
Mysql - 查询之关联查询
查询这块是重中之重, 关系到系统反应时间. 项目做到后期, 都是要做性能测试和性能优化的, 优化的时候, 数据库这块是一个大头.
sql格式: select 列名/* from 表名 where 条件 group by 列 having 条件 order by 列 asc/desc;
这里牵涉到一个查询执行顺序的问题.
单表查询执行顺序:
select sex, count(Sex) as count from tch_teacher where id > 15 group by Sex having count > 5 order by Sex asc limit 1;
1-> from 表 : 首先拿到表tch_teacher
2-> where 条件 : 根据where后面的条件筛选一遍数据集合A
3-> group by 分组 : 对筛选出的数据A, 根据group by后面的列进行分组, 得到数据集B
4-> having 筛选 : 对数据集B进行进一步筛选, 得到数据集C
5-> select 数据 : 这里有四步
第一步 : 根据select后面的列名, 去数据集C中取数据. 得到数据集D
第二步 : 对数据集D中的数据进行去重操作(这一步是建立在 sql中有distinct 情况下), 得到数据集E
第三步 : 对数据集E进行排序操作, 得到数据集F
第四步 : 对数据集F进行截取数据操作, 得到最终的数据集(执行 limit 10 操作)
在多表的时候, 优化器在优化的时候, 会有些区别, 有些地方, 会用到where条件, 然后才连表
一、连表查询
1. 交叉连接 -- 笛卡尔乘积 cross join
select * from tch_teacher cross join tch_contact
这种连接方式, 没见人用过. 如果tch_teacher,tch_contact表各有10条数据, 那么连接的结果, 就是 10 x 10 = 100 条数据.
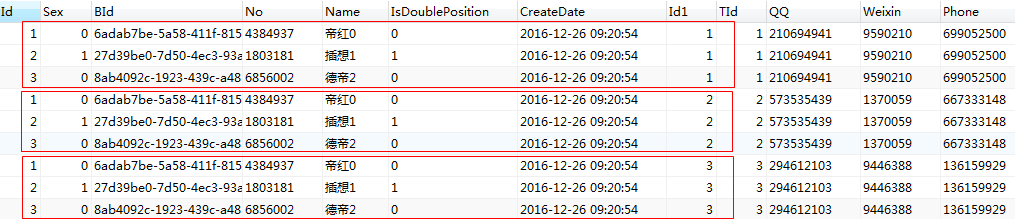
在mysql 中, cross join 后面是可以跟 on 和 where 的, 加上之后, 其实跟 inner join 是一样的
2. 内连接 -- inner join
内连接在不加on的情况下, 也是去求笛卡尔乘积. 不加on的用法并不推荐使用, 容易造成内存溢出的情况. 加on的时候, 在连表的时候, 就会对数据进行筛选, 以此来缩减有效数据范围
select * from tch_teacher inner join tch_contact
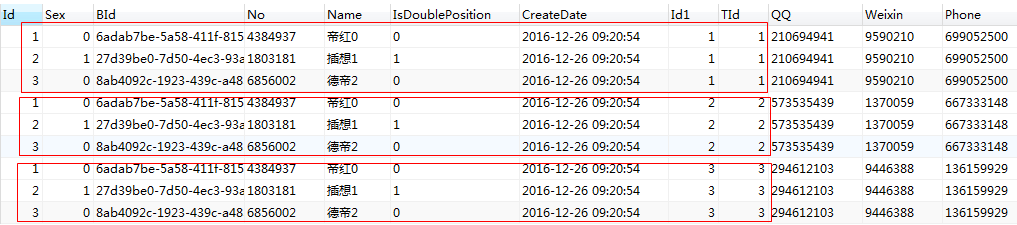
从上面的sql和图片来看, inner join 的时候, 可以不加on, 也能得到一个结果, 而且这个结果和交叉连接的结果是一样的.
这里还有另外两种写法:
select * from tch_teacher,tch_contact select * from tch_teacher join tch_contact
得到的结果是一样的.
3. 外连接 -- left/right join on
这里我特意加了一个on在上面, 因为不加on是会报错的.
left join 称之为左连接, 连接以左侧表数据为准, 当右表没有数据与之匹配的时候, 则会用null填补
right join 称之为右连接, 与 left join 相反, 这个是以右表为准
先看下效果吧
select * from tch_teacher left join tch_contact on tch_teacher.Id = tch_contact.TId;

select * from tch_teacher right join tch_contact on tch_teacher.Id = tch_contact.TId;

其实这里还有一个full join , 不过mysql里面的full join, 着实有些让人无语, 反正我没这么用过, 略过不表了.
这里我做了一个小测试, 这里的数据, tch_contact的tid值, 我取的是0~100000之间的随机数
select * from tch_teacher inner join tch_contact on tch_teacher.Id = tch_contact.TId ; select * from tch_teacher LEFT join tch_contact on tch_teacher.Id = tch_contact.TId ;
| tch_teacher | tch_contact | inner join(s) | 结果 | left join(s) | 结果 |
| 十万 | 十万 | 0.499 | 99999 | 0.526 | 137017 |
| 十万+5000 | 十万 | 0.345 | 99999 | 0.565 | 142017 |
| 十万-5000 | 十万 | 0.472 | 94949 | 0.534 | 130124 |
这里面的值, 是我反复运行之后, 在一些离散值里面, 取得比较靠近中心点的值.
4. 自己连自己
mysql里面, 有一个比较好用的功能, 就是自己连自己. 我再tch_teacher表里面加入一列, CreateBy, 存放的是这个表的Id值
select a.*, b.Name as CreateByName from tch_teacher a left join tch_teacher b on a.createby = b.id
能得到以下结果:

二、union查询
除了把几个表通过内部关系拼成一个表结果, 还可以, 把多个表的查询表结果拼成一个表结果. 所使用的方法就是union.
这里要注意的是, 列的顺序. 如果害怕列的顺序不一致不好排查, 可以把表结果的列名都重命名为相同的.
select Id, Sex, BId, `No`, Name, CreateDate from tch_teacher union select 0 as Id, Sex, BId, `No`, Name, CreateDate from tch_teacher_temp
union是会对最后的表结果进行去重操作的, 如果我不想去重, 只想快速得到拼接的结果, 可以使用 union all 来拼接.
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号