为什么在AHK脚本中,“常衡”二字输出时变成了“甯歌”?
为什么在AHK脚本中,“常衡”二字输出时变成了“甯歌”?
我用的输入法是自己修改的柚子输入法,基于AutoHotkey v1的脚本编制的。最近为了新增一个自定义的编码,输入ozoz时自动跳出28.35常衡,表示一个常衡盎司是28.35克(同时也增加了一个once编码输出31.1035这个字串)。但发现一个有意思的现象,即我在脚本中写的是
case "once": SendInput 31.1035
case "ozoz": SendInput 28.35常衡
本来我以为当输入ozoz时,会自动跳出来28.35常衡,但实际上出来的是28.35甯歌,很是奇怪。
凭经验,我知道这个是因为字符编码没有按照我们想像的来,从而出现了差错,因为28.35是ASCII字符,各编码集都能支持,因而没有出错,但汉字在不同的编码集中编码不一样,套用错了就会出现问题。
首先,我用notepad4看了一个保存的脚本文件,它用的是UTF-8编码方式,这个目前最常用的编码方式,可以理解。再用UltraEdit打开这个文件,切换到HEX模式下观察存贮的字符,在28.35之后,存贮的常衡对应的HEX字符是 E5 B8 B8 E8 A1 A1,再之后是分号(3B)与空格(20)这些我认识的HEX字符。
将E5 B8 B8 E8 A1 A1分成两等分(UTF8编码方式下,汉字一般是3字节/字), 将E5 B8 B8手工按UTF-8的编码思路逆向解析一下,
E5 B8 B8 → 1110 0101 1011 1000 1011 1000 → 去掉首字节的1110,后两字节的字首的10(即粗体部分)得:0101 11 1000 11 1000→再从后向前整理成字节 0101 1110 0011 1000 →转成HEX值 5E38
类似的处理 E8 A1 A1如下
E8 A1 A1 →1110 1000 1010 0001 1010 0001 →1000 10 0001 10 0001 → 1000 1000 0110 0001 →8861
按UTF-8方式解析,原来的E5 B8 B8 E8 A1 A1是两个unicode字符0x5E38, 0x8861编码得来的,查Unicode Codecharts,这两个字就是 常 和 衡。也就是说,我输入的常衡二字,在脚本保存时按照UTF-8方式编码存贮为十六进制值是E5 B8 B8 E8 A1 A1,这里逻辑上是通的,逆向解析出来也正确。
那为什么E5 B8 B8 E8 A1 A1在输出时却变成了甯歌二字呢? 或者说,在什么编码体系下,这几个十六进制值会变成甯歌呢?
我之前研究过C++中,汉字字符串保存到文件时,(在简体中文的windows上)就是按照GBK码的编码保存为十六进值的,因此也怀疑这里也有这种可能。但手头没有GBK编码表,需要借助网上的码表转换工具。
通过bing搜索我找到了一个内码与字符转换的网站,https://www.23bei.com/tool/54.html
在码值的部分我输入E5 B8 看看选哪种方式会转换成字符甯? 结果一试就出来了,就是GBK内码。
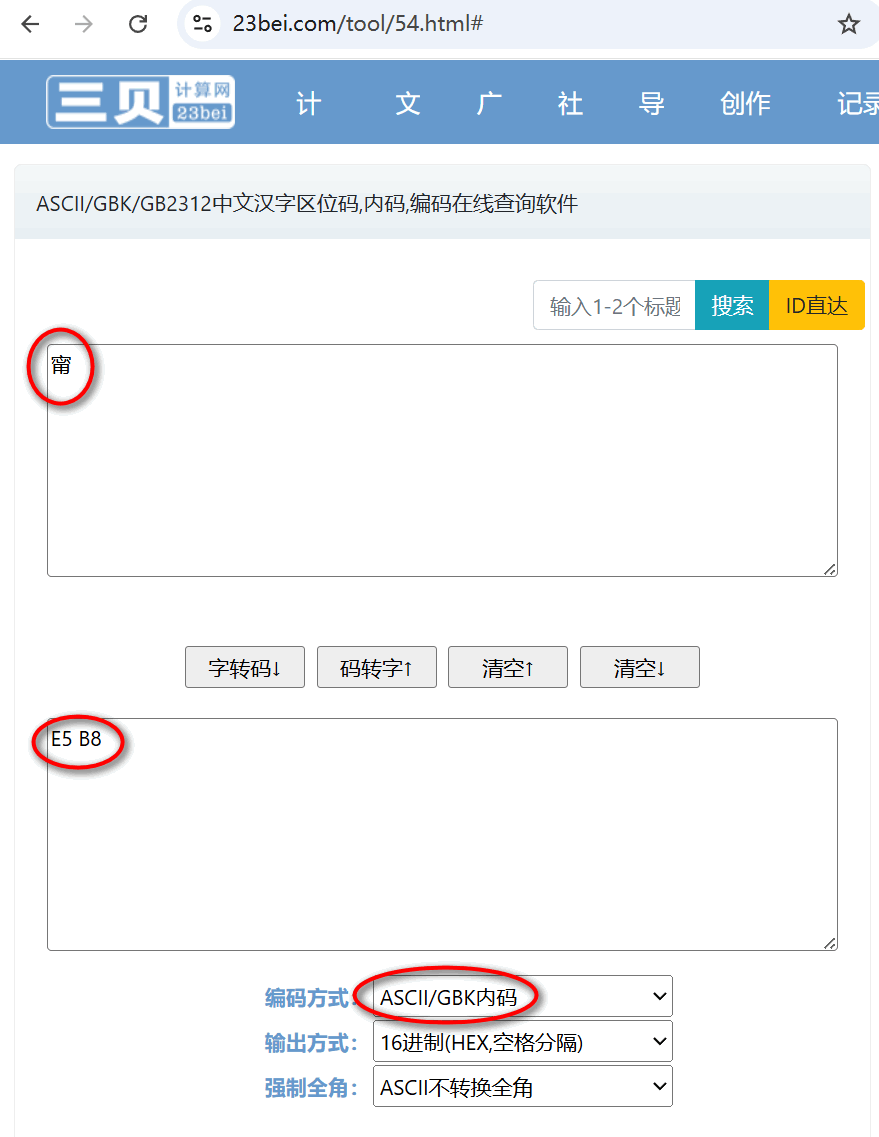
再试一下,B8 E8按GBK内码也 是转换成了歌字。(很显然这不是ASCII码)
这个事情的原理可能是这样的,autohotkey脚本中的SendInput函数,将后面的字符串流当成二进制形式的字符流,发送到了当前编辑器中,中文的windows默认二进制流采用的是GBK内码编码,因此就把原本是UTF-8形式存贮的28.35常衡,按GBK 内码形式解析成了28.35甯歌??(后面的a1 a1在GBK内码中对应是不显示的字符)。
换句话说,如果要发送的字符串是ASCII字符,无论哪种编码都是一样显示一样输出的,因为各编码体系中都是同样的码值。但一旦有了中文字符,sendinput本应要根据文件的编码方式(如UTF-8或其它方式),将字符串先转换为GBK内码的编码再输出,这样才能正确得到想到的字符。
当然,明白了这个原理,我们可以来个提前人工解码的操作,将GBK内码表示的“常衡”二字,加上2个空格组成6个字节(“B3 E3 BA E2 20 20”),直接存到脚本中,替换掉UTF8编码的字符串。 具体来说就是用十六进制编辑器直接修改,替换掉原脚本中的UTF8编码形式的“常衡”二字的编码(E5 B8 B8 E8 A1 A1)。至少B3E3、BAE2为什么代表常、衡二字,也是通过上面的网址通过字转码查询出来的。0x20代表的是空格。
经过这样的替换保存之后,启动输入法,输入relo重启词库之后, 再输入ozoz,跳出来的就是28.35常衡,完美解决问题。
不过这样处理之后,脚本文件中存在一个异常的不符合UTF8编码格式的地方,有时编辑器不能正确按UTF-8格式打开,这时需要我们重新按UTF-8格式强行打开文件就可以了,但它在这里会显示有点异常,因为它其实是GBK内码形式的字符,虽然不能正常显示为字符,编辑器notepad4还是显示了它的十六进制值。

进一步的思考,AHK的脚本在执行之前,在解释器默认按Windows的内码来读入的,因此它将字符串流当成是GBK内码形式的导致了出错。那我们能不能够告诉解释器,我们的脚本文件就是UTF-8编码方式,让它按UTF8编码来解析,这样不就不会乱码了吗?
查了一下AHK V1的文档,有一个FileEncoding函数,试了一下,发现这个是为脚本中的语句读写其它文件而设置的,并非让解释器读脚本文件时使用的。
搜索了一下,发现有人提出,可以在文件顶端写入EF BB BF三个字节表明这个文件是UTF8编码格式的,这样AHK解释器读入这个文件时,应该就会可以按UTF-8来解析了。
再次动手,用UltraEdit在脚本文件的最前面写了这三个字节。然后切换到文本编辑模式,将原来用GBK内码形式表示的字符(在UTF-8编码下,显示成问号了)删除,直接输入成所需要输出的文字,再保存。

试验了下,现在这样在文件中输入的是什么文字,跳出来的也就是什么文字,不再乱码了。
绕了这一大圈,终于搞明白了解释器对脚本的处理方式,因此做到了脚本文件中写代码的“所见即所得”。
也就是文件前面写一个BOM标志,保存时按UTF8保存,这样形式与内容都一致了,解释器可以得到了正确的提示,读到了正确的内容,输出也就正常,不再乱码了。
原来必须通过{U+2001C}这样的方式,或者上面以GBK内码形式的方式,都可以不用了,直接输入要输出的文字即可。标点符号的定义也就很方便了,如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号