

ALFRED:一个用于解释日常任务中基础指令的基准
https://arxiv.org/abs/1912.01734
https://github.com/askforalfred/alfred
摘要
我们提出了ALFRED(Action Learning From Realistic Environments and Directives),这是一种学习将自然语言指令和第一人称视觉映射到家庭任务动作序列的基准。ALFRED 包含了涉及不可逆状态变化的长而组合的任务,以缩小研究基准与实际应用之间的差距。ALFRED 包含了在交互式视觉环境中针对25000条自然语言指令的专家演示。这些指令既包括像“冲洗杯子并将其放在咖啡机中”这样的高层次目标,也包括像“走到右侧的咖啡机旁”这样的低层次语言指令。与现有的视觉与语言任务数据集相比,ALFRED 任务在序列长度、动作空间和语言方面更为复杂。我们发现,基于近期具身化视觉与语言任务的基线模型在ALFRED 上表现不佳,这表明该基准为开发创新的具身化视觉语言理解模型提供了很大的空间。
引言
在人类活动空间中运行的机器人必须学会将自然语言与现实世界相联系。符号定位问题[21]主要集中在将语言与静态图像连接起来。然而,机器人需要理解任务导向的语言,例如“冲洗杯子并放到咖啡机中”,如图1所示。

将语言转化为行为的平台变得越来越流行,催生了新的测试平台[3, 12, 14, 42]。这些基准测试包括语言驱动的导航和具身化问答,由于Matterport 3D [3, 11]、AI2-THOR [26] 和AI Habitat [45]等环境的影响,这些领域的建模已经取得了显著的进展。然而,这些数据集忽略了描述涉及对象的任务导向行为的复杂性。我们引入了ALFRED,一个新的基准,用于将人类语言与交互式视觉环境中的行为、动作及对象联系起来。基于规划者的专家演示不仅包括高层次和低层次的人类语言指令,还涵盖了AI2-THOR 2.0 [26] 中的120个室内场景。这些演示涉及部分可观测性、长时间的动作视野、不明确的自然语言和不可逆的行为。
ALFRED 包括25,743条英文指令,描述了8,055个平均每个包含50个步骤的专家演示,总计产生了428,322个图像-动作对。受机器人研究中基于分割的抓取[37]工作的启发,ALFRED中的代理通过视觉与对象互动,指定目标对象的像素级交互掩码。这种推断比简单的对象类别预测更现实,后者将定位视为已解决的问题。由于更大的动作和状态空间、长时间视野以及某些动作无法撤销,现有的束搜索[17, 48, 53]和回溯解决方案[24, 29]变得不可行。
为了建立基线性能水平,我们评估了一种类似于现有视觉与语言导航任务的序列到序列模型[28]。该模型在ALFRED的复杂任务上表现不佳,成功率不足5%。为了进行分析,我们还评估了单独的子目标。尽管在孤立的子目标上性能有所提高,但该模型缺乏长期和组合任务规划所需的推理能力。
总之,ALFRED促进了学习模型的发展,这些模型能够将语言转化为在视觉和物理上逼真的模拟环境中的一系列动作和互动。这个基准捕捉到了将人类语言转化为机器人完成家务任务时在现实世界中遇到的许多挑战。能够克服这些挑战的模型将开始缩小与现实世界中以语言驱动的机器人技术之间的差距。
相关工作
表1总结了ALFRED与其他带有语言注释的视觉动作数据集相比的优势。
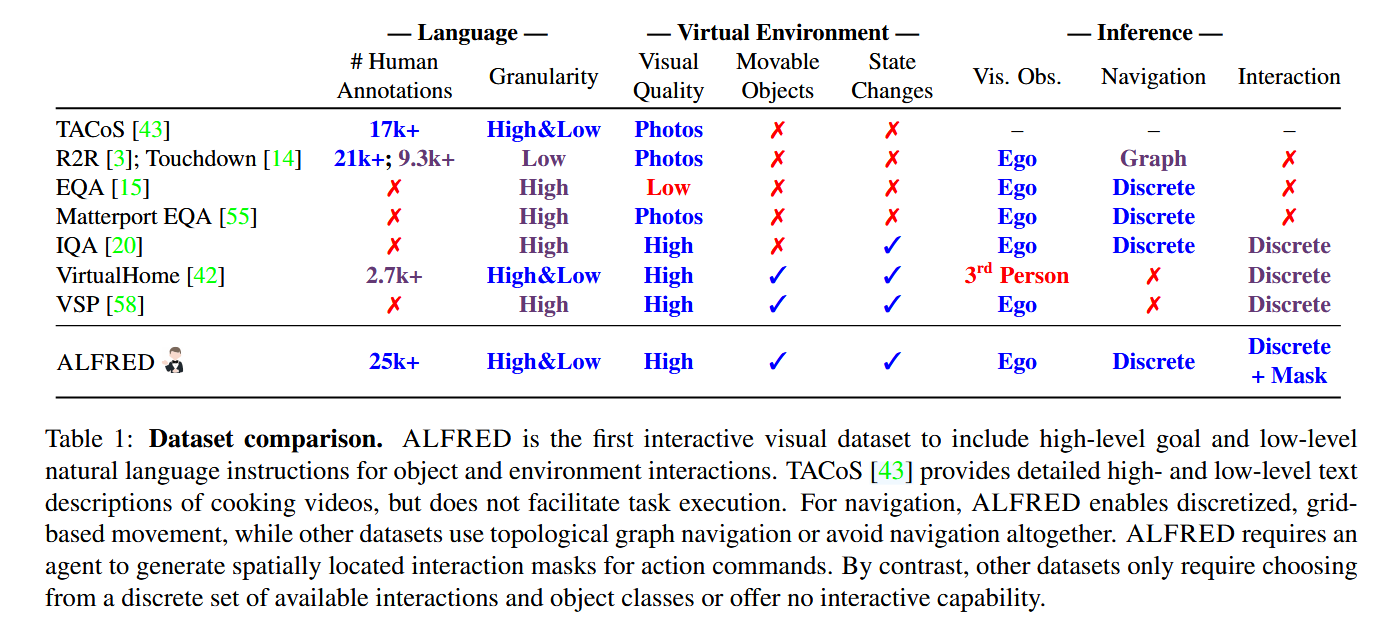
视觉与语言导航。在视觉-语言导航任务中,自然语言或模板语言通过第一人称视觉观察描述通往目标位置的路线[3, 12, 13, 14, 31]。自从R2R[3]提出以来,研究人员已经通过诸如进展监控等技术[28]显著提高了模型的导航性能[17, 24, 29, 53, 54],并引入了包含额外路径指令的任务变体[38, 39, 51]。然而,这些研究大多局限于静态环境。相比之下,ALFRED任务包括导航、物体交互和状态变化。
视觉与语言任务完成。存在几个基于简单方块世界和完全可观测场景的现有基准[9, 34]。ALFRED提供了更复杂的任务,场景视觉上更加丰富,并使用部分可观测环境。CHAI基准[33]评估代理执行家庭指令的情况,但使用的是通用的“交互”动作。ALFRED具有七种操作动作,如捡起、打开和开启,以及不同的状态变化,如干净与脏,语言和视觉复杂性的变化。
在最初的AI2-THOR环境中,先前的研究探讨了视觉语义规划任务[19, 58]。人工语言来自模板,环境交互通过离散类别预测处理,例如从预定义选项中选择苹果作为目标对象。ALFRED采用了人类语言指令,目标选择通过类别无关的像素级交互掩码进行。在VirtualHome[42]中,程序从视频演示和自然语言指令生成,但推理不涉及第一人称视觉和动作反馈或部分可观测性。
关于基于语言的指令在自然语言处理社区中已有大量文献。该领域的研究主要集中在将指令映射到动作上[5, 13, 32, 36, 49],但这些研究不涉及视觉交互环境。
具身问答。现有用于具身环境中视觉问答的数据集采用模板语言或静态场景[15, 20, 55, 57]。在ALFRED中,代理不是回答问题,而是必须完成使用自然语言指定的任务,这需要导航和与物体互动。
指令对齐。视频的语言注释使发现词与概念之间的视觉对应关系成为可能[1, 46, 43, 56, 59]。相比之下,ALFRED需要在交互式环境中执行任务,而不是从录制的视频中学习。
机器人指令遵循。指令遵循是机器人领域长期关注的议题[7, 10, 30, 35, 40, 41, 47, 52]。研究方向包括烹饪[10]、桌面清理[40]和移动操纵[30]等任务。通常,这些研究受限于少数场景[35],考虑的物体数量较少[30],或者使用相同的环境进行训练和测试[7]。相比之下,ALFRED包含120个场景,许多具有多样外观的物体类别,以及未见过的测试环境集。
ALFRED 数据集
ALFRED 数据集包含 25,743 条语言指令,对应 8,055 个专家演示片段。每个指令包括一个高层次的目标和一系列逐步指示。每个专家演示都可以在 AI2-THOR 2.0 模拟器中确定性地重播。
专家演示
专家演示由代理的环境第一人称视觉观察、每个时间步所采取的动作以及真实交互掩码组成。这些演示是由一个规划器生成的,该规划器使用了一些在推理时对代理不可用的元数据。导航动作包括移动代理或改变其摄像头方向,而操作动作包括拾取和放置物体、打开和关闭橱柜和抽屉,以及开关电器。交互可能涉及多个物体,例如使用刀切苹果、在水槽中清洗杯子或在微波炉中加热土豆。操作动作附带目标物体的真实分割。
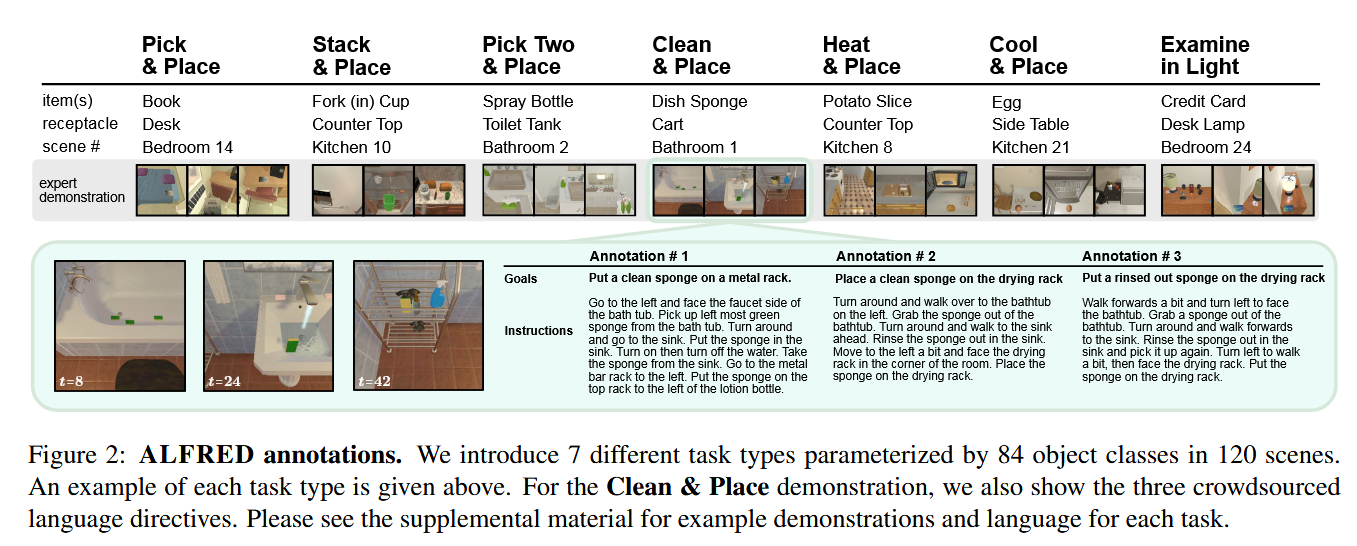
图 2 给出了 ALFRED 中高层次代理任务的示例,如将已清洗的物体放置到目标位置。这些任务由焦点物体、目标容器(如桌面)、执行任务的场景以及对于“堆叠和放置”任务的基底物体(如盘子)等参数化。ALFRED 包含这些七项任务的专家演示,这些任务使用 58 个唯一物体类别和 26 个容器物体类别在 120 个不同的室内场景中执行。对于像土豆切片这样的物体类别,代理必须先拿起刀并找到土豆才能切片。所有物体类别都包含多种视觉变化,包括不同的形状、纹理和颜色。例如,苹果类有 30 种独特的变体。室内场景包括不同类型的房间:每个厨房、浴室、卧室和客厅各有 30 个。
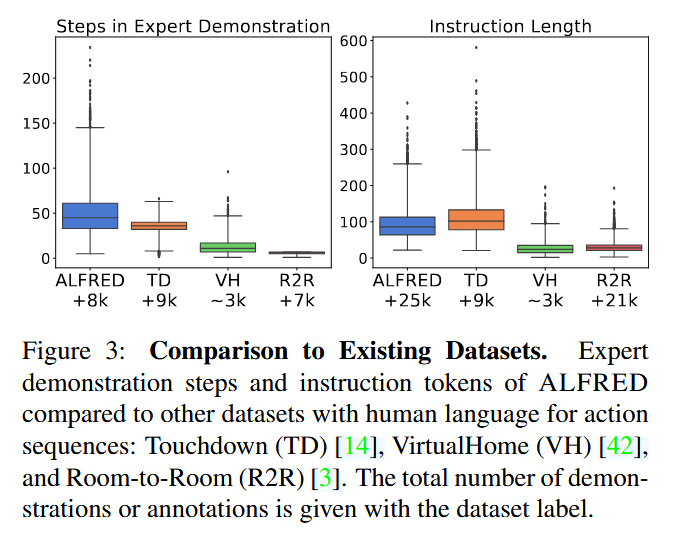
对于 2,685 种任务参数组合,我们每组参数生成三个专家演示,总计 8,055 个独特的演示,平均每个演示包含 50 个动作步骤。图 3 给出了 ALFRED 演示中动作步骤的分布与相关数据集的对比。例如,对于任务参数 {task: Heat & Place, object: potato, destination: counter top, scene: KITCHEN-8},我们通过将代理和物体放置在随机选择的起始位置来生成三个不同的专家演示。物体的起始位置具有某些常识性和类别特定的约束,例如,叉子可以放在抽屉里,但苹果不能。
与仅包含导航任务的数据集不同,其中专家演示可以来自A*规划器,我们的状态空间包括对象位置和状态变化。因此,为了生成专家演示,我们将代理和对象状态以及高层次的环境动态编码为规划域定义语言(PDDL)规则[18]。然后,我们定义了特定任务的PDDL目标条件,例如加热的土豆放置在桌面上。请注意,规划器将环境编码为完全可观测的,并且对世界动态具有完美知识。然而,在训练和测试代理模型时,环境是部分可观测的:它仅通过代理的自身体视图进行观测,随着动作的执行逐步展开。
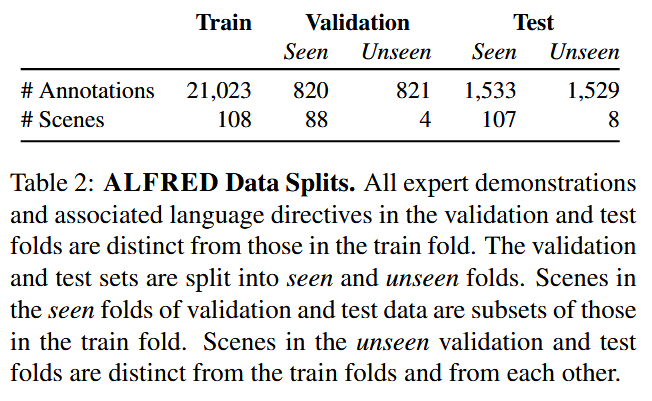
我们将这些专家演示划分为训练、验证和测试集(表2)。根据视觉-语言导航领域的研究[3],我们进一步将验证和测试集分为两种条件:已见环境和未见环境。这种划分有助于考察模型在完全新的空间中对新对象类别变化的泛化能力。
语言指令
对于每个专家演示,我们使用Amazon Mechanical Turk (AMT)从至少三位不同的标注者处收集了开放词汇、自由形式的自然语言指令,总共收集了2.5万个语言指令。语言指令包括高层目标和低层命令,如图1和图2所示。图3显示了ALFRED与相关数据集中语言注释标记长度的分布。
AMT工作人员被要求写指令,告诉一个“智能机器人”如何完成视频中展示的动作。我们为每个专家演示创建了一个视频,并将其切分为多个段落,使得每段对应一个指令。我们参考专家演示的PDDL计划来确定任务的子目标,例如,导航到刀子的许多低层步骤,或站在微波炉前加热土豆片的几个步骤。我们通过视频下方的颜色时间线条来直观突出与子目标相关的动作序列。在每个HIT(Human Intelligence Task)中,工作人员观看视频,然后为每个高亮显示的子目标段落编写低层的、逐步的指令。工作人员还编写了一个高层目标,总结机器人在专家演示过程中应完成的任务。
这些指令通过另一次HIT由至少两位标注者验证,必要时会有第三位仲裁者。在验证过程中,我们向工作人员展示所有三个语言指令的注释,但不展示视频。工作人员选择这三个指令是否描述了相同的动作,如果不相同,则选择哪个最不同。如果某个指令被大多数验证工作人员选为最不同,则该指令将被删除,并由另一名工作人员重新标注该演示。从定性分析来看,这些被拒绝的注释包含了错误的对象引用(例如,“鸡蛋”而不是“土豆”)或方向(例如,“向左走...”而不是“向右”)。
基线模型
针对 ALFRED 任务训练的代理需要综合处理视觉和语言输入,并生成一系列低级操作以与环境互动。
序列到序列模型
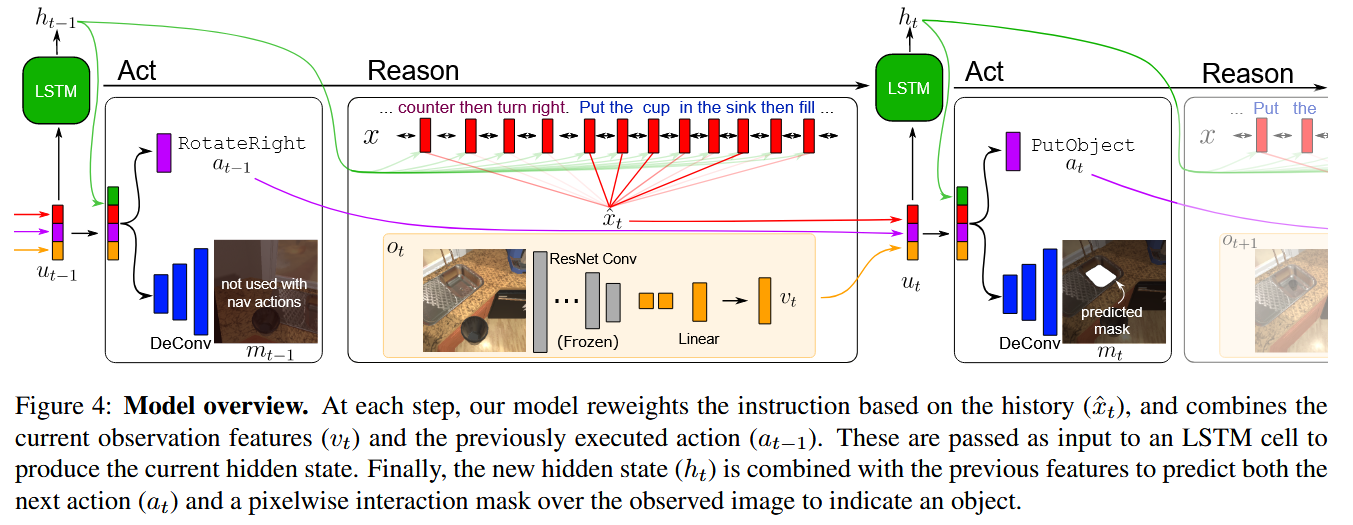
我们使用 CNN-LSTM 序列到序列(SEQ2SEQ)架构来建模交互代理。CNN 编码视觉输入,双向 LSTM 生成语言输入的表示,解码器 LSTM 在注意编码语言的同时推断一系列低级操作。详情请参见图 4 和补充材料中的实现细节。
监督训练。我们使用模仿学习在专家轨迹上训练所有模型。这确保了语言指令与视觉输入匹配。在每个时间步,模型被训练生成专家操作及其相关的操作掩码。
我们注意到,在 ALFRED 中使用 DAgger 风格 [44] 的学生强制范式是不简单的,即使不考虑语言对齐。在仅导航数据集(如 R2R [3])中即时获取专家演示操作只需重新运行 A*。而在 ALFRED 中,即时演示需要重新规划。在某些情况下,重新规划是不可能的:例如,在执行 {Clean & Place, apple, refrigerator, KITCHEN-3} 任务时,如果学生强制模型切掉了场景中唯一的苹果,则无法恢复该操作,任务也无法完成。
视觉编码。每个视觉观察 \(o_t\) 通过冻结的 ResNet-18 [22] 卷积神经网络(CNN)进行编码,我们采用最终卷积层的输出以保留用于在视觉帧中定位特定对象所需的空间信息。通过两个额外的 1×1 卷积层和一个全连接层来嵌入此输出。在训练过程中,来自专家演示的一组 \(T\) 个观察值被编码为 \(V = \langle v_1, v_2, \ldots, v_T \rangle\),其中 \(v_t\) 是时间步 \(t\) 的视觉特征向量。
语言编码。给定一个由 \(L_g\) 个词组成的自然语言目标 \(G = \langle g_1, g_2, \ldots, g_{L_g} \rangle\),以及由 \(L_s\) 个词组成的逐步指令 \(S = \langle s_1, s_2, \ldots, s_{L_s} \rangle\),我们将它们连接成一个单一的输入序列 \(X = \langle g_1, g_2, \ldots, g_{L_g}, \text{<SEP>}, s_1, s_2, \ldots, s_{L_s} \rangle\),其中 \(\text{<SEP>}\) 标记表示高级目标与低级指令之间的分隔。该序列被输入到双向 LSTM 编码器中,产生每个词的编码 \(x = \{x_1, x_2, \ldots, x_{L_g+L_s}\}\)。
语言上的注意力机制。代理在每个时间步的行动基于对指令中的词进行加权的注意力机制。我们对语言特征 \(x\) 进行软注意力计算,根据解码器上一时间步的隐藏状态 \(h_{t-1}\) 来计算注意力分布 \(\alpha_t\):
\(z_t = (W_x h_{t-1})^T x, \quad \alpha_t = \text{Softmax}(z_t), \quad \hat{x}_t = \alpha_t^T x\)
其中,\(W_x\) 是全连接层的可学习参数,\(z_t\) 是一个表示 \(x\) 中每个词注意质量的标量值向量,\(\hat{x}_t\) 是基于 \(z_t\) 诱导的注意力分布 \(\alpha_t\) 对 \(x\) 进行的加权和。
行动解码。在每个时间步 \(t\),接收到新的观察图像 \(o_t\) 后,LSTM 解码器接收视觉特征 \(v_t\)、语言特征 \(\hat{x}_t\) 和前一个动作 \(a_{t-1}\),并输出新的隐藏状态 \(h_t\):
\(u_t = [v_t; \hat{x}_t; a_{t-1}], \quad h_t = \text{LSTM}(u_t, h_{t-1})\)
其中 \([; ]\) 表示连接。隐藏状态 \(h_t\) 用于获取下一个注意力加权语言特征 \(\hat{x}_{t+1}\)。
行动和掩模预测。代理通过选择一个动作并生成一个像素级的二进制掩模来与环境交互,该掩模指示框架中的特定对象。尽管AI2-THOR支持代理导航和对象操控的连续控制,但我们离散化了动作空间。代理从13个动作中选择:5个导航动作(MoveAhead、RotateRight、RotateLeft、LookUp和LookDown)和7个交互动作(Pickup、Put、Open、Close、ToggleOn、ToggleOff和Slice)。交互动作需要一个像素级的掩模来表示感兴趣的对象。最后,代理预测一个停止动作以结束这一轮。我们将隐藏状态 \(h_t\) 与输入特征 \(u_t\) 连接,并训练两个独立的网络来预测下一个动作和交互掩模 \(m_t\) :
\(a_t = \arg\max (W_a [h_t; u_t])\) , \(m_t = \sigma (\text{deconv} [h_t; u_t])\)
其中 \(W_a\) 是全连接层的可学习参数, \(\text{deconv}\) 是三层反卷积网络, \(\sigma\) 是Sigmoid激活函数。动作选择使用softmax交叉熵与专家动作进行训练。交互掩模基于对象的真值分割,通过二进制交叉熵损失以监督方式端到端学习。为了应对这些密集掩模中的稀疏性问题,即目标对象可能仅占据视觉帧的一小部分,掩模损失被重新平衡。
实验
我们在AI2-THOR模拟器中评估基线模型。当在测试集上评估时,我们运行具有最低验证损失的模型。如果某个剧集超过1000步或导致超过10次失败的动作,则终止该剧集。失败的动作通常源于撞到墙壁或对不兼容的对象预测交互掩码,例如尝试拾起一个台面。这些限制鼓励效率和可靠性。我们评估模型在各个剧集中的任务执行的整体和部分成功情况。
评估指标
ALFRED使我们能够评估任务的完整性和任务目标条件的完成情况。在仅涉及导航的任务中,只能测量代理与目标的距离。而在ALFRED中,我们还可以评估任务目标条件是否已完成,例如土豆是否已经被切成片。在所有实验中,我们报告任务成功率和目标条件成功率。每个目标条件都依赖于多个指令,例如导航到一个对象然后切片。
任务成功率。每个专家演示都由要执行的任务参数化,如图2所示。任务成功率定义为:如果在行动序列结束时,对象位置和状态变化与任务目标条件相对应,则计为1,否则为0。考虑任务:“将热的土豆片放在台面上”。如果在剧集结束时,任何一个土豆片对象变为加热状态并放置在任何台面上,则认为代理成功完成任务。
目标条件成功率。模型的目标条件成功率为在剧集结束时完成的目标条件数与完成任务所需目标条件数的比值。例如,在前面的加热与放置示例中,有四个目标条件。第一,土豆必须被切片。第二,土豆片应被加热。第三,土豆片应放置在台面上。第四,加热的土豆片必须放置在台面上。如果代理切了土豆,然后将切片移动到台面上但没有加热,则目标条件成功率为2/4 = 50%。在ALFRED中,任务平均有2.55个目标条件。最终得分是每个剧集的目标条件成功率的平均值。任务成功率为1仅当目标条件成功率为1时。
路径加权指标。我们对两种指标都包含路径加权版本,该版本考虑了专家演示的长度[2]。通过PDDL求解器在全局信息上找到的专家演示不能保证是最优的。然而,它们避免了探索,使用最短路径导航,且通常效率较高。指标 \(s\) 的路径加权分数 \(ps\) 定义为:
其中, \(\hat{L}\) 是模型在情景中采取的动作数, \(L^*\) 是专家演示中的动作数。直观上,如果模型完成任务所需的时间是专家的两倍,它将获得一半的分数。
子目标评估
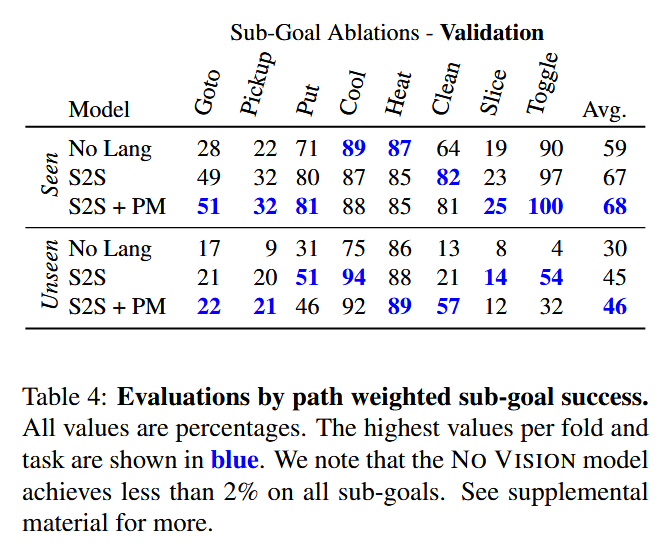
完成一系列动作以实现任务目标是具有挑战性的。除了评估整个任务的成功度外,我们还研究了模型在给定先前专家序列的情况下完成下一个子目标的能力。测试方法是首先强制代理遵循专家演示,以保持通向子目标的状态历史,然后要求代理在完整的语言指令和当前视觉观察的条件下完成子目标。例如,在任务“将一块热土豆片放在柜台上”中,我们可以在使用专家演示导航到并拿起刀子后,评估导航到土豆的子目标。ALFRED 中的任务平均包含 7.5 个这样的子目标(见表 4)。
分析
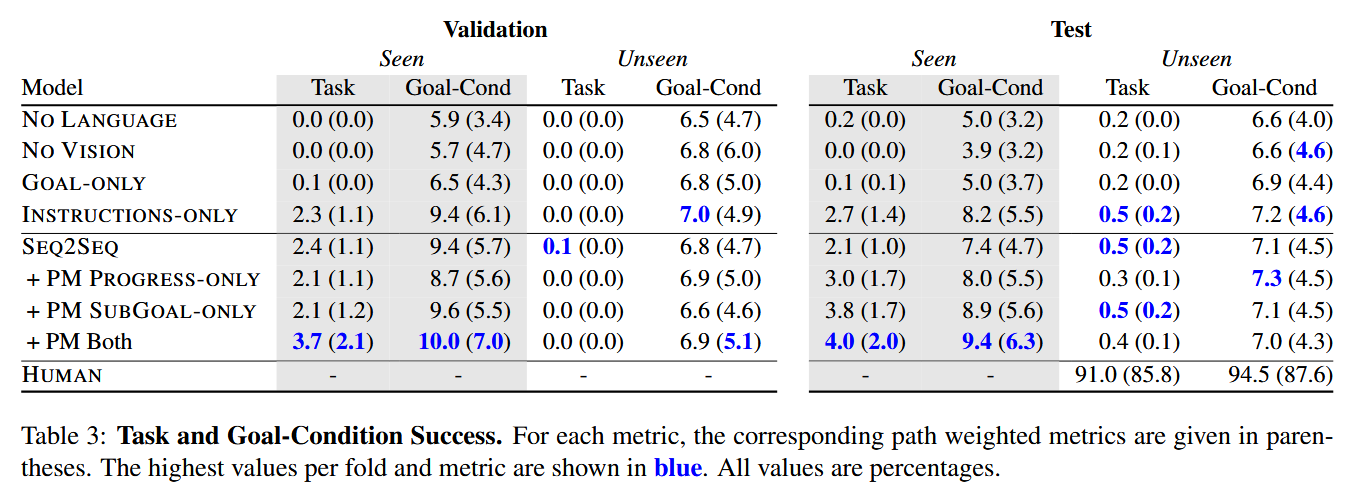
实验结果见表 3。我们发现,初始模型在没有空间或语义地图、对象分割或显式对象状态跟踪的情况下,在 ALFRED 的长时间跨度、高维状态空间任务中表现不佳。SEQ2SEQ 模型实现了约 8% 的目标条件成功率,表明代理确实学会了部分完成某些任务。这种差距(与人类相比)激发了对能够执行 ALFRED 引入的复杂视觉和语言规划的模型的进一步研究。与之形成鲜明对比的是,在其他专注于导航的视觉和语言数据集中,带有进度监控的序列到序列模型表现良好 [28]。
随机代理
随机代理通常作为视觉和语言任务中的基线。在 ALFRED 中,一个在每个时间步选择均匀随机动作并生成均匀随机交互掩模的代理在所有折叠上均实现 0% 的成功率,即使没有 API 失败限制。
单模态消融
先前的工作表明,没有视觉输入、语言输入或两者的代理比随机代理表现更好,且在几个导航和问答任务中与初始基线具有竞争力 [50]。这种性能差距是由于数据集中的结构偏差或模型容量问题。我们评估了这些消融基线(无语言和无视觉),以研究视觉和语言偏差在 ALFRED 中的影响。表 3 中的单模态消融性能表明,视觉和语言模态对于完成 ALFRED 中的任务都是必要的。无语言模型通过与训练期间见过的熟悉对象互动,完成了一些目标条件。无视觉模型通过遵循低级语言导航指令并记忆常见对象(如微波炉)在视觉帧中的交互掩模,同样完成了一些目标条件。
模型消融
我们还消融了模型可用的语言监督量,因为语言指令既作为高层次目标又作为逐步指导提供。仅提供高层次、不明确的目标语言(仅目标)不足以完成任务,但足以完成一些目标条件。仅使用低层次、逐步指导(仅指令)与同时使用高、低层次指导的性能相似。因此,这个简单的模型似乎没有利用目标指令来规划逐步执行的子目标。两种进度监控信号略有帮助,将成功率从约 1% 提高到约 2%。进度监控使任务完成更加高效,如持续更高的路径加权得分所示。它们可能有助于避免重复动作并预测停止动作。在所有情况下,代理采取的步骤都比专家多,这由较低的路径加权得分显示。有时,这是由于未能跟踪状态变化,例如多次在微波炉中加热鸡蛋。此外,模型在未见过的场景中泛化能力也较差,这是由于 ALFRED 中新的场景和新颖的对象类别实例带来的整体视觉复杂性。
人为评估
我们对来自未见过的测试集的100个随机抽样的指令进行了人为评估。实验涉及5名参与者,每名参与者使用键盘和鼠标的界面完成了20个任务。在实验之前,参与者被允许熟悉AI2-THOR。实验的动作空间和任务限制与基线模型相同。总体而言,参与者获得了91%的高成功率,而路径长度加权的成功率略低于专家的86%。这表明ALFRED中的指令与演示很好地对齐。
子目标性能
我们还评估了SEQ2SEQ模型在ALFRED中单个子目标上的性能。在这个实验中,我们使用专家轨迹将代理移动到子任务之前的状态。然后,代理根据语言指令和当前的视觉帧开始推理。表4展示了8个子目标的路径长度加权成功率。在已见过的环境中,使用SEQ2SEQ+PM模型的Goto和Pickup子任务分别达到了约51%和约32%的成功率。在未见过的环境中,视觉语义导航更为困难。同样,由于不熟悉的场景和对象实例,未见过的环境中Pickup动作的交互掩码较差。对于像Cool和Heat这样的简单子目标,成功率达到约90%,因为这些任务大多与对象无关。例如,无论手中的对象是什么,代理都会熟悉使用微波炉进行加热,因为厨房中微波炉的视觉多样性较小。总体而言,子目标评估表明,利用模块性和层次结构,或使用预训练的对象分割模型的模型可能在完整任务序列上取得进展。
结论
我们介绍了ALFRED,这是一种将自然语言指令和第一人称视觉映射到一系列动作的学习基准。ALFRED使我们更接近于社区目标,即开发能够导航和互动的受语言驱动的机器人。ALFRED所需的环境动态和交互掩码预测缩小了模拟环境中智能体与现实世界中运作的机器人之间的差距[37]。我们使用ALFRED评估了一种带有进度监控的序列到序列模型,这种模型在其他视觉-语言导航任务中被证明是有效的[28]。虽然该模型在完成某些子目标方面表现出了一定的竞争力(例如,在Heat & Place任务中,操作微波炉的方式相似),但总体任务的成功率较低。ALFRED任务的长期视角带来了显著的挑战,包括视觉语义导航、物体检测、指代表达定位和动作定位等子问题。这些挑战可能可以通过利用层次结构[8, 27]、模块化[4, 16]和结构化推理与规划[6]的模型来解决。我们对ALFRED基准带来的可能性和挑战感到鼓舞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号