语音前端处理算法
https://docs.espressif.com/projects/esp-sr/zh_CN/latest/esp32s3/audio_front_end/README.html
https://github.com/espressif/esp-sr
https://github.com/espressif/esp-skainet
概览
智能语音设备需要在远场噪声环境中,仍具备出色的语音交互性能,声学前端 (Audio Front-End, AFE) 算法在构建此类语音用户界面 (Voice-User Interface, VUI) 时至关重要。
-
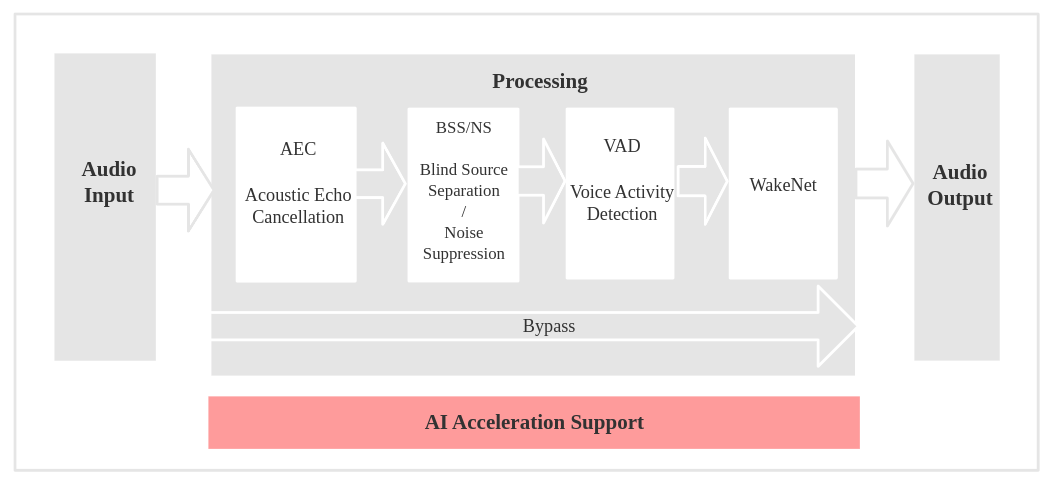
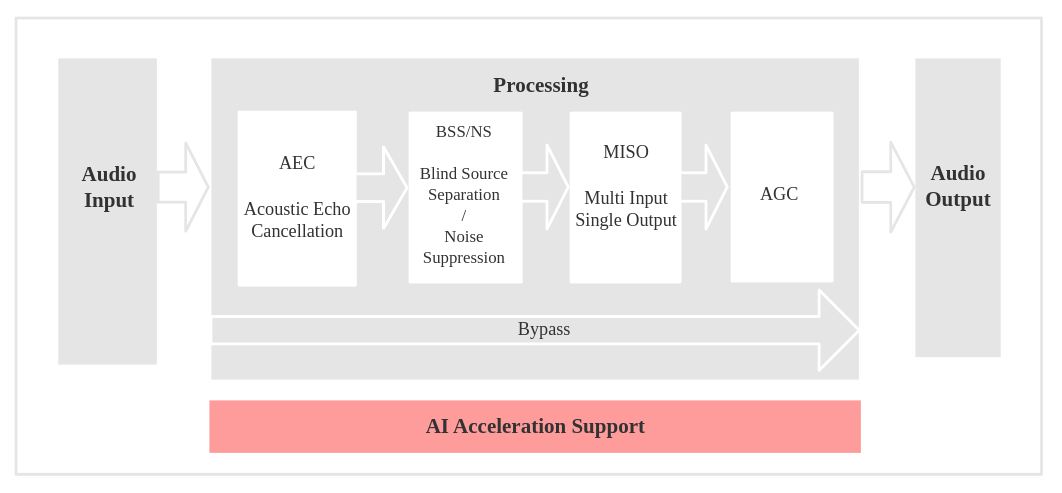
AEC (Acoustic Echo Cancellation)
回声消除算法,用于去除麦克风输入信号中的回声,保证在播放声音的同时,能够清晰地识别语音。通常支持多麦克风输入,以有效去除环境中的回声。 -
NS (Noise Suppression)
噪声抑制算法,专注于抑制音频信号中的非语音噪声,尤其是稳态噪声。此算法通常通过单通道音频信号进行处理,提升语音信号的清晰度。 -
BSS (Blind Source Separation)
盲源分离算法,通过多通道音频信号分离目标声源与干扰噪声,从而提高语音信号的质量。适用于复杂环境中提取有用的语音信息。 -
MISO (Multi Input Single Output)
多输入单输出算法,使用双通道输入并输出信噪比高的一路音频信号。适用于多个麦克风环境中的信号选择,能够在没有特定唤醒条件的情况下输出最清晰的信号。 -
VAD (Voice Activity Detection)
语音活动检测算法,用于实时判断当前音频帧是否包含语音活动,提供语音活跃状态的检测信息。 -
AGC (Automatic Gain Control)
自动增益控制算法,根据输入信号的强度动态调整输出音频的增益。对于弱信号,增大输出幅度;当信号过强时,自动降低输出幅度,避免音频失真。 -
WakeNet
基于神经网络的唤醒词检测模型,设计用于低功耗嵌入式系统,通过有效识别特定唤醒词,激活语音交互功能。
使用场景
语音识别
语音通话
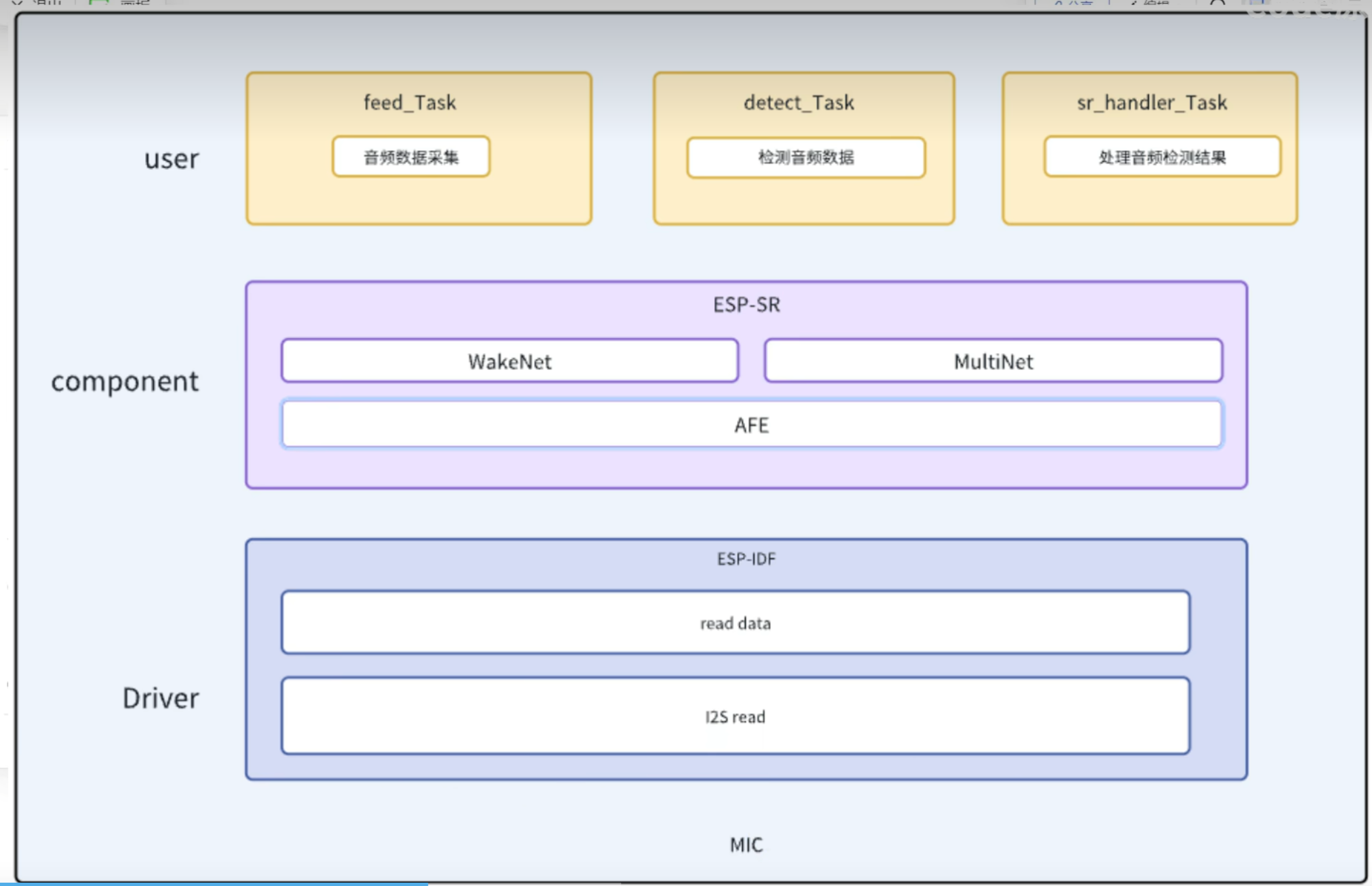
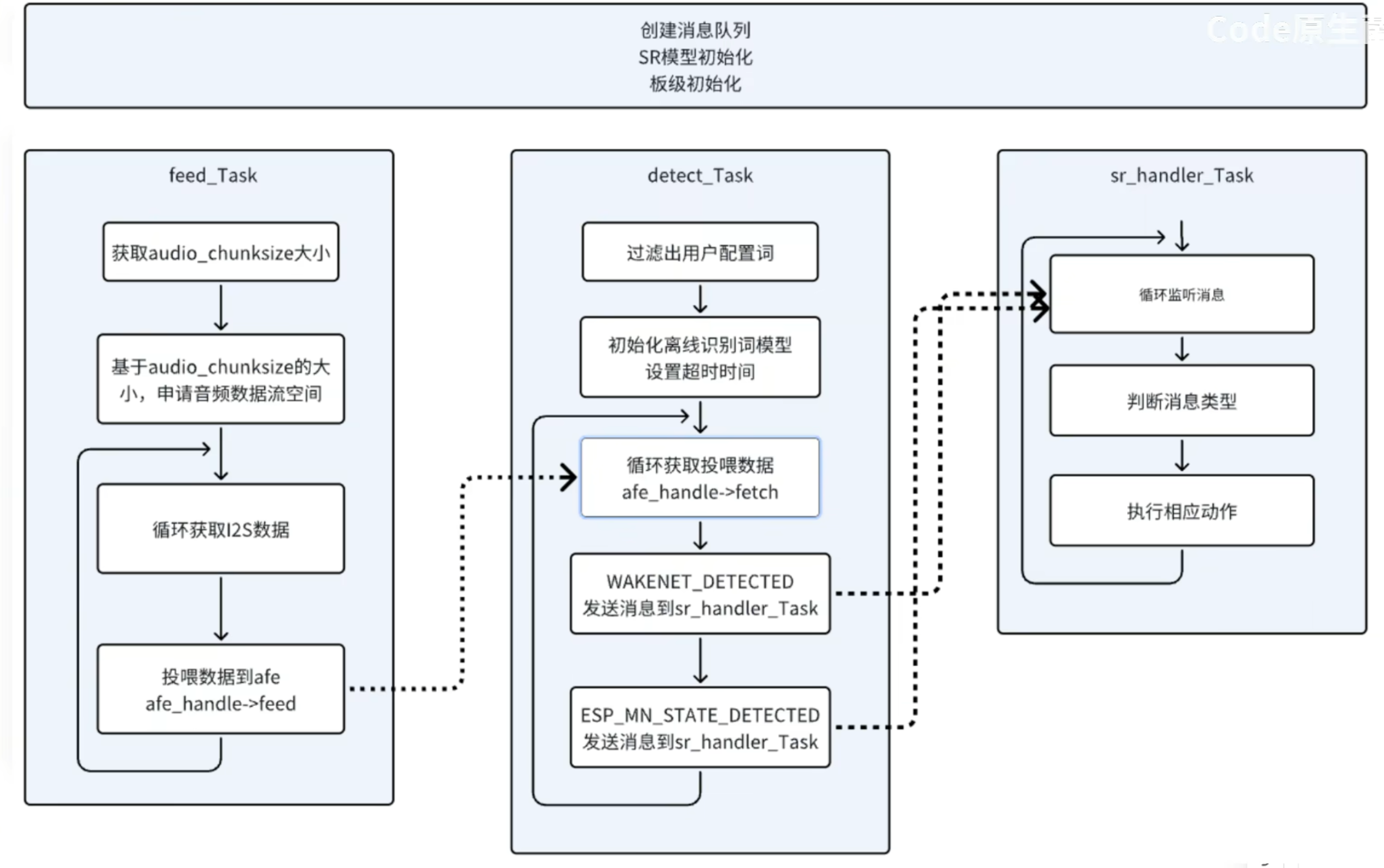
代码流程图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号