深度学习—梯度消失和爆炸、权重初始化
1、梯度消失和爆炸
梯度消失:一是在深层网络中;二是采用了不合适的损失函数,比如sigmoid(导数最大为0.25,神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。)。
梯度爆炸:一般出现在深层网络和权值初始化值太大的情况下。前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。
前向传播得到的结果与实际的结果得到一个偏差,然后通过梯度下降法的思想,通过偏导数与残差的乘积通过从最后一层逐层向前去改变每一层的权重。通过不断的前向传播和反向传播不断调整神经网络的权重,最终到达预设的迭代次数或者对样本的学习已经到了比较好的程度后,就停止迭代,那么一个神经网络就训练好了。
反向传播是梯度的连乘向前传更新权重。如果此部分大于1,那么层数增多的时候,最终的求出的梯度更新将以指数形式增加,即发生梯度爆炸;如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
2、解决方法
(1)梯度消失(深度网络中出现更多):
- 用ReLU激活函数来替代sigmoid函数;
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 残差学习;
- 批量归一化。
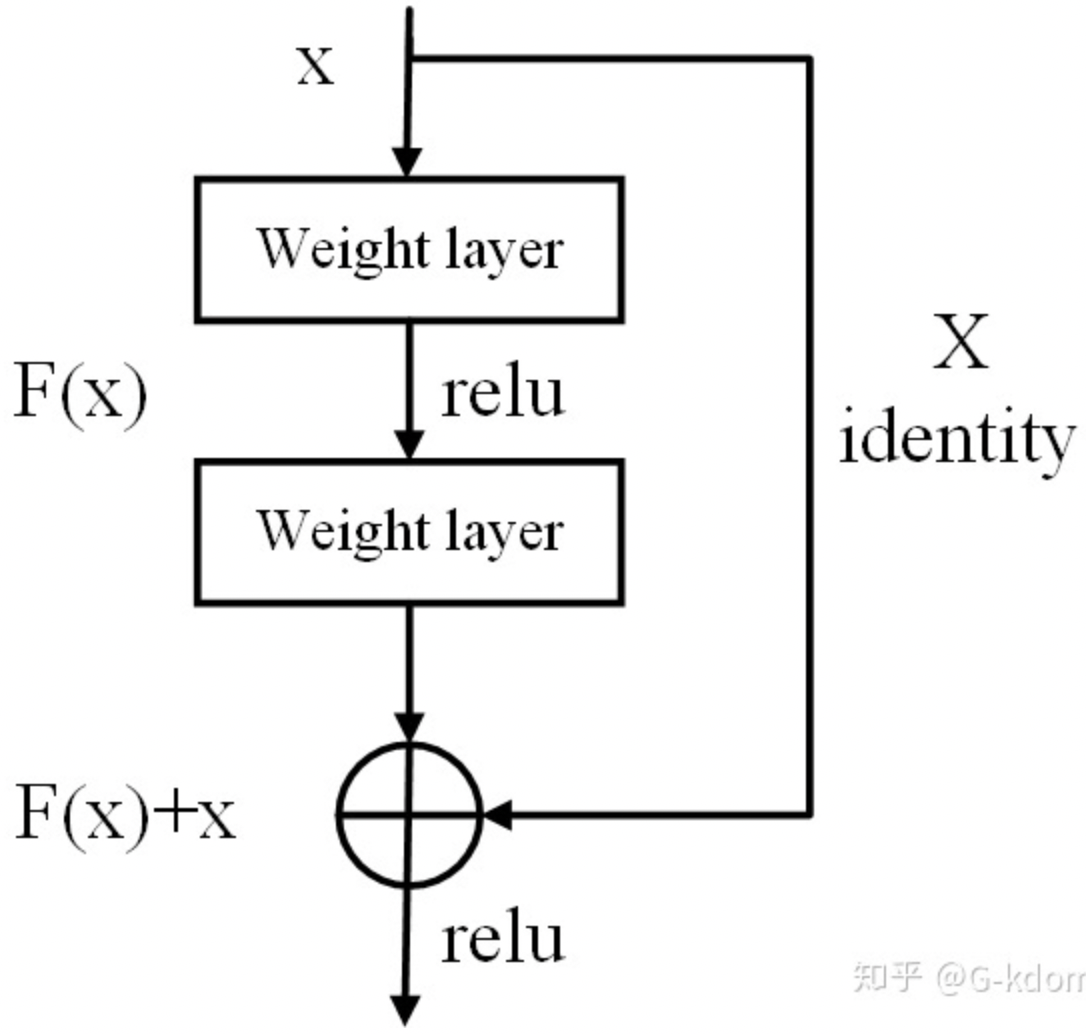
(2)梯度爆炸:
- 减少学习率;
- 权重正则化;
- 批量归一化;
- 因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取;
- 预训练 + 微调;
3、权重初始化
1、为什么需要权重初始化?
- ① 为了使神经网络在合理的时间内收敛;
- ② 为了尽量避免在深度神经网络的正向(前向)传播过程中层激活函数的输出梯度出现爆炸或消失。
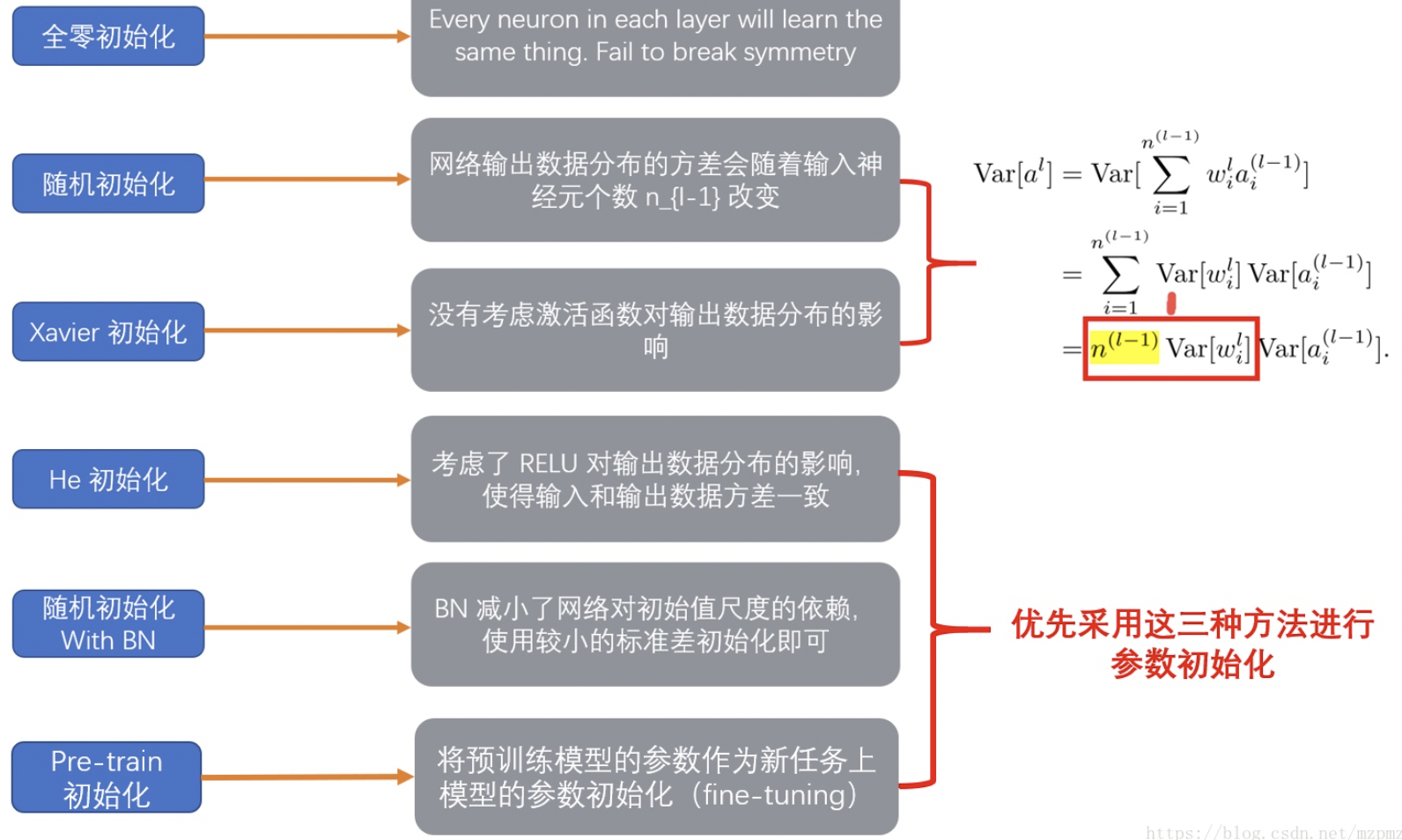
初始化为0或一固定值问题:
(a)w初始化全为0,很可能直接导致模型失效,无法收敛。全零初始化方法在前向传播过程中会使得隐层神经元的激活值均为0,在反向过程中根据BP公式,不同维度的参数会得到相同的更新。需要破坏这种“对称性”。
(b)如果将参数都初始化为0周围极小的值:也不好,比如如果用sigmoid做激活函数,它在0周围是近似线性的,如果我们的参数都初始化为0附近,那么可能数据经过神经元之后,大部分都落在线性区,那么我激活函数引入非线性的作用将被削减。
(c)如果参数都初始化为较大的值,很显然容易使得输出落入饱和区。
所以合理的初始化时比较重要的,一般采用随机的初始化。(在cnn中,w的随机化,也是为了使得同一层的多个filter,初始w不同,可以学到不同的特征,如果都是0或某个值,由于计算方式相同,可能达不到学习不同特征的目的)
(1)均匀分布初始化
在一个给定的区间[-r,r]内采用均匀分布来初始化参数。超参数r的设置可以按照神经元的连接数量进行自适应的调整。
(2)高斯分布初始化
可以选择随机初始化为很小的值(非常接近0的小数,正如我们上面所讨论的不能等于0)。上述建议的一个问题是,随机初始化神经元的输出的分布有一个随输入量增加而变化的方差。
目的是为了使神经元的输出服从均值为0,方差为1的正态分布,产生有效的激活。

在广泛采用 Batch Normalization 的情况下,使用普通的小方差的高斯分布即可。
(3)截断的正态分布
正态分布有个3σσ原则,意思就是99.7%的点都在距离中心3个标准差之内。换句话说,随机初始化的权值依然是有可能是离中心点比较远的。假设我们用了sigmoid作为激活函数,一旦初始值过小,或者过大,就可能会导致输入到隐藏层的数据太小或者太大,从而进入饱和区。一旦进入饱和区,这些对应的neuron就死掉了,再也不会更新了。所以为了防止这个dying neuron现象,我们就用了截断正态,保证初始的权值不太大也不太小。将权重在离均值两个标准差外的值去掉。
(4)随机初始化
随机初始化是很多人目前经常使用的方法,然而这是有弊端的,一旦随机分布选择不当,就会导致网络优化陷入困境。
(5)Xavier 初始化(Xavier Initialization)
Xavier(发音[‘zeɪvɪr])(适用于激活函数是 Sigmoid 和 tanh),初始化是兼顾了BP过程的除以( (n_in + n_out)/2 ),Xavier初始化的基本思想是保持输入和输出的方差一致,这样就避免了所有输出值都趋向于0。注意,为了问题的简便,Xavier初始化的推导过程是基于线性函数的,但是它在一些非线性神经元中也很有效。
(6)He initialization
在ReLU网络中,假定每一层有一半的神经元被激活,另一半为0,所以,要保持variance不变,只需要在Xavier的基础上再除以2
深度学习权重的初始化的太小,那信号将会在每层传递时逐渐缩小导致难以产生作用,如果权重初始化的太大,那信号将在每层间传递逐渐放大导致发散和失效,根据深度学习大牛的理论说明列,权重应该是满足均值为0,(Xavier初始化)方差为2除以两层神经元个数之和,就是权重链接的那两层。满足的分布就是均匀分布或者高斯分布。
(7)批量归一化
批量归一化放在激活函数之前,使网络对初始化更鲁棒。
参考文献:https://blog.csdn.net/qq_25737169/article/details/78847691

 浙公网安备 33010602011771号
浙公网安备 33010602011771号