RoboBrain:一个从抽象到具体的统一机器人操作大脑模型
https://arxiv.org/abs/2502.21257
摘要
近年来,多模态大语言模型(MLLMs)在多模态场景中展现出了卓越的能力。然而,它们在机器人场景中的应用,尤其是长时序操作任务,仍存在显著局限。这些局限主要源于当前MLLMs缺乏三项机器人“大脑”核心能力:规划能力(将复杂操作指令分解为可管理的子任务)、可供性感知(识别和理解交互对象的可供性)、以及轨迹预测(预见完成操作所需的完整轨迹)。为提升机器人“大脑”从抽象到具体的核心能力,我们提出了 ShareRobot,一个高质量、异构的大规模数据集,标注了任务规划、对象可供性和末端执行器轨迹等多维信息。ShareRobot 的数据多样性和准确性由三位人工标注者精心打磨。在此基础上,我们开发了 RoboBrain,一个基于 MLLM 的模型,结合了机器人和通用多模态数据,采用多阶段训练策略,并引入长视频和高分辨率图像,以提升其机器人操作能力。大量实验表明,RoboBrain 在多项机器人任务中取得了业界领先的性能,展现出推动机器人“大脑”能力提升的巨大潜力。
引言
近年来,多模态大语言模型(MLLMs)的发展极大推动了通用人工智能(AGI)的进步。通过利用来自互联网的大规模多模态数据集,并采用自监督学习技术,MLLMs 在视觉感知和理解人类语言指令方面表现出色,能够胜任如视觉问答、图像描述和情感分析等任务。尽管 MLLMs 取得了显著进展,但其在机器人领域的应用探索仍处于早期阶段,这也是亟需进一步研究和创新的重要方向。
近期的研究开始关注 MLLMs 在机器人领域的应用,主要聚焦于规划与子目标分解、动作序列生成、以及重规划与反馈等方面。然而,在机器人场景,尤其是长时序操作任务中,现有 MLLMs 的表现仍存在明显不足。这些不足主要体现在缺乏三项关键能力:规划、可供性感知和轨迹预测。例如,考虑一个机械臂需要提起茶壶并将水倒入杯中的任务,MLLM 应能够将该任务分解为“靠近并提起茶壶”、“移动茶壶至壶嘴对准杯子上方”、“倾斜茶壶倒水”等子任务。对于每个子任务,如“靠近并抓取茶壶”,MLLM 还需具备可供性感知能力,准确识别茶壶的可抓取区域。此外,轨迹预测能力对于规划从起点到茶壶可抓取部位的完整路径也至关重要。现有 MLLMs 在这些方面的挑战,主要源于缺乏专为机器人操作任务设计的大规模、细粒度数据集。

为赋予 RoboBrain 从抽象指令理解到具体动作表达的核心能力,我们首先提出了 ShareRobot,一个专为机器人操作任务设计的大规模、细粒度数据集,标注了任务规划、对象可供性和末端执行器轨迹等多维信息。在 ShareRobot 基础上,我们开发了 RoboBrain,一个基于 LLaVA 架构的 MLLM 模型,旨在提升机器人在复杂任务中的感知与规划能力。在 RoboBrain 的训练过程中,我们精心设计了机器人数据与通用多模态数据的比例,采用多阶段训练策略,并引入长视频和高分辨率图像。这一方法赋予了 RoboBrain 在机器人场景下强大的视觉信息感知能力,支持历史帧记忆和高分辨率图像输入,进一步提升了其在机器人操作规划中的能力。大量实验结果表明,RoboBrain 在 RoboVQA 和 OpenEQA 等多个机器人基准测试中均取得了业界领先的性能,并在轨迹和可供性预测准确率方面表现优异。这些结果验证了所提出数据集和框架在提升机器人“大脑”能力方面的有效性。
主要贡献如下:
- 提出 RoboBrain,一个面向机器人操作的统一多模态大语言模型,实现了从抽象指令到具体动作的高效转化。
- 精心设计了机器人数据与通用多模态数据的比例,采用多阶段训练策略,并引入长视频和高分辨率图像,使 RoboBrain 具备历史帧记忆和高分辨率图像输入能力,进一步提升了其机器人操作规划能力。
- 提出 ShareRobot,一个高质量、异构的数据集,标注了任务规划、对象可供性和末端执行器轨迹等多维信息,有效提升了多项机器人能力。
- 大量实验结果表明,RoboBrain 在多项机器人基准测试中取得了业界领先的性能,展现出其在实际机器人应用中的巨大潜力。
相关工作
用于机器人操作规划的多模态大语言模型(MLLM)
现有研究大多利用 MLLM 主要聚焦于自然语言和视觉观测任务的理解,对于将高层任务指令分解为可执行步骤的研究相对较少。PaLM-E 通过将真实世界观测映射到语言嵌入空间来生成多模态输入。RT-H 和 RoboMamba 则在生成推理结果的同时,通过额外的策略头获得机器人动作。然而,尽管这些模型能够生成规划文本和动作,但在执行复杂原子任务方面仍缺乏足够的机制,凸显了提升可供性感知和轨迹预测能力的必要性。
用于操作规划的数据集
早期的操作数据集主要包含标注的图像和视频,突出展示了基本的手-物体交互,如抓取和推动。近期在机器人操作领域的进展强调了多模态和跨形态数据集,以提升泛化能力。诸如 RH20T、BridgeDataV2 和 DROID 等数据集增强了场景多样性,拓宽了操作场景的范围。值得注意的是,RT-X 将来自 60 个数据集、22 种形态的数据整合到 Open X-Embodiment(OXE)资源库中。在本工作中,我们从 OXE 中提取高质量数据,将高层描述分解为低层规划指令,并将其转化为问答格式,以增强模型训练效果。
ShareRobot 数据集
为了增强 RoboBrain 在规划、可供性感知和轨迹预测方面的能力,我们开发了 ShareRobot 数据集——一个专为机器人操作任务设计的大规模、细粒度数据集。数据集的生成流程如图所示。具体细节如下:
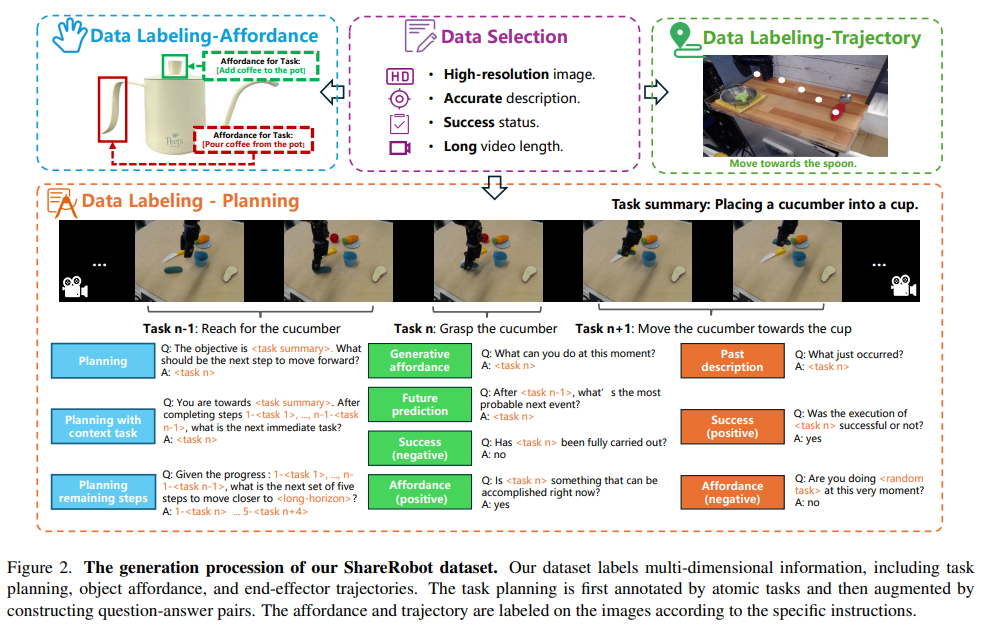
总览
ShareRobot 是一个综合性数据集,通过将抽象概念转化为具体动作,促进更高效的任务执行。其主要特点包括:
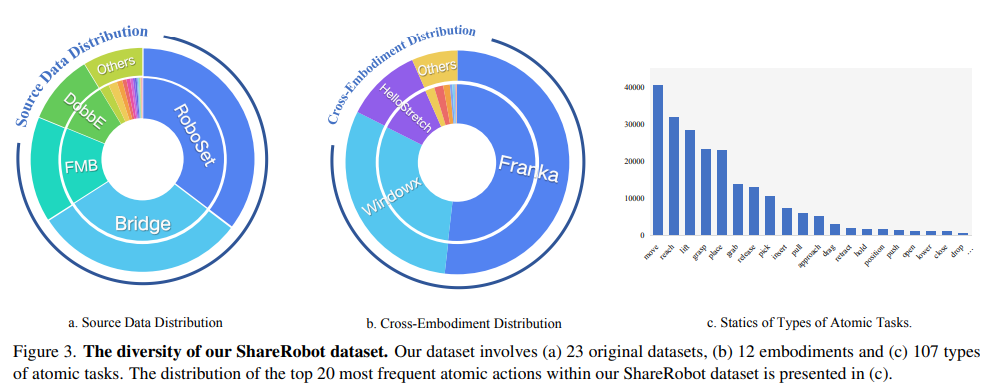
- 细粒度:与 Open X-Embodiment 数据集仅提供高层任务描述不同,ShareRobot 的每个数据点都包含与单帧关联的详细低层规划指令。这种细致性提升了模型在恰当时机执行任务的准确性。
- 多维度:为提升 RoboBrain 从抽象到具体的能力,我们标注了任务规划、对象可供性和末端执行器轨迹,使任务处理更加灵活和精确。
- 高质量:我们制定了严格的数据筛选标准,关注高分辨率、描述准确、任务成功、可供性可见和运动轨迹清晰。最终筛选出 51,403 条高质量数据,为 RoboBrain 的核心能力奠定基础。
- 大规模:ShareRobot 包含 1,027,990 对问答数据,是目前最大规模的开放式任务规划、可供性感知和轨迹预测数据集,有助于深入理解从抽象到具体的复杂关系。
- 丰富多样性:与 RoboVQA 数据集场景有限不同,ShareRobot 涵盖 12 种机器人形态、102 个场景和 107 种原子任务类型。这种多样性有助于 MLLM 在多变的真实环境中学习,提升复杂多步规划的鲁棒性。
- 易扩展性:我们的数据生成流程高度可扩展,便于随着新机器人形态、任务类型和环境的出现进行扩充,确保 ShareRobot 能支持日益复杂的操作任务。
数据筛选
基于 Open X-Embodiment 数据集,我们精心筛选了 51,403 条数据,主要关注图像质量、描述准确性和任务成功状态。具体原则如下:
- 高分辨率图像:剔除缺少图像或分辨率低于 128 像素的视频。
- 描述准确:过滤无描述或描述模糊的视频,避免影响模型的规划能力。
- 任务成功:剔除失败演示的视频,避免影响模型学习。
- 视频长度:剔除帧数少于 30 的视频,这类视频包含的原子任务有限。
- 目标无遮挡:移除目标物体或末端执行器被遮挡的视频,确保模型能准确识别位置和可供性。
- 轨迹清晰:剔除轨迹不清晰或不完整的演示,因为轨迹预测是 RoboBrain 的能力之一。
数据标注
规划标注
我们从每条机器人操作演示中抽取 30 帧,结合高层描述,利用 Gemini 将其分解为低层规划指令。三位标注员对指令进行审核和优化,确保标注准确。随后,我们为 RoboVQA 的 10 种问题类型各设计 5 种模板,在数据生成时为每条数据随机选取 2 个模板生成问答对。最终将 51,403 条数据扩展为 1,027,990 对问答数据,并由标注员监控生成过程,确保数据完整性。
可供性标注
我们筛选出 6,522 张图像,并根据高层描述为每张图像标注可供性区域,格式为 {左上角 (x, y),右下角 (x, y)}。随后对每条标注进行严格人工审核和优化,确保与可供性区域精准对应。
轨迹标注
我们筛选出 6,870 张图像,并根据低层指令为每张图像标注末端执行器轨迹,至少包含三个 (x, y) 坐标点。随后对每条标注进行严格人工审核和优化,确保与轨迹精准对应。
数据统计
我们从 Open X-Embodiment 数据集中选取了 23 个原始数据集,涵盖 102 个不同场景(如卧室、实验室、厨房、办公室)和 12 种机器人形态。统计显示,数据集中包含 132 种原子动作,出现频率最高的 5 种为 “pick”、“move”、“reach”、“lift”、“place”,这些都是实际机器人操作中常见的任务类型,说明数据分布合理。最终,我们获得了 1,027,990 对规划问答数据,其中 100 万对用于训练,2,050 对用于测试。可供性数据集中,6,000 张用于训练,522 张用于测试。轨迹数据集中,6,000 张用于训练,870 张用于测试。
RoboBrain 模型
本节将介绍 RoboBrain 的整体架构。我们的目标是让多模态大语言模型(MLLM)能够理解抽象指令,并显式输出对象可供性区域和潜在操作轨迹,实现从抽象到具体的转化。我们采用多阶段训练策略:第一阶段聚焦于通用 OneVision(OV)训练,构建具备强大理解和指令跟随能力的基础 MLLM;第二阶段则专注于机器人训练,赋予 RoboBrain 从抽象到具体的核心能力。
模型架构
RoboBrain 由三大模块组成:用于规划的基础模型、用于可供性感知的 A-LoRA 模型,以及用于轨迹预测的 T-LoRA 模型。在实际应用中,模型首先生成详细的任务规划,然后将其拆分为子任务描述,分别执行可供性感知和轨迹预测。整体流程如图所示。
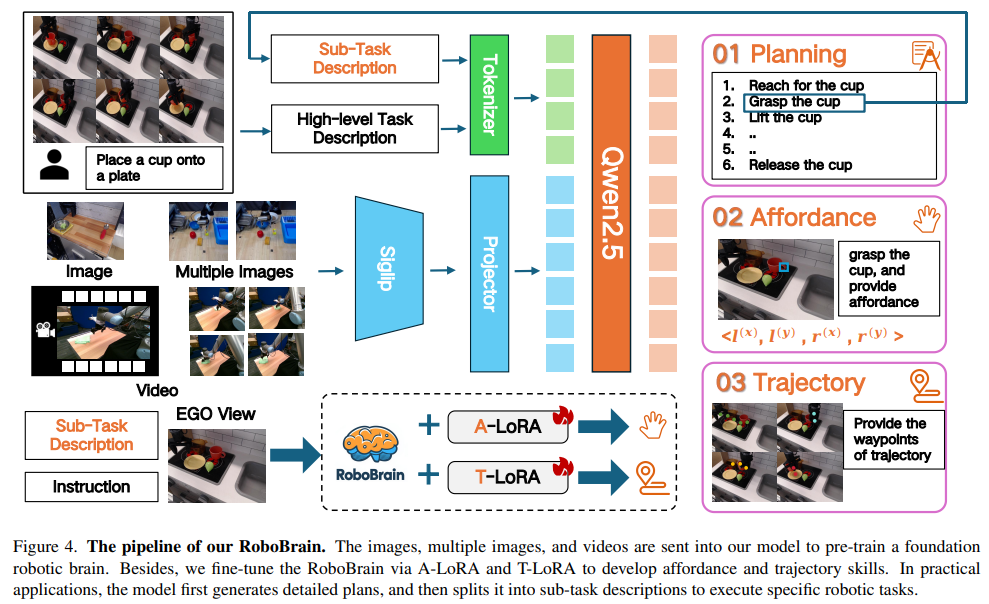
用于规划的基础模型
我们采用 LLaVA 作为 RoboBrain 的基础模型,包含三个主要模块:视觉编码器(ViT)、投影器(Projector)和大语言模型(LLM)。具体来说,我们使用 SigLIP 作为视觉编码器,2 层 MLP 作为投影器,以及 Qwen2.5-7B-Instruct 作为 LLM。给定图像或视频 \(X_v\) 作为视觉输入,ViT 将其编码为视觉特征 \(Z_v = g(X_v)\),再通过投影器映射到 LLM 的语义空间,得到视觉 token 序列 \(H_v = h(Z_v)\)。最后,LLM 基于人类语言指令 \(X_t\) 和 \(H_v\),以自回归方式生成文本响应。
A-LoRA 模块:可供性感知
在本工作中,可供性指的是人手与物体接触的区域。人类在与物体交互时,通常会本能地在特定区域进行接触。我们用“边界框”来表示可供性。形式化地,设图像 \(I\) 包含多个物体及其可供性:\(O_i = \{A_{i}^{0}, A_{i}^{1}, ..., A_{i}^{N}\}\),其中第 \(i\) 个物体有 \(N\) 个可供性。可供性的格式为 \(\{l^{(x)}, l^{(y)}, r^{(x)}, r^{(y)}\}\),其中 \(\{l^{(x)}, l^{(y)}\}\) 表示左上角坐标,\(\{r^{(x)}, r^{(y)}\}\) 表示右下角坐标。
T-LoRA 模块:轨迹预测
在本工作中,轨迹指的是“二维视觉轨迹”。我们将轨迹关键点定义为一系列二维坐标,表示末端执行器或手在操作过程中的移动。形式化地,在时间步 \(t\),轨迹关键点可表示为 \(P_{t:N} = \{(x_i, y_i) \mid i = t, t + 1, ..., N\}\),其中 \((x_i, y_i)\) 是第 \(i\) 个轨迹点,\(N\) 为整个操作序列的总步数。
训练策略
阶段一:通用 OneVision 训练
在第一阶段,我们借鉴了 LLaVA-OneVision 的训练数据和策略,构建了具备通用多模态理解和视觉指令跟随能力的基础模型,为后续机器人操作规划能力的提升打下基础。详细配置信息见表格。
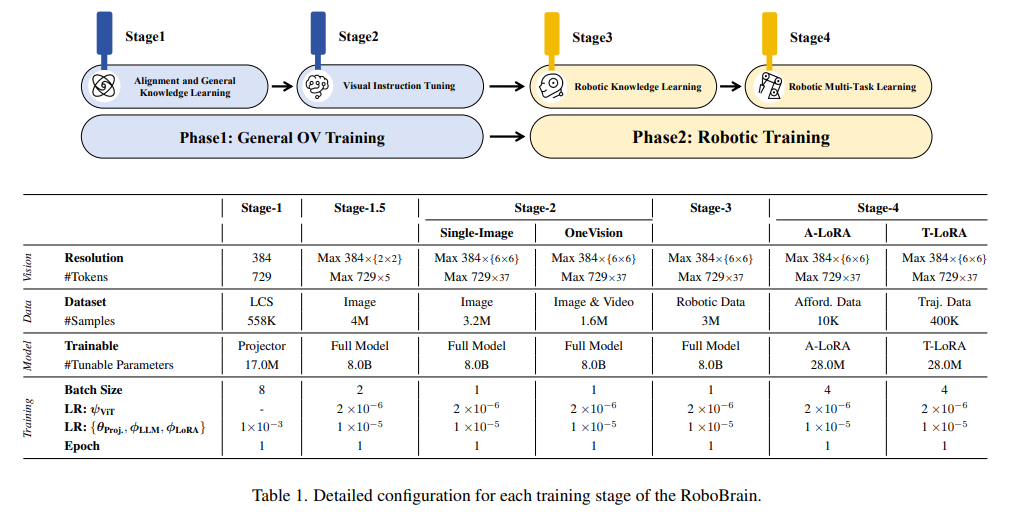
在 Stage 1,我们使用 LCS-558K 数据集的图文数据训练投影器,实现视觉特征 \(Z_v\) 与 LLM 语义特征 \(H_v\) 的对齐。Stage 1.5 使用 400 万高质量图文数据训练整个模型,提升多模态通用知识理解能力。Stage 2 进一步用 320 万单图像数据和 160 万图像及视频数据训练整个模型,增强 RoboBrain 的指令跟随能力和高分辨率图像、视频理解能力。
阶段二:机器人训练
在第二阶段,我们基于第一阶段构建的强大多模态基础模型,进一步提升其机器人操作规划能力。具体来说,我们希望 RoboBrain 能理解复杂抽象指令,支持历史帧信息和高分辨率图像感知,并输出对象可供性区域和预测潜在操作轨迹,实现从抽象到具体的转化。详细配置信息见表格。
在 Stage 3,我们收集了 130 万条机器人数据,提升模型的操作规划能力。数据来源包括 RoboVQA-800K、ScanView-318K(含 MMScan-224K、3RScan-43K、ScanQA-25K、SQA3d-26K)以及本文提出的 ShareRobot-200K 子集。这些数据涵盖丰富的场景扫描图像、长视频和高分辨率数据,增强模型对多样环境的感知能力。ShareRobot 数据集中的细粒度高质量规划数据进一步提升了 RoboBrain 的操作规划能力。为缓解灾难性遗忘问题,我们从第一阶段选取约 170 万高质量图文数据,与 Stage 3 的机器人数据混合训练,微调整个模型。Stage 4 则通过引入 ShareRobot 及其他开源数据集的可供性和轨迹数据,利用 LoRA 模块训练,增强模型从指令中感知可供性和预测操作轨迹的能力,实现具体操作能力的提升。
实验
实现细节
在整个训练阶段,我们采用了 Zero3 分布式训练策略,所有实验均在配备 8 张 A800 GPU 的服务器集群上进行。每个阶段的训练组件,包括图像分辨率设置、批量大小、轮数和学习率等,详见表格。
评测指标
规划任务
我们选择 RoboVQA、OpenEQA 以及 ShareRobot 的测试集作为机器人多维度评测基准。在 RoboVQA 上,我们采用 BLEU1 至 BLEU4 作为评测指标。在 OpenEQA 和 ShareRobot 上,我们使用 GPT-4o 作为评测工具,根据模型预测与真实答案的一致性或相似性进行打分,作为模型最终性能分数。
可供性预测
我们采用平均精度(AP)来评估模型的可供性预测能力。AP 指标总结了不同阈值下的精度-召回曲线,并在多个 IoU 阈值下计算,以获得更全面的评估。
轨迹预测
我们评估模型预测轨迹与真实轨迹的相似性,二者均表示为归一化到 [0, 1000) 的二维路径点序列。评测指标包括离散 Fréchet 距离(DFD)、Hausdorff 距离(HD)和均方根误差(RMSE)。DFD 衡量整体形状和时序对齐,HD 反映最大偏差,RMSE 衡量平均点误差,三者共同提供了轨迹准确性和相似性的全面评估。
机器人大脑任务评测
规划任务评测
我们选取了 6 个强大的多模态大语言模型(MLLM)作为对比基线,涵盖开源和闭源、不同架构。具体包括 GPT-4V、Claude3、LLaVA-1.5、LLaVA-OneVision-7b、Qwen2-VL-7b 和 RoboMamba。实验结果如雷达图所示。RoboBrain 在三个机器人基准上均超越所有基线模型,尤其在 OpenEQA 和 ShareRobot 上表现突出,得益于其对机器人任务和长视频的强大理解能力。在 RoboVQA 上,RoboBrain 的 BLEU-4 分数比第二名高出 18.75,展现了其复杂长序列任务分解能力。

可供性预测评测
结果如表所示。我们与 Qwen2-VL-7B 和 LLaVA-NeXT-7B 进行了对比。Qwen2-VL 具备更强的视觉定位能力,LLaVA-NeXT 拥有高分辨率和强大的视觉塔。我们在 AGD20K 可供性测试集上评测,RoboBrain 显著优于其他模型,AP 分别比 Qwen2-VL 提高 14.6,比 LLaVA-NeXT 提高 17.3,验证了 RoboBrain 能准确理解物体物理属性并给出可供性区域。
| 模型 | AP ↑ |
|---|---|
| LLaVA-NeXT-7B | 9.8% |
| Qwen2-VL-7B | 12.5% |
| RoboBrain(本工作) | 27.1%(+14.6) |
轨迹预测评测
我们比较了模型的多个变体,结果如下表:
- Baseline:在轨迹相关 VQA 数据上微调;
- Start_Points:加入末端执行器二维起始坐标;
- Max_Points:通过均匀采样将路径点限制为 10 个;
- Spec_Token & End_Points:加入末端执行器位置和特殊 token,强调路径点及起止点。
最终模型集成了所有设计,DFD、HD、RMSE 分别比基线下降 42.9%、94.2%、31.6%。加入起点后,有效纠正了生成轨迹与末端执行器的平移偏差。
| 方法 | DFD ↓ | HD ↓ | RMSE ↓ |
|---|---|---|---|
| RoboBrain (Base) | 0.191 | 0.171 | 0.133 |
| + Start_Points | 0.176 | 0.157 | 0.117 |
| + Max_Points | 0.185 | 0.163 | 0.125 |
| + Spec_Token | 0.109(-42.9%) | 0.010(-94.2%) | 0.091(-31.6%) |
可视化
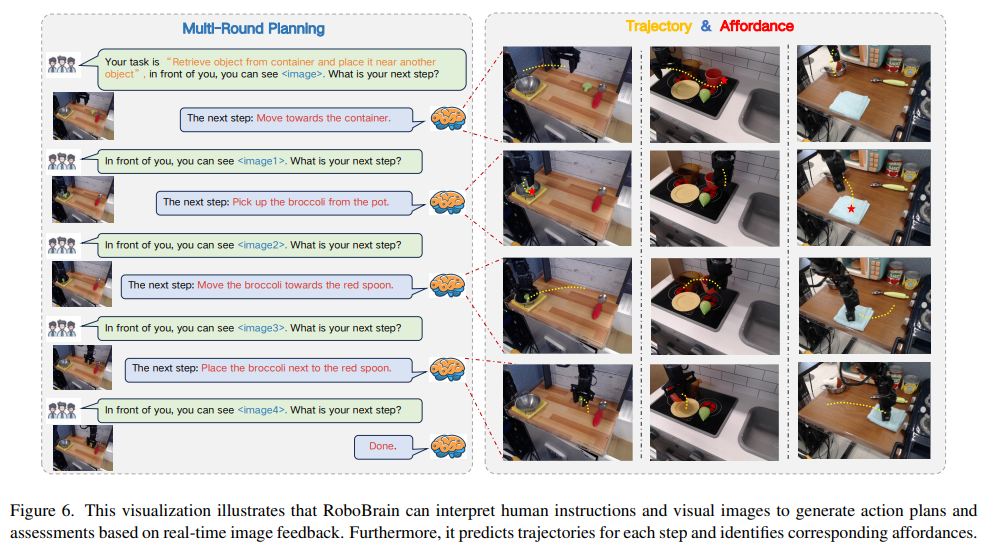
下图展示了 RoboBrain 的可视化案例。给定人类指令和视觉输入,RoboBrain 能进行多轮交互,理解并规划后续步骤,同时输出更具体的可供性区域和轨迹。
结论
本文提出了 ShareRobot,一个高质量的数据集,标注了任务规划、对象可供性和末端执行器轨迹等多维信息。同时,我们提出了 RoboBrain,一个基于多模态大语言模型(MLLM)的模型,融合了机器人和通用多模态数据,采用多阶段训练策略,并引入长视频和高分辨率图像以提升机器人操作能力。大量实验表明,RoboBrain 在多项机器人任务中取得了业界领先的性能,展现出显著推动机器人能力提升的潜力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号