


K8S部署BOBAI 服务(Nvidia版)
目录
一、GPU 节点部署 Driver && CUDA部署
1、前提准备
检查机器上面有支持CUDA的NVIDIA GPU
lspci | grep -i nvidia
查看自己的系统是否支持
验证系统是否有GCC编译环境
gcc -v
验证系统是否安装了正确的内核头文件和开发
sudo yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r)
2、开始安装
禁用nouveau
nouveau是一个第三方开源的Nvidia驱动,一般Linux安装的时候默认会安装这个驱动。 这个驱动会与Nvidia官方的驱动冲突,在安装Nvidia驱动和和CUDA之前应先禁用nouveau。
# 查看系统是否正在使用nouveau
lsmod | grep nouveau
# 如果显示内容,则禁用。以下是centos7的禁用方法
#新建一个配置文件
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
#写入以下内容
blacklist nouveau
options nouveau modeset=0
#保存并退出
:wq
#备份当前的镜像
sudo mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak
#建立新的镜像
sudo dracut /boot/initramfs-$(uname -r).img $(uname -r)
#重启
sudo reboot
#最后输入上面的命令验证
lsmod | grep nouveau
开始安装驱动NVIDIA Driver (也可跳过,直接去安装CUDA)
📌一定要确认NVIDIA Driver的版本适合自己的显卡
-
下载NVIDIA Driver
首先到 NVIDIA 驱动下载 下载对应的显卡驱动:
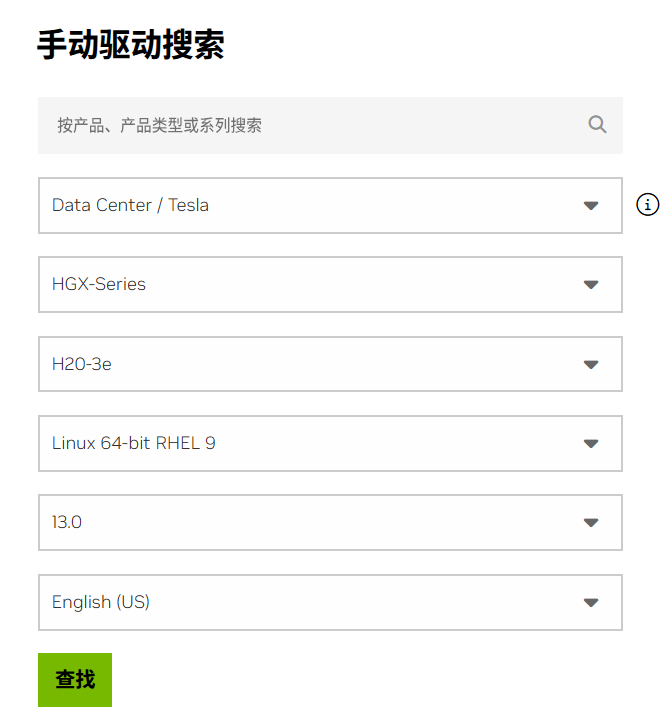
在下载前确认Driver是否支持自己的显卡

-
安装NVIDIA Driver
rpm -ivh nvidia-driver-local-repo-rhel9-580.82.07-1.0-1.x86_64.rpm -
验证驱动是否安装成功
# 执行如下命令 root@GPU1:~ nvidia-smi +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.161.08 Driver Version: 535.161.08 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla T4 On | 00000000:3B:00.0 Off | 0 | | N/A 51C P0 29W / 70W | 12233MiB / 15360MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ | 1 Tesla T4 On | 00000000:86:00.0 Off | 0 | | N/A 49C P0 30W / 70W | 6017MiB / 15360MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | +---------------------------------------------------------------------------------------到这里我们的GPU的驱动就安装好了,系统也可以正常的识别到GPU了。这里显示的CUDA Version指的是当前驱动最大支持的CUDA版本。
开始安装CUDA Toolkit
-
下载CUDA Toolkit
首先下载CUDA Toolkit
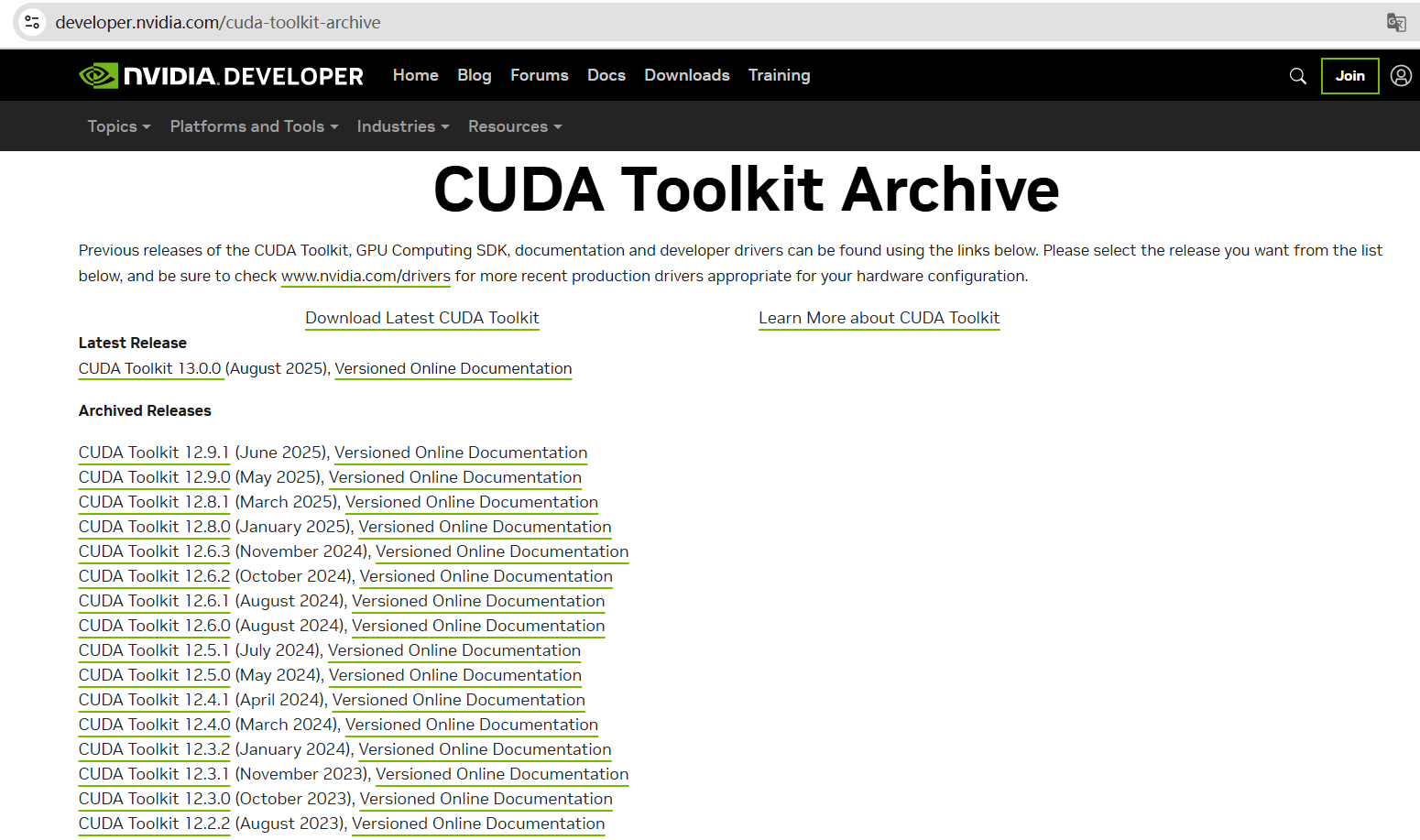
选择好自己的系统和版本

建议下载.run文件
-
安装CUDA Toolkit
wget https://developer.download.nvidia.com/compute/cuda/13.0.0/local_installers/cuda_13.0.0_580.65.06_linux.run sudo sh cuda_13.0.0_580.65.06_linux.run # 安装成功的日志示例 =========== = Summary = =========== Driver: Installed Toolkit: Installed in /usr/local/cuda-13.0/ Please make sure that - PATH includes /usr/local/cuda-13.0/bin - LD_LIBRARY_PATH includes /usr/local/cuda-13.0/lib64, or, add /usr/local/cuda-13.0/lib64 to /etc/ld.so.conf and run ldconfig as root To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-13.0/bin To uninstall the NVIDIA Driver, run nvidia-uninstall Logfile is /var/log/cuda-installer.log下载并安装即可,其实如果你没有安装NVIDIA Driver这一步会帮你安装好适合你的NVIDIA Driver,比如这个会安装580.65.06版本的Driver。
-
配置环境变量
vim /etc/profile.d/cuda.sh # 编辑一个新文件,内容如下: # 添加 CUDA 13.0 到 PATH export PATH=/usr/local/cuda-13.0/bin:$PATH # 添加 CUDA 13.0的 lib64 到 LD_LIBRARY_PATH export LD_LIBRARY_PATH=/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH保存,刷新配置文件
source /etc/profile.d/cuda.sh
检查是否部署成功 ```markdown # 如果输出版本号即为成功 (base) root@Colourdata-GPU:~# nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2025 NVIDIA Corporation Built on Fri_Feb_21_20:23:50_PST_2025 Cuda compilation tools, release 12.8, V12.8.93 Build cuda_12.8.r12.8/compiler.35583870_0
二、容器环境(Docker or Containerd)
1、安装 nvidia-container-toolkit
说明:
NVIDIA Container Toolkit 的主要作用是将 NVIDIA GPU 设备挂载到容器中。兼容docker、containerd、cri-o等。
With dnf: RHEL/CentOS, Fedora, Amazon Linux
# 配置生产存储库
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
# 安装NVIDIA Container Toolkit 软件包
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo dnf install -y \
nvidia-container-toolkit-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools-${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1-${NVIDIA_CONTAINER_TOOLKIT_VERSION}
2、配置Runtime 为NVIDIA
Docker
# 配置runtime=doker
sudo nvidia-ctk runtime configure --runtime=docker
# 建议在 /etc/docker/daemon.json 里面检查一下,并将默认runtime也修改为nvidia
(base) root@Colourdata-GPU:~# vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://ihsxva0f.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"storage-driver": "overlay2",
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
systemctl daemon-relod
systemctl restart docker
Containerd
# 配置runtime=containerd
sudo nvidia-ctk runtime configure --runtime=containerd
# 建议在 /etc/containerd/config.toml 里面检查一下,并将默认runtime也修改为nvidia
# 修改好后重启containerd
sudo systemctl restart containerd
以上部署完成,就可以配置K8S调用GPU了。
三、K8S调用GPU
说明:
device-plugin由NVIDIA提供,官网文档。
部署Plugin
-
建议先给GPU节点打上标签 gpu=true
-
部署服务
# 下载地址,建议选择新版本 https://github.com/NVIDIA/k8s-device-plugin/blob/main/deployments/static/nvidia-device-plugin.yml # 发布服务 root@test:~# kubectl apply -f nvidia-device-plugin.yml root@test:~# kubectl get po -l app=gpu -n bobai NAME READY STATUS RESTARTS AGE nvidia-device-plugin-daemonset-7nkjw 1/1 Running 0 10m -
检查服务是否部署成功
# 如果可以看到nvidia gpu说明服务已经部署成功了 root@test:~# kubectl describe node GPU | grep nvidia.com/gpu nvidia.com/gpu: 2
以上部署完成后,你的K8S集群就可以调用GPU了。
三、部署服务
1、部署Deekseek-v3
示例yaml文件如下,仅供参考
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-v3
namespace: bobai
spec:
replicas: 1
selector:
matchLabels:
app: deepseek-v3
template:
metadata:
labels:
app: deepseek-v3
spec:
containers:
- command:
- sh
- -c
- vllm serve --port 8000 --trust-remote-code --served-model-name deepseek-v3 --dtype=fp8 --max-model-len 65536 --gpu-memory-utilization 0.95 /models/DeepSeek-V3
name: deepseek-v3
image: registry.cn-shanghai.aliyuncs.com/colourdata/bobai-dependency:vllm
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000
volumeMounts:
- name: model-volume
mountPath: /models
resources:
requests:
nvidia.com/gpu: 8
memory: "16Gi"
cpu: "8"
limits:
nvidia.com/gpu: 8
memory: "32Gi"
cpu: "16"
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 300
periodSeconds: 10
failureThreshold: 3
readinessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 300
periodSeconds: 10
failureThreshold: 3
volumes:
- name: model-volume
hostPath:
path: /models
type: Directory
2、qwen-embedding模型部署
示例yaml文件如下,仅供参考
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-embedding
namespace: bobai
spec:
replicas: 1
selector:
matchLabels:
app: vllm-embedding
template:
metadata:
labels:
app: vllm-embedding
spec:
containers:
- command:
- sh
- -c
- vllm serve --port 8000 --trust-remote-code --served-model-name vllm-embedding --max-model-len 4096 --gpu-memory-utilization 0.85 /models/Qwen3-Embedding-0.6B
name: vllm-embedding
image: registry.cn-shanghai.aliyuncs.com/colourdata/bobai-dependency:vllm
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000
volumeMounts:
- name: model-volume
mountPath: /models
resources:
limits:
nvidia.com/gpu: 1
requests:
memory: "8Gi"
cpu: "4"
limits:
memory: "16Gi"
cpu: "8"
livenessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
readinessProbe:
tcpSocket:
port: 8000
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 3
volumes:
- name: model-volume
nfs:
server: 192.168.2.250
path: /data/bobai/models
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: vllm-embedding
namespace: bobai
spec:
type: ClusterIP
ports:
- port: 8000
protocol: TCP
targetPort: 8000
selector:
app: vllm-embedding
3、Tika部署
示例yaml文件如下,仅供参考
apiVersion: apps/v1
kind: Deployment
metadata:
name: tika
namespace: bobai
spec:
replicas: 1
selector:
matchLabels:
app: tika
template:
metadata:
labels:
app: tika
spec:
containers:
- name: tika
image: tika-ocr-cn:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9998
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1"
livenessProbe:
tcpSocket:
port: 9998
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
readinessProbe:
tcpSocket:
port: 9998
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 3
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: tika-service
namespace: bobai
spec:
type: ClusterIP
selector:
app: tika
ports:
- protocol: TCP
port: 9998
targetPort: 9998
4、部署ASR
示例yaml文件如下,仅供参考
apiVersion: apps/v1
kind: Deployment
metadata:
name: openai-edge-tts
namespace: bobai
spec:
replicas: 1
selector:
matchLabels:
app: openai-edge-tts
template:
metadata:
labels:
app: openai-edge-tts
spec:
containers:
- name: openai-edge-tts
image: travisvn/openai-edge-tts:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5050
env:
- name: API_KEY
value: "Colourdata1234@"
- name: PORT
value: "5050"
- name: DEFAULT_VOICE
value: "en-US-AvaNeural"
- name: DEFAULT_RESPONSE_FORMAT
value: "mp3"
- name: DEFAULT_SPEED
value: "1.0"
- name: DEFAULT_LANGUAGE
value: "en-US"
- name: REQUIRE_API_KEY
value: "True"
- name: REMOVE_FILTER
value: "False"
- name: EXPAND_API
value: "True"
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1"
livenessProbe:
tcpSocket:
port: 5050
initialDelaySeconds: 30
periodSeconds: 10
failureThreshold: 3
readinessProbe:
tcpSocket:
port: 5050
initialDelaySeconds: 10
periodSeconds: 5
failureThreshold: 3
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: openai-edge-tts-service
namespace: bobai
spec:
type: ClusterIP
selector:
app: openai-edge-tts
ports:
- protocol: TCP
port: 5050
targetPort: 5050

 浙公网安备 33010602011771号
浙公网安备 33010602011771号