InternVL3: 探索开源多模态模型的高级训练和测试方法
https://arxiv.org/abs/2504.10479
摘要
我们介绍InternVL3,这是InternVL系列的一个重要进展,采用了原生的多模态预训练范式。与将纯文本大型语言模型(LLM)改编为支持视觉输入的多模态大型语言模型(MLLM)不同,InternVL3在单一预训练阶段中,同时从多样化的多模态数据和纯文本语料库中获取多模态和语言能力。这种统一的训练范式有效解决了传统事后训练管道中常见的复杂性和对齐挑战。为了进一步提升性能和可扩展性,InternVL3引入了可变视觉位置编码(V2PE)以支持扩展的多模态上下文,采用先进的事后训练技术如监督微调(SFT)和混合偏好优化(MPO),并采用测试时扩展策略以及优化的训练基础设施。广泛的实证评估表明,InternVL3在多种多模态任务中表现出色。特别是,InternVL3-78B在MMMU基准上取得了72.2分,成为开源MLLM中的新标杆。其能力在与领先专有模型(包括ChatGPT-4o、Claude 3.5 Sonnet和Gemini 2.5 Pro)的竞争中表现出色,同时保持了强大的纯语言能力。为了追求开放科学原则,我们将公开发布训练数据和模型权重,以促进下一代MLLM的研究和开发。
绪论
多模态大规模语言模型(MLLMs)[32, 66, 121, 21, 19, 123, 68, 114, 97, 136, 71, 31, 85, 117, 18, 89, 105, 69] 最近在广泛的任务中达到了乃至超过了人类水平的表现,强调了它们作为迈向通用人工智能(AGI)的重要一步的潜力。然而,大多数领先的 MLLMs——无论是开源的还是专有的——都是通过复杂的多阶段管道 [21, 19, 18, 5, 121, 7] 从仅文本的大型语言模型中改编而来。这些“后处理”方法建立在原始基于文本的预训练过程之上,因此在集成视觉等其他模态时引入了对齐挑战。实际上,弥合模态差距通常需要纳入来自专业领域的辅助数据(例如,光学字符识别场景)以及复杂的无参数冻结或多阶段微调计划,以确保核心语言能力不受损害 [73, 7, 5, 18]。这些资源密集型策略突显了对更高效多模态训练范式的需要。
在本报告中,我们介绍了 InternVL3,这是 InternVL 系列 [21, 20, 18] 的最新里程碑,其特点是采用了原生多模态预训练策略。与首先预训练一个仅文本的大型语言模型,然后通过多模态对齐进行改造以支持视觉处理不同,InternVL3 从预训练阶段开始学习多模态能力,同时接触纯文本语料库和多样化的多模态数据集。这种统一的方法使模型能够更高效和集成地同时获得语言和多模态能力。
InternVL3 进一步通过多种创新来加强性能和可扩展性。我们采用可变视觉位置编码(V2PE)机制 [42] 以适应更长的多模态上下文。此外,包括有监督微调(SFT)和混合偏好优化(MPO)[124] 在内的高级后训练策略,以及测试时缩放策略 [125] 和优化的训练基础设施 [15],显著提高了 InternVL3 的效率和性能。
全面的实证评估表明,InternVL3 在多学科推理、文档理解、多图像/视频理解、现实世界理解、多模态幻觉检测、视觉定位和多语言能力等广泛任务中超越了其前辈(例如,InternVL2.5 [18])。值得注意的是,通过纳入扩展的领域特定数据集,InternVL3 在工具使用、GUI 代理、工业图像分析和空间推理方面也表现出显著改进,从而大幅扩展了 InternVL 系列所解决的多模态场景。它在与其他开源 MLLMs 如 Qwen2.5-VL [7] 以及封闭源模型(如 ChatGPT-4o [98]、Claude-3.5 Sonnet [3]、Gemini-2.5 Pro [117])的竞争中表现出极高的竞争力。这种多功能性在 MMMU 基准测试 [141] 中得分为 72.2 分,为开源 MLLMs 设立了一个新的标准。此外,InternVL3 展示了与其他相似规模的先进 LLMs 相当的语言能力。
InternVL3
基于此前的InternVL系列模型[21, 19, 18],我们提出InternVL3,这是InternVL模型家族的新一代产品。InternVL3专门设计用于简化训练管道,同时显著增强多模态能力。在本节中,我们首先阐述InternVL3的核心组件,包括其模型架构、训练流程、测试时的扩展策略以及基础设施层面的优化。
模型架构
InternVL3的架构遵循其前代产品的通用框架,采用“ViTMLP-LLM”范式[66, 18, 41, 20]。详细的架构规范汇总于表1。尽管后续讨论的原生预训练范式可以实现从头开始训练MLLMs,我们选择使用预训练模型权重初始化ViT和LLM组件,以减少计算成本。视觉编码器提供两种配置:InternViT-300M和InternViT-6B。对于语言模型,我们利用预训练的大型语言模型(LLMs),特别是Qwen2.5系列和InternLM3-8B。重要的是,我们的LLM组件仅从预训练的基础模型初始化,未采用指令调优的变体。模型中使用的多层感知器(MLP)是一个两层网络,采用随机初始化。与InternVL2.5的做法一致,InternVL3引入了像素展平操作,以提高处理高分辨率图像的可扩展性。这一操作将视觉标记的数量减少到原来的四分之一,使每个448×448的图像块用256个视觉标记表示。

可变视觉位置编码(Variable Visual Position Encoding)
InternVL3 引入了 可变视觉位置编码(Variable Visual Position Encoding, V2PE)机制 [42],该机制为视觉标记(visual tokens)采用更小且灵活的位置增量。这一设计使得在不显著扩展位置窗口的前提下,能够处理更长的多模态上下文。
具体来说,每个用于多模态大模型(MLLM)的训练样本可表示为:
其中每个标记 \(x_i\) 可以是文本嵌入、视觉嵌入,或其他模态的特定表示(例如视频补丁嵌入)。其对应的位置索引 \(p_i\) 按如下方式顺序计算:
与传统 MLLM 模型为每个标记统一地递增 1 的方式不同,V2PE 根据模态采用递归的方式计算位置索引,使得不同模态的标记拥有不同的位置信息分配规则:
其中 \(\delta < 1\),用于减缓视觉标记位置索引的增长速度。文本标记仍保留位置增量为 1,以保持其位置上的区分度。
为了保持视觉标记之间的相对位置关系一致,V2PE 设计在 同一图像中保持 \(\delta\) 恒定。训练过程中,\(\delta\) 从一个预定义的分数集合中随机选取:
在推理阶段,\(\delta\) 可根据输入序列长度灵活选择,从而平衡模型性能和位置索引是否落在模型的上下文窗口范围内。需要注意的是,当 \(\delta = 1\) 时,V2PE 会退化为 InternVL2.5 中所使用的传统位置编码机制。
原生多模态预训练
我们提出了一种原生多模态预训练方法,将语言预训练和多模态对齐训练整合到一个单一的预训练阶段。与传统范式不同,传统范式首先训练一个仅语言的大模型(通常先进行语言预训练,然后进行语言后训练),随后再调整以适应其他模态,我们的方法通过在预训练过程中交替使用多模态数据(如图像-文本、视频-文本或交错的图像-文本序列)与大规模文本语料库,实现了综合优化。这种统一的训练方案使预训练模型能够同时学习语言和多模态能力,最终增强其处理视觉-语言任务的能力,而无需引入额外的桥接模块或后续的模型间对齐程序。
多模态自回归公式。设 \(M\) 表示一个基于Transformer的模型,参数为 \(\theta\) ,能够同时处理文本、图像和视频。具体来说,对于任意训练样本 \(x = x_1, x_2, \ldots, x_L\) (其标记长度为 \(L\) ),我们采用标准的左到右自回归目标:
其中 \(w_i\) 表示第 \(i\) 个令牌的损失权重。虽然该公式自然地通过所有模态的令牌传播梯度,但我们将损失计算仅限于文本令牌,结果为:
在这种选择性目标下,视觉令牌充当文本预测的条件上下文,而不是直接被预测。因此,模型学会了以有利于下游语言解码任务的方式嵌入多模态信息。值得注意的是,关于令牌权重 \(w_i\) 的设计选择,如 InternVL2.5 [18] 所讨论的,广泛使用的令牌平均和样本平均策略可能导致梯度偏向较长和较短的响应。为了解决这一问题,我们采用了平方平均,定义为:
其中 \(l\) 表示需要计算损失的训练样本中的令牌数量。
| 平均策略 | 权重表达式 \(w_i\) | 损失归一化方式 | 偏向倾向 | 说明 |
|---|---|---|---|---|
| 令牌平均 | \(\frac{1}{l^0} = 1\) | 总损失 / 所有令牌数 | 偏向长响应 | 每个令牌权重相同,长样本贡献更多梯度 |
| 平方平均 | \(\frac{1}{l^{0.5}}\) | 每样本损失 / 样本长度的平方根 | 中性折中 | 折中策略,平衡长短样本的影响 |
| 样本平均 | \(\frac{1}{l^1} = \frac{1}{l}\) | 每样本损失 / 样本长度 | 偏向短响应 | 每个样本权重相同,短样本每个令牌的影响更大 |
联合参数优化。与传统的“仅语言训练后接着多模态适应”范式不同,我们的方法在多模态预训练期间联合更新所有模型参数。具体来说:
其中 \(D_{\text{多模态}}\) 是大规模纯文本和多模态语料库(例如,图像-文本或视频-文本对)的联合。因此,我们优化了一个单一模型来处理这些组合数据源。这种多任务联合优化确保了文本表示和视觉特征的协同学习,强化了模态间的对齐。
此外,这种集成优化不同于传统的“仅语言训练后接着多模态适应”管道,后者在适应多模态预训练语言模型(MLLM)时,通常会冻结或部分微调大型语言模型(LLM)组件中的某些层,甚至在视觉变换器(ViT)编码器中也是如此。相反,我们的方法联合训练每一层,允许所有参数在大规模多模态语料库上联合优化,确保语言和视觉特征同步演化。因此,最终参数为纯语言和多模态任务的高性能做好了准备,而无需额外的调优步骤。
数据。InternVL3 中使用的预训练数据大致分为两类:多模态数据和纯语言数据。多模态数据集包括现有数据集的综合和新获取的现实世界数据。具体来说,我们利用了 InternVL2.5 的预训练语料库,涵盖了图像描述、一般问答、数学、图表、光学字符识别(OCR)、知识基础、文档理解、多轮对话和医学数据等多个领域。尽管总体数据规模没有增加,但通过更新多层感知机(MLP)模块的权重以及与视觉变换器(ViT)和大语言模型(LLM)组件相关的权重,该数据集的效用显著提升。此外,为了增强模型在实际应用中的泛化能力,还加入了与图形用户界面(GUI)、工具使用、3D 场景理解和视频理解相关任务的数据。
为了弥补多模态数据集中通常文本内容较短且多样性不足的问题,我们将纯语言数据纳入预训练过程。这有助于保持和增强模型的语言理解和生成能力。语言语料库主要基于 InternLM2.5 的预训练数据,并进一步用各种开源文本数据集 [8, 77, 79] 进行扩充。这一增强旨在提高模型在知识密集型任务以及数学和推理任务中的性能。
鉴于平衡这些异构数据源的复杂性,确定适当的采样策略并非易事。在 InternVL3 中,我们采用两阶段策略来确定多模态数据和语言数据之间的最佳采样比例。首先,我们在多模态和语言数据集上分别训练模型,并在相应的基准上评估其性能,以确定每种模态内的最佳采样比例。然后,在固定总训练预算下,我们将两种模态结合起来,确定它们的相对采样比例。实证研究表明,语言数据与多模态数据的比例为 1:3 时,总体性能在单模态和多模态基准测试中表现最佳。在此配置下,总训练令牌数约为 2000 亿,其中 500 亿来自语言数据,1500 亿来自多模态数据。
后训练
在本机多模态预训练之后,我们应用了一个两阶段的后训练策略,以进一步增强模型的多模态对话和推理能力。该策略包括监督精调(SFT)和混合偏好优化(MPO)。在SFT阶段,模型在积极监督信号下被训练以模仿高质量的响应。在随后的MPO阶段,我们引入了来自正样本和负样本的额外监督,从而进一步提升模型的整体能力。
监督精调。在这一阶段,InternVL2.5 [18] 中提出的随机JPEG压缩、平方损失重新加权和多模态数据打包技术也被应用于InternVL3系列。与InternVL2.5相比,InternVL3的SFT阶段的主要进展在于使用了更高质量和更多样化的训练数据。具体而言,我们进一步扩展了工具使用、3D场景理解、GUI操作、长上下文任务、视频理解、科学图表、创造性写作和多模态推理的训练样本。
混合偏好优化。在预训练和SFT过程中,模型根据先前的真实标记进行下一个标记的预测。然而,在推理过程中,模型根据自己的先前输出预测每个标记。真实标记与模型预测标记之间的这种差异引入了分布偏移,这可能会损害模型的思维链(CoT)推理能力。为了解决这一问题,我们采用混合偏好优化(MPO)[124],引入来自正样本和负样本的额外监督,以使模型的响应分布与真实分布对齐,从而提高推理性能。具体而言,MPO 的训练目标是偏好损失 \(L_p\) 、质量损失 \(L_q\) 和生成损失 \(L_g\) 的组合,可以表示为:
\(L = w_pL_p + w_qL_q + w_gL_g\)
其中 \(w^*\) 表示分配给每个损失成分的权重。特别地,DPO 损失 [101] 作为偏好损失,使模型能够学习选定响应和拒绝响应之间的相对偏好:
\(L_p = -\log \sigma \left( \beta \log \frac{\pi_\theta (y_c | x)}{\pi_0 (y_c | x)} - \beta \log \frac{\pi_\theta (y_r | x)}{\pi_0 (y_r | x)} \right)\) ,
其中 \(\beta\) 是KL惩罚系数,而 \(x\) 、 \(y_c\) 和 \(y_r\) 分别表示用户查询、选定响应和拒绝响应。策略模型 \(\pi_\theta\) 从模型 \(\pi_0\) 初始化。之后,使用 BCO 损失 [53] 作为质量损失,这有助于模型理解单个响应的绝对质量: \(L_q = L_q^+ + L_q^-\) ,(11)其中 \(L_q^+\) 和 \(L_q^-\) 分别表示选定响应和拒绝响应的损失。它们分别计算,要求模型区分单个响应的绝对质量。损失项定义如下:
\(L_q^+ = -\log \sigma \left( \beta \log \frac{\pi_\theta (y_c | x)}{\pi_0 (y_c | x)} - \delta \right)\) ,(12) \(L_q^- = -\log \sigma \left( -\beta \log \frac{\pi_\theta (y_r | x)}{\pi_0 (y_r | x)} - \delta \right)\) ,
其中 \(\delta\) 表示奖励偏移,计算为先前奖励的移动平均值,以稳定训练过程。最后,使用语言模型(LM)损失作为生成损失,帮助模型学习首选响应的生成过程。损失函数在公式 6 中定义。
测试时扩展
测试时扩展已被证明是一种能够有效增强大语言模型(LLMs)和多模态大语言模型(MLLMs)推理能力的方法 [108, 94, 87, 70, 120, 36, 152, 125]。在本研究中,我们采用 Best-of-N 评估策略,并使用 VisualPRM-8B [125] 作为评分模型,在推理和数学评估任务中挑选出最佳响应。
视觉过程奖励模型VisualPRM 首先为给定解答的每一步打分,然后将这些分数平均,得到该解答的总体得分。该过程被建模为一个多轮对话任务,以便充分发挥 MLLMs 的生成能力。在第一轮中,模型接收图像 I、问题 q 以及逐步解答中的第一步 s0,即 \(s = {s_0, s_1, \cdots, s_n} \in S\)。在随后的每一轮中,模型会接收到一个新的步骤。在训练阶段,模型需要预测每一轮中所给步骤的正确性,具体如下:
其中 c_i \in {+, -}$ 表示第 i 步的正确性。在推理阶段,每一步的得分被定义为生成符号 “+” 的概率。
数据。VisualPRM400K [125] 用于训练 VisualPRM,该数据集是基于从 MMPR v1.2 [124] 收集的多模态问题构建的。遵循 VisualPRM400K 的数据管道,我们进一步通过从 InternVL3 的 8B 和 38B 变体中采样轨迹来扩展 VisualPRM400K。
基础设施
为了促进模型训练,我们扩展了最初设计用于优化大规模LLM训练的零冗余优化器(ZeRO)的InternEVO框架[15],以支持我们的InternVL模型的训练。这一扩展使模型能够有效地扩展到数千个GPU上的数百亿参数。增强的框架引入了ViT、MLP和LLM组件的灵活且解耦的切分策略,通过重叠通信和计算显著提高了训练效率。它进一步支持了包括数据、张量、序列和管道并行性在内的全面并行策略,以及这些策略的任意组合。
多模态大语言模型(MLLM)训练中的一个关键挑战是由视觉和文本标记比例的差异导致的计算负载不平衡。这种不平衡可能会因过度负担ViT或LLM模块而导致效率低下。为了解决这一问题,我们引入了一套技术,能够动态平衡模块间的计算工作负载,确保资源的高效和均衡利用。
对于不同规模的InternVL模型,扩展的InternEVO框架制定了一个优化目标,以确定最小化不同模块维度下内存消耗和通信开销的最优配置。为了支持长达32K标记的序列,我们的方法结合了头并行和序列并行技术,有效地克服了可扩展性瓶颈,同时保持计算效率。与InternVL2.5的训练相比,在相同计算预算下,InternEVO在InternVL3中的应用使得相同规模模型的训练速度提高了50%到200%。
实验
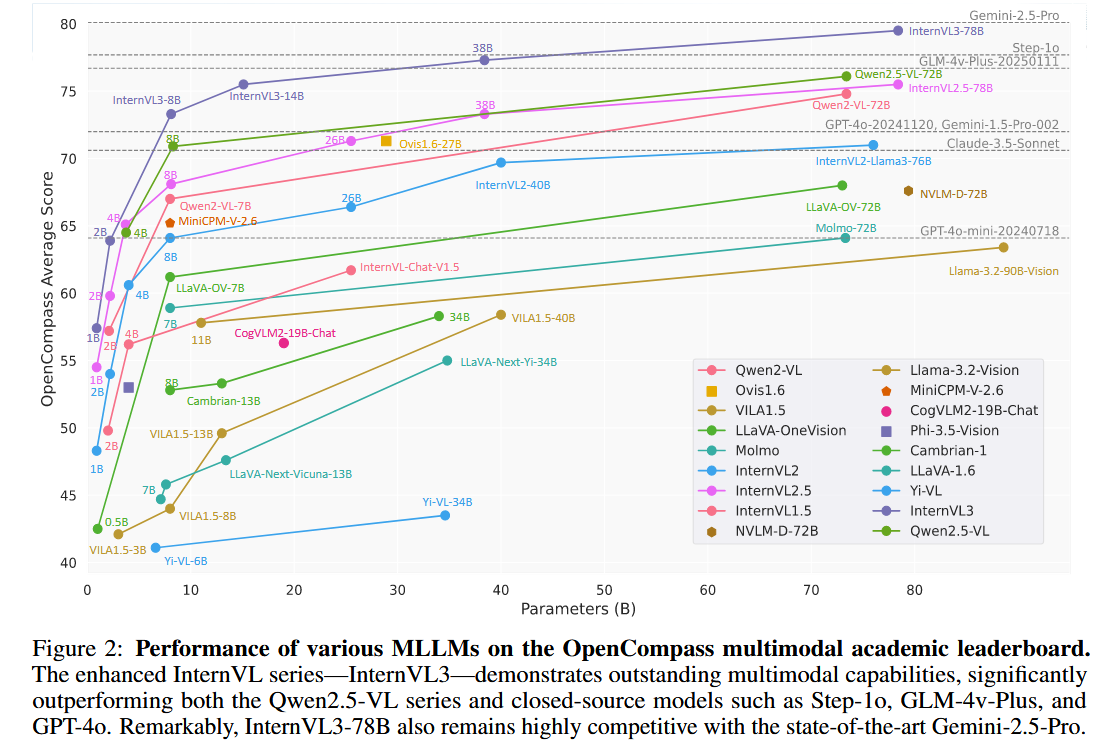
在本节中,我们首先使用广泛采用的多模态基准测试,比较 InternVL3 与当前先进的多模态语言模型(MLLMs)的整体多模态能力。随后,我们在多个领域评估 InternVL3 的性能,包括多模态推理、数学、光学字符识别(OCR)、图表和文档理解、多图像理解、现实世界的理解、全面的多模态评估、多模态幻觉评估、视觉定位、多模态多语言理解、视频理解及其他多模态任务,其中大多数测试使用了 VLMEvalKit [33]。此外,我们详细评估了 InternVL3 的语言能力。最后,我们分析了 InternVL3 相对于其前代产品 InternVL2.5 的几个关键改进,包括朴素的多模态预训练、V2PE 位置编码以及后训练技术带来的改进。
与其他先进多模态大语言模型的整体比较
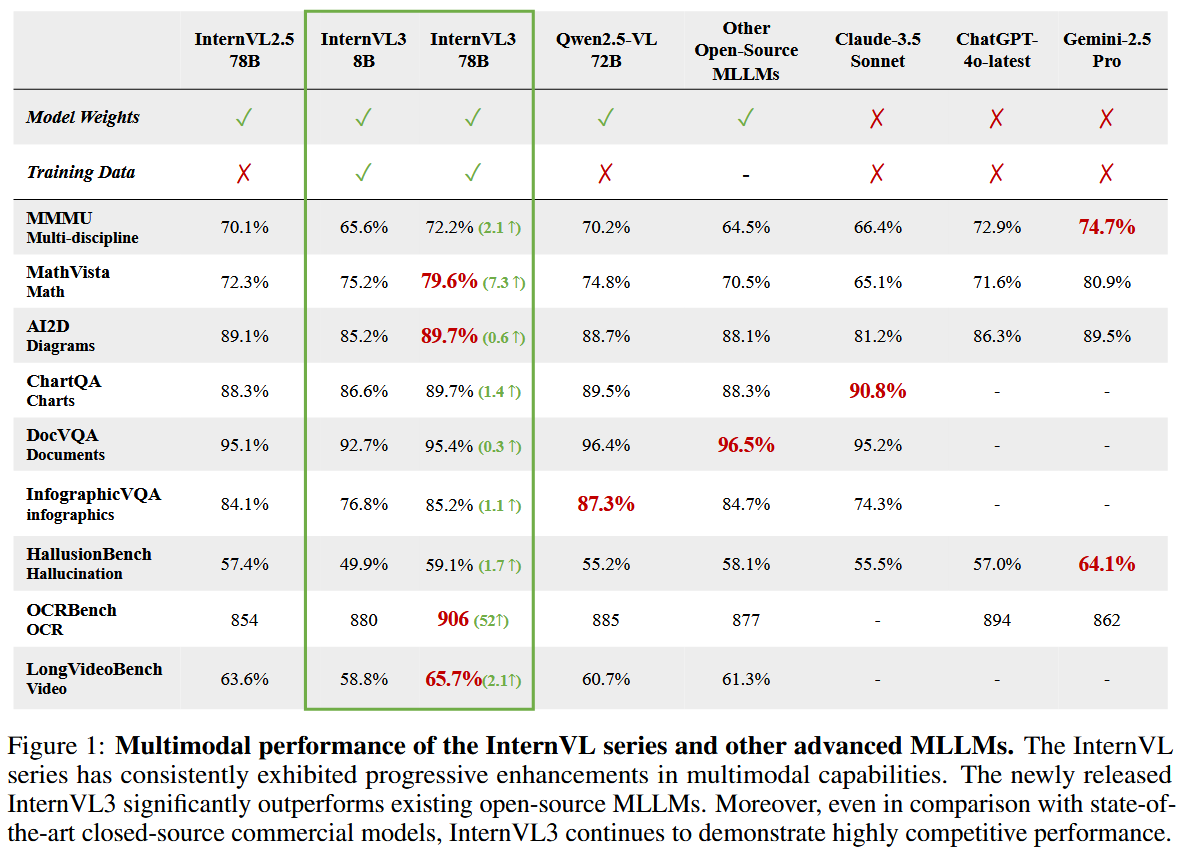
图1详细评估了InternVL3在一系列基准测试中的表现,包括MMMU [141]、MathVista [80]、AI2D [57]、ChartQA [91]、DocVQA [93]、InfographicVQA [92]、HallusionBench [45]、OCRBench [76]和LongVideoBench [129]。与以往的模型相比,InternVL3在广泛的任务类别中表现出显著的改进。这些进步主要归功于改进的训练策略、精细的测试方法以及扩展的训练语料库。
具体而言,InternVL3在MMMU基准测试中取得了72.2的显著成绩,证明了其在处理复杂多模态挑战方面的卓越能力。除了在MMMU上的表现,InternVL3在各种任务中持续超越了早期的InternVL系列版本,强调了其在需要复杂多模态理解和推理的实际应用场景中的广泛适用性。除了超越其开源对手,InternVL3在与领先的闭源商业模型(如ChatGPT-4o-latest [98]和Claude-3.5 Sonnet [3])的比较中也表现出竞争力。
在许多情况下,InternVL3与这些专有模型之间的性能差距显著缩小——在某些基准测试中,如AI2D和ChartQA,InternVL3甚至超过了它们。尽管如此,我们的结果还显示,Gemini2.5 Pro [117]在某些任务(例如在HallusionBench上)仍然保持性能优势,这表明尽管InternVL3取得了显著进展,但我们的InternVL系列仍有进一步改进的空间。
多模态推理与数学
为了全面评估InternVL3的多模态推理和数学能力,我们在一系列基准测试上进行了实验,包括用于多学科推理的MMMU [141]、用于数学推理的MathVista [80]、MathVision [119]和MathVerse [146],以及用于逻辑推理补充评估的DynaMath [155]、WeMath [99]和LogicVista [131]。
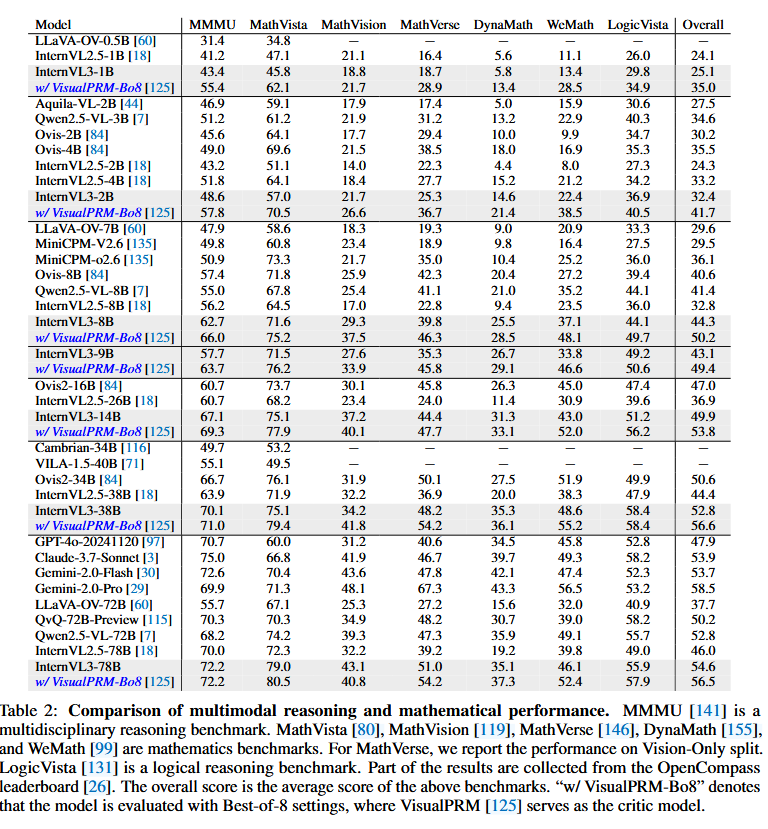
如表2所示,InternVL3在所有测试基准上均表现强劲。具体而言,在MMMU基准上,基于InternVL3的模型一直优于规模较小的竞争对手。例如,随着模型规模的增加,InternVL3-78B在MMMU上的得分超过72,表明其在处理抽象的多学科概念时具备强大的理解和推理能力。在数学领域,InternVL3在各种基准测试中都显示出显著的提升。在MathVista上,InternVL3-78B的性能接近79.0,而在MathVision和MathVerse上的结果也具有竞争力,证明了该模型在处理复杂的数学问题时的能力增强。此外,DynaMath、WeMath和LogicVista上的性能随着模型规模的扩大而持续提升。总体得分——所有基准测试的平均值——表明InternVL3模型在不同方面实现了均衡的提升,超越了许多先前的开源方法。
InternVL3的一个显著特点是最佳N选择评估策略 [125] 的效率。采用这一方法时,即使参数规模相对较小的模型(例如InternVL3-1B和InternVL3-2B)也在推理性能上表现出显著提升。具体而言,在MathVerse的视觉部分,最佳8选择策略分别使InternVL3-38B和InternVL3-78B的性能提升了约6.0和3.2个百分点。这一提升突显了测试时扩展的有效性。
OCR、图表和文档理解
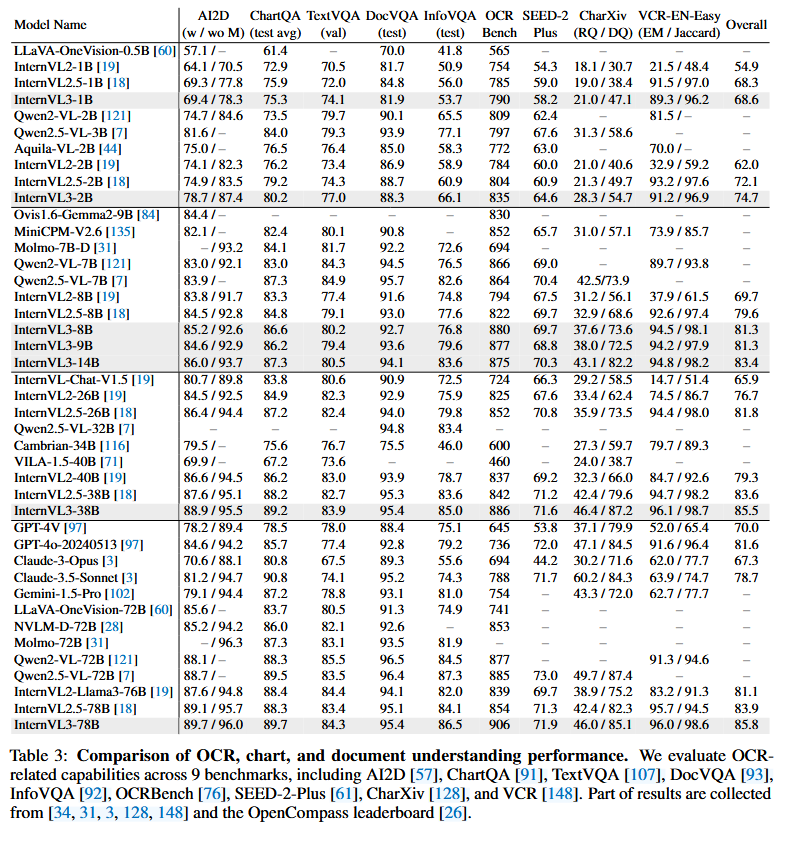
为了评估模型在涉及文本、文档和图表理解的任务中整合的视觉-语言理解能力,我们在九个基准测试上进行了全面评估,包括 AI2D [57]、ChartQA [91]、TextVQA [107]、DocVQA [93]、InfoVQA [92]、OCRBench [76]、SEED-2-Plus [61]、CharXiv [128] 和 VCR [148]。如表 3 所示,InternVL3 系列不仅在这些基准测试中保持了稳健的性能,而且在与其他开源和闭源模型的比较中也表现出竞争力或优越性。在 10 亿参数规模下,InternVL3-1B 的表现与之前的低规模模型大致相当。在 20 亿参数规模下,InternVL3-2B 的绝对分数不仅有所提高——例如,在 AI2D 上达到 78.7/87.4,在 DocVQA 上达到 88.3——而且在参数规模相似的模型中,如 Qwen2-VL-2B [121] 表现更为出色。虽然其 TextVQA 性能(77.0)与 Qwen2-VL-2B 相当,但在文档和图表理解方面的改进表明,所提出的原生多模态预训练在需要精确视觉-文本整合的任务中特别有效。新的预训练协议在更大规模下的益处更加显著。中等规模的模型如 InternVL3-8B 和 InternVL3-9B 在性能上取得了显著提升,其中 InternVL3-8B 在 AI2D 上达到 85.2/92.6,在 DocVQA 上达到 92.7,VCR 分数为 94.5/98.1。此外,与 Qwen2-VL-72B [121] 或者像 GPT-4o-20240513 [97] 这样的闭源模型相比,InternVL3 的高规模变体——特别是 InternVL3-38B 和 InternVL3-78B——进一步推动了这一领域的边界。例如,InternVL3-78B 在 OCRBench 上取得了 906 的惊人分数,VCR 分数为 96.0/98.6,明显超过了类似模型的相应指标。
多图像理解
我们在一系列广泛认可的基准测试中评估了InternVL3的多图像关系感知和理解能力,包括BLINK [39]、Mantis-Eval [51]、MMIU [95]、MuirBench [118]、MMT-Bench [137]和MIRB [153],如表4所示。这些基准测试全面评估了跨图像推理和上下文整合等技能,这些技能对于有效的多模态互动至关重要。InternVL3在不同参数规模上始终优于其早期版本。例如,在1B规模上,InternVL3-1B相较于先前模型表现出显著而一致的改进,BLINK得分为42.9,MMT-Bench得分为52.9。在2B规模上,性能提升更为显著;InternVL3-2B在Mantis-Eval上的得分达到65.9,相对于InternVL2.5-2B提升了超过11个点,并且在MMT-Bench上的表现也提升至59.5。这些改进表明,InternVL3的高级预训练策略和增强的训练数据集显著提升了其捕捉和推理图像间关系的能力。
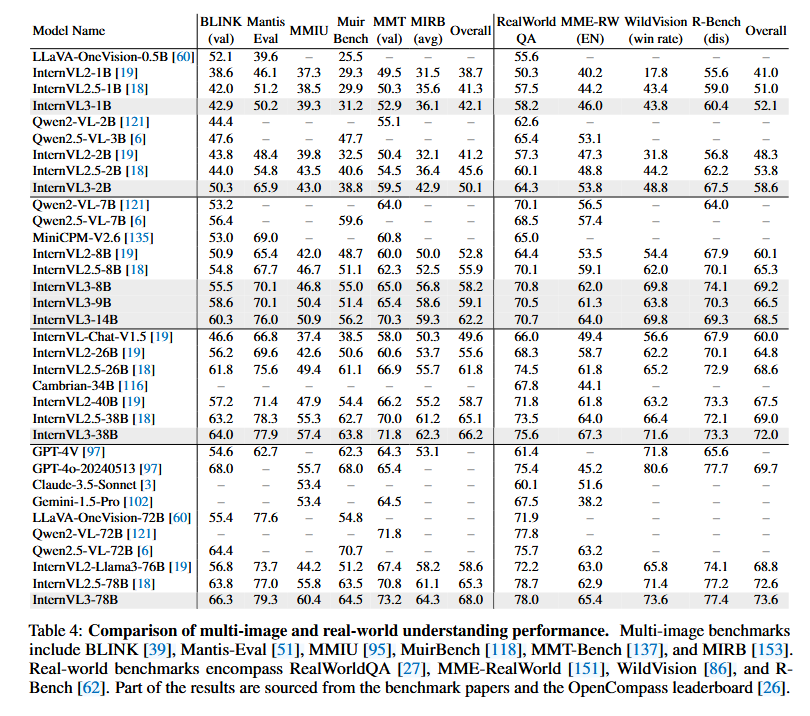
在更高的规模上,这一趋势持续存在。InternVL3-8B及其后续更大的变体不仅在BLINK和MMT-Bench上取得了稳定改进,还在MIRB和MuirBench基准测试中表现出显著进步。特别是,InternVL3-78B在BLINK上的得分为66.3,在MMT-Bench上的得分为73.2,使其成为GPT-4o等领先闭源模型的有力竞争者。这些结果表明,通过原生多模态预训练学习多模态能力以及模型参数的扩展是不同评估环境下性能提升的关键因素。尽管取得了这些令人鼓舞的成果,但在某些基准测试(如MuirBench)上,我们的InternVL3与Qwen2.5VL等其他多语言多模态模型(MLLMs)之间仍存在明显的性能差距,这表明未来的工作可能受益于训练数据策划的进一步改进和模型的额外优化。
现实理解能力
我们对InternVL3系列模型在四个现实理解基准测试——RealWorldQA [27]、MMERealWorld [151]、WildVision [86] 和 R-Bench [62]——上进行了评估,以检测其解决现实和复杂任务的能力。如表4所示,即使是最小的InternVL3家族变体(InternVL3-1B)也表现出了良好的性能,其在RealWorldQA上的得分为58.2,在MME-RealWorld上的得分为46.0,在WildVision上的胜率为43.8,在R-Bench上的得分为60.4。模型规模的扩大进一步提升了所有指标的性能。中等规模的变体,如InternVL3-8B和InternVL3-14B,延续了这一积极趋势,InternVL3-8B在RealWorldQA上的得分为70.8,在R-Bench上的得分为74.1。这些改进突显了扩展的有效性,因为较大的模型提供了更强大的表示和增强的现实场景理解能力。
在较高规模的模型中,InternVL3-38B和InternVL3-78B在InternVL3系列中取得了顶级结果。特别是,InternVL3-78B在RealWorldQA上的得分为78.0,在MME-RealWorld上的得分为65.4,在WildVision上的胜率为73.6,在R-Bench上的得分为77.4。与竞争模型(如GPT-4o [97],其在RealWorldQA上的得分为75.4,在WildVision上的得分为80.6)相比,InternVL3系列展示了其竞争优势。InternVL3-78B不仅在RealWorldQA上超过了GPT-4o,而且在R-Bench上的表现与其相当,还在MME-RealWorld上大幅领先,表明该模型在需要感知精确性和全面理解的任务上具有全面的性能优势。
综合多模态评估
综合多模态评估基于既定基准,包括 MME [37]、MMBench(评估英文和中文任务)[75]、MMBench v1.1(英文)[75]、MMVet [138]、MMVet v2 [139] 和 MMStar [13],具体见表5。具体而言,InternVL3-1B 在 MMBench 上的得分为 72.6/67.9(英文/中文),并将 MMBench v1.1 的得分提高到 69.9,相比 InternVL2.5-1B 基线(70.7/66.3 和 68.4,分别为)。在 2B 规模下,改进更加显著, InternVL3-2B 记录的 MME 为 2221.2,MMBench 表现为 81.1/78.4,以及 MMBench v1.1 得分为 78.6。
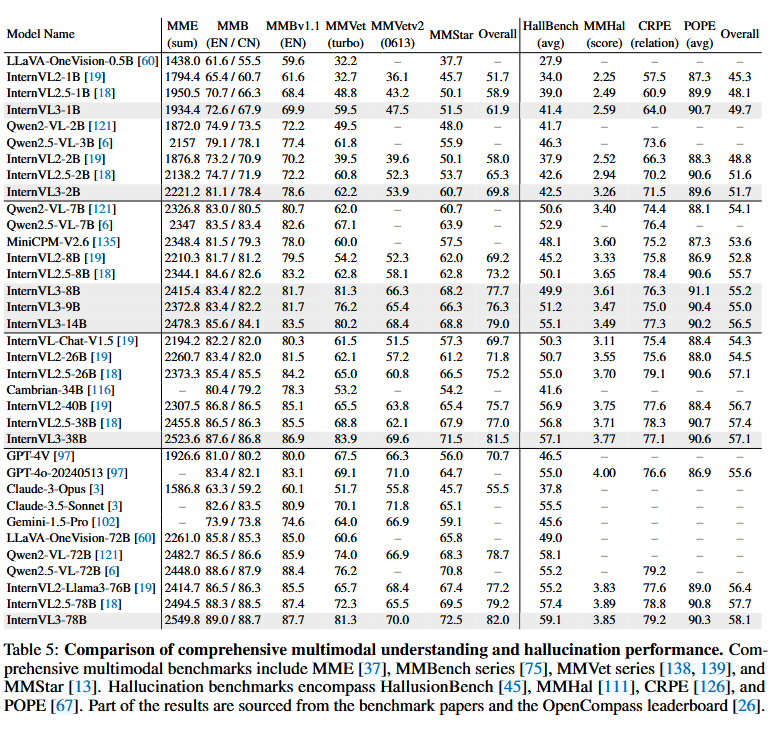
在更大规模下,InternVL3 模型持续表现出优异性能。例如,InternVL38B 模型的 MME 为 2415.4,而 InternVL3-38B 和 InternVL3-78B 模型的 MME 分别为 2523.6 和 2549.8。相应的 MMBench 和 MMBench v1.1 得分也显示出稳定的提升,InternVL3-78B 在英文和中文任务上的得分为 89.0/88.7,仅英文任务的得分为 87.7。与 Qwen2-VL-72B 和 Qwen2.5-VL-72B 等其他竞争模型相比,InternVL3 系列,尤其是 78B 变体,在多模态理解基准测试中表现出一致的性能优势。
多模态幻觉评估
我们在四个已建立的基准测试——HallusionBench [45]、MMHal-Bench [111]、CRPE [126] 和 POPE [67]——上评估了 InternVL 的幻觉倾向,具体见表 5。与之前的 InternVL 系列相比,新的 InternVL3 模型在不同规模上表现出整体竞争力,同时在处理多模态幻觉挑战方面提供了持续的改进。在小参数规模下,InternVL3-1B 在 HallusionBench 上的得分为 41.4,比 InternVL2.5-1B 基线(得分为 39.0)有明显的提升。同样,InternVL3 的 2B 变体在 HallusionBench 上的表现(42.5)与其 InternVL2.5 对应模型(42.6)相当,但在 CRPE 表现上略有提升(71.5 对 70.2)。
在大规模设置中,InternVL3-38B 和 InternVL3-78B 尤为引人注目。InternVL3-38B 在 HallusionBench 上的得分为 57.1,而 InternVL3-78B 为 59.1,并且 CRPE 得分提升至 79.2。这些数据表明 InternVL3 系列与领先的封闭源和开源模型(如 GPT-4o 和 Qwen2.5-VL 系列)具有竞争力。尽管这些进展,某些基准测试(如 MMHal)上的轻微下降表明,尽管 InternVL3 系列整体有所进步,但优化数据和训练策略以实现更一致的改进仍然是未来工作的重点方向。
视觉定位
我们在 RefCOCO [56]、RefCOCO+ [56] 和 RefCOCOg [88] 数据集上评估了 InternVL 的视觉定位能力,任务是根据给定的文本描述准确地在图像中定位目标对象。表 6 显示了不同模型之间的全面比较,包括几种专门的定位模型和多个多模态大语言模型。
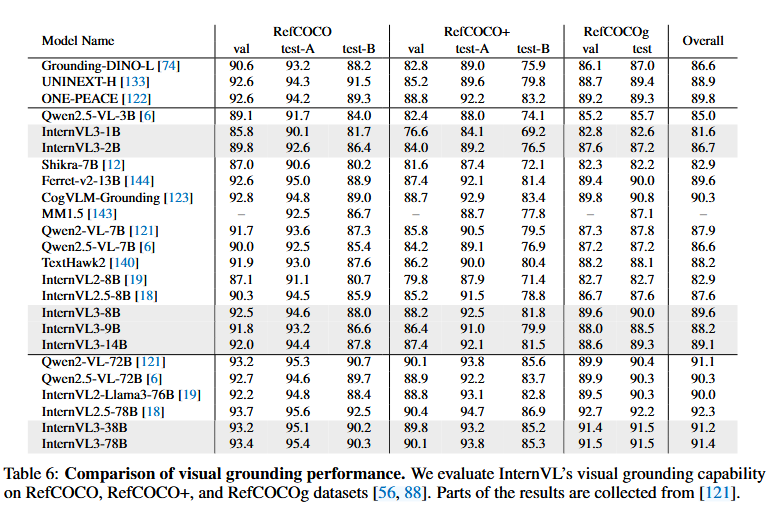
在较小规模的模型中,我们观察到 Qwen2.5-VL-3B 的平均得分为 85.0,而 InternVL3-1B 和 InternVL3-2B 模型的平均得分分别为 81.6 和 86.7。值得注意的是,随着模型规模的扩大,InternVL3 系列表现出显著的改进。InternVL3-8B、InternVL3-9B 和 InternVL3-14B 的平均得分在 88.2 至 89.6 之间,反映出随着模型规模的增加,性能逐渐提升的趋势。然而,当模型规模进一步增大时,性能提升似乎趋于平稳。例如,InternVL2.5-78B 的平均得分为 92.3,而 InternVL3-78B 的得分仅为 91.4。我们推测这是因为 InternVL3 的训练数据扩展中没有包含额外的定位特定数据,定位目标数据的相对减少可能限制了其定位能力。
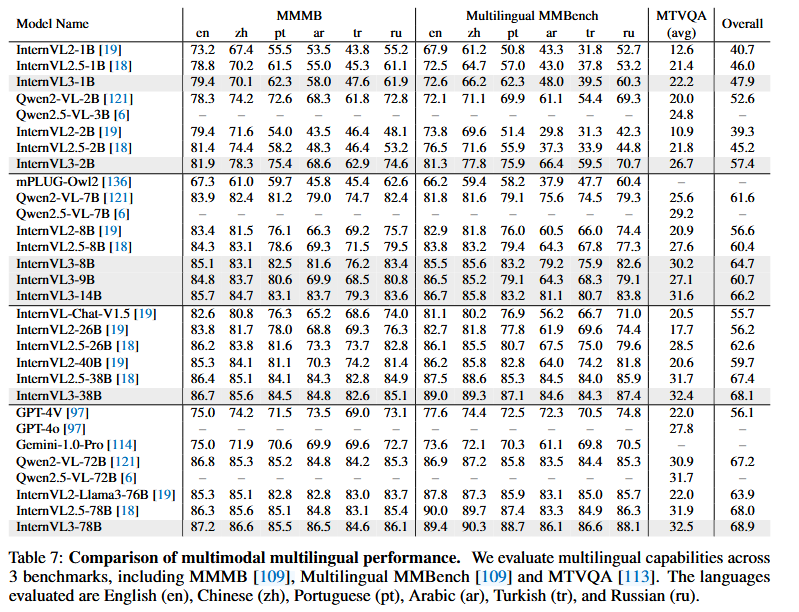
多模态多语言理解
我们使用基准测试——多模态多语言基准(MMMB)、多语言MMBench [109] 和 MTVQA [113]——评估 InternVL 的多模态多语言理解能力,如表 7 所示。
InternVL3 系列在多语言性能方面与前代产品相比显示出持续的改进。例如,轻量级的 InternVL3-1B 已经在性能上略有提升,而更大规模的变种,如 InternVL3-38B 和 InternVL3-78B,在所有三个基准测试中的平均得分显著提高。与其他领先模型的比较进一步凸显了 InternVL3 系列的有效性。特别值得注意的是,InternVL3 变种在性能上与 Qwen2VL-72B [121] 和 Qwen2.5-VL-72B [6] 等模型相当或更优。总体而言,InternVL3 系列在 MMMB、多语言 MMBench 和 MTVQA 方面增强的性能突显了我们在推进全球多模态应用方面方法的潜力。
视频理解
视频理解对于评估多语言多模态语言模型(MLLMs)如何捕捉复杂视频内容中的时间和多模态线索至关重要。在这项工作中,我们在六个已建立的基准测试——VideoMME [38]、MVBench [65]、MMBench-Video [35]、MLVU [154]、LongVideoBench [129] 和 CG-Bench [2]——中评估了 InternVL3 系列,详见表 8。总体而言,InternVL3 模型在性能上比前代产品有明显的改进,并且表现出良好的可扩展性趋势。随着模型容量的增加,性能提升变得更加显著。例如,InternVL3-2B 在 Video-MME 评分(58.9/61.4)和 MVBench 及 MLVU 性能方面均优于早期的 2B 变种。
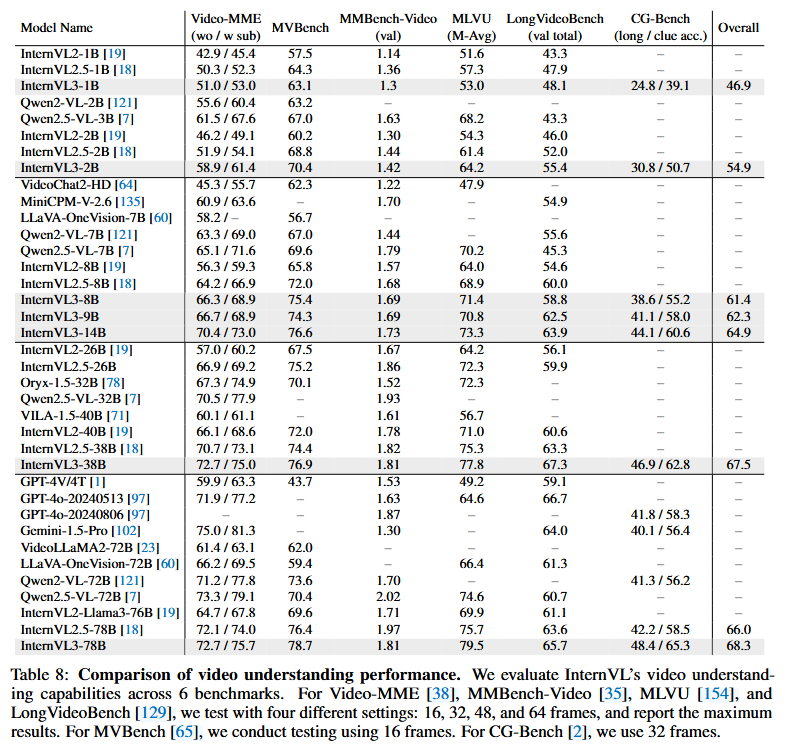
InternVL3系列的扩展行为在较大规模的模型中尤为明显。InternVL3-14B的Video-MME得分为70.4/73.0,而InternVL3-38B和InternVL3-78B将这些指标进一步提升,分别达到了72.7/75.0和72.7/75.7。此外,对InternVL3系列进行的CG-Bench评估提供了对长距离视频推理的进一步见解,性能随着模型规模的增加而稳步提升,例如InternVL3-78B在CG-Bench上的得分为48.4/65.3。
与其它开源模型相比,InternVL3系列展示了竞争优势。例如,尽管Qwen2.5-VL模型取得了令人印象深刻的结果(Qwen2.5-VL-72B在Video-MME上的得分为73.3/79.1),但InternVL3系列在其他指标(如MVBench和MLVU)上往往表现更优。同样,尽管像Gemini-1.5-Pro这样的闭源系统在某些基准测试中(如Video-MME)有时会表现出更佳的结果,但InternVL3的整体性能,尤其是在较大规模模型中,具有很强的竞争力。
GUI定位
GUI定位要求对界面元素进行精确的定位和理解,这对于自动化UI测试和辅助技术等应用至关重要。在表9中,我们报告了GUI定位基准测试的性能,将InternVL3与最新的多模态和GUI特定模型进行比较。结果表明,InternVL3在不同规模上均表现出竞争力。在ScreenSpot [22]基准测试中,InternVL3-72B达到了88.7%的准确率,略微超过了UI-TARS-72B [100](88.4%)和Qwen2.5-VL-72B(87.1%),而Aguvis-72B [132]以89.2%的成绩领先。值得注意的是,InternVL3-38B(85.6%)显著超过了GPT-4o(18.1%)和Gemini 2.0(84.0%)。

对于更具挑战性的ScreenSpot-V2 [130]基准测试,InternVL3表现出强大的扩展行为:InternVL3-72B达到了90.9%,超过了UI-TARS-72B(90.3%)。8B的变体(81.4%)已经超过了UI-TARS-72B,而38B的模型(88.3%)进一步缩小了与72B版本的差距。这些结果突显了InternVL3在GUI理解任务中的稳健性,特别是在处理复杂屏幕布局和动态界面方面。模型规模的性能提升表明,更大的架构能够更好地捕捉精确GUI定位所需的细粒度视觉-文本对齐。InternVL3模型的优异性能突出了其在解释复杂视觉布局方面的稳健性。未来的工作将探讨将这些能力扩展到更具动态性和交互性的GUI环境中。
空间推理
空间推理涉及从视觉输入中构建三维环境的心理表征——这是自动驾驶等应用中的关键能力。表10报告了视觉-空间智能基准测试(VSI-Bench)[134]的性能结果,其中InternVL3与其他最先进的人工智能模型进行了比较。结果清楚地表明,InternVL3在空间推理任务中优于其竞争对手。特别是,InternVL3-8B变体得分为42.1,在基准测试中领先所有开源模型。
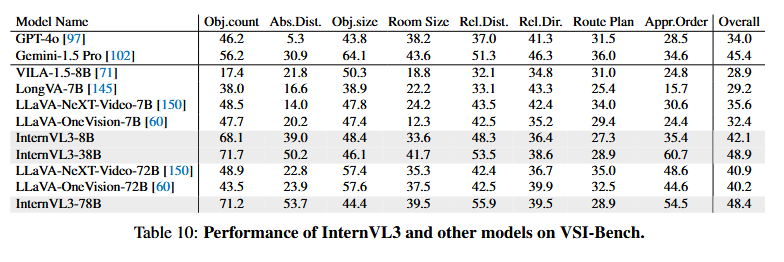
此外,InternVL3-38B和InternVL3-78B变体分别得分为48.9和48.4——均优于GPT-4o、Gemini-1.5 Flash和Gemini-1.5 Pro等专有模型。此外,InternVL3在基准测试的几个子类别任务中表现出色。它在对象计数任务中得分为71.2,在绝对距离估计中得分为53.7,在相对距离估计中得分为55.9,在外观顺序预测中得分为54.5,展示了其强大的空间推理能力。这些令人鼓舞的结果强调了InternVL3在提升3D场景理解方面的潜力,未来的工作将进一步探索其在各种下游应用中的集成。
语言能力评估
表11展示了在多种基准测试中对语言能力的性能评估。这些基准测试涵盖了全面的知识、语言理解、推理、数学和编程任务的一系列评估,例如MMLU [46]、CMMLU [63]、C-Eval [48]、GAOKAO-Bench [149]、TriviaQA [52]、NaturalQuestions [58, 110]、RACE [59]、WinoGrande [103]、HellaSwag [142]、BigBench Hard [112]、GSM8K-Test [25]、MATH [47]、TheoremQA [17]、HumanEval [14]、MBPP [4]和MBPP-CN [4]。
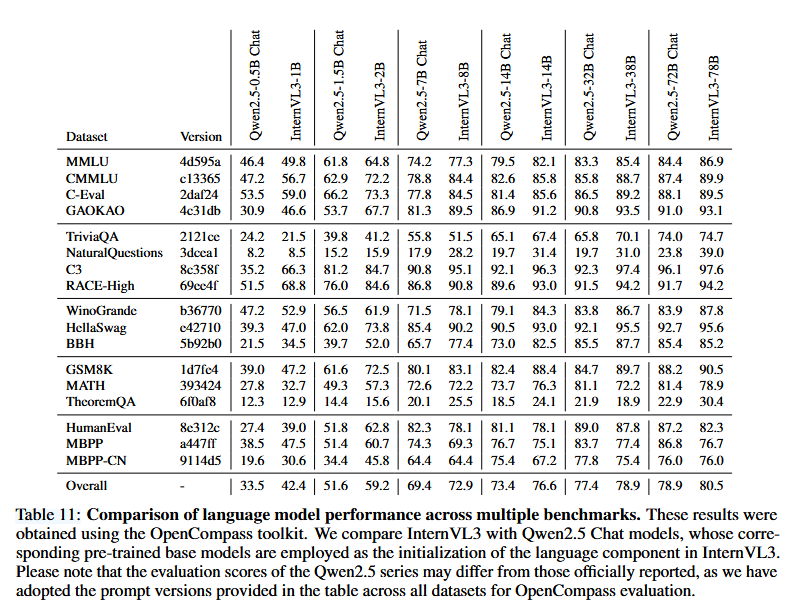
特别是,实验比较了Qwen2.5聊天模型与相应的InternVL3变体的性能。这两个模型系列都以相同的预训练Qwen2.5基础模型为起点。经过原生多模态预训练和额外的后续训练后,InternVL3系列在大多数评估基准中表现出优于Qwen2.5聊天模型的性能。这种语言能力的提升主要归因于几个因素,包括整合了约25%的纯文本数据、在原生多模态预训练期间的联合参数优化以及在后续训练阶段中广泛使用高质量的文本语料库。这种策略不仅加强了多模态理解能力,也显著提升了语言能力。因此,即使从相同的预训练基础模型出发,InternVL3采用的集成多模态和纯文本训练策略使其在语言能力方面表现出显著优于Qwen2.5聊天模型的性能,后者采用的是专门为纯文本任务设计的训练管道。
消融研究
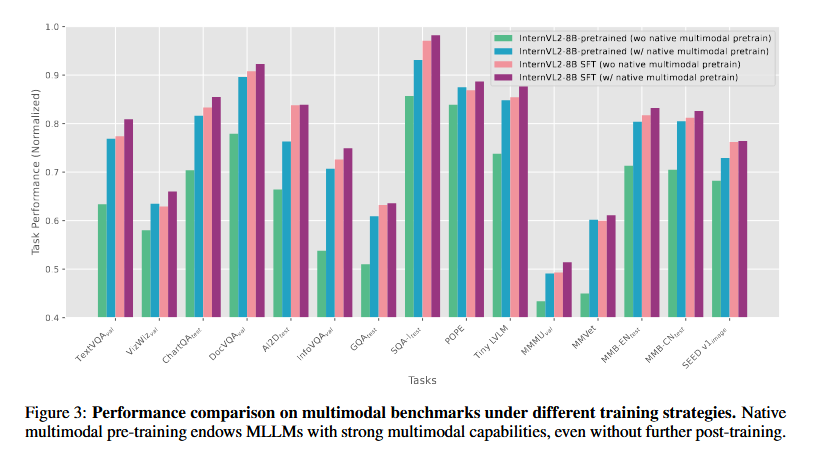
原生多模态预训练的有效性。为了评估原生多模态预训练的有效性,我们在保持其架构、初始化参数和训练数据完全不变的前提下,对InternVL2-8B模型进行了实验。传统上,InternVL2-8B采用的训练流程为:从用于多模态对齐的MLP预热阶段开始,然后进入指令微调阶段。在我们的实验中,我们将传统的MLP预热阶段替换为我们的原生多模态预训练过程。这种修改有助于隔离原生多模态预训练对模型整体多模态能力的具体贡献。图3中的评估结果显示,经过原生多模态预训练的模型在大多数基准测试中的表现与完全多阶段训练的InternVL2-8B基线模型相当。此外,当在高质量数据上进行指令微调时,该模型在评估的多模态任务中表现出进一步的性能提升。这些发现强调了原生多模态预训练在赋予大语言模型强大多模态能力方面的效率。
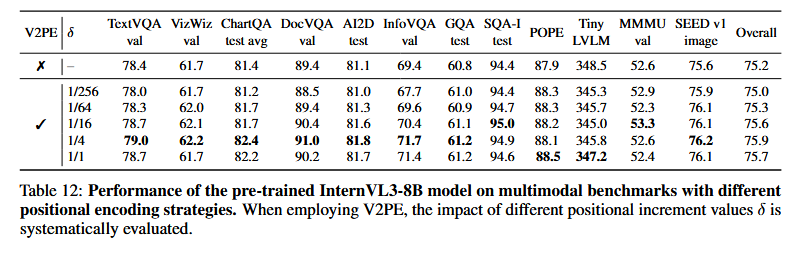
变量视图位置编码的评估。为了促进长文本场景下的多模态能力,InternVL3在其视觉嵌入中采用了变量视图位置编码(V2PE)。然而,在原始V2PE [42] 中,这种专用于视觉令牌的位置编码在适度上下文长度的多模态任务中并未显示出优势。为了进一步探索V2PE在更广泛环境中的效用,我们在原生多模态预训练阶段引入了V2PE,并对InternVL3-8B预训练模型在标准多模态基准测试中进行了评估。如表12所示,引入V2PE后,大多数评估指标的性能显著提升。此外,我们的消融研究——通过改变位置增量δ——表明,即使对于主要涉及短上下文的任务,较小的δ值也可以实现最优性能。这些发现为未来旨在优化大语言模型中视觉令牌位置编码策略的努力提供了重要见解。值得注意的是,为了确保公平的比较,本报告中的其他所有结果均维持δ = 1,除非表12中展示的实验结果。
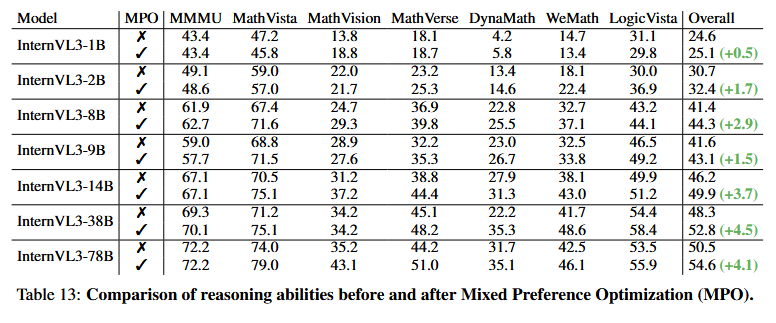
混合偏好优化。在这里,我们展示了MPO的有效性。如表13所示,与未使用MPO的模型相比,使用MPO微调的模型在七个多模态推理基准测试中表现出更优的推理性能。具体而言,InternVL3-78B和InternVL3-38B分别比其对应模型高出4.1和4.5分。值得注意的是,用于MPO训练的数据是用于SFT训练数据的子集,这表明性能提升主要归因于训练算法,而非训练数据。
结论
我们介绍了InternVL3,这是InternVL系列的重要进展,实现了一种原生的多模态预训练范式。通过在预训练阶段联合学习语言和多模态能力,InternVL3 避免了后处理多模态语言模型 (MLLM) 训练管道中常见的训练复杂性和优化挑战。通过引入可变视觉位置编码 (V2PE) 以扩展多模态上下文,采用高级后训练策略(如监督微调和混合偏好优化)以及测试时的扩展,InternVL3 在广泛的多模态任务中建立了新的开源基准,同时保持了强大的语言能力。特别是,InternVL3-78B 在 MMMU 基准测试中获得了 72.2 分,超过了之前的开源 MLLM,并缩小了与领先的专有模型(如 Gemini-2.5 Pro)的性能差距。为促进多模态大语言模型的社区驱动创新,我们将公开发布 InternVL3 的训练数据和模型权重,从而鼓励在这一快速发展的领域进行进一步的研究和开发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号