
性能分析--上下文切换(context switch)
定义:
context switch:每秒上下文切换的次数
什么是CPU上下文:
我们都知道,Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
根据任务的不同,CPU的上下文切换可以分为不同的场景:
- 进程上下文切换
- 线程上下文切换(这个是我们性能测试时关注的点)
- 中断上下文切换
为什么要关注进程的上下文切换:
进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是“免费”的,需要内核在 CPU 上运行才能完成:

每次上下文切换都需要几十纳秒到数微秒的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也正是,导致平均负载升高的一个重要因素。
另外,我们知道, Linux 通过 TLB(Translation Lookaside Buffer)来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
知道了进程上下文切换潜在的性能问题后,我们再来看,究竟什么时候会切换进程上下文:
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux 为每个 CPU 都维护了一个就绪队列,将活跃进程(即正在运行和正在等待 CPU 的进程)按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。
进程在什么时候才会被调度到 CPU 上运行呢?
- 最容易想到的一个时机,就是进程执行完终止了,它之前使用的 CPU 会释放出来,这个时候再从就绪队列里,拿一个新的进程过来运行
- 为了保证所有进程可以公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序
如果出现(cs)性能问题那么主要从最后五个方面排查
大体上分为两方面:
- cpu 不足
- 进程或线程自己需要切换
针对cpu不足有两种情况;
1.1、本进程消耗 --解决自身问题
1.2、其他进程消耗 --解决别人那问题
针对进程或线程自己需要切换:
分析自己进程或线程的问题
实例分析:
一、cpu不足
1.1情况模拟:
使用top命令查看
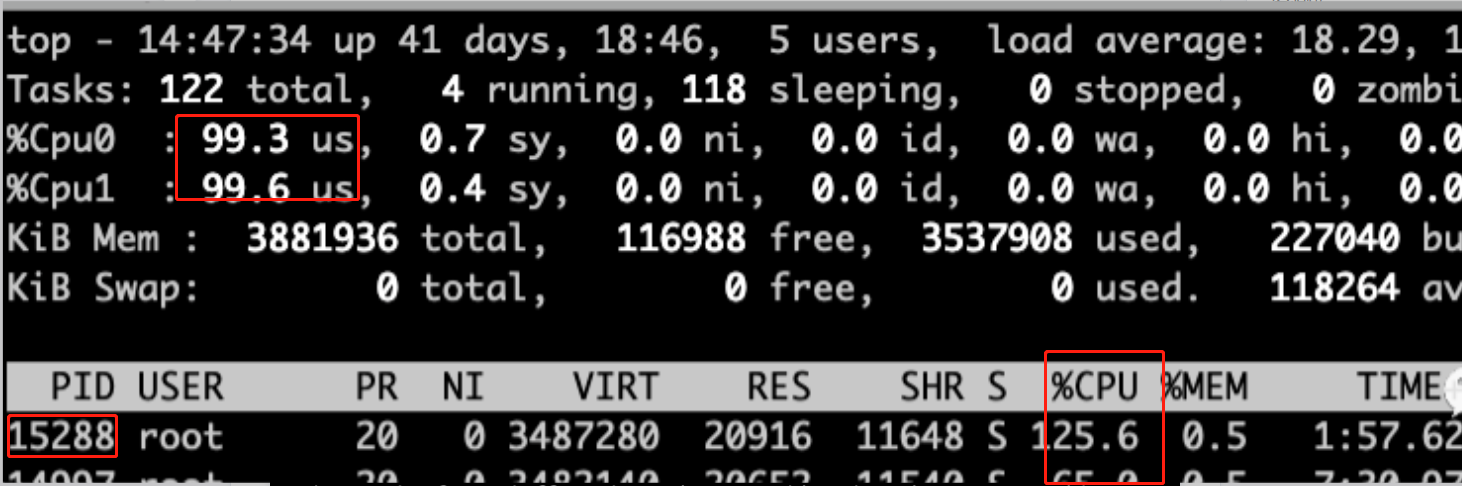
看到CPU被消耗光了,确实也都在用户空间us cpu 使用vmstat 查看(CPU空闲时也差不多有2000多的切换)
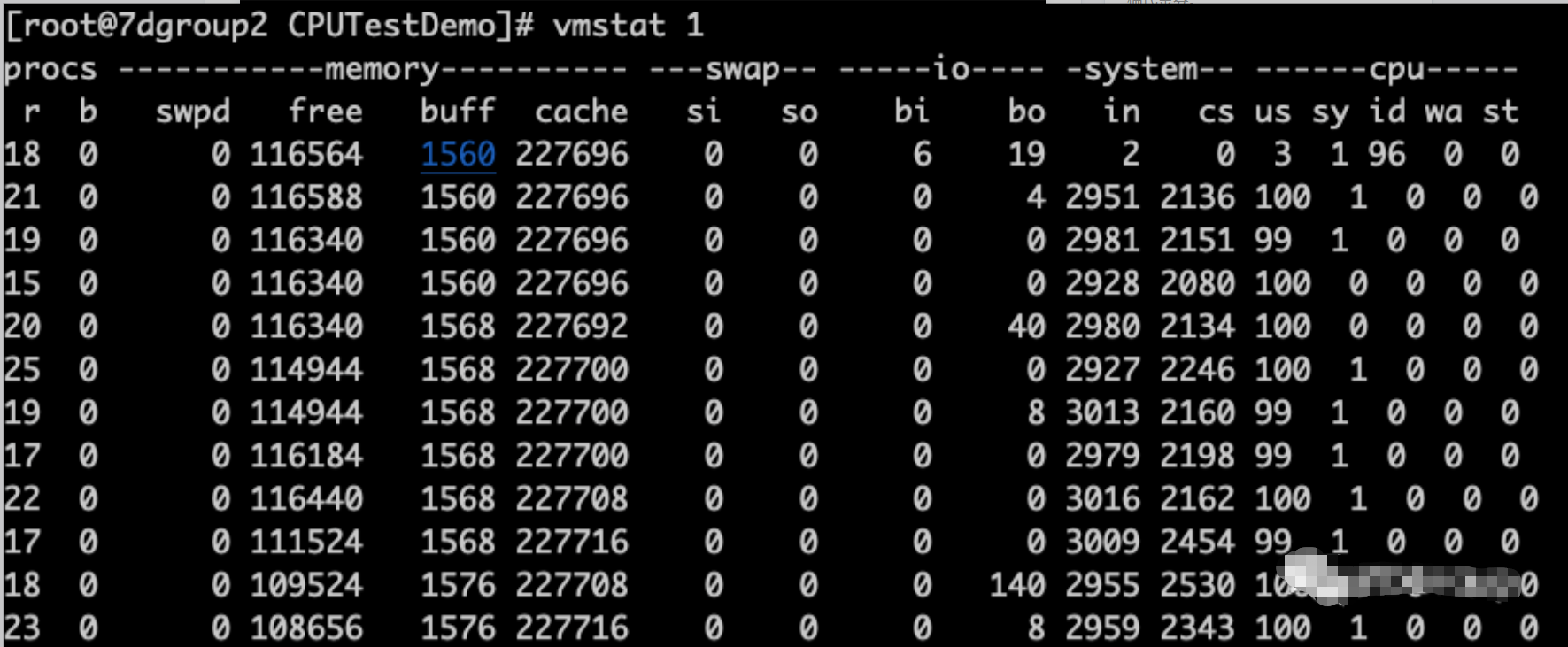
从vmstat上来看,并看不到多大的CS。但是已经可以看到CPU队列高、CPU使用率高了
使用命令pidstat -w -t -p 15288 查看
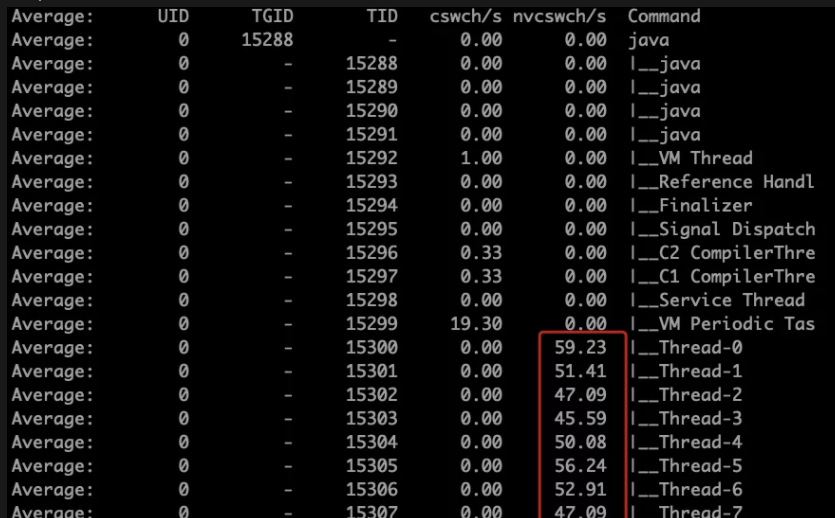
从上图可以看到nvcswch/s已经有值了,我这里是每秒刷新一次。也就是说每个线程大概每秒被动切换了50多次。
你有没有觉得,这个值看起来似乎并不大是不是?并且在vmstat中也没看到多高的CS切换呀,因为在CPU空闲时也差不多有2000多的切换呀。(在我这个环境中是这样的数值,在其他环境中,这个值会有变化。)
为什么会出现这种情况呢。因为现在CPU都被15288抢占,本来操作系统正常的CS都抢不到CPU了,只被15288里面的几个进程消耗掉了。那正常的CS就连CPU都抢不到,当然CS也就减少了,这时整个系统其实是处在瘫痪的状态的。
1.2情况模拟:
cpu 被其他进程消耗,导致本进程被动切换
使用top命令查看
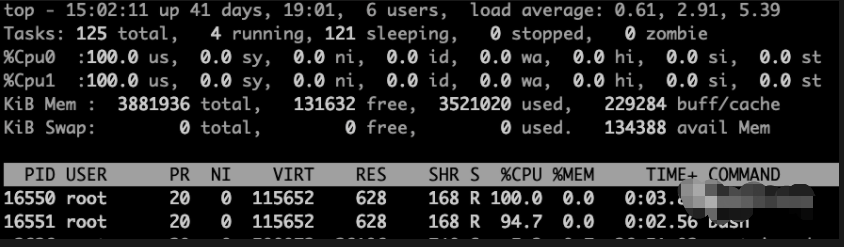
消耗cpu的进程有两个16550 16551
然后启动我们自己的模拟进程
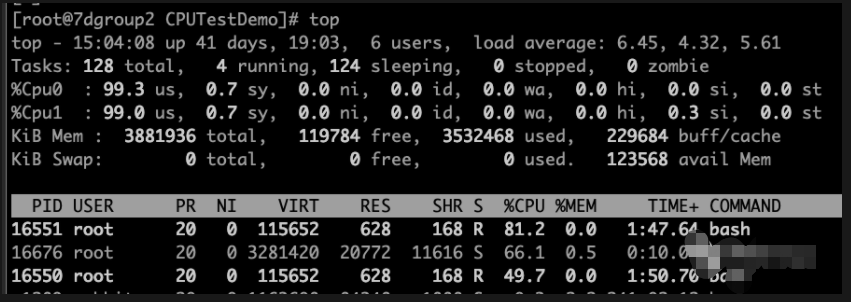
查看模拟进程的上下文切换情况:
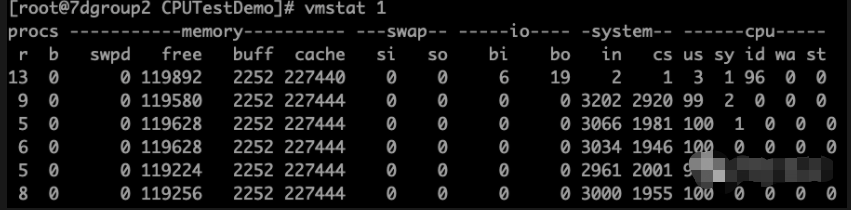
从命令看来cs比平时低很多
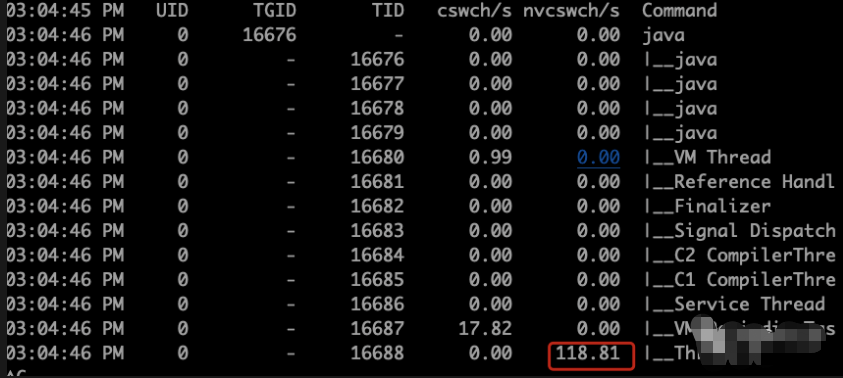
看到切换了,并且切换的意愿不是很强烈。被动切换
那么现在杀掉其他两个进程 再来查看切换
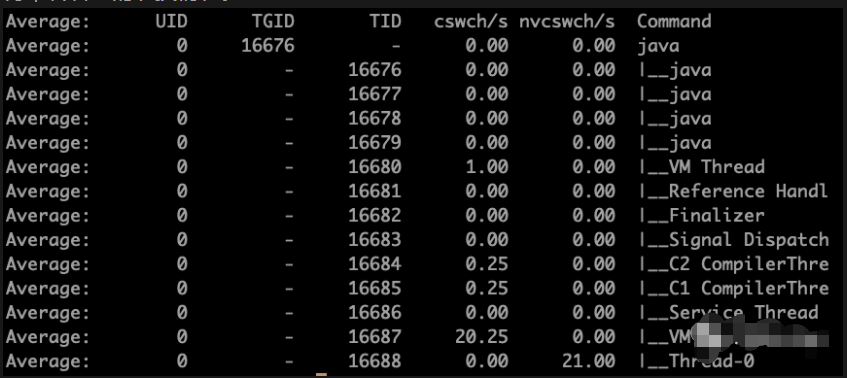
是不是少了很多
二、进程或线程自己需要切换
自动切换和服务代码有关
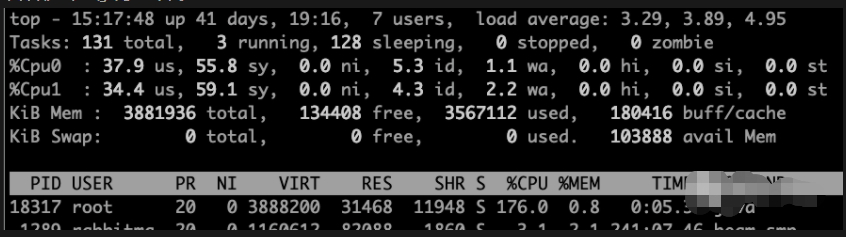
这里启动了400个线程来达到预期结果。 这里可以看到sy cpu 过高 是因为模拟代码中仅仅是sleep 如果失败业务代码的话就是us cpu 了
这里来看一下上下文切换情况:
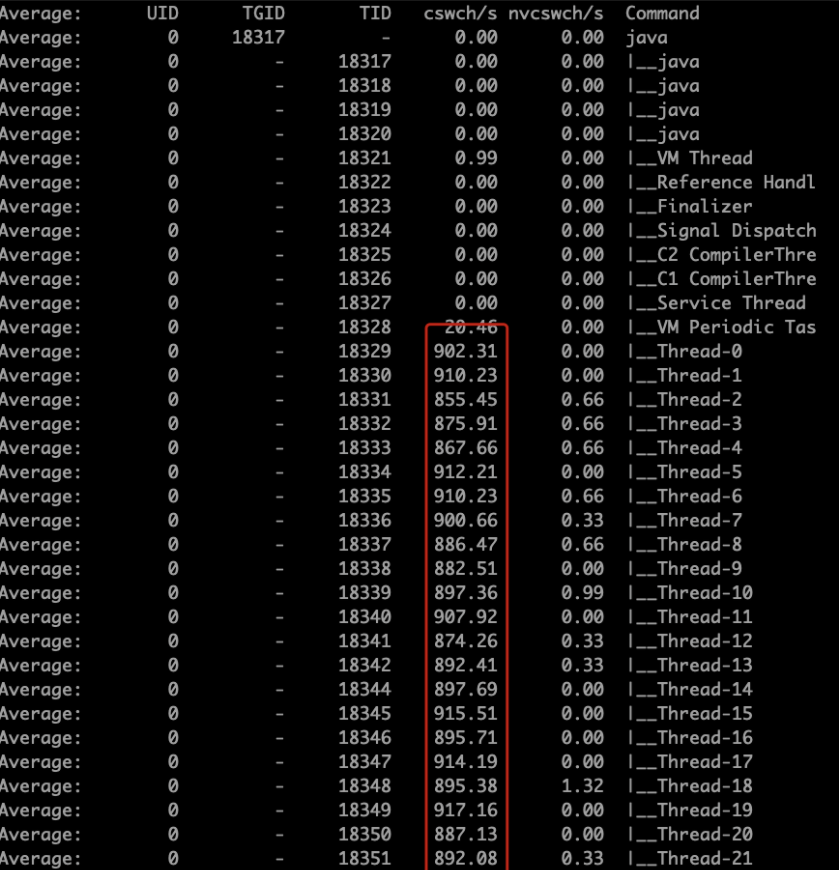
这种情况是资源切换上下文的情况。
1 /* 2 * context_switch - switch to the new MM and the new thread's register state. 3 */ 4 static __always_inline struct rq * 5 context_switch(struct rq *rq, struct task_struct *prev, 6 struct task_struct *next, struct rq_flags *rf) 7 { 8 prepare_task_switch(rq, prev, next); 9 10 /* 11 * For paravirt, this is coupled with an exit in switch_to to 12 * combine the page table reload and the switch backend into 13 * one hypercall. 14 */ 15 arch_start_context_switch(prev); 16 17 /* 18 * kernel -> kernel lazy + transfer active 19 * user -> kernel lazy + mmgrab() active 20 * 21 * kernel -> user switch + mmdrop() active 22 * user -> user switch 23 */ 24 if (!next->mm) { // to kernel 25 enter_lazy_tlb(prev->active_mm, next); 26 27 next->active_mm = prev->active_mm; 28 if (prev->mm) // from user 29 mmgrab(prev->active_mm); 30 else 31 prev->active_mm = NULL; 32 } else { // to user 33 membarrier_switch_mm(rq, prev->active_mm, next->mm); 34 /* 35 * sys_membarrier() requires an smp_mb() between setting 36 * rq->curr / membarrier_switch_mm() and returning to userspace. 37 * 38 * The below provides this either through switch_mm(), or in 39 * case 'prev->active_mm == next->mm' through 40 * finish_task_switch()'s mmdrop(). 41 */ 42 switch_mm_irqs_off(prev->active_mm, next->mm, next); 43 44 if (!prev->mm) { // from kernel 45 /* will mmdrop() in finish_task_switch(). */ 46 rq->prev_mm = prev->active_mm; 47 prev->active_mm = NULL; 48 } 49 } 50 51 rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); 52 53 prepare_lock_switch(rq, next, rf); 54 55 /* Here we just switch the register state and the stack. */ 56 switch_to(prev, next, prev); 57 barrier(); 58 59 return finish_task_switch(prev); 60 }
这里是切换上下文源码。
- context_switch :切换上下文的方法(下面是切换上下文的三个参数)
- rq :指向切换上下文发生cpu的运行队列
- prev:被切进程
- next:切向进程

文章摘抄自:性能分析之自愿和非自愿上下文切换 ( )
深入理解CPU上下文切换(知乎 https://zhuanlan.zhihu.com/p/99923968)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号