机器学习(三十五)— AUC 原理及计算方式
1、AUC(Area Under Curve)原理
ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)

ROC曲线:
- 横坐标:假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率;
- 纵坐标:真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。
对角线对应于随机猜测模型,而(0,1)对应于所有正例排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。

推荐系统的 auc:https://mp.weixin.qq.com/s/e3qcSo8LPDf2S8TUvU6S1A
AUC代表模型预估样本之间的排序关系,即正负样本之间预测的gap越大,auc越大。
- ROC曲线反映了分类器的分类能力,结合考虑了分类器输出概率的准确性
- AUC量化了ROC曲线的分类能力,越大分类效果越好,输出概率越合理
- AUC常用作CTR的离线评价,AUC越大,CTR的排序能力越强
计算逻辑问题:
AUC计算是基于模型对全集样本的的排序能力,而真实线上场景,往往只考虑一个用户一个session下的排序关系。这里的gap往往导致一些问题。正如参考[3]中的举例的几个case,比较典型。主要包括两点:
- 线上会出现新样本,在线下没有见过,造成AUC不足。这部分更多是采用online learning的方式去缓解,AUC本身可改进的不多。
- 线上的排序发生在一个用户的session下,而线下计算全集AUC,即把user1点击的正样本排序高于user2未点击的负样本是没有实际意义的,但线下auc计算的时候考虑了它。
- 改进:deepES 数据分析时,分用户进行 pnr 统计;
2、计算方式
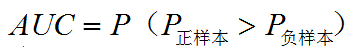
![]()
AUC的计算主要以下几种方法:
1、计算ROC曲线下的面积。这是比较直接的一种方法,可以近似计算ROC曲线一个个小梯形的面积。几乎不会用这种方法
2、从AUC统计意义去计算。所有的正负样本对中,正样本排在负样本前面占样本对数的比例,即这个概率值。
- 具体的做法就是它也是首先对prob score从大到小排序,然后令最大prob score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。
- 然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。
- 得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。
- 最后再除以M×N。

(1)方法一:


具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
(2)方法二
参考文献:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号