

自主决定是否需要思考Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models
https://arxiv.org/abs/2505.16854
https://github.com/kokolerk/TON
摘要
强化学习(RL)已被证明是提高视觉-语言模型(VLMs)推理能力的有效后训练策略。组相对策略优化(GRPO)是一种近期突出的方法,通过鼓励模型在回答之前生成完整的推理轨迹,从而提高标记的使用量和计算成本。受人类思维过程的启发,人们在面对简单问题时会跳过推理,而在必要时会仔细思考,我们探索如何使VLMs首先决定何时需要进行推理。为此,我们提出了一种两阶段训练策略TON:(i)监督微调(SFT)阶段,采用简单而有效的“思维丢弃”操作,其中推理轨迹被随机替换为空白思维。这引入了一种“思考与否”的格式,作为选择性推理的冷启动;(ii)GRPO阶段,使模型能够自由探索何时思考或不思考,同时最大化任务导向的结果奖励。实验结果表明,与普通GRPO相比,TON可以将完成长度减少多达90%,同时不会牺牲性能,甚至有所提高。进一步的评估涵盖了视觉-语言任务的多样性,包括在3B和7B模型下不同推理难度的任务,一致显示模型随着训练的推进逐步学会跳过不必要的推理步骤。这些发现为强化学习方法中的人类思维模式提供了新的视角。
引言
“思考还是不思考,这是个问题。”
强化学习(RL)近年来已成为视觉-语言模型(VLMs)中主流的监督后微调(SFT)策略 [1, 2, 3, 4]。诸如 GRPO [5] 等方法通过基于规则驱动奖励的 KL 散度损失展示了增强推理能力的有希望的结果。然而,这些方法由于依赖于全长生成轨迹,通常会导致不必要的冗长和重复的推理过程 [6, 7, 8]。为了解决这一低效问题,一些工作试图在预训练阶段通过基于规则的奖励惩罚缩短推理链 [9, 10, 11],或者引入外部控制机制,如最近的 Qwen3 [12]。然而,更自然和可扩展的解决方案是使模型能够决定何时进行思考——类似于人类根据任务难度调整认知努力的方式。
在本研究中,我们首先通过实证证据表明,思考并不总是必要的。在 AITZ [13] 中,我们观察到即使是完全省略整个推理过程,仍有 51% 的问题可以正确回答,从而显著节省了思考资源。这一发现强调了选择性推理策略在提高效率的同时不牺牲准确性的潜力。其次,通过探索一种简单的提示策略——允许模型跳过简单查询的推理步骤——我们观察到,即使是增强了数学能力的多模态语言模型(VLMs)也难以适应性地省略冗余的思考生成。相反,它们往往采取保守的方法,无论任务难度如何,都会生成完整的推理路径。这表明,“思考与否”的能力不仅取决于推理能力,而应被视为一种独立的技能——这种技能应通过监督微调(SFT)阶段的格式遵循明确激活。
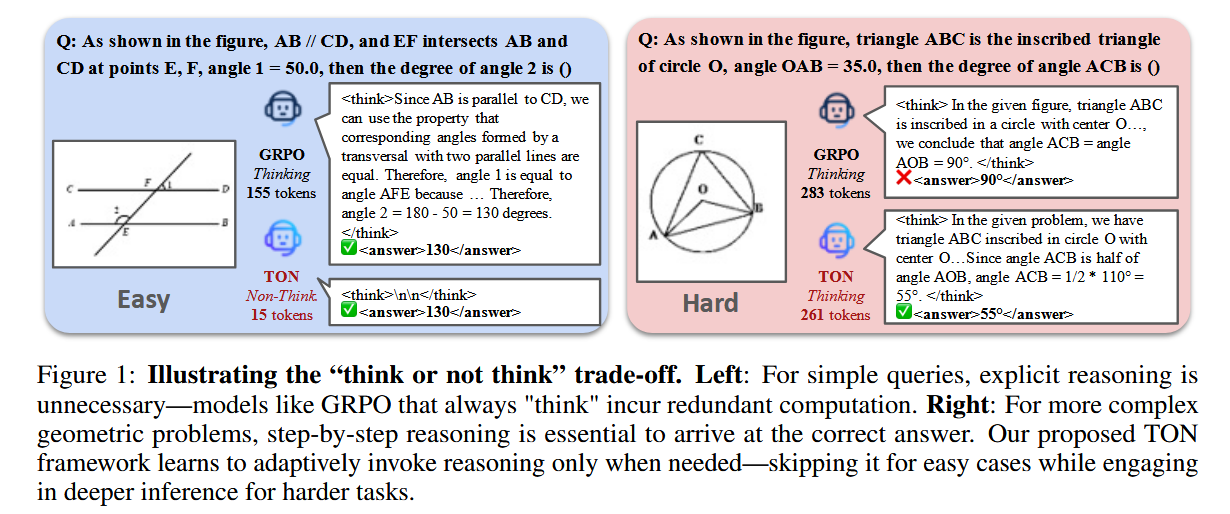
基于上述观察,我们引入了TON(即“思考与否”),这是一种采用简单而有效的“思考丢弃”方法的两阶段训练框架。该方法显式地将推理路径替换为最小的“\n\n”分隔符,并通过SFT训练模型,使其能够跳过推理——从而实现推理的绕过。随后的GRPO阶段通过自我探索进一步完善这种选择性推理策略,奖励不引入额外正则化的答案。如图1所示,传统的GRPO在任何任务难度下都会一致地生成推理序列。相反,我们的方法TON能够根据任务的复杂性自适应地分配推理。对于简单的任务(左侧),TON可以跳过不必要的推理直接给出答案,减少90%的令牌使用量。对于更复杂的任务(右侧),它依然进行详细、逐步的推理以得出正确的解决方案。
基于TON,我们使用Qwen-2.5-VL系列,并对一系列视觉-语言任务进行了广泛的评估,包括计数(CLEVR [14],SuperCLEVR [15])、移动代理导航(AITZ [13])和数学推理(GeoQA [16]),这些任务涵盖了不同推理水平和多样化任务设置。总体而言,我们发现TON在不牺牲性能的情况下显著减少了完成长度——在CLEVR上减少了87%的令牌,在GeoQA上减少了65%的令牌。值得注意的是,在多步骤导航任务AITZ上,TON将任务级别的平均输出长度从3.6K减少到0.9K令牌。此外,我们观察到省略推理路径甚至可以提高性能:在GeoQA上,TON在准确性方面比传统的GRPO基线高达17%,显示出“免费午餐”效应,即更短的推理优于或匹配更长的推理路径。全面的消融研究进一步揭示了在训练过程中,随着奖励的提高,跳过思考的比例逐渐增加,这表明模型学会了以适应性的方式选择性地绕过不必要的推理步骤。
相关工作
强化学习在视觉-语言模型中的应用。大多数视觉-语言模型(VLMs)通过在大量指令数据上进行监督微调(SFT)以获取广泛的基础知识 [17, 18, 13, 19]。为了进一步提升性能,最近的研究采用了利用人类反馈的后训练范式 [20, 21, 22]。基于人类反馈的强化学习(RLHF)通过偏好标注拟合奖励模型,并通过近端策略优化(PPO)改进策略 [23, 24, 21, 25]。直接偏好优化(DPO)[26] 通过将策略更新重新定义为二分类任务,使模型输出分布与人类偏好对齐,而不依赖奖励模块,简化了这一工作流程。除了这些方法,集团相对策略优化(GRPO)[5] 结合了离线和在线学习:它对思维过程的组进行采样,使用答案验证(如数学验证器)作为奖励反馈,并在每个组内计算相对优势。通过避免使用价值函数,GRPO 提供了一个优雅的解决方案,促进了多样化的推理路径和改进的答案质量。尽管有一系列后续工作 [27, 28, 9],所有这些方法都假设每个问题都需要完整的思考过程,导致解码时间过长。相比之下,我们的工作关注于“何时思考”而非“如何思考”:我们引入了一种选择性推理策略,学习跳过不必要的“思考”阶段,提高推理效率,而不牺牲准确性。
语言模型中的推理。从早期的链条思维 [29, 30, 31] 提示到最近的推理密集型强化学习方法 [5, 22, 32, 33],推理已成为语言模型发展的核心维度。大多数现有工作强调如何增强推理能力,通常导致越来越长和复杂的思维过程 [7, 34, 10],而相对较少的研究关注推理的效率。例如,[35] 提出了一种从长到短的策略来压缩解码长度,[36] 鼓励模型输出“我不知道”来终止无效的推理,[37] 引入了一种考虑令牌预算的推理策略。虽然这些方法为控制推理长度提供了有希望的见解,但我们主张更基础的视角:模型在开始推理过程之前,应首先确定是否需要推理。简单的问题可以直接回答,而无需任何明确的推理,而复杂的问题可能需要维持一个完整的推理轨迹 [8, 6, 9]。在本工作中,我们在 VLMs 中探索选择性推理范式,引入了一种简单而有效的方法——思维丢弃(thought-dropout)。我们在计数、数学等任务中验证了其有效性,并进一步将其扩展到更实际的代理设置中。
任务定义
我们将视觉语言推理环境形式化为一个马尔可夫决策过程(MDP),该过程由一个元组 \((V, Q, S^*, \pi, r)\) 定义,涵盖了广泛的视觉语言任务。这里, \(V\) 表示视觉上下文(例如,一张图像)。 \(Q\) 是关于视觉输入的语言查询或问题。模型通过策略 \(\pi\) 接收输入对 \((V, Q)\) ,并生成一个预测答案 \(S\) 。环境根据模型的响应 \(O\) 提供一个标量奖励函数 \(r(\cdot)\) 。正确的预测(例如, \(O\) 与真实答案 \(S^*\) 匹配)会得到正奖励,而错误的预测则会得到零奖励。在这个环境中的目标是学习一个自适应策略 \(\pi_\theta\) ,该策略由参数 \(\theta\) 定义,最大化预期奖励,使模型能够在多种输入设置下选择性且高效地进行推理。
奖励函数。
奖励函数 \(r(\cdot)\) 可以是基于模型的 [23, 25] 或基于规则的,如最近在 [5, 22] 中所演示的那样,通常分为两种类型:格式奖励 \(r_f\) 和结果奖励 \(r_o\) 。虽然结果奖励通常根据不同的任务或请求在以前的工作中精心设计 [5, 1, 2, 9],格式奖励 \(r_f\) 通常是共享的。给定响应 \(O\) ,它应遵循所需的 HTML 标签格式 <think>T <\think><answer>S<\answer>,其中 \(T\) 是推理过程(即,一个思维)而 \(S\) 是预测答案。这种表示要求模型在得出答案之前进行思考,并且便于解析推理过程和最终结果(例如,通过正则表达式)。
TON:通过策略优化实现的选择性推理
观察。实际上,人类在执行许多任务时并不需要明确的推理——许多任务可以通过直觉完成。同样,模型在不需要明确思考的情况下,也常常能够正确回答简单的问题。如图2所示,在推断过程中有和没有思考过程的不同设置下,正确和错误样本的百分比(详见附录A中的整体性能)。我们发现,52.1% 的答案在没有“思考”时仍然正确,而 14.5% 的答案甚至只有在没有“思考”时才是正确的——这表明明确的思考并非总是必要。

一个直接的想法是提示模型决定是否需要“思考”(我们在第5.4节中提示模型在简单问题上跳过思考)。然而,正如我们在实验中所展示的(图5d和附录G.7),模型仍然倾向于生成完整的推理过程,而不会进行任何不带思考的尝试。这表明,决定是否思考的能力不仅由推理能力决定,而应被视为一种独立的技能——这种技能必须在监督微调(SFT)阶段通过遵循格式进行显式训练。这些观察结果促使我们在SFT阶段早期激活这种能力,并开发TON,以实现通过自动在“思考”和“不思考”模式之间切换来选择性推理。
第一阶段 SFT:思维丢弃(Thought Dropout)
在初始阶段,模型通常会在“思考-回答”格式的数据上进行微调,其中“思考”部分包含高质量的推理轨迹,以作为冷启动。为了将这种预定义的推理能力扩展到选择性推理,我们将“思考”与“非思考”视为输出格式的一部分,通过在训练过程中丢弃“思考”部分来实现。然而,确定哪些样本应该被跳过是困难的,因为不同的模型表现出不同的推理能力。因此,我们从随机丢弃开始,并允许模型在第二阶段的强化学习(见第4.2节)中自我学习决策。为此,我们提出了一种“思维丢弃”方法,该方法通过随机注入空的“思维”段来实现,仅需对代码进行少量修改:
算法1:thought_dropout的伪代码
def thought_dropout(thought, dropout_prob):
if random.random() < dropout_prob:
thought = "\n\n"
return thought
这种方法在第二次强化学习阶段之前,注入了回答格式和跳过思维格式作为先验知识。
思维从何而来?
给定一个在环境 (V, Q, S∗, π, r) 中运行的策略,一个关键的挑战是如何在不依赖外部模型(如闭源API)的情况下,策划高质量的冷启动“思维”数据。一种朴素的方法是运行多次推理并通过答案匹配仅保留成功的案例——但我们发现这种方法效果不佳。为了解决高质量“思维”数据的稀缺问题,我们采用了一种逆向思维策略:利用基础模型\(\pi\)本身自动生成丰富的思维序列语料。具体而言,给定视觉上下文V、文本查询Q和真实答案S∗,我们提示策略\(\pi_\theta\)推导出相应的中间思维过程如下:
特别地,我们使用以下提示生成中间思维:
逆向思维提示
Based on the following question and image, generate a thought process to explain how to derive the answer from the inputs.
Image: {Image}
Question: {Question}
Answer: {Answer}
Do not output the answer, only generate the reasoning process. Formulate your outputs using concise language.
通过这种方式,我们无需依赖外部模型即可策划足够的思维数据。这些数据作为我们的冷启动训练语料库,使我们能够应用思维丢弃策略在SFT过程中激活模型跳过思维的能力。
第二个 RL 阶段:组相对策略优化
虽然 SFT 教授了跳过思想的格式,但仍然留下了一个核心问题未解决:何时应该跳过或保留思想?理想情况下,模型应该学会自己探索这一决策。为此,我们采用基于 GRPO 的强化学习,以增强模型在其推理过程中探索这一决策的能力。给定图像 \(v \in V\) 和文本查询 \(q \in Q\) ,GRPO 从策略 \(\pi_\theta\) 中采样 \(N\) 个具有变体 \(\{o_1, o_2, \ldots, o_N\}\) 的候选响应,并使用奖励函数 \(r(\cdot)\) 评估每个响应 \(o_i\) ,该函数测量候选响应在给定问题的上下文中的质量。为了确定这些响应的相对质量,GRPO 通过计算奖励的均值和标准差来标准化奖励,并随后得出优势:
其中 \(A_i\) 表示候选响应 \(o_i\) 相对于其他采样响应的优势。GRPO 通过以下目标函数更新策略 \(\pi_\theta\) ,鼓励模型生成具有更高优势的组内响应:
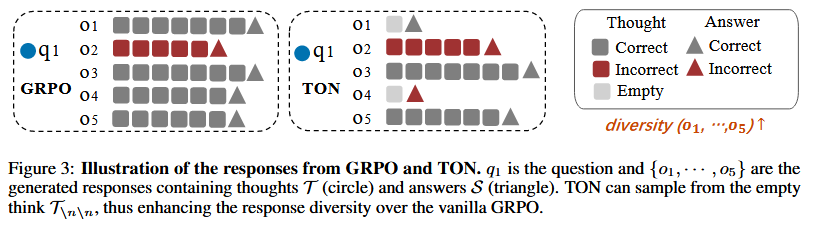
TON 如何影响 GRPO? 如图 3 所示,我们的 TON 允许模型在推理步骤中选择“空白思考” \(\emptyset\) ,从而导致 TON 生成的非思考响应( \(o_i \sim \emptyset\) )和思考响应( \(o_i \sim T\) )之间的分布显著不同,与仅生成思考响应( \(o_i \sim T\) )的普通 GRPO 相比。与强调在稀疏奖励空间中通过动态采样优化优势分布 \(A_i\) 的先前工作(如 DAPO [27])不同,我们的 TON 将重点转向响应的潜在分布空间( \(\pi_\theta(o_i | v, q)\) ),从而增强了公式 4 中项 \(\alpha\) 和 \(\beta\) 的多样性。
如何设计奖励? 为了在不同的设置中支持 GRPO 的训练,仔细检查奖励设计的选择至关重要。我们考虑两种主要类型的匹配:
(i) 离散匹配。对于具有确定性、分类或数值输出的任务(例如,分类、计数或数学问题),我们使用二元值奖励 \(r_d(s, g) = 1(s = g)\) :如果预测答案 \(s\) 匹配真实标签 \(g\) ,我们分配 \(r_d = 1\) ;否则, \(r_d = 0\) 。
(ii) 连续匹配。对于产生连续输出的任务(例如,UI 导航或对象定位中的空间坐标),我们允许一个容差区域。给定预测点 \(p = [x, y]\) 和真实标签框 \(b = [x_1, y_1, x_2, y_2]\) ,我们定义:
如果只有真实标签点 \(p^*\) 可用,我们使用距离阈值 \(\theta\) :
在实践中,我们将适用的组件相加以形成最终奖励: \(r_o = r_d + r_c\) 。这种简单而灵活的方案可以覆盖分类、数值推理和定位任务。请参阅附录 B 以获取将这些奖励与格式奖励适配到个别下游任务的详细信息。
实验
在本节中,我们在各种基准上进行实验以评估我们的方法。主要设计实验是为了研究以下关键问题:
- Q1:与纯GRPO相比,TON如何影响性能和效率?
- Q2:TON的跳过行为与推理能力的强弱(例如,不同模型大小或同一模型在不同迭代次数下)之间是否存在相关性?
- Q3:我们是否真的需要带有思维丢弃的SFT?如果基础模型足够强大,我们能否仅依赖于提示跟随?
基准和设置
为了在以下设置中评估我们方法的有效性和泛化能力:
基准测试。我们使用三个视觉-语言基准测试对TON进行评估,包括通用基准CLEVR [14](3D对象计数)、代理基准AITZ [13](移动导航)和数学基准GeoQA [16](中学生数学题目),如表1所示,涵盖了从简单到复杂的推理水平范围。
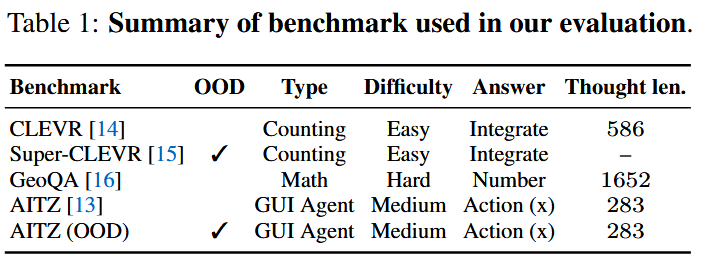
为了基准测试模型的分布外(Out-of-Distribution, OOD)性能,我们还在Super-CLEVR [15]上进行了评估,以补充对CLEVR的测试。AITZ包含四个测试领域:我们在{General}上进行训练,并在剩余的OOD领域{Web shopping, Google apps, Install}上进行测试。我们在GeoQA中去除了选择题,要求模型生成答案,从而增加了推理的复杂性。AITZ包含动作思考注释,我们直接使用这些注释,同时在CLEVR和GeoQA上应用我们的逆向思考方法来生成SFT的想法。更多基准测试细节参见附录E。
训练细节。我们的实验使用Qwen-2.5-VL-Instruct-3B/7B [38]作为基线模型。所有实验都利用了8个NVIDIA H20 GPU。我们对CLEVR和AITZ进行了100步训练,对GeoQA进行了300个轮次训练,考虑到其较高的推理难度。详见附录F中的设置细节。我们利用vLLM [39]加速GRPO训练。我们在GRPO之前添加了SFT阶段,作为代理任务的基准测试,使用与TON相同的设置,因为我们观察到直接应用GRPO会导致训练过程中产生0坐标奖励,考虑到其复杂的输出格式。为了简化,我们将dropout概率设置为50%,并在5.3节中考察了从{20%, 50%, 80%}中选择的不同dropout比率的影响。
评估方面,我们对所有数据集都采用贪婪策略进行测试。在CLEVR和GeoQA任务中,答案为数值,我们通过将预测值与真实值进行比较来衡量准确率。在AITZ任务中,答案以JSON格式结构化,我们报告了步骤级别和任务级别的指标,包括类型准确率(正确的动作类型)和精确准确率(正确的动作类型和点击坐标)[17]。
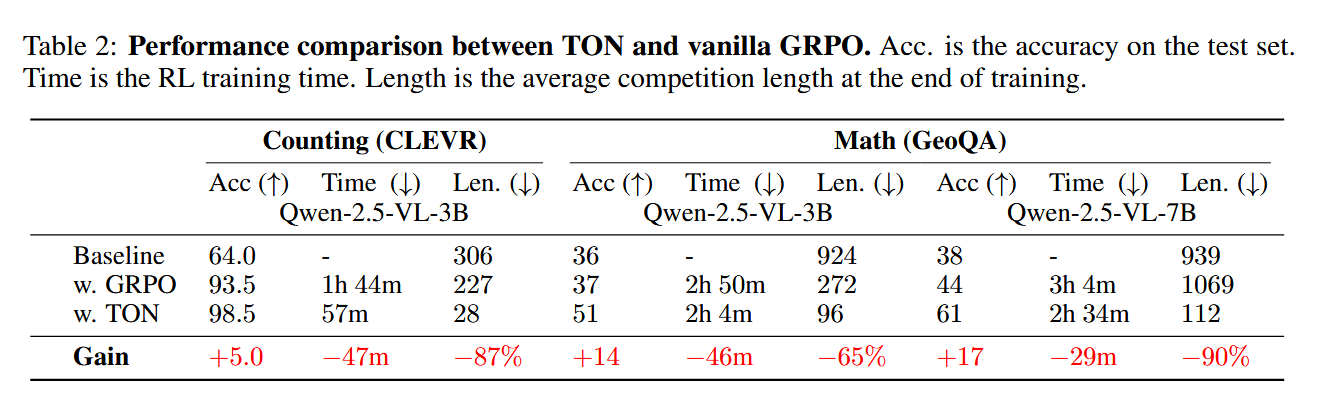
Q1: TON 与 GRPO 的性能和效率比较
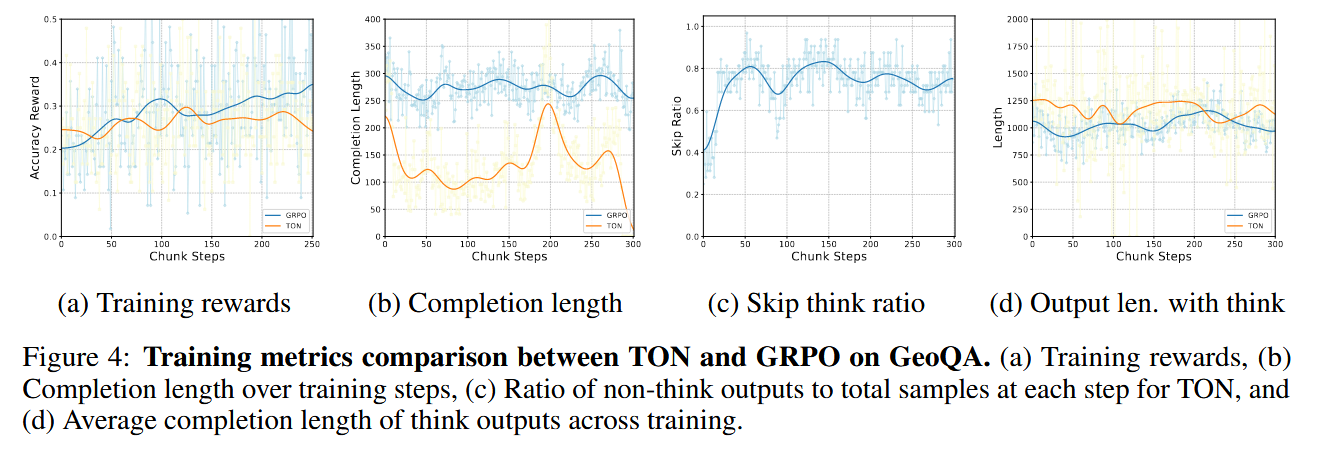
表2展示了TON在CLEVR和GeoQA基准上的性能,在3B和7B设置下,包括性能、时间消耗以及RL阶段的平均完成长度。我们发现,TON在最多提高17个百分点的准确率的同时,能够将平均完成长度减少高达90%,实现了与GRPO相当甚至更优的性能。这表明,跳过不必要的推理可以带来更好的性能。完成长度的减少降低了生成样本时的解码时间,从而缩短了训练时间。图4a和4b显示了奖赏和完成长度曲线,其中TON的奖赏与原始GRPO保持一致,而完成长度显著减少。附录G.2和G.1展示了训练过程中的全部指标。
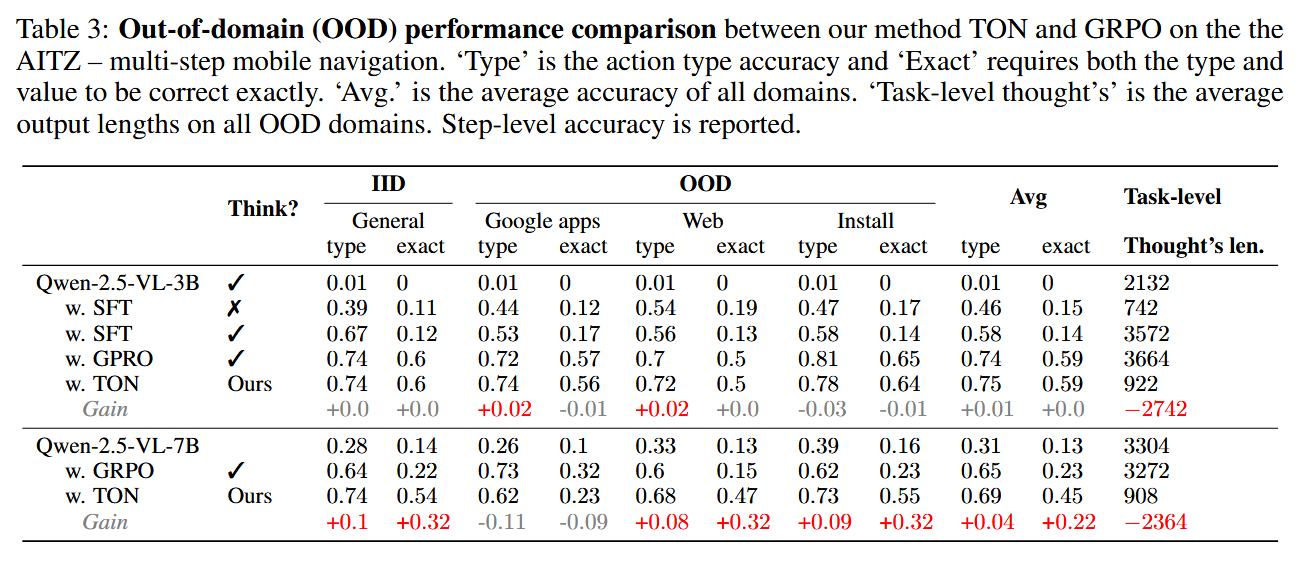
多步导航和领域外测试。表3评估了TON在AITZ多步移动导航任务上的性能,并采用贪婪解码策略评估了其在领域外测试集上的泛化能力。表3总结了TON在AITZ上对IID(常规)和OOD(Google Apps、网络购物和安装)领域的步骤类型匹配准确率和完全匹配准确率,详细的训练可视化请参见附录G.3。总体而言,TON展示了与GRPO相当的OOD泛化性能,同时显著减少了任务级别的输出长度,从3K减少到0.9K(减少了70%的token)。这突显了TON在不牺牲性能的前提下大幅度减少完成长度的潜力。其他基准上的OOD性能请参见附录G.4。
Q2: 跳过思维比率分析
除了TON实现的性能改进和生成长度减少外,我们进一步研究了训练过程中“Thought dropout”中跳过比率的变化趋势。图4c展示了GeoQA数据集上每个步骤生成样本的跳过比率百分比。我们观察到,随着训练奖励的增加,训练过程中跳过比率呈现出增长趋势。附录G.6中的图19显示了这一趋势在三个基准测试中的普遍性。这一现象表明,模型逐渐内化了推理过程——学会了跳过显性的思维过程,同时仍然能够生成准确的答案。此外,图4d展示了使用“think”生成的输出长度。TON保持与基础GRPO可比的长度,表明TON模型可以在不需要深度推理时选择不思考,但在需要时仍然保持严谨。
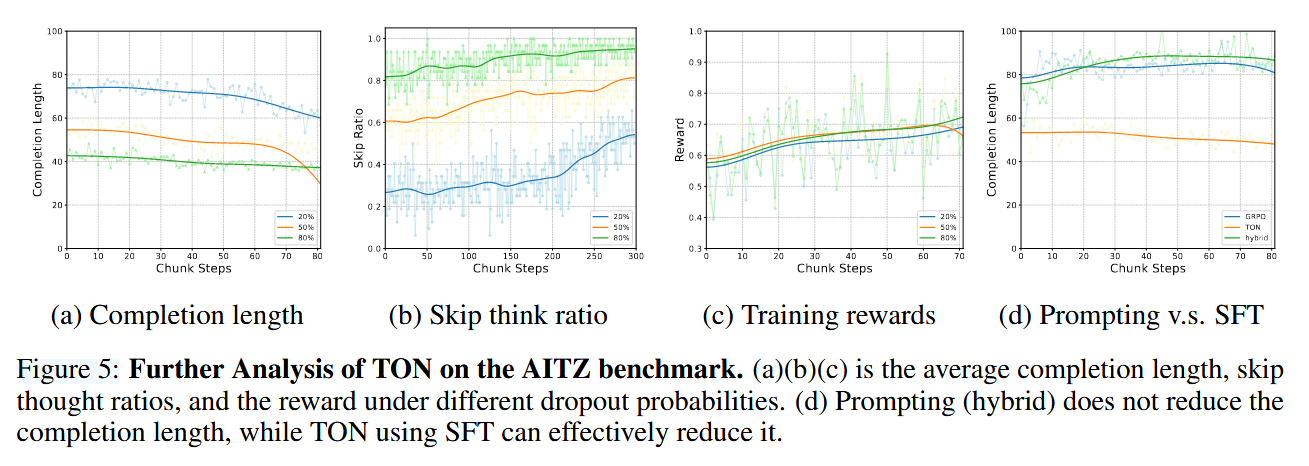
思维删除比率消融实验。我们在SFT阶段实验了20%、50%和80%不同思维删除比率的影响。图5a和5b显示了AITZ上训练过程中生成长度和跳过比率的变化。图5c展示了这三种变体的奖励曲线。更多指标详见附录G.5。尽管删除比率不同,但TON在训练过程中始终表现出跳过比率的增加。值得注意的是,20%的设置显示出跳过率的快速增加,而较高的80%设置在整个训练过程中相对稳定。这促使我们从较低的删除概率开始进一步研究。TON可以根据奖励信号动态优化——在性能高时降低删除比率,在性能下降时增加删除比率。
Q3: TON中SFT重要性的实证验证
除了在SFT阶段引入跳过-思考格式(如TON中所做的),我们还探索了一种更简单的替代方案:修改提示,鼓励模型自动省略推理步骤,从而在不需单独SFT阶段的情况下直接进行GRPO训练。混合思维提示定义如下:
混合思维提示
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant evaluates whether the question is simple enough to answer directly.
If simple, the output is formatted as <think>\n\n<\think><answer>answer here<\answer>.
If the question is difficult, the assistant needs to first think then answering the question.
The output is formatted as <think> reasoning process here <\think><answer> answer here <\answer>.
The assistant is encouraged to use <think>\n\n<\think> while maintaining accuracy.
图5d展示了使用混合提示、基础GRPO(全思考提示)和TON在AITZ上训练过程中的生成长度。附录G.7展示了三个基准测试中的类似趋势,显示混合提示与基础GRPO在生成长度上的差异微小。此外,我们观察到,在GeoQA中,GRPO生成的所有样本中只有2个“跳过”案例,而AITZ中则没有。我们认为这是模型倾向于通过生成长且详细的推理过程来确保安全,这与其在预训练或SFT阶段学到的固有行为模式一致。由于模型没有产生跳过思维的输出,对这些输出施加额外的奖励也没有效果,导致在整个训练过程中没有贡献。这些发现强调了我们SFT阶段中使用思维删除(第4.1节)以建立预期的格式遵循行为的必要性。
定性示例
图6比较了GRPO和TON在AITZ基准上的多步移动导航表现。虽然GRPO在每一步都生成冗长的推理,但TON能够适应性地跳过不必要的思考,减少了60%的令牌使用,同时不牺牲任务准确度。这表明TON在处理现实世界的长期程序化代理任务时具有较高的效率。
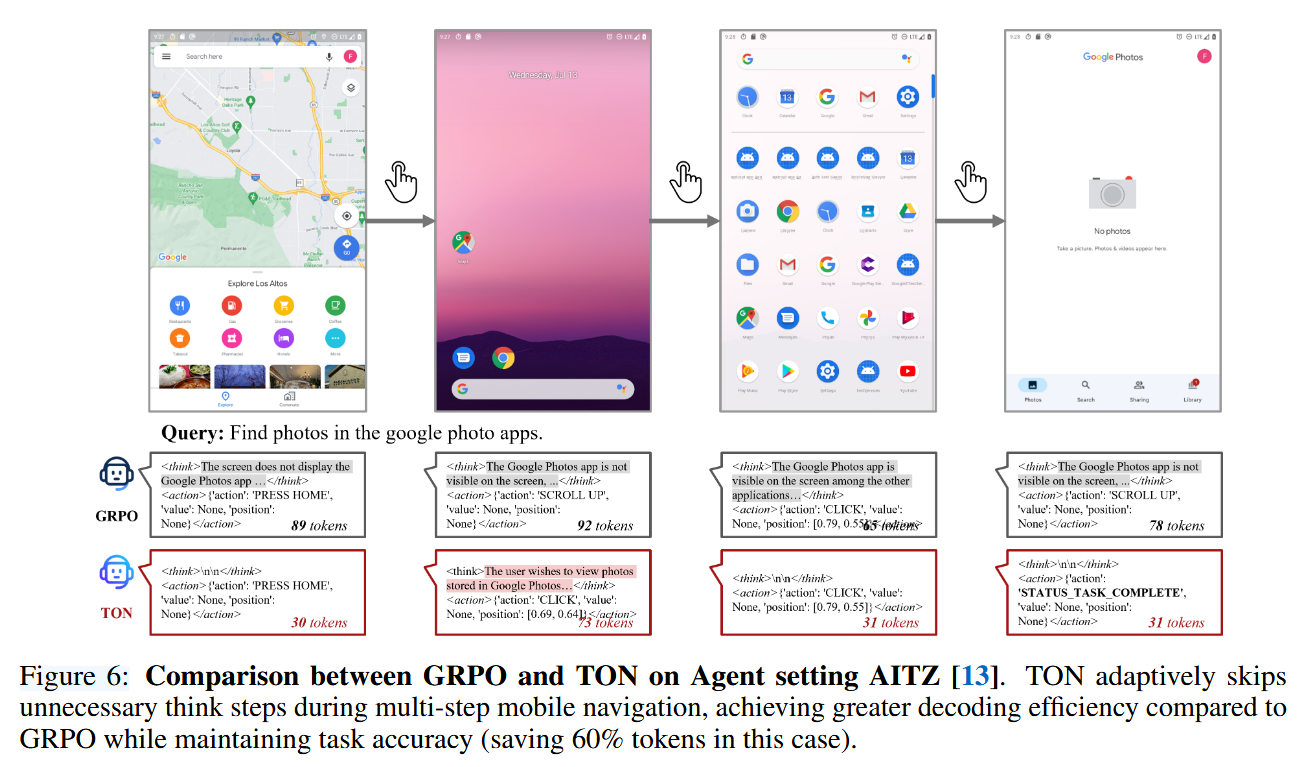
表4进一步展示了TON选择性激活推理的能力。与GRPO每次都生成详细思考轨迹不同,TON省略了那些一眼即可回答的简单问题的推理,而在涉及视觉遮挡的复杂场景中生成准确且集中的推理。

结论
我们提出了TON,这是一种简单而有效的两阶段训练框架,使视觉-语言模型能够学习何时进行推理——引入了选择性推理作为一种可控和可训练的行为。通过在监督微调期间结合思考dropout,并通过GRPO进行奖励引导的精细化,TON显著减少了完成长度(最多减少90%),且在多样化的推理任务中没有牺牲性能,甚至在某些情况下有所提升。我们的研究结果挑战了全程推理轨迹总是有益的假设,并为多模态智能和强化学习中的更高效、更类人的推理策略铺平了道路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号