操作系统发展史 & 进程
今日内容
- UDP协议
- 操作系统发展史
- 进程
- 单核情况下的进程调度
- 进程三状态图
- 同步异步
- 阻塞非阻塞
内容详细
一、UDP协议
1、什么是UDP协议
UDP是传输层的协议,功能即为在IP的数据报服务之上增加了最基本的服务:复用和分用以及差错检测。
UDP提供不可靠服务,具有TCP所没有的优势:
-
UDP无连接,时间上不存在建立连接需要的时延。
-
UDP没有拥塞控制,应用层能够更好的控制要发送的数据和发送时间,网络中的拥塞控制也不会影响主机的发送速率。
2、案例
import socket
udp_sk = socket.socket(type=socket.SOCK_DGRAM) # UDP协议
udp_sk.bind(('127.0.0.1',9000)) # 绑定地址
msg,addr = udp_sk.recvfrom(1024)
udp_sk.sendto(b'hi',addr)
udp_sk.close()
import socket
ip_port=('127.0.0.1',9000)
udp_sk=socket.socket(type=socket.SOCK_DGRAM)
udp_sk.sendto(b'hello',ip_port)
back_msg,addr=udp_sk.recvfrom(1024)
print(back_msg.decode('utf-8'),addr)
"""
时间服务器的实现原理
1.内部小电容供电
2.远程时间同步
"""
例子:简易qq程序
二、操作系统发展史
操作系统发展史就是围绕着提高CPU利用率发展的,每次技术的进步,CPU的利用率就大大提高
"""学习并发编程其实就是在学习操作系统的发展史(底层逻辑)"""
1、穿孔卡片时代
CPU利用率极低
使用计算机的人要拿着自己的程序(穿孔卡片)在门外等候,输入时间非常长,CPU利用时间就少
2、联机批处理系统
将多个程序员的程序一次性录入磁带中 之后交由输入机输入并由CPU执行
3、脱机批处理系统
现代计算机的雏形(远程输入 高速磁带 主机)
工作人员只需要买一台输入设备在家,就可以把程序传输到高速磁带中(内存),然后再用CPU执行
多道技术
前提是单核CPU
- 切换+保存状态
切换:CPU在执行进程代码时,如果遇到进行IO操作会立刻停止当前进程的执行,切换到其它进程的执行中去
保存状态:在切换之前,会保留当前进程的执行状态,以便切换回来时可以在断开处继续
'''
CPU工作机制:
1、当某个程序进入IO操作状态时,操作系统会强行剥夺该程序的CPU执行权限
2、当某个程序长时间占用CPU时,操作系统也会强行剥夺该程序的CPU执行权限
'''
并行与并发:
并行:多个程序同时运行(每个程序执行都需要一个CPU)
并发:多个程序只要看起来像是同时运行的就可以
# 问:单核CPU能否实现并行
肯定不能,但是可以实现并发
# 问:12306可以同一时间支持几个亿的用户买票 问是并行还是并发
肯定是并发(高并发)
星轨:微博能够支持八个星轨
三、进程
1、什么是进程
程序:实现功能的编程代码,存在硬盘中(是死的)
进程:运行中的应用程序,存在内存中(是活的)
2、单核情况下的进程调度
- FCFS 先来先服务
对短作业不友好
- 启动时间短先启动
对长作业不友好
- 时间片轮转法 + 多级反馈队列
1、先给所有要执行的进程分配相同的时间片(CPU执行时间)
2、然后根据每个进程消耗的时间片多少进行分级,需要执行时间长的进入下一级
3、优先执行第一级需要时间片少的进程
进程的三状态图
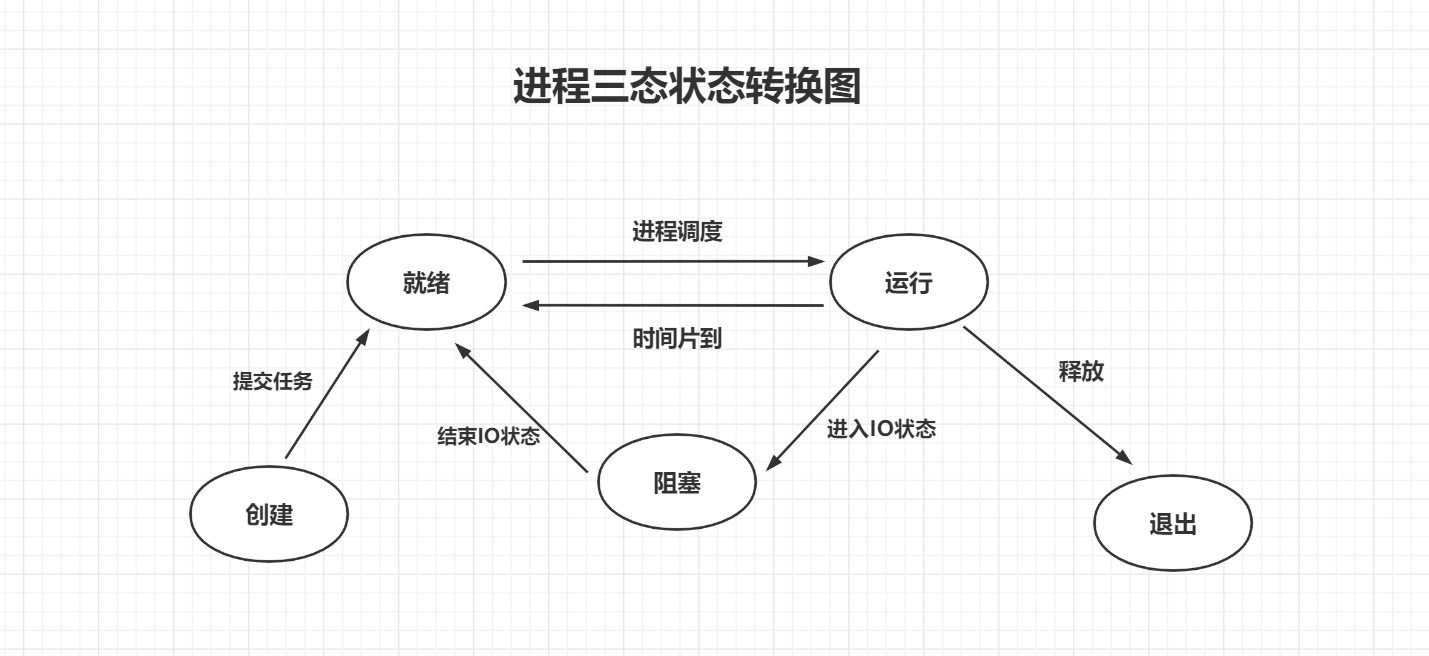
3、同步异步
同步
CPU 提交任务之后原地等待返回信息,再去执行其它任务
异步
提交任务之后不会等待,先去执行其它任务,接收到返回信息后再回来执行,有反馈机制
4、阻塞非阻塞
阻塞
阻塞态:IO操作、异常断开
非阻塞
就绪态与执行态
四、代码层面创建进程
1、创建进程两种方式
直接创建进程对象(主要的)
from multiprocessing import Process
import time
import os
def run(name):
print(os.getpid()) # 获取进程号
print(os.getppid()) # 获取父进程号
print('%s is running ' % name)
time.sleep(3)
print('%s is over' % name)
if __name__ == '__main__':
p = Process(target=run, arg=('elijah', )) # 生成一个进程对象
p.start() # 告诉操作系统要启动这个子进程,然后继续执行主进程 异步提交
print(os.getpid())
print('主进程')
'''
在windows中开设进程类似于导入模块
代码自上而下执行
一定要在__main__判断语句内执行开设进程的代码
否则,被导入模块也会执行开设进程的代码,这样会陷入死循环
'''
'''
在linux中是直接将代码完整地复制一份执行
不用在__main__判断语句中执行
'''
用类创建进程对象
class MyProcess(Process):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print('%s正在运行' % self.name)
time.sleep(3)
print('%s已经结束' % self.name)
if __name__ == '__main__':
p = MyProcess('jason')
p.start()
print('主')
2、进程的 join 方法
主进程开设子进程之后,等待子进程执行完成之后再往下执行
from multiprocessing import Process
import time
def run(name, n):
print('%s is running' % name)
time.sleep(n)
print('%s is over' % name)
if __name__ == '__main__':
start_time = time.time()
process_list = []
for i in range(1, 4):
p = Process(target=run, args=(i, i))
p.start()
process_list.append(p)
for p in process_list:
p.join()
print(time.time() - start_time)
print('主进程')
# 运行结果
1 is running
2 is running
3 is running
1 is over
2 is over
3 is over
3.309438943862915 # 执行时间
主进程
'''
当第一个 p.join() 执行时,只有主进程会在原地等待它执行结束
其它两个子进程并不受影响,会继续执行
所以总的时间是最长的那个子进程执行时间
'''
3、进程之间默认无法交互
主程序开设子程序,相当于再开辟了一块内存重新执行一遍代码(以被导入模块执行,__main__判断语句内的代码不会执行),那它执行修改数据操作不会影响到主进程的数据,因为进程之间默认无法进行交互
from multiprocessing import Process
money = 100
def test():
global money
money = 90
if __name__ == '__main__':
p = Process(target=test)
p.start()
p.join()
print(money)
# 执行结果
100
4、进程对象方法
1.current_process查看进程号
2.os.getpid() 查看进程号 os.getppid() 查看父进程进程号
3.进程的名字,p.name直接默认就有,也可以在实例化进程对象的时候通过关键字形式传入name=''
3.p.terminate() 杀死子进程
4.p.is_alive() 判断进程是否存活 3,4结合看不出结果,因为操作系统需要反应时间。主进程睡0.1即可看出效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号