【综述】大模型后训练综述
https://arxiv.org/abs/2503.06072
摘要
大型语言模型(LLMs)的出现彻底改变了自然语言处理,使其在从对话系统到科学探索等各领域中变得不可或缺。然而,其预训练架构在特定场景下常暴露出诸多局限,包括推理能力受限、伦理风险不明以及领域适应性不足等问题。这些挑战促使先进的后训练语言模型(PoLMs)应运而生,如 OpenAI-o1/o3 和 DeepSeek-R1(统称为大型推理模型,LRMs),以弥补上述不足。
本文首次系统性地综述了 PoLMs 的发展历程,围绕五大核心范式展开:
- 微调:提升任务特定准确性
- 对齐:确保伦理一致性与人类偏好匹配
- 推理:推动多步推断能力,尽管奖励设计仍具挑战
- 高效性:在复杂性提升的背景下优化资源利用
- 集成与适应:扩展多模态能力并解决一致性问题
本文梳理了从 ChatGPT 基础对齐策略到 DeepSeek-R1 创新推理方法的演进,展示了 PoLMs 如何利用数据集缓解偏见、深化推理能力并增强领域适应性。我们的贡献包括首次系统性总结 PoLMs 演化历程、构建技术与数据集的结构化分类体系,并提出以 LRMs 提升推理能力和领域灵活性的战略议程。
作为首部该领域综述,本文整合了最新 PoLMs 进展,建立了未来研究的理论框架,助力 LLMs 在科学与社会应用中实现更高的精准性、伦理稳健性与多样性。
引言
语言模型(LMs)是用于建模和生成自然语言的复杂计算框架。这些模型彻底改变了自然语言处理(NLP)领域,使机器能够理解、生成并与人类语言进行交互,方式接*人类认知。与人类通过互动和环境自然*得语言不同,机器必须经过大量数据驱动的训练才能具备类似能力。这带来了显著的研究挑战:让机器能够理解和生成自然语言,并进行自然、符合语境的对话,不仅需要庞大的计算资源,还需要精细的方法论。
大型语言模型(LLMs)的出现,如 GPT-3、InstructGPT 和 GPT-4,标志着语言模型发展的变革阶段。这些模型以庞大的参数量和先进的学*能力为特征,能够捕捉复杂的语言结构、语境关系和细微的模式。这使得 LLMs 不仅能预测下一个词,还能在翻译、问答、摘要等多种任务中生成连贯、语境相关的文本。LLMs 的发展引发了广泛的学术关注,研究主要分为两个阶段:预训练和后训练。
预训练
预训练的概念源自计算机视觉任务中的迁移学*,其主要目标是利用大规模数据集开发通用模型,便于后续针对不同下游任务进行微调。预训练的一大优势在于可以利用任何未标注的文本语料,提供丰富的训练数据。然而,早期的静态预训练方法难以适应不同语义环境,促使动态预训练技术的发展,如 BERT 和 XLNet。BERT 通过 Transformer 架构和自注意力机制,有效克服了静态方法的局限,确立了“预训练-微调”学*范式,推动了后续多种架构的创新。
后训练
后训练是指在模型完成预训练后,为特定任务或用户需求进一步优化和适应模型的技术与方法。自 GPT-3 发布以来,后训练领域迎来了创新高峰。各种方法被提出以提升模型性能,包括微调(利用标注数据或特定任务数据调整模型参数)、对齐策略(优化模型以更好地契合用户偏好)、知识适应(让模型融入领域知识)、推理能力提升(增强模型逻辑推理和决策能力)。这些统称为后训练语言模型(PoLMs),推动了 GPT-4、LLaMA-3、Gemini-2.0、Claude-3.5 等模型的发展,显著提升了 LLM 的能力。然而,后训练模型在适应新任务时仍面临需重新训练或大幅调整参数的挑战,使得后训练模型的开发成为活跃研究领域。
如上所述,预训练语言模型(PLMs)主要提供通用知识和能力,而 PoLMs 则专注于将这些模型适应具体任务和需求。最新的 LLM,如 DeepSeek-R1,展示了 PoLMs 在提升推理能力、契合用户偏好和增强跨领域适应性方面的演进。随着开源 LLMs 和领域大数据集的不断涌现,学术界和工业界越来越重视 PoLMs 的定制化发展。
现有文献中,PLMs 已被广泛讨论和综述,而 PoLMs 的系统性回顾则较为稀缺。为推动相关技术发展,有必要全面梳理现有研究,识别关键挑战、空白和改进机会。本综述旨在填补这一空白,构建后训练研究的结构化框架,如图1所示,系统探讨从 ChatGPT 到 DeepSeek 的多阶段后训练技术,包括微调、LLM 对齐、推理增强和效率提升等方法,并重点介绍 DeepSeek 所采用的创新策略。
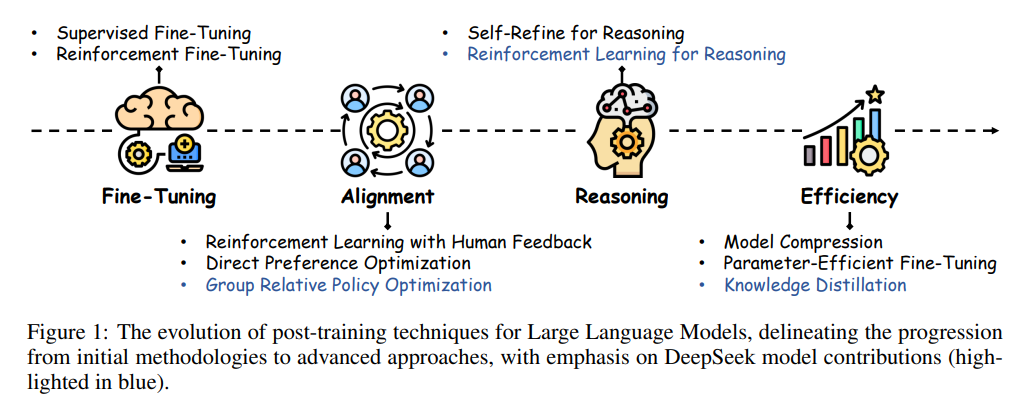
主要贡献
本文是首篇系统综述 PoLMs 的论文,全面、结构化地探讨了该领域的最新进展。以往综述多聚焦于 LLM 的某一特定方面,如偏好对齐、参数高效微调、基础技术等,内容较为局限。相比之下,本文采取整体视角,全面回顾后训练常用核心技术,并进行系统分类。此外,我们还考察了相关数据集和实际应用,并识别了开放挑战与未来研究方向,如图2所示。
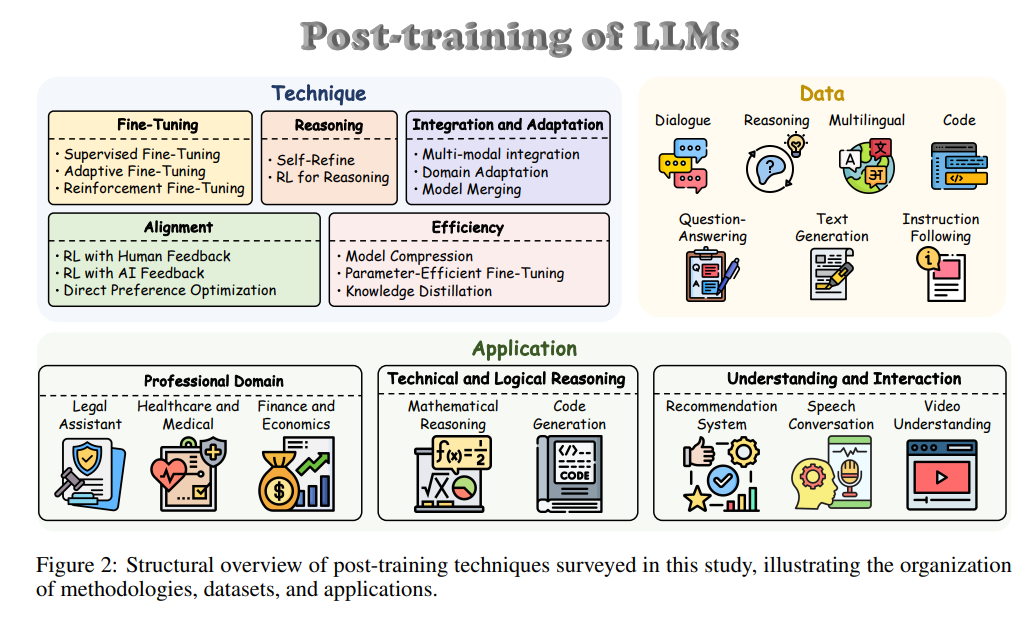
主要贡献如下:
-
全面的历史综述
首次系统梳理 PoLMs 的发展历程,从 ChatGPT 的人类反馈强化学*(RLHF)到 DeepSeek-R1 的创新冷启动强化学*方法。涵盖关键技术(微调、对齐、推理、效率、集成与适应),分析其发展及相关挑战,如计算复杂性和伦理问题。通过连贯叙述和重要参考文献,为研究者提供后训练演进的全景视角,成为该领域的基础资源。 -
结构化分类与框架
提出结构化分类体系(见图2),将后训练方法分为五大类,数据集分为七种类型,并将应用框架划分为专业、技术和交互领域。该框架理清方法间的关系及实际意义,为后训练研究提供系统化视角。通过明晰分类和分析洞见,提升新手和专家的理解与获取能力,成为导航后训练复杂性的全面指南。 -
未来方向
强调大型推理模型(LRMs)的崛起,如 o1 和 DeepSeek-R1,利用大规模强化学*推动推理能力突破。指出持续进步对提升推理能力和领域适应性至关重要。分析识别了关键挑战,包括可扩展性、伦理对齐风险和多模态集成障碍,并提出如自适应强化学*框架和公平优化等研究方向,推动后训练向更高精度和可信度发展,以满足未来需求。
组织结构
本文系统梳理了 PoLMs 的历史演进、方法体系、数据集、应用场景及未来发展。第二节回顾 PoLMs 的历史。第三节探讨微调,包括监督微调(SFT)和强化微调(RFT)。第四节聚焦对齐,涵盖人类反馈强化学*(RLHF)、AI反馈强化学*(RLAIF)和直接偏好优化(DPO)。第五节关注推理,包括自我优化方法和推理强化学*。第六节综述效率提升方法,如模型压缩、参数高效微调(PEFT)和知识蒸馏。第七节探讨集成与适应,包括多模态方法、领域适应和模型融合。第八节回顾后训练常用数据集。第九节分析 LLM 应用。第十节评估开放问题和未来方向。最后,第十一节总结全文并展望研究前景。
概述
PoLMs 的发展历史
大型语言模型(LLMs)的进步是自然语言处理(NLP)领域的关键篇章,后训练方法在其从通用预训练架构到专用任务自适应系统的演变中发挥了重要作用。本节梳理了后训练语言模型(PoLMs)的历史轨迹,从 BERT 和 GPT 等基础预训练里程碑,到当代模型如 o1 和 DeepSeek-R1 所体现的先进后训练范式。正如图3所示,这一进程反映了从建立广泛语言能力到提升任务适应性、伦理对齐、推理能力和多模态集成的转变,标志着 LLM 能力的变革性发展。
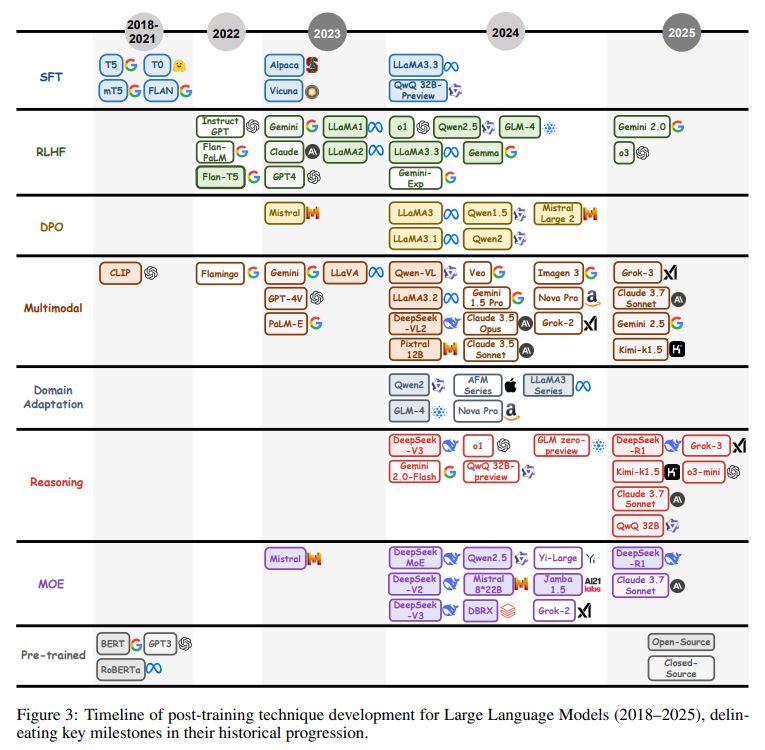
现代 PoLMs 的历史起点与 2018 年的预训练革命相契合,BERT 和 GPT 的发布重新定义了 NLP 基准。BERT 的双向自编码框架利用 Transformer 架构和自注意力机制,擅长捕捉上下文依赖关系,适用于问答等任务;而 GPT 的自回归设计则强调生成连贯性,为文本生成树立了典范。这些模型确立了“预训练+微调”范式,2019 年 T5 的出现进一步统一了多任务学*,为后续后训练方法奠定了坚实基础。
自 2020 年起,PoLMs 的发展显著加速,推动了高效适应多样任务的需求。前缀微调和提示微调等创新方法通过修改模型输入而非重训练整个架构,实现了多任务灵活性,节省了计算资源并拓宽了应用范围。2021 年,随着人类反馈强化学*(RLHF)的出现,模型优化开始以用户为中心,通过人类评价对齐模型输出,提升了实际对话场景的实用性。2022 年,RLHF 采用了*端策略优化(PPO),进一步提升了对齐稳定性并缓解了对噪声反馈的过拟合。ChatGPT 的发布展示了 RLHF 的变革潜力,推动了 PoLMs 研究的热潮。同时,链式思维(CoT)提示作为推理增强策略出现,鼓励模型在复杂任务中表达中间步骤,提高了透明度和准确性,尤其在逻辑推理和问题解决领域表现突出。
2022 至 2024 年间,PoLMs 进一步多样化,关注领域特定性、伦理稳健性和多模态集成,体现了 LLM 精细化优化的新趋势。领域适应技术如检索增强生成(RAG)通过集成外部知识库,实现了专业领域的上下文丰富输出,无需完全重训练,极大提升了专业应用的时效性。伦理对齐方面,直接偏好优化(DPO)在 2023 年简化了 RLHF 流程,直接优化模型输出以匹配人类偏好,提升了效率和稳健性。多模态能力也在不断推进,PaLM-E 和 Flamingo 等模型率先实现了视觉-语言集成,BLIP-2 和 LLaVA 则将多模态扩展到医学影像等更广领域。效率创新方面,专家混合(MoE)架构如 Google 的 Switch-C Transformer 引入了稀疏激活机制,Mixtral 进一步优化了可扩展性与性能。推理能力提升方面,自我博弈和蒙特卡洛树搜索(MCTS)与 CoT 集成,增强了 LLM 的决策能力,为高级推理模型奠定了基础。
专家混合(MoE)模型的兴起是架构上的重要进展,区别于传统密集架构,通过动态激活部分参数,实现了计算效率与大规模参数的兼容。Google 的 Switch-C Transformer 在 2022 年率先采用了 1.6 万亿参数分布于 2048 个专家的设计,兼顾了资源需求与性能提升。后续如 Mixtral 和 DeepSeek V2.5 进一步优化了这一框架,在 LMSYS 基准上取得了领先成绩,证明稀疏 MoE 架构在可扩展性和效果上可与密集模型媲美。这些进展推动了效率导向的 PoLMs,使 LLM 能以更低计算开销处理复杂任务,拓宽了实际应用范围。到 2025 年,DeepSeek-R1 的出现成为 PoLMs 创新的里程碑,摒弃了传统的有监督微调(SFT),转向链式思维推理和探索性强化学*策略。以 DeepSeek-R1-Zero 为例,集成了自我验证、反思和扩展 CoT 生成,验证了 RL 驱动推理激励在开放研究范式下的有效性,并引入了蒸馏技术,将复杂推理模式从大模型迁移到小模型。这一方法不仅优于单独 RL 训练,还开创了可扩展、以推理为中心的 LLM 新范式,有望解决后训练方法在计算效率和任务适应性上的长期挑战。
PoLMs 的公式基础
策略优化原理
*端策略优化(PPO)算法是强化学*中的关键技术,尤其适用于如人类反馈强化学*(RLHF)等场景,在这些场景中,保持训练的稳定性和效率至关重要。PPO 通过限制策略更新的幅度,确保模型行为的变化逐步且可控,从而防止性能出现灾难性波动。这对于微调大规模语言模型尤为重要,因为剧烈的策略更新可能导致模型行为不可预测或不理想。
定义
在 PPO 中,状态 \(s_t\) 表示模型在时刻 \(t\) 的环境,包括模型决策所需的全部信息。动作 \(a_t\) 是模型在状态 \(s_t\) 下的选择,构成模型决策序列。每执行一个动作,智能体会收到奖励 \(r_t\),作为环境反馈,指示该动作的成败。优势函数 \(A^\pi(s, a)\) 衡量在当前策略下,在状态 \(s\) 采取动作 \(a\) 的优越性,相较于该状态下所有动作的期望值。其形式定义为动作价值函数 \(Q^\pi(s, a)\) 与状态价值函数 \(V^\pi(s)\) 的差值:
其中,\(Q^\pi(s, a)\) 表示在状态 \(s\) 采取动作 \(a\) 并遵循策略 \(\pi\) 后获得的期望累计奖励,\(V^\pi(s)\) 是从状态 \(s\) 出发遵循策略 \(\pi\) 的期望累计奖励,两者均考虑了未来奖励的折扣因子 \(\gamma\)。
策略更新
PPO 通过优势函数对策略 \(\pi_\theta\) 进行增量优化,采用如下剪切目标函数:
其中,\(r_{t}(\theta)\) 是当前策略与旧策略在动作 \(a_t\) 上的概率比值:
\(\hat{A}_{t}\) 是第 \(t\) 步的优势估计,剪切函数 \(\operatorname{clip}(r_{t}(\theta), 1-\epsilon, 1+\epsilon)\) 将策略更新限制在安全范围,由超参数 \(\epsilon\) 控制。该机制确保更新不会偏离旧策略过多,从而保证训练过程的稳定性。
价值函数更新
价值函数 \(V_\phi\) 估算在策略 \(\pi_\theta\) 下,从状态 \(s_t\) 出发的期望累计奖励。为保证价值函数估算准确,需最小化预测值与实际奖励的均方误差:
其中,\(R(s_t)\) 是从状态 \(s_t\) 获得的实际累计奖励,\(V_\phi(s_t)\) 是当前策略下的估算值。目标是调整参数 \(\phi\),使预测值与实际奖励的差距最小化,提高价值函数的准确性。
RLHF 原理
人类反馈强化学*(RLHF)是一种通过引入人类生成反馈来对齐模型与人类偏好的关键方法。该方法通过显式捕捉人类输入的奖励函数,使模型更好地适应用户偏好和实际应用场景。
定义
在 RLHF 中,语言模型 \(\rho\) 在词汇表 \(\Sigma\) 上生成序列概率分布。模型 \(\rho\) 生成的序列 \(x_0, x_1, \dots, x_{n-1}\) 来自输入空间 \(X = \Sigma^{\leq m}\),每个 token 依赖于之前的 token。模型输出的条件概率分布为:
模型 \(\rho\) 在输入空间 \(X\)、数据分布 \(D\) 和输出空间 \(Y = \Sigma^{\leq n}\) 上进行任务训练。例如,在文本摘要任务中,GPT-2 通过 RLHF 训练,目标是根据数据集预测文本摘要。
目标函数
策略 \(\pi\) 是与原始模型 \(\rho\) 结构相同的语言模型,初始时 \(\pi = \rho\)。目标是通过优化策略,最大化输入输出对 \((x, y)\) 的期望奖励 \(R(x, y)\)。奖励函数 \(R(x, y): X \times Y \to \mathbb{R}\) 为每对输入输出分配一个标量值,最优策略 \(\pi^*\) 通过如下最大化问题获得:
该目标函数是标准强化学*问题,模型通过与环境交互,在人类反馈引导下学*最大化期望奖励。
DPO 原理
直接偏好优化(DPO)在 RLHF 基础上,直接根据人类偏好优化模型输出,通常以成对比较的形式表达。DPO 摒弃了传统奖励函数,专注于通过最大化偏好奖励优化模型行为。
目标函数
DPO 采用与前述方法相同的 RL 目标,在一般奖励函数 \(r\) 下,KL 约束奖励最大化的最优解为:
其中,\(Z(x)\) 是归一化分区函数。即使采用最大似然估计 \(r_{\phi}\) *似真实奖励 \(r^*\),分区函数 \(Z(x)\) 也可*似,简化了优化过程。该公式通过直接调整策略以匹配人类反馈,实现了更高效的偏好优化。
偏好模型
采用 Bradley-Terry 模型对两个输出 \(y_1\) 和 \(y_2\) 的偏好建模,最优策略 \(\pi^*\) 满足如下偏好模型:
其中,\(p^*(y_1 \succ y_2 \mid x)\) 表示在输入 \(x\) 下人类偏好输出 \(y_1\) 胜于 \(y_2\) 的概率。该方法有效地将人类偏好融入模型优化过程。
GRPO 原理
群体相对策略优化(GRPO)算法是强化学*中*端策略优化(PPO)的一种变体,首次在 DeepSeek 的相关工作中提出。GRPO 省略了评论模型,改用群体分数估算基线,与 PPO 相比显著降低了训练资源消耗。
定义
GRPO 与 PPO 的最大区别在于优势函数的计算方法。正如前文所述,PPO 中优势函数 \(A^\pi(s, a)\) 来源于 Q 值与 V 值的差异。
目标函数
具体而言,对于每个问题 \(q\),GRPO 从旧策略 \(\pi_{\theta_{old}}\) 中采样一组输出 \(\{o_1, o_2, \dots , o_G\}\),然后通过最大化如下目标优化策略模型:
其中,\(\epsilon\) 和 \(\beta\) 是超参数,\(\hat{A}_{i,t}\) 是仅基于每组内部输出的相对奖励计算的优势,具体将在后文详细介绍。
PoLMs 的微调方法
微调是将预训练的大型语言模型(LLMs)适应特定任务的基石,通过有针对性的参数调整来提升模型能力。该过程利用带标签或任务特定的数据集来优化性能,弥补通用预训练与领域需求之间的差距。本章探讨三种主要的微调范式:有监督微调,通过标注数据集提升任务准确性;自适应微调,通过指令微调和基于提示的方法定制模型行为;以及强化微调,结合强化学*通过奖励信号迭代优化输出,实现动态交互下的持续提升。
有监督微调
有监督微调(SFT)通过任务特定的标注数据集,将预训练的 LLMs 适配到具体任务。与依赖指令提示的指令微调不同,SFT 直接利用标注数据调整模型参数,使模型既精准又具备上下文适应性,同时保持广泛的泛化能力。SFT 架起了预训练阶段广泛语言知识与目标应用需求之间的桥梁。预训练的 LLMs 通过海量语料*得通用语言模式,减少了微调阶段对大量领域数据的依赖。模型选择至关重要:如 T5 等小型模型适合数据有限的资源受限场景,而 GPT-4 等大型模型则能在复杂、数据丰富的任务中发挥更强能力。
SFT 数据集准备
SFT 数据集构建
SFT 数据集通常结构为 $ \mathcal{D} = {(I_k, X_k)}_{k=1}^{N} $,其中 $ I_k $ 为指令,$ X_k $ 为对应实例。该配对使 LLM 能够识别任务模式并生成相关输出。方法如 Self-Instruct 可通过合成新指令-输出对提升多样性,并用如 ROUGE-L 等指标过滤重复项以保持数据多样性。
SFT 数据集筛选
筛选确保最终数据集中仅保留高质量的指令-实例对。筛选函数 \(r(\cdot)\) 用于评估每对的质量,得到精筛子集 \(\mathcal{D}'\):
其中 \(\tau\) 为用户设定的质量阈值。例如,指令跟随难度(IFD)指标量化指令对模型生成预期响应的引导效果。IFD 函数表达为:
其中 \(Q\) 为指令,\(A\) 为预期响应,\(\theta\) 为模型参数。该指标比较有无指令时生成响应的概率,归一化衡量指令的引导效果。未达阈值的对将被剔除,形成精筛数据集 \(\mathcal{D}'\)。
SFT 数据集评估
评估 SFT 数据集需选取高质量子集 \(\mathcal{D}_{\text{eval}}\) 作为模型性能基准。该子集可从精筛数据集抽样或独立划分以保证公正。传统 SFT 评估方法如 Few-Shot GPT 和微调策略资源消耗大,而指令挖掘则更高效。指令挖掘采用线性质量规则和一系列指标(如响应长度、平均奖励模型分数)评估数据集质量,并分析这些指标与整体质量的相关性。
SFT 过程
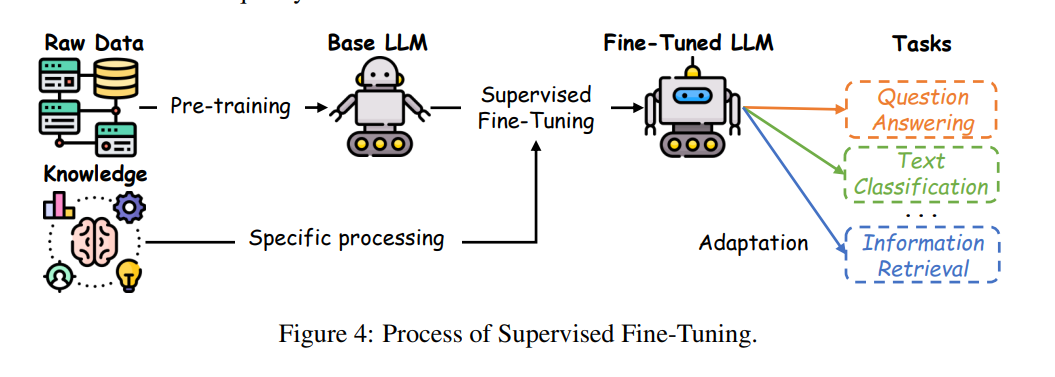
如图4所示,数据集准备好后,微调过程从预训练 LLM 开始,通常通过无监督或自监督方式在大规模原始数据集上预训练,目标是*得通用特征表示。随后在微调阶段,模型参数通过任务特定标注数据调整,使模型与应用需求对齐。该阶段常用的目标函数为交叉熵损失。对于有 \(N\) 个样本和 \(C\) 个类别的分类任务,表达为:
其中 \(y_{ij}\) 为样本 \(i\) 在类别 \(j\) 的真实标签,\(P\bigl(y_j \mid x_i; \theta\bigr)\) 为模型预测概率。最小化该损失推动模型更好地对齐真实标签,提升目标任务表现。
典型案例如 BERT 模型,先在大规模语料(如 BooksCorpus 和 Wikipedia)预训练,再用任务特定数据(如 IMDB 数据集)微调,实现情感分类、问答等任务的专精化。
全参数微调
全参数微调指调整预训练模型的所有参数,相较于如 LoRA 或 Prefix-tuning 等参数高效方法只调整部分参数。全参数微调常用于高精度需求场景,如医疗和法律领域,但计算开销巨大。例如,微调 65 亿参数模型需超 100GB GPU 内存,资源受限环境面临挑战。为缓解压力,出现了如 LOMO 等内存优化技术,减少梯度和优化器状态的内存占用。参数更新规则为:
其中 \(\theta_t\) 为第 \(t\) 次迭代的参数,\(\eta\) 为学*率,\(\nabla_{\theta} L(\theta_t)\) 为损失函数梯度。混合精度训练、激活检查点等技术也有助于降低内存需求,使大模型能在有限硬件上微调。
GPT-3 到 InstructGPT
典型的全参数微调案例是 GPT-3 到 InstructGPT 的转变,模型全部参数通过指令任务数据集微调,获得最优性能,但计算成本极高。
自适应微调
自适应微调通过引入额外提示,定制预训练模型行为,以更好地满足用户需求并处理更广泛任务。该方法为模型输出生成提供灵活框架,显著提升 LLMs 的适应性。主要方法包括指令微调和基于提示的微调,两者均通过任务特定引导提升模型的灵活性和准确性。
指令微调
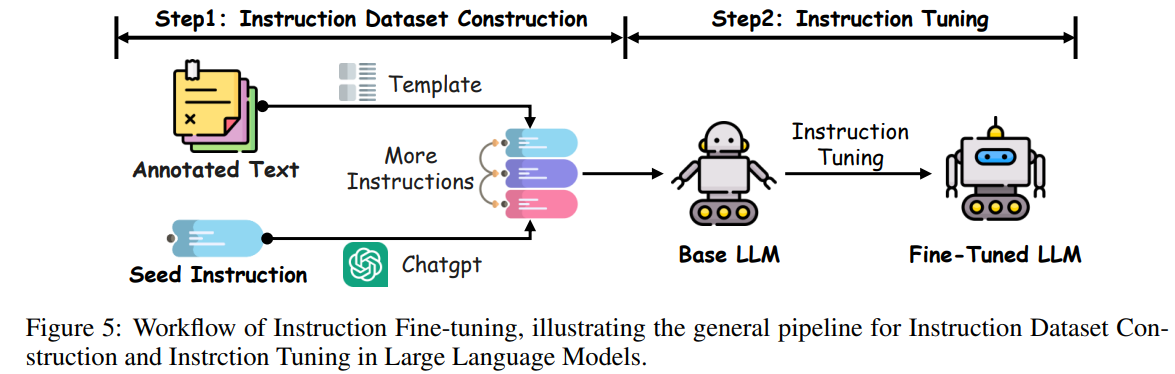
指令微调通过在专门构建的指令数据集上微调基础 LLM,显著提升模型在多任务和多领域的泛化能力。如图5所示,过程始于将现有 NLP 数据集(如文本分类、翻译、摘要)转化为包含任务描述、输入示例、预期输出和演示的自然语言指令。Self-Instruct 等技术可自动生成更多指令-输出对,扩展模型任务覆盖。微调过程使模型参数与任务指令对齐,最终获得在熟悉和新任务上均表现优异的 LLM。例如,InstructGPT 和 GPT-4 在指令跟随能力上有显著提升。
指令微调的效果高度依赖于指令数据集的质量和广度。高质量数据集应涵盖多语言、多领域和多任务复杂度,确保模型具备广泛适用性。此外,指令的清晰性和组织性对模型理解和执行任务至关重要。集成演示示例(如 Chain-of-Thought 提示)可显著提升复杂推理任务表现。微调阶段任务分布均衡也很重要,避免因任务覆盖不均导致过拟合或性能下降。比例任务采样、加权损失函数等方法有助于解决这些问题,确保每个任务对微调过程均有贡献。通过精心构建和管理指令数据集,研究者可大幅提升微调 LLMs 的泛化能力,使其在多任务和多领域中表现卓越。
前缀微调
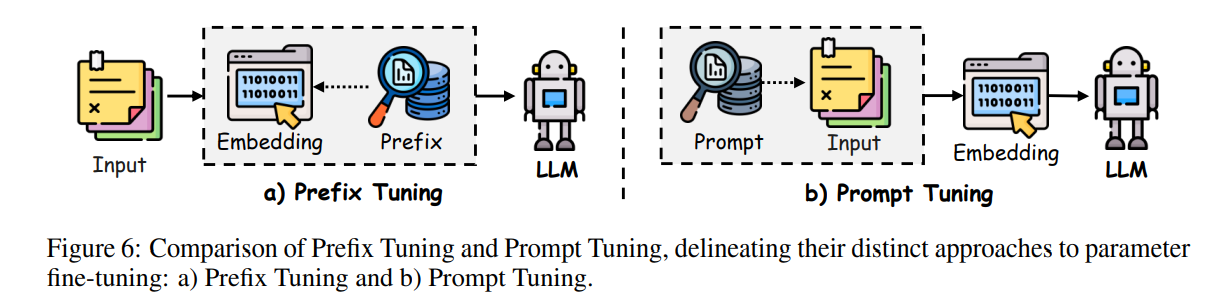
前缀微调是一种参数高效的微调方法,通过在语言模型每层 Transformer 中添加可训练的前缀 token(连续向量),而保持核心模型参数不变。如图6(a)所示,这些前缀向量为任务特定,作为虚拟 token 嵌入。优化前缀向量时采用重参数化技巧,即学*一个小型多层感知机(MLP)函数,将小矩阵映射到前缀参数,而非直接优化前缀向量,有助于稳定训练过程。优化后仅保留前缀向量用于提升任务表现。
通过在输入序列前添加连续提示,并利用层级提示,可在无需全模型微调的情况下引导模型生成任务特定输出。仅调整前缀参数,提升了参数效率。P-Tuning v2 在 Transformer 架构中引入层级提示向量,专用于自然语言理解任务,并通过多任务学*优化跨任务共享提示,提升不同参数规模下的模型表现。前缀微调有助于大语言模型快速高效适应特定任务,适合灵活高效应用场景。
提示微调
提示微调是一种高效适配大语言模型的方法,通过优化输入层的可训练向量,而非修改模型内部参数。如图6(b)所示,该技术在离散提示方法基础上引入软提示 token,可采用无约束格式或前缀结构。这些学*到的提示嵌入与输入文本嵌入结合后输入模型,引导模型输出,同时保持预训练权重不变。
两种典型实现为 P-tuning(采用灵活方法结合上下文、提示和目标 token,适用于理解和生成任务,通过双向 LSTM 架构增强软提示表示学*)和标准提示微调(采用更简单设计,将前缀提示加到输入,仅在训练时更新提示嵌入)。研究表明,提示微调在许多任务上可达到全参数微调的性能,但所需可训练参数显著减少。其成功与底层语言模型能力密切相关,因为提示微调仅调整输入层少量参数。P-Tuning v2 等新方法已证明提示微调可在不同模型规模下有效扩展,处理复杂任务。提示微调成为传统微调的高效替代方案,性能相当但计算和内存成本更低。
强化微调
强化微调(ReFT)是一种将强化学*(RL)与有监督微调(SFT)结合的高级技术,提升模型解决复杂动态问题的能力。与传统 SFT 通常为每个问题使用单一 Chain-of-Thought(CoT)注释不同,ReFT 允许模型探索多条有效推理路径,从而提升泛化能力和问题解决技巧。
ReFT 过程始于标准 SFT 阶段,模型先在标注数据上学*基础任务解决能力。随后,模型通过如 PPO 等 RL 算法进一步优化。在强化阶段,模型为每个问题生成多条 CoT 注释,探索不同推理路径。通过将模型预测答案与真实答案对比,正确输出获得奖励,错误输出受到惩罚。该迭代过程促使模型调整策略,最终提升推理能力。
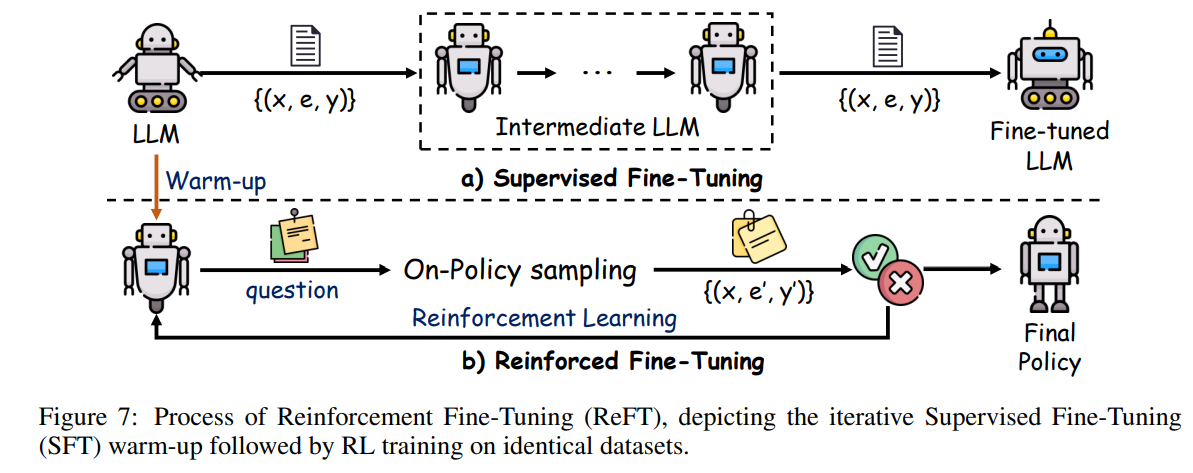
如图7所示,ReFT 分两阶段进行。上半部分为 SFT 阶段,模型多轮遍历训练数据,学*每个问题的正确 CoT 注释。下半部分为 ReFT 阶段:以 SFT 训练好的模型为起点,模型根据当前策略生成备选 CoT 注释(\(e'\)),并将预测答案(\(y'\))与真实答案(\(y\))对比。正确答案获得正奖励,错误答案获得负奖励,推动模型提升表现。这些奖励信号用于通过强化学*更新模型策略,增强其生成准确多样 CoT 注释的能力。
最新研究表明,ReFT 显著优于传统 SFT 方法。此外,集成推理时策略(如多数投票和重排序)可进一步提升性能,使模型在训练后优化输出。值得注意的是,ReFT 无需额外或增强训练数据,仅利用 SFT 阶段的现有数据即可实现性能提升,体现了模型更强的泛化能力,能更高效地从有限数据中学*。
PoLMs 的对齐方法
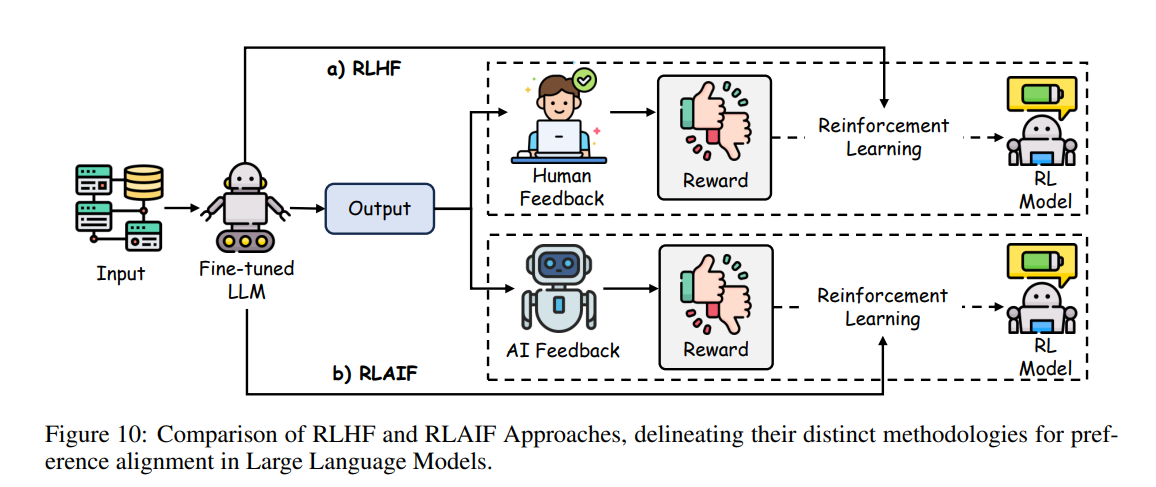
在大语言模型(LLM)的对齐中,核心目标是引导模型输出符合人类的期望和偏好,尤其是在安全关键或面向用户的应用场景下。本章讨论了实现对齐的三大主要范式:人类反馈强化学*(RLHF),通过人类标注数据作为奖励信号;AI反馈强化学*(RLAIF),利用 AI 生成的反馈以解决可扩展性问题;以及直接偏好优化(DPO),直接从人类偏好数据中学*,无需显式奖励模型。每种范式在实现稳健对齐的过程中都具有独特的优势、挑战和权衡。相关方法的简要对比见表2。
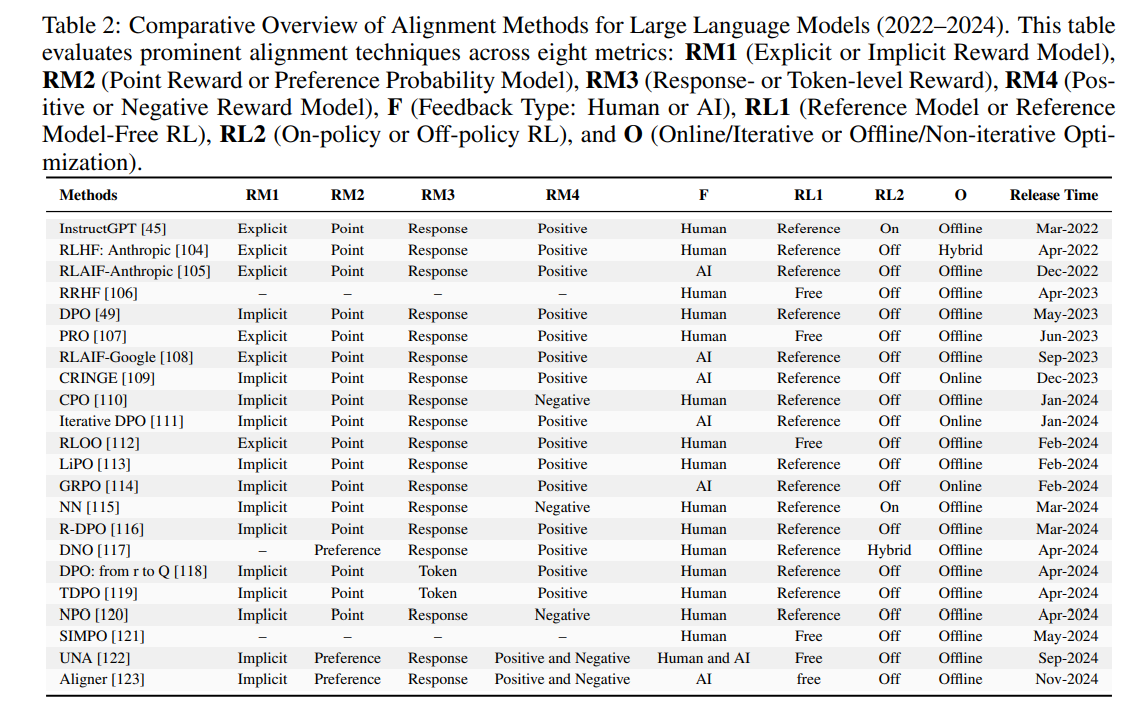
人类反馈强化学*
有监督微调(SFT)一直是指导 LLM 遵循人类指令的基础技术。然而,纯监督场景下标注数据的多样性和质量可能参差不齐,且监督模型捕捉更细致或自适应人类偏好的能力有限。为此,基于强化学*(RL)的微调被提出以弥补这些不足。其中,人类反馈强化学*(RLHF)是最早且最具影响力的 RL 后训练对齐方法之一。
如图8所示,RLHF 首先收集人类反馈(如偏好标签或奖励信号),然后利用这些信息训练奖励模型。在奖励模型的引导下,策略会迭代调整,以更好地匹配人类偏好。与 SFT 相比,RLHF 引入了持续的、偏好驱动的更新,带来了更强的对齐效果。现代 LLM(如 GPT-4、Claude、Gemini 等)均受益于这些机制,在指令遵循、事实一致性和用户相关性方面表现提升。下文将讨论 RLHF 的主要组成部分,包括反馈机制、奖励建模和策略学*方法。
RLHF 的反馈机制
人类反馈是 RLHF 的核心,为奖励模型提供用户偏好信息并指导策略更新。本节采用相关分类法,将常见人类反馈类型分为不同类别。表3展示了这些反馈类型在粒度、参与度和显式性等维度上的差异。每种反馈方式对模型优化有不同贡献,具有不同的可解释性、可扩展性和抗噪性。
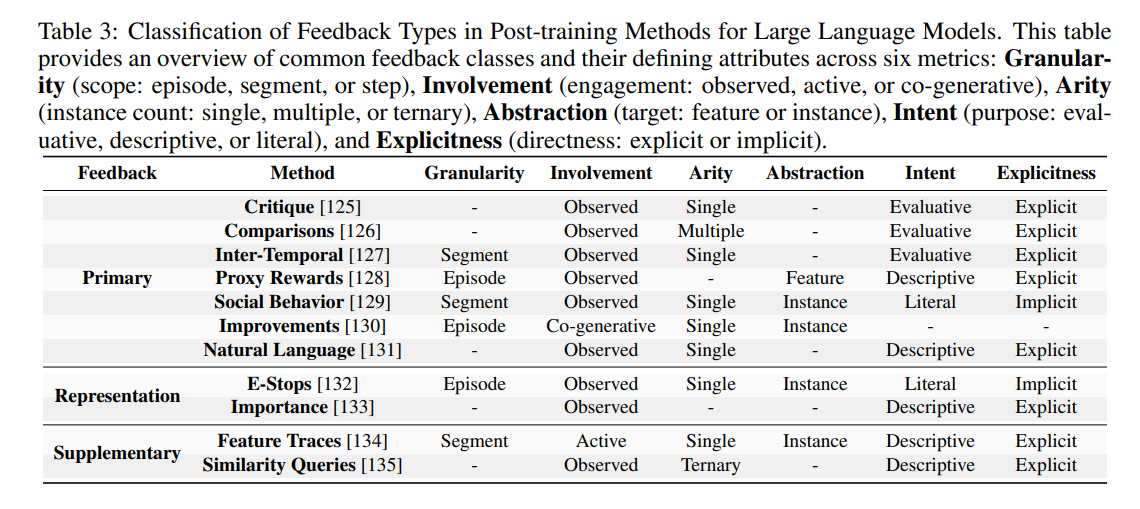
主要反馈:此类反馈直接影响 RLHF 的奖励模型。例如,批评反馈关注对智能体行为的显式人类评估,常通过二元或多标签注释来降低噪声。比较反馈允许评估者对多个输出或轨迹进行比较,尽管更大的选择集能提供更丰富信号,但也可能导致因果混淆。时序反馈通过在不同时间点提供判断来优化轨迹评估,代理奖励则通过*似奖励函数引导模型实现用户目标。社交行为反馈利用隐性线索(如面部表情)使智能体目标与用户情感一致。改进反馈强调实时人类干预以增量优化策略。自然语言反馈则通过文本信息传达偏好和改进建议。
补充反馈:除主要反馈外,还有两类补充奖励建模过程。紧急停止(e-stop)允许人类通过中止智能体轨迹进行干预,但不提供替代方案,特点是隐性参与和防止不良行为。重要性标签则标记特定观察对实现目标的重要性,提供显式但不直接改变行为的反馈。此类反馈因情境而异,作为补充输入强化奖励模型的学*过程。
表征特定反馈:某些反馈类型主要用于增强表征学*,而非直接塑造奖励函数。特征轨迹反馈要求人类演示某一特征的单调变化,从而动态扩展特征集。相似性查询通过比较轨迹三元组,利用轨迹空间的距离指导表征学*。通过这些表征特定反馈,RLHF 能更好地泛化到新任务和新场景。
RLHF 的奖励模型
真实奖励函数 \(r(x, y)\) 通常未知,因此需基于人类偏好构建可学*的奖励模型 \(r_{\theta}(x, y)\)。该模型预测候选输出 \(y\) 对于输入 \(x\) 符合人类期望的程度。训练数据通常由人类评估者对输出对进行比较或标注,模型一般采用交叉熵损失进行训练。为防止策略 \(\pi\) 偏离初始模型 \(\rho\),奖励函数中引入了由超参数 \(\beta\) 控制的惩罚项:
其中 \(\pi(y \mid x)\) 表示微调策略生成输出 \(y\) 的概率,\(\rho(y \mid x)\) 为原始模型的概率。该项确保策略在适应人类反馈的同时,仍受原有知识约束。
评估奖励函数 \(r_{\theta}(x, y)\) 至关重要,因为它直接影响学*效果和策略性能。准确评估该函数有助于确定适合的奖励结构,从而实现模型输出与人类偏好的对齐。然而,在安全敏感领域,标准 rollout 方法和离线策略评估可能因在线交互风险、偏见及对真实奖励的需求而不可行。为应对这些挑战,常用两种方法:
距离函数:*期研究关注于奖励评估距离函数,考虑潜在变换(如势能塑造)。例如,EPIC 衡量奖励函数在多种变换下的等价性,DARD 则优化规范化以确保评估基于可行转移。EPIC 类距离方法推广了 EPIC 的方法论,允许规范化、归一化和度量函数的多样性,STARC 在保留 EPIC 理论性质的基础上提供了更多灵活性。
可视化与人工检查:其他方法依赖可解释性和人工策划数据集来评估奖励函数的有效性。PRFI 通过预处理简化奖励函数,同时保持等价性,从而提升其透明度。CONVEXDA 和 REWARDFUSION 则提出了用于测试奖励模型对语义变化响应一致性的数据集。这些技术共同提升了奖励函数的评估可靠性,强化了大语言模型与人类偏好的对齐。
RLHF 的策略学*
RLHF 的策略学*(见图9)包括在线和离线两种方式,通过人类反馈优化策略。
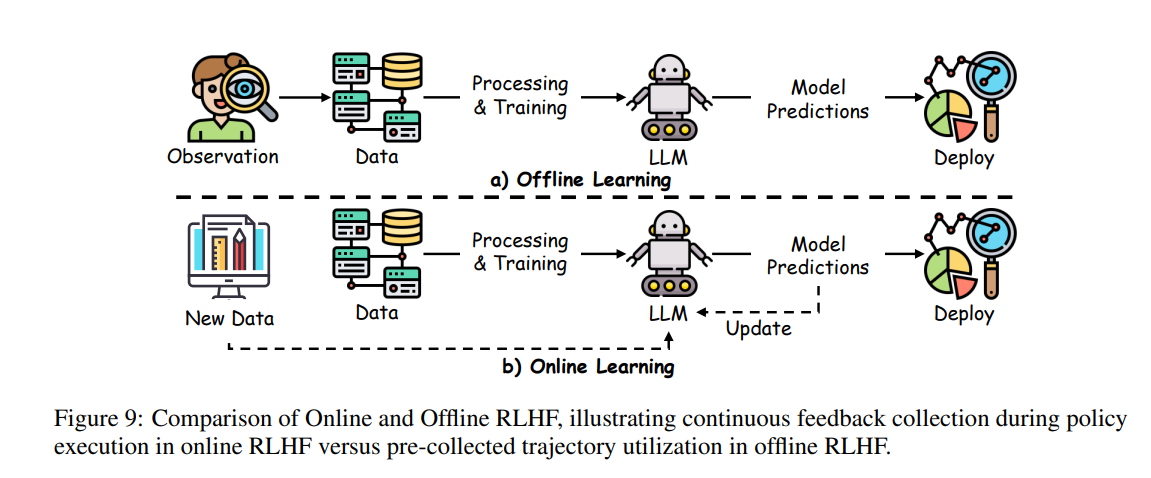
在线学*:在在线 RLHF 中,系统实时收集对新生成模型轨迹的人类偏好。DPS 等算法利用贝叶斯更新管理对决过程,PPS 和 PEPS 融合动态规划与 bandit 思想优化策略行为。LPbRL 通过特征嵌入捕捉不断变化的奖励结构,PbOP 则将最小二乘估计应用于转移动态和偏好信号。*期,PARL 将反馈采集视为策略优化的组成部分,提升了数据收集效率。
离线学*:在离线 RLHF 中,利用先前收集的偏好标注轨迹进行策略学*或优化。例如,研究了基于成对比较数据的悲观最大似然估计方法,为策略学*建立了性能界限。FREEHAND 和 DCPPO 等扩展方法推广到未知偏好模型,探索离线数据覆盖与策略泛化的关系。此外,针对 Boltzmann 成对比较模型的过拟合问题进行了研究,DCPPO 进一步探讨了动态离散选择模型以提升反馈效率。
在线与离线学*的融合:混合方法结合离线预训练与在线偏好聚合,既利用预收集数据,又能实时更新。PFERL 采用两阶段方法以最小化人类查询次数,PERL 则探索乐观最小二乘策略以实现主动探索。对决强化学*(Dueling RL)及其扩展(如 PRPRL 中的 REGIME)通过合理划分数据采集与反馈收集,优化了样本效率、标注成本和策略性能之间的权衡。
强化学*与 AI 反馈(RLAIF)
强化学*与 AI 反馈(RLAIF)扩展了 RLHF 范式,通过利用大语言模型(LLM)生成反馈信号。这种方法可以补充或替代人工反馈,在人工标注稀缺、成本高昂或不一致的任务中,提供更具可扩展性、低成本的偏好数据。
RLAIF 与 RLHF 的对比
在大规模应用 RLHF 时,主要挑战在于其对人工生成偏好标签的依赖,这需要大量资源来收集、整理和标注数据。数据标注过程既耗时又昂贵,且人工评估者可能带来不一致性,从而使所有模型输出的大规模一致标注变得复杂。这些限制极大地影响了 RLHF 的可扩展性和效率。
为了解决这些问题,RLAIF 被提出,它结合了人工反馈与 AI 生成反馈,通过强化学*训练模型。通过将 LLM 作为反馈来源,RLAIF 减少了对人工标注者的依赖,为传统 RLHF 提供了可行的替代方案。这种方法能够持续生成反馈,显著提升了可扩展性,同时保留了人工引导模型优化的灵活性。
如图10 所示,RLHF 与 RLAIF 的关键区别在于反馈来源:RLHF 依赖人工生成的偏好,而 RLAIF 使用 AI 生成的反馈来指导策略更新。实证研究(如 )表明,RLAIF 在人类评估者的评价下,能够达到与 RLHF 相当甚至更优的性能。值得注意的是,RLAIF 不仅超越了传统的监督微调基线,而且使用与策略模型规模相同的 LLM 偏好标注器,突显了该方法的高效性。
RLAIF 训练流程
RLAIF 的训练流程包括多个关键阶段,利用 AI 生成的反馈不断优化模型行为。该流程使 LLM 的输出能够以可扩展的方式与人类期望对齐,具体阶段如下:
- AI 反馈收集:在此阶段,AI 系统根据预设标准生成反馈,这些标准可能包括任务相关指标、响应的正确性或输出的适当性。与需要解释和人工标注的人工反馈不同,AI 反馈可以在广泛的模型输出中一致生成。这一特性使 AI 反馈能够持续提供,极大地扩展了反馈循环。
- 奖励模型训练:随后,AI 生成的反馈用于训练或优化奖励模型。该模型将输入-输出对映射到相应的奖励,使模型输出与反馈所指示的期望结果对齐。传统 RLHF 依赖直接人工反馈评估输出,而 RLAIF 使用 AI 生成标签,虽然可能带来一致性和偏见问题,但在可扩展性和独立于人力资源方面具有优势。
- 策略更新:最后阶段是根据前一步训练的奖励模型更新模型策略。通过强化学*算法调整模型参数,优化策略以在各种任务中最大化累积奖励。该过程是迭代的,奖励模型不断引导模型输出更好地符合预期目标。
RLAIF 的主要优势在于无需持续人工干预即可扩展反馈循环。通过用 AI 生成反馈替代人工反馈,RLAIF 促进了 LLM 在多任务中的持续改进,缓解了人工标注带来的瓶颈。
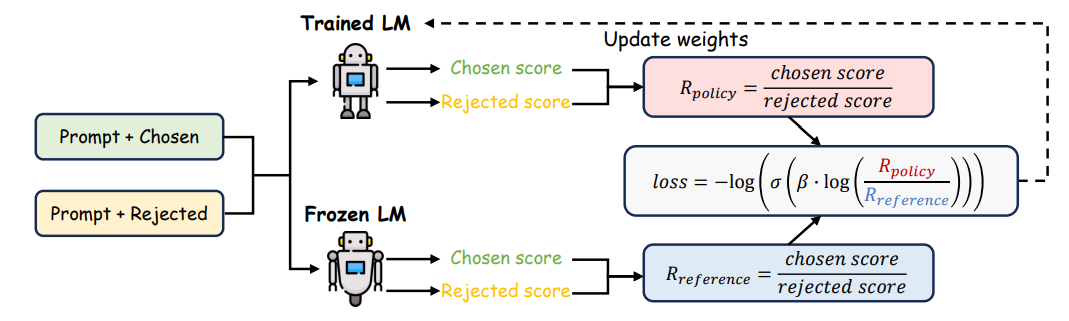
直接偏好优化(DPO)
如前所述,RLHF 通常包括三个阶段:监督微调、奖励建模和强化学*(通常通过 PPO 实现)。尽管 RLHF 有效,但在奖励模型拟合及其用于微调大语言模型的阶段,过程复杂且易不稳定。难点在于构建能准确反映人类偏好的奖励模型,以及在优化该奖励的同时保持语言模型与原始模型的接*性。
为了解决这些问题,直接偏好优化(DPO)被提出,作为一种更稳定且计算效率更高的替代方案。DPO 通过直接将奖励函数与最优策略关联,简化了奖励优化过程。它将奖励最大化问题视为基于人类偏好数据的单阶段策略训练问题,从而避免了奖励模型拟合的复杂性和对 Bradley-Terry 模型的依赖。
DPO 的基础
RLHF(基于人类反馈的强化学*)包括训练奖励模型(RM)和通过强化学*微调语言模型(LM)。DPO 简化了这一过程,直接利用人类偏好数据训练语言模型,从而在策略中隐式地捕获奖励模型。
KL 正则化奖励最大化目标
DPO 以广为接受的 KL 正则化奖励最大化框架为起点,其目标如下:
其中,\(r(x, y)\) 表示奖励函数,\(\beta > 0\) 是控制与参考策略 \(\pi_{\mathrm{ref}}\) 接*程度的系数,\(\mathrm{KL}(\cdot\|\cdot)\) 表示 Kullback-Leibler 散度。\(x \sim \mathcal{D}\) 表示从数据分布中采样的输入,\(y \sim \pi(\cdot \mid x)\) 表示从策略中采样的输出。
最优策略的推导
在适当假设下,方程的解可表示为 Boltzmann 分布:
其中归一化项 \(Z(x)\) 保证 \(\pi^{*}\) 是有效的概率分布:
奖励的重参数化
对上述最优策略取自然对数,可将奖励 \(r(x, y)\) 与最优策略 \(\pi^{*}\) 关联起来:
其中 \(\beta \log Z(x)\) 是常数,不影响奖励的两两比较。如果已知最优策略 \(\pi^{*}\),则真实奖励 \(r^{*}(x, y)\) 可确定到该常数项。
Bradley–Terry 偏好模型
在 Bradley-Terry 模型下,人类对两个输出 \(y_1\) 和 \(y_2\) 的偏好由其奖励差决定。偏好 \(y_1\) 的概率为:
将奖励重参数化公式代入上式,得到最终偏好模型:
该表达式将人类偏好概率与最优策略 \(\pi^{*}\) 和参考策略 \(\pi_{\mathrm{ref}}\) 的比值联系起来。
DPO 的目标
DPO 通过直接从偏好数据学*策略,避免了显式奖励建模。给定偏好三元组数据集 \(\{(x, y_{w}, y_{l})\}\),其中 \(y_{w}\) 为更受偏好的输出,\(y_{l}\) 为较不受偏好的输出,DPO 最大化观测偏好的似然。其目标函数为:
其中 \(\sigma(\cdot)\) 是逻辑 Sigmoid 函数,\(\beta \log \frac{\pi_{\theta}(y \mid x)}{\pi_{\mathrm{ref}}(y \mid x)}\) 表示 \(\pi_{\theta}\) 与参考策略之间的奖励差。通过最大化 \(\mathcal{L}_{\mathrm{DPO}}\),策略 \(\pi_{\theta}\) 可无需单独奖励模型而与人类偏好对齐。
由于 DPO 目标继承了 RLHF 的 KL 正则化形式,因此在明确定义的偏好假设下保留了理论一致性,并将训练过程统一为单阶段。这样,DPO 能更直接地将语言模型与人类评价对齐,降低系统复杂性并提升训练稳定性。
DPO 的训练细节
DPO 框架基于两个核心模型:参考策略 \(\pi_{\mathrm{ref}}\) 和目标策略 \(\pi_{\mathrm{tar}}\)。参考策略通常为预训练且经监督微调的语言模型,在训练过程中保持不变。目标策略则从 \(\pi_{\mathrm{ref}}\) 初始化,并通过偏好反馈迭代更新,从而更好地与人类判断对齐。图11展示了整体流程。
数据收集与准备
DPO 依赖于精心整理的偏好数据集。对于每个提示 \(x\),从参考策略 \(\pi_{\mathrm{ref}}\) 采样多个候选响应。人工标注者根据连贯性、相关性和清晰度等标准对这些响应进行比较或排序。最终的偏好标签成为优化目标策略 \(\pi_{\mathrm{tar}}\) 的核心训练信号。
训练流程
目标策略通过一系列基于梯度的更新来优化 DPO 损失 \(L_{\mathrm{DPO}}\)。具体步骤如下:
- 生成:\(\pi_{\mathrm{ref}}\) 为每个提示 \(x\) 生成候选输出。
- 标注:人工标注者比较生成的输出,确定其相对偏好。
- 优化:利用这些两两偏好,迭代更新 \(\pi_{\mathrm{tar}}\),使其更好地模拟人类偏好的输出。
在整个过程中,\(\pi_{\mathrm{ref}}\) 保持不变,作为衡量改进的稳定基线。
实践注意事项
选择一个稳健的参考策略对于 DPO 的有效初始化至关重要。SFT(监督微调)通常能为 \(\pi_{\mathrm{ref}}\) 提供良好的基线,使后续的偏好驱动更新能专注于细节优化而非基础能力的*得。此外,偏好数据需足够多样,以覆盖用户期望的不同变化,从而提升模型的适应性并防止过拟合于狭窄任务。
DPO 变体
多个 DPO(直接偏好优化)变体已出现,以应对特定的对齐挑战并优化文本生成的不同方面。表2 总结了这些方法,涵盖了从生成优化到冗长控制、列表式偏好和负面偏好等多种场景。
优化生成的 DPO
令牌级和迭代式 DPO 策略有助于更细粒度或持续地与人类偏好对齐。令牌级 DPO将问题重构为一个 bandit 问题,采用由 \((S, A, f, r, \rho_0)\) 定义的马尔可夫决策过程(MDP)。这种方法缓解了对不受偏好令牌的过度 KL 散度问题。TDPO采用顺序前向 KL 散度而非反向 KL,提升了文本生成的对齐性和多样性保持能力。迭代式 DPO通过多轮偏好评估(通常由模型自身执行)不断优化输出。成对 Cringe 优化(PCO)将二元反馈扩展到成对设置,利用软边界平衡探索与利用。步进式 DPO将偏好数据集分区,并进行迭代更新,每轮使用更新后的策略作为下一轮的基线。
可控与灵活的 DPO
部分 DPO 变体旨在管理冗长性并减少对固定参考策略的依赖。R-DPO通过在目标函数中加入正则项来惩罚输出长度,解决过于冗长或重复的响应问题。SimPO通过归一化响应长度并简化损失函数以同时处理期望与非期望输出,消除了对参考策略的需求。RLOO利用 REINFORCE 算法,无需训练价值模型,显著降低了计算开销。它将整个响应视为单一动作,并从稀疏奖励中学*,相较于传统的基于 PPO 的方法,简化了实现流程。
列表式 DPO
与仅限于成对比较的偏好数据不同,列表式 DPO 方法针对输出集合进行优化。列表式偏好优化(LiPO)直接在候选响应的排序列表上应用学*排序技术,相较于重复的成对比较提升了效率。RRHF将偏好对齐融入 SFT,无需单独的参考模型。PRO将列表式偏好分解为更简单的二元任务,简化了 SFT 期间的对齐过程。
负面 DPO
某些任务需要从不期望或有害的输出中学*:Negating Negatives(NN)丢弃正面响应,并最大化与较不受偏好输出的差异。负面偏好优化(NPO)对负面偏好进行梯度上升,有效减少有害输出并缓解灾难性崩溃。
PoLMs 的推理训练方法
推理是使大语言模型(LLMs)能够处理多步逻辑、复杂推断和复杂决策任务的核心支柱。本章探讨了两种提升模型推理能力的核心技术:自我优化推理,引导模型自主检测并纠正自身推理步骤中的错误;以及基于强化学*的推理,通过奖励优化提升模型链式思考的一致性和深度。这些方法共同提升了模型在长程决策、逻辑证明、数学推理等复杂任务中的鲁棒性。
推理中的自我优化
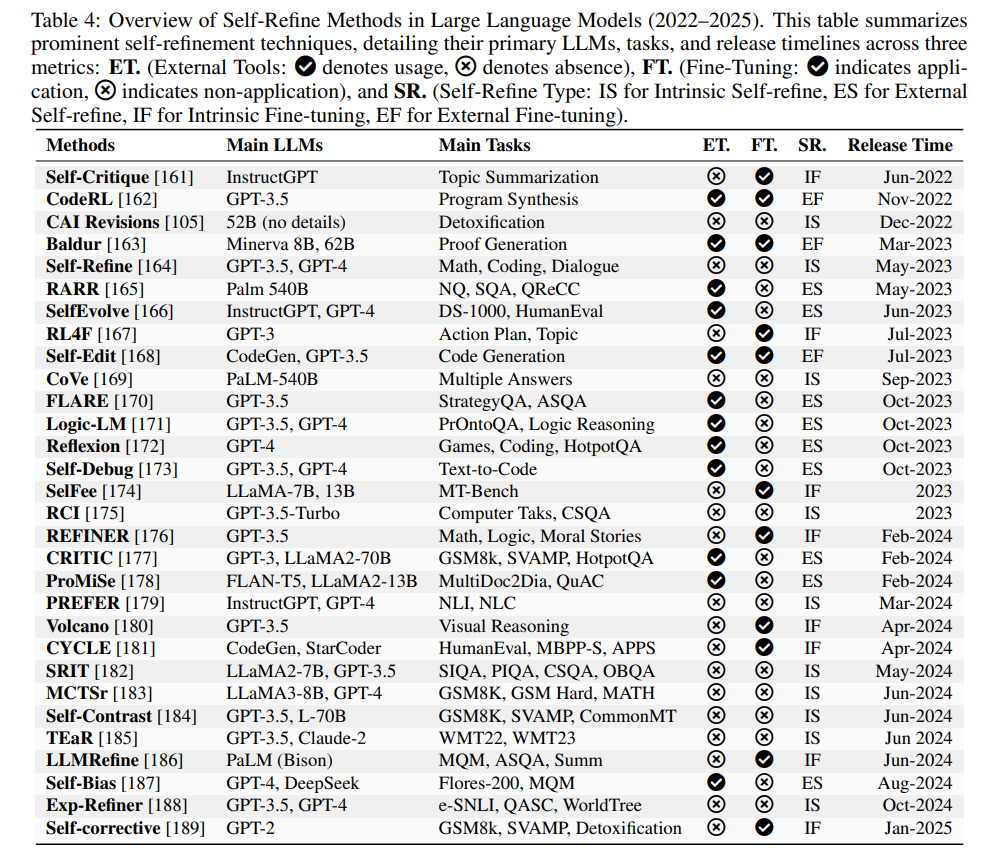
推理仍然是优化 LLMs 以应对复杂逻辑推断和情境决策任务的核心挑战。在此背景下,自我优化成为一种强大的机制,能够在文本生成过程中或之后迭代定位并纠正错误,显著提升推理深度和整体可靠性。如图12所示,自我优化方法可分为四类:内在自我优化,依赖模型自身的内部推理循环;外部自我优化,结合外部反馈资源;微调的内在自我优化,基于自生成修正迭代更新模型推理过程;以及微调的外部自我优化,利用外部信号和微调以更自适应、长期的方式优化推理。表4进一步展示了每种类别如何在不同任务中增强 LLM 的推理能力。
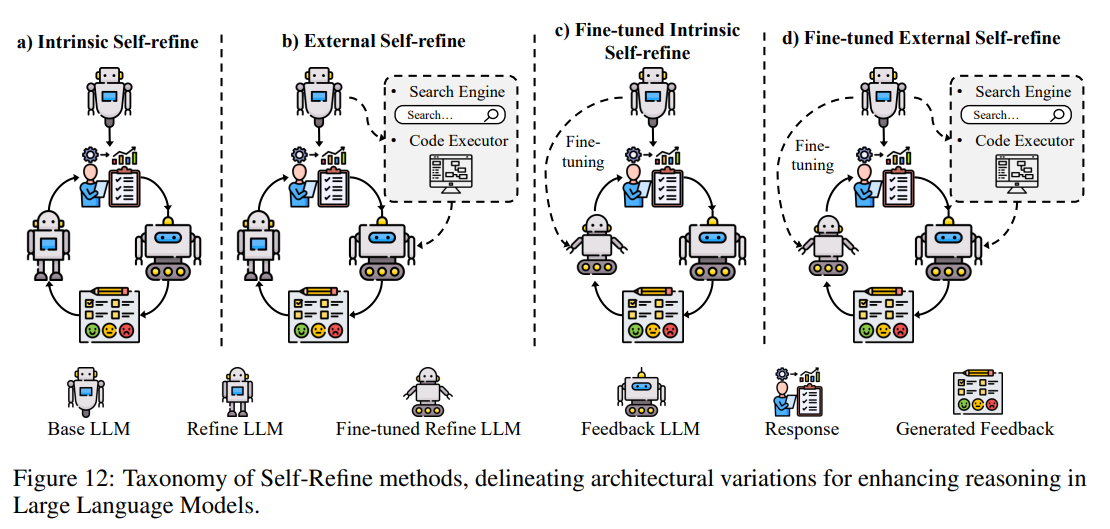
内在自我优化
内在自我优化方法专注于赋能模型自身在无需外部工具的情况下检测并修复错误。例如,RCI 提示仅在发现矛盾或错误时触发修正,避免对轻微不确定性过度反应。CAI 修订则纠正不良输出(如冒犯性文本),同时教会模型自我调节响应。同样,Self-Refine 利用从低质量提示到高保真指令的转变,优化中间逻辑以提升一致性。CoVe 通过将多答案问题拆分为子任务,并分别验证每个子任务,确保整个推理链的精确性和一致性。
弱到强泛化(W2SG)方法利用先进算法,使强学生模型能够从能力较弱的教师模型产生的噪声演示中有效学*。该框架在不同领域取得了多项关键进展和应用。*期研究通过多种创新进一步提升了 W2SG。例如,集成学*技术已成功应用于提升 W2SG 方法的鲁棒性和有效性。Zheng 等人(2024)采用弱到强外推以增强 LLMs 的对齐能力。
外部自我优化
这些方法涉及外部反馈源或计算工具来指导和纠正模型的推理。CRITIC 系统性地检查逐步输出,提升复杂推理任务的可靠性。Reflexion 和 Self-Debug 分别将生成答案与参考解或少样本示例进行比较,迭代优化逻辑。FLARE 和 Logic-LM 等技术结合外部文档或符号求解器的参考,减少逻辑失误。RARR 和 SelfEvolve 证明,验证中间状态(如编译器消息或相关知识源)是早期修剪错误路径并引导模型获得正确解答的有效方式。RLHF(2024b)提出了基于人类反馈的迭代偏好学*,包括在线场景下的迭代版直接偏好优化(DPO)算法,以及离线场景下的多步拒绝采样策略。PIT(SelfImprovement 2024a)则通过人类偏好数据隐式学*改进目标。
微调的内在自我优化
通过专门针对内部修正进行微调,这些方法系统性地强化了 LLM 的自我纠错循环。Self-Critique 旨在通过自我审查提升摘要质量,SelFee 则利用迭代反馈循环确保更高的逻辑一致性。Volcano 通过在 LLM 架构中微调专用修正模块,减少多模态幻觉,RL4F 则利用基于强化学*的批判循环,在需要深入推理的基准测试中平均提升 10% 的性能。REFINER 同样专注于中间推理路径,无需改变模型原始生成过程,证明通过训练模型仔细复查部分输出可实现持续改进。此外,易到难泛化作为 W2SG 的一种有前景的变体,模型先在易于验证的样本上训练,再处理更复杂任务。其中一个显著实现是先在可由人类验证的样本上训练强奖励模型,再用其指导更强模型完成挑战性任务。此外,W2SG 的有效性已在计算机视觉等领域得到验证。
微调的外部自我优化
在需要长期改进的场景下,模型参数通过外部反馈机制进行更新。例如,Self-Edit 根据执行结果重新生成代码输出,迭代提升正确性;Baldur 通过添加或修改上下文强化定理证明;CodeRL 在程序合成任务中采用基于测试的批判机制验证功能准确性。这些技术共同证明,结合外部资源与有针对性的微调能够促进模型整体推理性能的可靠、逐步提升。
推理中的强化学*
在上一小节中,我们探讨了自我优化(self-refine)方法,这是一种广泛用于提升大语言模型(LLM)推理能力的本地微调技术。该方法通常应用于单步任务或输出优化,如文本生成和问答,能够快速提升推理效果。然而,对于需要多步逻辑的复杂推理任务,这种方法往往力不从心。
OpenAI o1 系列的发布,凸显了强化学*(RL)作为一种强大的替代方案,通过基于奖励的反馈训练 LLM,以优化长链式的推理过程,从而显著提升在数学证明、战略规划等复杂任务中的表现。o1 的成功推动了大规模 RL 研究,QwQ-32B-Preview 等模型在数学和编程领域表现突出,DeepSeek-R1 也达到了与 o1 相当的推理能力。本节将重点分析 RL 在提升推理中的作用,聚焦于 DeepSeek-R1 及其衍生模型 DeepSeek-R1-Zero,这两者是当前开源领域的领先代表。
将推理建模为马尔可夫决策过程(MDP)
LLM 的推理过程可以优雅地建模为一个序列决策过程,模型针对输入查询 $ x $,迭代生成一系列中间步骤 $ a_1, a_2, \dots, a_T $,以最大化获得正确最终答案的概率。这一概念将推理转化为强化学*(RL)可处理的结构化框架,具体为马尔可夫决策过程(MDP),记为 $ \mathcal{M} = (\mathcal{S}, \mathcal{A}, P, R, \gamma) $。MDP 包含状态、动作、转移、奖励和时间折扣等要素,为训练 LLM 解决复杂推理任务提供了坚实的数学基础。通过将推理视为一系列有意识的选择,模型能够系统性地探索和优化逻辑路径,类似于游戏或机器人领域的决策过程,但又针对语言和概念推理的独特挑战进行了调整。最终目标是学*最优策略 $ \pi^*(a_t | s_t) $,以最大化期望累计奖励 $ J(\theta) = \mathbb{E}{\pi\theta} \left[ \sum_{t=1}^{T} \gamma^t R(s_t, a_t) \right] $,并通过 PPO 或 A2C 等 RL 技术不断提升推理能力。
状态空间
状态空间 $ \mathcal{S} $ 是 MDP 的核心,每个状态 $ s_t \in \mathcal{S} $ 代表当前推理轨迹,包括语言和结构信息。具体来说,$ s_t $ 包含初始查询 $ x $、之前的推理步骤 $ {a_1, \dots, a_{t-1}} \(,以及编码逻辑依赖和中间结论的内部记忆表示,如部分解或推断关系。状态会随着推理过程动态演化,既整合显式生成的路径,也融合上下文理解的隐含知识。例如,在数学证明中,\) s_t $ 可能包括题目陈述、已推导的方程和可用定理的记忆,确保模型在多步推理或文本生成等任务中保持逻辑连贯。
动作空间
动作空间 $ \mathcal{A} $ 定义了每一步可能的决策,动作 $ a_t \in \mathcal{A} $ 即选择下一个推理步骤。动作可以是生成自然语言片段、应用预定义的逻辑或数学变换(如代数简化)、从知识库中选取相关定理或规则,或在获得结论时终止推理。动作空间可离散(如在形式化证明中选择有限逻辑规则),也可连续(如在开放式推理中生成自由文本),体现了 LLM 的生成灵活性。这种双重性使模型能适应结构化领域(如符号逻辑)和非结构化领域(如常识推理),灵活调整策略,始终朝着问题的解决方向前进。
转移函数
转移函数 $ P(s_{t+1} | s_t, a_t) $ 描述了每次动作后状态的演化,决定了 MDP 框架下推理轨迹的推进。与传统 RL 环境中外部变量引入的随机性不同,LLM 的推理转移主要是确定性的,由模型的自回归输出或结构化推理规则驱动,如在证明中应用演绎步骤。但由于模型知识有限、状态不明确或文本生成中的概率采样,仍会出现不确定性。自回归 LLM 的转移过程通常是可预测的序列生成,但错误累积或理解偏差的可能性要求 RL 设计具备鲁棒性,以确保在多样化场景下推理的可靠性。这种“确定性中带不确定”的动态,凸显了需要自适应策略来稳定推理过程,无论是精确的数学推导还是复杂的文本生成。
奖励函数
奖励函数 $ R(s_t, a_t) $ 是 MDP 的评估核心,为每一步推理质量提供关键反馈,指导模型学*。与游戏等传统 RL 任务的显式奖励不同,推理任务的奖励设计需兼顾稀疏与密集,反映任务复杂性和目标。稀疏奖励如仅在最终答案正确时赋值,简单但在多步任务中学*速度慢;密集奖励则根据每步正确性、逻辑有效性或与人类偏好的一致性,提供细粒度指导。这种灵活性使奖励函数能适应多样推理需求,无论是证明中有效推理规则的应用,还是叙述段落的连贯性,确保模型获得有意义的信号,优化即时和长期推理策略。
折扣因子
折扣因子 \(\gamma\):标量 \(\gamma \in [0,1]\),决定即时与未来奖励的权衡。较高的 \(\gamma\) 鼓励多步推理优化,促进深层次的推理链而非短期策略。
综上,MDP 框架的目标是学*最优推理策略 \(\pi^*(a_t | s_t)\),以最大化期望累计奖励:
该框架支持应用 PPO 或 A2C 等 RL 技术,通过环境反馈不断优化 LLM 的推理能力。
推理中的奖励设计
与游戏分数等传统 RL 任务不同,LLM 推理需要结构化奖励设计,兼顾正确性、效率和信息量。常见方法包括:
- 二元正确性奖励:最终答案正确则 $ r_T = 1 $,否则为 0,简单但反馈稀疏,方差较大;
- 逐步准确性奖励:根据推理规则有效性或中间步骤一致性,逐步提供反馈,指导多步推理;
- 自一致性奖励:衡量多条推理路径的一致性,路径一致则奖励更高,提升鲁棒性;
- 偏好型奖励:基于 RLHF 或 RLAIF,由人类或 AI 反馈训练的模型 $ r_\phi(s_t, a_t) $ 评估推理质量,为复杂任务提供细致指导。
基础模型的大规模强化学*
大规模强化学*已成为提升 LLM 推理能力的变革性后训练范式,突破了传统 SFT 的局限,转向动态、自我进化的优化策略。该方法利用大规模计算框架和迭代奖励反馈,直接优化基础模型,无需预先标注数据,实现复杂推理技能的自主发展。通过大规模 RL,LLM 能解决多步推理任务(如数学问题、逻辑推理、战略规划),而传统 SFT 受限于静态人工数据。DeepSeek-R1 就是这一范式的典型代表,采用先进 RL 技术,在优化资源效率的同时实现了最前沿的推理表现(见图13)。本节将详细介绍 DeepSeek-R1 的关键方法,包括新型优化算法、自适应探索和轨迹管理,这些共同推动了 RL 驱动推理的潜力。
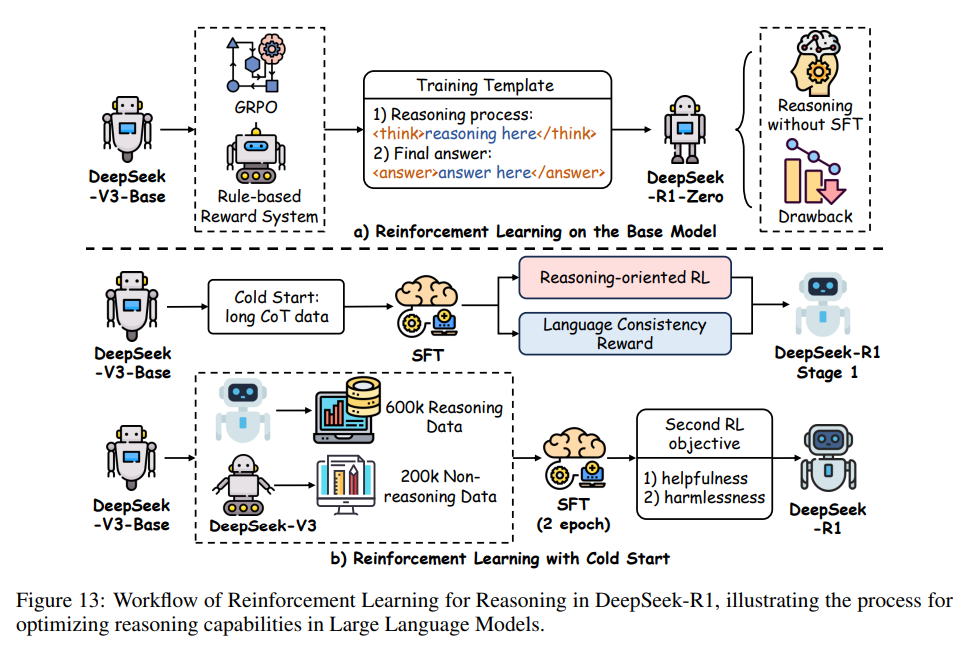
群体相对策略优化(GRPO)
DeepSeek-R1-Zero 模型采用了 Proximal Policy Optimization(PPO)的高级变体——群体相对策略优化(GRPO),以缓解传统 RL 训练 LLM 时的高计算和资源消耗。与标准 PPO 依赖大量评论网络不同,GRPO 通过群体基线估计简化优化流程,大幅降低训练开销,同时保持策略更新的鲁棒性。这种高效性使大规模 RL 能在资源有限的系统上部署,支持跨长轨迹的推理策略迭代优化。GRPO 的应用使 DeepSeek-R1-Zero 成为可扩展的推理增强方案,是当前 RL 驱动推理研究的基石(见图13)。
DeepSeek-R1-Zero
DeepSeek-R1-Zero 展现了大规模 RL 的变革潜力,无需传统 SFT 预训练,完全依靠 RL 自我进化。该方法通过奖励反馈迭代优化内部推理链,无需预标注数据,模型能自主发展复杂推理技能。在多步推理任务(如数学问题、逻辑推导)中表现显著提升,证明了 RL 能从基础模型激发高级推理能力。作为最强开源推理模型之一,DeepSeek-R1-Zero 的成功验证了冷启动 RL 策略的可行性,既节省资源,又能达到最前沿水平。
步进式奖励建模
为指导整个推理轨迹 $ \tau = (s_1, a_1, \dots, s_T, a_T) $,DeepSeek-R1 采用步进式奖励模型 $ f_\theta $,在每个时间步提供细粒度反馈,定义为 $ r_t = f_\theta(s_t, a_t \mid \mathcal{D}{\text{reasoning}}) $,其中 $ \mathcal{D}{\text{reasoning}} $ 包含人工标注的 CoT 序列及步骤级正确性标签。这种密集奖励结构不同于仅在序列末端给出奖励的稀疏方式,能即时、有效地评估每步推理质量,帮助模型精准优化策略。借助专家数据,奖励模型确保反馈符合人类推理标准,在长链推理任务中保持一致性和准确性,是解决复杂逻辑合成问题的关键。
自适应探索
DeepSeek-R1 通过自适应探索机制优化策略目标:
其中熵项 $ \mathcal{H} $ 由自适应系数 $ \lambda_t = \alpha \cdot \exp(-\beta \cdot \text{Var}(R(\tau_{1:t}))) $ 调节,依据轨迹奖励方差动态调整。该方法平衡探索与利用,训练初期鼓励多样推理路径,方差降低后收敛于最优策略,从而提升推理的鲁棒性和效率。
轨迹剪枝
为提升推理过程的计算效率,DeepSeek-R1 引入双注意力评论器 $ V_\psi(s_t) = \text{LocalAttn}(s_t) + \text{GlobalAttn}(s_{1:t}) $,结合局部步骤评估与全局轨迹上下文,综合评估每个状态的价值。当 $ V_\psi(s_t) < \gamma \cdot \max_{k \leq t} V_\psi(s_k) $ 时,剪除低价值推理路径,将资源集中于高质量轨迹。该机制减少无效探索,加速收敛,确保模型优先处理高质量推理序列,是其在复杂推理任务中表现卓越的关键。
冷启动 RL 推理
DeepSeek-R1-Zero 进一步推动 RL 应用,采用冷启动策略,完全依赖大规模 RL,从未训练的基础模型出发。该自我进化方法通过迭代反馈优化推理链,无需预标注数据,直接在推理任务上训练。DeepSeek-R1-Zero 的表现与 SFT 初始化模型(如 DeepSeek-R1)相当甚至更优,既减少了对大规模标注数据的依赖,也展示了 RL 自主发展复杂推理能力的潜力,为未来 LLM 发展提供了可扩展范式。总体而言,RL 为推理能力提升提供了有力框架,奖励设计、策略优化(如 GRPO)和探索机制至关重要。未来研究可探索融合模仿学*或自监督目标的混合方法,进一步优化推理能力,巩固 RL 在 LLM 推理中的核心地位。
提高效率的 PoLMs
在前几章讨论的后训练优化技术基础上,后训练效率专注于 LLMs 在初始预训练后的运行性能。其主要目标是优化关键部署指标(如处理速度、内存使用和资源消耗),从而使 LLMs 更适用于实际应用场景。实现后训练效率的方法主要分为三类:模型压缩(见 §6.1),通过剪枝和量化等技术减少整体计算负载;参数高效微调(见 §6.2),仅更新部分模型参数或采用专用模块,从而降低再训练成本并加快新任务适应速度;以及知识蒸馏(见 §6.3),将大型预训练模型的知识迁移到较小模型,使后者在资源消耗更低的情况下获得相*性能。
模型压缩
模型压缩是一组旨在降低 LLMs 规模和计算需求的技术,包括后训练量化、参数剪枝和低秩*似。
后训练量化
量化是 LLMs 的关键压缩方法之一,它将高精度数据类型 \(X^H\)(如 30 位浮点数)转换为低精度格式 \(X^L\)(如 8 位整数)。其转换公式为:
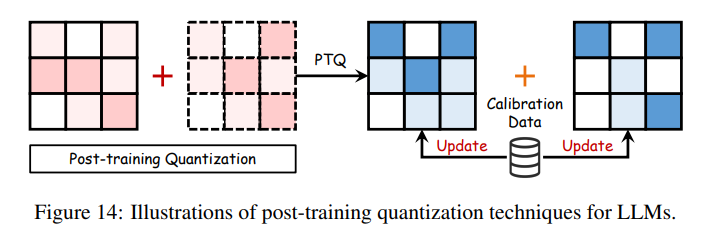
其中 \(\mathcal{K}\) 表示量化常数,\(\text{absmax}\) 指元素的绝对最大值,\(\text{Round}\) 用于将浮点数转换为整数。LLM 量化包括后训练量化(PTQ)和量化感知训练(QAT)。PTQ 在预训练后调整模型权重和激活值,利用小型校准数据集优化计算效率和性能,如图14所示。表5展示了多种主流 LLM 量化方法的性能指标。
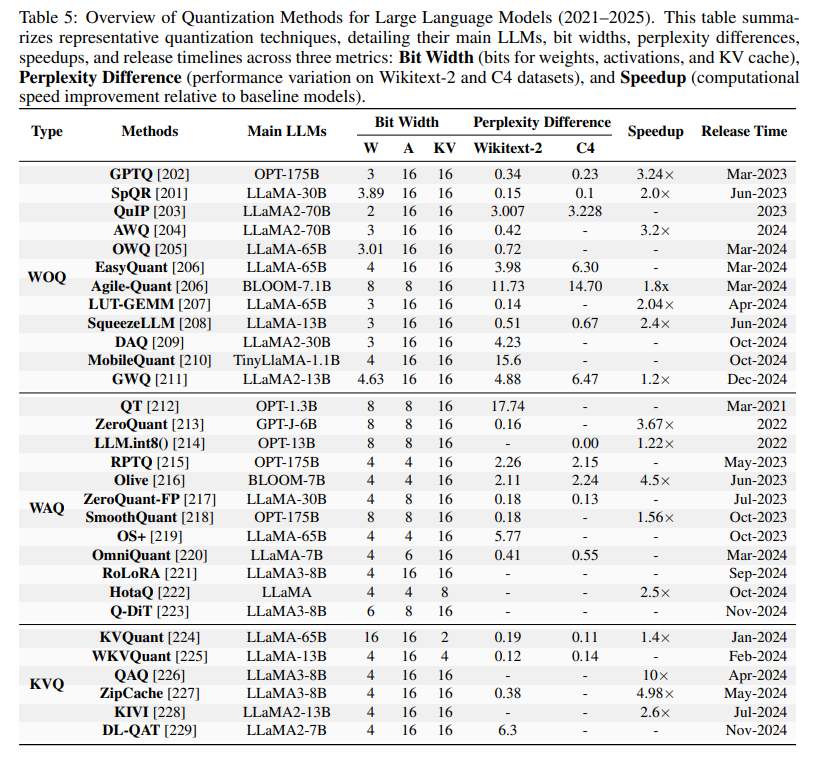
仅权重量化(WOQ):WOQ 主要压缩模型权重以提升效率。GPTQ 采用分层量化和最优脑量化(OBQ),将权重压缩至 3 或 4 位,降低内存和处理时间。QuIP 通过非一致性处理实现 2 位量化,进一步提升紧凑性。AWQ 和 OWQ 则通过对敏感权重保持高精度,减少推理时的精度损失。SpQR 结合稀疏量化与解码,实现高效逐 token 推理并保持模型响应性。
权重-激活联合量化(WAQ):WAQ 将权重和激活值联合量化以提升效率。LLM.int8() 针对激活异常值采用精确存储,并量化至 8 位以保持性能。SmoothQuant 采用逐通道缩放,将量化难点从激活转移到权重,实现无损量化。OS\(+\) 通过通道级偏移和缩放缓解异常值影响,提升效率。OmniQuant 将量化难点从激活转移到权重,并微调极值裁剪阈值。RPTQ 通过通道分组,确保量化参数的一致性,进一步提升效率。
KV-Cache 量化(KVQ):KV-Cache 量化解决了 LLMs 在输入 token 数量增加时的内存优化难题。KVQuant 针对大上下文长度推理提出专用方法,在性能损失极小的情况下实现高效推理。KIVI 通过对 key 和 value cache 分别采用不同量化策略,实现无需微调的 2 位量化和显著内存节省。WKVQuant 进一步采用二维量化和跨块正则化,带来与权重-激活量化相当的内存效率和接*的性能。
参数剪枝
参数剪枝是提升 LLMs 效率的重要技术,通过减少模型规模和复杂度而不损失精度。如图15所示,剪枝分为非结构化剪枝和结构化剪枝。
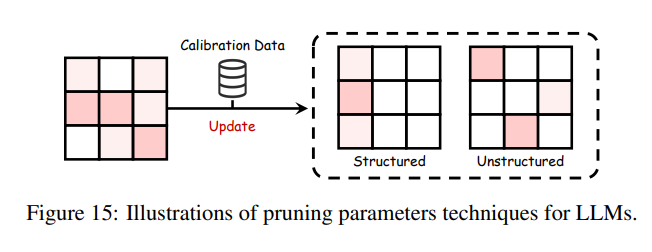
非结构化剪枝:非结构化剪枝通过去除不重要的权重提升 LLMs 的稀疏性。SparseGPT 采用一次性剪枝实现高达 60% 的稀疏度且损失极小。Wanda 基于权重幅值和激活进行剪枝,无需再训练。SAMSP 利用 Hessian 矩阵敏感性动态调整稀疏度,减少误差。DSnoT 通过迭代剪枝提升性能。Flash-LLM 则从全局内存检索稀疏权重,并在片上缓冲区密集重构以实现高效计算。
结构化剪枝:结构化剪枝针对参数组整体剪枝,提升硬件效率并简化结构。例如,LLM-runer 评估 LLaMA 重要性并用 LoRA 恢复剪枝后精度。FLAP 利用结构化指标无须微调即可优化压缩。SliceGPT 采用 PCA 剪枝并保持效率。Sheared LLaMA 通过正则化剪枝优化模型形状。LoRAPrune 基于 LoRA 重要性迭代结构化剪枝提升效率。Deja Vu 通过预测关键注意力头和 MLP 参数,利用上下文稀疏性降低延迟并保持精度。
低秩*似:低秩*似通过将权重矩阵 \(W\) *似为更小的矩阵 \(U\) 和 \(V\),实现 \(W \approx UV^\top\),从而减少参数数量并提升运行效率。例如,TensorGPT 采用张量列分解(TTD)开发更高效的嵌入格式。LoSparse 将低秩*似与剪枝结合,专注于压缩相关神经元成分。FWSVD 实现加权 SVD,ASVD 提供无训练 SVD,两者均面向后训练效率。SVD-LLM 进一步通过建立奇异值与压缩损失的直接关系提升压缩效果。
参数高效微调(Parameter-Efficient Fine-Tuning)
参数高效微调(PEFT)的过程是将大型语言模型(LLM)的主干参数全部冻结,仅对新添加的少量参数进行修改。如图16所示,PEFT 方法分为四类:加性 PEFT、选择性 PEFT、重参数化 PEFT 和混合 PEFT。
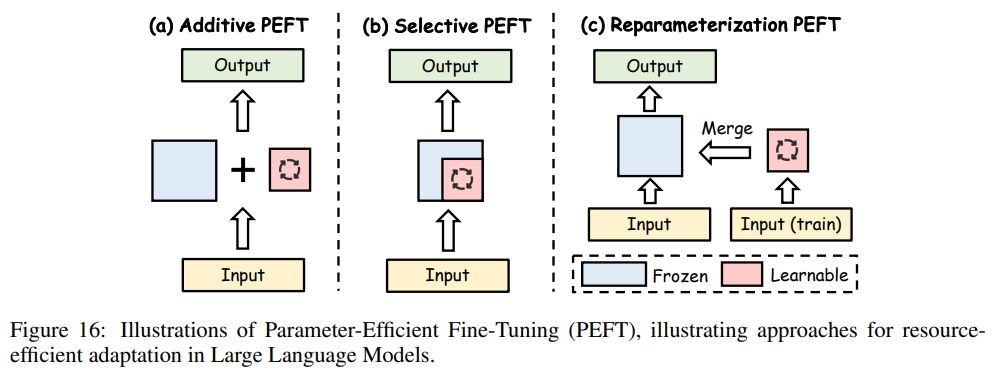
加性 PEFT
加性 PEFT 通过在 LLM 中加入新的可训练模块,而不改变原有参数,实现任务特定的微调,同时保留基础模型的知识,从而高效完成微调。
Adapters
Adapter 在 Transformer 块中集成了紧凑层,其定义如下:
其中,adapter 层包含降维投影矩阵 \(W_{\text{down}} \in \mathbb{R}^{r \times d}\)、非线性激活函数 \(\sigma\) 和升维投影矩阵 \(W_{\text{up}} \in \mathbb{R}^{d \times r}\)。\(d\) 为隐藏层维度,\(r\) 为瓶颈维度,降低复杂度同时保持性能。在此基础上,Serial Adapter 在每个 Transformer 块中引入了两个模块;AdapterFusion 通过在 \(Add \& Norm\) 后放置 adapter 提高了效率;Parallel Adapter(PA)让 adapter 与子层并行运行,CoDA 也采用了并行优化。与 AdapterFusion 不同,MerA 通过最优传输技术统一了 adapter 的权重和激活。
Soft Prompt
Soft prompt 通过在输入序列中添加可调向量(而非优化离散 token)提升模型性能,其形式化如下:
其中 \(s_i^{(l)}\) 表示 soft prompt token,\(x_i^{(l)}\) 为原始输入 token,\(N_S\) 和 \(N_X\) 分别为 soft prompt 和原始输入 token 的数量。Prefix Tuning 在 Transformer 层间引入可学*向量,通过重参数化稳定训练,并被 P-Tuning v2 和 APT 进一步优化。Prompt Tuning 则专注于初始嵌入层,实现低计算成本的大模型优化。Xprompt 和 IDPG 简化了 prompt 的生成与插入。SPoT 和 PTP 解决了稳定性和收敛速度问题,DePT 和 SMoP 通过优化 prompt 结构降低了计算需求。
其他加性方法
除上述技术外,(IA)\(^3\) 和 SSF 等方法通过对模型参数进行极小但有效的调整,实现了训练后高效微调。自注意力和前馈网络(FFN)操作定义如下:
其中 \(\odot\) 表示 Hadamard 乘积,缩放向量 \(l_k\) 和 \(l_v\) 可平滑地集成到 \(A_Q\) 和 \(A_W\) 的权重矩阵中。此外,IPA 可将 GPT-4 等 LLM 与用户需求对齐,无需更改底层模型,从而在微调过程中保持高效。
选择性 PEFT
选择性 PEFT 通过仅微调部分参数提升效率,如图16(b)所示。具体做法是对参数 \(\theta = \{\theta_1, \theta_2, \dots, \theta_n\}\) 应用二值掩码 \(M = \{m_1, m_2, \dots, m_n\}\),其中每个 \(m_i\) 表示 \(\theta_i\) 是否被选中微调。更新后的参数集表达为:
其中 \(\eta\) 为学*率,\(\frac{\partial \mathcal{L}}{\partial \theta_i}\) 为损失函数的梯度。仅选中的参数(\(m_i = 1\))会被更新,从而降低计算成本并保持有效性。早期方法包括 Diff pruning,通过可微 \(L_0\) 范数对可学*二值掩码进行正则化;FishMask 基于 Fisher 信息选择更相关参数;LT-SFT 应用彩票假设(Lottery Ticket Hypothesis)识别关键参数;SAM 采用二阶*似进行选择;Child-tuning 在子网络中动态选择参数。此外,FAR 和 BitFit 通过优化特定参数组进一步体现了选择性 PEFT 的思想。
重新参数化 PEFT
重新参数化 PEFT 主要采用低秩参数化以提升效率,如图16(c)所示。LoRA(低秩适应)引入了两个可训练矩阵,\(W_{\text{up}} \in \mathbb{R}^{d \times r}\) 和 \(W_{\text{down}} \in \mathbb{R}^{r \times k}\),并将输出修改为:
其中 \(\alpha\) 是缩放因子。这种方法允许高效地适应新任务,同时保留核心知识。在 LoRA 的基础上,Intrinsic SAID 通过最小化微调参数空间进一步降低计算需求。动态变体如 DyLoRA 和 AdaLoRA 可根据任务需求动态调整秩,AdaLoRA 还结合了基于 SVD 的剪枝以提升效率。SoRA 通过去除正交约束简化了流程,Laplace-LoRA 则采用贝叶斯校准进行微调。
Compacter 和 VeRA 进一步减少了参数复杂度。此外,DoRA 优化了方向分量的更新,HiRA 采用 Hadamard 积实现高秩更新,从而提升了效率和性能。为应对多任务和不断变化的领域,Terra 集成了时变矩阵,ToRA 则利用 Tucker 分解进一步优化 LoRA 结构。
除了结构设计外,PiSSA 和 LoRA-GA 通过 SVD 和梯度对齐优化了 LoRA 的初始化。同时,LoRA+、LoRA-Pro 和 CopRA 进一步优化了梯度更新策略。ComLoRA 则采用竞争学*机制,选择表现最佳的 LoRA 组件。
混合型 PEFT
混合型 PEFT 方法通过集成或优化多种微调策略提升后训练效率。典型方法 UniPELT 将 LoRA、前缀微调和适配器融合于 Transformer 块中,并通过前馈网络(FFN)产生标量 \(G \in [0, 1]\) 的门控机制动态激活各组件,从而优化参数利用率。另一创新方法 MAM Adapter 通过在自注意力层中战略性地放置前缀微调,并在前馈层中使用缩放并行适配器,进一步优化了该技术。此外,基于 NAS 的方法如 NOAH 和 AUTOPEFT 通过识别针对特定任务的最优 PEFT 配置提升后训练效率。HeadMap 采用贪婪方法识别关键注意力头(即知识电路),并通过将这些注意力头的输出映射回 LLM 的残差流,有效提升模型性能。最后,LLM-Adapters 提供了一个在 LLM 中集成多种 PEFT 技术的框架,确保在不同模型规模下实现最高效的模块部署。
知识蒸馏
知识蒸馏(KD)是 LLM 后训练优化的核心技术之一,能够将大型预训练教师模型的知识迁移到紧凑的学生模型中,从而在不牺牲性能的前提下提升效率。KD 最初用于模型压缩,因其能将复杂知识提炼到资源高效的架构中而备受关注,适用于边缘设备和嵌入式系统等受限环境。通过利用教师模型丰富的输出分布(比传统硬标签更具信息量),KD 使学生模型不仅能复制类别预测,还能学*教师模型中蕴含的类别间关系和细微模式。该过程通常通过优化一个复合损失函数实现,兼顾监督学*目标和蒸馏特定目标,从而在显著降低计算和内存需求的同时,保持泛化能力。
KD 的基本机制是最小化一个融合了传统分类损失和蒸馏项的混合损失。具体而言,给定教师模型的软输出概率 \(\mathbf{p_t}\)、学生模型的预测 \(\mathbf{p_s}\)、真实标签 \(\mathbf{y}\) 及学生输出 \(\mathbf{y_s}\),KD 损失表达为:
其中 \(\mathcal{L}_{CE}\) 表示与真实标签对齐的交叉熵损失,\(\mathcal{L}_{KL}\) 表示教师与学生分布间的 Kullback-Leibler 散度,\(\alpha \in [0, 1]\) 为调节两者权重的超参数。软目标 \(\mathbf{p_t}\) 通常由温度参数 \(T\) 调节(即 \(\mathbf{p_t} = \text{softmax}(\mathbf{z_t}/T)\),\(\mathbf{z_t}\) 为教师 logits),可编码更丰富的概率信息,使学生模型能够模仿教师模型的决策细节,而不仅仅是标签准确率。
KD 广泛应用于资源受限环境下的模型压缩和迁移学*场景,教师模型指导任务特定的学生模型。其有效性取决于教师模型能力、学生模型架构及蒸馏损失设计。*期进展已将 KD 扩展到输出蒸馏之外,使 LLM 的后训练优化更加高效和灵活。
KD 方法可根据对教师模型内部参数和中间表示的访问程度分为黑盒 KD 和白盒 KD。如下表6所示,知识蒸馏方法主要分为两类:黑盒 KD 和白盒 KD。我们系统性总结了 LLM 中各种知识蒸馏技术及其对应的技能、教师模型和学生模型。
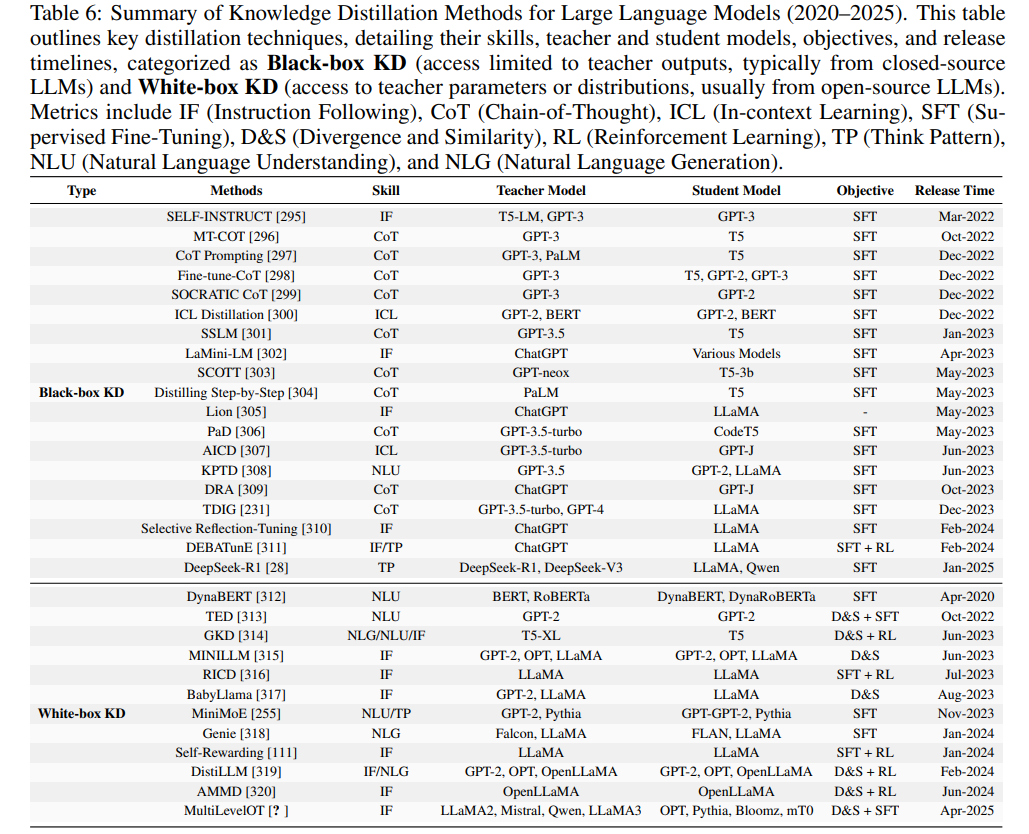
黑盒 KD
黑盒 KD 指学生模型仅从教师模型的输出 logits 学*,而无法访问其内部表示或架构细节。这种方法最初由 Hinton 提出,因其灵活性被广泛采用。黑盒 KD 的主要优势在于将教师模型视为一个不透明函数,即使教师模型为专有或预训练模型且访问受限,也能实现知识迁移。
在实际应用中,大型教师 LLM(如 ChatGPT 和 GPT-4)常用于生成高质量输出,而较小的语言模型(SLM),如 GPT-2、T5、Flan-T5 和 CodeT5,则作为学生模型。这些 SLM 在保持强泛化能力的同时优化了效率,适合部署于资源受限环境。
白盒 KD
白盒 KD 在传统蒸馏范式基础上,利用教师模型的内部表示进行更丰富的监督。当教师模型架构已知且可访问时,白盒 KD 能为学生模型提供更丰富的信息。
与黑盒 KD 仅将教师模型视为不透明函数不同,白盒 KD 允许学生模型不仅从教师输出 logits 学*,还能利用其中间激活、隐藏层甚至注意力权重。
DeepSeek-R1:推理模式的直接蒸馏
DeepSeek-R1 通过将大规模模型中的复杂推理模式蒸馏到紧凑架构中,显著提升了小型 LLM 的推理能力,而无需在小模型上直接进行高成本的强化学*。该方法称为直接蒸馏,利用由大型教师模型生成的约 80 万样本的精心数据集,其中包括 20 万条由 DeepSeek-V3 生成的非推理实例和 60 万条由 DeepSeek-R1-Stage1 检查点生成的推理实例。这些样本为 SFT 阶段提供了基础,使开源基础模型(如 Qwen 和 LLaMA mini 变体)能够继承大型模型的复杂推理能力。
DeepSeek-R1 的直接蒸馏过程如图17所示,分为结构化管道。首先,经过大规模数据预训练的教师模型生成涵盖推理与非推理输出的多样语料,捕捉逻辑模式和事实知识。非推理数据(约 20 万条)提供了通用知识基线,推理数据(约 60 万条)则包含多步推理链,体现了教师模型的高级能力。随后,这些数据用于 SFT 阶段,学生模型通过对齐输出分布进行训练,利用推理数据直接微调小模型,实现紧凑的推理模型蒸馏。与传统强化学*直接应用于小模型(因容量有限导致推理能力不足)不同,DeepSeek-R1 的直接蒸馏通过迁移预优化的推理行为,提升了性能并降低了资源消耗。
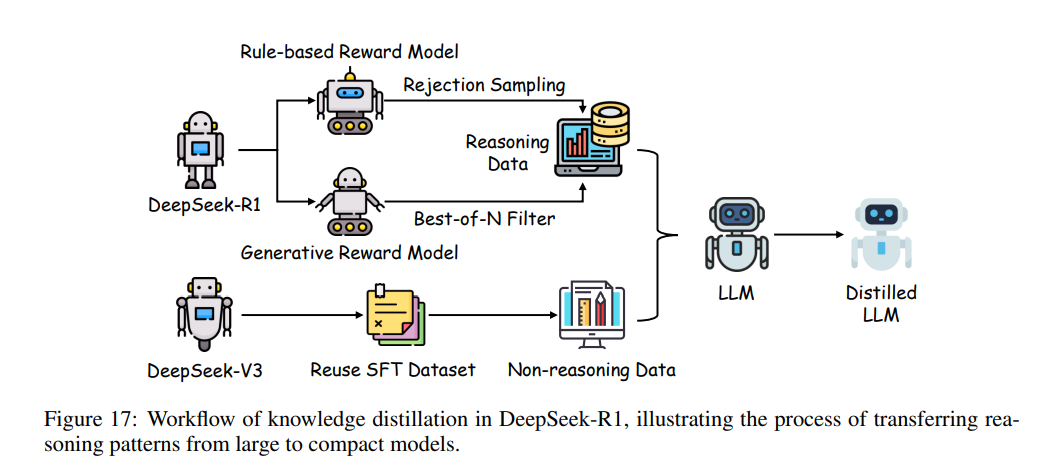
DeepSeek-R1 KD 方法的显著特点在于跨模型规模保持推理完整性。通过集成 DeepSeek-R1-Stage1(经大规模强化学*优化的检查点)的推理轨迹,学生模型不仅能复制事实准确性,还能模拟复杂的推理过程,如数学问题求解或逻辑推断。这种有针对性的迁移不同于传统 KD 侧重分类任务,凸显了 DeepSeek-R1 在推理导向蒸馏方面的创新。此外,该方法通过利用教师模型预计算的推理输出,减少了学生模型强化学*迭代需求,提升了训练效率和可扩展性。该方法为将高级推理能力蒸馏到紧凑 LLM 提供了范例,为未来后训练优化工作提供了蓝图。
集成与适应的 PoLMs
集成与适应技术对于提升大语言模型(LLMs)在多样化真实世界应用中的多功能性和有效性至关重要。这些方法使 LLMs 能够无缝处理异构数据类型,适应专业领域,并融合多种架构优势,从而应对复杂、多层次的挑战。本章阐述了三种主要策略:多模态集成(见 7.1 节),使模型能够处理文本、图像和音频等多样数据模态;领域适应(见 7.2 节),针对特定行业或用例优化模型;以及模型融合(见 7.3 节),将不同模型的能力整合以优化整体性能。这些方法共同提升了 LLMs 的适应性、效率和鲁棒性,拓宽了其在各类任务和场景中的应用范围。
多模态集成
在前述章节介绍的后训练优化策略基础上,本节探讨了旨在增强 LLMs 和大型多模态模型(LMMs)处理多模态数据能力的高级方法。尽管有监督微调提升了 LLMs 在特定任务中的表现,但其在充分发挥多模态能力方面仍有限,因此需要更复杂的后训练方法。这些技术使 LMMs 能够应对复杂的跨模态任务(如根据视觉输入生成网页代码、解读文化类表情包、无需光学字符识别进行数学推理等),通过将多样数据类型集成到统一框架中。通常,LMMs 包含模态编码器、预训练的 LLM 主干和模态连接器,如图 7.1 所示。该架构为后训练方法奠定了基础,通过优化各组件,实现强大的多模态集成与性能提升。
模态连接
模态连接方法对于将多模态数据综合为一致的表示框架至关重要,主要分为三类:基于投影、基于查询和基于融合的方法,如图19所示。
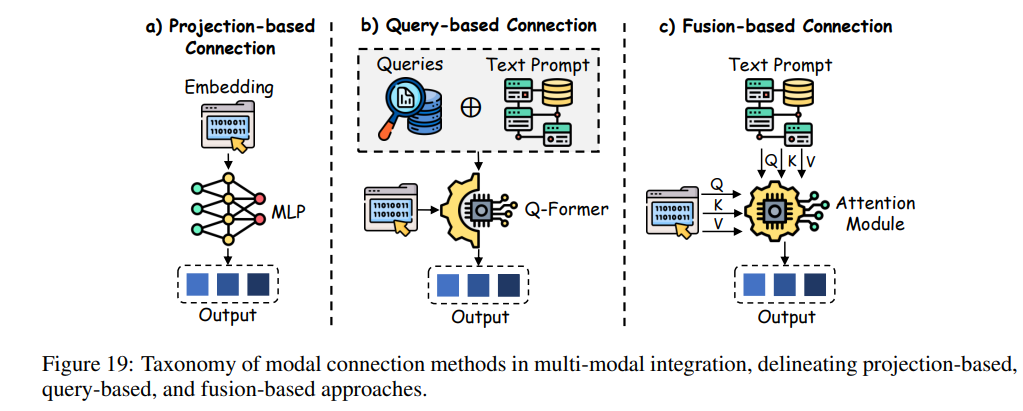
基于投影的模态连接
投影方法将不同模态输入转换为统一的文本嵌入空间,使其特征与 LLMs 的语言维度对齐,实现无缝集成。例如,LLaMA-Adapter 通过引入图像编码器,将 LLMs 扩展为多模态系统,实现基于图像的指令跟踪。其升级版 LLaMA-Adapter V2 在 LLMs 早期层嵌入视觉标签,提升视觉知识的融合。FROMAGe 通过微调冻结的 LLM 和视觉编码器的输入输出层,实现跨模态交互;LLaVA-1.5 利用双线性多层感知机(MLP)增强多模态处理的鲁棒性。Shikra 通过集成空间坐标提升自然语言对话能力,VILA 优化视觉-语言预训练以实现更强的零样本能力。DetGPT 将推理驱动的目标检测与自然语言交互结合,利用投影技术实现高效多模态通信。SOLO 采用单一 Transformer 架构,实现端到端的视觉-语言建模,直接接受原始图像像素和文本输入,无需单独的预训练视觉编码器。MiniGPT-4 通过单一投影层将冻结的视觉编码器与 Vicuna 对齐,采用两阶段训练实现 GPT-4 级能力。Idefics 以自回归设计和多阶段预训练实现高效推理。LaVIT 通过离散视觉分词器统一视觉与语言,实现无缝生成。DeepSeek-VL2 通过动态分块和多头潜在注意力提升高分辨率图像理解。Qwen2.5-VL 通过重新设计的视觉 Transformer,在感知和视频理解任务中表现突出。
基于查询的模态连接
查询方法通过可学*的查询 token 从不同模态中提取结构化信息,弥合文本与非文本数据的鸿沟。BLIP-2 首创查询 Transformer,将文本与视觉输入高效集成。Video-LLaMA 将该技术扩展到视频理解,结合多种视觉编码器;InstructBLIP 优化查询机制,确保指令精确执行。X-LLM 通过专用接口对齐多模态输入,mPLUG-Owl 和 Qwen-VL 优化 Q-Former 架构以提升计算效率。LION 进一步展示了查询方法在视觉知识融合中的有效性,提升了 LMMs 在多任务中的表现。Qwen-VL 系列基于 Qwen-7B,集成视觉感受器、位置感知适配器和三阶段训练流程,实现多语言、细粒度视觉-语言理解。Lyrics 框架通过视觉细化器(图像标注、目标检测、语义分割)和多尺度查询 Transformer(MQ-Former),提升大规模视觉-语言模型的语义感知能力。
基于融合的模态连接
融合方法通过将多模态特征直接嵌入 LLMs 架构,在推理阶段实现更深层次的跨模态交互。Flamingo 采用交叉注意力层,在 token 预测时融合视觉特征,实现动态多模态处理。OpenFlamingo 允许冻结的 LLMs 关注视觉编码器输出,提升灵活性。Otter 引入指令微调,增强多模态指令跟随能力。CogVLM 在 Transformer 层集成视觉专家模块,实现特征无缝融合。Obelics 利用交错的图文训练数据,展现了融合方法在实现一致多模态表现上的鲁棒性。InternVL 扩展视觉编码器至 60 亿参数,并通过语言中间件(QLLaMA)逐步对齐 LLMs。Llama 3 是 Meta 开发的新一代多语言、工具型基础模型,参数规模达 4050 亿,支持 128K token 上下文窗口,通过提升数据质量、大规模训练和结构化后训练策略实现优化。
模态编码器
模态编码器将原始多模态输入压缩为紧凑且语义丰富的表示,支持在多样任务和模态下高效处理。这些组件对于将异构数据转换为 LLMs 可兼容格式至关重要,应用涵盖视觉推理、音频理解等。表 7总结了主流视觉、音频及其他模态编码器的特性及其在多模态集成中的贡献。
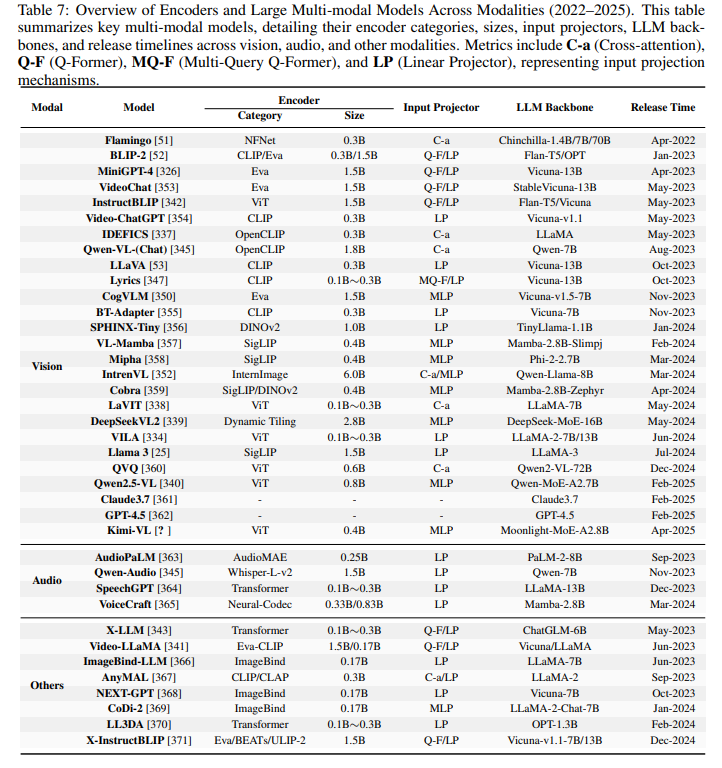
视觉编码器
视觉编码器是多模态学*的基础,使 LMMs 能够理解和生成视觉数据。CLIP 通过对比学*建立图文联合表示,提升跨模态对齐能力。EVA 优化视觉注意力机制,提高效率。ImageBind 构建多模态统一嵌入空间,提升零样本识别能力。SigLIP 引入配对 sigmoid 损失优化图文预训练,DINOv2 采用无监督学*从多源数据中提取鲁棒视觉特征。LLaVA 通过自指导策略将图像转化为文本描述,利用先进 LLMs 生成新型数据集。Video-ChatGPT 支持大规模指令数据集下的视频对话理解,BT-Adapter 通过高效时序建模优化视频理解。VideoChat 专注于时空推理,利用专用数据集,CoDi-2 和 Mipha 在多模态处理上实现效率提升。VL-Mamba 和 Cobra 引入状态空间模型优化推理,SPHINX-Tiny 强调数据多样性和训练效率。
音频编码器
音频编码器提升了 LMMs 处理和理解听觉输入的能力,拓展了多模态范围。SpeechGPT 集成大规模语音数据集与卷积、Transformer 架构,实现强大的指令跟随能力。AudioPaLM 结合文本与语音处理,采用通用语音模型(USM)编码器,在零样本语言翻译等任务中表现优异。WavCaps 利用 CNN14 和 HTSAT 缓解音频-语言数据稀缺问题,借助先进 LLMs 优化数据集质量,提升学*效果,凸显音频模态在多模态系统中的关键作用。
其他编码器
除视觉和音频外,3D 理解和多模态融合等编码器也是构建全面 LMMs 的关键。NEXT-GPT 支持文本、图像、视频和音频的跨模态内容生成,通过最小参数调整推进类人 AI 能力。ImageBind-LLM 对齐视觉与语言嵌入,提升跨模态指令跟随能力。LL3DA 处理点云数据,实现 3D 推理与规划,提出空间理解新方法。X-LLM 针对图像和视频输入采用 Q-Former,语音采用 C-Former,将音频特征压缩为 token 级嵌入,提升多模态学*效率。
域自适应
域自适应(Domain Adaptation, DA)是提升大语言模型(LLM)在特定领域表现的关键后训练策略,确保其在目标应用中的高效性。DA 基于迁移学*原理,将初始模型 $ M_{\text{source}} $ 通过适应函数 $ F_{\text{adapt}} $ 转化为领域专用模型 $ M_{\text{target}} $,如下图所示:
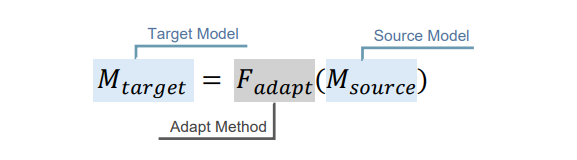
该过程使 $ M_{\text{target}} $ 能够应对指定领域的独特需求和复杂性,从而优化其性能和相关性。通过提升 LLM 在编程、数学推理等领域的能力,DA 不仅增强了领域专用能力,还提高了计算效率,克服了通用模型在领域术语和推理范式上的不足。此外,DA 显著减少了训练领域专用模型所需的大量标注数据和计算资源,成为后训练方法的核心。
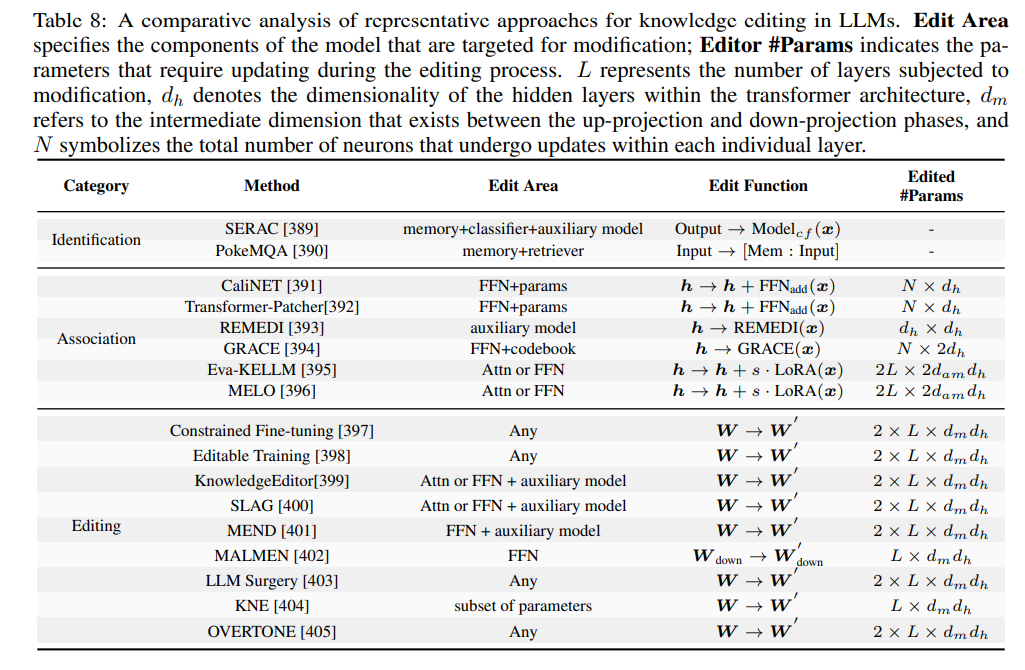
知识编辑
知识编辑是一种高级后训练方法,旨在修改 LLM 以满足领域特定需求,同时保持其基础能力。该技术通过有针对性的参数调整,既保留模型原有性能,又能快速集成新的或更新的领域知识。知识编辑支持模型对不断变化的知识环境进行快速适应,成为后训练流程不可或缺的一环。主要方法(如外部知识利用、集成和内在编辑)见表8。
知识编辑的形式化定义:
设原始 LLM 参数为 \(\theta\),在数据集 \(\mathcal{D}_{\text{old}}\) 上预训练。令 \(\mathcal{D}_{\text{new}}\) 为包含新或更新信息 \(\Delta K\) 的数据集。知识编辑的目标是通过调整 \(\Delta \theta\) 得到修正后的参数 \(\theta'\),使模型有效吸收 \(\Delta K\) 并尽量减少对 \(\mathcal{D}_{\text{old}}\) 性能的影响。形式化为约束优化问题:
其中 \(\mathcal{L}\) 表示在新数据集上的损失函数(如交叉熵)。为保护原始数据集上的性能,需满足如下约束:
\(\epsilon\) 为限制性能损失的小常数。该公式确保 \(\theta'\) 能集成新知识同时保留原有知识库。实际操作中,\(\Delta \theta\) 可限制在特定结构(如注意力层或前馈网络),以降低计算开销并避免全面重训练。
知识识别:
知识编辑的首要阶段是检测并吸收新信息。PokeMQA~ 采用可编程范围检测器和知识提示高效检索相关事实。SERAC~ 结合反事实模型和分类器,判断新知识源的适用性,采用最小侵入式方法保护基础模型,无需大规模结构修改。EvEdit~ 基于事件提出知识锚点和更新边界,解决知识更新导致的涟漪效应。
知识关联:
在识别后,将新信息与模型现有知识框架关联。Transformer-Patcher~ 适配 Transformer 架构以集成更新事实,CaliNET~ 重新校准参数以匹配事实内容。Eva-KELLM、MELO、REMEDI~ 等方法针对特定行为进行精细更新,GRACE~ 则提升知识插入后的预测准确性,实现与原有表示的无缝融合。
内在知识编辑:
最后阶段将关联后的事实嵌入模型内部结构,实现全面吸收。传统微调计算资源消耗大,先进技术可缓解此负担。受限微调和元学*减少知识丢失和过拟合风险。Editable Training 和 KnowledgeEditor 支持快速参数调整,性能影响小;SLAG、MEND、MALMEN~ 解决编辑冲突并支持大规模更新,确保基础能力的同时集成新领域知识。
LLM Surgery 通过反向梯度移除过时数据、梯度下降集成新事实,并引入 KL 散度项保护现有知识,实现高效计算。
KNE 采用知识神经元集成方法,仅定位并更新与新知识强相关的神经元,实现更精确编辑并保护无关知识。
OVERTONE 针对异质 token 过拟合问题,提出 token 级平滑技术,自适应优化训练目标,保护预训练知识并提升模型对新知识的推理能力。
这些技术确保模型在集成新知识的同时保留基础能力。
检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)将传统信息检索与现代 LLM 结合,提升生成内容的相关性和事实准确性。RAG 动态检索外部信息并嵌入生成过程,弥补 LLM 在领域知识上的不足,减少幻觉内容。该方法在需要精确、最新信息的领域(如问答系统、科学研究、医疗)表现尤为突出,能高效处理复杂查询和知识密集型任务。此外,RAG 能降低对话系统中误导性回答的发生率,提升知识驱动的自然语言生成质量。
本节聚焦于基于训练的 RAG 方法,因无训练 RAG 可能因缺乏任务优化而影响知识利用效率。三种主流训练策略——独立训练、顺序训练和联合训练——提升了模型的适应性和集成能力,见图20。
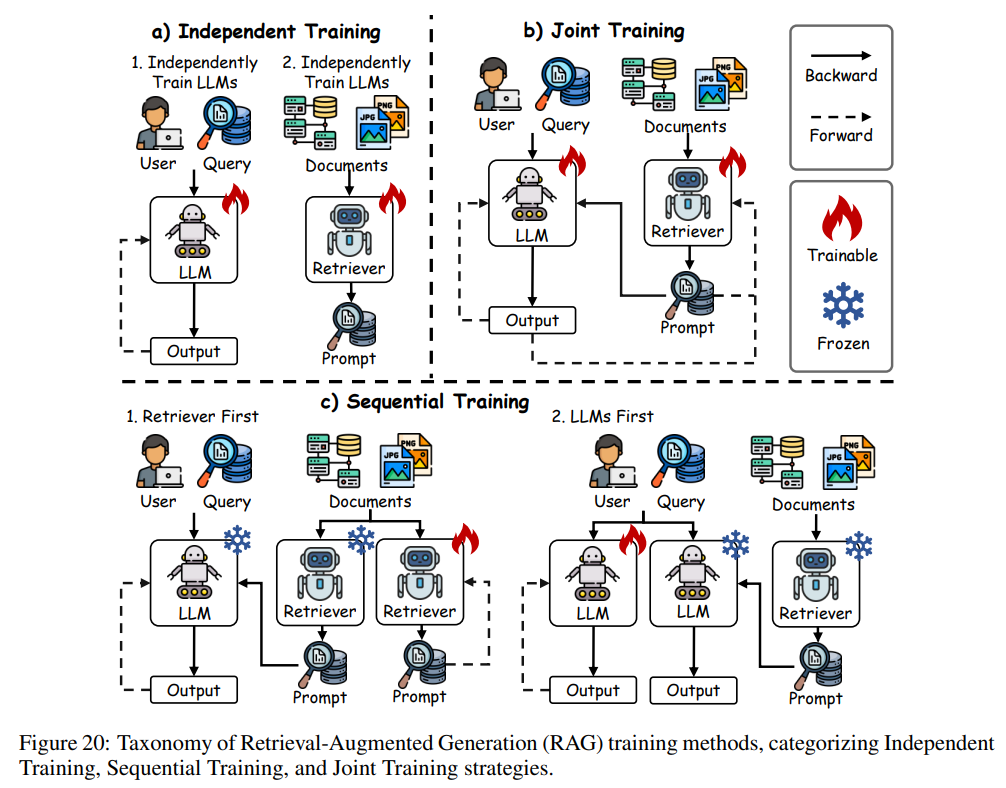
独立训练:
该策略将检索器和生成器作为独立模块训练,可灵活选择稀疏或稠密检索器以适应任务需求。DPR~ 采用双 BERT 网络分别编码查询和段落,通过对比学*优化检索,无需生成器参与。Reward-RAG 仅根据 GPT 反馈微调检索器,生成器保持不变。
顺序训练:
顺序训练通过依次优化模块提升效率,促进检索器与生成器协同。Retriever-First 方法(如 RETRO~)先预训练 BERT 检索器,再训练编码-解码器以集成检索内容,提升性能。LLM-First 方法(如 RA-DIT~)则先微调语言模型以有效利用检索知识,再优化检索器以增强一致性和连贯性。
联合训练:
联合训练在端到端框架下同步优化检索器和生成器。RAG~ 通过最小化负对数似然联合训练两者,REALM~ 则利用最大内积搜索(MIPS)提升检索精度。这些方法能根据任务需求调整,最大化外部知识利用并减少生成错误。
模型融合
模型融合已成为提升大语言模型(LLM)在训练和推理阶段性能与效率的重要后训练策略。该方法通过整合多个专用模型为统一架构,避免了大量的再训练需求,并有效应对了模型规模庞大和计算资源消耗等挑战。与在混合数据集上训练不同,模型融合是将单任务模型集成为具备多任务能力的整体,从而为多任务学*提供了一种资源高效的范式。通过简化训练流程并促进通用模型的开发,模型融合优化了 LLM 在多样化应用场景下的部署。给定候选模型集合 $ M = {M_1, M_2, \dots, M_n} $,目标是设计一个融合函数 $ F_{\text{merge}} $,生成统一模型 $ M' $,通常以基础模型 $ M_1 $ 为锚点,如下图所示:
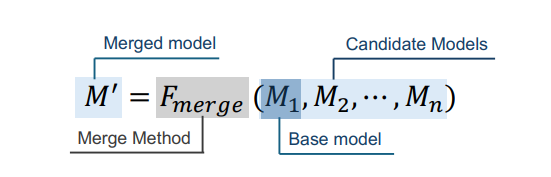
分层级的模型融合方法
模型融合技术系统性地分为三大层级:权重级、输出级和模型级融合,如图21所示。
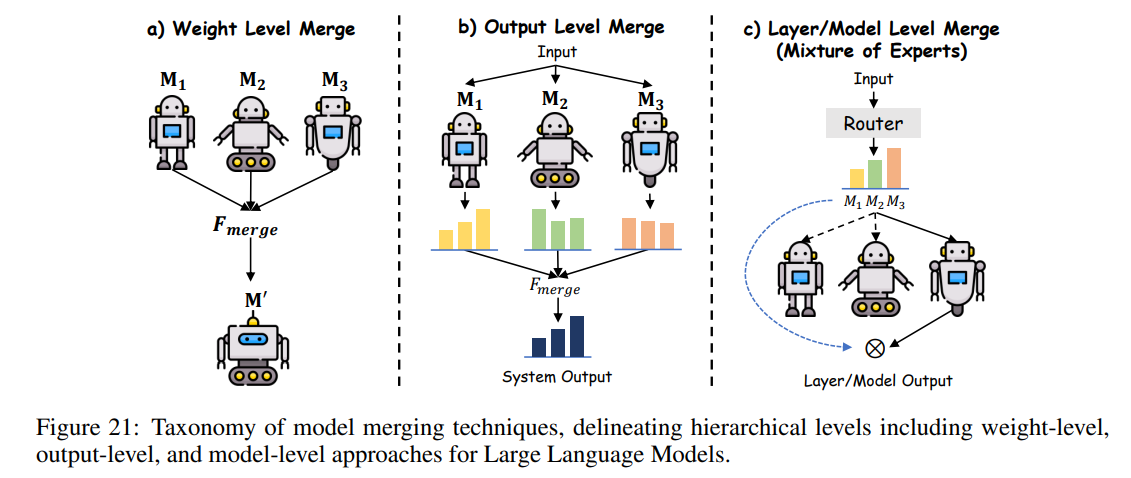
权重级模型融合
权重级融合直接操作参数空间,适用于架构相似或任务相关的模型。形式化地,给定参数集合 \(\theta_1, \theta_2, \dots, \theta_n \in \mathbb{R}^d\),线性融合方案将其聚合为统一参数 \(\theta'\):
Model Soup 通过线性组合不同任务微调后的模型权重,得到高效的单一模型。Task Arithmetic (TA) 则通过参数算术操作提升模型适应性。为缓解参数对齐问题,TIES-merging 保证参数一致性,DARE 通过概率性调整参数差异,优化融合过程的连贯性与效率。
输出级模型融合
当模型架构或初始化差异较大时,输出级融合更为适用。该方法聚合模型的输出分布而非内部参数,公式如下:
其中 $ y_1 $ 和 $ y_2 $ 分别为模型 $ M_1 $ 和 $ M_2 $ 的概率分布。类似集成策略,该方法将多个模型的预测合成为统一输出。LLMBlender 通过独立生成输出并结合排序与生成过程进行融合,FuseLLM 则将合并后的输出概率蒸馏为单一网络以保持分布一致性。FuseChat 通过将多个 LLM 的知识迁移到目标模型,实现权重与输出级的桥接,增强模型协同效应。
模型级模型融合
模型级融合通过路由机制集成子模型或层,常见于专家混合(MoE)框架,表达式如下:
其中 \(\mathrm{Merge}\) 可为硬路由或软路由函数。Switch Transformer 采用离散门控选择性激活专家层,降低计算负担,但因路由刚性可能影响性能。SoftMoE 和 SMEAR 则利用连续门控实现专家间平滑切换,提升组件整合与模型一致性。
融合前方法
融合前方法通过优化权重空间、架构一致性和参数对齐,为模型融合奠定兼容基础,减少后续融合阶段的冲突与干扰。这些技术提升了融合效果,确保统一模型保留各子模型优势并降低性能退化风险。
线性化微调
该方法在预训练模型的切线空间内微调,避免原始非线性参数空间,实现权重解耦,减少融合时的干扰。部分线性化适配器(如 TAFT)或注意力层等技术,将权重更新限定在不同输入区域,保留模型独立功能。通过线性化约束,促进多样模型的无缝集成。
架构转换
该策略将异构模型转化为可直接参数融合的同构形式。方法包括知识蒸馏(如 FuseChat)和插入恒等层(如 CLAFusion)。GAN Cocktail 通过初始化目标模型以吸收不同架构的输出,实现结构差异的统一融合。
权重对齐
该方法通过排列将模型对齐到共享权重空间,利用线性模态连通性(LMC)提升兼容性。技术包括最优传输(OTFusion)、启发式匹配(Git re-basin)和基于学*的对齐(Deep-Align)。REPAIR 针对缺乏归一化层的模型缓解对齐失败,确保融合前参数的稳健收敛。
融合中方法
融合中方法聚焦于动态优化参数融合策略,解决任务冲突、减少干扰,并提升融合模型的性能与泛化能力。这些方法应对实时整合不同模型的挑战,增强统一架构的适应性与鲁棒性。
基础融合
该方法采用参数平均或任务向量算术,任务向量 \(\tau_t\) 定义为第 \(t\) 个任务微调参数 \(\Theta^{(t)}\) 与初始参数 \(\Theta^{(0)}\) 的差异:
多任务学*可通过 \(\Theta^{(\text{merge})} = \Theta^{(0)} + \lambda \sum_{t=1}^T \tau_t\) 实现。尽管计算高效且概念简洁,但该方法易受任务间参数干扰影响,限制了在复杂任务场景下的应用。
加权融合
该策略根据各模型的重要性动态分配融合系数,优化融合结果。MetaGPT 通过归一化每个任务向量的平方 L2 范数计算最优权重:
参数变化较大的任务获得更高权重。SLERP 采用球面插值实现参数平滑过渡,保持模型连续性,Layer-wise AdaMerging 则在每层优化系数,提升融合的任务精度。
子空间融合
该方法将模型参数投影到稀疏子空间,减少干扰并保持计算效率,解决参数贡献重叠问题。TIES-Merging 保留幅值最大的 20% 参数并解决符号冲突,DARE 缩放稀疏权重以减少冗余,Concrete 通过双层优化生成自适应掩码,确保模型组件的精细整合并降低任务间干扰。
路由式融合
该技术根据输入特征动态融合模型,实现上下文响应式集成。SMEAR 计算样本依赖的专家权重以突出关键特征,Weight-Ensembling MoE 通过输入驱动路由线性层实现选择性激活,Twin-Merging 融合任务共享与任务私有知识,构建灵活的融合框架,提升多任务鲁棒性。
后校准
该方法在融合后通过对齐统一模型与独立模型的隐藏表示,纠正表示偏差,缓解性能下降。Representation Surgery 通过提升表示一致性,增强融合模型的鲁棒性与准确性。
数据集
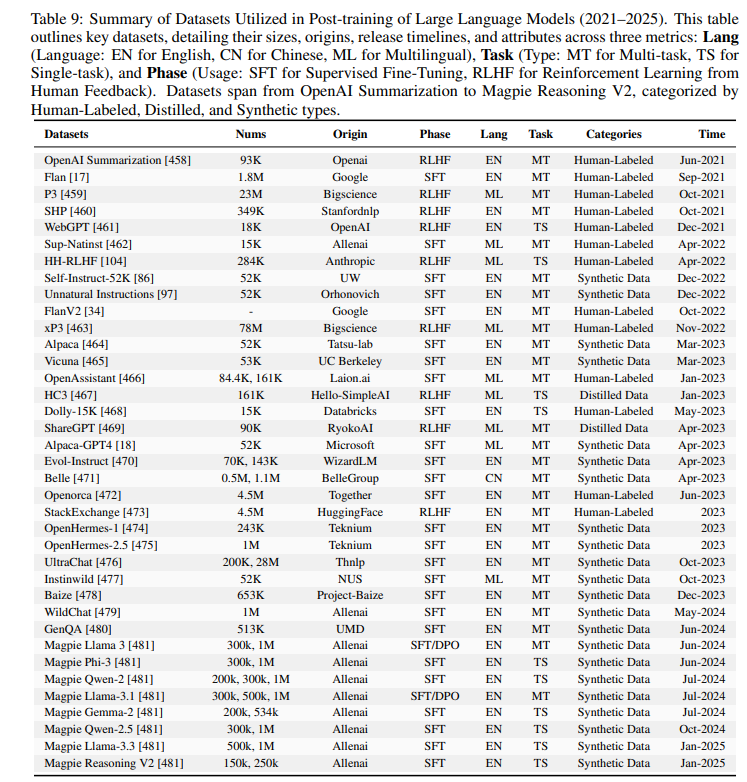
后训练技术被精心设计用于提升大语言模型(LLM)在特定领域或任务上的适应能力,而数据集则是这一优化过程的基石。大量研究表明,数据的质量、多样性和相关性深刻影响模型效果,往往决定了后训练工作的成败。为阐明数据集在此过程中的关键作用,本文对后训练阶段所用数据集进行了全面回顾和深入分析,并根据其收集方式将其分为三大类:人工标注数据、蒸馏数据和合成数据。这些类别反映了数据策划的不同策略,模型可采用单一方法或多种类型的混合方法,以在可扩展性、成本和性能之间取得平衡。表 9详细概述了这些数据集类型,包括其来源、规模、语言、任务及后训练阶段(如 SFT 和 RLHF),后续章节将进一步探讨它们在提升 LLM 能力方面的贡献与挑战。
人工标注数据集
人工标注数据集以其卓越的准确性和上下文契合度而著称,这些优势源于标注者对任务细节的深刻理解及其进行精确、情境化调整的能力。此类数据集是优化指令微调的基石,通过提供高质量、专家策划的训练信号,显著提升了 LLM 在多样任务上的表现。在这一类别中,Flan、P3(Public Pool of Prompts)、Sup-Natinst(Super-Natural Instructions)和 Dolly-15K 等数据集作为后训练阶段广泛采用的代表性资源,各自通过人类专业知识为模型能力优化做出了独特贡献。
SFT 阶段的人工标注数据。 在 SFT 阶段,人工标注数据集发挥着不可或缺的作用,如 Flan、Sup-Natinst 和 Dolly-15K 提供了精心设计的提示-响应对和任务指令,提升了 LLM 在多样 NLP 基准上的效果。
-
Flan
Flan 数据集是基础资源,最初包含 62 个广为认可的 NLP 基准(如 HellaSwag、MRPC、ANLI),以 180 万个样本支持英语多任务学*。*期,FlanV2 作为升级版本,将 Flan、P3、Sup-Natinst 及众多其他数据集整合为统一语料库,极大提升了其在多语言和多任务领域的 SFT 实用性。 -
Sup-Natinst
Super-Natural Instructions(Sup-Natinst)涵盖 76 种任务类型,涉及 55 种语言,是多语言 LLM 后训练的多样化资源。每个任务都配有清晰的任务定义(描述输入到输出的映射)及一组示例,展示正确与错误的响应,为模型精准执行任务和提升跨语言适应性提供了坚实基础。 -
Dolly-15k
Dolly-15K 由 Databricks 员工开发,包含 1.5 万个人工生成的高质量提示-响应对,专为 LLM 指令微调设计。涵盖头脑风暴、内容生成、信息抽取、开放式问答和摘要等多种主题和场景,任务类型丰富,帮助模型灵活适应多样化指令环境,提升上下文相关性。
人工标注数据集在 SFT 阶段的强大作用,源于其广泛覆盖的任务和场景。补充资源如 OpenAssistant 提供了全球众包的多语言对话语料库,免费用于研究;OpenOrca 则通过数百万 GPT-3.5 和 GPT-4 的补全扩展了 FlanV2,成为微调和任务对齐的动态资源。然而,尽管这些数据集对模型泛化能力贡献巨大,如何确保标注质量和多样性仍是挑战,需要严格的质量控制以最大化其影响力。
RLHF 阶段的人工标注数据。
在 RLHF 阶段,P3、其多语言扩展 xP3 以及 SHP 等人工标注数据集为 LLM 提供了关键的人类评价,优化模型与用户偏好的对齐,为奖励建模提供了细致反馈机制。
-
P3
P3 数据集是精心策划的指令微调资源,汇集了来自 Hugging Face Hub 的 2300 万多任务提示,每条都配有人工编写的指令,涵盖多样 NLP 任务,为 RLHF 提供了丰富基础,提升模型适应性和精度。 -
xP3
xP3(Crosslingual Public Pool of Prompts)将 P3 扩展为多语言框架,覆盖 46 种语言和 16 种 NLP 任务,支持 BLOOMZ 和 mT0 等模型的多任务提示微调。内容包括英文 P3 数据集、4 个新英文任务(如翻译、程序合成)及 30 个多语言 NLP 数据集,是跨语言 RLHF 优化的综合资源。 -
SHP
SHP 包含 34.9 万个人类偏好标注,针对 18 个主题领域的问题和指令响应进行评价,用于训练 RLHF 奖励模型和评估自然语言生成(NLG)质量。其独特之处在于完全依赖人类创作数据,与 HH-RLHF 等混合数据集形成对比。
这些数据集通过多样化的人类评价,提升了 RLHF 阶段模型与用户偏好的对齐。OpenAI Summarization 和 Webgpt 提供结构化的比较反馈和李克特量表评分,有助于模型输出更贴*人类期望。HH-RLHF 进一步通过有益性和无害性评价,为安全和伦理模型奠定基础。StackExchange 则贡献了领域特定的用户生成内容,丰富了训练数据,尤其适用于需要技术领域专业知识的模型。然而,这些数据集在可扩展性、标注偏见和领域适用性方面仍面临挑战,因此在实现模型全面对齐时,可能需要更广泛的数据集进行补充。
蒸馏数据集
蒸馏数据集是通过对庞大的原始数据集进行复杂处理,提炼出紧凑且优化的子集,既保留了对大语言模型(LLM)训练至关重要的信息,又兼顾了性能和训练效率,降低了计算资源消耗。这种方法得到的数据集在效果上常常能媲美甚至超越未蒸馏的数据集,加速模型收敛,尤其在 RLHF 阶段显著减少资源消耗。典型代表如 ShareGPT 和 HC3(人类-ChatGPT 对比语料库),通过提炼真实交互和对比信息,为 LLM 微调提供了高效的训练信号。
-
ShareGPT
ShareGPT 是一个动态数据收集平台,通过 API 汇集了约 9 万条真实用户与 ChatGPT 或 GPT-4 的对话。数据包含真实的人类指令和问题,以及对应的 AI 回复,将自然对话模式浓缩为高质量资源,使 RLHF 能有效提升 LLM 的对话流畅性和上下文响应能力。 -
HC3
HC3 数据集专为对比 ChatGPT 生成的回复与人类撰写的答案而设计,涵盖 16.1 万组问答对,领域包括开放话题、金融、医学、法律和心理学。该蒸馏语料库便于分析回复特征和质量,帮助研究者提升 LLM 的输出真实性和领域准确性,同时突出人类与 AI 内容的差异。
合成数据集
合成数据在 LLM 微调(SFT)阶段具有变革性价值,由 AI 模型自动生成,提供了低成本、可扩展且保护隐私的替代方案。通过自动化生成指令-回复对和多轮对话,合成数据能扩展训练语料,增强模型适应性。Self-Instruct-52K、Vicuna 和 Baize 是提升 LLM 指令遵循和对话生成能力的代表性合成数据集。
基于 Self-Instruct 方法的数据集
Self-Instruct 方法的合成数据集以少量人工编写的种子样本为起点,利用 LLM 扩展出大量指令遵循数据,提升模型对多样化指令的响应能力。典型数据集包括 Self-Instruct-52K、Alpaca 及 Magpie 系列,通过自动化规模化推动指令微调的发展。
-
Self-Instruct-52K
Self-Instruct-52K 以人工种子和多样化提示模板为基础,生成 5.2 万条指令样本,显著提升模型对任务指令的理解和执行能力。 -
Alpaca
Alpaca 及 Alpaca-GPT4 从 175 组种子扩展出 5.2 万条高质量指令-回复对,分别采用 GPT-3 和 GPT-4 生成,增强了模型的指令遵循能力。InstInWild 则将该方法应用于多语言场景,生成英中双语数据,提升跨语言适应性。 -
Magpie 数据集
Magpie 数据集利用对齐的 LLM,通过预设模板生成指令-回复对,形成如 Magpie Reasoning V2(注重链式推理)、Magpie Llama-3 和 Qwen-2 系列(针对主流模型)、Magpie Gemma-2(适配 Gemma 架构)及 Magpie-Air-DPO(融合偏好优化信号)等专用数据集,全面提升 SFT 和指令微调在对话与推理任务中的表现。
此外,Unnatural Instructions(24 万例)、Evol-Instruct(7-14.3 万例,采用复杂度迭代提升)、Belle(50-110 万条中文对话,源自 ChatGPT)等数据集极大扩展了指令生成规模,但在质量控制、复杂度调节和偏见消除方面仍面临挑战,需持续优化以确保在复杂应用中的可靠性。
基于 Self-Chat 方法的数据集
Self-Chat 数据集采用模型自我模拟多轮对话或与其他模型互动,提升对话生成能力,弥补现有语料的不足。Baize、UltraChat 和 OpenHermes 是通过自动化交互策略构建的代表性数据集。
-
Baize
Baize 利用 ChatGPT 的 Self-Chat 技术生成 65.3 万组多轮对话,融合 Quora、Stack Overflow 和 Alpaca 的种子数据,提升了模型的指令遵循和对话连贯性,优化 SFT 效果。 -
UltraChat
UltraChat 通过多个 ChatGPT API 生成逾 1200 万条高质量对话,涵盖多样话题,有效解决了多轮数据集常见的质量低和标注不准问题,为对话增强提供了坚实的 SFT 资源。 -
OpenHermes
OpenHermes 由 Teknium 开发,包括 OpenHermes-1(24.3 万条)和扩展版 OpenHermes-2.5(100 万条),覆盖广泛主题和任务类型,为对话和指令遵循能力提升提供了高质量 SFT 数据。
这些 Self-Chat 数据集通过模型自我交互(如 Baize 的多样种子和 UltraChat 的 API 批量生成),显著提升了多轮对话质量,填补了训练数据的关键空白。
基于真实用户交互的数据集
真实用户交互数据集收集了用户与 LLM 的真实对话,捕捉多样且真实的输入,提升模型应对实际场景的能力。Vicuna、WildChat 和 GenQA 是此类数据集的代表。
-
Vicuna
Vicuna 基于 ShareGPT 公共 API 收集的约 7 万条用户对话,经过 HTML 转 Markdown、低质量样本过滤和长对话分段处理,确保了高质量的 SFT 数据,适用于真实交互建模。 -
WildChat
WildChat 包含 100 万条多语言、多类型的真实用户-ChatGPT 交互,涵盖模糊请求、语码转换等独特场景,既可作为 SFT 资源,也可用于用户行为分析。 -
GenQA
GenQA 提供逾 1000 万条清洗过滤后的指令样本,完全由 LLM 自动生成,无需人工或复杂流程,快速补充了现有语料的覆盖空白。
合成数据在成本、扩展性和隐私方面具有显著优势,但在深度和真实性上可能不及人工标注数据,存在偏见传播和过度简化的风险。过度依赖 AI 生成内容可能加剧模型固有错误,因此需将合成与人工数据结合,提升 LLM 的鲁棒性和多场景适用性。
应用领域
尽管预训练赋予了大型语言模型(LLMs)强大的基础能力,但在专业领域部署时,LLMs仍面临诸多限制,包括上下文长度受限、易产生幻觉、推理能力不足以及固有偏见等。这些缺陷在实际应用中尤为重要,因为精确性、可靠性和伦理一致性至关重要。这些挑战引发了根本性问题:(1)如何系统性提升LLM以满足特定领域需求?(2)有哪些策略能有效缓解实际应用中的障碍?后训练成为关键解决方案,通过优化模型对领域术语和推理模式的识别能力,同时保留广泛能力,增强LLM的适应性。本章将阐述后训练LLM在专业、技术和交互领域的变革性应用,说明定制化后训练方法如何应对上述挑战,并提升模型在多样化场景中的实用价值。
专业领域
法律助手
法律领域是利用后训练赋予LLM专业知识的典型场景,使其能够应对法律知识的复杂性和司法实践中的多重挑战。大量研究已探索LLM在法律问答、判决预测、文档摘要等任务中的应用,以及检索增强和司法推理等更广泛任务。经过后训练的法律助手,如 LawGPT 和 Lawyer-LLaMA,展现出卓越的专业能力,不仅能在多种法律事务中提供可靠建议,还能在专业资格考试中取得优异成绩,体现了其高级解读和分析能力。多语言支持(如 LexiLaw 和 SAUL)进一步扩展了模型在英语和中文等语言中的适用性。核心进展在于基于精选法律语料进行后训练,如 ChatLaw,将大量法律文本整合为对话数据集,使模型在推理和术语识别方面得到优化。
医疗健康
后训练显著提升了LLM在医疗健康领域的表现,利用领域数据精准满足临床和学术需求。在临床场景中,LLM可用于药物发现、药物协同预测与催化剂设计、诊断支持、病历生成和患者交流;在学术领域,则在医学报告生成和问答等任务中表现突出,得益于定制化后训练带来的性能提升。例如,ChatMed在50万条医疗咨询记录上训练,诊断和咨询准确性显著提升;PULSE在400万条涵盖中文医学和通用领域的指令上微调,展现出多任务能力。这些模型通过嵌入细致医学知识的后训练,远超通用模型,凸显了定制数据集在实际应用中的不可替代性。此类进展不仅改善了任务效果,也推动LLM融入医疗流程,确保精确和上下文相关性,彰显后训练在医疗领域的变革作用。
金融与经济
在金融与经济领域,LLM在情感分析、信息抽取和问答等任务中展现出巨大潜力,后训练通过领域优化进一步提升了模型效能。通用LLM虽具备基础能力,但如 FinGPT 和 DISC-FinLLM 等专业模型在金融语料后训练后,在市场动态和术语理解等任务上表现更佳。XuanYuan同样通过大规模金融数据集和先进后训练技术,提升了经济建模和预测的准确性,超越未微调模型。这些进展表明,后训练对于适应金融应用的复杂需求至关重要,确保模型在定量和定性分析中具备行业标准的可靠性和专业性。
移动代理
大型多模态模型(LMMs)的发展推动了基于LMM的图形用户界面(GUI)代理的研究,旨在开发能在多种GUI环境(包括网页、个人电脑和移动设备)执行任务的AI助手。在移动场景下,一类研究通过工具集成和额外探索阶段提升单一代理的感知和推理能力。*期进展通过多代理系统实现决策和反思,显著提升任务效率。MobileAgent-E引入了代理间的分层结构,实现了长远规划和低层级动作的高精度。这些进展凸显了多模态后训练策略在打造适应性强、高效的移动智能代理中的关键作用。
技术与逻辑推理
数学推理
LLM在数学推理(如代数、微积分和统计分析)方面展现出巨大潜力,后训练在提升模型计算与类人推理能力方面至关重要。GPT-4在标准化数学测试中取得高分,得益于多样化的预训练语料,后训练则进一步提升了其能力。DeepSeekMath通过专业数学数据集和如监督微调(SFT)、群体相对策略优化(GRPO)等技术,增强了推理精度,能以结构化思路解决复杂问题。OpenAI的o1通过强化学*(RL)不断优化推理策略,在多步推导和证明中表现优异。持续的后训练不仅提升了准确性,还使LLM输出更符合严谨的数学逻辑,使其成为教育和科研领域中不可或缺的高级推理工具。
代码生成
后训练彻底改变了代码生成领域,使LLM在自动编程、调试和文档生成方面表现卓越,极大地提升了软件开发效率。Codex在大规模多样化代码库上训练,为 GitHub Copilot 提供了强大的实时编程辅助能力。Code Llama等专业模型通过编程数据集后训练,进一步优化了对多种语言和框架的支持。OpenAI的o1将其数学推理能力扩展到代码生成,能生成高质量、上下文相关的代码片段,媲美人类开发者。当前研究聚焦于提升个性化、深化上下文理解,并嵌入伦理保障以防止代码滥用,确保LLM在技术领域既能提升生产力,又能遵循负责任开发原则。
理解与交互
推荐系统
LLM在推荐系统中发挥了变革性作用,能分析用户行为、产品描述和评论,提供高度个性化的建议。后训练增强了模型整合情感分析的能力,使其能细致理解内容和情感色彩,如GPT-4及LLaRA、AgentRec等专业系统。亚马逊和淘宝等电商巨头利用这些能力处理评论情感、搜索查询和购买历史,优化用户偏好模型并高精度预测兴趣。除了商品排序,后训练LLM还能进行对话式推荐、规划和内容生成,提升用户体验,实现动态、上下文敏感的交互,充分体现后训练在数据分析与实际应用之间的桥梁作用。
语音对话
后训练LLM重塑了语音处理领域,在识别、合成和翻译方面实现了前所未有的自然度和准确性。模型可完成文本转语音、文本生成音频和语音识别等任务,支撑了亚马逊Alexa、苹果Siri和阿里天猫精灵等主流工具。Whisper以高保真转录为代表,GPT-4o则实现了实时语音交互,融合多模态输入。未来发展方向包括多语言翻译和个性化语音合成,后训练使LLM能打破语言壁垒,针对用户特征定制响应,提升全球人机交互的可达性和参与度。
视频理解
LLM在视频理解领域的拓展是重要前沿,后训练使如Video-LLaMA等模型能进行视频字幕、摘要和内容分析,简化多媒体创作与理解。Sora更进一步,可根据文本提示生成复杂视频,降低技术门槛,推动创新叙事。这些进展通过后训练使LLM适应视觉-时序数据,提升了解读深度和应用价值,广泛应用于教育和娱乐等领域。然而,这也带来了计算可扩展性、隐私保护和伦理治理等新挑战,尤其是生成内容的滥用问题。随着后训练方法不断发展,解决这些问题将是确保视频相关应用可持续、负责任部署的关键,需在创新与社会责任之间取得平衡。
未解决问题与未来方向
在本节中,我们对大语言模型(LLMs)后训练方法中尚未解决的挑战和未来发展方向进行了批判性评估,分析重点聚焦于 OpenAI 的 o1 和 DeepSeek-R1 等模型带来的变革性进展。这些模型通过大规模强化学*(RL)重塑了推理基准,但它们的出现也加剧了后训练技术中持续存在的局限性亟需解决的紧迫性。以下小节阐述了七个关键的开放问题,每一项都对领域发展至关重要,并提出了可行的研究策略,以推动未来研究并确保 LLMs 在多样化应用中的负责任演进。
超越大规模强化学*的推理能力提升。
o1 和 DeepSeek-R1 的推出标志着 LLM 推理能力的范式转变,利用 RLHF 和群体相对策略优化(GRPO)等强化学*框架,在多步问题求解(如数学证明和逻辑推导)方面取得了前所未有的准确性。然而,对二元奖励信号和大量人工反馈的依赖暴露了一个关键局限:难以在复杂、开放式任务(如科学假设生成或动态环境中的战略决策)中实现有效泛化。随着 LLMs 在现实世界场景中模拟类人推理的需求增长,这一问题变得尤为紧迫。当前 RL 方法面临奖励稀疏和任务复杂性适应性不足的问题,亟需创新框架。可行的解决方案包括开发多目标 RL 系统,结合自监督一致性检查(如推理步骤间逻辑一致性验证)和领域特定先验(如数学公理或科学原理),以在无需大量人工标注的情况下引导推理。这些进展有望减少对昂贵反馈环的依赖,提升可扩展性,并使 LLMs 能够应对未知推理领域,DeepSeek-R1 的冷启动 RL 创新为此提供了现实可能。
下一代 LLMs 后训练的可扩展性。
随着 LLMs 规模和复杂度不断提升,以 DeepSeek-R1 的参数密集型架构为代表,后训练的可扩展性成为一项艰巨且紧迫的挑战。RL 方法(如 DeepSeek-R1 的冷启动策略)资源消耗巨大,限制了资源有限的群体获取,尤其在多模态应用(如视频分析)和实时系统(如对话代理)中尤为突出。这一问题至关重要,因为它可能加剧资源丰富与资源匮乏研究社区之间的鸿沟,阻碍 LLMs 的公平发展。参数高效微调(PEFT)虽能缓解部分负担,但在大规模数据集上表现常常下降,凸显了可扩展替代方案的需求。未来可行方向包括设计轻量级 RL 算法(如对 GRPO 进行内存优化)、分布式后训练框架(通过去中心化网络分担计算负载)、以及先进的蒸馏技术(在降低资源消耗的同时保留推理和适应性)。这些方案若能实现,将有助于推动后训练的民主化,满足领域对可持续和包容性创新的迫切需求。
RL 驱动模型的伦理对齐与偏见缓解。
以 RL 为后训练手段(如 o1 的审慎对齐策略)会加剧训练数据(如 HH-RLHF 或合成语料)中固有偏见的风险,这在 LLMs 应用于医疗诊断、司法决策等敏感领域时尤为紧迫。伦理对齐的动态性——在一个文化环境下的公平可能在另一个环境中构成偏见——成为实现普遍可信 LLMs 的重大障碍,对确保 AI 系统的公平与安全至关重要。现有方法可能导致过度审查(如抑制创造性输出)或矫正不足(如延续有害偏见)。解决这一问题需要开发公平感知 RL 目标,结合多利益相关者偏好模型(如汇聚多元人类判断)和对抗性去偏技术,在训练过程中消除数据偏见。*期可解释性工具和多目标优化的进展为这些方法的可行性提供了支持,有助于在伦理稳健性与实用功能之间实现平衡,这也是 o1 在实际部署中面临的关键挑战。
多模态无缝集成以实现整体推理。
向多模态 LLMs 发展的趋势(如 o1 的推理增强和 GPT-4o 的综合能力)凸显了后训练方法在实现文本、图像、音频等数据类型无缝集成以支持整体推理方面的紧迫需求,这对实时视频分析、增强现实和跨模态科学探索等应用至关重要。现有方法在实现强健的跨模态对齐方面表现不佳,主要受限于数据异质性和多模态训练语料的稀缺,限制了 LLMs 对多样输入的协同推理能力。该挑战的解决有望带来变革性应用,但若无可扩展框架则难以实现。DeepSeek-R1 的冷启动 RL 提供了有益启示,表明统一模态编码器(如将异构数据编码到共享潜空间)和动态 RL 策略(自适应加权模态贡献)有望弥合这一鸿沟。未来研究应优先创建多模态基准和合成数据集,借鉴 Magpie 等项目,推动进展,鉴于多模态预训练和 RL 优化的最新突破,这一目标已具备可行性。
上下文自适应可信度框架。
后训练 LLMs 的可信度日益被视为动态、依赖上下文的属性,而非静态品质,正如 o1 在教育等敏感领域的审慎输出与在创意任务中的自由响应所体现的那样。这种变异性——安全需求(如避免教育场景中的错误信息)与实用性需求(如激发写作创意)之间的冲突——构成了一个紧迫挑战,对用户信任和 LLMs 在多样化现实场景中的适用性至关重要。现有后训练方法常常过度强调安全,导致实用性受损,或未能适应特定场景需求,影响可靠性。解决之道在于开发上下文敏感的 RL 模型,动态调整安全与实用性权衡,结合实时用户反馈和可解释安全指标(如生成内容的透明度评分),以确保适应性。自适应学*系统和实时监控的进展为这一方法的可行性提供了支持,为在高风险应用中实现可信度与功能性的平衡提供了路径。
后训练创新的可及性与民主化。
先进后训练方法的计算强度(如 DeepSeek-R1 的 RL 驱动策略)使其应用局限于资源丰富的群体,成为阻碍创新的紧迫障碍,尤其影响小型研究社区和行业部门(对推动 AI 公平进步至关重要)。这种排他性不仅限制了贡献的多样性,也阻碍了领域协同应对全球挑战的能力。实现创新民主化需要开发高效、开源的工具和框架,降低准入门槛而不牺牲质量,这一目标可通过 RL 的可扩展 PEFT 适配、后训练模型共享平台(如 Hugging Face hubs)、以及类似 Magpie 的合成数据生成流程实现。未来应致力于优化这些方案,推动广泛采用,确保 o1 和 DeepSeek-R1 等后训练创新惠及更广泛的 AI 生态系统。
创造性智能与系统 2 思维。
将创造性智能融入系统 2 推理是 LLMs 发展的新前沿,正如文献所强调。尽管 o1 和 DeepSeek-R1 等推理型 LLMs 在有条理、逐步的逻辑分析(模拟系统 2 思维)方面表现出色,但其创造性智能能力——即生成新颖想法、综合异质概念、灵活应对非结构化问题——仍有待深入探索。这一缺口至关重要,因为创造性智能是类人问题解决的基础,涉及艺术创作、科学发现和战略创新等领域,单靠严格逻辑框架远远不够。该挑战的紧迫性在于其有望推动 LLMs 从分析工具跃升为自主创造性代理,迈向通用人工智能(AGI)的变革性进步。下文将进一步阐述这一开放问题,并结合调研见解提出未来方向。
结论
本文首次对后训练语言模型(PoLMs)进行了全面综述,系统梳理了其从 2018 年 ChatGPT 对齐起源到 2025 年 DeepSeek-R1 推理里程碑的发展轨迹,肯定了其在推理精度、领域适应性和伦理完整性方面的变革性影响。我们评估了包括微调、对齐、推理、效率、集成与适应等广泛技术,综合分析了其在法律分析、多模态理解等专业、技术和交互领域的贡献。分析表明,PoLMs 显著提升了 LLMs 能力,从最初的对齐创新发展到复杂的推理框架;但同时也揭示了持续存在的挑战,包括偏见持续、计算可扩展性和伦理对齐的上下文变异性。这些发现通过新颖的分类体系加以总结,强调了将推理进步与效率和伦理要求相结合的综合方法的必要性。我们认为,持续的跨学科合作、严格的方法评估以及自适应、可扩展框架的开发,是实现 LLMs 成为可靠、负责任工具的关键。作为首部此类综述,本文整合了*年来 PoLMs 的进展,为未来研究奠定了坚实的理论基础,激励后续工作培育兼具精度、伦理稳健性和多样性的 LLMs,以满足科学和社会不断变化的需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号