RoboBrain2.0 技术报告
https://arxiv.org/abs/2507.02029
摘要
我们介绍了RoboBrain 2.0,这是我们最新一代的具身视觉-语言基础模型,旨在为物理环境中的复杂具身任务统一感知、推理与规划。RoboBrain 2.0 提供了两个版本:轻量级的 7B 模型和全规模的 32B 模型,采用异构架构,包含视觉编码器和语言模型。尽管体积紧凑,RoboBrain 2.0 在广泛的具身推理任务中表现出色。在空间和时间基准测试上,32B 版本取得了领先成绩,超越了以往的开源和专有模型。特别地,它支持关键的现实世界具身 AI 能力,包括空间理解(如可供性预测、空间指代、轨迹预测)和时间决策(如闭环交互、多智能体长时规划、场景图更新)。本报告详细介绍了模型架构、数据构建、多阶段训练策略、基础设施和实际应用。我们希望 RoboBrain 2.0 能推动具身 AI 研究,并作为构建通用具身智能体的实用一步。
引言
近年来,大型语言模型(LLMs)和视觉-语言模型(VLMs)已成为推动通用人工智能(AGI)发展的关键力量。在数字环境中,这些模型在感知、理解和推理等方面展现出卓越能力,并被广泛应用于多模态问答、图像生成与编辑、GUI 控制、视频理解等任务。同时,它们也在教育、医疗、搜索和智能助手等实际领域得到初步应用。
然而,如何弥合“数字智能”与“物理智能”之间的鸿沟——让模型能够感知周围环境、理解具身任务并与现实世界交互——仍是迈向 AGI 的关键挑战。具身基础模型代表了迈向物理智能的有前景的研究方向。近期的多项工作已将 LLMs 和 VLMs 的能力扩展到具身场景,推动了多模态融合、感知与动作执行的发展。尽管这些模型取得了令人鼓舞的进展,但在复杂、开放的现实环境中部署时,仍面临三大核心能力瓶颈:
- 空间理解有限:当前模型难以准确建模物理环境中的相对与绝对空间关系,难以识别可供性,影响实际应用;
- 时间建模薄弱:缺乏对多阶段、跨智能体的时序依赖与反馈机制的理解,限制了长时规划与闭环控制能力;
- 推理链不足:现有模型难以从复杂的人类指令中提取因果逻辑,并与动态环境状态对齐,限制了对开放式具身任务的泛化能力。
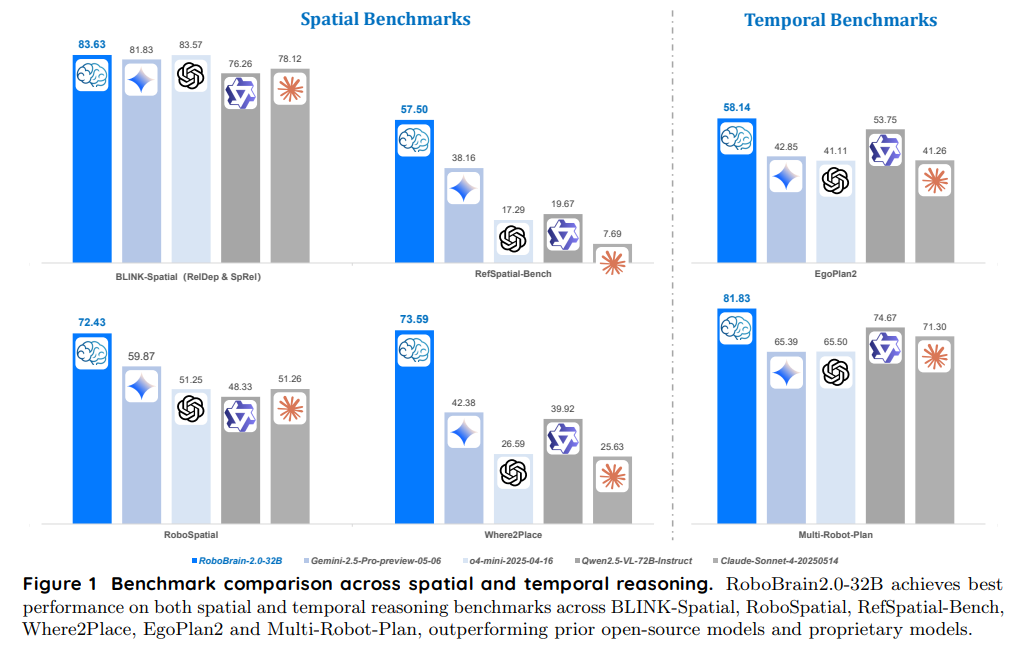
为应对上述挑战,我们提出了RoboBrain 2.0,这是我们最新一代的具身视觉-语言基础模型,旨在打通物理环境中的感知、推理与规划。RoboBrain 2.0 能够统一处理视觉观测与语言指令,实现对环境的整体理解、目标导向推理与长时规划。我们发布了两个版本:轻量级的 RoboBrain 2.0–7B 和全规模的 RoboBrain 2.0–32B,以满足不同资源约束下的部署需求。在空间与时间推理基准测试中,32B 版本大多取得了最优成绩,超越了以往的开源和专有模型,如图1所示。模型能力如图2所示。

本报告系统介绍了 RoboBrain 2.0 的设计理念、核心组件与关键创新。我们重点介绍了支撑空间理解、时间推理与因果推理的丰富数据贡献,这些数据构成了 RoboBrain 2.0 能力的基础。为解决空间数据稀缺问题,我们开发了空间数据合成流水线,构建了涵盖指点、可供性预测、轨迹生成等任务的大规模高质量数据集。为提升时间推理与反馈建模能力,我们基于 RoboOS 设计了多机器人协作模板,利用外部模型生成跨智能体的长时规划轨迹,并模拟随机故障事件收集闭环反馈数据,增强模型鲁棒性。为进一步丰富推理数据,我们从强大的推理型 VLMs 中提取了基于时空任务上下文的逐步思考轨迹,用作跨视觉、语言与动作的因果链学习监督信号。
RoboBrain 2.0 采用高效异构架构与渐进式多阶段训练策略,支持具身场景下的空间理解、时间建模与长链因果推理。模型由约 6.89 亿参数的轻量级视觉编码器和 7B/32B 参数的解码式语言模型组成,采用三阶段课程式训练策略——涵盖基础时空学习、具身时空增强与链式推理——在大规模多模态与具身数据集上进行训练。训练基于我们开源的 FlagScale 框架,集成了混合并行、预分配内存优化、高吞吐 I/O 流水线与强健的容错机制。这些基础设施创新显著降低了训练与部署成本,并确保了大规模多模态模型的可扩展性。我们在 12 个公开基准上评估了 RoboBrain 2.0,涵盖空间理解、时间建模与多模态推理,尽管模型体积紧凑,仍在 6 个基准上取得了最优成绩。我们将代码、模型权重与基准测试开源,助力学术社区可复现研究、加速具身 AI 发展,并推动实际机器人系统的落地应用。
为全面展示 RoboBrain 2.0 的架构、训练方法与能力,报告结构如下:第二节介绍模型设计,包括视觉编码器与语言模型的协同,以及图像与视频输入策略;第三节描述数据构建流程,涵盖通用多模态理解、空间推理与时间建模三大类;第四节介绍多阶段训练策略,包括基础时空学习、具身增强与链式推理;第五节阐述支撑大规模训练与推理的基础设施,包括混合并行、内存优化、数据加载与故障恢复;第六节报告公开基准上的评测结果,突出 RoboBrain 2.0 在空间推理、时间反馈与具身规划方面的能力;最后一节讨论当前局限性并展望未来研究方向。
架构
RoboBrain 2.0 采用模块化的编码器-解码器架构,实现了复杂具身任务中感知、推理与规划的统一。如下图所示,模型通过四个核心组件处理多视角视觉观测和自然语言指令:(1)文本/结构化输入的分词器;(2)视觉编码器;(3)将视觉特征映射到语言模型token空间的MLP投影器;(4)以Qwen2.5-VL为基础的语言模型主干。与传统VLMs主要关注静态VQA不同,RoboBrain 2.0 在保持强大VQA能力的同时,专注于空间感知、时间建模和长链因果推理等具身推理任务。该架构将高分辨率图像、多视角输入、视频帧、语言指令和场景图编码为统一的多模态token序列,实现全面处理。
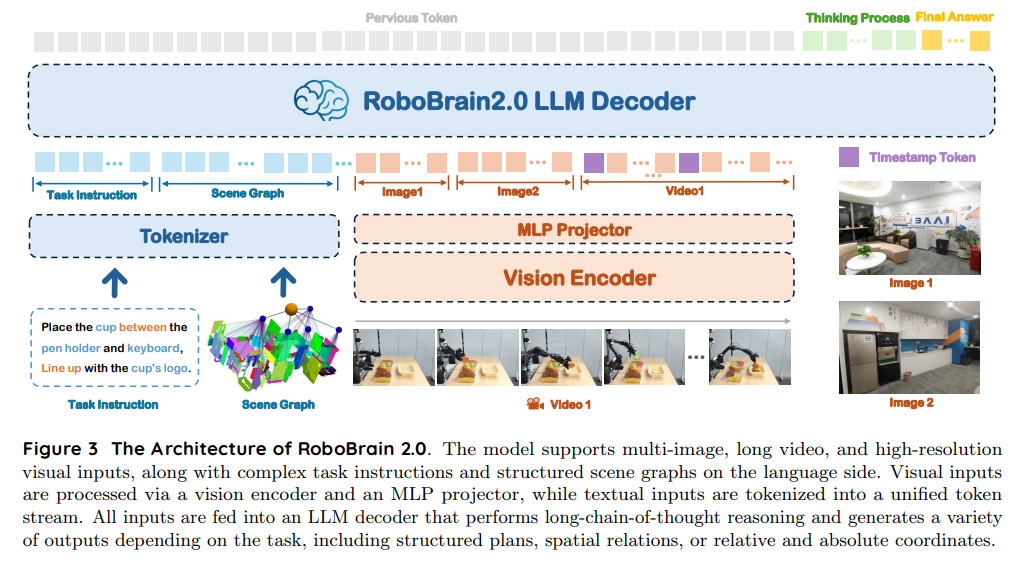
输入模态与分词
RoboBrain 2.0 支持多种面向具身AI任务的输入模态:
- 语言指令:描述高层目标或低层动作的自然语言命令。RoboBrain 2.0 能处理不同抽象层级的自然语言指令,从高层空间指令(如“将苹果搬到最近的桌子,靠左侧杯子对齐”)到低层运动指令(如“导航到最近的桌子”,“抓取苹果”,“检测与左侧杯子对齐的位置”,“将苹果放入盒子”)。
- 场景图:探索环境的结构化JSON表示,包含已发现物体、类别、空间位置和具身配置(如:name: KitchenTable1, type: table, object: [basket, knife], robot: RealMan-single-arm)。
- 多视角静态图像:来自多个视角的图像,如头戴、腕戴摄像头或3D环境的多视角投影。这些图像由视觉编码器独立处理,并拼接为统一token序列。
- 视频帧:视频序列(如智能体的第一视角),可选地带有时间戳token,便于时间定位与推理。
语言指令和场景图通过语言分词器处理。视觉输入(包括多视角图像和视频帧)由视觉编码器转为稠密视觉嵌入,再通过MLP投影器映射到LLM的token空间,实现解码器内的统一多模态推理。
视觉编码器与投影
RoboBrain 2.0 的视觉编码器通过自适应位置编码和窗口注意力机制,支持动态分辨率的图像和视频输入。这一设计使其能高效处理具身任务中常见的高分辨率和多视角视觉观测。
为适应长时序和时间定位的任务需求,我们采用逐帧视觉分词和多维RoPE进行时空编码。每个视觉嵌入通过轻量级MLP投影到语言模型的token空间。多视角场景下,不同摄像头的视觉token被串行化,并添加视角特定的位置标识,随后与其他输入模态融合。
LLM解码器与输出表示
RoboBrain 2.0 采用仅解码式语言模型,统一高层推理与空间输出生成。与传统VLMs主要返回静态短答案不同,RoboBrain 2.0 灵活支持简洁回复和多步链式推理,能更深入理解复杂指令和物理场景。
为适应具身任务,解码器被训练生成多样化输出,包括语义表达(如指代物体或动作)、空间坐标(如绝对位置或边界框)、中间推理轨迹。旋转位置编码和时间条件token使模型能在多轮感知-动作循环中保持连贯性,这对动态环境下的长时规划至关重要。RoboBrain 2.0 支持的输出格式包括:
- 自由文本:用于任务分解、场景图更新、智能体调用和人机对话。
- 空间坐标:用于表示图像空间中的点位置、边界框或轨迹,供下游控制器使用。
- 推理轨迹(可选):长链式解释,支持深度问题求解和决策透明。
这种统一的解码方式使RoboBrain 2.0 能高效处理从空间定位、视觉理解到长时多智能体规划和因果推理等广泛具身任务。
训练数据
如下图所示,RoboBrain 2.0 的训练数据集极为多样且丰富,旨在提升其在空间理解、时间建模和长链因果推理等具身场景下的能力。训练数据涵盖高分辨率图像、多视角输入、视频序列、场景图和自然语言指令等多种模态。整个数据集被精细地划分为三大类:通用多模态理解、空间感知和时间建模,确保模型能够在复杂物理环境中高效地感知、推理和规划。
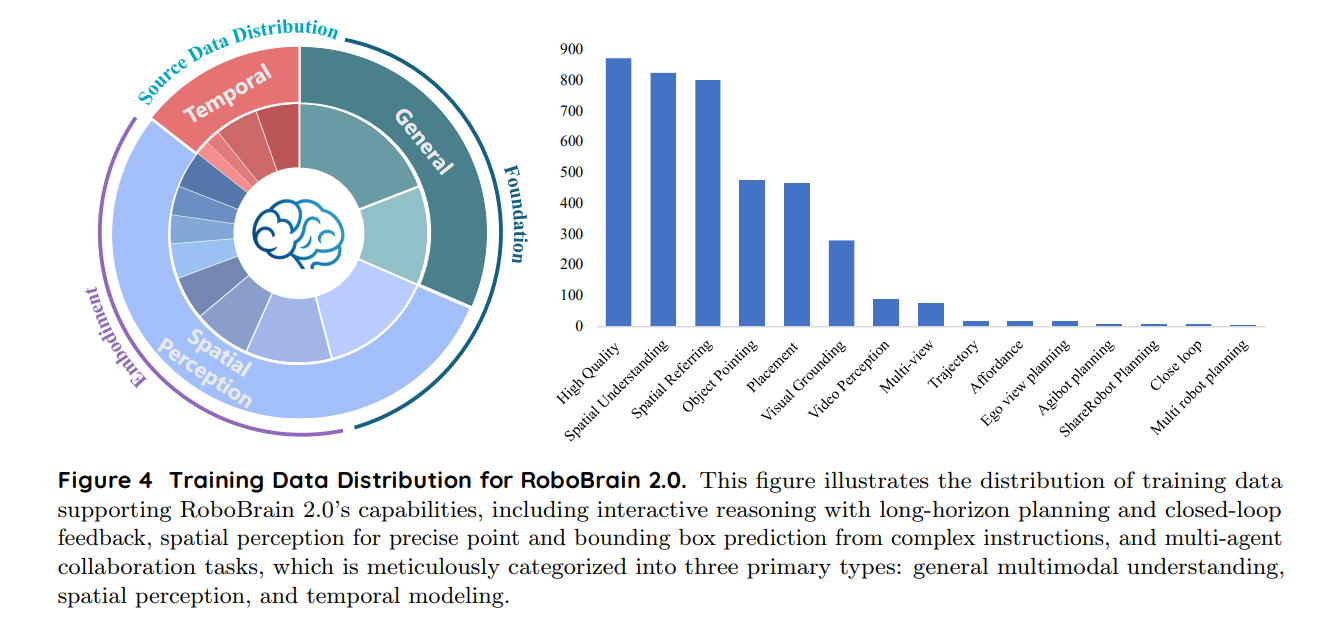
通用多模态理解(General MLLM VQA)
高质量数据。 RoboBrain 2.0 的通用训练集包含 87.3 万高质量样本,主要来源于 LLaVA-665K 和 LRV-400K,涵盖标准视觉问答(VQA)、区域级查询、OCR-VQA 和视觉对话等任务。LLaVA-665K 作为主要数据源,包含多样化的 VQA 风格数据,包括标准 VQA、OCR 问题、区域查询、视觉对话和纯语言对话。为提升训练效率,同一图像的多个问答对被合并为单一对话,过滤无效样本并截断过长对话。A-OKVQA 样本通过复制选项平衡多选格式,OCR-VQA 提供专注于场景文本理解的对话,Visual Genome 提供密集的目标级标注,RefCOCO 对话被拆分为短多轮片段。纯语言对话以单模态批次采样,提高训练吞吐。最终从该源保留 53.1 万高质量样本。
LRV-400K 由 GPT-4 合成,生成 40 万张图像条件指令,涵盖 16 种视觉-语言任务。与以往仅依赖稀疏图像描述不同,该数据集利用 VG 的密集标注,GPT-4 为每张图像生成多样化的陈述和提问。过滤后,选取 34.2 万样本用于训练。
空间数据(Spatial Data)
视觉定位
视觉定位数据集旨在通过精确的目标级定位提升多模态理解能力,基于LVIS大规模标注精心构建。我们从LVIS中筛选了152K高分辨率图像,涵盖丰富的目标类别和复杂场景。每个目标标注都被转换为标准化的边界框坐标\((x_1,y_1,x_2,y_2)\),用于一致的空间指代。为促进丰富的视觉对话,我们生成了86K多轮问答对话,逐步探索视觉关系、属性推理和上下文理解。该数据集在类别分布上保持均衡,同时保留了遮挡、视角变化和稀有实例等挑战性样本,以支持鲁棒的视觉定位能力。
目标指向
目标指向数据集用于训练RoboBrain 2.0在图像中通过指点方式定位指定目标。我们采用Pixmo-Points数据集作为数据来源,包含223K张图像和230万点标注。但直接使用Pixmo-Points存在目标实例密集重复(如书架上的书)等问题。为此,我们采用两步过滤:首先,去除标注点数超过十个的样本以简化训练;其次,利用GPT-4o作为场景分析器,仅保留室内相关目标(如厨具、家具、装饰品),剔除无关或室外场景。最终获得64K图像、19万组问答对,显著降低了杂乱度,更适合体感场景。问答对通过28个人工设计的模板自动生成,如“请指出图中所有\(label\)的位置”或“帮我通过指点找到图中的\(label\)”,其中\(label\)为目标类别。模板随机选取,提升语言多样性和泛化能力。对于目标引用指点,我们引入RoboPoint数据集,包含28.8万张图像和34.7万组问答。为避免过多点影响训练收敛,每个问题最多随机采样十个点,并将归一化坐标转换为绝对值以适配模型训练。
可供性
可供性数据集聚焦于理解目标功能属性及空间空位区域。目标可供性识别部分,采用PACO-LVIS的部件级标注,涵盖75类目标和200类部件,涉及46K图像。我们提取目标及其功能部件的边界框和分割掩码,并统一转换为\((x_1,y_1,x_2,y_2)\)格式,作为可供性预测的标签。问题通过GPT-4o自动生成,涉及目标功能和部件用途,如“手提包的哪个部位可以用来提起?”(对应手柄)。整体目标可供性问题避免直接点名目标,如“哪种设备可以移动以控制屏幕上的光标?”(对应鼠标)。该流程共生成56.1万组问答。空间可供性学习部分,包含RoboPoint的区域指代数据,覆盖27万张图像、32万组问答和14种空间关系标签。每条标注被转换为绝对坐标点集\([(x_1,y_1),(x_2,y_2),...]\),每个答案最多采样十个点。该数据集使RoboBrain 2.0能够推理现实场景中的目标放置空间可供性。
空间理解
为提升RoboBrain 2.0的三维空间推理能力,我们构建了空间理解数据集,共包含82.6万条样本。该数据集重点关注以物体为中心的空间属性(如位置、朝向)及物体间关系(如距离、方向),涵盖定性与定量两方面。数据集覆盖了31种空间概念,远超以往数据集的约15种。我们部分采用RefSpatial流程,通过自动化模板和大模型生成,构建了二维网页图片和三维视频数据集:
二维网页图片
旨在提供多样室内外场景下的核心空间概念和深度感知。为弥合室内外场景在尺度和类别上的差异,我们利用了大规模OpenImage数据集。由于直接从二维图片进行三维推理较难,我们将其转化为伪三维场景图。具体做法为:在筛选170万张图片至46.6万张后,首先用RAM进行物体类别预测,GroundingDINO检测二维框。随后,结合Qwen2.5-VL和启发式方法,针对二维框生成分层描述,从粗略(如“杯子”)到细致(如“左数第三个杯子”),实现复杂环境下的明确空间指代。接着,利用UniDepth V2和WildeCamera获取深度和相机参数,实现三维点云重建。最终,结合GroundingDINO的物体框和SAM 2.1的分割掩码,每个场景图包含物体标签、二维框、实例掩码和物体级点云,得到轴对齐三维框。物体描述作为节点,空间关系作为边。QA对通过模板和大模型自动生成,包括基于分层描述的物体位置问题。
三维场景视频
整合了五个原始数据集的多模态三维场景理解数据。我们通过模板化问题筛选、严格的数据处理、多阶段质量筛查(如一致性检查、异常值剔除),并将所有格式标准化为统一表示。该流程支持从物体定位到复杂三维场景空间推理等多种任务,提升了环境感知的细粒度和可靠性。
三维体感视频
聚焦于室内环境下的细粒度空间理解。我们利用CA-1M数据集,从200万帧中筛选出10万高质量帧。与二维数据相比,准确的三维框信息使我们能构建更丰富的场景图,生成更多定量QA对(如尺寸、距离等)。
空间指代
在强化基础三维空间理解后,我们进一步引入空间指代数据集,共包含80.2万条样本,将空间理解能力延伸至物理世界交互。与以往视觉定位或物体指点数据集常涉及模糊或多目标不同,该数据集专注于单一、明确的目标,契合机器人对精准物体识别与定位的需求,如精确抓取与放置。我们遵循RefSpatial的构建流程,对于位置数据,从基于二维网页图片和三维体感视频构建的场景图中采样描述-点对,采用分层描述。对于放置数据,利用全注释三维数据集生成顶视占用图,编码物体位置、朝向及度量空间关系(如“在椅子右侧10厘米”),以支持准确的空间指代任务。
时间数据(Temporal Data)
第一视角规划
我们通过部分处理EgoPlan-IT数据集构建了第一视角规划数据集,该数据集包含5万条自动生成的样本。对于每个选定的任务实例,我们提取多个先前动作的帧以表示任务进展,并选取一帧来捕捉当前视角。为增强语言多样性,我们采用多种提示模板来描述任务目标、视频上下文和当前观察。每个问题都包含正确的下一个动作以及最多三个从负样本中随机抽取的干扰动作。该设置支持多模态指令微调,结合多样的视觉和文本输入,旨在提升第一视角任务规划性能。
ShareRobot 规划。
ShareRobot数据集是一个大规模、细粒度的机器人操作资源,提供了适用于任务规划的多维注释。其规划部分为每一帧视频提供详细的低层次指令,有效地将高层任务描述转化为结构化、可执行的子任务。每个数据实例都包含精确的规划注释,以支持准确、一致的任务执行。该数据集包含100万对问答,覆盖5.1万个实例,涵盖102个不同场景、12种机器人形态和107个原子任务。所有规划数据均由人工专家按照标准格式精心注释,使模型能够学习稳健的多步规划策略,适应多样化的真实场景。ShareRobot的规模、质量和多样性有助于提升模型在复杂环境中进行细粒度推理和任务分解的能力。
Agitbot 规划。
Agitbot规划数据集是基于AgiBot-World数据集构建的大规模机器人任务规划数据集,包含9,148对问答,涵盖19个操作任务和109,378张第一人称视角图片。每个样本包含4-17帧连续图像,记录任务进展,并采用多模态对话格式。AgiBot-Planning提供将高层目标转化为可执行子任务的逐步规划指令。每个数据点包括当前目标、历史步骤和所需的后续动作。数据集覆盖从家庭冰箱操作到超市购物等多种场景,注释采用标准化对话格式,便于模型学习多样化的真实环境。通过连续视觉序列和细粒度行动计划,AgiBot-Planning增强了模型在复杂环境中进行长时序任务规划和空间推理的能力。
多机器人规划
多机器人规划数据集(基于RoboOS)通过在家庭、超市和餐厅三种环境中模拟协作任务场景构建。每个样本通过结构化模板生成,指定详细的场景图、机器人规格和工具列表。针对每个场景,我们设计了需要多机器人协作的高层次、长时序任务目标,并生成相应的工作流图,将任务分解为带有详细推理解释的子任务。基于这些分解,我们进一步为每个子任务生成面向具体机器人的工具计划,将高层任务目标转化为精确的低层观察-动作对。具体而言,我们定义了1,659种多机器人协作任务,并利用自动化工具生成了44,142个样本。
闭环交互
闭环交互数据集旨在促进高级体感推理,包含大规模合成的“观察-思考-行动”轨迹,将第一视角视觉观察与结构化思考标记结合。数据涵盖120种不同的室内环境,包括厨房、浴室、卧室和客厅,涉及4,000多个可交互对象和容器。该数据集基于Embodied-Reasoner在AI2Thor模拟器中通过多阶段流程构建,包括:1)基于模板生成场景适用的任务指令;2)从对象关联图推导关键动作序列,编码功能关系;3)有策略地加入搜索动作以模拟真实探索。为丰富推理深度,自动生成详细的思考过程,涵盖情境分析、空间推理、自我反思、任务规划和验证,这些内容被无缝嵌入观察与动作之间,形成连贯的推理链,引导模型完成复杂的长时序交互任务。
训练策略
RoboBrain 2.0 通过渐进式的三阶段训练策略实现了具身能力(空间理解、时间建模和链式推理),如下表所示。从强大的视觉-语言基础出发,我们逐步引入更复杂的具身监督,使模型能够从静态感知进化到动态推理和可执行的现实世界规划。
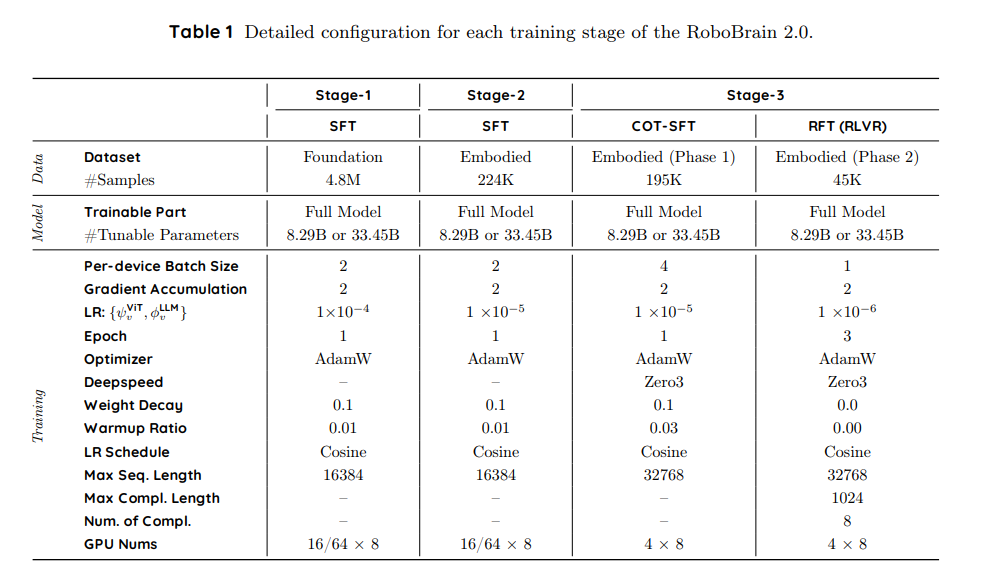
第一阶段:基础时空学习
第一阶段侧重于构建空间感知和时间理解的一般能力。我们在大规模多模态数据集上对模型进行微调,涵盖密集描述、目标定位、交错的图文文档和基础视频问答,以及指代表达理解。这些数据集覆盖了常见的物理场景和交互模式,帮助模型建立对物体、空间关系和运动事件的基本锚定能力。本阶段为理解第一视角视频流和空间锚定指令打下了基础。
第二阶段:具身时空增强
为更好地使模型适应具身任务,我们引入了精心筛选的高分辨率、多视角和第一视角视频数据集,以及带有指令增强的导航与交互数据。任务包括视角感知的指代表达、三维可供性估计和以物体为中心的场景图构建。
本阶段训练强调对长时序依赖的建模,使模型能够对扩展的动作和观测序列进行推理。此外,还引入了多智能体协作场景,模型学习在共享环境中解释和预测其他智能体的行为。为支持这些能力,我们采用了更长的序列长度和多摄像头输入编码,使模型能够同时处理和融合来自多个视角的视觉信息。通过本阶段训练,模型能够将历史视觉线索与当前指令整合,实现更连贯的长时规划、稳健的场景理解和动态交互环境下的自适应决策。
第三阶段:具身场景下的链式推理
在第三阶段,我们采用链式思维(CoT)方法增强模型的高级推理能力,遵循Reason-RFT的两阶段框架:基于CoT的监督微调(CoT-SFT)和强化微调(RFT)。我们利用来自合成和真实具身场景的多轮推理样例,涵盖长时任务规划、操作预测、闭环交互、时空理解和多机器人协作,数据来源于前述训练数据集。
具体而言,(1)CoT-SFT阶段:我们用GPT-4o和自定义提示对10%的训练数据进行链式思维标注,然后对第二阶段得到的初始模型进行监督微调。(2)RFT阶段:额外采样10%的训练数据,收集模型的回答,将错误答案整理为重格式化的训练集(如多选题或LaTeX/数值答案)。优化采用Group Relative Policy Optimization(GRPO),奖励函数综合评估答案的准确性和格式正确性。
基础设施
大规模训练基础设施
为了提升多模态模型训练的效率与稳定性,我们开发并集成了一系列关键优化技术,包括混合并行策略、内存预分配、分布式数据加载、算子融合以及细粒度的计算-通信重叠。这些优化显著提升了资源利用率和训练吞吐量。
在数据预处理方面,我们基于Megatron–Energon框架进行构建,并融合了自定义优化策略。我们的系统支持多种数据集的动态混合,这些数据集包含多样的模态,包括纯文本、单张图片、多图序列和视频,同时允许在每个数据集内严格保持样本顺序。自定义的基于WebDataset的格式实现了对多种数据模态的兼容,大幅减少了预处理时间,同时提升了数据处理的灵活性和可扩展性。
多维混合并行
多模态模型在架构和数据特性上与传统LLM有显著不同。在架构方面,多模态模型本质上是异构的:视觉模块(如带有Adaptor的ViT)通常是小规模的仅编码器组件,而语言模块则是更大的仅解码器Transformer。在数据方面,训练样本包括纯文本、单图像、多图像序列和视频。图像token、文本token以及融合后token序列的长度在样本间差异极大。
这些异构性给分布式训练框架带来了巨大挑战。为此,我们在自研框架FlagScale中实现了多项针对性策略:
- 非均匀流水线并行:由于ViT模块出现在模型前部且计算开销较低,我们减少了第一流水线阶段中的LLM层数,从而在不增加内存开销的情况下提升训练吞吐量。
- 分离重计算策略:在退火阶段,视觉输入可能包含多达2万至3万个token,ViT模块常因而OOM。为缓解此问题,我们仅在ViT模块启用重计算以减少中间激活的内存占用,而在LLM模块关闭重计算以保持计算效率。
内存预分配
在RoboBrain 2.0的有监督微调训练过程中,样本间输入长度差异极大。PyTorch默认的缓存内存分配器在如此动态输入条件下容易导致内存碎片,频繁引发OOM错误。
一种常见但低效的做法是在每次前向传播前调用torch.cuda.empty_cache(),但这会严重降低性能。我们通过分析PyTorch的内存分配机制,发现碎片化往往源于缺乏足够大且连续的缓存内存块用于新tensor,导致新分配并加剧碎片。
为此,我们引入了内存预分配策略:在训练前统计整个数据集的最大序列长度,并在第一步将所有样本填充至该最大长度。这样可确保tensor复用预分配的内存块,减少碎片并保持吞吐。
数据预处理
我们采用原生Megatron-Energon进行统一数据加载,无需外部训练框架。此外,我们优化了预处理流程,将耗时最多可减少90%。
我们评估并对比了两种预处理策略:
- 同时预处理JSON和图片。使用默认Megatron-Energon数据管道时,JSON元数据和图片均被压缩为WebDataset二进制文件。但该方法存在两大问题:(1)效率低:预处理32万样本需2小时以上;(2)图片读取器不一致:Megatron-Energon用cv2,而如RoboBrain 2.0等模型用PIL,可能引入细微差异影响训练表现。
- 仅预处理JSON(推荐)。在我们优化的流程中,仅对JSON文件预处理,图片保持原始格式。图片预处理延后至TaskEncoder模块,使用与Qwen2.5-VL一致的预处理器。(1)高效:32万样本预处理耗时不足10分钟;(2)与模型输入对齐:确保图片处理在预处理与训练阶段完全一致,消除不一致性并提升模型表现。
分布式数据加载
为减轻计算节点的I/O负担,我们在大规模分布式训练中减少冗余数据加载。与单节点不同,分布式训练系统中GPU因并行策略不同而角色各异。
数据加载通常发生在数据并行(DP)维度,每个DP rank处理唯一数据分片。但在多维混合并行(如DP-PP-TP)下,只有部分GPU进程需实际加载数据:
(1)在每个流水线并行(PP)组内,仅首尾阶段需加载数据;
(2)在张量并行(TP)组内,每组仅需一个GPU加载数据,其余通过广播接收。
该设计显著减少了冗余I/O操作,提升了整体数据吞吐。
容错机制
为应对训练过程中的硬件和软件故障,我们在FlagScale训练框架与系统平台间协同设计了容错机制。常见错误如LostCard、KubeNodeNotReady等会被自动检测并触发作业自动恢复与重启,确保最小中断。
此外,我们基于Megatron-Energon自定义的DataLoader模块支持完整数据状态恢复,可从最近的检查点无缝恢复,保证数据加载与样本洗牌状态完全一致。
强化微调基础设施
我们采用可验证奖励的强化学习(RLVR)对RoboBrain 2.0进行增强,使用VeRL,这是专为后训练LLM和VLM设计的开源RL框架。基于HybridFlow架构,VeRL具备混合控制器模型,集成了全局控制器用于RL角色间数据流协调,以及分布式控制器用于RL角色内并行处理。该架构支持高效执行复杂后训练流程,并确保可扩展性。
VeRL支持多种RL算法(如GRPO)并可无缝集成LLM,非常适合RoboBrain 2.0的强化微调(RFT)需求。该框架通过优化的数据流管理和并行处理能力,实现了高性能模型调优且开销极小。其对大规模训练任务的高效处理和严格的奖励验证,使VeRL成为通过RLVR提升RoboBrain 2.0能力的理想平台。
推理基础设施
为提升模型推理效率,我们采用FlagScale,这也是一个多后端推理框架,可根据不同模型在异构硬件加速器上的性能特征自动搜索最优推理引擎和配置参数,从而有效降低推理延迟。
鉴于具身AI模型对精度高度敏感,我们进一步引入了混合比特量化策略。该策略在保持模型性能的同时提升推理效率和资源利用率。具体而言,视觉编码器保留全精度浮点计算以确保关键特征提取的准确性;而在语言模块中,权重量化为8位整数,激活保持16位浮点格式。该混合精度方法在对模型精度影响可忽略的情况下,显著降低了计算开销和内存占用。
此外,量化过程对现有推理流程几乎无侵入性,可灵活集成至当前系统。在端到端具身任务中,仅权重量化即可实现约30%的推理延迟降低,显示了该方法在实际部署场景中的有效性与实用性。
评估结果
我们对 RoboBrain-2.0 进行了全面评估,重点关注其在具身空间和时间推理能力方面的表现。为确保评估的一致性和严谨性,我们采用了 FlagEvalMM,我们灵活的系统化多模态模型评测框架。空间推理基准(如 CV-bench、Blink、Where2Place、ShareRobot-Bench)的评测结果见6.1节,突出了该模型在具身空间推理方面的优势。对多机器人协作和长时序规划能力(如 EgoPlan2、RoboBench)的深入分析见 6.2节,展示了模型在时间推理任务上的进步。
空间推理能力
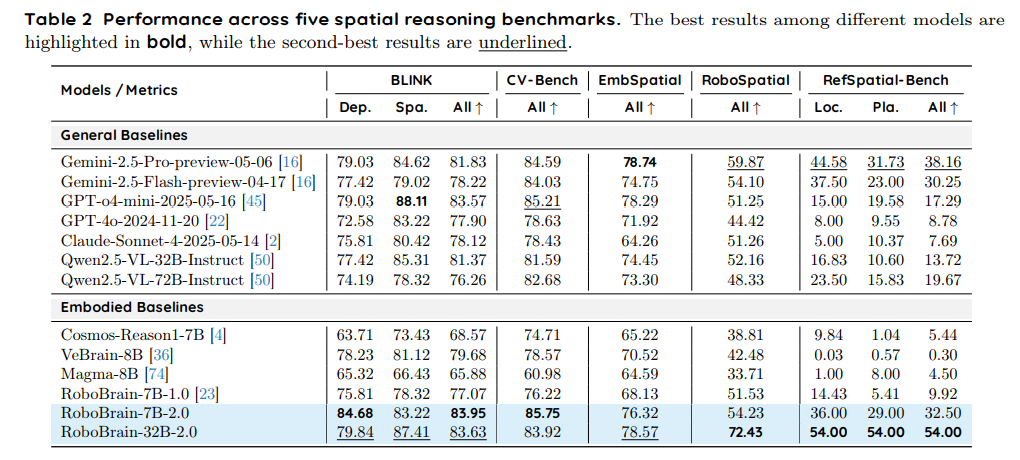
RoboBrain-32B-2.0 和 RoboBrain-7B-2.0 在九个空间推理基准上表现出色:BLINK、CV-Bench、EmbSpatial、RoboSpatial 和 RefSpatial-Bench(见表2),以及 SAT、VSI-Bench、Where2Place 和 ShareRobot-Bench(见表 3)。以下是对其取得的最新(SOTA)和接近 SOTA 竞争性结果的详细分析。
-
BLINK.
在 BLINK 基准中,模型被评估其深度感知(Dep.)和空间关系理解(Spa.)能力。RoboBrain-7B-2.0 取得了 SOTA 平均分 83.95(Dep.: 84.68, Spa.: 83.22),超过了所有通用基线,包括 GPT-o4-mini-2025-05-16(83.57)、Gemini-2.5-Pro-preview-05-06(81.83)、Qwen2.5-VL-32B-Instruct(81.37)、Claude-Sonnet-4-2025-05-14(78.12)、GPT-4o-2024-11-20(77.90)和 Qwen2.5-VL-72B-Instruct(76.26),以及具身基线如 VeBrain-8B(79.68)和 Cosmos-Reason1-7B(68.57)。RoboBrain-32B-2.0 紧随其后,平均分为 83.63(Dep.: 79.84, Spa.: 87.41),超过了除 RoboBrain-7B-2.0 外的所有通用和具身基线,展现了强大的空间推理能力。 -
CV-Bench.
CV-Bench 基准评估模型在 2D/3D 空间理解和视觉处理方面的准确性。RoboBrain-7B-2.0 以 SOTA 准确率 85.75 位居首位,略高于 RoboBrain-32B-2.0(83.92),两者均超过所有通用基线,包括 GPT-o4-mini-2025-05-16(85.21)、Gemini-2.5-Pro-preview-05-06(84.59)、Qwen2.5-VL-72B-Instruct(82.68)、Qwen2.5-VL-32B-Instruct(81.59)、GPT-4o-2024-11-20(78.63)和 Claude-Sonnet-4-2025-05-14(78.43),以及具身基线如 VeBrain-8B(78.57)和 Cosmos-Reason1-7B(74.71)。 -
EmbSpatial.
EmbSpatial 基准评估模型在具身空间任务中的表现。RoboBrain-32B-2.0 取得了接近 SOTA 的准确率 78.57,略低于 Gemini-2.5-Pro-preview-05-06(78.74),但超过了所有其他通用基线,包括 GPT-o4-mini-2025-05-16(78.29)、Qwen2.5-VL-32B-Instruct(74.45)、Qwen2.5-VL-72B-Instruct(73.30)、GPT-4o-2024-11-20(71.92)和 Claude-Sonnet-4-2025-05-14(64.26)。RoboBrain-7B-2.0 以 76.32 的分数紧随其后,超过了大多数通用基线和所有具身基线,显示出强大的具身空间推理能力。 -
RoboSpatial.
RoboSpatial 基准衡量机器人环境中的空间推理能力,如物体定位和操作。RoboBrain-32B-2.0 取得了明显的 SOTA 分数 72.43,远超通用基线如 Gemini-2.5-Pro-preview-05-06(59.87)、Qwen2.5-VL-72B-Instruct(48.33)、GPT-o4-mini-2025-05-16(51.25)和 Claude-Sonnet-4-2025-05-14(51.26)。RoboBrain-7B-2.0 得分 54.23,超过了除 RoboBrain-32B-2.0 外的所有通用基线,展现了在机器人任务空间推理方面的显著提升。 -
RefSpatial-Bench.
RefSpatial-Bench 基准评估模型在空间指代表达上的能力,需要在空间约束下进行精确的点预测,评测指标包括位置(Loc.)和放置(Pla.)准确率。RoboBrain-32B-2.0 取得了 SOTA 分数 54.00(Loc.)和 54.00(Pla.),显著超过所有通用基线,包括 Gemini-2.5-Pro-preview-05-06(44.58, 31.73)、Qwen2.5-VL-72B-Instruct(23.50, 15.83)、Qwen2.5-VL-32B-Instruct(16.83, 10.60)、GPT-o4-mini-2025-05-16(15.00, 19.58)、GPT-4o-2024-11-20(8.00, 9.55)和 Claude-Sonnet-4-2025-05-14(5.00, 10.37)。RoboBrain-7B-2.0 得分 36.00(Loc.)和 29.00(Pla.),超过了除 RoboBrain-32B-2.0 外的所有通用基线,在复杂空间指代任务中展现了竞争性的精度。
- SAT.
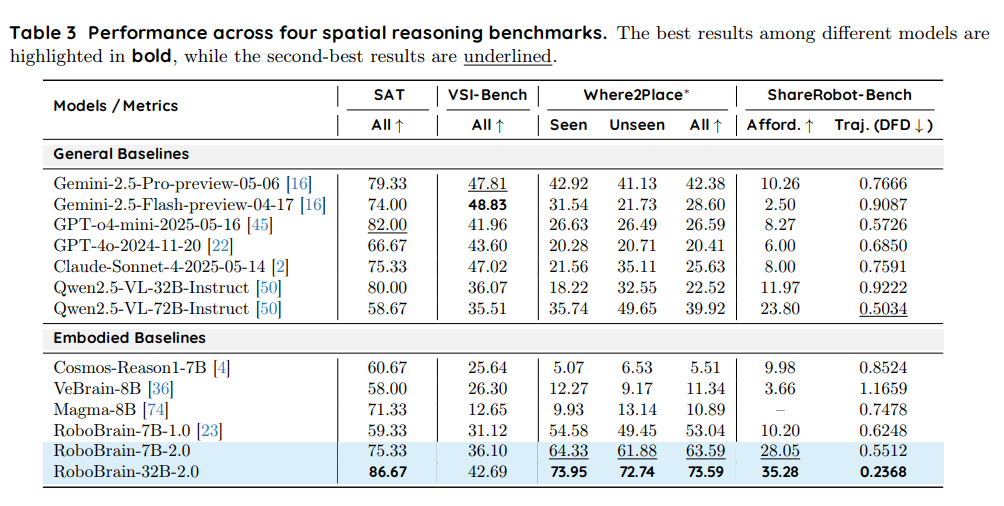
SAT 基准衡量模型在各种场景和任务中的一般空间推理能力。RoboBrain-32B-2.0 取得了明显的 SOTA 分数 86.67,显著超过所有通用基线,包括 GPT-o4-mini-2025-05-16(82.00)、Gemini-2.5-Pro-preview-05-06(79.33)、Qwen2.5-VL-72B-Instruct(58.67)和 Claude-Sonnet-4-2025-05-14(75.33)。RoboBrain-7B-2.0 得分 75.33,超过了大多数通用和具身基线,展现了其强大的空间推理能力。
*经检查,我们发现测试集中包含若干错误案例,已手动筛查并剔除。
-
VSI-Bench.
VSI-Bench 评估视觉-空间整合能力。Gemini-2.5-Flash-preview-04-17 取得了最佳表现 48.83。RoboBrain-32B-2.0 得分 42.69,超过了大多数通用和具身基线,包括 GPT-o4-mini-2025-05-16(41.96)和 Qwen2.5-VL-72B-Instruct(35.51)。RoboBrain-7B-2.0 得分 36.10,显示出扎实的视觉-空间整合能力。 -
Where2Place.
Where2Place 基准衡量模型在空间约束下预测物体放置(包括已见和未见场景)的能力。RoboBrain-32B-2.0 取得了 SOTA 平均分 73.59(已见:73.95,未见:72.74),大幅超过所有通用和具身基线,包括 Qwen2.5-VL-72B-Instruct(39.92)、Gemini-2.5-Pro-preview-05-06(42.38)、Claude-Sonnet-4-2025-05-14(25.63)和 VeBrain-8B(11.34)。RoboBrain-7B-2.0 也表现优异,平均分为 63.59(已见:64.33,未见:61.88),超过了除 RoboBrain-32B-2.0 外的所有基线。 -
ShareRobot-Bench-Affordance.
ShareRobot Affordance 任务评估模型对物体功能性和交互理解的能力。RoboBrain-32B-2.0 以 35.28 的准确率取得了 SOTA 表现,领先于所有通用基线,包括 Qwen2.5-VL-72B-Instruct(23.80)、Qwen2.5-VL-32B-Instruct(11.97)、GPT-4o-2024-11-20(6.00)和 Claude-Sonnet-4-2025-05-14(8.00)。RoboBrain-7B-2.0 得分 28.05,超过了除 RoboBrain-32B-2.0 外的所有通用和具身基线。 -
ShareRobot-Bench-Trajectory.
ShareRobot Trajectory 任务评估导航和运动预测能力,采用动态 Fréchet 距离(DFD),数值越低表示性能越好。RoboBrain-32B-2.0 取得了 SOTA DFD 0.2368,超过了所有通用和具身基线,包括 Qwen2.5-VL-72B-Instruct(0.5034)、GPT-o4-mini-2025-05-16(0.5726)和 Gemini-2.5-Pro-preview-05-06(0.7666)。RoboBrain-7B-2.0 以 0.5512 的 DFD 紧随其后,展现了强大的路径规划能力。
时间推理能力
RoboBrain-32B-2.0 和 RoboBrain-7B-2.0 在三项关键的时间推理基准上表现卓越:多机器人规划、Ego-Plan2 和 RoboBench,如表4 所示。以下是对其取得的最新(SOTA)和接近 SOTA 结果的详细分析。
-
多机器人规划
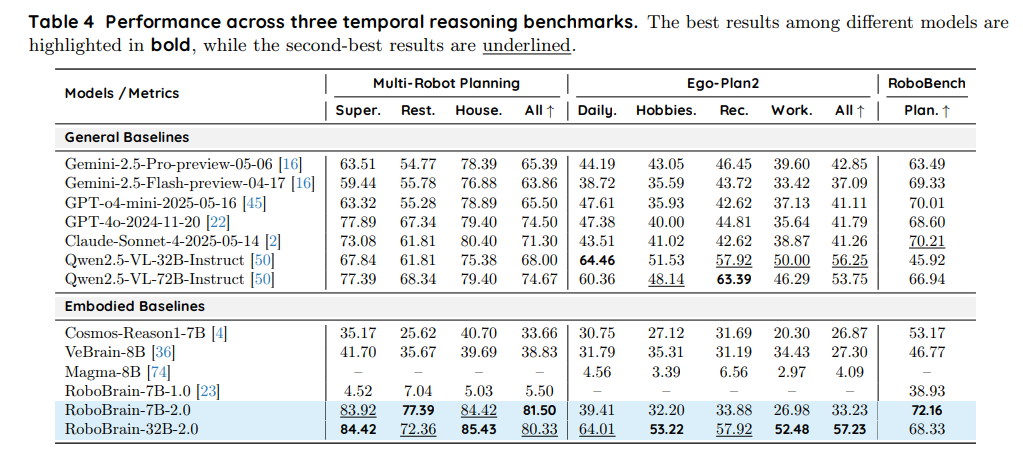
在多机器人规划任务中,模型被评估其在不同场景下协调多台机器人的能力:Super(超市)、Rest(餐厅)和 House(家庭)。RoboBrain-32B-2.0 取得了 SOTA 平均分 80.33(Super: 84.42,Rest: 72.36,House: 85.43),显著超过所有通用基线,包括 GPT-4o-2024-11-20(74.50)、Qwen2.5-VL-72B-Instruct(74.67)、Claude-Sonnet-4-2025-05-14(71.30)、Gemini-2.5-Pro-preview-05-06(65.39)和 Qwen2.5-VL-32B-Instruct(68.00)。它还超过了具身基线 RoboBrain-7B-2.0(81.50)。RoboBrain-7B-2.0 以平均分 81.50 紧随其后(Super: 83.92,Rest: 77.39,House: 84.42),超过了所有通用基线,并在 Rest 和 House 场景下与 RoboBrain-7B-1.5-OS 的表现持平。 -
Ego-Plan2
Ego-Plan2 基准评估模型在四个类别下规划日常活动的能力:Daily(日常)、Hobbies(爱好)、Rec(娱乐)和 Work(工作)。RoboBrain-32B-2.0 取得了 SOTA 平均分 57.23(Daily: 64.01,Hobbies: 53.22,Rec: 57.92,Work: 52.48),显著超过所有通用和具身基线,包括 Qwen2.5-VL-32B-Instruct(56.25)、Qwen2.5-VL-72B-Instruct(53.75)、Gemini-2.5-Pro-preview-05-06(42.85)、GPT-4o-2024-11-20(41.79)、Claude-Sonnet-4-2025-05-14(41.26)、GPT-o4-mini-2025-05-16(41.11)、VeBrain-8B(27.30)和 Cosmos-Reason1-7B(26.87)。相比之下,RoboBrain-7B-2.0 平均分为 33.23(Daily: 39.41,Hobbies: 32.20,Rec: 33.88,Work: 26.98),低于 Qwen2.5-VL-32B-Instruct 和 Qwen2.5-VL-72B-Instruct 等通用基线,但超过了 VeBrain-8B 和 Cosmos-Reason1-7B 等具身基线。 -
RoboBench
RoboBench 基准(规划部分)评估模型根据预定义技能规划机器人移动操作任务的能力,涵盖跨具身体、跨物体和跨视角三类。在该基准上,RoboBrain-7B-2.0 取得了 SOTA 分数 72.16,超过了所有通用和具身基线,包括 Claude-Sonnet-4-2025-05-14(70.21)、GPT-o4-mini-2025-05-16(70.01)。RoboBrain-32B-2.0 得分为 68.33,超过了 GPT-4o-2024-11-20(68.60)和 Qwen2.5-VL-72B-Instruct(66.94)等多个通用基线,以及 Cosmos-Reason1-7B(53.17)和 VeBrain-8B(46.77)等其他具身基线。
结论与未来工作
在本报告中,我们介绍了 RoboBrain 2.0,这是我们最新一代的具身视觉-语言基础模型,旨在支持复杂物理环境中的统一感知、推理与规划。RoboBrain 2.0 基于模块化架构,配备专用视觉编码器和仅解码语言模型,实现了高分辨率图像与视频理解,以及空间和时间推理。通过渐进式的三阶段训练策略——涵盖基础时空学习、具身增强和链式思维推理——该模型在各种具有挑战性的具身任务中展现出强大的泛化能力。尽管体积紧凑,RoboBrain 2.0 在大多数公开的具身空间与时间推理基准上取得了业界领先的结果,在空间理解、闭环交互和长时规划方面超越了开源和专有模型。其能力覆盖了广泛的具身场景,包括可供性预测、空间指代、轨迹预测、多智能体协作以及场景图构建与更新。
我们认为 RoboBrain 2.0 是迈向更通用具身人工智能的坚实基础,强调感知、推理与规划的紧密集成。展望未来,我们计划从两个关键方向扩展 RoboBrain 2.0:
-
具身VLM驱动的VLA: 我们旨在将最前沿的具身视觉-语言模型(VLM)集成到视觉-语言-动作(VLA)框架中。通过利用VLM强大的时空感知和高级推理能力,该方向力求显著提升动作生成的通用性与鲁棒性。由此产生的系统将支持对复杂、开放式指令的更细致理解和更精确执行,适用于真实世界场景。
-
系统级集成: 为提升 RoboBrain 2.0 的实际应用价值,我们将推动其与先进机器人平台和操作系统的紧密集成。这将实现无服务器部署、无需适配的技能注册以及低延迟实时控制。与此同时,我们设想构建一个协作式具身人工智能生态系统——一个“智能应用商店”——支持现实机器人系统中感知、推理与控制的即插即用组件。
我们在 https://superrobobrain.github.io 发布了 RoboBrain 2.0,包括模型检查点、训练配方和评测工具,以支持具身人工智能领域更广泛的研究和下游应用。我们希望这项工作能够弥合视觉-语言智能与现实物理交互之间的鸿沟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号