阿里语义VAD:基于改进模型结构的多任务学习推进VAD系统发展
http://arxiv.org/pdf/2312.14860v1
摘要
在语音识别系统中,语音活动检测(VAD)是一个至关重要的前端模块。针对传统基于DFSMN的二值VAD系统在噪声鲁棒性方面的不足,本文进一步提出了基于多任务学习的改进模型的语义VAD,以满足实时和离线系统的特定应用需求。内部数据集上的评估结果显示,与基于DFSMN的实时VAD系统相比,基于RWKV的实时语义VAD系统在字符错误率(CER)、检测代价函数(DCF)和噪声鲁棒性比率(NRR)上分别实现了7.0%、26.1%和19.2%的相对下降。同样,与基于DFSMN的离线VAD系统相比,基于SAN-M的离线VAD系统在CER、DCF和NRR上分别实现了4.4%、18.6%和3.5%的相对下降。
引言
自动语音识别(ASR)系统在人机通信中变得越来越重要。它通常与语音活动检测(VAD)系统[1–3]配对使用,VAD系统通过从输入音频信号中移除非语音数据来提取实际语音数据,从而使ASR系统能够专注于处理有效的语音段,减少由于无效语音导致的识别错误。
早期的VAD研究依赖于手工设计的声学特征,如能量比、过零率和信号周期性[4–6]。随后,包括隐马尔可夫模型(HMM)和高斯混合模型(GMM)在内的监督机器学习方法也被证明是有效的[7]。目前,基于神经网络的VAD模型,如深度神经网络(DNN)[8]、前馈序列记忆网络(FSMN)[10]和深度FSMN[11],在语音研究中受到了广泛关注。在我们的系统实践中,二分类模型结构也从DNN演进到DFSMN,实现了显著的改进。随着应用情境的日益复杂,基于语义的VAD系统[12]被提出,以提高在嘈杂环境下的性能并减少实时场景中的高延迟。
基于不同的模型结构,我们的VAD系统经历了从单任务二分类到多任务语义分类的演变,以增强系统的鲁棒性。本文的其余部分组织如下:第2节介绍VAD系统的实践;第3节展示实验设置;第4节呈现实验结果;最后,第5节总结本工作。
VAD 系统的实践
单任务二元VAD
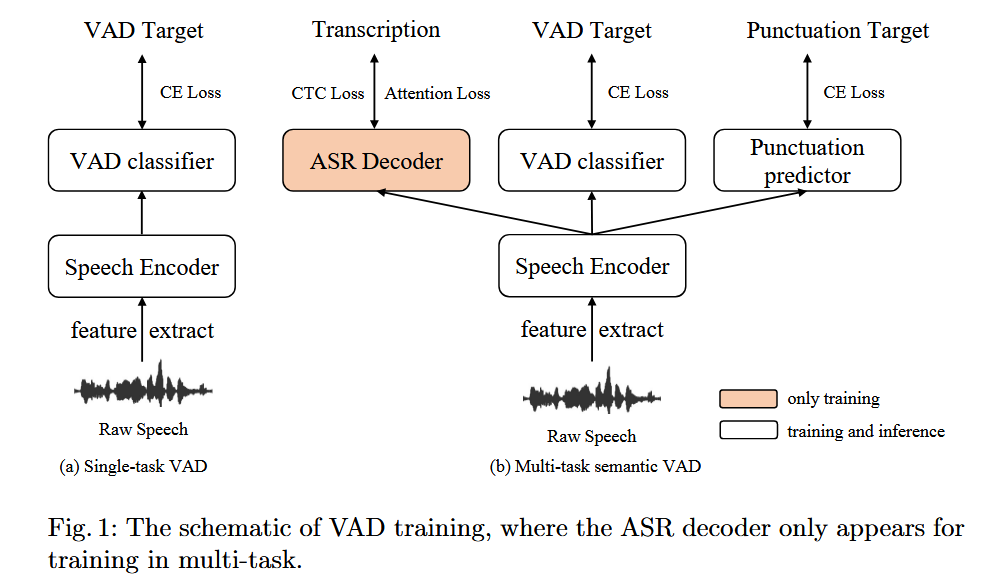
传统的单任务二元VAD训练框架如图1(a)所示,包括语音编码器和VAD分类器。通常,语音编码器采用诸如DNN、FSMN等统计模型。此外,模型训练中使用了交叉熵(CE)损失。
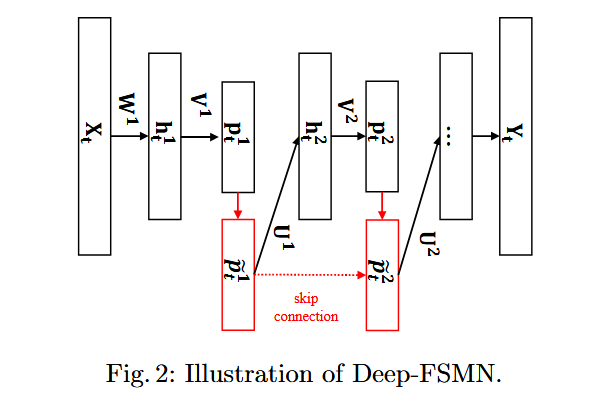
最初,我们采用了一种基于DNN的二分类模型。为了提高检测精度,我们尝试将DNN升级为DFSMN模型,该模型引入了历史信息和相邻隐藏层记忆单元之间的跳跃连接,解决了深度模型中常见的梯度消失问题,如图2所示。结果表明,与相同大小的DNN相比,DFSMN可以将检测成本函数(DCF)相对降低34%。
DFSMN 中记忆块的公式如上所示。这里:
表示第 \(l\) 层线性投影层的线性输出;
\(\tilde{p}_{l}^{t}\) 表示第 \(l\) 层记忆块的输出;
\(N_1^l\) 和 \(N_2^l\) 分别表示第 \(l\) 层记忆块的回顾阶数(look-back order)和前瞻阶数(lookahead order) [11]。
本文主要讨论了基于DFSMN的模型。在实际应用中,DFSMN模型通过配置\(N_2^l\),可以在保持分类性能的同时,灵活控制模型的延迟。因此,这种模型结构已在各种在线和离线语音活动检测(VAD)系统中得到广泛应用。在在线场景中,通常将每层的N2l设置为较小的值,甚至为0,以确保模型级别的低延迟。在离线场景中,可以将其设置为较大的值,以捕捉未来信息。
多任务语义VAD
随着语音识别应用的日益增多,传统的二元VAD系统在噪声环境下的性能以及在互动场景中的端点延迟问题表现出了局限性。通过多任务训练框架,引入了标点预测和自动语音识别(ASR)任务,以增强VAD训练中语义信息的学习[12],从而提高VAD系统的整体性能。
基于多任务的语义VAD训练的示意图如图1(b)所示,它包括语音编码器、解码器、标点预测和VAD分类器。在语义VAD的训练中,我们最初使用了与语音编码器相同的DFSMN结构。然而,我们从ASR领域中两种流行的模型结构中汲取了灵感,即接受加权键值模型(RWKV)[13]和配备记忆的自注意力模型(SAN-M)[14],分别用于训练实时和离线VAD系统。
RWKV模型架构结合了递归神经网络(RNN)[15]和Transformer[16]的优点,非常适合实时VAD系统。我们通过在RWKV块前加入卷积降采样层来增强RWKV模型。每个RWKV块由一个时间混合子块和一个通道混合子块组成,具有递归结构,如图3(a)所示。
给定输入序列x,一个RWKV块使用以下公式将时间混合模块和通道混合模块结合:
与原始公式不同的是,我们在残差连接前添加了一个Dropout层,以避免过拟合。SAN-M架构结合了Transformer的自注意力能力和DFSMN记忆块,使其能够通过自注意力增强单一特征内的条件依赖(CD依赖),并通过DFSMN记忆块从整个数据集的统计平均分布中学习条件独立依赖(CI依赖)。事实证明,SAN-M在ASR任务中优于Transformer[14]。SAN-M架构如图3(b)所示,在多头注意力输出中加入了DFSMN滤波器。在SAN-M的训练过程中,由于训练数据通常具有较长的持续时间(>10秒),常见做法是将输入数据切块,称为SAN-M切块。
实验设置
数据集
我们进行了广泛的实验以评估DFSMN、RWKV和SAN-M在普通话语音识别任务中的性能。在实验中,我们使用了1500小时的内部普通话语音数据作为训练集,其中每段语音的最短时长为10秒。我们使用了大约10小时的长语音数据作为测试集,包括普通近场(表1中的Test1、Test2和Test3)、带噪声的会议数据(表1中的Test4和Test5)以及音视频场景(表1中的Test6)等。此外,我们还使用了大约6小时的纯噪声测试集,包括大约2000个背景音乐样本和4000个普通噪声样本。
评估指标
DCF 是 VAD 系统中最常用的评估指标之一 [12]。本文提出了一种新的评估指标,称为噪声拒绝率(NRR),以根据实际经验评估系统的性能。NRR 用于评估系统在纯噪声数据集中的抗噪能力。此外,通常通过将 VAD 与 ASR 结合在长语音上评估对 CER(字符错误率)的影响。
噪声拒绝率(NRR):N 表示纯噪声测试集中音频样本的数量,M 表示被 VAD 模型拒绝的噪声音频样本数量。M 和 N 的比值被称为 NRR。
模型配置
本研究中,我们使用 80 维对数梅尔滤波器组(Fbank)作为输入特征。窗口大小设置为 25 毫秒,窗口移位为 10 毫秒,所有帧在语音编码器之前以 2 的因子下采样。
基于 DFSMN 的 VAD 包括一个输入线性层、十个 DFSMN 块和一个输出线性层。线性层的维度为 256。DFSMN 块的投射维度为 1024。lorder 设置为 10,rorder 在在线和离线模式下分别设置为 0 和 10。
语义 VAD 训练包括四个组件:编码器、解码器、标点预测和 VAD 分类器。我们将两种改进的模型,RWKV 和 SANM,与 DFSMN 进行了比较。基于 DFSMN 的语义 VAD 模型的配置类似于二分类任务,但增加了语义信息。训练过程中,ASR 采用 CTC 损失。在 RWKV 中,一个 Conv2d 层(out_channels = 256,kernel_size = 3,stride = 2)后接一个输出维度为 256 的线性层。随后是 4 个 RWKV 块。块中的自注意力和前馈网络的维度分别设置为 256 和 1024。相应的解码器是一个隐藏大小为 320 的单层 rnnt。基于 SAN-M 的编码器由 4 个 SAN-M 块和一个具有 4 头多头注意力(MHA)的前馈组件组成。MHA 和前馈网络(FFN)的维度分别设置为 320 和 1280。相应的解码器基于流块感知多头注意力(SCAMA)[17]。
所有实验中,基于 DFSMN、RWKV 和 SAN-M 的语音编码器的大小约为 24MB。我们使用 FunASR 工具包 [18] 进行实验。
结果
在实时系统中,我们在表1和表3中展示了CER、DCF和NRR的结果。
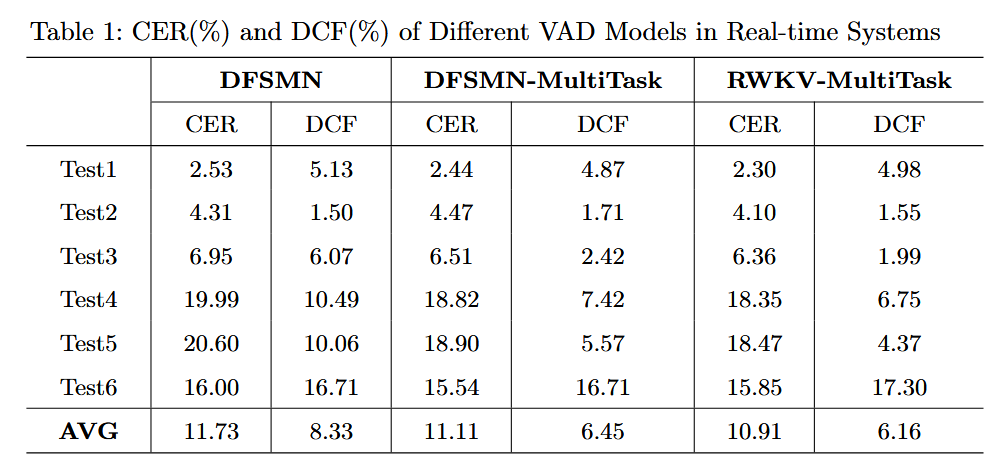

与基于DFSMN的二分类器相比,基于RWKV的语义VAD实现了CER相对降低7.0%,DCF相对降低26.1%,NRR相对提高19.2%。
在离线系统中,我们在表2和表4中展示了CER、DCF和NRR的结果。
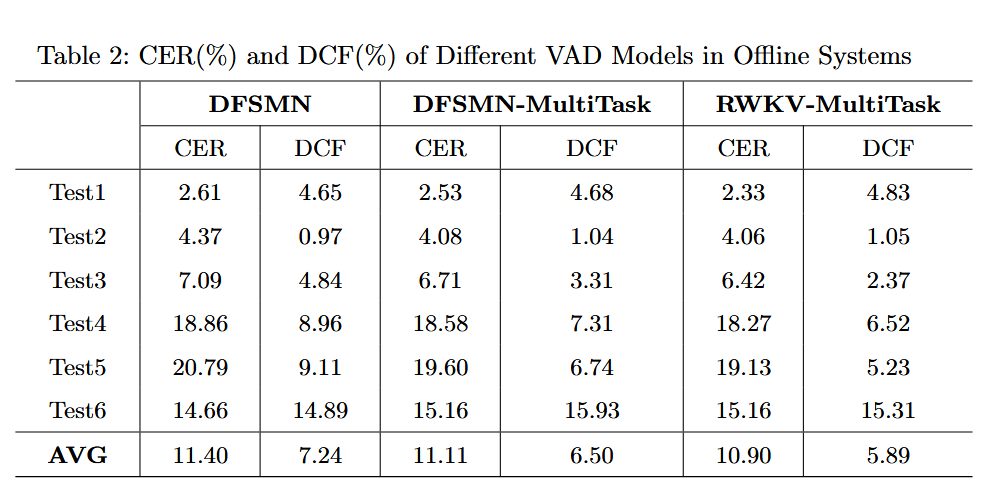
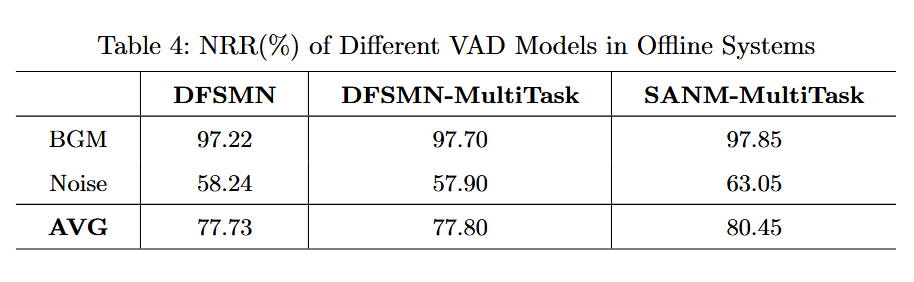
与基于DFSMN的二分类器相比,基于SAN-M的离线VAD系统实现了CER相对降低4.4%,DCF相对降低18.6%,NRR相对提高3.5%。总体而言,基于DFSMN的语义模型相比于传统的二分类方法展现了显著的改进。
此外,通过引入改进的模型结构如RWKV和SAN-M,语义模型的性能可以进一步提升。例如,在表1中的Test5,这是一个噪声会议数据集,实现了CER相对降低10%。然而,表2中的Test6由于缺乏上下文数据,CER有所恶化。未来,我们将基于具体案例进行优化,包括训练数据和后处理策略。
结论
在本文中,我们介绍了基于RWKV的实时语义VAD系统和基于SAN-M的离线语义VAD系统。实验结果表明,语义VAD系统在CER、DCF和NRR指标上优于基于DFSMN的系统。未来,我们将探索利用更复杂的数据并采用高级后处理策略,以进一步提升语义VAD系统的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号