最大的“字典”与 铹以后的元素名
(更新Unicode标准相关的内容 2025-7-5)
我有一部辞书叫"汉语大字典", 这是我见过收字量最大的字典.足足收集了6万多个汉字.看着这里面种种不认识的字, 不得不感叹, 汉字实在是太丰富了, 以前老人说“字有牛毛多,孔夫子只认识一只脚”,真不虚传。
当然,“字有牛毛多”只是比喻,还有比这个字典要多得多的字集,那就是国际通用的字符集 Unicode标准字符集。要想看看罕用字有多少,你可以看一下Unicode标准的rsindex.pdf文件(针对汉字)或是它的完整字符集 codecharts.pdf,它收集的汉字,绝对让一般人震惊!看着这些一个个查实论证的汉字,我不再觉得自己是个“博士”,而应该是个小学生,看着密密麻麻的生字,绝大部分我都不认识, 感觉自己认识的字都是九牛上那一根细毛.
不信,你可以下载这个文件打开来看看: RS Index.pdf
虽然没有任何字义解释,但是,作为一份国际公认的标准,Unicode的汉字收字量可能是最大的。我把它称为最大的字典(我不是文字专业人员,可能国内有在研的一些大汉字收集库我不知道或是没有对外公开),虽然这个字典只是收字,都没有任何注音与释义。(如果你想查汉字的释义,可以看看字海网或叶典网,这个网站挺不错)
如果你想知道这个汉字有没有被Unicode标准收录,查这个文件RSindex.pdf就对了。
RS是Radical Stroke的缩写,偏旁和笔画(也有用“笔划”这个词的)的意思。了解一下它的索引方式对提高查询速度是有帮助的。它前面是偏旁索引,每个偏旁都有一个编号,每个偏旁不同形态如简体、繁体是合并放在一起的。要注意的是,这个偏旁的设计与新华字典是有些不同的,采用的是“康熙字典”里的偏旁--比如建字底可以找到,但走之旁就看不到,其实它归入了编号162的偏旁。偏旁的编号也是从笔划少到笔划多来排列的。
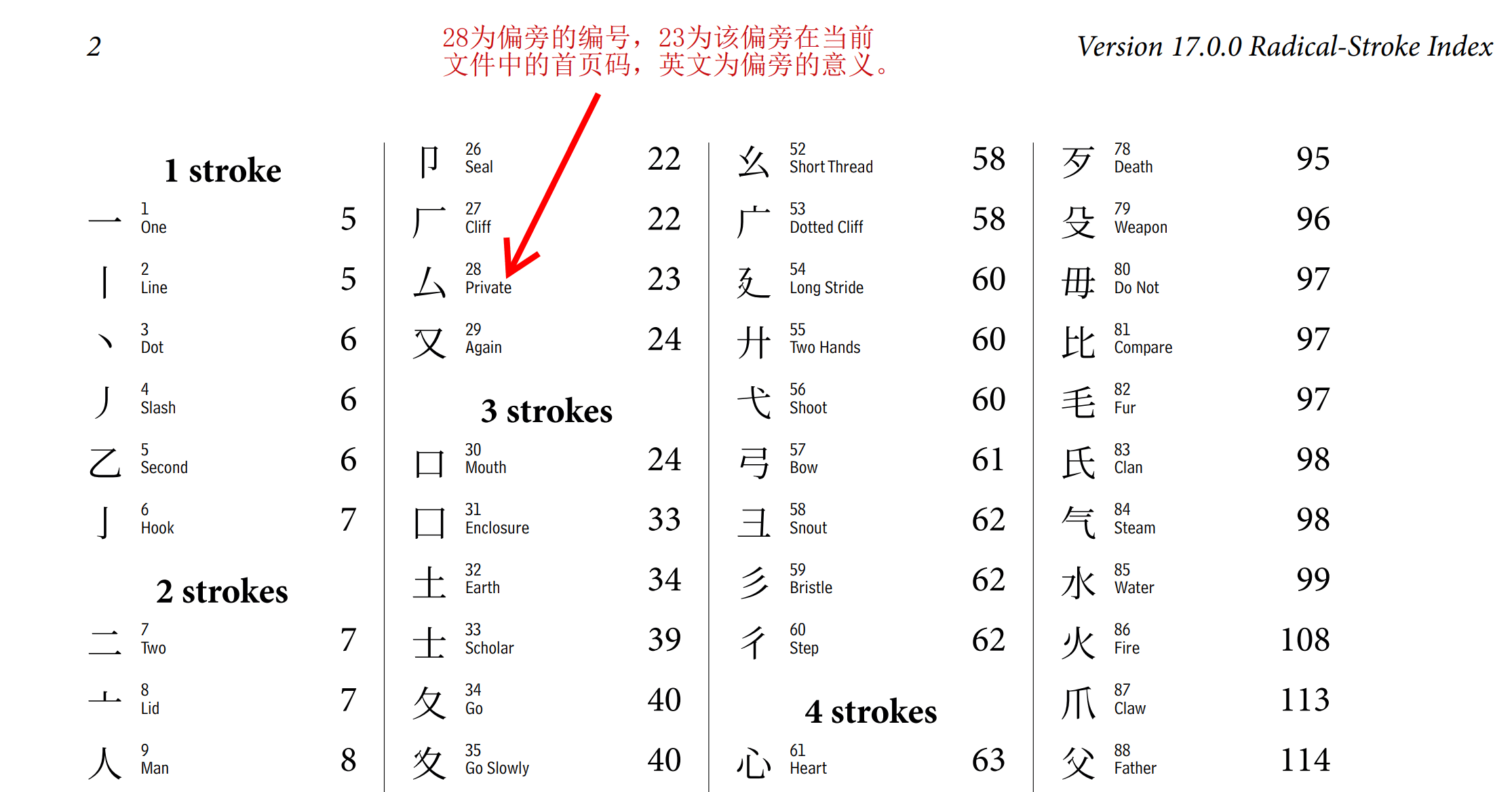
在正文检索部分,按偏旁的顺序从前往后排,每个偏旁之内,按剩下的笔划数来排。夹杂在正文中大一点的数字如1,2,3,4等,是除去偏旁后该汉字剩下的笔划数。当然首先排列的是偏旁自身这个汉字,其次是增加笔划的汉字。
在每个汉字下面有4位或5位的十六进制数字(0-9, A-F),代表的是这个字符在Unicode编码表中的码值(Code point), 说白了就是在标准中的唯一编号。这个是原始的编码,与文本文件中使用的UTF-8编码不是一回事,UTF-8(或UTF-16)它针对Unicode原始编码进行了一些变换以便于存贮/识别和传输。
现在你看一眼吧,厶字偏旁下,你认识哪些字?

最新的(尚未发布正式版,因此可能有小改动的)Unicode 版本为 17,目前在beta版。
说到这里,再说几个特殊的例子,前面讲过的biang字是一例,这里再讲一些新发现的化学元素用的汉字,这些新的化学元素名(由“全国科学技术名词化学名词审定委员会” 规定),平时很难打出来,主要困难在于:1)多数输入法没有收录它们 ,2)大多数字体文件也没有收录它们 3)还有些情况下软件不支持这类汉字的显示。 所以有时人们不得不用两个字来表示这种汉字。但其实如果知道方法,是可以打出来的。对应的方法是(以下条件都要具备)
1)找到支持这种汉字输出的输入法,要不你就去别的地方一个一个复制,或者Word中还可以用Unicode编码+Alt-X快捷键来输入。五笔输出的这里有一个 黄狗大字符输入法,拼音的我不知道,有些汉字的拼音可能都没有标准,是不是拼音输入法就无法使用?
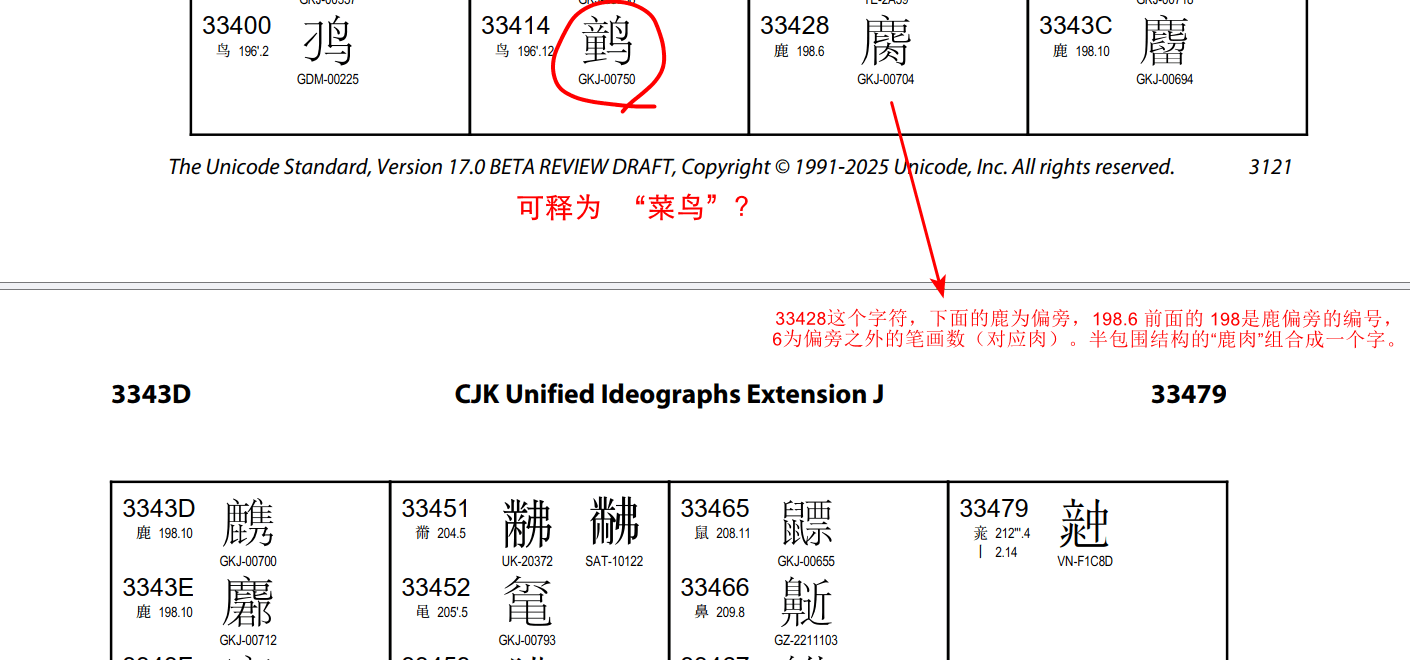
2)找到支持这种汉字的字体并安装。上面的输入法安装带了一个这样的字体,你也可以再找找别的支持大字符集的字体。因为CJK汉字在标准收录中是不断扩展的,从扩展A一直到今年将发布的扩展J。到目前为止,能够支持到扩展J的字体还没有看到,只有在Unicode标准的PDF文件中查看这些字。
如果找不到支持的字体,那就只有自己造字或者用图片替代字了,然后等着字体更新了,需要一定的时间。
3)软件要支持这种大字符集的汉字显示,有些英文小软件可能是支持不了,我知道Office的几个软件应该是没有问题的。
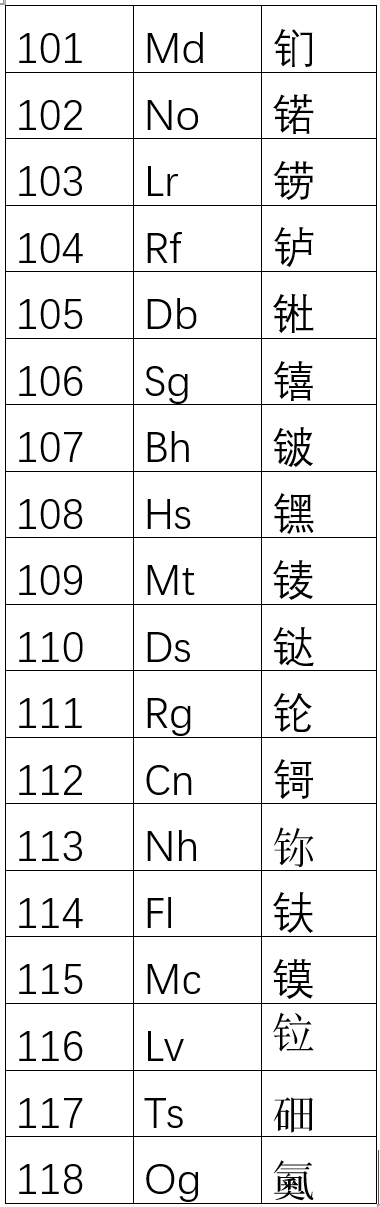
所以,我特意在这个大字典中,找到了113铹之后的几个元素的汉字。如果要用到这几个汉字,你可以在rsindex.pdf这个文件中,根据偏旁找到你要的字,再复制到你的软件中(少数情况下即使某些字即使文本复制了也复制不出来要的内容,原因在后面的博客中讲)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号