python---正则表达式
1.什么是正则表达式?
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
2. 常见语法
a. 直接匹配汉字或者字母
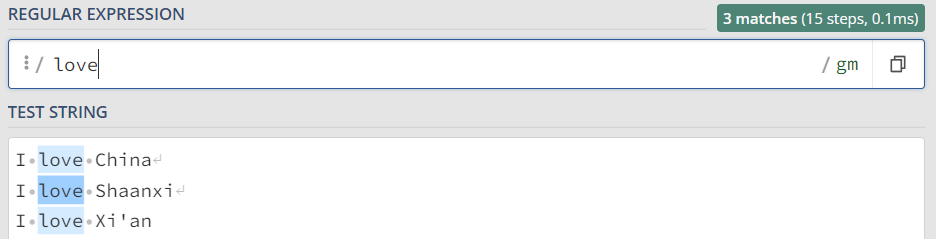
python代码如下所示:
import re content = ''' I love China I love Shaanxi I love Xi'an ''' p = re.compile(r'love') for one in p.findall(content): print(one)
b. 点匹配所有字符
. 表示要匹配所有除换行字符以外的所有单个字符
提取下边文字里所有的颜色
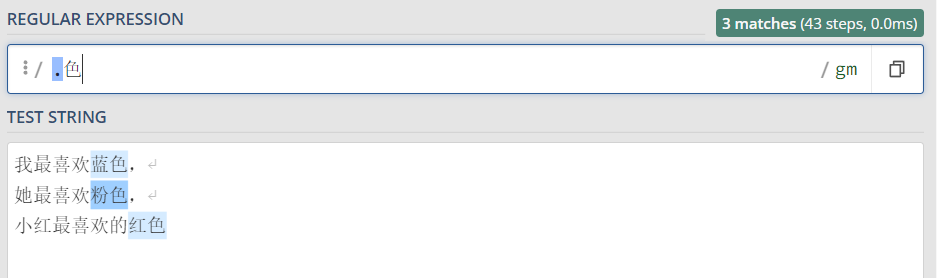
python代码:
import re content = ''' 我最喜欢蓝色, 她最喜欢粉色, 小红最喜欢红色 ''' p = re.compile(r'.色') for one in p.findall(content): print(one) 运行结果: 蓝色 粉色 红色
c. 星重复匹配任一次
* 表示匹配前面的子表达式任意次,包括0次。
提取冒号后边的所有字符
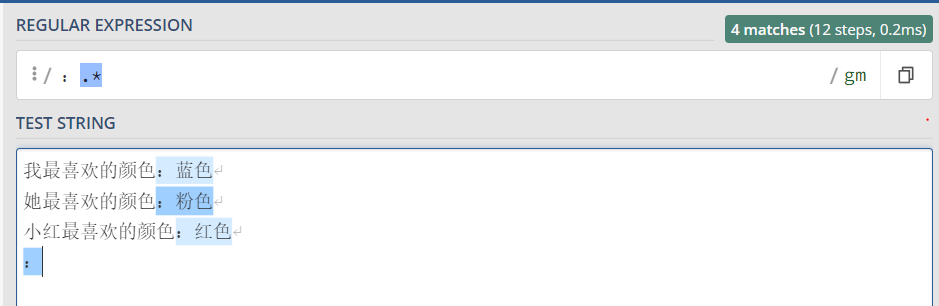
特别是最后一行,冒号后面没有其它字符了,但是*表示可以匹配0次, 所以表达式也是成立的。
python代码如下:
import re content = ''' 我最喜欢的颜色:蓝色 她最喜欢的颜色:粉色 小红最喜欢的颜色:红色 : ''' p = re.compile(r':.*') for one in p.findall(content): print(one)
运行结果:
:蓝色
:粉色
:红色
:
注意, .* 在正则表达式中非常常见,表示匹配任意字符任意次数。
当然这个 * 前面不是非得是 点 ,也可以是其它字符
d. 加号重复匹配多次
+ 表示匹配前面的子表达式一次或多次,不包括0次。
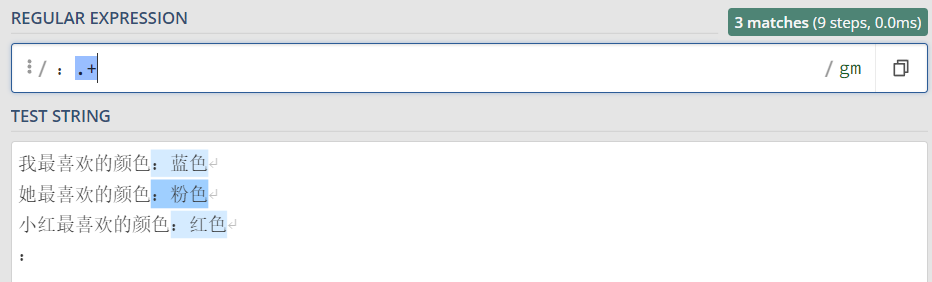
最后一行,冒号后面没有其它字符了,+表示至少匹配1次, 所以最后一行没有子串选中。
import re content = ''' 我最喜欢的颜色:蓝色 她最喜欢的颜色:粉色 小红最喜欢的颜色:红色 : ''' p = re.compile(r':.*') for one in p.findall(content): print(one) 运行结果: :蓝色 :粉色 :红色
e. 问号匹配0-1次
? 表示匹配前面的子表达式0次或1次。
从文本中,选择每行冒号后面的1个字符,也包括逗号本身。
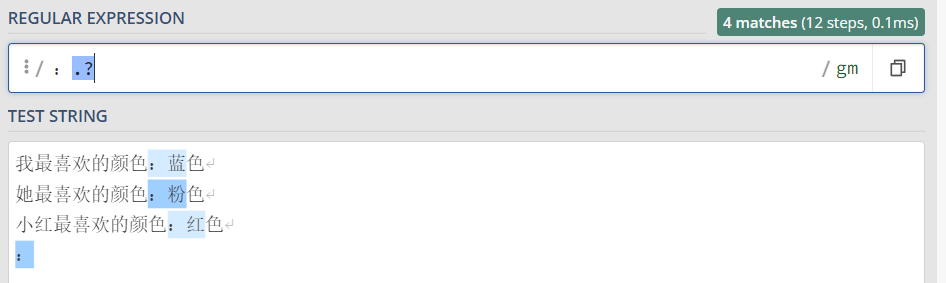
最后一行,冒号后面没有其它字符了,但是?表示匹配1次或0次, 所以最后一行也选中了一个冒号字符。
python代码:
import re content = ''' 我最喜欢的颜色:蓝色 她最喜欢的颜色:粉色 小红最喜欢的颜色:红色 : ''' p = re.compile(r':.?') for one in p.findall(content): print(one) 运行结果: :蓝 :粉 :红 :
f.花括号匹配指定次数
花括号表示 前面的字符匹配指定的次数。
\d{3}: 表示匹配连续的数字3次
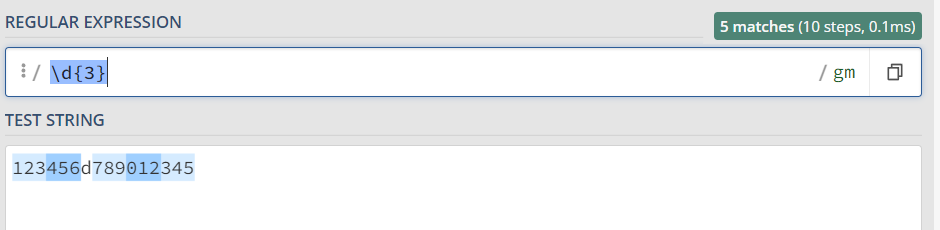
python代码如下:
import re content = ''' 123456d789012345 ''' p = re.compile(r'\d{3}') for one in p.findall(content): print(one)
运行结果:
123
456
789
012
345
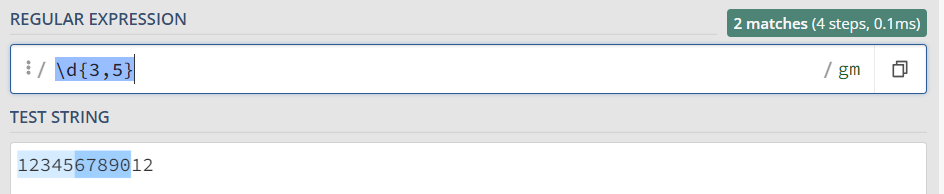
\d{3,5} 表示匹配连续的数字至少3次,至多5次
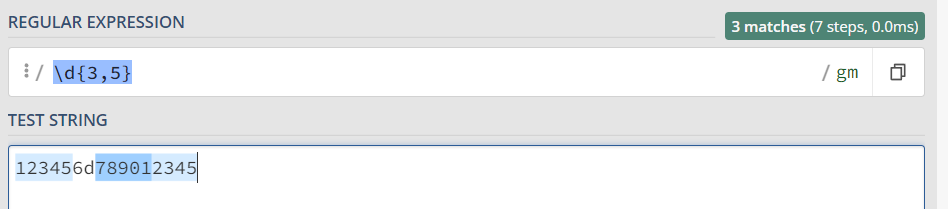
python代码:
import re content = ''' 123456d789012345 ''' p = re.compile(r'\d{3,5}') for one in p.findall(content): print(one) 运行结果: 12345 78901 2345
g.贪婪模式和非贪婪模式
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。属于贪婪模式的量词,也叫做匹配优先量词,包括:
“{m,n}”、“{m,}”、“?”、“*”和“+”。
在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括:
“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
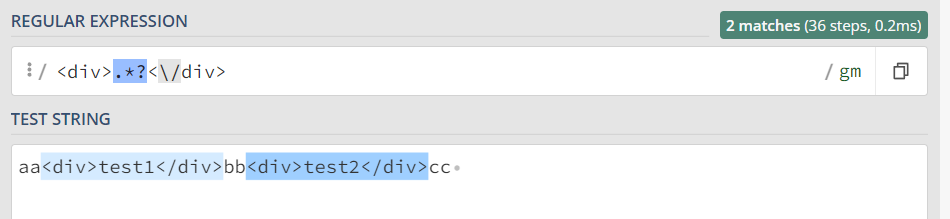
贪婪模式:

非贪婪模式

h. 匹配某种字符类型
反斜杠后面接一些字符,表示匹配 某种类型 的一个字符。
\d 匹配0-9之间任意一个数字字符,等价于表达式 [0-9]
\D 匹配任意一个不是0-9之间的数字字符,等价于表达式 [^0-9]
\s 匹配任意一个空白字符,包括 空格、tab、换行符等,等价于表达式 [\t\n\r\f\v]
\S 匹配任意一个非空白字符,等价于表达式 [^ \t\n\r\f\v]
\w 匹配任意一个文字字符,包括大小写字母、数字、下划线,等价于表达式 [a-zA-Z0-9_]
缺省情况也包括 Unicode文字字符,如果指定 ASCII 码标记,则只包括ASCII字母
\W 匹配任意一个非文字字符,等价于表达式 [^a-zA-Z0-9_]
反斜杠也可以用在方括号里面,比如 [\s,.] 表示匹配 : 任何空白字符, 或者逗号,或者点
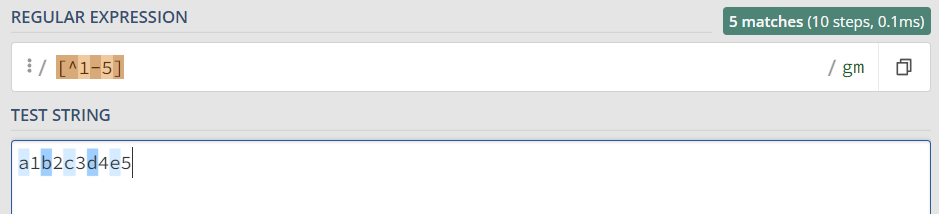
I. 方括号-匹配几个字符之一
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。
[a-c] 中间的 - 表示一个范围从a 到 c。
如果你想匹配所有的小写字母,可以使用 [a-z]

如果在方括号中使用 ^ , 表示 非 方括号里面的字符集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号