第一次个人编程作业
https://github.com/eiheihei233/031902420
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 300 | 600 |
| · Coding | · 具体编码 | 300 | 800 |
| · Code Review | · 代码复审 | 60 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 920 | 1985 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。
3.1.1 代码的组织架构
首先确定一个类来放入主函数对程序总体进行控制。分别创建原文件类,关键字类和答案类将读入的数据和要输出的数据进行存放。一个搜索类用来进行屏蔽字的搜索,一个转换类将中文字符转换为拼音。
一共有七个类对程序进行控制。
TxtRead类:传入地址字符串转化为UTF-8码的BufferReader并传出
FileLine类:存入文件每一行的信息,包括行内容,所在行数,行内字符数量,并开放get,set。
MaskWords类:存入屏蔽字的内容和屏蔽字的内容,并开放get,set。
Answer类: 存入屏蔽字所在行,屏蔽字总数,屏蔽字,原文中的屏蔽字显示。
SeekFunction类: 一个函数seek,进行遍历对原文和屏蔽字进行搜索。
ChineseChange类: 将中文转换为拼音,通过Ascii码进行转换。
mainControl类: 对程序进行总控。
3.1.2 算法的关键:搜索函数
首先对屏蔽字进行分类,当屏蔽字为英文时只需要对字符串进行遍历,比较简单,只要注意屏蔽字的开始位置在搜索结束位置的时候也要进行改变。
当屏蔽字为中文的时候,当文章也为中文相同的字时和英文的情况相同。当文章为拼音时将关键字转化为拼音进行比较,同音字部分和偏旁部分没有实现。
独到之处:简单但是很不全面,我没有下载第三方拼音包来跑,只用了最简单的ASCII码将中文转化为英文,还有很多的漏洞。(很多东西都不会,算法看了网络上的开源算法,但是太菜了)
(3.2)计算模块接口部分的性能改进。
写这个程序都没有写完全部的功能,性能改进更是达不到那步。
改进思路有很多,比如换一个算法,下载一个第三方库进行偏旁部首的检测,拼音部分的检测也做得不全面,还有很多要做。
性能分析图
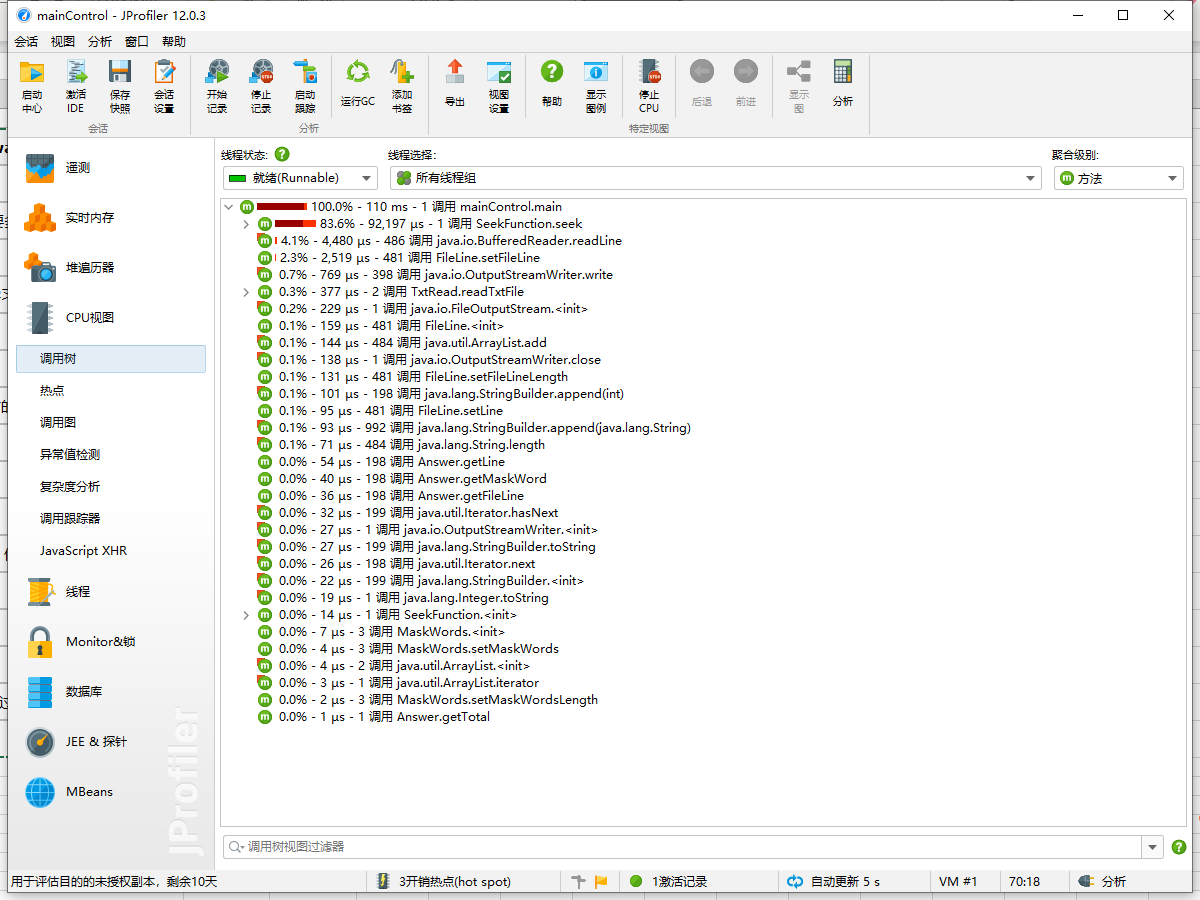
程序中消耗最大的函数
public ArrayList<Answer> seek(){
for (FileLine fileLine : fileLineArrayList) {//fileLine 既为每一行的数据
String fileStr = fileLine.getFileLine(); //要寻找的字符串
int fileLength = fileLine.getFileLineLength(); //字符串长度
int fileNumber = fileLine.getLine(); // 字符串所在行数
for (MaskWords maskWord : maskWordsArrayList) { //对每一个屏蔽字进行判断
String maskStr = maskWord.getMaskWords(); //屏蔽字的字符串
int maskLength = maskWord.getMaskWordsLength();// 屏蔽字的长度
if ((maskStr.charAt(0) >= 'a' && maskStr.charAt(0) <= 'z') || (maskStr.charAt(0) >= 'A' && maskStr.charAt(0) <= 'Z')) { //屏蔽字为英文
int minChar = 0;
int maxChar = fileLength - 1;
int value; // 用于存放字符匹配个数
for (int k = 0; k < fileLength; k++) {
value = 0;
if (maskStr.toUpperCase().charAt(value) == fileStr.toUpperCase().charAt(k)) {
minChar = k; //找到起始位置
value = 1;
for (int l = k + 1; l < fileLength; l++) {
if(fileStr.toUpperCase().charAt(l) == maskStr.toUpperCase().charAt(0)){ // 起始位置的变动
minChar = l;
}
if(fileStr.toUpperCase().charAt(l) == maskStr.toUpperCase().charAt(value)){
value++;
}
if(fileStr.toUpperCase().charAt(l) == maskStr.toUpperCase().charAt(maskLength - 1)){
maxChar = l;
break;
}
}
}
if (value == maskLength) { //样例输出
Answer answer = new Answer();
Answer.setTotal(Answer.getTotal() + 1);
answer.setLine(fileNumber);
answer.setMaskWord(maskStr);
answer.setFileLine(fileStr.substring(minChar,maxChar + 1));
answerArrayList.add(answer);
}
}
}else { // 屏蔽字为中文
int minChar = 0; //屏蔽字的开始位置
int maxChar = fileLength - 1; //屏蔽字的结束位置
int value; // 用于存放字符匹配个数
for (int k = 0; k < fileLength; k++) {
value = 0;
String maskCharString = maskStr.substring(value,value + 1); //将屏蔽字的每一个字分开
String maskPinYin = new ChineseChange().convertAll(maskCharString); //将关键字变成拼音
int flag = 0; //关键字拼音匹配个数
for (int i = 0; i < maskPinYin.length(); i++) {
if(i + k >= fileLength) break; //防止越界
if (maskPinYin.toLowerCase().charAt(i) == fileStr.toLowerCase().charAt(i + k)){
flag++;
}
}
// 屏蔽字和原文相同 屏蔽字拼音和原文相同 屏蔽字拼音缩写和原文相同
if (maskCharString.charAt(value) == fileStr.charAt(k) || flag == maskPinYin.length() || maskPinYin.toLowerCase().charAt(0) == fileStr.toLowerCase().charAt(k) ) {
minChar = k;
value = 1;
char pri = maskPinYin.charAt(0);
for (int l = k + 1; l < fileLength; l++) {
maskCharString = maskStr.substring(value,value + 1);
maskPinYin = new ChineseChange().convertAll(maskCharString);
int flag1 = 0;
for (int i = 0; i < maskPinYin.length(); i++) {
if (i + l >= fileStr.length()) break;
if (maskPinYin.toLowerCase().charAt(i) == fileStr.toLowerCase().charAt(i + l)){
flag1++;
}
}
if(fileStr.charAt(l) == maskStr.charAt(0) || fileStr.toLowerCase().charAt(l) == pri){
minChar = l;
value = 1;
}
if(fileStr.charAt(l) == maskStr.charAt(value) || maskPinYin.toLowerCase().charAt(0) == fileStr.toLowerCase().charAt(k)){
value++;
}
if(fileStr.charAt(l) == maskStr.charAt(maskLength - 1)){
maxChar = l;
break;
}
}
}
//拼音的缩写 未完成
//偏旁部首 未完成
if (value == maskLength) { //样例输出
Answer answer = new Answer();
Answer.setTotal(Answer.getTotal() + 1);
answer.setLine(fileNumber);
answer.setMaskWord(maskStr);
answer.setFileLine(fileStr.substring(minChar,maxChar + 1));
answerArrayList.add(answer);
}
}
}
}
}
return answerArrayList;
}
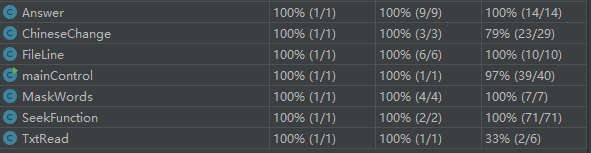
(3.3)计算模块部分单元测试展示。
直接将QQ群给的测试样本传入到程序中
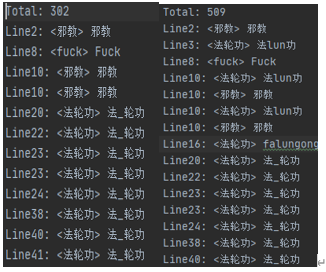
对中文转换单独进行测试
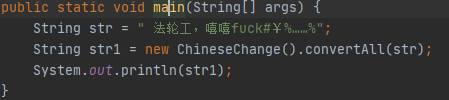
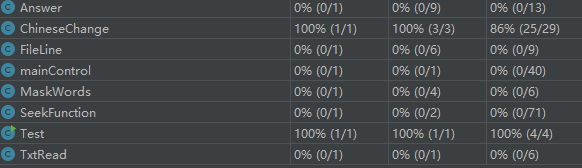
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
IO文件读取失败
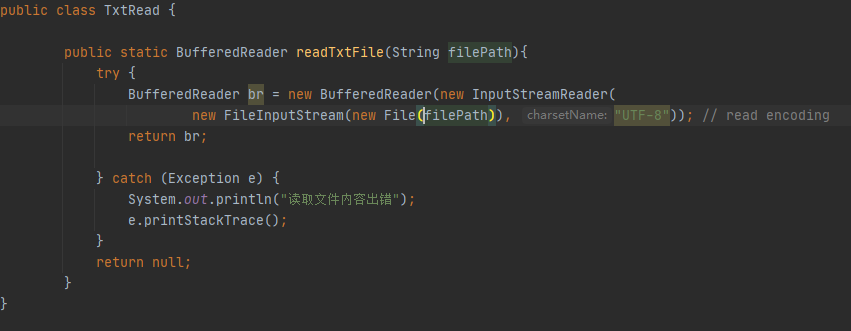
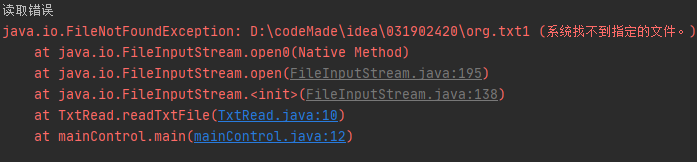
三、心得
(4.1)在完成本次作业过程的心得体会(3')
第一次正式的使用GitHub,遇到很多的问题,GitHub到现在我连接还是时灵时不灵,把hosts改了之后就更进不去了,试了很多方法还是没有解决,只能多刷新几次碰运气进网站。
了解到IDEa中很多实用的插件,覆盖率和性能分析都是第一次使用。在代码部分没有事先上网查资料就直接写的做法很蠢,第三方库的下载和使用还没有搞懂,所以很多功能都没有实现。
在之后还要完善很多东西。Java我也是假期才开始学习,很多基本的用法都没有学完,这次的任务在刚拿到手的时候有很多思路,奈何基础不好,本来想用正则去做,但是写一行错一行,就
换了一种暴力的思路,要学的东西还有很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号