Infini-Thor 具身大海捞针:长上下文推理的环境、架构和训练考虑
https://arxiv.org/pdf/2505.16928
摘要
我们提出了 infini-thor,这是一个面向长时序具身任务的新框架,旨在推动具身人工智能中的长上下文理解能力。infini-thor 提供了:
- (1) 一个可扩展、可复现且无限制生成长时序轨迹的生成框架;
- (2) 一个新颖的具身问答任务——“具身大海捞针”,在该任务中,多个分散线索贯穿于超长轨迹,考验智能体的长上下文推理能力;
- (3) 一个长时序数据集和基准套件,包含跨越数百环境步的复杂任务,并配有真实动作序列。
为实现这一能力,我们探索了多种架构适配方法,包括交错的目标-状态-动作建模、上下文扩展技术以及上下文并行训练,以赋能基于大模型的智能体进行极端长上下文推理与交互。实验结果和分析凸显了我们基准带来的挑战,并为长时序条件下的训练策略和模型行为提供了洞见。我们的工作为下一代能够进行稳健、长期推理与规划的具身人工智能系统奠定了基础。
引言
现实世界中的具身推理是一个顺序决策问题,需要进行长时序规划,任务的成功依赖于对时间上相距甚远的多个事件的记忆与推理。将大型预训练视觉-语言-动作(VLA)模型用作此类任务的策略时,必须克服“长上下文”推理这一核心挑战。我们关注于:在使用VLA模型进行长时序具身任务时,环境、模型架构和训练方法的哪些设计选择最为关键。为此,我们开发了一个面向长时序任务的新框架,旨在推动具身人工智能中长上下文理解能力的边界。
我们提出了 infini-thor,这是一个用于生成、训练和评估长时序具身任务的新框架。我们的基准任务独特地包含了合成的最终目标,该目标涉及多个在时间上相距甚远的物体,需要智能体在数百步内进行多步推理。图1展示了一个示例:智能体在早期(t=17)观察到番茄,在较晚(t=560)观察到台面,最终在t=670接收到“将番茄放到台面上”的任务。这一设置突出了长时序依赖的挑战,智能体必须在数百步后记住并操作关键物体和位置。
这种长时序设置引入了一个新的挑战性任务——具身大海捞针(Needle(s) in the Embodied Haystack, NiEH)。与标准的大海捞针任务不同,NiEH面临两大挑战:(1)线索(Needle)分散在多个时间点;(2)输入为多模态,结合了环境中的视觉和语言观测。该任务旨在评估智能体回忆和推理先前环境细节(如识别物体、回忆已执行动作)的能力。
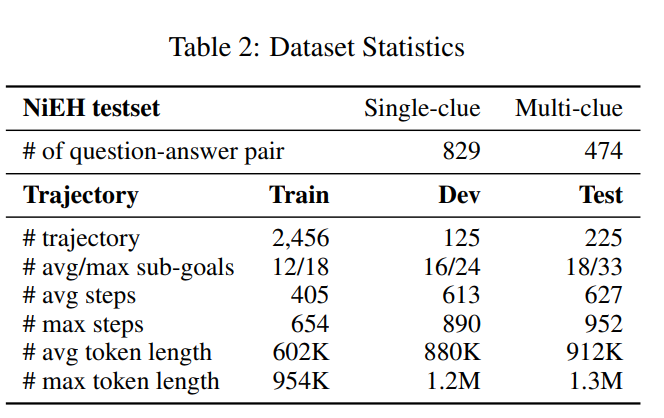
除了静态评测(如NiEH),infini-thor 还支持交互式评测,允许智能体在动态环境中执行策略并完成长时序任务。为此,我们发布了一个用于训练的轨迹数据集,训练集每个episode超过400步,开发集和测试集超过600步。这些轨迹可用于模仿学习。我们的实验表明,训练时访问更长上下文会显著提升性能,凸显了该数据集对长上下文具身推理的重要性。
我们进一步探讨了具身智能体在极长序列下的多种架构设计。我们发现,交错的目标-状态-动作建模(Goal-State-Action)——即采用LLM主干、联合建模目标、状态和动作序列的多模态、目标条件VLA架构,是解决此类问题最实用的方法。此外,鉴于标准LLM受限于固定上下文窗口,无法原生处理超过百万token的输入,我们探索了旋转位置编码缩放和位置插值等长上下文扩展技术。最后,我们展示了如何通过Context Parallelism(一种高效扩展到超长序列的并行训练策略)在扩展上下文输入上微调模型,从而进一步增强长上下文推理能力。
我们提供了全面的实验和分析,展示了我们的基准所带来的挑战,以及基线模型在长时序设置下的表现。我们系统研究了不同的训练配置,包括微调和长上下文适配的多种方案,并评估了它们对模型性能的影响。
我们的贡献总结如下:
- 提出 infini-thor,一个用于生成、训练和评估长时序具身任务的新框架,包含需要跨越数百步进行多步推理的合成最终目标。
- 提出了一项新颖的具身问答任务——具身大海捞针(NiEH),要求智能体在长轨迹中回忆和推理多个分散线索。
- 发布了大规模轨迹数据集和交互式评测环境,支持长时序场景下的离线模仿学习和在线策略执行。
- 描述了包括交错目标-状态-动作建模、长上下文扩展和Context Parallelism在内的架构适配,专为交互式具身推理设计。
- 提供了实证结果和分析,为当前具身AI系统在长时序任务下的能力与局限性提供了洞见。
相关工作
| Benchmark/Platform | Task Horizon | Interaction w/ env | modality | # steps | GT actions | QA set (single) | QA set (multi) |
|---|---|---|---|---|---|---|---|
| ProcTHOR | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| MineDojo | Long | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| Habitat 3.0 | Long | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| VirtualHome | Short | ✓ | multi | 11.6 | ✓ | ✗ | ✗ |
| ALFRED | Medium | ✓ | multi | 50 | ✓ | ✗ | ✗ |
| ALFWorld | Medium | ✓ | text | 50 | ✓ | ✗ | ✗ |
| BEHAVIOR-100 | Med/Long | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| BALROG | Long | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| EQA | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| MM-EGO | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ |
| infini-thor | Long | ✓ | multi | 600+ | ✓ | ✓ | ✓ |
Short (< 50 steps), Medium (50–300 steps), and Long (> 300 steps) describe task horizon, reflecting the approximate number of environment steps required to complete a task in each benchmark. Single/Multi in the QA set column denotes single- and multi-evidence question type.
虚拟环境中的长时序规划。
AI2THOR 提供了广泛用于具身推理研究的交互式室内环境,ProcTHOR 通过程序化生成可扩展环境,进一步支持更长轨迹的生成。MineDojo 在 Minecraft 平台上提供了一个开放式平台,专门面向需要长期规划的任务。此外,VirtualHome 和 Habitat 3.0 等平台也适用于涉及长时交互和复杂活动序列的任务。然而,这些平台仅提供环境本身,并未包含用于长时序具身任务训练和评测的标准化数据集或基准套件。
具身问答与多模态“大海捞针”任务。
具身问答(Embodied QA)任务,如 EmbodiedQA 和 MM-EGO,要求智能体基于视觉观测回答问题,通常需要对智能体轨迹进行空间和时间上的推理。虽然这些基准强调多模态理解,但在评测过程中并不涉及与环境的主动交互。与我们的 NiEH 任务相关的另一个领域是多模态大海捞针(NiH)问题。传统的大海捞针任务主要考察长上下文输入中的文本回忆能力,而近期的多模态变体则引入了视觉元素。然而,这些工作通常只涉及较短的上下文窗口(通常不超过 72K tokens),且不要求具身推理或动态轨迹中的时间依赖。
长时序具身任务的数据集与基准。
近期的研究推动了长时序具身任务的发展,要求智能体完成具有长期依赖的多步目标。ALFRED 和 ALFWorld 引入了带有动作标注和文本指令的多步任务,但其任务时长相对较短,通常不超过 50 步。BEHAVIOR-100 评估了智能体在家庭活动中的泛化能力,其中部分任务需要较长时间的参与,但主要聚焦于单一任务。BALROG 是用于测试长上下文 LLM 智能体能力的基准,但其范围仅限于游戏领域。
长上下文基准。
在具身智能体领域之外,也有一些通用基准关注长上下文推理的挑战。例如,LongBench 和 RULER 主要聚焦于检索或摘要任务。GSM-\(\infty\) 则将 GSM-8K 扩展到极长文本输入下的数学推理能力评测。
infini-thor:用于生成、训练和评估长时序具身任务的环境
infini-thor 提供了一个生成框架,用于合成长轨迹,以训练和评估 AI 智能体在长时序具身任务中的表现。
我们基于 AI2-THOR 模拟器构建了 infini-thor,这是一个支持多样化场景、物体和智能体动作的交互式 3D 环境,广泛应用于具身 AI 研究。
infini-thor 能够生成长度无限制的轨迹,并在训练和测试阶段为智能体提供动态交互的评测设置。
这既支持通过大规模数据集进行离线学习,也支持通过智能体与环境的直接交互实现在线学习。
每条由 infini-thor 生成的轨迹包含多个任务目标,例如“将干净的海绵放在金属架上”或“捡起苹果并放到微波炉上”,这些目标要求智能体具备扎实的理解和行动能力以完成任务。
这使得智能体能够在长时间的回合中探索和与环境互动。
在每条轨迹的结尾,智能体会被分配一个合成的长时序任务,该任务需要对在不同时间步遇到的实体进行推理。
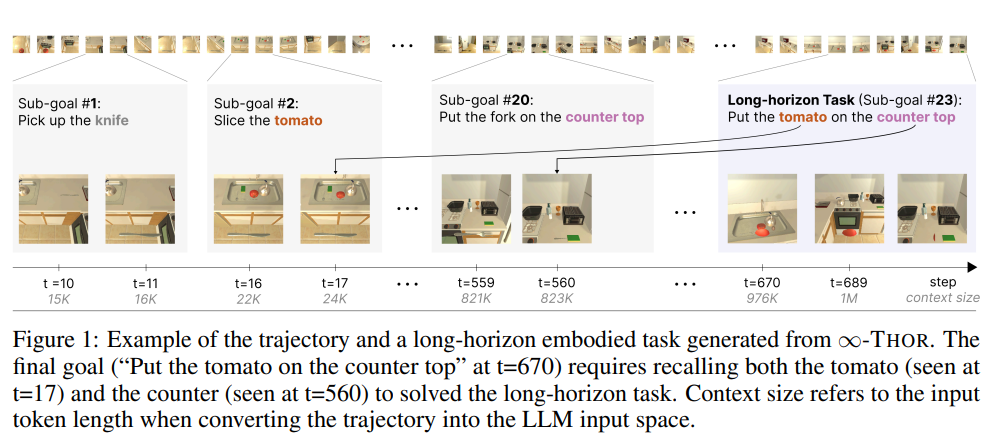
如图1所示,长时序任务(子目标 #23,t=689,“将番茄放到台面上”)依赖于智能体在更早(t=17)观察到的番茄和在较晚(t=560)观察到的台面。我们的生成框架可以生成无限数量的任务,轨迹长度极长,当轨迹被 LLM 处理时,其上下文 token 数可超过 100 万甚至更多。
成功完成此类任务要求智能体:(1)在数百步内记忆并整合关键环境信息;(2)基于时间上分离的依赖关系进行行动规划,体现出对长上下文推理和稳健时空记忆的需求。
静态评测:具身大海捞针(Needle(s) in the Embodied Haystack)
我们首先提出了一项新颖的静态评测任务:具身大海捞针(Needle(s) in the Embodied Haystack, NiEH)。NiEH 旨在评估智能体回忆和推理其在轨迹中遇到的环境状态的能力。与传统的具身问答任务主要关注单一图像的视觉理解不同,NiEH 更强调对环境随时间变化的推理,要求智能体能够解释并整合多模态观测序列。

如图2所示,NiEH 包含两种任务类型。在单线索设定下,问题可通过单一观测步骤回答;而在多线索设定下,则需要结合多个时间上相距甚远的步骤来回答问题。NiEH 测试集涵盖了多样的问题类型,包括二元(“是”或“否”)、“什么”、“哪里”以及“多少次”等问题。这些问题难度跨度大,从简单的记忆回忆(类似于传统的大海捞针范式)到需要跨越时空多步推理的复杂查询。
测试集构建。
我们首先回放生成的轨迹,收集智能体的第一视角观测,以及轨迹中与智能体发生交互的所有物体(如被拾取、移动或仅被观察到的物体)。基于这些交互,我们应用一套基于规则的模板生成问答对,例如“Q. 你切了什么物体?A. {物体名称}和“Q. {物体名称} 在桌子上吗?A. 是/否”。随后,我们根据频率对问题进行采样,以确保不同物体类型的多样性,并利用回放日志标注 GT(真实)答案步骤。
在生成问答对并标注 GT 步骤后,我们使用四个不同的多模态大模型(LLaVA-OneVision 7B、Qwen2.5-VL 7B、Deepseek-VL 7B 和 Pixtral 12B)对每个问题的可回答性进行交叉验证。由于这些模型在标准视觉问答任务上表现优异,我们过滤掉所有四个模型在 GT 图像上都无法正确回答的问题。在测试时,整个轨迹被视为“大海捞针”输入,并根据 GT 图像所在深度进行裁剪。关于模板、生成规则及四个模型的验证分数等详细信息见附录。
具身大海捞针的挑战。
NiEH 任务为当前模型带来了两大挑战。首先,许多问题需要对多个时间上相距甚远的事件进行推理。如图2(b) 所示,智能体在 \(t=24\) 时将 dish sponge 从垃圾桶移到台面,随后又在 \(t=751\) 放入抽屉。像“你在把 dish sponge 放到台面之前,它在哪里?”这样的问题,要求模型回忆并串联起数百步中的多个动作和位置。其次,部分问题要求模型在长轨迹中聚合稀疏且分散的证据。如图2(b) 的第二个例子,“你移动了几次信用卡?”这一问题需要模型追踪并统计从开局到结束所有相关动作的发生次数。这些挑战凸显了模型在复杂具身环境下,跨越时间和多模态进行稳健长时序推理的必要性。
长时序轨迹的构建与交互式评测
借助 infini-thor 的生成框架,我们能够合成长时序轨迹,用于构建离线学习和评测所需的训练、验证和测试集。我们的方法基于规划器(planner)驱动的方式,将多个单任务演示顺序拼接为一条长轨迹,并在整个过程中保持物体状态和智能体交互的一致性。
具体而言,每条轨迹的生成首先从七种预定义任务模板中采样一种任务类型(如“拾取两个物体并放置”、“拾取并放置到可移动容器”等)。随后,采样完成任务所需的物体,例如需要拾取的物品或需要交互的容器。基于采样得到的任务和物体,我们利用经典的任务规划器(基于PDDL定义的领域)生成真实动作序列。这些计划会在模拟器中执行,仅保留成功完成的回放轨迹。我们将这些成功的演示拼接起来,构成长达数百步的长时序序列。对于最终目标,所涉及的物体仅从轨迹最前20%和最后20%的观测中采样,以此强制要求智能体在完成最终任务时必须联合回忆和推理时间上相距甚远的两个物体,形成长时序依赖。通过上述流程,我们分别生成了2,456条训练集、125条验证集和225条测试集轨迹。
面向长时序视觉-语言-动作模型的架构
具身智能体需要在复杂且动态的环境中高效交互,这要求其具备理解多模态输入(视觉、语言)并生成连贯动作序列的能力。开发此类视觉-语言-动作(VLA)模型极具挑战性,因为它需要无缝整合感知理解、语言推理与动作预测。
现有的VLA模型通常采用视觉、语言和动作模块分离的编码器,或仅关注于短时序、低层级的任务(如受限环境下的机械臂操作),此类任务的决策仅依赖于最近的观测和单条指令。尽管近期多模态大模型(如LLaVA、MiniGPT-4、Llama 3.2)展现出强大的多模态推理能力,但它们主要针对静态输入(如单张或少量图片),缺乏长时序具身任务所需的动态交互与记忆能力,无法处理连续的视觉-语言-动作序列。此外,许多最先进的模型仅通过专有API访问,难以应用于实时、可控的具身环境,也难以管理长期记忆状态。
我们探索了以多模态大模型为统一VLA建模器的潜力,采用目标、状态(视觉观测)与动作token交错输入的结构,如图3所示。这种交错的多模态输入使模型能够同时处理视觉、语言和动作,从而促进更连贯、实时的交互建模。
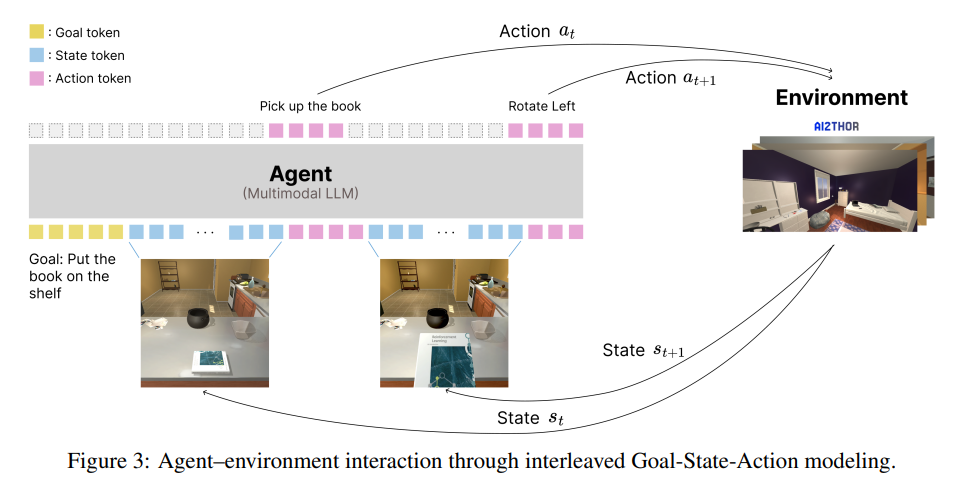
具体而言,我们的目标条件智能体采用多模态大模型主干,训练其在目标和状态token序列的条件下自回归地预测后续动作。在每个时间步\(t\),环境会提供新的视觉观测\(s_t\),该观测被编码为状态token并追加到已有token流中。模型随后在完整的目标、状态和历史动作序列的条件下自回归地预测下一个动作\(a_t\)。该动作被执行于环境中(如“捡起书本”),进而获得下一个观测\(s_{t+1}\),形成感知-动作闭环。这一交互过程可持续数百步,使模型能够在动态环境下,基于时序上相距甚远的信息进行推理,同时保持行为的现实性和连贯性。通过交错的目标-状态-动作建模,我们的架构能够支持长时序具身任务中的连贯决策。
上下文扩展
由于大多数大语言模型(LLM)在上下文长度上存在限制,直接使用现成模型无法处理超过百万 token 的长输入。我们探索了多种长上下文扩展技术,使模型能够在无需从头训练的情况下泛化到更长的输入序列。具体包括:
线性插值:通过线性插值位置索引,将输入位置缩放到预训练 RoPE 的范围内;
动态缩放:根据输入序列长度在运行时自适应调整 RoPE 频率,采用线性缩放以在不同长度下保持一致的位置编码行为;
YaRN:在推理时动态插值注意力频率,在预训练和外推位置编码之间取得平衡;
LongRoPE:通过特殊设计的外推函数增强 RoPE,使其能够在不降低注意力质量的情况下稳健泛化到超长序列。
这些技术可在微调阶段、推理阶段或两者结合时应用。
Context Parallelism(上下文并行)
为了进一步提升模型对长上下文的推理能力,关键在于在扩展上下文输入上进行微调。然而,注意力机制的二次复杂度使得直接在长序列上训练在计算上不可行。为了解决这一挑战,我们采用了 Context Parallelism,这是一种高效的长上下文并行训练技术。
Context Parallelism 利用 Ring Attention,一种新颖的注意力层并行实现方式。在 Ring Attention 中,键值(KV)分片在多设备间循环交换,并迭代计算部分注意力分数。该过程重复进行,直到每个设备都整合了所有 KV 分片,从而在不增加标准注意力全部内存开销的前提下,实现完整的注意力覆盖。通过将 Context Parallelism 与我们的大规模长上下文数据集结合,我们能够将微调扩展到极长序列,从而显著提升模型的长时序推理能力。
实验
静态评测:具身大海捞针(Needle(s) in the Embodied Haystack)
我们首先在具身大海捞针(NiEH)和多线索具身大海捞针(NsiEH)任务上评估模型性能,这些任务考察智能体在长时序轨迹中检索和推理稀疏证据的能力。
构建具身大海捞针。 与传统的大海捞针任务将目标句子插入长文本(如一本书)不同,我们将整个具身轨迹作为输入上下文。为模拟不同的推理深度,我们根据真实图像所在位置,从轨迹起始或末尾裁剪输入序列。在 NsiEH 任务中,多个证据分散在轨迹各处,我们将 GT 步骤之间的中间步骤按时间顺序填充到上下文中。
结果分析。
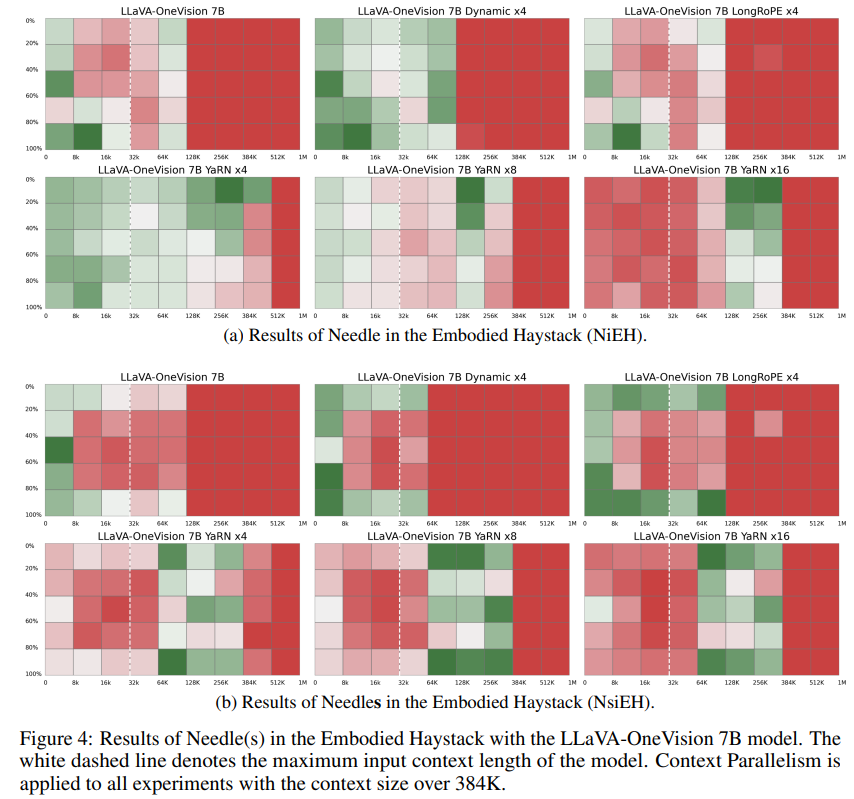
图4展示了 LLaVA-OneVision 7B 模型在不同上下文扩展方法下的表现。线性插值、动态缩放和 LongRoPE 在超过 128K tokens 的超长上下文下均表现不佳(线性插值在所有样例上均失败,未在图中展示)。YaRN 在 NiEH 和 NsiEH 两项任务中均表现最优,能够在超过 384K tokens 的上下文长度下成功回答问题,这可能得益于其与 LLaVA-OneVision 的 Qwen2 主干架构的高度契合(该主干在预训练时采用了 RoPE 和 YaRN 缩放)。YaRN 在中等缩放因子(如 x4)时效果最佳,进一步提升到 x8 和 x16 并未带来额外收益。特别地,x16 在 256K–384K token 区间略有提升,但在较短上下文(<64K)下反而导致性能下降,说明过度缩放可能引入不稳定性并负面影响模型表现。总体来看,所有方法在 512K tokens 以上均失效。我们预计,随着模型被推向更大上下文窗口,这一趋势仍将持续,未来亟需更先进的方法来有效处理极长上下文场景。
单线索 vs 多线索推理。
将 NiEH 与更具挑战性的 NsiEH 任务对比,我们发现多线索设定下模型性能显著下降。尤其是在涉及稀疏或时间上相距甚远证据的中等深度问题(如“你在把 Mug 放到 CounterTop 之前,它在哪里?”)或需要聚合多个线索的问题(如“你移动了几次 Apple?”)时,表现尤为明显(见图4(b))。这些结果表明,NiEH 和 NsiEH 任务对当前长上下文模型提出了巨大挑战,成功完成任务不仅需要细粒度的时序记忆,还要求模型具备跨越长时序、多线索推理的能力。
在 infini-thor 中的交互式评测
我们在 AI2THOR 模拟器中进行交互式在线评测,以衡量智能体在长时序测试集上的表现。
实验分析了不同上下文扩展方法、不同缩放因子以及多种微调上下文长度(32K、64K 和 130K)下的奖励累积情况。
训练设置。
我们在训练集上微调 LLaVA-OneVision 7B 模型,同时冻结视觉编码器。
32K 上下文长度下,使用 8 张 H100 GPU 结合张量并行和流水线并行进行训练;对于更长上下文(64K 和 130K),采用 Context Parallelism 技术。更多训练细节见附录。
计划级评测。
我们基于奖励累积评估智能体在给定历史状态和动作下的表现。评测在计划级别进行,每个计划对应一段针对特定中间目标的短动作序列。例如,“前往某位置”的计划通常包括如 Move Ahead、Rotate Right/Left、Look Up/Down 等动作。每条轨迹由多个此类顺序计划组成。在每一步,智能体会获得任务目标和历史状态-动作序列,预测后续动作并持续与环境交互直至计划完成。更多评测细节见附录。
结果与讨论。
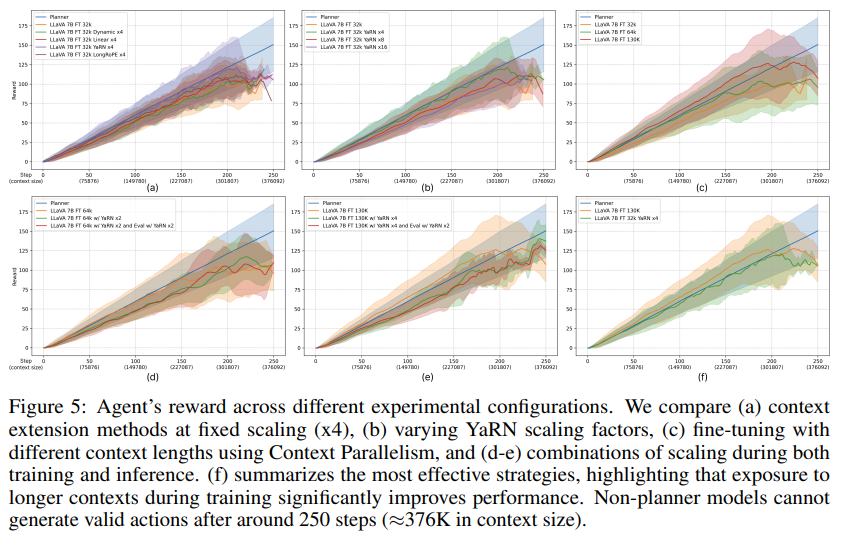
图5展示了六种实验配置下的对比结果。Planner 轨迹作为性能上界。我们通过实验结果回答以下关键问题:
Q. 哪种上下文扩展方法表现最佳?
图5(a) 在固定缩放因子 x4 下比较了不同上下文扩展方法。与 NiEH 结果类似,YaRN 始终取得最高表现,且与 Planner 上界非常接近。
Q. 进一步提升缩放因子是否有助于性能?
图5(b) 探索了 YaRN 在不同缩放因子(x4、x8、x16)下的表现。结果显示,缩放因子超过 x4 后,性能提升并不显著,存在收益递减现象。
Q. 在包含长轨迹的数据集上微调是否有效?
图5(c) 展示了结合 Context Parallelism 微调的效果,使上下文长度扩展到 64K 和 130K tokens。
在 130K 上下文下,模型可学习约 86 步的序列,远超 32K 下的 22 步。
这表明训练时暴露于更长上下文能显著提升模型表现,说明通过 infini-thor 增加长时序数据有望进一步提升模型能力。
本实验未应用上下文扩展方法。
Q. 训练和推理阶段同时应用上下文扩展是否有额外收益?
图5(d) 和 (e) 展示了训练和评测阶段均应用缩放的实验。结果表明,在微调后评测阶段再次缩放并未带来额外提升,反而在较短上下文($\leq$300K tokens)下可能降低性能。
综上所述,当有长轨迹数据集时,微调策略最为有效。若缺乏大规模训练数据,采用 YaRN x4 缩放即可在 200K tokens 内获得接近 Planner 上界的表现(见图5(f))。
结论
我们提出了 infini-thor,这是一个面向长时序具身任务的新框架,旨在推动具身人工智能中的长上下文理解能力。该框架支持可扩展地合成长且复杂的轨迹,并配有真实动作序列,既可用于离线训练,也支持与环境的在线交互。在此基础上,我们提出了一项新颖的具身问答基准——“具身大海捞针”,该任务要求智能体在超长轨迹中,基于稀疏且时间上相距甚远的视觉证据进行推理。为适应这一场景,我们探索了多种架构适配方法,包括交错的目标-状态-动作建模、上下文扩展技术(如 YaRN 和 LongRoPE),以及通过 Context Parallelism 实现高效微调。实验结果表明,训练时暴露于更长上下文能显著提升模型性能,而现有的上下文扩展技术在长上下文推理方面仍面临挑战。我们希望本框架和基准能够促进更多关于在真实、交互式环境下实现稳健长时序推理模型的研究。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号