
HR系统数据清洗实战:六大难题逐项破解与落地流程详解
HR系统里的“数据不靠谱”到底有多坑?
业务部门质疑:报表不准、口径不一
在不少企业的人力资源部门,数据报表经常成为“众矢之的”。
举个常见场景:季度末,HR小王加班赶出一份《全员月度出勤统计》,满心以为这次数据齐全、公式也全新校对过。可邮件一发出去,业务部门很快打回:“我们一线项目上明明有10人转岗,怎么还显示在原岗位?还有,出勤天数和我们自己统计的对不上。”
这类质疑并非个案。HR系统里的数据如果没有统一标准、及时更新和有效清洗,经常会出现“同一员工多种写法”“转岗未同步”“历史数据残留”等问题。每次被业务部门追问,HR只能一条条去查底表、核对原始记录,既耗时又难以彻底解决。
领导追问:数据对不上,责任难追溯
更让人头疼的是,领导层对数据的期望越来越高。比如,某集团总公司要求各下属单位上报年度人力成本分析报表,想通过数据辅助决策。但等到各分子公司的数据汇总后,发现“全员人数”“用工成本”“离职率”三个核心指标在总部和分公司报表中都对不上号。
领导的一句“为什么数据不一致?哪份才是准的?”往往让HR团队陷入长时间的“溯源大作战”:有的数据源自旧系统,有的手工录入,有的口径不同,责任归属模糊,事情一推再推,结果分析报告迟迟出不来。
案例还原:集团员工信息初始化时的“数据混乱现场”
以某大型制造集团为例,在HR系统上线初期需要对全体员工信息进行数据初始化。这个过程中,HR团队从多个来源(旧人事系统、Excel表、员工自助填报)汇总数据,结果却发现:
- 员工姓名有不同写法(如“王伟”“王伟A”“王 伟”)
- 身份证号和出生日期不一致,部分缺失
- 岗位名称、工号、手机号、邮箱等字段格式混乱
- 部分员工重复导入,导致同一人在系统中出现多条记录
- 部门名称既有“研发部”又有“技术研发”,同一部门多种写法
这导致后续任何统计报表都“对不上”——离职人数、岗位调动、薪酬调整等核心数据只能靠人工反复比对,严重影响HR运营效率和数据分析的准确性。
六大清洗难题:HR数据治理的“拦路虎”
1. 字段标准化:同一员工多种写法,系统分析崩溃
在HR系统导入员工信息时,经常遇到同一员工名字、部门、岗位等字段出现多种写法。比如,“李晓明”也被写作“李小明”、“LXM”,部门既有“市场部”又有“市场中心”,岗位既有“技术员”也有“技术专员”。
带来的影响:
- 系统分组或汇总时,同一个人/部门被拆成多条,统计结果失真
- 智能分析、自动画像等功能无法准确归集员工数据
- 新系统上线初期,数据标准不统一导致自动导入失败,需反复人工校对
2. 缺失值与异常值:数据不全,分析无从下手
在做员工信息初始化或数据迁移时,发现部分员工的身份证号、工号、联系方式缺失,甚至部分薪资字段被错误地填为0或9999。
带来的影响:
- 无法唯一识别员工,后续流程(如薪酬、社保申报)易出错
- 薪酬分析、离职率等关键指标失真
- 部分数据因异常值被系统自动忽略或报错,影响整体数据分析链路
3. 结构混乱:一张表装下所有,数据难以利用
在Excel或旧系统导出数据时,常见一张表里既有员工基本信息、岗位变化记录,又有绩效、薪酬等混杂字段。表格字段命名杂乱,甚至存在合并单元格和多级表头。
带来的影响:
- 系统自动导入失败,需要手工拆表、重命名、格式转换
- 后续查询、统计、可视化分析难以实现自动化
- 数据溯源、历史追踪难度大,容易丢失关键业务信息
4. 主键混乱/主数据缺失:跨系统ID对不上
HR系统、考勤系统、财务系统各有一套员工ID,导致同一人在不同系统中ID各异。数据集成时,人员信息无法一一对应。
带来的影响:
- 各业务系统间数据打不通,无法实现自动化对账、同步
- 组织大调整、员工调岗、离职等关键业务流转断层
- 数据接口开发、数据治理成本高,业务协同效率低
5. 重复冗余:一人多条记录,报表乱套
员工信息导入过程中,同一人因历史数据、系统导入、手工录入等原因出现多条记录,有的甚至因名字小差异而被系统误判为不同人。
带来的影响:
- 全员人数、薪酬总额等核心指标被高估
- 离职率、调岗率等分析失准
- 后续流程如调薪、晋升审批反复出错
6. 业务口径不一:同名字段不同算法,协同分析无共识
同样叫“月度绩效”,有的部门按满分100分计,有的按系数算,有的直接填“优秀/良好/一般”。报表合并时,数据口径完全对不上。
带来的影响:
- 绩效分析、激励分配不具可比性,失去决策参考价值
- 跨部门协同、集团层面的人才画像、智能分析都失效
- 系统升级、数据迁移时需大量手动修正口
HR数据清洗的分场景实操经验分享
1. 字段标准化:字典表、映射规则和前端校验
我们在HR系统上线初期,针对员工姓名、部门、岗位等关键字段,会建立了集团级的“数据标准字典表”。具体流程如下:
- 汇总现有数据:收集各子公司、各业务线的现用字段(如部门名、岗位名)。
- 制定标准口径:明确每个字段的唯一标准写法,例如“研发部”统一为“产品研发部”,所有岗位名称均采用全称。
- 建立映射表:将历史数据中的各种写法一一对应到标准口径,并在数据导入脚本中内置自动转换规则。
- 前端输入校验:HR系统前端设置下拉选项、自动补全等机制,防止新数据录入时出现未标准化内容。

2. 缺失值与异常值处理:三看法则与分级补全
在员工信息数据初始化时,HR团队会设定“字段重要性分级”+“业务校验”原则:
- 核心字段(如工号、身份证号):缺失直接剔除,需一对一人工补全或员工自助核查后方可入库。
- 次要字段(如邮箱、手机号):允许留空,但标记为“需后续补全”。
- 异常值:如薪酬字段为0或9999,自动触发“人工复核”流程,由业务负责人确认是否为真实业务场景(如实习生0薪或测试数据)。
3. 数据结构规范:宽表/长表设计与分拆
针对“历史一张大表装所有”的混乱局面,集团信息化团队推动“结构分拆”:
- 组织表、岗位表、员工主表三分离:系统中每张表只承载单一业务对象,字段命名标准化,并建立外键关联。
- 业务流程驱动数据动态更新:比如员工调岗、晋升、离职,均通过业务流程自动变更数据结构,避免手工修改带来混乱。
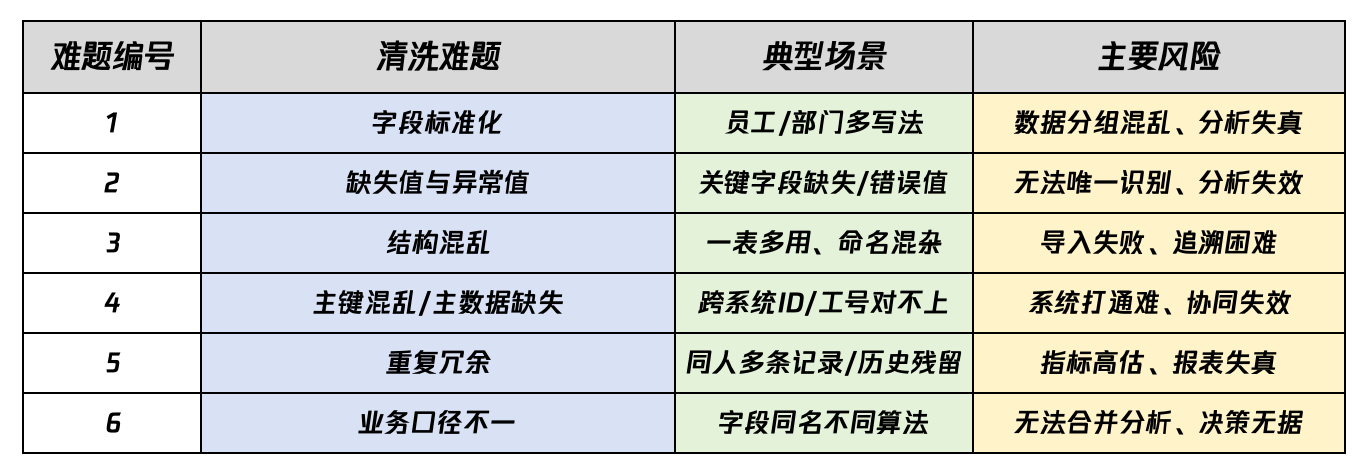
4. 主数据治理与ID映射:让多系统说“同一种语言”
为解决“跨系统ID不一致”问题,集团在eHR系统中设立“主数据管理模块”:
- 唯一员工ID生成机制:每位员工在eHR系统中生成唯一主键,其他业务系统全部以此为对照。
- ID映射表维护:跨系统同步时,自动将考勤、财务、OA等系统的原ID映射到eHR主ID,避免数据“漂移”。
- 主数据系统同步:对于大型企业,所有业务系统都与主数据平台集成,减少接口开发与维护难度。
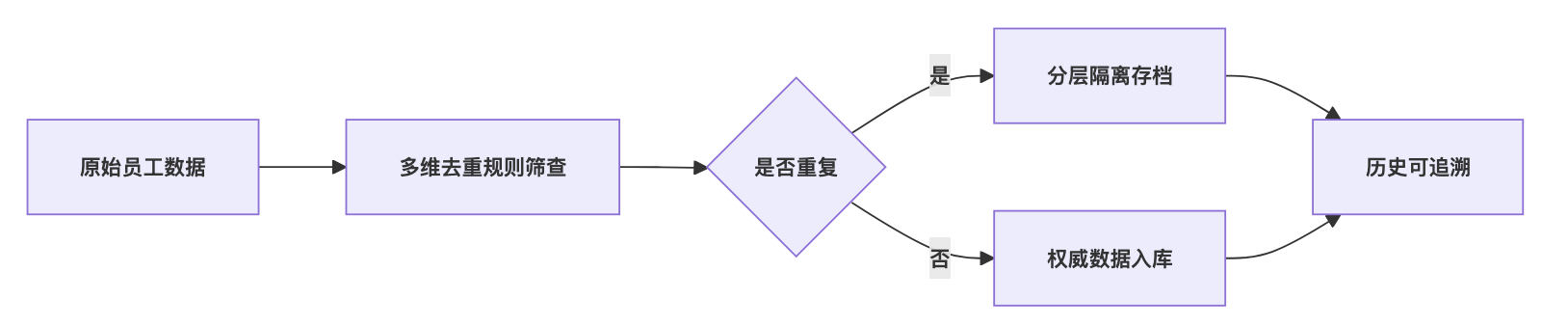
5. 多维去重与冗余过滤:权威记录与追溯链路
针对“同一员工多条记录”的问题:
- 多维去重规则:以“姓名+身份证号+入职时间”为复合主键,筛查重复数据。
- 分层过滤机制:测试数据、演示数据、历史无效数据进入专用“隔离表”,不参与正式统计。
- 权威数据标记:每条数据根据更新时间、来源打标签,只保留最新且权威的那条,历史记录可追溯。
6. 口径统一:字段解释、算法定义和悬浮提示
为避免“同名不同算法”带来的分析混乱:
- 口径文档归口管理:每一个关键业务字段都由集团统一发布“口径解释”,如“绩效分数=得分*权重,不含加分项”。
- 系统内置悬浮提示:HR系统和BI报表界面,相关字段均有“口径说明”悬浮提示,便于用户随查随用。
- 口径变更可追溯:所有字段口径变动均留有历史版本,便于分析前后的数据差异。
数据治理的价值与趋势
在很多企业里,HR数据清洗总被默认为一项枯燥而琐碎的幕后工作,仿佛只是为上线做准备的“脏活累活”。实际上,真正成熟的HR数字化体系,绝不会把数据治理当成临时补丁,而是将其视作企业管理能力的重要组成部分。只有把清洗、标准化、结构治理等动作落实到每一个数据流转细节,HR数据才能变成有价值的资产,而不仅仅是填表、导报表的原材料。
随着企业数字化转型不断深入,数据治理的影响力已经远远超出了HR部门本身。以往那种拼盘式的系统集成,业务系统各自为政,数据维护分散,最终导致的不是效率提升,而是“数不可用”——报表对不上、分析做不准、责任难追溯。越来越多的大型组织开始意识到:只有从根本上统一数据标准、建立主数据平台,让eHR系统成为唯一权威的数据源,才能让各业务系统协同运作,减少接口开发和维护的反复投入,也让数据在企业内部真正流动起来。
更值得关注的是,系统性的数据治理不是一次性投入,而是长期与业务流程深度绑定的机制。从员工入职、调岗、离职、薪酬变动,到每一次组织架构调整,数据的生成、修改和归档都应有严格的校验和标准。如果说过去的数据清洗像是“临时打扫”,那么现在的主流做法则是“嵌入式维护”——用自动校验、流程驱动让脏数据无处遁形,让数据质量成为业务流转的天然副产品。
这种转变带来的最大变化,是让HR数据成为真正的决策底座。无论是推进智能排班、精准薪酬管理,还是支撑HRBI报表、人才画像、组织健康度等高阶分析,数据质量的提升都直接决定了数字化成果的上限。数据治理已经不是谁来“背锅”的苦差事,而是企业数字化能力的核心竞争力之一。未来,那些把数据治理做到日常、做进流程的企业,才有可能在智能化、自动化的时代走得更远。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号