先前交互中获得的额外信息,这些信息既包括当前任务中的交互,也包括之前完成的任务中的交互。我们通过一个统一的智能体记忆系统来形式化这种能力,该系统表示为一个不断演变的记忆状态
其中 \(\mathbb{M}\) 表示允许的记忆配置空间。对 \(\mathcal{M}_t\) 没有特定的内部结构要求;它可以是文本缓冲区、键值存储、向量数据库、图结构或任何混合表示。
在任务开始时,\(\mathcal{M}_t\) 可能已经包含了从先前轨迹中提取的信息(跨试验记忆)。在任务执行过程中,新的信息积累并作为短期、特定任务的记忆发挥作用。这两种角色都在单一的记忆容器中得到支持,时间上的区别来自于使用模式而不是架构上的分离。
记忆生命周期:形成、演化和检索
记忆系统的动态特征由三个概念性操作符表征。
记忆形成
在时间步 \(t\),智能体产生信息产物 \(\phi_t\),这些产物可能包括工具输出、推理轨迹、部分计划、自我评估或环境反馈。一个形成操作符
选择性地将这些产物转化为记忆候选者,提取具有潜在未来用途的信息,而不是逐字存储整个交互历史。
记忆演化
通过演化操作符
将形成的记忆候选者整合到现有的记忆库中,该操作符可能会合并冗余条目、解决冲突、丢弃低效用信息或重组记忆以提高检索效率。结果的记忆状态在随后的决策步骤和任务中持续存在。
记忆检索
在选择动作时,智能体 \(i\) 检索一个依赖于上下文的记忆信号
其中 \(R\) 表示一个检索操作符,它构建一个任务感知查询并返回相关记忆内容。检索到的信号 \(m_t^i\) 被格式化为可以直接被LLM策略使用的格式,例如一系列文本片段或结构化摘要。
智能体循环中的时间角色
尽管记忆被表示为统一状态 $ \mathcal{M}_t $,但三个生命周期操作符(形成 \(F\)、演化 \(E\) 和检索 \(R\))不必在每个时间步骤中都被调用。相反,不同的记忆效应源自不同的时间调用模式。
例如,某些系统仅在任务初始化时执行一次检索,
其中 \(\bot\) 表示空检索策略。其他系统则可能根据上下文触发器间歇性或连续性地检索记忆。
同样,记忆形成可能从原始观察的最小累积开始,
到复杂可复用模式或抽象的提取和精炼。因此,在一个任务内部,短期记忆效应可能来自轻量级日志记录,或者来自更复杂的迭代精炼;在跨任务时,长期记忆可能在任务边界处周期性更新或在整个操作过程中持续更新。因此,短期和长期记忆现象不是从离散的架构模块中产生的,而是从形成、演化和检索的时间模式中产生的。
记忆-智能体耦合
记忆与智能体决策过程之间的交互同样灵活。通常,智能体策略可以表示为
其中检索到的记忆信号 \(m_t^i\) 可能存在或不存在,这取决于检索计划。当在某个步骤禁用检索时,\(m_t^i\) 可以被视为一个特殊的空输入。
因此,整个智能体循环包括观察环境、可选地检索记忆、计算动作、接收反馈以及可选地通过形成和演变更新记忆。不同的智能体实现会在不同的时间频率下实例化这些操作的不同子集,从而产生从被动缓冲区到主动演化的知识库的各种记忆系统。
比较智能体记忆与其他关键概念
尽管人们对具有记忆功能的智能体系统兴趣日益增长,但社区对什么是智能体记忆的理解仍然存在分歧。在实践中,研究人员和从业者常常将智能体记忆与相关概念如大语言模型记忆、检索增强生成(RAG)和上下文工程混淆。虽然这些概念在信息如何在大语言模型驱动系统中管理和利用方面本质上是相互关联的,但它们在范围、时间特性和功能角色上有所不同。
这些重叠但又不同的概念导致了文献和实践中的模糊性。为了澄清这些区别,并将智能体记忆置于更广泛的背景中,我们在接下来的小节中探讨智能体记忆如何与大语言模型记忆、RAG 和上下文工程相关联并区别开来。
图 2 通过维恩图直观地展示了这些领域之间的共同点和区别。
图2:智能体记忆与大语言模型记忆、RAG和上下文工程的概念比较。该图展示了共享的技术实现(例如,KV重用、图检索),同时突出了根本区别:与大语言模型记忆的架构优化、RAG的静态知识访问或上下文工程的瞬时资源管理不同,智能体记忆的独特特征在于其专注于维护一个持久且自我进化的认知状态,该状态整合了事实知识和经验。列出的类别和示例是说明性的而非严格并行的,作为代表性参考点来阐明概念关系,而非定义一个严格的分类法。
智能体记忆与大语言模型记忆
从高层次来看,智能体记忆几乎完全涵盖了传统上所称的大语言模型(LLM)记忆。自2023年以来,许多自称为“LLM记忆机制”的研究,在当代术语下更适合作为早期的智能体记忆实例来理解。这种重新解释源于“LLM智能体”这一概念的历史模糊性。在2023年至2024年间,社区内对于这一概念没有一个稳定或一致的定义:在某些情况下,仅通过提示LLM调用计算器就足以将其视为一个智能体;而在其他情况下,则需要具备更为丰富的功能,例如明确规划、工具使用、记忆以及反思推理等。直到最近,一个更加统一和结构化的定义才开始出现(例如,基于LLM的智能体 = LLM + 推理 + 规划 + 记忆 + 工具使用 + 自我改进 + 多轮交互 + 感知),尽管即使是这个定义也并非普遍适用。
在这种历史背景下,早期系统如MemoryBank和MemGPT将它们的工作描述为提供LLM记忆。然而,它们实际上解决的是经典的智能体挑战,例如使基于LLM的对话智能体能够跟踪用户偏好、维护对话状态信息,并在多轮交互中积累经验。根据现代对智能体性的更成熟理解,这些系统自然被归类为智能体记忆的实例。
话虽如此,这种包含关系并不是绝对的。有一条独立的研究路线确实关注于LLM内部的记忆:管理大模型的键-值(KV)缓存、设计长上下文处理机制,或修改模型架构(例如RWKV、Mamba、基于扩散的语言模型)以更好地随着序列长度的增长保留信息。这些工作侧重于内在模型动态,通常处理不需要智能体行为的任务,因此应被视为超出智能体记忆范围之外。
重叠
在我们的分类体系中,历史上被称为“LLM记忆”的大部分内容对应于智能体记忆的形式。诸如少量样本提示等技术可以被视为一种长期记忆形式,在这种形式中,过去的示例或提炼的任务摘要作为可重复使用的知识通过检索或上下文注入而被纳入。自我反思和迭代改进方法自然与短期、试验内记忆相一致,因为智能体会在同一任务中反复利用中间推理痕迹或先前尝试的结果。即使是在单个任务过程中用来保存显著信息的KV压缩和上下文窗口管理,也作为智能体意义上的短期记忆机制发挥作用。这些技术都支持智能体在整个任务执行过程中积累、转换和重用信息的能力。
区别
相比之下,直接干预模型内部状态的记忆机制——例如用于延长有效上下文的架构修改、缓存重写策略、循环状态持久化、注意力稀疏机制或外部化的KV存储扩展——更适合作为LLM记忆而非智能体记忆进行分类。它们的目标是扩展或重组底层模型的表现能力,而不是为决策智能体提供一个不断演化的外部记忆库。这些机制通常不支持跨任务持久性、环境驱动的适应性或有意识的记忆操作(如形成、演变、检索),因此超出了本调查中定义的智能体记忆的操作范围。
智能体记忆与RAG
在概念层面上,智能体记忆和检索增强生成(RAG)表现出显著的重叠:这两种系统都构建、组织并利用辅助信息存储来扩展LLM/智能体超出其固有参数知识的能力。例如,结构化表示如知识图谱和索引策略在两种方法中都有出现,而最近在智能体RAG中的发展展示了自主检索机制如何以类似于智能体记忆架构的方式与动态数据库交互。实际上,许多RAG和智能体记忆系统的底层工程堆栈共享共同的构建模块,包括向量索引、语义搜索和上下文扩展模块。
尽管存在这些技术上的趋同,但这两个范式历史上是根据应用背景加以区分的。传统的RAG技术主要通过访问静态知识源来增强LLM,无论是平面文档存储、结构化知识库还是外部索引的大规模语料库,以支持按需检索。这些系统旨在将生成基于最新的事实,减少幻觉,并提高知识密集型任务的准确性,但它们通常不维护一个内部的、不断演变的过去交互的记忆。相比之下,智能体记忆系统是在智能体与其环境持续互动的过程中实例化的,不断将由智能体自身行为和环境反馈产生的新信息纳入持久记忆库中。
早期的表述中,RAG和智能体记忆之间的区别相对清晰:RAG从外部维护的知识中为单个任务调用检索,而智能体记忆则在多轮、多任务交互中演变。然而,随着检索系统本身变得越来越动态,这一界限变得越来越模糊。例如,某些检索任务在迭代查询期间持续更新相关上下文(例如,在多跳QA设置中逐步添加相关上下文)。有趣的是,像HippoRAG/HippoRAG2这样的系统被RAG和记忆社区都解读为解决LLM长期记忆挑战的方案。因此,一个更实用(虽然不是完全可分离)的区别在于任务领域。RAG主要用于通过大型外部来源的上下文来增强LLM的单个推理任务,这在经典的多跳和知识密集型基准测试中得到体现,如HotpotQA、2WikiMQA和MuSiQue。相反,智能体记忆系统通常在需要持续多轮互动、时间依赖性或环境驱动适应性的场景中进行评估。代表性基准包括长上下文对话评估如LoCoMo和LongMemEval,复杂问题解决和深度研究基准如GAIA、XBench和BrowseComp,以代码为中心的智能体任务如SWE-bench Verified,以及终身学习基准如StreamBench。我们在第6节中提供了关于记忆相关基准的全面总结。
尽管如此,即使是基于领域的区分也包含大量的灰色地带。许多自称为智能体记忆系统的论文在长文档问答任务(如 HotpotQA)下进行评估,而许多被标榜为 RAG 系统的论文实际上实现了形式上的智能体自我改进,随着时间不断提炼和精炼知识或技能。因此,标题、方法论和实证评估经常模糊了这两种范式之间的概念边界。
为了进一步澄清这些关系,以下三个段落借鉴了已建立的 RAG 分类法:模块化 RAG、图 RAG 和智能体 RAG,并考察与每种谱系相关的核心技术如何在 RAG 和智能体记忆系统中体现。
模块化RAG
模块化RAG指的是将检索流水线分解为明确指定的组件(如索引、候选检索、重新排序、过滤和上下文组装)的架构,这些组件以相对静态且类似流水线的方式运行。这些系统将检索视为一个精心设计的、模块化的子系统,位于大型语言模型之外,主要用于在推理过程中向模型的上下文窗口注入相关知识。从智能体记忆的角度来看,相应的技术通常出现在检索阶段,其中通过向量搜索、语义相似度匹配或基于规则的过滤来实现记忆访问,这在流行的智能体记忆框架如Memary、MemOS和Mem0中可见。
图形 RAG
图形 RAG 系统将知识库结构化为图,范围从知识图谱到概念图或文档-实体关系,并利用图遍历或基于图的排序算法来检索上下文。这种表示方法能够实现多跳关系推理,这已被证明对于知识密集型任务非常有效。在智能体记忆的背景下,当智能体随着时间积累关系性见解时,如链接概念、跟踪子任务之间的依赖关系或记录通过交互推断出的因果关系时,图形结构的记忆自然产生。一些已确立的做法包括 Mem0\(^g\) 、A-MEM 、Zep 和 G-memory 。值得注意的是,基于图的智能体记忆系统可能在其操作过程中构建、扩展或重组其内部图。因此,基于图的检索构成了两种范式的结构基础,但只有智能体记忆将图视为一种生动且不断演变的经验表示。我们在 第3节 中提供了对基于图的记忆形式的进一步分析,并也建议读者参考相关综述。
智能体性RAG
智能体性RAG将检索集成到一个自主决策循环中,其中LLM智能体主动控制何时、如何以及检索什么。这些系统通常采用迭代查询、多步骤规划或自我导向的搜索程序,使智能体能够通过深思熟虑的推理来细化其信息需求,如在PlanRAG和Self-RAG中的实现所示。从智能体记忆的角度来看,智能体性RAG占据着最接近的概念空间:两种系统都涉及与外部信息存储的自主交互,两者都支持多步骤细化,并且都可以将检索到的见解纳入后续推理中。关键区别在于,经典的智能体性RAG通常操作于一个外部且通常是任务特定的数据库,而智能体记忆则维护一个内部的、持久的、自我进化的记忆库,该记忆库可以跨任务积累知识。
智能体记忆与上下文工程
智能体记忆与上下文工程之间的关系最好理解为不同操作范式的交汇,而不是一种层级上的包含关系。上下文工程是一种系统的设计方法,将上下文窗口视为受约束的计算资源。它严格优化信息负载,包括指令、知识、状态和记忆,以缓解巨大的输入容量与模型生成能力之间的不对称性。而智能体记忆则侧重于对具有演变身份的持久实体的认知建模,上下文工程则在资源管理范式下运作。从上下文工程的角度来看,智能体记忆只是上下文组装函数中的一个变量,需要高效调度以最大化推理效果。相反,从智能体的角度来看,上下文工程作为实现层,确保认知连续性保持在底层模型的物理限制内。
重叠
这两个领域在长时交互过程中工作记忆的技术实现上显著趋同,通常采用功能上相同的机制来解决有限上下文窗口带来的限制。两种范式都依赖于先进的信息压缩、组织和选择技术,以在长时间的交互序列中保持操作连续性。例如,在上下文工程框架中处于核心地位的令牌修剪和基于重要性的选择方法,在智能体记忆系统中通过过滤噪声和保留显著信息发挥着基础作用。
同样地,滚动摘要技术作为一种共享的基础原语,同时作为缓冲区管理策略和瞬时情景记忆机制发挥作用。实际上,在这些情况下,上下文设计与维护智能体短期记忆之间的界限几乎消失,因为两者都依赖于相同的底层摘要、动态信息检索和递归状态更新。
区别
当从短期文本处理转向更广泛的长期存在的智能体领域时,这种区别变得尤为明显。上下文工程主要解决大型语言模型与其操作环境之间交互界面的结构组织问题。这包括优化工具集成推理和选择流程以及标准化通信协议,例如MCP。这些方法的重点是确保指令、工具调用和中间状态正确格式化、高效调度,并在上下文窗口的限制内可执行。因此,上下文工程在资源分配和接口正确性的层面上运作,强调语法有效性和执行效率。
相比之下,智能体记忆定义了一个更为广泛的认知范围。除了瞬时上下文组装之外,它还包括事实知识的持久存储、经验痕迹的积累与演变,在某些情况下还包括将记忆内化为模型参数。不同于管理信息如何在推理时呈现给模型,智能体记忆控制着智能体所知道的内容、经历过的事件以及这些元素随时间的演变。这包括将重复互动整合成知识,从过去的成功与失败中抽象出程序性知识,以及在任务和情节间保持一致的身份。
从这个角度来看,上下文工程构建了使感知和行动在资源限制下得以实现的外部框架,而智能体记忆则构成了支持学习、适应和自主性的内部基础。前者优化了智能体与模型之间的瞬时接口,后者则维持了一个超越任何单个上下文窗口的持久认知状态。
形式:什么承载记忆?
作为组织先前工作的起点,我们首先考察构成智能体记忆的最基本表示单位。我们首先试图回答:智能体记忆可以采取哪些架构或表示形式?
在不同的智能体系统中,记忆并不是通过单一的、统一的结构实现的。相反,不同的任务设置要求不同的存储形式,每种形式都有其自身的结构特性。这些架构赋予记忆不同的能力,塑造了智能体如何在交互过程中积累信息并保持行为一致性。它们最终使记忆能够在各种任务场景中发挥其预期作用。
根据记忆所在的位置及其表示形式,我们将这些记忆分为三类:
三种主要的记忆形式
- 词元级记忆:记忆被组织为明确且离散的单元,可以单独访问、修改和重建。这些单元对外部可见,并且可以在一段时间内以结构化形式存储。
- 参数记忆:记忆存储在模型参数中,信息通过参数空间的统计模式进行编码,并在前向计算期间隐式访问。
- 潜在记忆:记忆在模型的内部隐藏状态、连续表示或演化的潜在结构中表示。它可以在推理过程中或跨交互周期中持续存在并更新,捕捉依赖于上下文的内部状态。
上述三种记忆形式建立了理解“什么承载记忆”的核心结构框架。每种形式以自己的方式组织、存储和更新信息,产生不同的表示模式和操作行为。有了这个结构分类法,我们可以更系统地研究为什么智能体需要记忆以及记忆如何在持续交互过程中演变、适应并塑造智能体行为。这一分类为后续讨论提供了概念基础。
词元级记忆
词元级记忆的定义
词元级记忆以持久、离散的单元形式存储信息,这些信息可以外部访问和检查。这里的词元是一个广泛的表示概念:除了文本词元外,还包括视觉词元、音频帧——任何可以在模型参数之外写入、检索、重组和修订的离散元素。
由于这些单元是显式的,词元级记忆通常是透明的、易于编辑且易于解释,使其成为检索、路由、冲突处理以及与参数化和潜变量记忆协调的自然层。词元级记忆也是最常见的记忆形式,并且现有工作最多。
尽管所有词元级记忆都具有作为离散单元存储的特性,但它们在这些单元如何组织方面存在显著差异。存储词元的结构组织在决定智能体如何高效地搜索、更新或推理过去信息方面起着核心作用。为了描述这些差异,我们根据单元之间的结构组织对词元级记忆进行分类,从没有明确拓扑结构到多层拓扑结构:

图3:按拓扑复杂性和维度组织的词元级记忆分类法:
(a) 平面记忆(1D)将信息存储为线性序列或独立簇,没有显式的单元间拓扑结构,常用于块集、对话日志和经验池。
(b) 平面记忆(2D)引入单层结构化布局,其中单元通过树或图结构链接以捕获关系依赖性,支持多种节点类型,如图像和聊天记录。
(c) 层次记忆(3D)采用多层形式,如金字塔或多层图,以促进不同数据粒度之间的垂直抽象和跨层推理,例如原始文档和合成的问答对。
三种主要类型的词元级记忆
- 平面记忆(一维):没有明确的单元间拓扑结构。记忆以序列或单元袋的形式累积(例如,片段、轨迹、块)。
- 平面记忆(二维):在一个平面上有结构但单层的组织:单元通过图、树、表等形式相关联,没有跨层关系。结构是明确的,但不是分层的。
- 分层记忆(三维):在多层之间有结构并有层间链接,形成体积或分层记忆。
这三种类型的词元级记忆在3中得到了清晰的说明。从没有拓扑结构的平面记忆,到具有单层结构组织的平面记忆,再到具有多层互联结构的分层记忆,这种组织谱系不仅决定了词元级记忆如何支持搜索、更新和推理,还决定了记忆本身的结构及其提供的功能。在接下来的小节中,我们将介绍每种组织形式的优点和局限性、典型用例以及代表性工作。代表性词元级记忆方法的总结和比较见表1。
值得一提的是,继ReAct提出的想法之后,一系列研究开始关注长期交互任务。其中许多任务引入了明确的记忆概念,因为记忆通常以明文形式存储,因此属于词元级记忆的范围。大多数研究强调如何压缩或折叠累积的交互痕迹,以便智能体能够在不超出上下文限制的情况下操作长序列。
Linear or independent records
| Method | Multi | Type | Memory Form | Task |
|---|---|---|---|---|
| Reflexion | ❌ | E&W | Trajectory as short-term and feedback as long-term | QA, Reasoning, Coding |
| Memento | ❌ | Exp | Trajectory case (success/failure). | Reasoning |
| JARVIS-1 | ✅ | Exp | Plan-environment pairs. | Game |
| Expel | ❌ | Exp | Insights and few-shot examples. | Reasoning |
| Buffer of Thoughts | ❌ | Exp | High-level thought-templates. | Game, Reasoning, Coding |
| SAGE | ❌ | Exp | Dual-store with forgetting mechanism. | Game, Reasoning, Coding |
| ChemAgent | ❌ | Exp | Structured sub-tasks and principles. | Chemistry |
| AgentKB | ❌ | Exp | 5-tuple experience nodes. | Coding, Reasoning |
| H²R | ❌ | Exp | Planning and Execution layers. | Game, Embodied Simulation |
| AWM | ❌ | Exp | Abstracted universal workflows. | Web |
| PRINCIPLES | ❌ | Exp | Rule templates from self-play. | Emotional Companion |
| ReasoningBank | ❌ | Exp | Transferable reasoning strategy items. | Web |
| Voyager | ✅ | Exp | Executable skill code library. | Game |
| DGM | ❌ | Exp | Recursive self-modifiable codebase. | Coding |
| Memp | ❌ | Exp | Instructions and abstract scripts. | Embodied Simulation, Travel Planning |
| UFO2 | ✅ | Exp | System docs and interaction records. | Windows OS |
| LEGOMem | ❌ | Exp | Vectorized task trajectories. | Office |
| ToolMem | ❌ | Exp | Tool capability. | Tool Calling |
| SCM | ❌ | Fact | Memory stream and vector database. | Long-context |
| MemoryBank | ❌ | Fact | History and user profile. | Emotional Companion |
| MPC | ❌ | Fact | Persona and summary vector pool. | QA |
| RecMind | ❌ | Fact | User metadata and external knowledge. | Recommendation |
| InteRecAgent | ❌ | Fact | User profiles and candidate item. | Recommendation |
| Ego-LLaVA | ✅ | Fact | Language-encoded chunk embeddings. | Multimodal QA |
| ChatHaruhi | ❌ | Fact | Dialogue database from media. | Role-Playing |
| Memochat | ❌ | Fact | Memos and categorized dialogue history. | Long-conv QA |
| RecursiveSum | ❌ | Fact | Recursive summaries of short dialogues. | Long-conv QA |
| MemGPT | ❌ | Fact | Virtual memory (Main/External contexts). | Long-conv QA, Doc QA |
| RoleLLM | ❌ | Fact | Role-specific QA pairs. | Role-Playing |
| Think-in-memory | ❌ | Fact | Hash table of inductive thoughts. | Long-conv QA |
| PLA | ❌ | Fact | Evolving records of history and summaries. | QA, Human Feedback |
| COMEDY | ❌ | Fact | Single-model compressed memory format. | Summary, Compression, QA |
| Memoro | ✅ | Fact | Speech-to-text vector embeddings. | User Study |
| Memory Sharing | ❌ | Fact | Query-Response pair retrieval. | Literary Creation, Logic, Plan Generation |
| Conv Agent | ❌ | Fact | Chain-of-tables and vector entries. | QA |
| EM-LLM | ❌ | Fact | Episodic events with Bayesian boundaries. | Long-context |
| Memocrs | ❌ | Fact | User metadata and knowledge. | Recommendation |
| SECOM | ❌ | Fact | Paragraph-level segmented blocks. | Long-conv QA |
| Mem0 | ❌ | Fact | Summary and original dialogue. | Long-conv QA |
| RMM | ❌ | Fact | Reflection-organized flat entries. | Personalization |
| MEMENTO | ✅ | Fact | Interaction history entries. | Personalization |
| MemGuide | ❌ | Fact | Dialogue-derived QA pairs. | Long-conv QA |
| MIRIX | ✅ | Fact | Six optimized flat memory types. | Long-conv QA |
| SemanticAnchor | ❌ | Fact | Syntactic 5-tuple structure. | Long-conv QA |
| MMS | ❌ | Fact | Dual Retrieval and Context units. | Long-conv QA |
| Memory-R1 | ❌ | Fact | RL-managed mem0 architecture. | Long-conv QA |
| ComoRAG | ❌ | Fact | Fact/Semantic/Plot units with probes. | Narrative QA |
| Nemori | ❌ | Fact | Predictive calibration store. | Long-conv QA |
| Livia | ✅ | Fact | Pruned interaction history. | Emotional Companion |
| MOOM | ❌ | Fact | Decoupled plot and character stores. | Role-Playing |
| Mem-α | ❌ | Fact | Core, Semantic, and Episodic Mem. | Memory Management |
| Personalized Long term Interaction | ❌ | Fact | Hierarchical history and summaries. | Personalization |
| LightMem | ❌ | Fact | Optimized Long/Short-term store. | Long-conv QA |
| MEXTRA | ❌ | Fact | Extracted raw dialogue data. | Privacy Attack |
| MovieChat | ✅ | Fact | Short-term features and long-term persistence. | Video Understanding |
| MA-LMM | ✅ | Fact | Visual and Query memory banks. | Video Understanding |
| VideoAgent | ✅ | Fact | Temporal text descriptions and object tracking. | Video Understanding |
| KARMA | ✅ | Fact | 3D scene graph and dynamic object states. | Embodied Task |
| Embodied VideoAgent | ✅ | Fact | Persistent object and sensor store. | MultiModal |
| Mem2Ego | ✅ | Fact | Map, landmark, and visited location stores. | Embodied Navigation |
| Context-as-Memory | ✅ | Fact | Generated context frames. | Video Generation |
| RCR-Router | ❌ | Fact | Budget-aware semantic subsets. | QA |
Structured single-layer graphs/trees
| Method | Multi | Type | Memory Structure | Task |
|---|---|---|---|---|
| D-SMART | ❌ | Fact | Structured memory with reasoning trees. | Long-conv QA |
| Reflexion | ❌ | Work | Reflective text buffer from experiences. | QA, Reasoning, Coding |
| PREMem | ❌ | Fact | Dynamic cross-session linked triples. | Long-conv QA |
| Query Reconstruct | ❌ | Exp | Logic graphs built from knowledge bases. | KnowledgeGraph QA |
| KGT | ❌ | Fact | KG node from query and feedback. | QA |
| Optimus-1 | ✅ | F&E | Knowledge graph and experience pool. | Game |
| SALI | ✅ | Exp | Topological graph with spatial nodes | Navigation |
| HAT | ❌ | Fact | Hierarchical aggregate tree. | Long-conv QA |
| MemTree | ❌ | Fact | Dynamic hierarchical conversation tree. | Long-conv QA |
| TeaFarm | ❌ | Fact | Causal edges connecting memories. | Long-conv QA |
| COMET | ❌ | Fact | Context-aware memory through graph. | Long-conv QA |
| Intrinsic Memory | ❌ | Fact | Private internal and shared external mem. | Planning |
| A-MEM | ❌ | Fact | Card-based connected mem. | Long-conv QA |
| Ret-LLM | ❌ | Fact | Triplet table and LSH vectors. | QA |
| HuaTuo | ❌ | Fact | Medical Knowledge Graph. | Medical QA |
| M3-Agent | ✅ | Fact | Multimodal nodes in graph structure. | Embodied QA |
Multi-level architectures
| Method | Multi | Type | Memory Structure | Task |
|---|---|---|---|---|
| GraphRAG | ❌ | Fact | Multi-level community graph indices. | QA, Summarization |
| H-Mem | ❌ | Fact | Decoupled index layers and content layers. | Long-conv QA |
| EMG-RAG | ❌ | Fact | Three-tiered memory graph. | QA |
| G-Memory | ❌ | Exp | Query-centric three-layer graph structure. | QA, Game, Embodied Task |
| Zep | ❌ | Fact | Temporal Knowledge Graphs. | Long-conv QA |
| SGMem | ❌ | Fact | Chunk Graph and Sentence Graph. | Long-conv QA |
| HippoRAG | ❌ | Fact | Knowledge with query nodes. | QA |
| HippoRAG 2 | ❌ | Fact | KG with phrase and passage. | QA |
| AriGraph | ❌ | Fact | Semantic and Episodic memory graph. | Game |
| Lyfe Agents | ❌ | Fact | Working, Short & Long-term layers. | Social Simulation |
| CAM | ❌ | Fact | Multilayer graph with topic. | Doc QA |
| HiAgent | ❌ | E&W | Goal graphs with recursive cluster. | Agentic Tasks |
| ILM-TR | ❌ | Fact | Hierarchical Memory tree. | Long-context |
Legend:
- Multi: Multimodal capability (✅ = Support for modalities beyond text; ❌ = Text-only).
- Type: Functional category (Fact = factual memory, Exp = experiential memory, Work = working memory).
- Memory Form/Structure: Organization mechanism of stored units.
- Task: Primary application domains.
平面记忆 (1D)
为了清晰连贯地呈现,我们根据先前工作的主要设计目标和技术重点对平面记忆进行分组。这种分组具有组织作用,并不意味着由此产生的类别是严格并行或互斥的。实际上,某些方法可能适用于多个类别,而一些涉及多模态信息的方法在多模态不是其中心关注点时可能会在其他部分讨论。这样的组织方式使我们能够系统地回顾文献,同时保持解释的灵活性。
对话
一些关于扁平记忆的工作集中在对话内容的存储和管理上。早期的方法主要集中在通过存储原始对话历史或生成递归摘要来扩展上下文窗口以防止遗忘。MemGPT 引入了操作系统隐喻,采用层次化管理方式,启发了后续工作将活跃上下文与外部存储解耦,从而实现无限上下文管理。
为了提高检索精度,记忆单元的粒度和结构变得越来越多样化,并且更加符合认知规律。一些工作,如 COMEDY、Memory Sharing 和 MemGuide 将信息压缩成紧凑的语义表示或查询-响应对以方便直接查找,而其他工作,如 MIRIX 采用了从向量-表组合到多功能记忆类型的混合结构。此外,研究开始基于认知心理学定义记忆边界,通过语法元组组织信息或根据贝叶斯惊奇和段落结构分割事件,从而匹配类似人类的认知分割。
随着对话深度的增加,记忆进化为存储高级认知过程和叙事复杂性。系统不仅存储事实记录,像 Think-in-Memory 和 RMM 这样的系统还存储归纳思维和回顾反思,以指导未来的推理。在角色扮演或长篇叙事等复杂场景中,ComoRAG 和 MOOM 等方法将记忆分解为事实级、情节级和角色级组件,确保智能体在长时间互动中保持一致的人格和理解。
记忆已经从静态存储过渡到了自主和自适应优化。Mem0 建立了标准化的记忆维护操作,为智能控制奠定了基础。最近的进步引入了强化学习来优化记忆构建,而其他机制则专注于动态校准和效率,例如预测缺失信息、跨多智能体系统管理令牌预算以及减少长期存储中的冗余。
偏好
一些记忆系统专注于建模用户的不断变化的品味、兴趣和决策模式,特别是在推荐场景中,理解偏好是核心。与以对话为中心的记忆不同,后者侧重于保持对话的一致性,偏好记忆则集中于识别用户的品味和倾向。早期的努力如RecMind将用户特定信息与外部领域知识分开,同时存储事实性的用户属性和项目元数据。InteRecAgent将记忆融入推荐工作流程,但更关注当前候选集,保留用户档案和活跃项目池以支持上下文感知推荐。MR.Rec构建了一个记忆索引,归档了整个交互过程,存储了原始项目信息和每类别的偏好摘要。在对话设置中,Memocrs提出了一种更结构化的设计,包括一个跟踪实体和用户态度的用户特定记忆,以及一个聚合跨用户知识的通用记忆。
个人资料
一部分扁平记忆系统专注于存储和维护稳定的用户资料、角色属性或长期身份信息,以便智能体能够在多个回合和任务中保持一致的行为。MemoryBank 是这一方向上最早的框架之一:它按时间戳组织对话历史和事件摘要,逐步构建支持准确检索身份相关信息的用户资料。AI Persona 使记忆系统不仅处理对话上下文中呈现的信息,还从多维人机交互维度处理信息。MPC 通过在记忆池中存储实时人物信息和对话摘要扩展了这一想法,使对话行为在长时间互动中与一致的人物保持一致。提出了一种更全面的个人资料维护机制,结合长期和短期记忆以及每个回合后自动生成的摘要形成中期上下文,使用户资料能够通过互动不断演变。
在虚拟角色扮演环境中,ChatHaruhi 从小说和电视剧本中提取对话,使模型能够通过检索记忆来维持角色一致的行为。RoleLLM 采用更结构化的方法,通过构建问答对来捕捉特定于角色的知识。
经验
与静态的一般知识不同,经验记忆源于智能体在实际交互任务中的动态积累,包括特定的观察、思维链、行动轨迹和环境反馈。需要注意的是,本节仅从令牌级存储的角度简要概述了经验记忆;对该领域的更全面分析和详细讨论将在中呈现。
经验记忆最基本的形式是直接存档历史行为轨迹。这种范式使智能体能够通过检索和重用过去的事例(包括成功和失败的案例)来为当前决策提供信息。
为了解决原始轨迹有限的泛化能力问题,大量研究集中在将特定交互抽象成更高层次、更普遍的经验上。作为最早和最具影响力的方法之一,反射区分了短期记忆(即轨迹历史)和长期记忆(即自反模型产生的反馈)。某些研究将复杂的交互历史压缩成通用工作流、规则模板或高级“思维模板”,以促进跨问题的转移和重用。其他工作则强调记忆的结构组织和动态维护。这些方法通过构建特定领域的结构化知识库、采用分层计划-执行记忆架构或结合类似人类的遗忘和反思机制,确保存储的见解对新任务保持适应性,并能高效更新。
在涉及编程或特定工具使用的背景下,经验记忆演变为可执行技能。在这种范式下,智能体将探索经验整合到代码库、过程脚本或工具使用条目中。利用环境反馈,这些系统迭代地改进代码质量,甚至动态修改其底层逻辑以实现自我进化。此外,针对操作系统等复杂环境,一些研究将成功的执行记录提炼成可重用的示例或向量化表示,从而促进了从离线构建到在线分配的有效流程。
多模态
多模态记忆系统以从原始多模态数据(如图像、视频帧、音频片段和文本)中提取的离散令牌级单元形式存储信息,使智能体能够跨通道并在长时间的经验跨度内捕获、压缩和检索知识。在可穿戴和第一人称设置中,早期工作如Ego-LLaVA 捕捉第一人称视频并将其转换为轻量级语言描述。Memoro 采用类似的理念,但使用语音转文本形成基于嵌入的记忆块。在此方向上,Livia 将长期用户记忆融入具有情感意识的AR系统中,应用遗忘曲线和修剪策略。
对于视频理解,重点转向将瞬时视觉线索与持久上下文信息分开。MovieChat 采用短期/长期分割,存储最近帧特征。MA-LMM 则进一步采用了双库设计——一个存储原始视觉特征,另一个保留查询嵌入。VideoAgent 采用更语义化的方法,维护文本片段描述的时间记忆以及跟踪帧间实体的对象级记忆。在交互式视频生成中,Context-as-Memory 表明简单地将先前生成的帧作为记忆存储也可以非常有效。
在具身场景中,记忆本质上与空间结构和持续互动相关联。KARMA 引入了两级记忆系统:长期记忆在3D场景图中存储静态对象,而短期记忆则跟踪对象位置和状态变化。Embodied VideoAgent 也构建持久的对象记忆,但将其与第一人称视频和额外的具身传感器融合。Mem2Ego 将这一想法扩展到导航中,将全局地图、地标描述和访问历史分为三个不同的记忆存储。补充这些任务驱动的设计,MEMENTO 提供了一个评估框架,将多模态交互历史视为智能体的记忆,从而系统地评估具身系统如何利用累积的感知经验。
讨论
Flat Memory 的主要优势在于其简单性和可扩展性:可以以极低的成本追加或修剪记忆,而相似性搜索等检索方法允许在不需要预定义结构的情况下灵活访问。这使得它们适用于广泛的回忆、情景积累和快速变化的交互历史。然而,缺乏显式的关系组织意味着连贯性和相关性严重依赖于检索质量。随着记忆的增长,冗余和噪声可能会累积,模型可能检索到相关单元但并不理解它们之间的关系,从而限制了组合推理、长期规划和抽象形成。因此,无拓扑结构的集合在广泛覆盖和轻量级更新方面表现出色,但在需要结构化推理或稳定知识组织的任务中受到限制。
平面记忆(2D)
平面记忆引入了显式的组织拓扑结构,但仅限于单一层结构,简称为2D。该拓扑结构可以是图、树、表或隐式连接结构等,在一个平面上编码相邻关系、父子顺序或语义分组等关系,而没有层次级别或跨层引用。
平面记忆的核心在于通过建立显式的关联机制突破单一存储池,实现从单纯的“存储”到“组织”的飞跃。
树
树结构以层次方式组织信息,能够处理不同层次的抽象。HAT 通过分割长交互并逐步聚合它们来构建层次聚合树。这种多级结构支持从粗到细的检索,在长上下文问答中表现优于扁平向量索引。为了减少对话碎片化,MemTree 引入了一种动态表示方法,该方法从孤立的对话日志中推断出层次模式。它逐渐将具体事件总结为更高级别的概念,使智能体能够同时使用详细记忆和抽象知识。
图
图结构在二维记忆中占据主导地位,因为它们能够捕捉复杂的关联、因果关系和时间动态。基础工作如Ret-LLM将外部存储抽象为可寻址的三元组单元,使大模型能够与以关系为中心的表格交互,该表格功能类似于轻量级知识图谱。在医学领域,HuaTuo通过整合结构化的中医知识图谱和临床文本注入专业知识来微调基础模型。KGT引入了一种实时个性化机制,其中用户偏好和反馈被编码为特定用户知识图中的节点和边。对于推理密集型任务,PREMem将部分推理负担转移到记忆构建阶段,从原始对话中推导出结构化记忆项及其演化关系。同样地,Memory-augmented Query Reconstruction维护了一个专门的查询记忆,记录过去的KG查询和推理步骤,并使用检索到的记录来重构更准确的查询。基于时间线视角,TeaFarm沿着分段的时间线组织对话历史,并应用结构化压缩来管理终身上下文。COMET通过使用外部常识库解析对话并动态更新具有推断隐藏属性的上下文感知人格图,进一步完善了对话记忆。A-Mem将知识标准化为卡片状单元,按相关性组织并将相关记忆放在同一个盒子中,从而构建一个完整的记忆网络。内在记忆智能体采用分区架构,子智能体维护自己的角色特定私有记忆,同时协作读写共享记忆。扩展到多模态智能体,M3-Agent将图像、音频和文本统一为以实体为中心的记忆图。SALI构建了一个现实-想象混合记忆,将真实观察和想象的未来场景统一为一致的导航图。
混合
复杂的任务通常需要混合架构,这种架构将不同的认知功能分开,同时共享一个共同的记忆基底。Optimus-1 明确地将静态知识分离到一个用于规划的层次化有向知识图中,并将动态交互分离到一个抽象的多模态经验池中,以进行反思和自我改进。D-SMART 将一个结构化的事实记忆(实现为一个持续更新的知识图)与基于遍历的推理树结合起来。
讨论
平面记忆通过有效地在其节点之间建立联系,使记忆能够利用集体协同效应,从而编码更全面的上下文知识。此外,它支持超越简单迭代的检索机制,包括结构化的键-值查找和沿图边的关系遍历。这些功能使其在存储、组织和管理记忆方面表现出色。然而,它也面临着一个关键的限制:没有分层存储机制,所有记忆必须整合到单一的、整体的模块中。随着任务场景变得越来越复杂和多样化,这种冗余和平坦的设计对于实现稳健性能变得越来越不充分。更重要的是,高昂的构建和搜索成本显著阻碍了其实际部署。
层次化记忆(3D)
层次化记忆通过层级间的连接将信息组织成一个体积化的结构空间。
这种层次结构支持不同抽象程度的表示——从原始观察到紧凑的事件摘要,再到更高层次的主题模式。跨层连接进一步形成了一个体积化的记忆空间,系统不仅可以在单元之间横向导航,还可以在抽象层次上垂直导航。
层次化记忆超越了简单的分层,旨在构建具有深度抽象能力和动态进化机制的复杂系统。这些工作通常采用多级图结构或受神经科学启发的机制来构建更接近人类的体积化记忆空间,在这个空间中,信息更加丰富,记忆单元之间的联系更加清晰和明确。
金字塔
此类别将记忆构建为多级金字塔,在其中信息逐步被组织成更高层次的抽象,并以从粗到细的方式进行查询。HiAgent 通过子目标中心的分层工作记忆来管理长期任务,保持当前活动子目标的详细轨迹,同时将已完成的子目标压缩成更高级别的摘要,这些摘要可以在需要时选择性地检索。GraphRAG 通过社区检测构建多层次图索引,递归地将实体级别的子图聚合为社区级别的摘要。扩展了聚类记忆节点的想法,Zep 将智能体记忆形式化为时间知识图,并同样执行社区划分。ILM-TR 采用树状、金字塔形索引与内循环机制相结合,反复在不同抽象层次上查询摘要并更新短期记忆缓冲区,直到检索到的证据和生成的答案稳定下来。为了确保可控的个性化,EMG-RAG 将可编辑记忆图组织成三个层级,其中树状类型和子类索引(L1, L2)位于实体级记忆图(L3)之上。在多智能体系统中,G-Memory 使用由洞察图、查询图和交互图组成的三层图层次结构来组织共享经验。这种设计使得可以以查询为中心遍历,从而在高层次跨试验洞察和具体协作的紧凑轨迹之间垂直移动。
多层
这些形式强调分层专业化,将记忆组织成不同的模块或层次,专注于特定类型的信息或功能。Lyfe Agents 将显著的长期记录与低价值的瞬时细节分开,使系统能够保持一个紧凑且行为上重要的记忆层。H-Mem 明确地将长期对话记忆组织成一个多级层次结构,按语义抽象排序,其中较低层次存储细粒度的交互片段,而较高层次存储越来越压缩的摘要。受生物学启发的架构,如 HippoRAG,将记忆分解为关联索引组件(实现为开放知识图)和底层段落存储,使用图层来协调存储内容上的多跳检索。其继任者 HippoRAG 2 将这种设计扩展到非参数化的持续学习设置中,通过更深层次的段落集成和在线 LLM 过滤来丰富索引层。AriGraph 在统一图内按信息类型分离记忆,结合编码环境结构的语义知识图世界模型和将具体观察结果链接回语义主干的事件级组件。类似地,SGMem 在原始对话之上添加了一个句子图记忆层,将历史表示为块状单元内的句子级图。CAM 通过逐步聚类重叠的语义图,将阅读过程本身分层为分层模式结构。
讨论
通过将记忆节点置于层次和关系维度的交点,层级记忆允许不同的记忆相互作用并形成多维协同效应。这种设计有助于系统编码更加全面且深度上下文化的知识。该形式还支持强大的检索:它能够实现复杂的多路径查询,这些查询可以在每一层内的关系网络中移动,并在各抽象层次之间跨越。这种能力使系统能够以高精度检索与任务相关的记忆,从而获得强大的任务表现。
然而,结构的复杂性和密集的信息组织给检索效率和整体效果带来了挑战。特别是,确保所有存储的记忆保持语义意义以及设计系统的最优三维布局仍然是困难而关键的问题。
参数记忆
与将信息存储为可见且可编辑的离散单元的标记级记忆不同,参数记忆直接将信息存储在模型的参数中。在本节中,我们探讨了将记忆嵌入到可学习参数空间中的方法,使模型能够在不参考外部存储的情况下内化和回忆信息。
根据记忆相对于核心模型参数的存储位置,我们将参数记忆区分为两种主要形式:
两种主要类型的参数记忆
- 内部参数记忆:记忆编码在模型的原始参数(例如权重、偏置)中。这些方法直接调整基础模型以整合新知识或行为。
- 外部参数记忆:记忆存储在附加或辅助参数集中,如适配器、LoRA模块或轻量级智能体模型。这些方法引入新的参数来携带记忆,而不修改原始模型权重。
这种区分反映了关键的设计选择:记忆是完全吸收到基础模型中还是以模块化的方式附加在其旁边。在接下来的小节中,我们将概述每种形式的实现方法,分析其优缺点,并列出代表性系统或工作。表2提供了代表性的参数记忆方法的概述。
| Method | Type | Task | Optimization |
|---|---|---|---|
| I. Internal Parametric Memory | |||
| (a) Pre-Train Phase | |||
| TNL | Working | QA, Reasoning | SFT |
| StreamingLLM | Working | QA, Reasoning | SFT |
| LMLM | Factual | QA, Factual Gen | SFT |
| HierMemLM | Factual | QA, Language Modeling | SFT |
| Function Token | Factual | Language Modeling | Pretrain |
| (b) Mid-Train Phase | |||
| Agent-Founder | Experiential | Tool Calling, Deep Research | SFT |
| Early Experience | Experiential | Tool Calling, Embodied Simulation, Reasoning, Web | SFT |
| (c) Post-Train Phase | |||
| Character-LM | Factual | Role Playing | SFT |
| CharacterGLM | Factual | Role Playing | SFT |
| SELF-PARAM | Factual | QA, Recommendation | KL Tuning |
| Room | Experiential | Embodied Task | RL |
| KnowledgeEditor | Factual | QA, Fact Checking | FT |
| Mend | Factual | QA, Fact Checking, Model Editing | FT |
| PersonalityEdit | Factual | QA, Model Editing | FT, PE |
| APP | Factual | QA | FT |
| DINM | Experiential | QA, Detoxification | FT |
| AlphaEdit | Factual | QA | FT |
| II. External Parametric Memory | |||
| (a) Adapter-based Modules | |||
| MLP-Memory | Factual | QA, Classification, Textual Entailment | SFT |
| K-Adapter | Factual | QA, Entity Typing, Classification | SFT |
| WISE | Factual | QA, Hallucination Detection | SFT |
| ELDER | Factual | Model Editing | SFT |
| T-Patcher | Factual | QA | FT |
| Factual | QA | SFT | |
| (b) Auxiliary LM-based Modules | |||
| MAC | Factual | QA | SFT |
| Retroformer | Experiential | QA, Web Navigation | RL |
表2:参数化记忆方法的分类法。我们根据存储位置相对于核心模型对现有工作进行分类:内部参数化记忆将知识直接嵌入到原始权重中,而外部参数化记忆将信息隔离在辅助参数集中。基于训练阶段,我们对文章进行了二次分类。这些方法在三个技术维度上进行比较:(1) 类型定义了记忆的性质,(2) 任务指定了目标下游应用,(3) 优化表示优化策略,例如SFT、FT(微调)和PE(提示工程)。
内部参数记忆
内部参数记忆将下游任务所需的知识域、个性化知识或先验注入模型中。我们也认为增强模型的长上下文能力是一种先验的注入。记忆注入的时间可以是预训练阶段、持续预训练阶段、训练中期或后训练阶段。存储在内部参数中的记忆不会增加额外的参数或附加模块。
预训练
一些研究在预训练阶段引入了记忆机制,旨在解决长尾世界知识难以压缩到有限模型参数中的问题。
LMLM 和 HierMemLM 在预训练阶段将用于知识检索的记忆存储在模型中,而将知识本身存储在外部知识库中。
还有一些研究优化了注意力机制的计算效率,以增强长窗口记忆能力。
中途训练
在持续预训练阶段,一些研究将来自下游任务的通用经验纳入其中。一些研究提高了大语言模型在中途训练阶段的长窗口性能或效率,使模型能够在需要记忆辅助的任务中保持更多的短期记忆。
后训练
其他工作在后训练阶段引入记忆以适应下游任务。一些工作使大型语言模型能够记住个性化用户历史或风格。一些工作允许大型语言模型从过去类似任务执行的成功或失败中学习。Character-LM 和 CharacterGLM 通过微调将大型语言模型调整为不同的特征。在后训练阶段,SELF-PARAM 通过 KL 散度蒸馏注入额外知识,而不需要额外的参数。Room 将知识存储在外,同时内部保存经验。KnowledgeEditor 修改内部参数,旨在仅编辑需要修改的知识。MEND 通过使用小型网络修改大型模型的梯度来实现快速知识编辑。PersonalityEdit 基于心理学中的个性理论提出了一个大型语言模型个性编辑数据集。APP 采用多种训练目标,以确保在知识编辑过程中相邻知识受到的干扰最小。DINM 提出了一种模型编辑方法,使模型能够学会拒绝此类危险请求而不影响其正常功能。
讨论
内部参数的优势在于其简单的结构,不会给基础模型增加额外的推理开销或部署成本。其缺点在于更新内部参数较为困难:存储新记忆需要重新训练,这不仅成本高昂,而且容易遗忘旧记忆。因此,内部参数记忆更适合大规模存储领域知识或任务先验,而不适合短期个性化记忆或工作记忆。
外部参数化存储
将记忆以标记的形式存储在大语言模型(LLMs)之外,会导致模型对输入窗口中的标记形式的记忆内容理解不足。同时,在LLMs的参数中存储记忆也存在问题,例如更新困难和与预训练知识冲突。一些研究采用了一种折衷的方法,通过外部参数引入记忆而不改变LLMs的原始参数。
适配器
一种常见的外部参数记忆方法依赖于附加到冻结基础模型上的模块。MLP-Memory通过MLP将RAG知识与Transformer解码器集成。K-Adapter通过训练特定任务的适配器模块注入新知识,同时保持原始骨干模型不变,从而实现持续的知识扩展而不干扰预训练表示。WISE进一步引入了双参数记忆设置——分离预训练知识和编辑知识——以及一种在推理时动态选择使用哪个参数记忆的路由机制,从而缓解长期编辑过程中的冲突。ELDER通过维护多个LoRA模块并学习一个根据输入语义自适应地选择或混合这些模块的路由函数,在这一方向上取得了进展,提高了长期编辑场景下的鲁棒性和可扩展性。总体而言,这些方法利用额外的参数子空间以模块化和可逆的方式存储和检索记忆,避免了直接修改核心模型权重所带来的灾难性干扰风险。
辅助语言模型
除了基于适配器的存储之外,另一条研究路线采用了一种架构上更为解耦的外部参数化记忆形式,其中记忆存储在单独的模型或外部知识模块中。MAC 通过摊销网络将新文档中的信息压缩为紧凑的调制,并将其存储在记忆库中。Retroformer 提出了一种学习范式,用于记忆过去任务执行中的成功或失败经验。
讨论
这种外部参数化存储方法在适应性和模型稳定性之间提供了平衡。因为记忆被编码到额外的参数模块中,所以可以在不干扰基础模型预训练表示空间的情况下添加、删除或替换这些模块。这支持了模块化更新、特定任务个性化以及受控回滚,同时避免了全模型微调时可能出现的灾难性遗忘或全局权重扭曲。
然而,这种方法也存在局限性。外部参数模块仍需与模型的内部表示流集成,这意味着它们的影响是间接的,并通过模型的注意力和计算路径进行中介。因此,记忆注入的有效性取决于外部参数如何与内部参数知识相接口。
潜在记忆
潜在记忆的定义
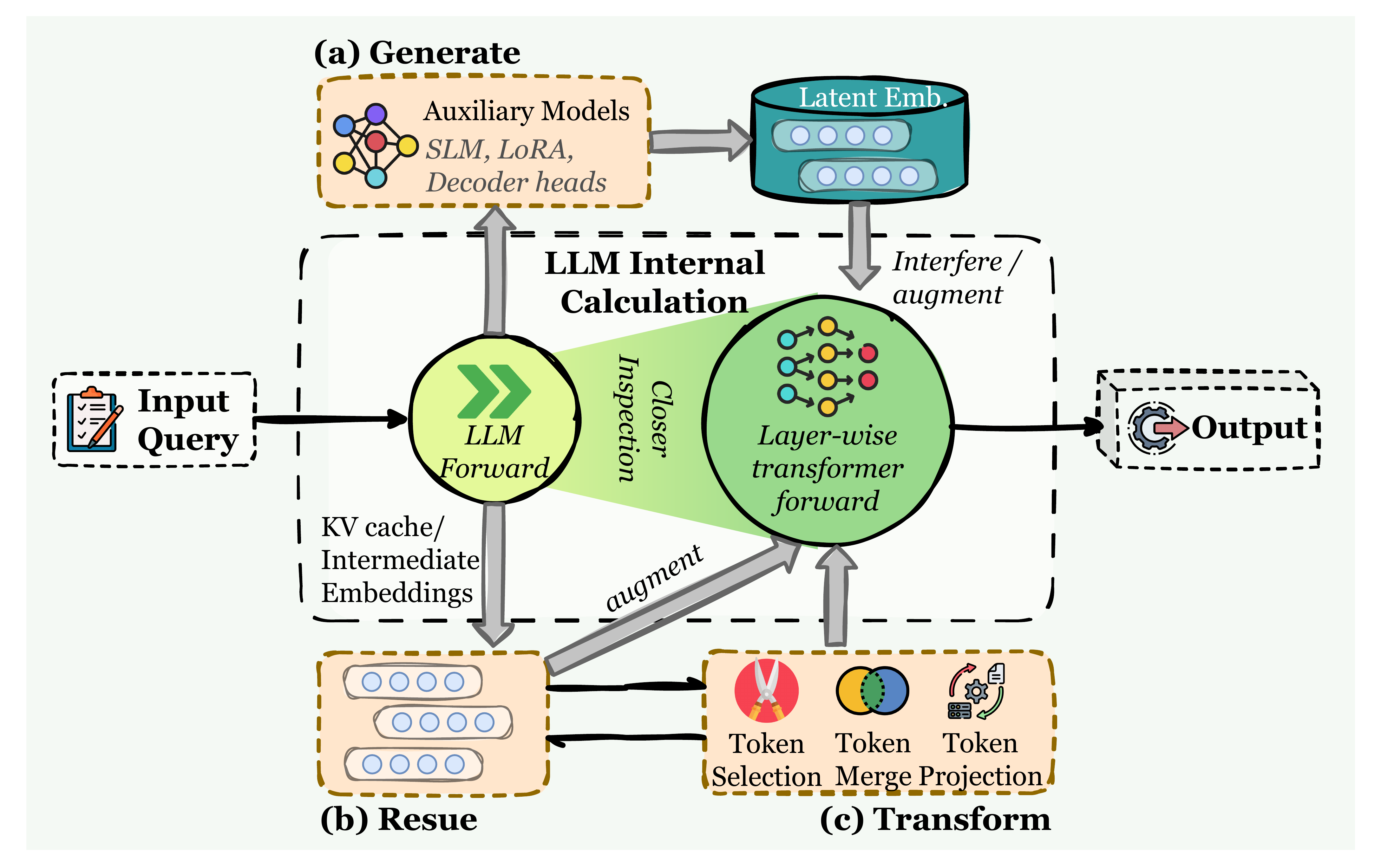
图4:LLM 智能体中的潜在记忆集成概览。 与显式的文本存储不同,潜在记忆在模型的内部表示空间中运作。该框架按潜在状态的来源划分为三类:(a) 生成(Generate):由辅助模型合成嵌入,以干预或增强 LLM 的前向计算; (b) 重用(Reuse):直接传播先前的计算状态,例如 KV 缓存或中间嵌入; (c) 转换(Transform):通过词元选择、合并或投影压缩内部状态,以维持高效的上下文管理。
潜在记忆是指隐含在模型内部表示中的记忆(例如,KV缓存、激活、隐藏状态、潜在嵌入),而不是以显式的人类可读令牌或专用参数集形式存储。
潜在记忆避免了以明文形式暴露记忆,并且实际上减少了推理延迟,同时通过在模型自身的表示空间内保留细粒度的上下文信号,可能提供更好的性能增益。
如4所示,我们根据潜在记忆的来源组织先前的工作,即潜在状态是如何形成并引入到智能体中的。我们在2中总结了这部分的工作。
三种主要类型的潜在记忆
- 生成:潜在记忆由独立模型或模块产生,然后作为可重用的内部表示提供给智能体。
- 重用:潜在记忆直接从前一计算中继承,最突出的是KV缓存重用(在同一轮次内或跨轮次),以及传播隐藏状态的递归或有状态控制器。
- 转换:现有的潜在状态被转换为新的表示(例如,蒸馏、池化或压缩),因此智能体可以在减少延迟和上下文足迹的同时保留关键信息。
| Method | Form | Type | Task | |
|---|---|---|---|---|
| I. Generate | ||||
| (a) Single Modal | ||||
| Gist | Gist Tokens | Working | Long-context Compression | |
| Taking a Deep Breath | Sentinel Tokens | Working | Long-context QA | |
| SoftCoT | Soft Tokens | Working | Reasoning | |
| CARE | Memory Tokens | Working | QA, Fact Checking | |
| AutoCompressor | Summary Vectors | Working | QA, Compression | |
| MemoRAG | Global Semantic States | Working | QA, Summary | |
| MemoryLLM | Persistent Tokens | Factual | Long-conv QA, Model Editing | |
| M+ | Cross-layer Token Pools | Factual | QA | |
| LM2 | Matrix Slots | Working | QA, Reasoning | |
| Titans | Neural Weights (MLP) | Working | QA, Language Modeling | |
| MemGen | LoRA Fragments | Working, Exp. | QA, Math, Code, Embodied Task, Reasoning | |
| EMU | Embeddings w/ Returns | Factual | Game | |
| TokMem | Memory Tokens | Exp. | Funcation calling | |
| Nested Learning | Nested Optimization | Factual | Language Modeling | |
| (b) Multi-Modal | ||||
| CoMem | Multimodal Embeddings | Factual | Multimodal QA | |
| ACM | Trajectory Embeddings | Working | Web | |
| Time-VLM | Patch Embeddings | Working | Video Understanding | |
| Mem Augmented RL | Novelty State Encoder | Working | Visual Navigation | |
| MemoryVLA | Perceptual States | Factual, Working | Embodied Task | |
| XMem | Key-Value Embeddings | Working | Video Segmentation | |
| II. Reuse | ||||
| Memorizing Transformers | External KV Cache | Working | Language Modeling | |
| SirLLM | Entropy-selected KV | Factual | Long-conv QA | |
| Memory\({}^{\mbox{3}}\) | Critical KV Pairs | Factual | QA | |
| FOT | Memory-Attention KV | Working | QA, Few-shot learning, Language Modeling | |
| LONGMEM | Residual SideNet KV | Working | Language Modeling and Understanding | |
| III. Transform | ||||
| Scissorhands | Pruned KV | Working | Image classification \ | |
| SnapKV | Aggregated Prefix KV | Working | Language Modeling | |
| PyramidKV | Layer-wise Budget | Working | Language Modeling | |
| RazorAttention | Compensated Window | Working | Language Modeling | |
| H2O | Heavy Hitter Tokens | Working | QA, Language Modeling |
表3:潜在记忆方法的分类。 我们根据潜在状态的来源对现有工作进行分类: Generate(生成)通过辅助模块合成记忆,Reuse(重用)传播内部计算状态, Transform(转换)对现有潜在状态进行压缩、修改或重构。我们从三个技术维度对方法进行对比:(1) Form 表示潜在记忆的具体数据类型,(2) Type 定义所记录内容的性质(例如工作记忆、事实记忆与经验记忆),(3) Task 表示目标下游应用。
生成
一个主要的研究方向是通过生成新的潜在表示而不是重用或转换现有的激活来构建记忆。在这种范式中,模型或辅助编码器创建紧凑的连续状态。这些状态可能作为序列中的特殊标记出现,也可能作为独立向量存在。它们总结了来自长上下文、任务轨迹或多模态输入的关键信息。生成的潜在摘要随后被存储、插入或用作后续推理或决策的条件。这使得系统能够在超过其固有上下文长度的情况下运行,保持特定任务的中间状态,并在不重新访问原始输入的情况下跨多个阶段保留知识。尽管具体形式因研究而异,但基本思想是一致的。记忆是通过学习编码或压缩明确产生的,由此产生的潜在状态作为可重用的记忆单元支持未来的推理。
这种设计选择可能会与参数化记忆产生潜在的模糊性,特别是因为许多方法依赖于单独训练的模型来生成潜在表示。然而,在本章中,我们的分类基于记忆的形式而非学习机制。关键在于,虽然这些方法通过学习编码来生成记忆,但生成的潜在表示被明确实例化并作为独立的记忆单元重用,而不是直接嵌入到模型的参数或前向传递激活中。在讨论具体方法时我们将回到这一区别。
单模态
在单模态设置中,一大类方法专注于长上下文处理和语言建模,其中模型生成一小部分内部表示来替代长原始输入。一种典型策略是将长序列压缩成几个内部标记或连续向量,这些可以在后续推理中重复使用。例如,Gist 训练语言模型,在处理长提示后生成一组摘要标记。在每个块边界引入一个特殊的哨兵标记,并鼓励模型将局部语义聚合到该标记中。SoftCoT 通过从最后一个隐藏状态生成特定实例的软标记来遵循类似的方向。CARE 通过训练一个上下文评估器进一步扩展了潜在标记,该评估器将检索到的RAG文档压缩为紧凑的记忆标记。
诸如AutoCompressor 和MemoRAG 的工作强调向量化或独立的潜在表示。AutoCompressor 将整个长文档编码成少量的摘要向量作为软提示,而MemoRAG 使用大语言模型产生紧凑的隐藏状态记忆,捕捉全局语义结构。这些方法不仅抽象出原始文本,还将检索到或上下文化的信息转换为新的优化用于重用的潜在记忆单元。为了支持更持久的记忆,MemoryLLM 在模型的潜在空间内嵌入了一组专用的记忆标记。M+ 将这一想法扩展到了跨层长期记忆架构。LM2 通过在每一层引入矩阵形状的潜在记忆槽,采取了相关但结构上不同的方向。
另一分支的工作将潜在记忆的生成内化于模型的参数动态中。尽管这些工作依赖于参数化的模块,其操作记忆单元仍然是潜在表示,因此它们牢固地属于这一类别。Titans 将长距离信息压缩成在线更新的MLP权重,在推理过程中生成潜在向量。MemGen 在解码期间动态生成潜在记忆:两个LoRA适配器确定在哪里插入记忆片段以及要插入什么潜在内容。EMU 训练一个状态编码器,以产生带有回报和期望性的潜在嵌入。
多模态
在多模态设置中,生成性潜记忆扩展到图像、音频和视频,将它们编码为紧凑的潜表示。CoMem 使用 VLM 将多模态知识压缩成一组嵌入,作为即插即用的记忆。类似地,将整个 GUI 交互轨迹压缩成固定长度的嵌入,并将其注入 VLM 输入空间。对于时间建模,Time-VLM 将视频或交互流分成块,并为每个块生成一个潜嵌入。
在基于视觉的导航中,学习了一个状态编码器,将视觉观察映射到潜空间,并构建一个仅包含新颖观察的片段记忆。MemoryVLA 维护一个感知-认知记忆库,以变压器隐藏状态的形式存储感知细节和高级语义。在长视频对象分割中,XMem 将每一帧编码为键-值潜嵌入,并将它们组织成一个多阶段记忆,包括感知、工作和长期组件。
讨论
这些单模态和多模态方法共享相同的基本原则:首先生成紧凑的潜在表示,然后将其作为记忆条目进行维护和检索。该模型能够主动构建高度信息密集的表示,以适应任务需求,以最小的存储成本捕获关键动态、长距离依赖关系或跨模态关系。它还避免了重复处理整个上下文,从而在扩展交互中实现更高效的推理。
然而,缺点也同样明显。生成过程本身可能会引入信息损失或偏差,并且状态可能在多次读写周期中漂移或累积错误。此外,训练专门模块来生成潜在表示会增加额外的计算开销、数据需求和工程复杂性。
重用
与生成新的潜在表示的方法相对,另一类研究直接重用模型的内部激活,主要是键-值(KV)缓存,作为潜在记忆。这些方法不转换(修改、压缩)存储的KV对,而是将前向传递中的原始激活视为可重用的记忆条目。主要挑战在于确定保留哪些KV对,如何对其进行索引,以及在长上下文或持续处理需求下如何高效地检索它们。
从认知角度来看,这种方法通过将生物记忆框定为键-值系统提供了概念基础,在该系统中,键作为检索地址,值编码存储的内容——这种抽象与现代大语言模型中的基于KV的记忆紧密相关。记忆变换器明确存储过去的KV对,并在推理过程中通过K最近邻搜索来检索它们。
FOT 通过引入记忆注意力层扩展了这一研究方向,这些层在推理过程中通过对额外的KV记忆进行KNN检索。LONGMEM 类似地增强了长距离检索,采用轻量级残差SideNet,将历史KV嵌入视为持久记忆存储。这些系统展示了如何通过检索感知的潜在KV状态组织可以显著增强对远距离信息的访问。
讨论
重用型潜在记忆方法强调了直接利用模型自身内部激活作为记忆的有效性,表明精心策划的KV表示可以作为一种强大且高效的基底,用于长距离检索和推理。
其最大的优势在于保持了模型内部激活的完整保真度,确保不会因剪枝或压缩而丢失信息。这使得它们在概念上简单、易于集成到现有形式中,并且高度忠实于模型的原始计算。然而,原始KV缓存随着上下文长度的增长而迅速增加,从而增加了记忆消耗并可能使检索效率降低。因此,重用的有效性在很大程度上取决于索引策略。
转换
转换型潜在记忆方法侧重于修改、压缩或重构现有的潜在状态,而不是生成全新的潜在状态或直接重用原始的KV缓存。这些方法将KV缓存和隐藏激活视为可塑的记忆单元,通过选择、聚合或结构转换来重塑它们。这样做,它们在生成型和重用型记忆之间占据了一个概念上的中间地带:模型不会创建新的潜在表示,但也不仅仅是简单地回放存储的KV对。
一个主要的研究方向集中在压缩KV缓存的同时保留关键语义。一些方法通过仅保留最具影响力的语言单位来减少记忆使用。当缓存容量超出时,Scissorhands 根据注意力分数修剪语言单位,而SnapKV 通过头投票机制聚合高重要性的前缀KV表示。PyramidKV 在各层间重新分配KV预算。SirLLM 基于这一视角,通过标记熵标准估计标记的重要性,并有选择地只保留信息丰富的KV条目。\(Memory^{3}\) 只存储最关键的注意力键值对,显著减少了存储需求。RazorAttention 引入了一种更明确的压缩方案:它计算每个头的有效注意力范围,仅保留有限的局部窗口,并使用补偿标记来保留被丢弃条目的信息。从更注重效率的角度来看,H2O 采用了一种更简单的淘汰策略,仅保留最近的语言单位以及特殊的H2标记以减小记忆占用。
讨论
这些方法展示了如何通过选择、检索增强或压缩重新编码,将潜在记忆转化为更有效的记忆表示,使大型语言模型能够在不依赖原始缓存重用的情况下扩展其可用上下文长度并提高推理性能。
它们的主要优势在于生成更加紧凑和信息密集的记忆表示,从而降低存储成本,并在长上下文中实现高效检索。通过重塑潜在状态,这些方法允许模型访问可能比原始激活更有用的精炼语义信号。然而,转换引入了信息丢失的风险,且与直接重用KV缓存相比,压缩后的状态变得更难以解释或验证。此外,用于剪枝、聚合或重新编码所需的额外计算也会增加系统的复杂性。
适配
如上所示,大量的工作集中在智能体记忆上,清楚地表明记忆机制对于智能体系统是必不可少的。在智能体系统中选择记忆类型反映了设计者期望智能体在给定任务中的行为方式。设计者不仅要求智能体记住某些信息,而且隐含地表达了他们希望这些信息如何塑造智能体的行为。因此,为一项任务选择正确的记忆类型远不止是一个简单的组合选择。
在本节中,我们从每种记忆类型的特征出发,讨论它们在理想情况下最适合的任务和场景,如图5所示。我们希望这一讨论能够为实际选择提供有用的想法和指导。示例仅展示了这些理想化设置下记忆的一种可能形式,并不意味着其他记忆类型在同一场景中缺乏独特优势。
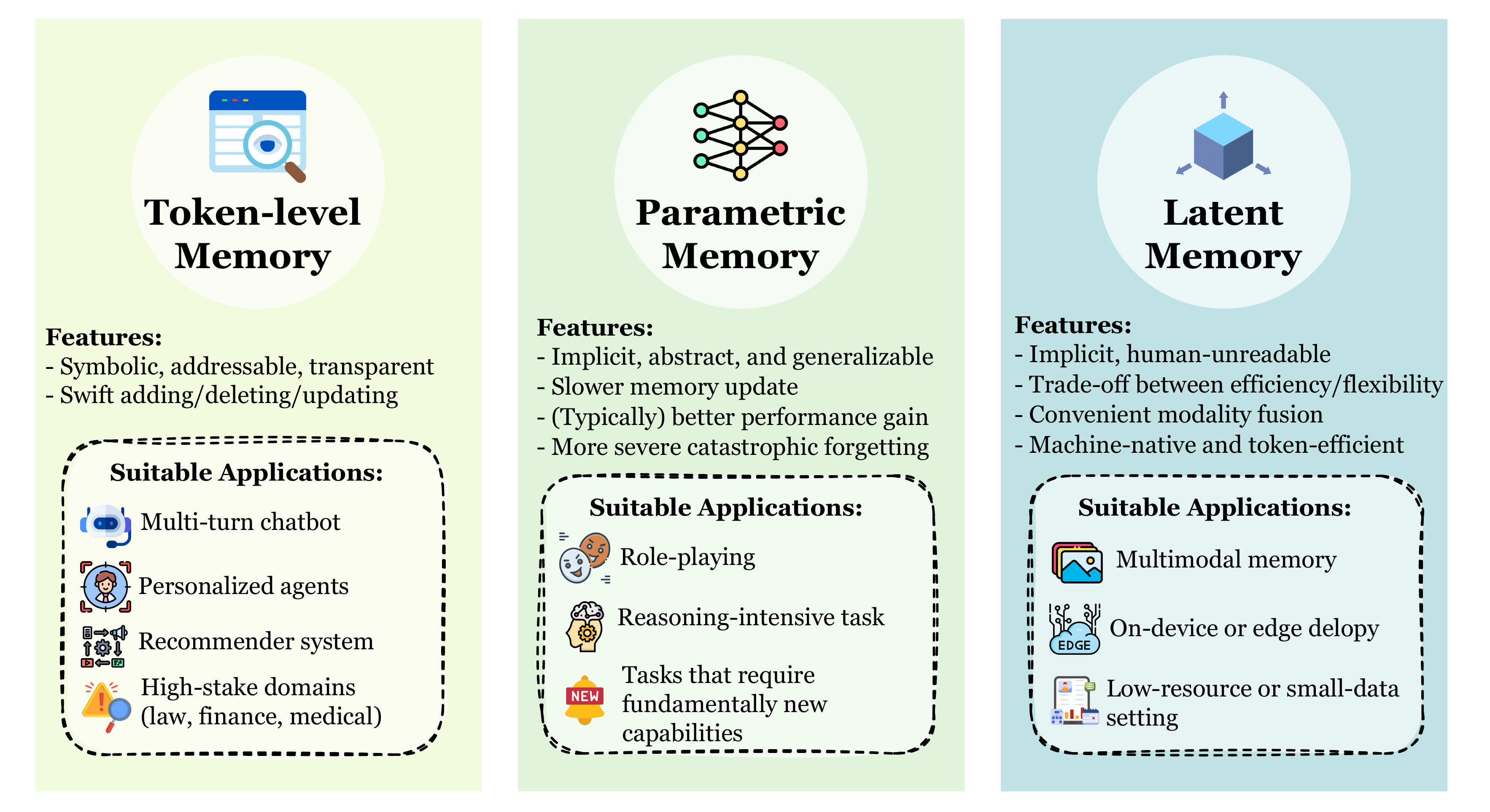
图5:LLM 智能体三种互补记忆范式概览。词元级记忆、参数记忆与潜在记忆在表示形式、更新动态、可解释性与效率等方面存在差异,因此在长时程与交互式智能体系统中呈现出不同的优势、局限与适用场景。
令牌级记忆
令牌级记忆保持符号化、可寻址和透明性,使其特别适合于需要明确推理、可控性和可问责性的场景。这种类型的记忆在实时、高频更新的环境中表现出色,其中智能体必须持续跟踪和修订信息,并且知识本身具有可以明确建模的清晰结构。其外部化能力使得记忆可以轻松检查、审计、转移或修改,使其特别适用于需要精确添加/删除/更新操作的领域。高水平的可解释性进一步确保了智能体的决策过程可以追溯到具体的记忆单元,这是在高风险应用中的关键属性。此外,令牌级记忆提供了长期稳定性并避免了灾难性遗忘,使智能体能够在较长时间范围内积累可靠的知识。另一个实际优势是,令牌级记忆通常作为即插即用模块实现,允许其与最新的闭源或开源基础模型无缝集成,而无需修改其内部参数。
可能的应用场景:
- 聊天机器人和多轮对话系统。
- 需要稳定记忆的长周期或终身智能体。
- 用户特定的个性化配置文件。
- 推荐系统。
- 企业或组织知识库。
- 法律、合规以及其他需要可验证来源的高风险领域。
参数化记忆
与符号记忆相比,参数化记忆是隐式的、抽象的和可泛化的,这使其自然适合需要概念理解和广泛模式归纳的任务。当智能体必须依赖适用于多种情境的一般知识或规则时,这种记忆特别有效,因为这些规律可以作为分布式表示内化,而无需显式外部查找。这种内化支持流畅推理和端到端处理,使模型能够系统地泛化到未见过的任务或问题变体。因此,参数化记忆更符合需要结构洞察力、稳健抽象以及深刻行为或风格模式的任务。
可能的应用场景:
- 角色扮演或一致的行为表现。
- 数学推理、编程、游戏和结构化问题解决。
- 人类对齐和规范性行为先验。
- 风格化、专业或领域专家的回应。
潜在记忆
与词元级或参数化记忆不同,潜在记忆介于显式数据和固定模型权重之间,能够在灵活性和效率之间实现独特的平衡。其低可读性提供了内在的隐私保护,使得潜在表示适用于敏感信息处理。同时,它们的高表达能力允许以最小的信息损失进行丰富的语义编码,使智能体能够捕捉跨模态或任务之间的细微关联。潜在记忆还支持高效的推理时间检索和集成,使智能体能够注入大量紧凑的知识。因此,这种记忆类型优先考虑性能和可扩展性而非可解释性,实现了高知识密度和压缩,非常适合受限或高度动态的环境。
可能的应用场景:
- 多模态或完全集成的智能体架构。
- 设备端或边缘部署及云服务环境。
- 加密或隐私敏感的应用领域。
功能性:为什么智能体需要记忆?
从大型语言模型作为通用的、无状态的文本处理器转变为自主的、目标导向的智能体,不仅仅是一个渐进的步骤,而是一种根本性的范式转变。这种转变暴露了无状态的关键局限性。根据定义,一个智能体必须在时间上持续存在、适应并连贯地交互。实现这一点不仅依赖于大的上下文窗口,而且从根本上依赖于记忆的能力。本节讨论智能体记忆的功能或基本目的,优先考虑其为何是必要的问题而非如何实现。我们认为智能体记忆不是一个单一的组件,而是一组不同的功能能力,每种能力都服务于使持久智能行为成为可能的独特目标。
为了提供系统的分析,本节围绕一个功能性分类来组织记忆的原因,该分类直接映射到智能体的核心需求。在最高层次上,我们区分了两个时间类别:长期记忆,作为跨会话积累知识的持久存储;短期记忆,作为活跃推理的会话内临时工作空间。这一高层次的时间划分进一步分解为三个主要的功能支柱,构成了我们分析的结构。此分类概述见图6。
图6:智能体记忆的功能分类法。我们依据功能(目的)将记忆能力组织为横跨两个时间域的三个主要支柱:(1) 事实记忆作为持久的陈述性知识库,用于确保交互的一致性、连贯性与适应性;(2) 经验记忆封装程序性知识,使智能体能够跨情节持续学习与自我进化;(3) 工作记忆提供对瞬态上下文进行主动管理的机制。
三种主要的记忆功能
- 事实记忆:智能体的陈述性知识库,通过回忆明确的事实、用户偏好和环境状态来确保一致性、连贯性和适应性。
该系统回答的问题是:“智能体知道什么?” - 经验记忆:智能体的过程性和策略性知识,通过从过去的轨迹、失败和成功中抽象化以实现持续学习和自我进化。
该系统回答的问题是:“智能体如何改进?” - 工作记忆:智能体在单个任务或会话期间用于主动上下文管理的容量有限、动态控制的草稿板。
该系统回答的问题是:“智能体现在在思考什么?”
这三种记忆系统不是孤立的,而是形成了一个动态的、相互连接的架构,定义了智能体的认知循环。这个循环始于编码,在编码过程中,智能体互动的结果(如新获得的事实或失败计划的结果)通过总结、反思或抽象化整合到长期记忆中。随后的处理发生在工作记忆中,它作为即时推断的活跃工作空间。为了支持这种推理,系统依赖检索来用从事实记忆和经验记忆的持久存储中提取的相关上下文和技能填充工作空间。
这种编码-处理-检索序列构成了使智能体能够同时从过去学习并在当下推理的中心架构模式。
事实记忆
事实记忆是指智能体存储和检索关于过去事件、用户特定信息以及外部环境状态的明确、陈述性事实的能力。这些信息包括广泛的内容,如对话历史、用户偏好以及外部世界的相关属性。通过允许智能体在解释当前输入时利用历史信息,事实记忆成为情境感知、个性化响应和扩展任务规划的基石。
为了理解智能体记忆的结构组成,我们借鉴了认知科学中关于陈述性记忆的框架。在神经科学中,陈述性记忆表示可以有意识访问的信息的长期存储,并通常分为两个主要组成部分:情景记忆和语义记忆。情景记忆存储与特定时间和空间背景相关的个人经历事件——即事件的“什么”、“哪里”和“何时”。其核心特征是能够精神上重新体验过去的事件。语义记忆则保留一般性的事实知识、概念和词义,而不依赖于它们被获取的具体场合。尽管在人脑中由一个统一的陈述性系统支持,这两个组成部分代表了不同的抽象层次。
在智能体系统中,这种生物学上的区分不是作为严格的二分法来操作的,而是作为一个处理连续体。系统通常通过将具体的交互历史记录为情景痕迹(例如对话回合、用户行为和环境状态)来启动这一过程。随后的处理阶段应用总结、反思、实体提取和事实归纳。由此产生的抽象内容存储在诸如向量数据库、键值存储或知识图谱等结构中,并由去重和一致性检查程序管理。通过这一序列,原始事件流逐渐转化为可重用的语义事实库。
功能上,这种架构确保智能体在交互过程中表现出三个基本属性:一致性、连贯性和适应性。
- 连贯性体现在强大的情境感知能力上。智能体能够回忆并整合相关的交互历史,引用过去的用户输入,并保持主题的连续性,从而确保响应形成逻辑连接的对话而非孤立的话语。
- 一致性意味着随时间推移的行为和自我呈现的稳定性。通过维护关于用户特定事实及其自身承诺的持久内部状态,智能体避免了矛盾和立场的任意变化。
- 适应性展示了基于存储的用户档案和历史反馈来个性化行为的能力。因此,响应风格和决策制定逐步与用户的特定需求和特征对齐。
为了说明,我们进一步根据它所指的主要实体组织事实记忆。这种以实体为中心的分类法,连同代表性方法及其技术设计选择,在3中进行了系统的总结。这种观点突出了两个核心应用领域:
- 用户事实记忆:指的是维持人类与智能体之间交互一致性的事实,包括身份、稳定的偏好、任务约束和历史承诺。
- 环境事实记忆:指的是与外部世界保持一致性的事实,例如文档状态、资源可用性和其他智能体的能力。
表4:事实记忆方法的分类法。我们根据主要目标实体对现有工作进行分类:用户事实记忆侧重于维持交互一致性,而环境事实记忆确保与外部世界的一致性。我们从三个技术维度对方法进行比较:(1) 载体标识存储介质;(2) 结构遵循词元级记忆的分类体系;(3) 优化表示集成策略,其中 PE 包括提示工程与不涉及参数更新的推理时技术,不同于 SFT 和 RL 等基于梯度的方法。
| Method | Carrier | Structure | Task | Optimization |
|---|---|---|---|---|
| I. User factual Memory | ||||
| (a) Dialogue Coherence | ||||
| MemGPT | Token-level | 1D | Long-term dialogue | PE |
| TiM | Token-level | 2D | QA | PE |
| MemoryBank | Token-level | 1D | Emotional Companion | PE |
| AI Persona | Token-level | 1D | Emotional Companion | PE |
| Encode-Store-Retrieve | Token-level | 1D | Multimodal QA | PE |
| Livia | Token-level | 1D | Emotional Companion | PE |
| mem0 | Token-level | 1D | Long-term dialogue, QA | PE |
| RMM | Token-level | 2D | Personalization | PE, RL |
| D-SMART | Token-level | 2D | Reasoning | PE |
| Comedy | Token-level | 1D | Summary, Compression, QA | PE |
| MEMENTO | Token-level | 1D | Embodied, Personalization | PE |
| O-Mem | Token-level | 3D | Personalized Dialogue | PE |
| DAM-LLM | Token-level | 1D | Emotional Companion | PE |
| MemInsight | Token-level | 1D | Personalized Dialogue | PE |
| (b) Goal Consistency | ||||
| RecurrentGPT | Token-level | 1D | Long-Context Generation, Personalized Interactive Fiction | PE |
| Memolet | Token-level | 2D | QA, Document Reasoning | PE |
| MemGuide | Token-level | 1D | Long-conv QA | PE, SFT |
| SGMem | Token-level | 2D | Long-context | PE |
| A-Mem | Token-level | 2D | QA, Reasoning | PE |
| M3-agent | Token-level | 2D | Multimodal QA | PE, SFT |
| II. Environment factual Memory | ||||
| (a) Knowledge Persistence | ||||
| MemGPT | Token-level | 1D | Document QA | PE |
| CALYPSO | Token-level | 1D | Tabletop Gaming | PE |
| AriGraph | Token-level | 3D | Game, Multi-op QA | PE |
| HippoRAG | Token-level | 3D | QA | PE |
| WISE | Parametric | / | Document Reasoning, QA | SFT |
| MemoryLLM | Parametric | / | Document Reasoning | SFT |
| Zep | Token-level | 3D | Document analysis | PE |
| MemTree | Token-level | 2D | Document Reasoning, Dialogue | PE |
| LMLM | Token-level | 1D | QA | SFT |
| M+ | Latent | / | Document Reasoning, QA | SFT |
| CAM | Token-level | 3D | Multi-hop QA | SFT, RFT |
| MemAct | Token-level | 1D | Multi-obj QA | RL |
| Mem-\(\alpha\) | Token-Level | 1D | Document Reasoning | RL |
| WebWeaver | Token-level | 1D | Deep Research | SFT |
| (b) Shared Access | ||||
| GameGPT | Token-level | 1D | Game Development | PE |
| Generative Agent | Token-level | 2D | Social Simulation | PE |
| S³ | Token-level | 1D | Social Simulation | PE |
| Memory Sharing | Token-level | 1D | Document Reasoning | PE |
| MetaGPT | Token-level | 1D | Software Development | PE |
| G-Memory | Token-level | 3D | QA | PE |
| OASIS | Token-level, Parametric | 1D | Social Simulation | PE |
用户事实记忆
用户事实记忆在会话和任务中持久保存特定用户的可验证事实,包括身份、偏好、日常习惯、历史承诺和显著事件。
其主要功能是防止无状态交互的特征故障模式,如共指漂移、重复引出和矛盾回应,从而减少对长期目标的中断。工程实践通常包括选择与压缩、结构化组织、检索与重用以及一致性管理,旨在以有限的访问成本维持长期对话和行为的一致性。
对话连贯性
对话连贯性要求智能体在长时间内保持对话上下文、特定用户事实和稳定的人格。这确保了后续轮次仍然对早期披露的信息和情感线索敏感,而不是退化为重复的澄清或不一致的回答。为了实现这一点,现代系统通过两种互补策略实现用户事实记忆:启发式选择和语义抽象。
为了有效处理有限的上下文窗口,主要策略是选择性地保留和排序交互历史。
系统不会保留所有原始日志,而是维护过去交互的结构化存储,并根据相关性、最近性、重要性或独特性等指标对条目进行排序。
通过基于这些分数过滤检索,高价值项目得以保留,并定期压缩成更高级别的摘要,从而在不使智能体的工作记忆过载的情况下维持连续性。
除了简单的选择外,高级框架还强调将原始对话片段转换和抽象为更高级别的语义表示。 诸如“记忆中思考”和“反思性记忆管理”等方法通过迭代更新操作将原始交互痕迹转换为思想表示或反思。这使得智能体能够查询稳定的语义记忆,保持后续回复的主题一致性并减少重复。同样,COMEDY 使用单一语言模型来生成、压缩和重用记忆,同时更新紧凑的用户档案。这些方法通过将记忆存储与原始令牌表面形式解耦,有效地在长对话历史中稳定了人格和偏好表达。
目标一致性
目标一致性要求智能体随着时间的推移维护和完善明确的任务表示。这确保了澄清问题、信息请求和行动严格与主要目标保持一致,从而最小化意图漂移。
为了减轻这种漂移,系统利用事实记忆来动态跟踪和更新任务状态。
像RecurrentGPT、Memolet和MemGuide这样的方法保留已确认的信息,同时突出未解决的部分。通过基于任务意图指导检索,这些方法帮助智能体满足缺失的约束并保持跨会话的关注。
对于复杂且长期的任务,记忆形式通常被结构化以促进围绕活动目标的局部检索。
例如,A-Mem将记忆组织成相互连接的笔记图,而H-Mem则使用关联机制在后续步骤依赖于先前观察时回忆先决条件事实。
在具体场景中,事实记忆使智能体行为基于用户的特定习惯和环境上下文。
诸如M3-Agent和MEMENTO之类的系统保存有关家庭成员、物体位置和日常事务的数据,重复使用这些信息以减少冗余探索和重复指令。
同样地,Encode-Store-Retrieve将自我中心视觉流处理成文本可寻址条目,允许智能体基于过去的视觉体验回答问题而无需用户重复。
摘要
这些机制共同将短暂的交互痕迹转化为持久的认知基础。通过将基于检索的排序与生成式抽象相结合,用户事实记忆使系统从简单的相似性匹配升级为主动维护明确的目标和约束。这一基础带来了双重好处:它通过长期的行为一致性培养了熟悉感和信任感,同时通过提高任务成功率、减少冗余和降低错误恢复开销来提高操作效率。
环境事实记忆
环境事实记忆涉及用户外部的实体和状态,包括长文档、代码库、工具和交互痕迹。
这种记忆范式解决了不完整的事实回忆和不可验证的来源问题,减少了多智能体协作中的矛盾和冗余,并在异构环境中稳定了长期任务。核心目标是提供一个可更新、可检索和可管理的外部事实层,在会话和阶段之间提供稳定的参考。
具体来说,我们将现有的实现分为两个互补的维度:知识持久性和多智能体共享访问。
知识持久性
知识记忆指的是对世界知识和领域特定知识的持久表示,这些表示支持长文档分析、事实问答、多跳推理以及代码和数据资源的可靠检索。
在知识组织方面,现有研究侧重于构建外部数据结构以增强推理能力。例如,HippoRAG 利用知识图谱来促进证据传播,而MemTree 采用动态层次结构来优化不断增长的语料库中的聚合和目标访问。关于存储形式,LMLM 通过将事实知识外部化到数据库中,明确地将其与模型权重分离,从而可以在不重新训练的情况下直接编辑知识并验证其来源。在叙述领域,CALYPSO 将冗长的游戏背景提炼成简短的散文,保持关键故事情节的可访问性。
在需要持续更新知识的场景中,以参数为中心的方法将持久性直接集成到模型架构中。MEMORYLLM、M+ 和 WISE 等方法通过引入可训练的记忆池或侧网络来吸收新信息。这些设计不仅仅依赖于静态的外部检索,而是专注于模型编辑的挑战,使智能体能够适应动态环境并在保留预训练骨干稳定性的同时纠正过时的事实。
共享访问
共享记忆为多智能体协作建立了一个可见且可管理的共同事实基础,用于对齐目标、携带中间产物并消除重复工作。通过维护一个集中的过去查询和响应的存储库,诸如记忆共享之类的框架使智能体能够异步地访问和构建同伴积累的见解。这种机制确保了单个智能体直接从集体知识中受益,从而抑制了矛盾结论并提高了整体系统效率。
对于复杂的项目协调,诸如MetaGPT和GameGPT之类的系统利用共享消息池作为发布计划和部分结果的中心工作空间。同样,G-Memory采用层次化记忆图作为统一的协调媒介。这些架构有助于围绕当前项目状态保持一致性,减少了通信开销,并允许从历史协作中提取可重用的工作流程。
在社会模拟领域,像生成性智能体和S\({}^3\)这样的平台以及OASIS和AgentSociety等大规模模拟器将全球环境和公共交互日志建模为共享记忆基底。该基底由群体逐步更新和观察,允许信息在智能体之间自然扩散,并支持大规模的历史感知的社会动态的一致性。
概要
环境事实记忆提供了一个可连续更新、可审计和可重用的外部事实层。在知识轴上,通过结构化组织和长期记忆模块,它提高了事实回忆的完整性、可解释性和可编辑性。在协作轴上,它通过共享和治理维护了跨智能体和跨阶段的一致性,从而能够在长周期、多参与者和多源信息的情况下实现稳健的决策和执行。
体验记忆
体验记忆封装了智能体如何将历史轨迹、提炼策略和交互结果编码为持久且可检索表示的机制。与管理瞬时上下文的工作记忆不同,体验记忆侧重于跨不同事件的知识长期积累和转移。
理论上基于认知科学,这一范式类似于人类的非陈述性记忆,特别是程序性和习惯系统。生物系统依赖于分布式神经回路进行隐式技能习得。相比之下,智能体体验记忆通常采用显式数据结构,如向量数据库或符号日志。这种实现差异赋予智能体一种在生物对应物中不存在的独特能力:能够内省、编辑并推理自己的程序知识。
至关重要的是,体验记忆为持续学习和自我进化提供了基础。通过维护一个结构化经验库,智能体实现了非参数化的适应路径,并避免了频繁参数更新所带来的高昂成本。该机制通过将交互反馈转化为可重用知识有效地闭合了学习循环。通过这一过程,智能体纠正过去的错误,抽象出通用启发式方法,并编译例行行为。因此,这种适应减少了冗余计算,并随着时间推移优化决策。
为了系统地分析现有文献,我们根据存储信息的抽象层次对体验记忆进行了分类。
基于抽象的分类法概述以及代表性范例见图7。基于此抽象分类下的代表性方法及其存储载体、表示形式和优化策略总结见表5。
- 案例型记忆存储历史事件的最小处理记录,优先考虑高信息保真度以支持直接重放和模仿。通过保持情境与结果之间的原始一致性,它作为具体、可验证证据的仓库,充当基于证据学习的情境示例。
- 策略型记忆从过去轨迹中提炼出可转移的推理模式、工作流程和高层次见解,以指导跨多种场景的规划。作为一种认知支架,它将决策逻辑与特定情境解耦,从而增强跨任务泛化能力并限制复杂推理的搜索空间。
- 技能型记忆封装了可执行的程序能力,从原子代码片段到标准化API协议,将抽象策略转化为可验证的操作。这一类别作为智能体的主动执行基底,使能力模块化扩展和高效处理工具使用环境成为可能。
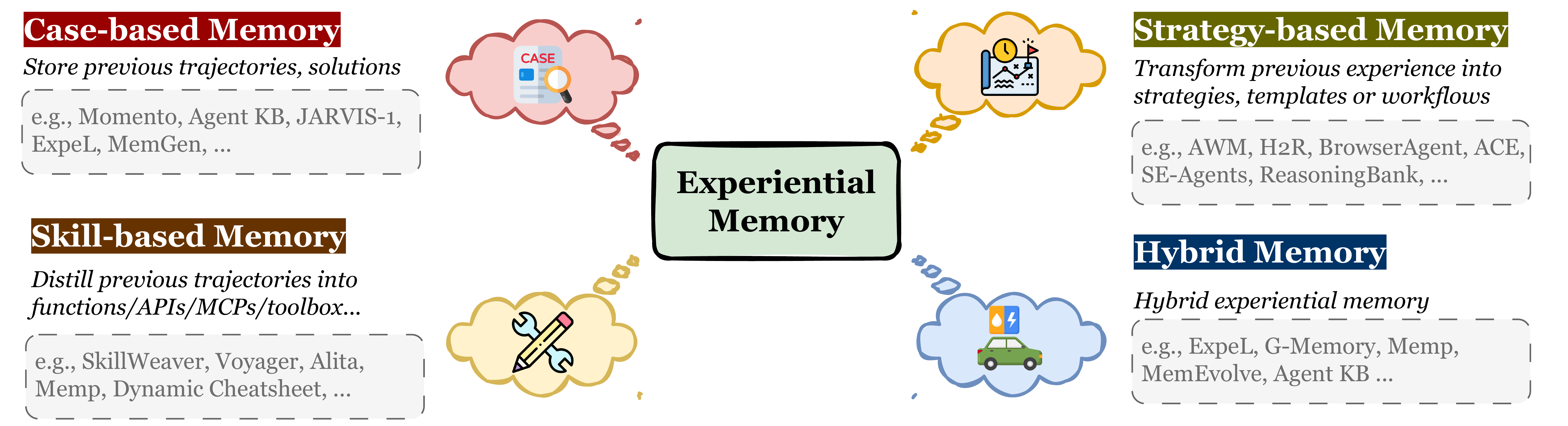
图7:经验记忆范式的分类体系。我们根据所存储知识的抽象层次对方法进行分类:(1) 基于案例的记忆:保留原始轨迹与解决方案,作为具体示例;(2) 基于策略的记忆:将经验抽象为高层策略、模板或工作流程;(3) 基于技能的记忆:将过程性知识提炼为可执行的函数与 API;(4) 混合记忆:整合多种表示形式。总体而言,这些系统映射了人类的程序性记忆机制,从而支持持续学习与自我进化。
这是根据您提供的LaTeX代码转换的Markdown格式文档。为了保持清晰度,我保留了定义的结构,并将长表格合并整理,去除了LaTeX引用标签以提高可读性。
| Method (方法) | Carrier (载体) | Form (形式) | Task (任务) | Optimization (优化) |
|---|---|---|---|---|
| I. Case-based Memory | ||||
| Expel | Token-level | Solution | Reasoning | PE |
| Synapse | Token-level | Solution | Web Interaction, Instruction-guided Web Task | PE |
| Fincon | Token-level | Solution | Financial | PE |
| MapCoder | Token-level | Solution | Coding | PE |
| Memento | Token-level | Trajectory | Reasoning | RL |
| COLA | Token-level | Trajectory | GUI, Web Navigation, Reasoning | PE |
| Continuous Memory | Latent | Trajectory | GUI | SFT |
| JARVIS-1 | Token-level | Trajectory | Game, GUI Interaction | PE |
| MemGen | Latent | Trajectory | Web Search, Embodied Simulation, Reasoning, Math, Code | RL, SFT |
| Early Experience | Parametric | Trajectory | Embodied Simulation, Reasoning, Web Navigation | SFT |
| DreamGym | Token-level | Trajectory | Web Interaction, Embodied Simulation, Shopping | RL |
| II. Strategy-based Memory | ||||
| Reflexion | Token-level | Insight | Embodied Simulation, Reasoning, Coding | PE |
| Buffer of Thoughts | Token-level | Pattern | Game, Reasoning, Coding | PE |
| AWM | Token-level | Workflow | Web Interaction, Instruction-guided Web Task | PE |
| RecMind | Token-level | Pattern | Recommendation | PE |
| H²R | Token-level | Insight | Game, Embodied Simulation | PE |
| ReasoningBank | Token-level | Insight | Web Interaction, Instruction-guided Web Task | PE |
| R2D2 | Token-level | Insight | Web Interaction | PE |
| BrowserAgent | Token-level | Insight | General QA, Web search | RL, SFT |
| Agent KB | Token-level | Workflow | Code, Reasoning | PE |
| ToolMem | Token-level | Insight | Reasoning, Image Generation | PE |
| PRINCIPLES | Token-level | Pattern | Emotional Companion | PE |
| SE-Agent | Token-level | Insight | Coding | PE |
| ACE | Token-level | Insight | Coding, Tool calling, Financial | PE |
| Flex | Token-level | Insight | Math, Chemistry, Biology | PE |
| AgentEvolver | Parametric | Pattern | Tool-augmented Task | RL |
| Dynamic Cheatsheet | Token-level | Insight | Math, Reasoning, Game | PE |
| Training-Free GRPO | Token-level | Insight | Math, Reasoning, Web Search | PE |
| III. Skill-based Memory | ||||
| CREATOR | Token-level | Function and Script | Reasoning, Math | PE |
| Gorilla | Token-level | API | Tool calling | SFT |
| ToolRerank | Token-level | API | Tool calling | PE |
| Voyager | Token-level | Code Snippet | Game | PE |
| RepairAgent | Token-level | Function and Script | Coding | PE |
| COLT | Token-level | API | Tool calling | SFT |
| ToolLLM | Token-level | API | Tool Calling | SFT |
| LEGOMem | Token-level | Function and Script | Office | PE |
| Darwin Gödel Machine | Token-level | Code Snippet | Code | PE |
| Huxley-Gödel Machine | Token-level | Code Snippet | Code | PE |
| MemP | Token-level | Function and Script | Embodied Simulation, Travel Planning | PE |
| SkillWeaver | Token-level | Function and Script | Web Interaction, Instruction-guided Web Task | PE |
| Alita | Token-level | MCP | Math, Reasoning, VQA | PE |
| Alita-G | Token-level | MCP | Math, Reasoning, VQA | PE |
| LearnAct | Token-level | Function and Script | Mobile GUI | PE |
| ToolGen | Parametric | API | Tool calling | SFT |
| MemTool | Token-level | MCP | Tool calling | SFT |
| ToolRet | Token-level | API | Web, Code, Tool Retrieval | SFT |
| DRAFT | Token-level | API | Tool calling | PE |
| ASI | Token-level | Functions and Scripts | Web Interaction | PE |
表5 经验记忆方法的分类体系。我们根据所存储知识的抽象层次对现有工作进行分类:基于案例的记忆保留原始记录以便直接回放,基于策略的记忆提炼用于规划的抽象启发式知识,基于技能的记忆编译可执行能力以支持行动。方法在三个技术维度上进行比较: (1) 载体用于标识存储介质;(2) 形式(Form)指定经验的表示格式; (3) 优化表示集成策略,其中 PE 包括提示工程与不涉及参数更新的推理时技术,不同于 SFT 和 RL 等基于梯度的方法。
体验记忆方法的分类
我们根据存储知识的抽象层次对现有工作进行分类:基于案例的记忆保留原始记录以直接重播,基于策略的记忆提炼用于规划的抽象启发式方法,基于技能的记忆编译用于行动的可执行能力。这些方法在三个技术维度上进行了比较:(1) 载体 (3) 识别存储介质;(2) 形式指定经验的表示格式;(3) 优化表示集成策略,其中 PE 包括提示工程和不涉及参数更新的推理时间技术,与 SFT 和 RL 等基于梯度的方法不同。
基于案例的记忆
基于案例的记忆存储了历史事件的最小处理记录,优先保证保真度,以确保这些事件可以作为情境示例进行重放或重复使用。与策略模板或技能模块不同,案例避免了广泛的抽象,从而保持了情境与解决方案之间的原始一致性。
轨迹
此类别保留了交互序列,以实现重放和基于证据的学习。为了在基于文本的环境中优化检索,Memento 采用软Q学习来动态调整选择高实用性的过去轨迹的概率。在多模态设置中,JARVIS-1 、EvoVLA 和 Auto-scaling Continuous Memory 保留了视觉上下文,前者存储了Minecraft中的生存经验,后者将GUI历史压缩为连续嵌入。此外,早期经验范式 构建了无奖励的、由智能体生成的交互轨迹,并通过训练中期将其整合到模型参数中以增强泛化能力。
解决方案
这一类别将记忆视为经过验证的解决方案的存储库。ExpeL 通过试错自主收集经验,将成功的轨迹作为范例存储,并提取文本洞察以指导未来行动。Synapse 同样注入抽象的状态-动作片段作为上下文示例,以对齐问题解决模式。在程序合成中,MapCoder 将相关示例代码作为类似剧本的案例保存,多智能体流水线检索并适应这些案例以提高复杂任务的可靠性。在金融领域,FinCon 维护过去行动、盈亏轨迹和信念更新的情景记忆,以促进稳健的跨轮决策。
摘要
基于案例的记忆提供了高信息保真度,并为模仿提供了可验证的证据。然而,依赖原始数据给检索效率和上下文窗口消耗带来了挑战。与可执行技能或抽象策略不同,案例不包含编排逻辑或函数接口。相反,它们作为高层推理操作的事实基础。
基于策略的记忆
与保留了发生事件的案例库不同,基于策略的记忆提取了如何行动的可转移知识,包括可重复使用的推理模式、任务分解、见解、抽象以及跨情境的工作流程。它将经验提升为可编辑、可审计和可组合的高层次知识,从而减少了对长时间轨迹回放的依赖,并提高了跨任务泛化能力和效率。在本节中,我们重点关注非代码或弱代码模板和工作流程。根据所保留知识的粒度和结构复杂性,我们将基于策略的记忆分为三种不同的类型:原子见解、顺序工作流程和图式模式。
见解
此类方法侧重于从过去的轨迹中提炼出离散的知识片段,如细粒度的决策规则和反思性启发式方法。
H\({}^2\)R 明确地将规划级和执行级记忆分离,使得高层次规划见解和低层次操作规则可以分别检索,以在多任务场景中实现细粒度迁移。
R2D2 将记忆、反思和动态决策相结合,用于网页导航,从失败和成功的案例中提取纠正性见解,以指导后续的情节。
对于长期网页自动化,BrowserAgent 将关键结论作为显式记忆保存下来,以稳定长链推理并减轻上下文漂移。
工作流程
与原子化、静态的见解不同,工作流程将策略封装为结构化的行动序列——可执行的例程从先前的轨迹中抽象出来,以指导推理时的多步骤执行。
智能体工作流记忆(AWM)在Mind2Web和WebArena上诱导可重用的工作流程,并将其作为高级框架来指导后续生成,从而提高成功率并减少步骤,而无需更新基础模型权重。这表明策略模板可以充当顶层控制器,补充案例级证据。
智能体知识库(KB)建立了一个统一的知识库,将工作流程视为可转移的过程知识。它采用分层检索,首先访问工作流程以构建战略方法,并能够在不同的智能体架构之间重用问题解决逻辑。
模式
在更抽象的层次上,推理模式作为认知模板封装了解决问题的结构,使智能体能够通过实例化这些可泛化的框架来解决复杂的推理任务。思维缓冲区维护了一个元缓冲区,其中包含用于解决新问题时检索和实例化的思维模板。同样地,推理库将成功和失败都抽象为可重用的推理单元,促进测试时的扩展和稳健的学习。RecMind 的自我启发规划算法生成中间自我引导以构建后续规划和工具使用。在对话智能体领域,PRINCIPLES 通过离线自博弈构建合成策略记忆,以指导推理时的策略规划,从而消除了额外训练的需求。
这些进展表明从描述性规则向可移植推理结构的范式转变。
摘要
基于策略的记忆,包括见解、工作流程和模式,作为高级框架指导生成性推理。
与依赖于检索特定原始轨迹的基于案例的记忆不同,这种记忆形式提炼出可泛化的模式,有效地约束搜索空间并提高对未见过任务的鲁棒性。
然而,一个关键区别在于这些策略作为结构指南而非可执行动作;它们指导规划过程但不直接与环境交互。
这一局限性需要基于技能的记忆来补充,在接下来的部分中将讨论这种记忆存储可调用的能力和工具。
最终,强大的智能体通常会协同这些组件:策略提供抽象的规划逻辑,而技能处理具体的执行。
基于技能的记忆
技能记忆捕捉了智能体的程序性能力,并将抽象策略转化为可验证的操作。它编码了智能体能够做什么,补充了智能体所知道的陈述性知识,并通过提供可调用、可测试和可组合的执行项来锚定感知-推理-行动循环。最近的证据表明,语言模型可以学习何时以及如何调用工具,并且随着大量工具库的增加而可靠地扩展,从而确立了技能记忆作为现代智能体执行基础的地位。
技能记忆涵盖了从内部细粒度代码到外部标准化接口的连续体。统一的标准非常简单:技能必须由智能体调用,其结果必须可验证以支持学习,并且它们必须与其他技能组合以形成更大的例行程序。
代码片段
作为可重用片段存储的可执行代码提供了从经验到能力的最快路径。在开放性任务中,智能体将成功的子轨迹提炼成可解释的程序,并在不同环境中重用它们。Voyager 通过不断增长的技能库体现了这一模式;达尔文哥德尔机则更进一步,在实证验证下安全地重写自己的代码,从而产生自我参照且逐步增强的能力集。
函数和脚本
将复杂行为抽象成模块化的函数或脚本可以提高可重用性和泛化能力。最近的进展使智能体能够自主创建用于解决问题的专用工具,并通过演示和环境反馈在诸如移动图形用户界面、网页导航和软件工程等不同领域中改进工具使用能力。此外,程序性记忆的新兴机制使智能体能够将执行轨迹提炼成可检索的脚本,从而促进对新场景的有效泛化。
API
API 作为封装技能的通用接口。虽然早期的工作集中在微调模型以正确调用工具上,但随着 API 库的指数级增长,主要瓶颈已经转移到检索上。标准的信息检索方法往往无法捕捉到工具的功能语义。因此,最近的方法转向了基于学习的检索和重排序策略,这些策略考虑了工具文档的质量、层次关系以及协作使用模式,以弥合用户意图与可执行功能之间的差距。
MCPs
为了减少基于API的生态系统中的协议碎片化,模型上下文协议提供了一个开放标准,统一了智能体发现和使用工具及数据的方式,包括按需加载工具的代码执行模式,从而减少了上下文开销。广泛的平台支持表明正朝着一个共同的接口层收敛。
除了标准可执行文件外,研究还探索了工具能力的可学习记忆以处理不确定的神经工具、参数集成将工具符号嵌入以统一检索和调用,以及架构即技能的观点,在这种观点下,专门的智能体是模块化设计空间内的可调用模块。总的来说,这些方向将技能记忆重新定义为一种可学习、可进化和可编排的能力层。
总结
总之,基于技能的记忆构成了智能体的主动执行基础,从静态代码片段和模块化脚本发展到标准化API和可学习架构。它通过将基于案例和基于策略记忆中的见解转化为可验证的过程,弥合了抽象规划与环境互动之间的差距。随着工具创建、检索和互操作性机制(例如,MCP)的成熟,技能记忆超越了简单的存储功能,实现了一个持续的能力合成、改进和执行循环,推动了开放式的智能体进化。
混合记忆
先进的智能体架构越来越多地采用混合设计,将多种形式的经验记忆整合起来,以平衡基于证据的推理与泛化的逻辑。通过维护涵盖原始事件、提炼规则和可执行技能的知识谱系,这些系统能够动态选择最合适的记忆格式,确保在不同情境下既能精确检索又能广泛泛化。
一个显著的方向是结合基于案例和基于策略的记忆,以促进互补推理。例如,ExpeL 将具体的轨迹与抽象的文本见解结合起来,使智能体能够回忆特定解决方案的同时应用一般启发式方法。Agent KB 采用分层结构,其中高级工作流程指导规划,而具体的解决方案路径提供执行细节。同样地,R2D2 整合了历史轨迹的回放缓冲区和从过去错误中提炼决策策略的反思机制,有效地连接了案例检索和策略抽象。此外,Dynamic Cheatsheet 通过存储累积的策略和问题解决见解来防止冗余计算,以便在推理时立即重用。
此外,最近的框架努力统一记忆的生命周期,包括基于技能的组件或建立全面的认知架构。在科学推理方面,ChemAgent 构建了一个自我更新的库,将执行案例与可分解的技能模块配对,使模型能够通过积累的经验来完善其化学推理能力。采取整体方法,LARP 为开放世界游戏建立了认知架构,和谐地整合了用于世界知识的语义记忆、用于交互案例的情景记忆以及用于可学习技能的过程记忆,确保一致的角色扮演和稳健的决策制定。最后,像 G-Memory 和 Memp 这样的进化系统实现了动态转换,其中反复成功的案例逐渐被编译成高效的技能,自动从大量检索过渡到快速执行。最近的一项努力,MemVerse 结合了参数记忆和令牌级过程记忆。
工作记忆
在认知科学中,工作记忆被定义为一种容量有限、动态控制的机制,通过选择、维持和转换当前任务相关信息来支持高级认知。它不仅仅是一个临时存储器,还意味着在资源限制下的主动控制。
这种观点基于多组件模型和嵌入过程理论等框架,这些框架都强调注意力焦点、干扰控制和有限容量。
当转移到大型语言模型(LLMs)时,标准上下文窗口主要作为一个被动的只读缓冲区。尽管模型可以在推理过程中使用窗口中的内容,但它缺乏明确的机制来动态地选择、维持或转换当前工作空间。
最近的行为证据表明,当前模型并不表现出类似人类的工作记忆特征,这强调了需要明确设计可操作的工作记忆机制。
在整个这一节中,我们将工作记忆定义为在一个单一事件中对上下文进行主动管理和操作的一系列机制。
目标是将上下文窗口从一个被动的缓冲区转变为一个可控的、可更新的且抗干扰的工作空间。
这种转变提供了直接的好处:在固定注意力预算下增加任务相关信息的密度,抑制冗余和噪声,并允许重写或压缩表示以保持连贯的思维链。我们根据交互动态将这些机制分类。
基于这种交互式分类法,代表性的工作记忆方法及其存储载体、任务领域和优化策略在4中进行了系统总结。
- 单回合工作记忆 专注于输入的浓缩和抽象。在这种情况下,系统必须在单次前向传递中处理大量即时输入,如长文档或高维多模态流。目标是动态过滤和重写证据,以构建一个有限的计算草稿板,从而最大化每个标记的有效信息负载。
- 多回合工作记忆 解决了时间状态维护问题。在顺序交互中,挑战在于防止历史累积压垮注意力机制。这涉及通过持续的读取、执行和更新循环来维持任务状态、目标和约束,确保中间产物在各回合中折叠和整合。
总之,对于大型语言模型而言,工作记忆代表了一种向主动、事件内上下文管理转变的范式。通过与主动操作的认知要求保持一致,它抑制了干扰,并为长上下文推理的工程约束提供了一个实用的解决方案。
| Method | Carrier | Task | Optimization |
|---|---|---|---|
| I. Single-turn Working Memory | |||
| (a) Input Condensation | |||
| Gist | Latent | Instruction Fine-tuning | SFT |
| ICAE | Latent | Language Modeling, Instruction Fine-tuning | Pretrain, LoRA |
| AutoCompressors | Latent | Langague Modeling | SFT |
| LLMLingua | Token-level | Reasoning, Conversation, Summarization | PE |
| LongLLMLingua | Token-level | Multi-doc QA, Long-context, Multi-hop QA | PE |
| CompAct | Token-level | Document QA | SFT |
| HyCo2 | Hybrid | Summarization, Open-domain QA, Multi-hop QA | SFT |
| Sentence-Anchor | Latent | Document QA | SFT |
| MELODI | Hybrid | Pretraining | Pretrain |
| (b) Observation Abstraction | |||
| Synapse | Token-level | Computer Control, Web Navigation | PE |
| VideoAgent | Token-level | Long-term Video Understanding | PE |
| MA-LMM | Latent | Long-term Video Understanding | SFT |
| Context as Memory | Token-level | Long-term Video Generation | PE |
| II. Multi-turn Working Memory | |||
| (c) State Consolidation | |||
| MEM1 | Latent | Retrieval, Open-domain QA, Shopping | RL |
| MemGen | Latent | Reasoning, Embodied Action, Web Search, Coding | RL |
| MemAgent | Token-level | Long-term Doc. QA | RL |
| ReMemAgent | Token-level | Long-term Doc. QA | RL |
| ReSum | Token-level | Long-horizon Web Search | RL |
| MemSearcher | Token-level | Multi-hop QA | SFT, RL |
| ACON | Token-level | App use, Multi-objective QA | PE |
| IterResearch | Token-level | Reasoning, Web Navigation, Long-Horizon QA | RL |
| SUPO | Token-level | Long-horizon task | RL |
| AgentDiet | Token-level | Long-horizon task | PE |
| SUMER | Token-level | QA | RL |
| (d) Hierarchical Folding | |||
| HiAgent | Token-level | Long-horizon Agent Task | PE |
| Context-Folding | Token-level | Deep Research, SWE | RL |
| AgentFold | Token-level | Web Search | SFT |
| DeepAgent | Token-level | Tool Use, Shopping, Reasoning | RL |
| (e) Cognitive Planning | |||
| SayPlan | Token-level | 3D Scene Graph, Robotics | PE |
| KARMA | Token-level | Household | PE |
| Agent-S | Token-level | Computer Use | PE |
| PRIME | Token-level | Multi-hop QA, Knowledge-intensive Reasoning | PE |
表6:工作记忆方法的分类。我们根据交互动态将方法划分为单轮(Single-turn)与多轮(Multi-turn)两种设置。方法从三个技术维度进行比较: (1) 载体(Carrier)用于标识存储介质;(2) 任务(Task)指定评估领域或应用场景;(3) 优化(Optimization)表示集成策略,其中 PE 包括提示工程与不涉及参数更新的推理时技术,不同于 SFT 和 RL 等基于梯度的方法。
单轮工作记忆
单轮工作记忆解决了在单次前向传递中处理大量即时输入(包括长文档和高维多模态流)的挑战。
其目标不是被动地消耗整个上下文,而是积极构建一个可写的工作空间。这涉及到过滤和转换原始信息,以在固定的注意力和记忆预算下提高信息密度和可操作性。
我们将这些机制分为两类:输入浓缩,即减少物理标记的数量;以及观察抽象,即将数据转换为结构化的语义表示。
输入浓缩
输入浓缩技术旨在预处理上下文,以最小化令牌使用量同时保留关键信息。这些方法通常分为三种范式:硬浓缩、软浓缩和混合浓缩。
硬浓缩基于重要性指标离散地选择令牌。像LLMLingua和LongLLMLingua这样的方法通过估计令牌困惑度来丢弃可预测或与任务无关的内容,而CompAct则采用迭代策略来保留最大化信息增益的段落。尽管效率高,但硬选择可能会破坏句法或语义依赖关系。
软浓缩将变长的上下文编码为密集的潜在向量(记忆槽)。Gist、In-Context Autoencoder (ICAE) 和AutoCompressors等方法训练模型将提示压缩为有效的摘要令牌或不同的记忆嵌入。这可以实现高压缩比,但需要额外的训练,并且可能会掩盖细粒度的细节。
HyCo2等混合方法试图通过结合全局语义适配器(软)和令牌级保留概率(硬)来调和这些权衡。
观察抽象
虽然凝聚关注于减少,观察抽象旨在将原始观察转换为便于推理的结构化格式。
该机制将动态、高维的观察空间映射到固定大小的记忆状态中,防止智能体被原始数据淹没。
在复杂的交互环境中,抽象将冗长的输入转换为简洁的状态描述。
Synapse 将非结构化的 HTML DOM 树重写为与任务相关的状态摘要,以指导 GUI 自动化。同样地,在多模态设置中,处理视频流中的每一帧在计算上是不可行的。工作记忆机制通过提取语义结构来解决这个问题:Context as Memory 基于视野重叠过滤帧,VideoAgent 将流转换为时间事件描述,而 MA-LMM 维护一个视觉特征库。这些方法有效地将高维、冗余的流重写为低维、语义丰富的表示形式,可以在有限的上下文窗口内进行高效处理。
摘要
单轮工作记忆充当一个主动压缩层,最大限度地提高上下文窗口在即时推理中的利用率。通过输入浓缩和观察抽象,这些机制有效地增加了操作工作空间的信息密度,确保在容量限制下仍能保留关键证据。然而,这种优化仅限于单轮内;它解决了静态输入的广度和复杂性问题,而不是动态交互的时间连续性问题。
多轮工作记忆
多轮工作记忆处理的问题空间与单轮设置根本不同。在长时交互中,主要瓶颈从即时上下文容量转移到任务状态和历史相关性的持续维护。即使有扩展的上下文窗口,历史积累最终也会耗尽注意力预算、增加延迟并导致目标漂移。
为了缓解这个问题,在多轮设置中的工作记忆作为外部化状态载体,组织了一个读取、评估和写入的连续循环。目的是在有限的资源预算内保持关键状态信息的可访问性和一致性。我们将这些机制按其状态管理策略分类:状态整合、层次折叠和认知规划。
状态整合
在连续的交互流中,状态整合通过动态更新将不断增长的轨迹映射到固定大小的状态空间中。将交互视为流式环境,MemAgent 和 MemSearcher 采用循环机制来更新固定预算记忆并丢弃冗余信息,从而从一个紧凑且不断演变的状态中回答查询。ReSum 通过定期将历史记录提炼为推理状态进一步扩展了这一点,并利用强化学习优化基于摘要条件的行为以进行无限探索。
超越启发式总结,ACON 将状态整合视为一个优化问题,共同压缩环境观察和交互历史到有界凝聚,并从失败案例中迭代改进压缩指南。IterResearch 进一步采用了受MDP启发的公式,通过迭代工作区重建,其中不断演化的报告作为持久性记忆,周期性合成缓解了长期研究中的上下文窒息和噪声污染问题。
关于状态表示,方法各异以确保常数大小的占用空间。MEM1 维护一个共享内部状态,该状态将新观察与先前记忆合并。与显式文本不同,MemGen 直接将潜在记忆标记注入推理流中。
分层折叠
对于复杂、长期的任务,状态维护需要超越线性汇总的结构。分层折叠基于子目标分解任务轨迹,在子任务激活时仅保持细粒度的跟踪,并在完成子轨迹后将其折叠成简洁的摘要。
这种先分解再整合的策略允许工作记忆动态扩展和收缩。HiAgent 通过使用子目标作为记忆单元来实例化这一点,仅保留活跃的动作-观察对,并在子目标完成后写回摘要。Context-Folding 和 AgentFold 通过将折叠操作变成可学习的策略来扩展这一点,训练智能体自主决定何时分支到子轨迹以及如何将它们抽象为高级状态。DeepAgent 进一步将这种方法应用于工具使用推理,将交互压缩为结构化的事件记忆和工作记忆,以支持细粒度的奖励分配。通过用稳定的高级抽象替换已完成的子轨迹,这些方法在保持小的活跃窗口的同时保留了关键上下文。
认知规划
在最高层次的抽象中,工作记忆创建并维护一个外化的计划或世界模型。状态函数不仅作为过去的总结,而且作为一个前瞻性的结构来指导未来的行动。
PRIME 将检索直接集成到规划循环中,确保记忆更新积极支持复杂的推理步骤。
在具身和能动环境中,将语言模型视为高级规划者将计划提升为工作记忆的核心。像 SayPlan 这样的方法使用 3D 场景图作为可查询的环境记忆,以在大空间内扩展规划。在 GUI 和家庭任务中,Agent-S 和 KARMA 等系统通过将推理锚定到分层计划,并利用增强记忆的检索来连接长期知识与短期执行,从而稳定了长周期性能。
通过使计划和结构化的环境表示成为工作记忆中可读写的核心,智能体可以保持目标一致性,并在感知失败时稳健地修订策略。
摘要
多轮工作记忆依赖于可操作状态载体的构建,而不是原始历史的保留。通过集成状态整合以压缩连续流、分层折叠以结构化子轨迹以及认知规划以锚定未来行动,这些机制有效地将推理性能与交互长度解耦。这一范式使智能体能够在遵守严格的计算和记忆限制的同时,在无限的时间范围内保持时间连贯性和目标一致性。
动态性:记忆如何运作与演变?

图8:智能体记忆的运行动态。我们将完整的记忆生命周期解耦为三个驱动系统适应性与自我进化的基本过程:(1) 记忆形成(Memory Formation)通过选择性识别具有长期效用的模式,将原始交互经验转化为信息密集的知识单元;(2) 记忆演化(Memory Evolution)通过巩固、更新与遗忘机制,将新记忆动态整合进既有记忆库,从而确保知识库保持连贯且高效;(3) 记忆检索(Memory Retrieval)执行上下文感知的查询以访问特定记忆模块,从而以精确的信息支持优化推理性能。字母顺序表示记忆系统内部各操作的执行顺序。
前几节介绍了记忆的架构形式和功能角色,概述了一个相对静态的概念框架。然而,这种静态观点忽略了智能体记忆本质上所具有的动态特性。与静态编码在模型参数或固定数据库中的知识不同,智能体记忆系统可以动态地构建和更新其记忆存储,并根据不同的查询执行定制化的检索。这种适应能力对于使智能体能够自我进化并进行终身学习至关重要。
因此,本节探讨了从静态存储到动态记忆管理和利用的范式转变。这一范式转变反映了智能体记忆相对于静态数据库方法的基本操作优势。实际上,智能体记忆系统可以根据推理痕迹和环境反馈自主提取精炼、可泛化的知识。通过将新提取的知识与现有记忆库动态融合和更新,系统确保了对不断变化环境的持续适应,并减轻了认知冲突。基于构建的记忆库,系统在特定时刻从指定的记忆模块中执行有针对性的检索,从而有效增强推理。为了系统地分析记忆系统“如何”运作和演变,我们将完整的记忆生命周期分解为三个基本过程。8全面展示了这一动态记忆生命周期,突出了记忆形成、演变和检索如何相互作用以支持自适应和自我进化的智能体行为。
记忆系统中的三个基本过程
- 记忆形成:此过程专注于将原始经验转化为信息密集的知识。记忆系统不是被动记录所有交互历史,而是选择性地识别具有长期效用的信息,如成功的推理模式或环境约束。这部分回答了“如何提取记忆?”的问题。
- 记忆演变:此过程代表记忆系统的动态演变。它关注于将新形成的记忆与现有记忆库整合。通过相关条目的巩固、冲突解决和自适应修剪等机制,系统确保记忆在不断变化的环境中保持可泛化、一致且高效。这部分回答了“如何精炼记忆?”的问题。
- 记忆检索:此过程决定了检索记忆的质量。根据上下文,系统构建任务感知的查询,并使用精心设计的检索策略访问适当的记忆库。因此,检索到的记忆在语义上相关且在功能上对推理至关重要。这部分回答了“如何利用记忆?”的问题。
这三个过程并不是独立的;相反,它们形成了一个相互连接的循环,推动着记忆系统的动态演化和运作。在记忆形成阶段提取的记忆会在记忆演化阶段与现有的记忆库进行整合和更新。利用通过前两个阶段构建的记忆库,记忆检索阶段能够实现有针对性的访问以优化推理。反过来,推理结果和环境反馈会反馈到记忆形成阶段以提取新的见解,并反馈到记忆演化阶段以完善记忆库。总体而言,这些组件使得大型语言模型能够从静态条件生成器转变为能够持续从变化的环境中学习并作出响应的动态系统。
记忆形成
我们将记忆形成定义为将原始上下文(例如,对话或图像)编码为紧凑知识的过程。由于处理冗长、嘈杂且高度冗余的原始上下文存在规模限制,因此需要进行记忆形成。全上下文提示经常遇到计算开销、禁止性的记忆占用以及在分布外输入长度上的推理性能下降等问题。为了缓解这些问题,最近的记忆系统将关键信息提炼成高效存储和精确检索的表示形式,从而实现更高效和有效的推理。
记忆形成与前面的部分不是独立的。根据任务类型的不同,记忆形成过程选择性地提取了3中描述的不同架构记忆,以实现的相应功能。基于信息压缩的粒度和编码逻辑,我们将记忆形成过程分为五种不同类型。表7总结了每种类别下的代表性方法,比较了它们的子类型、表示形式和关键机制。
五种记忆形成操作类别
- 语义摘要 将冗长的原始数据转换为紧凑的摘要,过滤掉冗余信息,同时保留全局、高层次的语义信息,以减少上下文开销。
- 知识蒸馏 提取特定的认知资产,范围从事实细节到经验规划策略。
- 结构化构建 将无定形的源数据组织成显式的拓扑表示形式,如知识图谱或层次树,以增强记忆的可解释性并支持多跳推理。
- 潜在表示 将原始经验直接编码为机器原生格式(例如,向量嵌入或KV状态),在一个连续的潜在空间内。
- 参数内化 通过参数更新将外部记忆直接整合到模型的权重空间中,有效地将可检索的信息转化为智能体的内在能力和本能。
尽管我们将这些方法分为五种类型,但我们认为这些记忆形成策略并不是互斥的。单一算法可以集成多种记忆形成策略,并在不同表示之间转换知识。
| Method | Sub-Type | Representation Form | Key Mechanism | |
|---|---|---|---|---|
| I. Semantic Summarization | ||||
| MemGPT | Incremental | Textual Summary | Merging new chunks into the working context | |
| Mem0 | Incremental | Textual Summary | LLM-driven summarization | |
| Mem1 | Incremental | Textual Summary | RL-optimized summarization (PPO) | |
| MemAgent | Incremental | Textual Summary | RL-optimized summarization (GRPO) | |
| MemoryBank | Partitioned | Textual Summary | Daily/Session-based segmentation | |
| ReadAgent | Partitioned | Textual Summary | Semantic clustering before summarization | |
| LightMem | Partitioned | Textual Summary | Topic-clustered summarization | |
| DeepSeek-OCR | Partitioned | Visual Token Mapping | Optical 2D mapping compression | |
| FDVS | Partitioned | Multimodal Summary | Multi-source signal integration (Subtitle/Object) | |
| LangRepo | Partitioned | Multimodal Summary | Hierarchical video clip aggregation | |
| II. Knowledge Distillation | ||||
| TiM | Factual | Textual Insight | Abstraction of dialogue into thoughts | |
| RMM | Factual | Topic Insight | Abstraction of dialogue into topic-based memory | |
| MemGuide | Factual | User Intent | Capturing high-level user intent | |
| M3-Agent | Factual | Text-addressable Facts | Compressing egocentric visual observations | |
| AWM | Experiential | Workflow Patterns | Workflow extraction from success trajectories | |
| Mem\(^p\) | Experiential | Procedural Knowledge | Distilling gold trajectories into abstract procedures | |
| ExpeL | Experiential | Experience Insight | Contrastive reflection and successful practices | |
| R2D2 | Experiential | Reflective Insight | Reflection on reasoning traces vs. ground truth | |
| \(H^{2}R\) | Experiential | Hierarchical Insight | Two-tier reflection (Plan \ | Subgoal) |
| Memory-R1 | Experiential | Textual Knowledge | RL-trained LLMExtract module | |
| Mem-\(\alpha\) | Experiential | Textual Insight | Learnable insight extraction policy | |
| III. Structured Construction | ||||
| KGT | Entity-Level | User Graph | Encoding user preferences as nodes/edges | |
| Mem0\(^g\) | Entity-Level | Knowledge Graph | LLM-based entity and triplet extraction | |
| D-SMART | Entity-Level | Dynamic Memory Graph | Constructing an OWL-compliant graph | |
| GraphRAG | Entity-Level | Hierarchical KG | Community detection and iterative summarization | |
| AriGraph | Entity-Level | Semantic+Episodic Graph | Dual-layer (Semantic nodes + Episodic links) | |
| Zep | Entity-Level | Temporal KG | 3-layer graph (Episodic, Semantic, Community) | |
| RAPTOR | Chunk-Level | Tree Structure | Recursive GMM clustering and summarization | |
| MemTree | Chunk-Level | Tree Structure | Bottom-up insertion and summary updates | |
| H-MEM | Chunk-Level | Hierarchical JSON | Top-down 4-level hierarchy organization | |
| A-MEM | Chunk-Level | Networked Notes | Discrete notes with semantic links | |
| PREMem | Chunk-Level | Reasoning Patterns | Cross-session reasoning pattern clustering | |
| CAM | Chunk-Level | Hierarchical Graph | Disentangling overlapping clusters via replication | |
| G-Memory | Chunk-Level | Hierarchical Graph | 3-tier graph (interaction, query, insight) | |
| IV. Latent Representation | ||||
| MemoryLLM | Textual | Latent Vector | Self-updatable latent embeddings | |
| M+ | Textual | Latent Vector | Cross-layer long-term memory tokens | |
| MemGen | Textual | Latent Token | Latent memory trigger and weaver | |
| ESR | Multimodal | Latent Vector | Video-to-Language-to-Vector encoding | |
| CoMEM | Multimodal | Continuous Embedding | Vision-language compression via Q-Former | |
| Mem2Ego | Multimodal | Multimodal Embedding | Embedding landmark semantics as latent memory | |
| KARMA | Multimodal | Multimodal Embedding | Hybrid long/short-term memory encoding | |
| V. Parametric Internalization | ||||
| MEND | Knowledge | Gradient Decomposition | Auxiliary network for fast edits | |
| ROME | Knowledge | Model Parameters | Causal tracing and rank-one update | |
| MEMIT | Knowledge | Model Parameters | Mass-editing via residual distribution | |
| CoLoR | Knowledge | LoRA Parameters | Low-rank adapter training | |
| ToolFormer | Capability | Model Parameters | Supervised fine-tuning on API calls |
表7:记忆形成方法的分类体系。我们根据记忆形成操作对现有方法进行分类。
这些方法从三个技术维度进行分析:
(1) 子类型(Sub-Type)标识具体的变体或适用范围,
(2) 表示形式(Representation Form)说明输出格式,
(3) 关键机制(Key Mechanism)指明核心算法策略。
语义摘要
语义摘要将原始观察数据转换为紧凑且语义丰富的摘要。生成的摘要捕捉了原始数据的整体、高层次信息,而不是具体的事实或经验细节。这类摘要的典型例子包括文档的整体叙述、任务的过程流程或用户的历史档案。通过过滤掉冗余内容并保留与任务相关的全局语义,语义摘要为后续推理提供了一个高层次的指导蓝图,而不会引入过多的上下文负担。为了实现这些效果,压缩过程可以通过两种主要方式实现:增量式和分区式语义摘要。
增量语义摘要
这种范式采用了一种时间整合机制,该机制不断将新观察到的信息与现有摘要融合,生成全球语义的演变表示。这种逐块处理的范式支持增量学习,避免了全序列处理的\(O(n^2)\)计算负担,并促进了向全球语义逐步收敛。早期实现如MemGPT和Mem0在适当的时候直接将新块与现有摘要合并,仅依赖于大语言模型(LLM)固有的摘要能力。然而,这种方法受到模型容量有限的限制,经常导致不一致或语义漂移。为了解决这些问题, 和 引入外部评估器来过滤冗余或不连贯的内容,分别使用基于卷积的判别器进行一致性验证以及DeBERTa过滤琐碎内容。后续方法如Mem1和MemAgent没有依赖辅助网络,而是通过PPO和GRPO强化学习增强了LLM自身的摘要能力。
随着增量摘要从启发式融合发展到过滤集成,最终到基于学习的优化,摘要能力逐渐内化于模型中,从而减少了迭代过程中的累积错误。尽管如此,串行更新的本质仍然存在计算瓶颈和潜在的信息遗忘问题,这推动了分区语义摘要方法的发展。
分区语义摘要
这种范式采用空间分解机制,将信息划分为不同的语义分区,并为每个分区生成单独的摘要。早期研究通常采用启发式分区策略来处理长上下文。MemoryBank 和 COMEDY 通过将每一天或会话视为基本单元来总结和聚合长期对话。在结构维度上, 和 通过将长文档分割成章节或段落来生成摘要的摘要。虽然直观,但这些方法往往存在跨分区的语义不连续性问题。为了解决这一问题,诸如 ReadAgent 和 LightMem 等方法在摘要之前引入了语义或主题聚类,从而增强了块间的一致性。超越文本压缩,DeepSeek-OCR 开创了通过光学二维映射压缩长上下文的想法,在多模态场景中实现了更高的压缩比。在视频记忆领域,FDVS 和 LangRepo 将长视频分割成片段,并通过整合字幕、目标检测和场景描述等多源信号生成文本摘要,然后分层聚合为全局长视频故事。
与增量摘要相比,分区方法提供了更高的效率并捕捉到更细粒度的语义。然而,其对每个子块的独立处理可能导致跨分区语义依赖性的丢失。
摘要
语义摘要作为一种有损压缩机制,旨在从冗长的交互日志中提取核心内容。与逐字存储不同,它更重视全局语义连贯性而非局部事实精确性,将线性的数据流转换为紧凑的叙述块。语义摘要的主要优势在于效率:它极大地缩短了上下文长度,使其非常适合长期对话。然而,这种做法的代价是分辨率损失:特定细节或细微提示可能会被平滑处理,从而限制了其在证据关键任务中的实用性。
知识蒸馏
虽然语义摘要在宏观层面上捕捉原始数据的全局语义,但知识蒸馏则以更细的粒度运行,从交互轨迹或文档中提取可重用的知识。广义上,知识指的是根据任务的基本功能所描述的各种形式的事实性和经验性记忆,如13所述。
事实记忆的提炼
这一过程侧重于将原始交互和文档转化为关于用户和环境状态的明确、陈述性知识。此过程通过保留可验证的事实而非瞬时上下文,确保智能体保持一致性和适应性。在用户建模领域,诸如 TiM 和 RMM 等系统采用抽象机制,将对话轮次转换为高层次的思想或基于主题的记忆,从而保持长期的人格一致性。对于用户的客观建模,如 MemGuide 方法从对话中提取用户意图描述。在推理过程中,它捕获并更新目标状态,将已确认的约束与未解决的意图区分开来,以减轻目标漂移。此外,这种提炼还扩展到多模态环境中,像 ESR 和 M3-Agent 等智能体将自我中心视角的视觉观察压缩成关于物体位置和用户日常活动的文本可寻址事实。
从经验记忆中提炼
这一过程专注于从历史轨迹中提取任务执行背后的策略。通过从成功的运行中推导出规划原则,并从失败中获得纠正信号,这种范式增强了智能体在特定任务上的问题解决能力。通过抽象和泛化,它进一步支持跨任务的知识转移。因此,经验泛化使智能体能够不断改进其能力并朝着终身学习迈进。
这项研究旨在从成功和失败的轨迹中提炼出高级规划策略和关键见解。一些方法侧重于基于成功的提炼,如AgentRR 和AWM 系统从成功案例中总结整体任务计划。Mem\(^p\) 分析并总结训练集中的黄金轨迹,将其提炼为抽象的过程知识。另一些方法采用以失败驱动的反思,例如Matrix、SAGE 和R2D2,这些方法将推理痕迹与真实答案进行比较以识别错误来源并提取反思性见解。结合两者,ExpeL 和《从经验到策略》通过对成功和失败经验的对比来揭示全面的规划见解。
然而,先前的工作主要集中在总结任务级别的规划知识上,缺乏细粒度、步骤级别的见解。为了解决这一差距,H\(^2\)R 引入了两层反思机制:它遵循ExpeL 构建一个高级规划见解池,同时进一步按子目标序列分割轨迹以得出逐步执行的见解。
早期的方法依赖于固定的提示来提取见解,这使得它们的性能对提示设计和底层大语言模型的能力非常敏感。最近,可训练的提炼方法变得流行起来。Learn-to-Memorize 优化了不同智能体的任务特定提示。另一方面,Memory-R1 使用LLMExtract 模块获取经验和事实知识,而只有后续的融合组件被训练以将这些输出整合到记忆库中。尽管这些方法采用了端到端框架,但它们仍然不足以增强大语言模型内在的提炼见解的能力。为了克服这一限制,Mem-\(\alpha\) 明确训练大语言模型关于要提取哪些见解以及如何保存这些见解。
摘要
这部分重点是从原始上下文中提取特定于功能的知识,而不涉及记忆存储的结构。每条知识可以被视为一个扁平的记忆单元。简单地将多个单元存储在无结构的表中忽略了它们之间的语义和层次关系。为了解决这个问题,记忆形成过程可以应用结构化规则来推导见解,并将它们存储在一个层次结构中。这里介绍的单一知识蒸馏方法虽然简单但至关重要,它是更复杂和结构化的记忆形成机制的基础组件。
结构化构建
虽然语义摘要和知识蒸馏在不同粒度级别上有效压缩摘要和知识,但它们通常将记忆视为孤立的单元。相比之下,结构化构建将无定形数据转化为有组织的拓扑表示。这一过程不仅仅是存储格式的变化,而是一种主动的结构操作,决定了信息如何链接和分层。与非结构化的纯文本摘要相比,结构化提取显著提高了可解释性和检索效率。关键的是,这种结构先验在捕捉多跳推理任务中的复杂逻辑和依赖关系方面表现出色,比传统的增强检索方法具有明显优势。
根据底层结构派生的操作粒度,我们将现有方法分为两类范式:实体级构建,通过将文本原子化为实体和关系来构建底层拓扑;块级构建,通过组织完整的文本段落或记忆项来构建结构。
实体级构建
该范式的基础结构源自关系三元组提取,它将原始上下文分解为其最细粒度的语义原子实体和关系。传统方法将记忆建模为平面知识图谱。例如,KGT 引入了一种实时个性化机制,其中用户偏好和反馈直接编码为特定用户知识图谱中的节点和边。同样,\(Mem0^{g}\) 利用大型语言模型在提取阶段将对话消息直接转换为实体和关系三元组。
然而,这些直接提取方法往往受限于大型语言模型的固有能力,导致潜在的噪声或结构错误。为了提高构建图的质量,D-SMART 采用了一种精炼的方法:首先利用大型语言模型将核心语义内容提炼成简洁、断言式的自然语言陈述,然后通过神经符号管道提取符合 OWL 标准的知识图谱片段。此外,Ret-LLM 对大型语言模型进行有监督微调,使其能够更稳健地与关系图进行读写交互。
尽管上述方法侧重于平面结构,但最近的进步已经朝着构建层次化记忆以捕捉高层次抽象的方向发展。例如,GraphRAG 从源文档中推导出实体知识图,并应用社区检测算法迭代地提取图社区并生成社区摘要。这种层次化方法识别了实体之间的更高层次的聚类关联,使得能够提取广义见解并促进在不同粒度下的灵活检索。
为了更好地反映原始数据的内部一致性和时间信息,一些工作通过引入情节图来扩展语义知识图。AriGraph 和 HippoRAG 建立了一个由语义图和情节图组成的双层结构。它们从对话中提取语义三元组,同时连接同时出现的节点或建立节点-段落索引。Zep 进一步将其形式化为三层时间图架构:一个情节子图(\(\mathcal{G}_{e}\)),通过双时间模型记录原始消息的发生和处理时间;一个语义子图(\(\mathcal{G}_{s}\))用于实体和时间限定的事实;以及一个社区子图(\(\mathcal{G}_{c}\))用于实体的高层次聚类和摘要。
块级构建
这一范式将连续的文本片段或离散的记忆项视为节点,在保持局部语义完整性的同时将其组织成拓扑结构。该领域的演变从固定语料库中的静态、平面(2D)提取发展到对传入轨迹的动态适应,最终形成了层次(3D)架构。
早期的方法侧重于将固定的文本库组织成静态平面结构。HAT 通过分割长文本并逐步汇总摘要来构建层次树。同样地,RAPTOR 使用 UMAP 进行降维和高斯混合模型进行软聚类,递归地聚类文本块,并迭代地总结这些聚类以形成一棵树。然而,这些静态方法缺乏处理流数据的灵活性,而无需昂贵的重建。
为了解决这个问题,动态平面方法在新轨迹到达时增量地构建记忆结构,根据其基础元素的不同而有所不同。基于原始文本的方法包括 MemTree 和 H-MEM。MemTree 采用自下而上的方法,新的文本片段检索最相似的节点并作为子节点插入或迭代地插入到一个子树中,触发所有父节点的自下而上摘要更新。相反,H-MEM 利用自上而下的策略,促使 LLM 将数据组织成由领域、类别、记忆轨迹和事件层组成的四层 JSON 层次结构。另一方面,A-MEM 和 PREMem 专注于重新组织提取的记忆项。A-MEM 将知识总结成离散的笔记,并链接相关笔记以构建网络化记忆。PREMem 对提取的事实性、体验性和主观性记忆进行聚类,以识别和存储跨会话的高维推理模式。
最近的进步超越了平面布局,构建了层次结构,提供了更丰富的语义深度。SGMem 通过使用 NLTK 将文本分割成句子,形成跨越所有句子节点的 KNN 图,并随后调用 LLM 来提取每个对话对应的摘要、事实和见解,从而构建层次结构。为了支持流数据到达时层次结构的增量构建,CAM 根据语义相关性和叙述连贯性在文本块之间建立边。它迭代地总结自我图,并通过节点复制显式地解耦重叠聚类来处理新的记忆插入。在多智能体场景中,G-memory 通过维护三个不同的图扩展了这种动态 3D 方法:用于原始聊天历史的交互图、用于特定任务的查询图和洞察图。这种结构使每个智能体能够在不同粒度级别上接收定制的记忆。
摘要
结构化构建的主要优势在于可解释性和处理复杂关系查询的能力。这些方法能够捕捉记忆元素之间错综复杂的语义和层次关系,支持对多步依赖关系的推理,并便于与符号或基于图的推理框架集成。然而,缺点是模式僵化:预定义的结构可能无法表示细微或模糊的信息,且提取和维护成本通常较高。
潜在表示
前几章重点介绍了如何构建词元级别的记忆;本部分则关注将记忆编码到机器的原生潜在表示中。潜在表示将原始经验编码为嵌入,这些嵌入存在于潜在空间中。与语义压缩和结构化提取不同,后者在将经验嵌入向量之前先进行总结,潜在编码本质上将经验存储在潜在空间中,从而减少了在总结和文本嵌入过程中的信息损失。此外,潜在编码更有利于机器认知,能够实现跨不同模态的统一表示,并确保记忆表示的密度和语义丰富性。
文本潜在表示
尽管最初设计是为了加速推理,但KV缓存也可以被视为一种记忆上下文中的潜在表示形式。它利用额外的记忆来存储过去的信息,从而避免了冗余计算。MEMORYLLM和M+将记忆表示为自更新的潜在嵌入,在推理过程中将其注入到变压器层中。此外,MemGen引入了一个记忆触发器来监控智能体的推理状态,并确定何时明确调用记忆,以及一个记忆豁免,该豁免利用智能体的当前状态来构建潜在的令牌序列。这个序列作为机器原生记忆,丰富了智能体的推理能力。
多模态潜在表示
在多模态记忆研究中,CoMEM 通过 Q-Former 将视觉-语言输入压缩为固定长度的标记,从而实现密集、连续的记忆,并支持无限上下文长度的即插即用。Encode-Store-Retrieve 使用 Ego-LLaVA 将第一人称视角视频帧转换为语言编码,随后通过嵌入模型将其转换为向量表示。尽管嵌入模型用于确保语义对齐,但这些方法通常面临压缩损失和计算开销之间的权衡,特别是在处理长上下文序列中的梯度流时。
当与具身人工智能结合时,多模态潜在记忆可以融合来自多个传感器的数据。例如,Mem2Ego 动态地将全局上下文信息与局部感知对齐,将地标语义嵌入为潜在记忆,以增强长距离任务中的空间推理和决策能力。KARMA 采用混合长期和短期记忆形式,将对象信息编码为多模态嵌入,实现了即时响应和一致表示之间的平衡。这些探索强调了潜在编码在提供跨模态统一且语义丰富的表示方面的优势。
摘要
潜在表示绕过了人类可读的格式,将经验直接编码为机器原生的向量或KV缓存。这种高密度格式保留了丰富的语义信号,这些信号在文本解码过程中可能会丢失,从而能够更平滑地与模型的内部计算集成,并且无缝支持多模态对齐。然而,它存在不透明性的问题。潜在记忆是一个黑箱,使得人类难以调试、编辑或验证其中存储的知识。
参数化内化
随着大型语言模型越来越多地整合记忆系统以支持长期适应,一个核心的研究问题是这些外部记忆应该如何被整合为参数形式。虽然上述讨论的潜在表示方法将记忆在模型外部参数化,但参数化内化直接调整模型的内部参数。它利用模型通过其学习到的参数空间来编码和泛化信息的能力。这一范式从根本上增强了模型的内在能力,消除了外部存储和检索的开销,同时无缝支持持续更新。正如我们在13中所讨论的,并非所有的记忆内容都具有相同的功能:一些条目提供陈述性知识,而其他条目则编码影响智能体推理和行为的过程策略。这种区分促使我们对记忆内化有一个更细致的看法,将其分为知识内化和能力内化。
知识内化
该策略涉及将外部存储的事实性记忆,如概念定义或领域知识,转换为模型的参数空间。通过这一过程,模型可以直接回忆和利用这些事实,而无需依赖显式检索或外部记忆模块。在实践中,知识内化通常通过模型编辑实现。早期工作,如MEND,引入了一个辅助网络,通过分解微调梯度实现快速、单步编辑,从而最小化对无关知识的干扰。在此基础上,ROME通过使用因果追踪精确定位存储特定事实的多层感知机层,并应用秩一更新来更精确地注入新信息并提高泛化能力,从而改进了编辑过程。MEMIT进一步推进了这一方向,支持批量编辑,通过多层残差分布和批量公式同时更新数千个事实,大大提高了可扩展性。随着LoRA等参数高效范式的兴起,知识内化可以通过轻量级适配器而不是直接修改参数来实现。例如,CoLoR冻结预训练的Transformer参数,仅训练小型LoRA适配器以内部化新知识,避免了全参数微调的高昂成本。尽管取得了这些进展,这些方法仍可能产生非目标效应,并在持续学习场景中容易出现灾难性遗忘。
能力内化
该策略旨在将经验性知识,如程序性专长或战略启发式方法,嵌入到模型的参数空间中。这种范式在广义上代表了一种记忆形成操作,从获取事实性知识转向内化经验能力。具体来说,这些能力包括特定领域的解决方案模式、战略规划以及有效运用智能体技能等。技术上,通过从推理痕迹中学习,采用监督微调或偏好导向的优化方法(如DPO和GRPO)来实现能力内化。由于这一方面不属于典型的智能体记忆研究范围,因此本节不会详细讨论。
摘要
参数化内化代表了记忆的最终整合,其中外部知识通过梯度融合到模型的权重中。这将范式从检索信息转变为拥有能力,模仿生物长期增强效应。随着知识变得实际上成为本能,访问延迟为零,使模型能够立即响应而无需查询外部存储。然而,这种方法面临几个挑战,包括灾难性遗忘和高昂的更新成本。与外部存储不同,参数化内化难以精确修改或移除而不产生意外副作用,从而限制了灵活性和适应性。
记忆演化
在上一节中介绍的记忆形成从原始数据中提取记忆。接下来的重要步骤是将新提取的记忆与现有的记忆库整合,使记忆系统能够动态演化。一个简单的策略是将新条目简单地添加到现有的记忆库中。然而,这种方法忽略了记忆条目之间的语义依赖性和潜在矛盾,并忽视了信息的时间有效性。为了解决这些限制,我们引入了记忆演化机制。该机制整合新旧记忆以合成高层次的见解,解决逻辑冲突,并剔除过时的数据。通过确保长期知识的紧凑性、一致性和相关性,这种方法使记忆系统能够随着环境和任务的变化调整其认知过程和上下文理解。
基于记忆演化的目标,我们将它分为以下几种机制:
- 记忆巩固合并新旧记忆并进行反思性整合,形成更普遍的见解。这确保了学习是累积的而不是孤立的。
- 记忆更新解决新旧记忆之间的冲突,纠正并补充存储库以保持准确性和相关性。它允许智能体适应环境或任务要求的变化。
- 记忆遗忘移除过时或冗余的信息,释放容量并提高效率。这防止了由于知识过载而导致性能下降,并确保记忆库专注于可操作且当前的知识。
这些机制共同维护了记忆库的泛化能力、准确性和时效性。通过积极管理记忆演化,这些机制强调了记忆系统的自主能力,促进了持续学习和自我改进。
图9提供了对这些记忆演化机制的统一视角,展示了它们在共享记忆数据库中的操作角色和代表性框架。

图9:记忆演化机制全景图。我们将演化过程划分为三条不同的分支,它们共同维护中心的记忆数据库: (a) 巩固:通过本地巩固、集群融合与全局整合,对原始材料进行处理并综合形成洞见; (b) 更新:通过对外部数据库执行冲突消解,并对内部模型进行参数更新,以保证准确性与一致性; (c) 遗忘:依据特定准则对数据进行剪枝以优化效率,包括时间过期、访问频率低与信息价值低。 外环展示了与各类演化机制相关的代表性框架与智能体。
整合
记忆整合旨在将新获得的短期痕迹转化为结构化和可泛化的长期知识。其核心机制是识别新旧记忆之间的语义关系,并将它们整合到更高层次的抽象或见解中。这一过程服务于两个主要目的。首先,它将碎片化的信息重组为连贯的结构,防止在短期保持过程中丢失关键细节,并促进稳定的知识模式的形成。其次,通过抽象、压缩和泛化经验数据,整合从特定事件中提取出可重用的模式,产生支持跨任务泛化的见解。
一个核心挑战在于确定新记忆应以何种粒度与现有记忆相匹配和合并。先前的工作涵盖了从局部内容合并到集群级融合以及全局整合等多种整合策略。
本地整合
此操作专注于涉及高度相似记忆片段的细粒度更新。在 RMM 中,每个新的主题记忆检索其最相似的前 K 个候选者,并由 LLM 决定是否合并,从而降低错误泛化的风险。在多模态设置下,当容量达到饱和时,VLN 触发一个池化机制。它识别出最相似或冗余的记忆对,并将它们压缩成更高级别的抽象。这些方法在保持记忆存储全局结构的同时细化了详细知识,提高了精度和存储效率。然而,它们无法完全捕捉到集群级别的关系或语义相关记忆中出现的更高阶依赖性。
集群级融合
采用集群级融合对于在记忆增长时捕捉跨实例规律至关重要。在不同集群之间,PREMem 将新的记忆集群与相似的现有集群对齐,并应用诸如泛化和细化等融合模式来形成更高阶的推理单元,从而显著提高可解释性和推理深度。在集群内部,TiM 定期调用一个大型语言模型来检查共享相同哈希桶的记忆,并合并语义上冗余的条目。CAM 将目标集群内的所有节点合并成一个代表性摘要,产生更高级别且一致的跨样本表示。这些方法以更广泛的规模重新组织了记忆结构,标志着向结构化知识迈进的重要一步。
全局整合
此操作执行整体整合,以保持全局一致性,并从积累的经验中提炼系统级的见解。语义总结侧重于从现有上下文中推导出全局摘要,可以视为摘要的初步构建。相比之下,本段强调如何将新信息整合到现有的摘要中,作为额外数据到达时的处理方式。对于用户事实记忆,MOOM 通过基于规则的处理、嵌入方法和LLM驱动的抽象,将临时角色快照与历史痕迹相结合,构建稳定的角轮廓。对于体验记忆,Matrix 通过迭代优化将执行轨迹和反思性见解与全局记忆结合,提炼出支持跨场景重用的任务无关原则。随着单步推理上下文和环境反馈的延长,像AgentFold 和Context Folding 这样的方法内化了压缩工作记忆的能力。在多步交互中,包括网页导航,这些方法在每一步后自动总结和浓缩全局上下文,支持高效且有效的推理。全局整合从完整的经验历史中整合高层、结构化的知识,提供可靠的上下文基础,同时提高泛化能力、推理准确性和个性化决策。
摘要
整合是将零碎的短期痕迹重组为连贯的长期图式的认知过程。它不仅限于简单的存储,还合成了孤立条目之间的联系,形成了结构化的世界观。它增强了泛化能力并减少了存储冗余。然而,它也存在信息平滑的风险,在抽象过程中可能会丢失异常事件或独特例外,从而可能降低智能体对异常和特定事件的敏感性。
更新
记忆更新指的是当出现冲突或获取新信息时,智能体修订或替换其现有记忆的过程。其目标是在不完全重新训练模型的情况下保持事实一致性并持续适应。与记忆巩固不同,记忆巩固侧重于抽象和泛化,而记忆更新则强调局部修正和同步,使智能体能够与不断变化的环境保持一致。
通过持续更新,智能体记忆系统可以保持知识的准确性和时效性,防止过时信息对推理造成偏差。因此,它是实现终身学习和自我进化的核心机制。根据记忆存储的位置,更新分为两类:(1) 外部记忆更新:对外部记忆存储进行更新;(2) 模型编辑:在参数空间内对模型内部进行编辑。
外部存储更新
向量数据库或知识图谱中的条目在出现矛盾或新事实时会进行修订。这种方法通过对外部存储的动态修改来保持事实一致性,而不是改变模型权重。静态记忆不可避免地会积累陈旧或冲突的条目,导致逻辑不一致和推理错误。更新外部记忆可以实现轻量级修正,同时避免了完全重新训练或重新索引的成本。
外部存储更新机制的发展沿着一条轨迹前进,从基于规则的校正到具有时间意识的软删除,再到延迟一致性策略,最终发展为完全学习的更新策略。早期系统如 MemGPT、D-SMART 和 Mem0\(^g\) 采用了一种简单的流程,即 LLM 检测新信息与现有信息之间的冲突,并调用替换或删除操作来更新记忆。虽然这些系统对于基本的事实修复是有效的,但它们依赖于破坏性替换,抹去了有价值的历史背景并打破了时间连续性。为了解决这个问题,Zep 引入了时间注释,将冲突的事实标记为无效的时间戳而不是删除它们,从而保留了语义一致性和时间完整性。这标志着从硬替换到软的、具有时间意识的更新的转变。然而,实时更新在高频交互下会带来显著的计算和 I/O 负担。因此,MOOM 和 LightMem 引入了双阶段更新:一个用于实时响应的软在线更新,随后是一个离线反思整合阶段,在该阶段中,类似的条目被合并并通过 LLM 推理解决冲突。这种最终一致性范式平衡了延迟和一致性。随着智能体强化学习的成熟,通过强化学习增强 LLM 的内在记忆更新决策成为可能。Mem-\(\alpha\) 将记忆更新表述为一个策略学习问题,使 LLM 能够学习何时、如何以及是否进行更新,从而实现在稳定性和新鲜度之间的动态权衡。
总体而言,外部存储更新已经从手动触发的校正转变为自我调节的、具有时间意识的学习过程,通过 LLM 驱动的检索、冲突检测和修订来保持事实一致性和结构稳定性。
模型编辑
模型编辑通过直接在模型的参数空间内进行修改,以纠正或注入知识而无需完全重新训练,代表了隐式知识更新。重新训练成本高昂且容易导致灾难性遗忘。模型编辑能够实现精确、低成本的修正,从而提高适应性和内部知识保留。
模型编辑的方法主要分为两类。(1) 显式定位与修改:ROME 通过梯度追踪识别编码特定知识的参数区域,并执行有针对性的权重更新;模型编辑网络 训练一个辅助的元编辑网络来预测最佳参数调整。(2) 隐空间自我更新:MEMORYLLM 在Transformer层中嵌入一个记忆池,定期替换记忆令牌以整合新知识;M+ 维护双层记忆,丢弃过时的短期条目并将关键信息压缩到长期存储中。
混合方法如ChemAgent 进一步结合外部记忆更新与内部模型编辑,同步事实和表示的变化,以便快速跨领域适应。
摘要
从实现的角度来看,记忆更新侧重于解决由新记忆触发的冲突和知识修订,而记忆巩固则强调新旧知识的整合与抽象。上述讨论的两种记忆更新策略建立了一种双路径机制,涉及外部数据库中的冲突解决和模型内部的参数编辑,使智能体能够进行持续的自我纠正并支持长期演化。关键挑战是稳定性-可塑性困境:即何时覆盖现有知识与何时将新信息视为噪声。错误的更新可能会覆盖关键信息,导致知识退化和错误推理。
遗忘
记忆遗忘指的是有意去除过时、冗余或低价值的信息,以释放容量并保持对重要知识的关注。与解决记忆之间冲突的更新机制不同,遗忘优先考虑消除过时信息,以确保效率和相关性。随着时间推移,无限制的记忆积累会导致噪音增加、检索延迟以及来自过时知识的干扰。受控遗忘有助于减轻过载并维持认知焦点。然而,过度激进的修剪可能会抹去罕见但重要的知识,从而在长期情境下损害推理的连续性。
遗忘机制可以分为基于时间的遗忘、基于频率的遗忘和基于重要性的遗忘,分别对应于创建时间、检索活动和综合语义评估。
基于时间的遗忘
时间驱动的遗忘仅考虑记忆的创建时间,随着时间推移逐渐减弱其强度以模拟人类记忆的衰退。MemGPT 在上下文溢出时会移除最早的消息。采用随机标记替换方法,替换比例为 K/N,以模拟人类认知中的指数型遗忘,在池容量超过限制时丢弃最旧的条目。与显式删除旧记忆不同,MAICC 通过随着时间逐渐衰减记忆权重来实现软性遗忘。这一过程反映了自然遗忘的过程,确保了持续适应而不会造成历史负担。
基于频率的遗忘
基于频率驱动的遗忘机制根据检索行为来优先处理记忆,保留频繁访问的条目同时丢弃不活跃的条目。XMem 采用LFU策略移除低频条目;KARMA 使用计数布隆过滤器跟踪访问频率;MemOS 应用LRU策略,移除长时间未使用的项目,同时归档高度活跃的项目。这确保了高效的检索和存储平衡。
通过区分创建时间和检索频率,这两个维度形成了一个更正交的分类体系:基于时间的衰减捕捉自然的时间老化过程,而基于频率的遗忘反映了使用动态,共同维护系统效率和最新性。
重要性驱动的遗忘
重要性驱动的遗忘整合了时间、频率和语义信号,以保留高价值的知识并剪枝冗余信息。早期工作如 和 通过结合时间衰减和访问频率的复合分数来量化重要性,实现了基于数值的选择性遗忘。后来的方法逐渐向语义层面评估发展:VLN 通过相似度聚类汇集语义冗余的记忆,而 Livia 则结合情感显著性和上下文相关性来建模情感驱动的选择性遗忘。随着大型语言模型(LLM)判断能力的日益增强,TiM 和 MemTool 利用 LLM 来评估记忆的重要性,并明确地剪枝或遗忘不那么重要的记忆。
这种转变反映了从静态数值评分到语义智能的过渡。现在,智能体可以有意识地遗忘,并选择性地保留与任务上下文、语义和情感线索最相关的记忆。
概要
基于时间的衰减反映了记忆随时间自然淡化的现象,基于频率的遗忘确保了对常用记忆的有效访问,而基于重要性的遗忘则引入了语义上的辨别。这三种遗忘机制共同决定了智能体记忆如何保持时效性、高效可访问性和语义相关性。然而,像LRU这样的启发式遗忘机制可能会消除长尾知识,这些知识虽然很少被访问,但对于正确的决策制定却是必不可少的。因此,在存储成本不是关键限制的情况下,许多记忆系统会避免直接删除某些记忆。
记忆检索
我们将记忆检索定义为从特定记忆存储库中检索相关且简洁的知识片段以支持当前推理任务的过程。主要挑战在于如何在大规模记忆存储中高效准确地定位所需的知识片段。为此,许多算法采用启发式策略或可学习模型来优化检索过程的各个阶段。根据检索的执行顺序,此过程可以分解为四个方面。
图10提供了这一检索流程的结构化概述,按照它们在检索阶段中的作用组织现有方法。
图10:智能体系统中记忆检索方法的分类体系。 该思维导图将现有文献组织为检索流水线中的四个不同阶段:检索时机与意图(决定何时启动检索过程);查询构建(涵盖查询分解与查询重写等技术);检索策略(将检索范式划分为词汇检索、语义检索、图检索与混合检索);以及检索后处理(通过重排序、过滤与聚合来精炼检索输出)。
四个记忆检索步骤
- 检索时机与意图 确定了记忆检索的具体时刻和目标,从被动的指令驱动触发转变为自主的自我调节决策。
- 查询构建 通过将查询分解或重写成有效的检索信号,弥合用户原始输入与存储记忆索引之间的语义差距。
- 检索策略 在记忆库上执行搜索,采用从稀疏词汇匹配到密集语义嵌入以及结构感知图遍历的各种范式。
- 检索后处理 通过对检索到的原始片段进行重新排序、过滤和聚合,确保提供给模型的最终上下文是简洁且连贯的。
总体而言,这些机制将记忆检索从静态搜索操作转变为动态认知过程。检索时机与意图决定了何时何地进行检索。接下来,查询构建指定了要检索什么,而检索策略则关注如何执行检索。最后,检索后处理决定如何整合和使用检索到的信息。一个强大的智能体系统通常会在统一的管道内协调这些组件,使智能体能够接近人类般的联想记忆激活,以实现高效的知识访问。
检索时机与意图
检索意图和时机决定了何时触发检索机制以及查询哪个记忆存储。现有的记忆系统在这方面采用了不同的设计方案,从始终开启的检索到由显式指令或内部信号触发的检索不等。例如,MIRIX 对每个查询都从六个记忆数据库中进行检索并将检索到的内容连接起来,这反映了优先考虑全面记忆访问的设计。其他方法则旨在更选择性地触发检索,允许模型决定记忆访问的时间和范围,从而实现更有针对性和高效的记忆资源使用。在本小节中,我们将从两个互补的角度回顾文献:自动检索时机和自动检索意图。
自动检索时机
这个术语指的是模型在推理过程中自主决定何时触发记忆检索操作的能力。最简单的策略是将决策委托给大语言模型(LLM)或外部控制器,使其仅根据查询来判断是否需要进行检索。例如,MemGPT 和 MemTool 允许 LLM 本身调用检索功能,在类似操作系统框架中高效访问外部记忆。然而,这些方法仅依赖于对查询的静态判断,忽略了模型在推理过程中动态演变的认知状态。
为了解决这一局限性,最近的研究将快慢思考机制整合到检索时序中。例如,ComoRAG 和 PRIME 首先生成快速响应,然后让智能体评估其充分性。如果初始推理被认为不足,系统会根据失败反馈触发更深层次的检索和推理。MemGen 进一步改进了触发机制,将显式的智能体级决策转化为潜在的、可训练的过程。它引入了记忆触发器,从潜在的展开状态中检测关键的检索时刻,从而提高了检索时序的精确性,同时保持端到端的可微分性。
自动检索意图
这一方面关注模型自主决定在分层存储形式中访问哪个记忆源的能力。例如,AgentRR 根据环境反馈动态地在低级过程模板和高级体验抽象之间切换。然而,它对显式反馈的依赖限制了其在开放式推理设置中的适用性。
为了克服这一限制,MemOS 采用了一种 MemScheduler,该调度器根据用户、任务或组织级别的上下文动态选择参数化、激活或纯文本记忆。然而,这种扁平的选择方案忽略了记忆系统的层次结构。H-MEM 通过引入基于索引的路由机制解决了这个问题,该机制执行从粗到细的检索,从领域层移动到事件层,并逐渐缩小搜索空间至最相关的子记忆。这种层次路由不仅提高了检索精度,还缓解了信息过载问题。
摘要
自主时间和意图有助于减少计算开销并抑制不必要的噪声,但同时也可能产生潜在的漏洞。当智能体高估其内部知识并在需要时未能启动检索时,系统可能会陷入一种静默故障模式,在这种模式下,知识缺口可能导致虚幻的输出。因此,需要达到一个平衡:在适当的时候向智能体提供必要的信息,同时避免过多的检索引入噪声。
查询构建
在启动检索过程后,接下来的挑战在于将原始查询转换为与记忆索引对齐的有效检索信号。查询构建充当用户表面表达与记忆潜在存储之间的翻译层。传统方法通常直接基于用户查询进行检索,这种方法简单但无法使查询语义与记忆索引的语义对齐。为了弥合这一差距,智能体记忆系统主动执行查询分解或查询重写,生成更好地匹配记忆潜在结构的中间检索信号。
查询分解
该方法将复杂查询分解为更简单的子查询,使系统能够检索到更细粒度和相关的信息。这种分解通过实现模块化检索和对中间结果的推理,缓解了一次性检索瓶颈。例如,Visconde 和 ChemAgent 使用大语言模型将原始问题分解为子问题,从记忆中检索每个子问题的候选结果,并最终将它们聚合为一个连贯的答案。然而,这些方法缺乏全局规划。为了解决这个问题,PRIME 和 MA-RAG 引入了一个受ReAct范式启发的规划智能体,该智能体首先制定全局检索计划,然后将其分解为子查询。然而,这些方法主要依赖于问题驱动的分解,因此不能明确识别模型缺少的具体知识。为了使子查询更具针对性,Agent KB 采用两阶段检索过程,其中教师模型观察学生模型的失败并相应地生成细粒度的子查询。这种有针对性的分解提高了检索精度并减少了无关结果,特别是在知识密集型任务中。
查询重写
与分解策略不同,这种策略通过重写原始查询或生成一个假设文档来在检索前细化其语义。这种重写可以缓解用户意图与记忆索引之间的不匹配。例如,HyDE 指示大语言模型以零样本方式生成一个假设文档,并使用其语义嵌入进行检索。生成的文档封装了所需的语义,有效地弥合了用户查询与目标记忆之间的差距。MemoRAG 通过将全局记忆纳入假设文档生成中扩展了这一思想。它首先压缩全局记忆,然后根据查询和压缩后的记忆生成一个草稿答案;这个草稿随后被用作重写后的查询。由于草稿能够访问全局记忆上下文,因此更忠实地捕捉用户意图并揭示隐含的信息需求。类似地,MemGuide 利用对话上下文提示大语言模型生成一个简洁的、命令式的短语,作为检索的高层次意图描述。除了直接提示大语言模型重写查询外,Rewrite-Retrieve-Read 通过强化学习训练一个小的语言模型作为专用的重写器,而 ToC 则采用澄清树逐步细化和明确用户的检索目标。
摘要
这两种范式,即分解和重写,并非互斥。Auto-RAG 通过在相同的检索条件下评估 HyDE 和 Visconde,然后选择对给定任务表现最佳的策略来整合两者。本研究的结果表明,记忆检索查询的质量对推理性能有显著影响。与早期主要关注设计复杂记忆架构的研究不同,近期的研究越来越重视检索构建过程,将记忆的作用转向服务于检索。不出所料,选择什么进行检索是这一过程中的关键组成部分。
检索策略
在明确检索目标后,我们得到了一个具有明确定义意图的查询。接下来的核心挑战在于如何利用这个查询从庞大且复杂的记忆库中高效准确地检索出真正相关的知识。检索策略作为查询与记忆库之间的桥梁,其设计直接决定了检索效率和结果质量。在本节中,我们将系统性地回顾各种检索范式,并分析它们的优势、局限性和应用场景——从基于关键词匹配的传统稀疏检索,到使用语义嵌入的现代密集检索,再到面向结构化知识的图检索,以及新兴的生成式检索方法,最后是集成多种范式的混合检索技术。
词汇检索
该策略依赖于关键词匹配来定位相关文档,代表性方法包括TF-IDF和BM25。TF-IDF基于词频和逆文档频率衡量关键词的重要性,实现了快速且可解释的检索。BM25通过引入词频饱和和文档长度归一化进一步改进了这一方法。这些方法常用于注重精度的检索场景中,其中结果的准确性和相关性优先于召回率。然而,纯粹的词汇匹配难以捕捉语义变化和上下文关系,使其对语言表达差异非常敏感,因此在开放领域知识或多模态记忆设置中效果较差。
语义检索
该策略将查询和记忆条目编码到一个共享的嵌入空间中,并基于语义相似性而不是词汇重叠进行匹配。代表性方法利用语义编码器,包括Sentence-BERT和CLIP。在记忆系统中,这种方法更好地捕捉任务上下文并支持语义泛化和模糊匹配,使其成为大多数智能体记忆框架中的默认选择。然而,语义漂移和强制的Top-K检索通常会引入检索噪声和虚假回忆。为了解决这些问题,最近的系统结合了动态检索策略、重新排序模块和混合检索方案。
图检索
该策略不仅利用语义信号,还利用图的显式拓扑结构,从而实现更精确和结构感知的检索。通过直接访问结构路径,这些方法表现出更强的多跳推理能力,并能更有效地探索长距离依赖关系。此外,将关系结构视为对推理路径的约束自然支持由精确规则和符号约束指导的检索。代表性方法如AriGraph、EMG-RAG、Mem0\(^g\)和SGMem首先识别最相关的节点或三元组,然后扩展到它们语义相关的K跳邻居以构建自我图。HippoRAG在检索到的节点上执行个性化PageRank,并根据这些种子节点的距离对图中的其余部分进行排名,从而实现有效的多跳检索。超越固定的扩展规则,CAM和D-SMART使用大语言模型来引导子图探索:CAM使用大语言模型选择中心节点的信息邻居和子节点进行关联探索,而D-SMART将大语言模型视为规划器,在知识图记忆中对目标实体的一跳邻居及其连接给定实体对的关系进行束搜索。对于时序图,Zep和MemoTime进一步在明确的时间约束下实现实体子图构建和关系检索,确保返回的结果满足所需的时间规则。
生成式检索
这种策略用直接生成相关文档标识符的模型替代词典或语义检索。通过将检索视为条件生成任务,该模型在参数中隐式存储候选文档,并在解码过程中执行深度查询-文档交互。利用预训练语言模型的语义能力,这一范式通常优于传统检索方法,特别是在小规模设置下。
然而,生成式检索需要额外的训练以内部化所有候选文档的语义,当语料库演变时会导致可扩展性有限。因此,尽管其生成和检索紧密结合表明了未开发的潜力,但智能体记忆系统对此范式的关注相对较少。
混合检索
这种策略结合了多种检索范式的优点。例如,Agent KB 和 MIRIX 系统结合了词汇和语义检索,在精确术语或工具匹配与更广泛的语义对齐之间取得平衡。类似地,语义锚定通过在语义嵌入和符号倒排索引上并行搜索来实现互补覆盖。其他一些方法则结合了多个评估信号以指导检索。例如,生成智能体通过一个评分方案展示了这种多因素方法,该方案累积了最近性、重要性和相关性。MAICC 采用了一种混合效用评分函数,将相似性与全局和预测的个体回报相结合。在基于图的设置中,检索通常分两个阶段进行:首先通过语义检索识别相关节点或三元组,然后利用图拓扑扩展搜索空间。
在数据库基础设施层面,MemoriesDB 引入了一个针对长期智能体记忆设计的时间-语义-关系数据库,提供了一种将这些维度集成到统一存储和访问框架中的混合检索架构。
通过融合异构检索信号,混合方法保持了关键词匹配的精确度,同时融入了语义方法的上下文理解能力,最终产生更全面且相关的结果。
检索后处理
初始检索往往返回冗余、噪声或语义不一致的片段。直接将这些结果注入提示中会导致上下文过长、信息冲突以及被无关内容分散注意力。因此,检索后处理对于确保提示质量至关重要。其目标是将检索到的结果提炼成简洁、准确且语义连贯的上下文。在实践中,两个核心组件包括:
(1) 重排序和过滤:进行细粒度的相关性估计,以移除无关或过时的记忆,并重新排列剩余的片段,从而减少噪声和冗余。
(2) 聚合和压缩:将检索到的记忆与原始查询整合,消除重复,合并语义相似的信息,并重构紧凑且连贯的最终上下文。
重排序和过滤
为了保持简洁连贯的上下文,初始检索结果会通过移除低相关性条目来进行重排序和过滤。早期的方法依赖于启发式标准来评估语义一致性。例如,语义锚定(Semantic Anchoring)结合了向量相似性和实体及话语层面的一致性,而RCR-Router则结合了多个手工设计的信号,包括角色相关性、任务阶段优先级和最近性。然而,这些方法通常需要大量的超参数调整以平衡异构的重要性分数。为减轻这一负担,学习记忆(learn-to-memorize)将分数聚合表述为一个强化学习问题,使模型能够学习检索信号的最佳权重。尽管这些技术主要优化了语义连贯性,但在需要严格时间推理的情况下,还需要额外的约束。
随着大语言模型(LLMs)能力的增强,最近的方法利用其内在的语言理解能力直接评估记忆质量。Memory-R1 和 都引入了基于大语言模型的评估器(答案智能体或自验证智能体),在生成最终响应之前过滤检索内容。然而,基于提示的过滤仍然受限于大语言模型的固有能力以及提示语义与下游使用之间的不匹配。因此,许多系统训练辅助模型来更稳健地估计记忆重要性。Memento 使用Q学习来预测检索项对正确答案贡献的概率,而MemGuide 则微调了LLaMA-8B,使用边际槽位完成增益来重新排序候选者。总的来说,这些重排序和过滤策略可以在不修改底层检索器的情况下精炼检索结果,从而支持与任何预训练检索模型兼容的同时进行特定任务的优化。
聚合与压缩
另一种通过检索后处理来提高下游推理质量和效率的方法是聚合与压缩。该过程将检索到的证据与查询结合起来,形成连贯且紧凑的上下文。与过滤和重新排序主要解决噪声和优先级问题不同,这一阶段侧重于将多个碎片化的记忆项合并成更高级别的精炼知识表示,并在需要特定任务适应时对这些表示进行细化。ComoRAG 通过其集成智能体展示了这一理念,该智能体识别与查询语义对齐的历史信号,并将其组合成一个抽象的全局摘要,提供广泛的上下文基础。MA-RAG 中的提取智能体对检索到的文档执行细粒度的内容选择,仅保留与当前子查询强相关的键信息,并生成符合局部推理需求的简洁片段。
此外,G-Memory 将聚合与压缩扩展到多智能体系统的个性化中。它整合了检索到的高级见解和稀疏化轨迹,然后使用大型语言模型根据智能体的角色定制这些浓缩的经验。这一过程将通用知识提炼为角色特定的提示,填充智能体的个性化记忆。
总结
总之,检索后处理作为关键的中间步骤,将嘈杂且碎片化的检索结果转化为精确且连贯的推理上下文。通过上述机制,检索后处理不仅提高了提供给模型的记忆密度和保真度,还使信息与任务要求和智能体特性相一致。
资源与框架
基准测试和数据集
在本节中,我们调查了用于评估基于大语言模型智能体的记忆、长期记忆、持续学习或长上下文能力的代表性基准测试和数据集。我们将这些基准测试分为两大类:(1) 专门针对记忆/终身学习/自我进化智能体设计的;(2) 最初为其他目的(例如工具使用能力、网络搜索、具身行为)开发的,但由于其长期性、多任务性或顺序性而对记忆评估相关的。
面向记忆/终身学习/自我进化智能体的基准测试
面向记忆的基准测试主要关注智能体如何构建、维护和利用过去交互或世界事实的显式记忆。这些任务通常会探究在多轮对话、特定用户会话或长篇合成叙述中信息的保留和检索,有时还包括多模态信号。
表8 提供了这些基准测试的综合概述,包括它们的记忆焦点、环境类型、模态和评估尺度,作为比较其设计目标和评估设置的结构化参考。
代表性示例如 MemBench、LoCoMo、WebChoreArena、MT-Mind2Web、PersonaMem、PerLTQA、MPR、PrefEval、LOCCO、StoryBench、Madial-Bench、DialSim、LongBench、LongBench v2、RULER、BALILong、MM-Needle 和 HaluMem 强调用户建模、偏好跟踪和对话级一致性,通常在可以精确控制真实记忆的模拟环境中进行。
终身学习基准测试不仅限于孤立的记忆检索,还考察智能体如何在长时间范围内和不断变化的任务分布中持续获取、整合和更新知识。诸如 LongMemEval、MemoryBank、MemoryBench、LifelongAgentBench 和 StreamBench 等基准测试围绕一系列任务或情节设计,在这些任务或情节中,新信息逐渐到来,而早期信息可能变得过时或冲突。这些设置强调现象如灾难性遗忘、前向和后向迁移以及测试时适应,使其适合研究记忆机制如何与持续学习目标相互作用。在许多情况下,不仅跟踪当前任务的表现,还跟踪先前看到的任务或对话的表现,从而量化智能体在适应新用户、领域或交互模式时如何保存有用的知识。
自我进化智能体基准测试更进一步,将智能体视为一个开放系统,可以通过交互迭代地改进自己的记忆、技能和策略。在这里,重点不仅在于存储和回忆信息,还在于元级别的行为,如自我反思、记忆编辑、工具增强存储和多轮次或多游戏中的策略改进。像 MemoryAgentBench、Evo-Memory 以及其他多情节或任务风格的环境可以在自我进化设置中实例化,允许智能体累积轨迹、合成更高层次的抽象,并基于自身过去的表现调整未来的行为。从这个角度来看,这些基准测试为评估智能体是否能够自主引导出更强大的行为提供了测试平台,将静态任务转变为长期适应、策略改进和真正自我改进记忆使用的竞技场。
其他相关基准
除了专门针对记忆或终身学习设计的基准测试外,广泛的面向智能体和长期视野评估套件也与研究基于LLM智能体的记忆相关能力密切相关。尽管这些基准最初是为了评估其他方面(如工具使用、具身互动或知识密集型推理)而引入的,但它们的顺序性、多步骤性和多任务性质隐含地对长期信息保留、上下文管理和状态跟踪提出了强烈要求。
具身和交互式环境构成了此类基准的主要类别。像ALFWorld和ScienceWorld这样的框架在模拟文本基础或部分基础环境中评估智能体,在这种环境中成功需要记住过去的观察结果、中间目标和跨扩展动作序列的环境动态。类似地,BabyAI专注于在时间上扩展的情节中遵循语言条件指令,隐式测试智能体在整个交互过程中维持任务相关状态的能力。虽然这些基准没有明确建模外部记忆模块,但有效表现往往依赖于智能体在长期内保存和重用信息的能力。
另一类突出的基准包括基于网络和工具增强的交互基准。WebShop、WebArena和MMInA评估智能体在涉及多步骤导航、信息收集和决策的真实或半真实网络环境中运行的情况。这些设置自然会产生长上下文轨迹,在其中必须回忆并整合早期动作、检索到的信息或用户约束。ToolBench进一步扩展了这一范式,通过评估智能体在复杂工作流中选择和调用API的能力,其中先前工具输出和工具使用经验的记忆对于连贯执行至关重要。
多任务和通用智能体评估平台也提供了关于记忆使用的间接但有价值的信号。AgentGym和AgentBoard将多样化的环境或任务汇总成统一的评估套件,要求智能体在跨任务适应的同时保留特定任务的知识和策略。基于PDDL的规划环境通常用于智能体基准测试,评估在结构化动作空间上的战略推理,其中智能体从跨情节积累和重用经验以提高长期规划性能中受益。
最后,一些最近的基准测试针对的是要求严格的现实世界或接近现实世界的推理场景,这些场景固有地强调长上下文和跨步骤一致性。SWE-Bench Verified在现实的软件存储库上评估代码修复,其中智能体必须对长文件和不断变化的代码状态进行推理。GAIA和xBench评估深度研究和搜索密集型任务,这些任务需要综合跨多个步骤和来源收集的信息。GenAI-Bench虽然专注于多模态生成质量,但也涉及复杂的流程,在这些流程中,先前提示、中间输出或视觉约束的记忆起着重要作用。
综上所述,这些基准通过将基于LLM的智能体置于丰富、交互式和长期视野的环境中,补充了专门针对记忆的评估。尽管记忆并不总是测量的明确目标,但在在这类环境中持续的表现隐含地依赖于智能体管理长上下文、保存相关信息以及将过去的经验整合到正在进行的决策中的能力,使它们成为实际研究记忆相关行为的宝贵测试平台。
Memory/Lifelong-learning/Self-evolving-oriented Benchmarks
| Name | Link | Fac. | Exp. | MM. | Env. | Feature | Scale |
|---|---|---|---|---|---|---|---|
| MemBench | Link | ✅ | ✅ | ❌ | simulated | interactive scenarios | 53,000 s. |
| MemoryAgentBench | Link | ✅ | ✅ | ❌ | simulated | multi-turn interactions | 4 t. |
| LoCoMo | Link | ✅ | ❌ | ✅ | real | conversational memory | 300 s. |
| WebChoreArena | Link | ✅ | ✅ | ✅ | real | tedious web browsing | 4 t./532 s. |
| MT-Mind2Web | Link | ✅ | ✅ | ❌ | real | conversational web navigation | 720 s. |
| PersonaMem | Link | ✅ | ❌ | ❌ | simulated | dynamic user profiling | 15 t./180 s. |
| LongMemEval | Link | ✅ | ❌ | ❌ | simulated | interactive memory | 5 t./500 s. |
| PerLTQA | Link | ✅ | ❌ | ❌ | simulated | social personalized interactions | 8,593 s. |
| MemoryBank | Link | ✅ | ❌ | ❌ | simulated | user memory updating | 194 s. |
| MPR | Link | ✅ | ❌ | ❌ | simulated | user personalization | 108,000 s. |
| PrefEval | Link | ✅ | ❌ | ❌ | simulated | personal preferences | 3,000 s. |
| LOCCO | Link | ✅ | ❌ | ❌ | simulated | chronological conversations | 3,080 s. |
| StoryBench | Link | ✅ | ✅ | ❌ | mixed | interactive fiction games | 3 t. |
| MemoryBench | Link | ✅ | ✅ | ❌ | simulated | continual learning | 4 t./ 20,000 s. |
| Madial-Bench | Link | ✅ | ❌ | ❌ | simulated | memory recalling | 331 s. |
| Evo-Memory | Link | ✅ | ✅ | ❌ | simulated | test-time learning | 10 t./ 3,700 s. |
| LifelongAgentBench | Link | ✅ | ✅ | ❌ | simulated | lifelong learning | 1,396 s. |
| StreamBench | Link | ✅ | ✅ | ❌ | simulated | continuous online learning | 9,702 s. |
| DialSim | Link | ✅ | ✅ | ❌ | real | multi-dialogue understanding | 1,300 s. |
| LongBench | Link | ✅ | ❌ | ❌ | mixed | long-context understanding | 21 t./4,750 s. |
| LongBench v2 | Link | ✅ | ❌ | ❌ | mixed | long-context multitasks | 20 t./503 s. |
| RULER | Link | ✅ | ❌ | ❌ | simulated | long-context retrieval | 13 t. |
| BABILong | Link | ✅ | ❌ | ❌ | simulated | long-context reasoning | 20 t. |
| MM-Needle | Link | ✅ | ❌ | ✅ | simulated | multimodal long-context retrieval | 280,000 s. |
| HaluMem | Link | ✅ | ❌ | ❌ | simulated | memory hallucinations | 3,467 s. |
| HotpotQA | Link | ✅ | ❌ | ❌ | simulated | long-context QA | 113k s. |
Other Related Benchmarks
| Name | Link | Fac. | Exp. | MM. | Env. | Feature | Scale |
|---|---|---|---|---|---|---|---|
| ALFWorld | Link | ✅ | ✅ | ❌ | simulated | text-based embodied environment | 3,353 t. |
| ScienceWorld | Link | ✅ | ✅ | ❌ | simulated | interactive embodied environment | 10 t./30 t. |
| AgentGym | Link | ❌ | ✅ | ❌ | mixed | multiple environments | 89 t./20,509 s. |
| AgentBoard | Link | ❌ | ✅ | ❌ | mixed | multi-round interaction | 9 t./1013 s. |
| PDDL* | Link | ❌ | ✅ | ❌ | simulated | strategy game | - |
| BabyAI | Link | ❌ | ✅ | ❌ | simulated | language learning | 19 t. |
| WebShop | Link | ❌ | ✅ | ✅ | simulated | e-commerce web interaction | 12,087 s. |
| WebArena | Link | ❌ | ✅ | ✅ | real | web interaction | 812 s. |
| MMInA | Link | ✅ | ✅ | ✅ | real | multihop web interaction | 1,050 s. |
| SWE-Bench Verified | Link | ❌ | ✅ | ❌ | real | code repair | 500 s. |
| GAIA | Link | ❌ | ✅ | ✅ | real | human-level deep research | 466 s. |
| xBench-DS | Link | ❌ | ✅ | ✅ | real | deep-search evaluation | 100 s. |
| ToolBench | Link | ❌ | ✅ | ❌ | real | API tool use | 126,486 s. |
| GenAI-Bench | Link | ❌ | ✅ | ✅ | real | visual generation evaluation | 40,000 s. |
表8: LLM Agent 记忆、长期、终身学习和自进化评估相关基准概览。 表格涵盖两类基准:(i) 专为记忆、终身学习或自进化 Agent 评估设计的基准,以及 (ii) 其他通过顺序、多步骤或多任务交互隐式强调长程记忆的 Agent 基准。 Fac. 和 Exp. 分别表示基准是评估事实记忆还是经验(交互衍生)记忆。MM. 表示是否存在多模态输入,Env. 表示基准是在模拟环境还是真实环境中进行。Feature 总结了评估的主要能力,Scale 报告了基准的近似规模(s. 代表样本 samples,t. 代表任务 tasks)。PDDL 表示常用的基于 PDDL 的规划子集。
开源框架
快速增长的开源记忆框架生态系统旨在为构建增强型LLM智能体提供可重用的基础设施。代表性开源记忆框架的结构化比较,包括它们支持的记忆类型、架构抽象和评估覆盖范围,在7中进行了总结。这些框架中的大多数通过向量或结构化存储支持事实记忆,并且越来越多的子集也开始建模体验痕迹,例如对话历史、用户行为和情节摘要,最近还出现了多模态记忆。针对LLM智能体的开源记忆框架涵盖了从具有丰富分层记忆抽象的以智能体为中心的系统到更通用的检索或记忆即服务后端(如MemGPT、Mem0、Memobase、MemoryOS、MemOS、Zep、LangMem、SuperMemory、Cognee、Memary、Pinecone、Chroma、Weaviate、Second Me、MemU、MemEngine、Memori、ReMe、AgentMemory和MineContext)。其中许多框架明确区分了短期和长期存储,并提供了基于图、基于配置文件或模块化的记忆空间,一些已经开始报告基于记忆基准的结果。其他框架通常提供可扩展的向量或图数据库、API以及有助于组织上下文的语义或流实体层,但往往将智能体行为和评估协议留给应用程序来处理。总体而言,这些框架在表示灵活性和系统设计方面正在迅速成熟。
位置与前沿
本节阐述了基于大型语言模型智能体的记忆系统设计中的关键立场和新兴领域。超越现有方法的描述性调查,我们重点关注范式级别的转变,这些转变重新定义了在长期智能体环境中如何构建、管理和优化记忆。具体而言,我们考察了从以检索为中心到生成性记忆的转变,从手动工程到自主管理的记忆系统的转变,以及从启发式管道到强化学习驱动的记忆控制的转变。我们进一步讨论了这些转变如何与多模态推理、多智能体协作和可信度相交,并概述了可能塑造下一代智能体记忆架构的开放挑战和研究方向。
记忆检索与记忆生成
回顾:从记忆检索到记忆生成
历史上,智能体记忆研究的主要范式一直集中在记忆检索上。在这种范式下,主要目标是根据当前上下文从现有的记忆存储中识别、过滤和选择最相关的记忆条目。大量的先前工作集中在通过更好的索引策略、相似性度量、重新排序模型或如知识图谱等结构化表示来提高检索准确性。在实践中,这包括使用密集嵌入的向量相似性搜索、结合词汇和语义信号的混合检索、分层过滤以及基于图的遍历等技术。这些方法强调了访问存储信息时的精确性和召回率,隐含地假设记忆库本身已经很好地形成。
然而,最近越来越多的关注转向了记忆生成。与将记忆视为待查询的静态存储库不同,记忆生成强调智能体主动按需合成新的记忆表示的能力。其目标不仅仅是检索和连接现有片段,而是以适应当前上下文和未来用途的方式整合、压缩和重组信息。这种转变反映了人们越来越认识到,有效使用记忆往往需要抽象和重组,特别是在原始存储信息嘈杂、冗余或与即时任务不一致时。
现有的记忆生成方法大致可以分为两个方向。一种方法采用先检索后生成的策略,其中检索到的记忆项作为重建的原材料。在这种设置下,智能体首先访问一组相关记忆,然后生成一个更简洁、连贯且特定于上下文的精炼记忆表示,如在ComoRAG、G-Memory 和 CoMEM 中实现的那样。这种方法保留了历史信息的基础,同时实现了自适应总结和重组。另一种方法探索直接记忆生成,即在没有任何显式检索步骤的情况下生成记忆。相反,智能体直接从当前上下文、交互历史或潜在内部状态生成记忆表示。诸如MemGen 和 VisMem 之类的系统通过构建针对手头任务定制的潜在记忆令牌来体现这一方向,完全绕过了显式记忆查找。
未来展望
展望未来,我们预计生成方法将在智能体记忆系统中发挥越来越核心的作用。我们强调了未来生成式记忆机制应理想上具备的三个特性。
首先,生成式记忆应该是上下文适应的。与其存储通用摘要,记忆系统应当生成针对智能体预期未来需求而明确优化的表示。这包括根据不同的任务、解决问题的不同阶段或交互模式调整记忆的粒度、抽象层次和语义焦点。
其次,生成式记忆应该支持跨异构信号的整合。智能体越来越多地在多样化的模态和信息源上操作,包括文本、代码、工具输出和环境反馈。记忆生成为将这些碎片化信号融合成统一表示提供了一种自然机制,这种表示比原始拼接或单独检索对下游推理更有用。我们假设潜在记忆(如\Cref{ssec:latent}中讨论的)可能是实现这一目标的一个有前途的技术路径。
第三,生成式记忆应该是可学习和自我优化的。未来的系统不应依赖于手动指定的生成规则,而是应通过优化信号(例如强化学习或长期任务性能)来学习何时以及如何生成记忆。从这个角度看,记忆生成成为智能体策略的一个组成部分,与推理和决策共同进化。
自动记忆管理
回顾:从手工设计到自动构建的记忆系统
现有的智能体记忆系统通常依赖于手动设计的策略来确定存储哪些信息、何时使用这些信息以及如何更新或检索它们。通过使用详细的指令、预定义的阈值或由人类专家制定的明确规则来指导固定的LLM,系统设计者可以以相对较低的计算和工程成本将记忆模块集成到当前的智能体框架中,从而实现快速原型设计和部署。此外,这些方法还提供了可解释性、可重复性和可控性,使开发人员能够精确指定记忆的状态和行为。然而,类似于其他领域的专家系统,这种手工策划的方法存在显著的局限性:它们本质上缺乏灵活性,并且往往无法在多样化的动态环境中泛化。因此,这些系统在长期或开放式的交互中表现不佳。
近期,在智能体记忆研究中的发展开始解决这些局限性,使智能体本身能够自主管理记忆的演变和检索。例如,CAM 赋予了LLM智能体自动将细粒度的记忆条目聚类为高层次抽象单元的能力。Memory-R1 引入了一个配备专用“记忆管理器”工具的辅助智能体来处理记忆更新。尽管取得了这些进展,当前的解决方案仍然受到限制:许多方案仍然由手动设计的规则驱动,或者针对狭窄的任务特定学习目标进行了优化,这使得它们难以推广到开放式设置中。
未来展望
为了支持真正的自动化记忆管理,一个有前景的方向是通过显式工具调用将记忆构建、演化和检索直接集成到智能体的决策循环中,使智能体本身能够推理记忆操作,而不是依赖外部模块或手工制作的工作流程。与现有的将智能体内部推理过程与其记忆管理动作分离的设计相比,基于工具策略的LLM智能体可以精确地知道它执行了哪些记忆操作(例如,添加/更新/删除/检索),从而导致更连贯、透明且上下文相关的记忆行为。
另一个关键前沿在于开发采用分层和自适应架构的自我优化记忆结构,这些架构受到认知系统的启发。首先,分层记忆结构已被证明可以提高效率和性能。除了层次结构之外,动态链接、索引和重构记忆条目的自演化记忆系统使得记忆存储本身能够随着时间进行自我组织,支持更丰富的推理并减少对手工设计规则的依赖。最终,这种自适应、自我组织的记忆架构为能够维护强大、可扩展且真正自主的记忆管理的智能体铺平了道路。
强化学习与智能体记忆
图11:RL 赋能的智能体记忆系统的演进。 从基于启发式规则或提示驱动流水线的无 RL 记忆系统,逐步发展到由强化学习主导部分记忆操作的部分 RL 介入设计,最终迈向端到端学习记忆架构与控制策略的全 RL 驱动记忆系统。这一演进体现了更广泛的范式转变:从人工工程化的记忆流水线,走向模型原生、可自我优化的 LLM 智能体记忆管理。
回顾:强化学习正在使智能体内部化记忆管理能力
强化学习正在迅速重塑基于现代大语言模型的智能体的发展范式。在广泛的智能体能力范围内,包括规划、推理、工具使用,以及在多样化的任务领域中,如数学推理、深度研究和软件工程,强化学习已经开始在推动智能体性能方面发挥核心作用。作为智能体能力的基础组成部分之一,记忆也遵循从基于管道到模型原生范式的类似趋势。智能体记忆研究社区整体上正从早期的启发式和手动设计转向越来越多地由强化学习控制关键决策的方法。展望未来,有理由预期完全基于强化学习的记忆系统最终可能会成为主导方向。在详细讨论这一发展轨迹之前,我们简要概述了第一阶段的发展。
这种通过强化学习逐步内部化并优化记忆管理的转变,在11中得到了示意性说明。
RL-free记忆系统
在前文综述的大量智能体记忆文献中,相当一部分可以归类为RL-free记忆系统。这些方法通常依赖于启发式或手动指定的机制,例如受遗忘曲线启发的固定阈值规则、在MemOS、Mem0和MemoBase等框架中发现的严格语义搜索流程,或是基于简单连接策略存储记忆块的方法。在某些系统中,一个大型语言模型以一种看似具有自主性的方式参与记忆管理,但其底层行为完全是提示驱动的。该大型语言模型被要求生成记忆条目,但并未接受任何专门针对有效记忆控制的训练,如在Dynamic Cheatsheet、ExpeL、EvolveR和G-Memory等系统中所见。这类方法因其简单性和实际可操作性,在该领域的早期工作中占据了主导地位,并且可能在未来一段时间内继续发挥影响力。
RL辅助的记忆系统
随着该领域的发展,许多研究开始将基于RL的方法融入到记忆流水线的选定组件中。早期的一个尝试是RMM,它使用了一个轻量级的策略梯度学习器,在初始检索阶段后根据BM25或其他语义相似性度量对记忆块进行排序。后来的系统探索了更为雄心勃勃的设计。例如,Mem-\(\alpha\) 将整个记忆构建过程委托给一个通过RL训练的智能体,Memory-R1 也采用了类似的理念。一条快速扩展的研究路线探讨了如何使智能体能够自主折叠、压缩和管理在超长多轮任务中的上下文。这种设置对应于工作记忆的管理。这一领域的许多领先系统都是通过RL训练的,包括但不限于Context Folding、Memory-as-Action、MemSearcher 和 IterResearch。这些RL辅助的方法已经展示了强大的能力,并指出了RL在未来记忆系统设计中日益重要的作用。
未来展望
展望未来,我们预计完全由强化学习(RL)驱动的记忆系统将成为智能体记忆演化的下一个重要阶段。我们强调了这类系统应理想地体现的两个特性。
- 首先,由智能体管理的记忆架构应当尽量减少对人工设计先验的依赖。许多现有框架继承了受人类认知启发的设计模式,如皮层或海马体类比,或是预定义的层次分类法,将记忆划分为情景、语义和核心类别。虽然这些抽象概念在早期研究中很有用,但它们可能并不是复杂环境中操作的人工智能体最有效或最自然的结构。一个完全由RL驱动的环境为智能体提供了发明新颖且可能更合适记忆组织的机会,这些组织直接从优化动态中产生,而不是基于人类直觉。在这种观点下,通过RL激励,鼓励智能体设计新的记忆格式、存储模式或更新规则,从而实现适应性和创造性而非手工制作的记忆架构。
- 其次,未来的记忆系统应赋予智能体对记忆管理所有阶段的完全控制权。当前辅助RL的方法通常只干预记忆生命周期的一个子集。例如,Mem-\(\alpha\) 自动化了某些方面的记忆写入,但仍依赖于手动定义的检索管道,而像MemSearcher这样的系统主要关注短期工作记忆,而不涉及长期巩固或演化。一个完全自主的记忆系统需要智能体以集成的方式自主处理多粒度记忆形成、记忆演化和记忆检索。要达到这种控制水平,几乎肯定需要端到端的RL训练,因为启发式或基于提示的方法不足以协调这些组件之间跨长时间范围的复杂交互。
这两方面共同指向了一个未来,在这个未来里,记忆不再仅仅是附加到大型语言模型智能体上的辅助机制,而是成为一个完全可学习且自我组织的子系统,通过RL与智能体共同进化。这样的系统有潜力使人工智能体真正实现持续学习和长期能力。
多模态记忆
回顾
随着基于文本的记忆研究变得越来越成熟并得到广泛探索,以及多模态大型语言模型和同时支持多模态理解和生成的统一模型不断进步,注意力自然转向了多模态记忆。这种转变反映了更广泛的认识,即许多现实世界中的智能体设置本质上是多模态的,而仅限于文本的记忆系统不足以支持在复杂环境中的长期推理和交互。
现有的多模态记忆研究可以大致分为两个互补的方向。第一个方向侧重于使多模态智能体能够存储、检索和利用来自多种感官输入的记忆。这一方向是智能体记忆的自然扩展,因为在现实环境中运行的智能体不可避免地会遇到异构数据源,包括图像、音频、视频和其他非文本信号。多模态记忆的进步程度紧密跟随相应模态的成熟度。视觉模态如图像和视频受到了最多的关注,导致了关于支持诸如视觉定位、时间跟踪和长期场景一致性等任务的视觉和视频记忆机制的研究越来越多。相比之下,音频和其他模态的记忆系统相对较少被探索。
第二个方向将记忆视为统一模型的支持组件。在这种情况下,记忆主要不是为了支持智能体决策,而是为了增强多模态生成和一致性。例如,在图像和视频生成系统中,记忆机制通常用于保持实体一致性、跨帧维护世界状态或确保长时间生成的一致性。在这里,记忆作为稳定结构,将生成锚定到先前产生的内容上,而不是作为智能体经验的记录本身。
未来展望
展望未来,多模态记忆很可能会成为智能体系统中不可或缺的组成部分。随着智能体越来越多地向具身化和交互式环境发展,它们的信息来源将本质上是多模态的,涵盖感知、行动和环境反馈。因此,有效的记忆系统必须以统一的方式支持异构信号的存储、整合和检索。
尽管最近取得了进展,但目前还没有提供真正全模态支持的记忆系统。大多数现有的方法仍然局限于单个模态或在模态之间松散耦合。未来的一个关键挑战在于设计能够灵活适应多种模态的记忆表示和操作,同时保持语义对齐和时间一致性。此外,多模态记忆必须超越被动存储,支持抽象、跨模态推理和长期适应。解决这些挑战对于使智能体能够在丰富、多模态的环境中稳健且一致地运行至关重要。
多智能体系统中的共享记忆
回顾:从孤立的记忆到共享的认知基础
随着基于大语言模型的多智能体系统(MAS)日益受到重视,共享记忆已成为实现协调、一致性和集体智能的关键机制。早期的多智能体框架主要依赖于孤立的本地记忆,并结合显式的消息传递,其中智能体通过对话历史或特定任务的通信协议来交换信息。虽然这种设计避免了智能体之间的直接干扰,但它常常存在冗余、碎片化上下文和高通信开销的问题,尤其是在团队规模和任务时间跨度增加时。
后续的研究引入了集中式的共享记忆结构,例如全局向量存储、黑板系统或共享文档,所有智能体都可以访问这些结构。这些设计支持了一种团队级别的记忆,促进了共同关注、减少了重复,并有助于长期协调。代表性系统表明,共享记忆可以作为规划、角色交接和共识构建的持久共同基础。然而,简单的全局共享也暴露了新的挑战,包括记忆杂乱、写入竞争以及缺乏基于角色或权限的访问控制。
未来展望
展望未来,共享记忆很可能从一个被动的存储库演变为一种主动管理和自适应的集体表示。一个重要方向是开发具有智能体意识的共享记忆,在这种记忆中,读写行为取决于智能体的角色、专长和信任度,从而实现更结构化和可靠的知识聚合。
另一个有前景的方向是基于学习的共享记忆管理。未来的系统可能不再依赖于手工设计的同步、总结或冲突解决策略,而是训练智能体根据长期团队表现来决定何时、何内容以及如何贡献给共享记忆。最后,随着多智能体系统越来越多地在开放和多模态环境中运行,共享记忆必须支持跨异构信号的抽象,同时保持时间和语义的一致性,我们认为潜在记忆在这方面展现出了一个有希望的路径。在这些方向上的进展对于将共享记忆从协调辅助工具转变为稳健集体智能的基础至关重要。
世界模型的记忆
回顾
世界模型的核心目标是构建一个能够高保真模拟物理世界的内部环境。这些系统作为下一代人工智能的关键基础设施。世界模型的核心属性是生成既无限可扩展又实时交互的内容。与传统的视频生成(创建固定长度的片段)不同,世界模型通过在每一步接收动作并预测下一个状态来提供连续反馈的方式进行迭代操作。
在这种迭代框架中,记忆机制成为系统的基础。记忆存储并维护从前一时间步继承的空间和语义信息或隐藏状态。它确保生成的下一个部分与先前上下文在场景布局、物体属性和运动逻辑方面保持长期一致性。本质上,记忆机制使世界模型能够处理长期的时间依赖性,并实现可信的模拟交互。
以前,记忆建模依赖于简单的缓冲方法。基于帧采样的条件生成依赖于少数历史帧。虽然直观,但这导致了上下文碎片化和感知漂移,因为早期细节丢失了。滑动窗口方法采用了类似注意力池和局部KV缓存的LLM技术。尽管这解决了计算瓶颈问题,但它将记忆限制在一个固定的窗口内。一旦物体离开这个视图,模型实际上就忘记了它,从而阻碍了如闭环等复杂任务的完成。
到2025年末,该领域从有限的上下文窗口转向结构化的状态表示。当前架构遵循三条主要路径:
- 状态空间模型(SSMs)架构,如长上下文SSMs,利用Mamba风格的主干。这些模型将无限的历史压缩成固定大小的递归状态,理论上具有无限的记忆容量且推理成本恒定。
- 显式记忆库。与压缩状态不同,这些系统维护一个外部的历史表示存储以支持精确回忆。不同的方法在其结构逻辑上有所不同:UniWM采用分层设计,通过基于特征的相似性门控将短期感知与长期历史分开。相反,像WorldMem和Context-as-Memory (CaM)这样的基于检索的方法则维护一个扁平的过去上下文库,利用几何检索(例如,视场重叠)动态选择相关帧以维持3D场景的一致性。
- 稀疏记忆与检索为了平衡长期一致性和效率,Genie Envisioner和Ctrl-World使用稀疏记忆机制。这些模型通过注入稀疏采样的历史帧或检索姿态条件下的上下文来增强当前观察,以锚定预测并在操作任务期间防止漂移。
未来展望
从架构的角度来看,该领域正在经历一个根本性的转变,即从侧重于被动保留的数据缓存转向侧重于主动维护的状态模拟。这一演变目前正在凝结成两种不同的范式,旨在解决实时响应与长期逻辑一致性之间的冲突。
- 双系统架构。受认知科学的启发,世界模型可以分为快速和慢速组件。系统1代表了处理即时物理和流畅交互的快速且直觉性的层次,使用如SSM等高效骨干。系统2代表了处理复杂推理、规划和世界一致性的缓慢且深思熟虑的层次,使用大规模VLM或显式记忆数据库。
- 主动记忆管理。被动机制正被主动记忆策略所取代。新的模型不再将记忆视为盲目存储最近历史的固定缓冲区,而是设计为认知工作空间,根据任务相关性积极地策划、总结和丢弃信息。最近的经验研究表明,在处理功能性无限上下文时,这种主动记忆管理显著优于静态检索方法。这一转变标志着从简单地记住最后N个标记到维持连贯且可查询的世界状态的转变。
可信记忆
回顾:从可信的RAG到可信的记忆
如本综述所示,记忆在实现智能体行为中起着基础性作用,支持持久性、个性化和持续学习。然而,随着记忆系统更深入地嵌入基于大语言模型(LLM)的智能体中,信任问题变得至关重要。
早期关于检索增强生成(RAG)系统中的幻觉和事实性问题的关注现在已经演变为对记忆增强型智能体更广泛的信任讨论。与RAG类似,使用外部或长期记忆的一个主要动机是通过可检索的事实内容来减少幻觉。然而,不同于RAG的是,智能体记忆通常存储特定于用户、持久且可能敏感的内容,包括从事实知识到过去的交互、偏好或行为痕迹。这给隐私、可解释性和安全性带来了额外的挑战。
最近的研究表明,记忆模块可以通过间接的提示攻击泄露私有数据,突出了记忆化和过度保留的风险。同时,有观点认为智能体记忆系统必须支持访问控制、可验证遗忘和可审计更新的显式机制以保持可信度。值得注意的是,在智能体场景中,当记忆跨越长时间跨度时,这些威胁会被放大。
可解释性仍然是一个关键瓶颈。虽然像文本日志或键值存储这样的显式记忆提供了一定程度的透明度,但用户和开发者仍然缺乏工具来追踪哪些记忆项被检索、它们如何影响生成、或者是否被误用。在这方面,像RAGChecker这样的诊断工具以及像RAMDocs与MADAM-RAG这样的冲突解决框架为追踪记忆使用和不确定性下的推理提供了灵感。
此外,除了个体记忆之外,集体隐私在共享或联邦记忆系统中的新兴重要性也被强调,这些系统可能跨多智能体部署或组织运作。所有这些发展共同表明了需要将信任提升为记忆设计中的首要原则。
未来展望
展望未来,我们认为可信记忆必须围绕三个相互关联的支柱构建:隐私保护、可解释性和幻觉鲁棒性——每个方面都要求在架构和算法上进行创新。
对于隐私,未来的系统应支持细粒度的权限记忆、用户管理的保留策略、加密或设备端存储,以及必要的联合访问。诸如差分隐私、记忆删减和自适应遗忘(例如,基于衰减的模型或用户擦除界面)等技术可以作为防止记忆化和泄露的保障。
可解释性要求超越可见内容,包括可追溯的访问路径、自我合理化的检索,以及可能的反事实推理(例如,如果没有这段记忆会有什么不同?)。记忆注意力的可视化、记忆影响的因果图和面向用户的调试工具可能成为标准组件。
幻觉缓解将受益于冲突检测、多文档推理和不确定性感知生成方面的持续进步。低置信度检索下的弃权、回退到模型先验,或多智能体交叉检查等策略是很有前景的。除了行为保障外,新兴的机制可解释性技术通过分析内部表示和推理电路如何贡献于幻觉输出提供了互补的方向。诸如表示层探测和推理路径分解等方法能够更细粒度地诊断幻觉的来源,并提供干预和控制的原则性工具。
从长远来看,我们设想的记忆系统由类似操作系统的抽象概念管理:分段、版本控制、可审计,并由智能体和用户共同管理。构建这样的系统将需要在表征学习、系统设计和政策控制方面的协调努力。随着大型语言模型智能体开始在持久且开放的环境中运行,可信记忆不仅将成为一个理想的功能,而且是现实世界部署的基础要求。
人-认知连接
回顾
当代智能体记忆系统的架构已经与过去一个世纪中建立的人类认知基础模型趋同。当前的设计将容量有限的上下文窗口与大规模外部向量数据库相结合,反映了阿特金森-希夫林多存储模型,有效地实现了工作记忆与长时记忆之间区别的一个人工对应物。
此外,将智能体记忆划分为交互日志、世界知识和基于代码的技能,表现出与图尔文对情景记忆、语义记忆和程序记忆分类的显著结构一致性。
当前框架将这些生物学类别转化为工程制品,其中情景记忆提供自传式的连续性,而语义记忆则提供广义的世界知识。
尽管存在这些结构上的相似之处,但在检索和维护的动力学方面仍存在根本差异。人类记忆是一个建构过程,大脑根据当前的认知状态积极重构过去的事件,而不是重放精确的记录。相比之下,大多数现有的智能体记忆系统依赖于逐字检索机制(如RAG),将记忆视为不可变标记的存储库,通过语义相似性进行查询。因此,虽然智能体拥有过去的真实记录,但它们缺乏人类智能所特有的记忆扭曲、抽象以及历史动态重塑的生物能力。
未来展望
为了弥合静态存储与动态认知之间的差距,下一代智能体必须超越纯粹的在线更新,引入类似于生物睡眠的离线巩固机制。借鉴互补学习系统(CLS)理论,未来的架构可能会引入专门的巩固间隔,在这些间隔中,智能体将脱离环境交互,进行记忆重组和生成重放。在这些离线期间,智能体可以自主地从原始的情景痕迹中提炼出可泛化的模式,执行主动遗忘以剔除冗余噪声,并优化其内部索引,而不受实时处理的延迟限制。
最终,这种进化表明了记忆形式和功能的范式转变:从显式的文本检索转向生成性重构。未来的系统可能利用生成性记忆,其中智能体按需合成潜在的记忆令牌,模仿大脑的重构性质。通过整合类似睡眠的巩固周期,智能体将从单纯存档数据的实体演变为内化经验的实体,通过定期压缩大量的情景流来解决稳定性和可塑性的两难问题,从而形成高效、参数化的直觉。
结论
本综述探讨了智能体记忆作为现代基于大语言模型的智能体系统的基础组成部分。通过统一的形式、功能和动态视角来审视现有研究,我们澄清了智能体记忆的概念框架,并将其置于更广泛的智能体智能演进中。在形式层面上,我们识别出三种主要实现:标记级、参数级和潜在记忆,每一种在过去几年中都经历了独特而迅速的发展,反映了在表示、适应性和与智能体策略集成方面的根本不同权衡。在功能层面上,我们超越了先前调查中常见的长期与短期的粗略二分法,而是提出了一种更细致且全面的分类法,根据它们在知识保留、能力积累和任务级推理中的作用,区分事实记忆、经验记忆和工作记忆。这些观点共同揭示了记忆不仅仅是辅助存储机制,而是通过它,智能体能够实现时间连贯性、持续适应性和长时域能力的关键基质。
除了整理之前的工作外,我们还确定了关键挑战和新兴方向,指向智能体记忆研究的下一阶段。特别是,强化学习的日益整合、多模态和多智能体环境的兴起以及从以检索为中心向生成记忆范式的转变表明,未来的记忆系统将变得完全可学习、自适应和自我组织。这样的系统有可能将大型语言模型从强大但静态的生成器转变为能够持续交互、自我改进并在随时间进行原则性推理的智能体。
我们希望本综述为未来的研究提供一个连贯的基础,并成为研究人员和实践者的参考。随着智能体系统的不断成熟,记忆设计将继续是一个核心且开放的问题,可能会在开发鲁棒、通用和持久的人工智能方面发挥决定性作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号